

Methoden zur Verbesserung der Webserverleistung

| Einführung | Mit der kontinuierlichen Entwicklung des Internets werden immer mehr Bedürfnisse im täglichen Leben über das Internet erfüllt. Von Lebensmitteln, Kleidung, Wohnen und Transport bis hin zu finanzieller Bildung, von Taschen bis hin zu Identität verlassen sich die Menschen ständig auf das Internet Immer mehr Menschen nutzen das Internet, um ihre eigenen Bedürfnisse zu erfüllen. |
Als Webserver, der direkt auf Anfragen von Kunden reagiert, muss er zweifellos mehr Anfragen gleichzeitig standhalten und Benutzern ein besseres Erlebnis bieten. Zu diesem Zeitpunkt stellt die Leistung der Webseite häufig einen Engpass für die Geschäftsentwicklung dar und es ist dringend erforderlich, die Leistung zu verbessern. Der Autor dieses Artikels hat einige Erfahrungen zur Verbesserung der Leistung des Webservers während des Entwicklungsprozesses zusammengefasst und mit allen geteilt.
ProblemanalyseFür die Leistung des Webservers analysieren wir zunächst die relevanten Indikatoren. Aus Benutzersicht gilt: Wenn ein Benutzer einen Webdienst aufruft, ist die Benutzererfahrung umso besser, je kürzer die Rückgabezeit der Anforderung ist. Aus Serversicht ist die Serverleistung umso stärker, je mehr Benutzeranfragen gleichzeitig übertragen werden können. Durch die Kombination der beiden Aspekte fassen wir die beiden Richtungen der Leistungsoptimierung zusammen:
1. Erhöhen Sie die maximale Anzahl gleichzeitiger Anfragen, die der Server unterstützen kann
2. Verbessern Sie die Bearbeitungsgeschwindigkeit jeder Anfrage.
Die Optimierungsrichtung wird geklärt. Zunächst führen wir ein gemeinsames Architekturmuster auf der Serverseite ein, das heißt, eine Webanfrage von einem Browser oder einer App wird über mehrere Strukturebenen auf der Serverseite verarbeitet und zurückgegeben.
Architekturmodus: IP-Lastausgleich->Cache-Server->Reverse-Proxy->Anwendungsserver->Datenbank
Wie in Abbildung 1 gezeigt, geben wir zur Vereinfachung der Erklärung ein praktisches Beispiel: LVS(Keepalived)->Squid->nginx->Go->MySQL
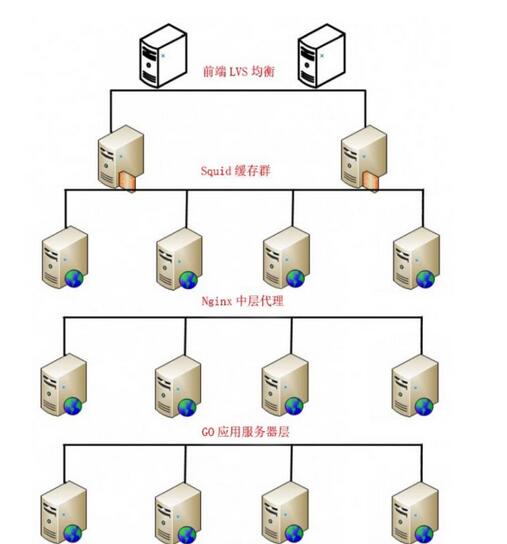
Abbildung 1: Serverseitige Architektur
Wir verteilen Anfragen auf jeder Ebene, sodass mehrere Zweige der Struktur auf niedrigerer Ebene gleichzeitig arbeiten können, um die maximale Gesamtzahl der Parallelitäten zu erhöhen.
In Kombination mit der Architektur analysieren wir, welche Probleme normalerweise die Leistung beeinträchtigen und finden die entsprechenden Lösungen.
Unter normalen Umständen sind die Ebenen des IP-Lastausgleichs, des Cache-Servers und des Nginx-Proxys hauptsächlich Probleme mit der Clusterstabilität. Die Orte, an denen es häufig zu Leistungsengpässen kommt, sind die Anwendungsserverschicht und die Datenbankschicht. Nachfolgend sind einige Beispiele aufgeführt:
1. Auswirkungen der Behinderung(1) Frage:
Die meisten Webanfragen sind blockierender Natur. Wenn eine Anfrage verarbeitet wird, wird der Prozess angehalten (belegt die CPU), bis die Anfrage abgeschlossen ist. In den meisten Fällen werden Webanfragen schnell genug abgeschlossen, sodass dieses Problem kein Problem darstellt. Bei Anfragen, deren Ausführung lange dauert (z. B. Anfragen, die große Datenmengen oder externe APIs zurückgeben), bedeutet dies jedoch, dass die Anwendung bis zum Ende der Verarbeitung gesperrt ist. Während dieses Zeitraums werden andere Anfragen nicht verarbeitet. Und es ist offensichtlich, dass diese ungültig sind. Die Wartezeit wird verschwendet und die Systemressourcen werden belegt, was die Anzahl der gleichzeitigen Anforderungen, die wir uns leisten können, erheblich beeinträchtigt.
(2) Lösung:
Während der Webserver auf die Verarbeitung der vorherigen Anfrage wartet, können wir die E/A-Schleife öffnen, um andere Anwendungsanfragen zu verarbeiten, bis die Verarbeitung abgeschlossen ist, eine Anfrage starten und Feedback geben, anstatt beim Warten auf die Anfrage zu hängen um den Vorgang abzuschließen. Auf diese Weise können wir unnötige Wartezeiten einsparen und diese Zeit nutzen, um mehr Anfragen zu verarbeiten, sodass wir den Durchsatz der Anfragen erheblich steigern können, was bedeutet, dass wir makroskopisch die Anzahl gleichzeitiger Anfragen erhöhen, die wir bearbeiten können.
(3) Beispiel
Hier verwenden wir Tornado, ein Python-Webframework, um speziell zu erklären, wie die Blockierungsmethode geändert werden kann, um die Parallelitätsleistung zu verbessern.
Szenario: Wir erstellen eine einfache Webanwendung, die HTTP-Anfragen an die Gegenstelle (eine sehr stabile Website) sendet. Während dieser Zeit ist die Netzwerkübertragung stabil und wir berücksichtigen nicht die Auswirkungen des Netzwerks.
In diesem Beispiel verwenden wir Siege (eine Stresstestsoftware), um in 10 Sekunden etwa 10 gleichzeitige Anfragen an den Server durchzuführen.
Wie in Abbildung 2 gezeigt, können wir leicht erkennen, dass das Problem hier darin besteht, dass die Roundtrip-Zugriffsanforderung des Servers an das entfernte Ende unabhängig davon, wie schnell jede Anfrage selbst zurückkommt, eine ausreichend große Verzögerung erzeugt, da der Prozess nicht wartet Bis die Anfrage abgeschlossen ist und die Daten verarbeitet werden, befindet sie sich immer im erzwungenen Ruhezustand. Bei ein oder zwei Anfragen ist das noch kein Problem, aber wenn man 100 (oder sogar 10) Benutzer erreicht, bedeutet das eine allgemeine Verlangsamung. Wie in der Abbildung gezeigt, erreichte die durchschnittliche Antwortzeit von 10 ähnlichen Benutzern in weniger als 10 Sekunden 1,99 Sekunden, also insgesamt 29 Mal. Dieses Beispiel zeigt nur eine sehr einfache Logik. Wenn Sie weitere Geschäftslogik oder Datenbankaufrufe hinzufügen, werden die Ergebnisse noch schlechter. Wenn mehr Benutzeranfragen hinzugefügt werden, wächst die Anzahl der Anfragen, die gleichzeitig verarbeitet werden können, langsam, und bei einigen Anfragen kann es sogar zu Zeitüberschreitungen oder Fehlschlägen kommen.
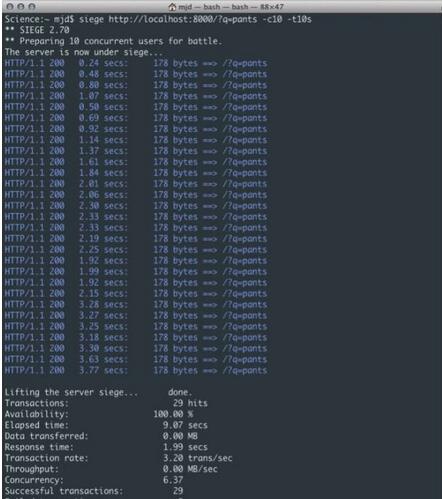
Abbildung 2: Blockierungsreaktion
Im Folgenden verwenden wir Tornado, um nicht blockierende HTTP-Anfragen auszuführen.
Wie in Abbildung 3 dargestellt, sind wir von 3,20 Transaktionen pro Sekunde auf 12,59 gestiegen und haben insgesamt 118 Anfragen in der gleichen Zeit bearbeitet. Das ist wirklich eine große Verbesserung! Wie Sie sich vorstellen können, können mit steigenden Benutzeranfragen und längeren Testzeiten mehr Verbindungen bedient werden, ohne dass die oben genannten Versionen langsamer werden. Dadurch erhöht sich die Anzahl der gleichzeitig ladbaren Anfragen stetig.
Praxis zur Verbesserung der Webserverleistung
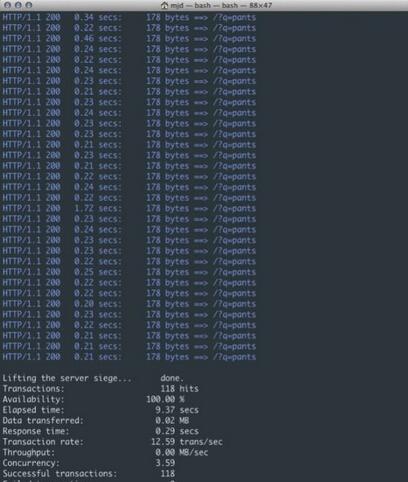
Abbildung 3: Nicht blockierende Antwort
2. Der Einfluss der Recheneffizienz auf die Reaktionszeit und die Anzahl der ParallelitätenLassen Sie uns zunächst das Grundwissen vorstellen: Eine Anwendung ist ein Prozess, der auf der Maschine ausgeführt wird. Ein Prozess ist ein unabhängiger Ausführungskörper, der in seinem eigenen Speicheradressraum ausgeführt wird. Ein Prozess besteht aus einem oder mehreren Betriebssystem-Threads. Diese Threads sind eigentlich Ausführungskörper, die zusammenarbeiten und sich denselben Speicheradressraum teilen.
(1) Frage
Die traditionelle Rechenmethode läuft in einem einzelnen Thread, der eine geringe Effizienz und eine schwache Rechenleistung aufweist.
(2) Lösung
Eine Lösung besteht darin, die Verwendung von Threads ganz zu vermeiden. Sie können beispielsweise mehrere Prozesse verwenden, um die Last auf das Betriebssystem zu verlagern. Ein Nachteil besteht jedoch darin, dass wir die gesamte Kommunikation zwischen Prozessen abwickeln müssen, was normalerweise einen höheren Overhead verursacht als das Parallelitätsmodell des gemeinsam genutzten Speichers.
Eine andere Möglichkeit besteht darin, Multithreading zu verwenden. Es ist jedoch bekannt, dass es für Anwendungen, die Multithreading verwenden, schwierig ist, eine genaue Synchronisierung verschiedener Threads zu erreichen und die Daten zu sperren, sodass nur ein Thread die Daten gleichzeitig ändern kann. Erfahrungen aus der Softwareentwicklung zeigen jedoch, dass dies zu höherer Komplexität, fehleranfälligerem Code und geringerer Leistung führt.
Das Hauptproblem ist die gemeinsame Nutzung von Daten im Speicher, die auf unvorhersehbare Weise von mehreren Threads bearbeitet werden, was zu nicht reproduzierbaren oder zufälligen Ergebnissen führt (sogenannte „Race Conditions“). Dieser klassische Ansatz eignet sich also eindeutig nicht mehr für die moderne Multi-Core-/Multi-Prozessor-Programmierung: Das Thread-pro-Verbindung-Modell ist nicht effizient genug. Unter vielen geeigneten Paradigmen gibt es eines namens „Communicating Sequential Processes“ (CSP, erfunden von C. Hoare) und eines namens „Message-Passing-Model“ (das bereits in anderen Sprachen wie Erlang verwendet wird).
Die Methode, die wir hier verwenden, besteht darin, eine parallele Architektur zur Verarbeitung von Aufgaben zu verwenden. Ein gleichzeitiges Programm kann mehrere Threads auf einem Prozessor oder Kern verwenden, um Aufgaben auszuführen, aber nur das gleiche Programm kann zu einem bestimmten Zeitpunkt auf mehreren Kernen oder mehreren Prozessoren ausgeführt werden in der Zeit. Die eigentliche Parallelität liegt auf dem Prozessor.
Parallelität ist die Fähigkeit, die Geschwindigkeit durch die Verwendung mehrerer Prozessoren zu erhöhen. Gleichzeitige Programme können also parallel sein oder nicht.
Der Parallelmodus kann Multi-Threads, Multi-Cores, Multi-Prozessoren und sogar mehrere Computer gleichzeitig nutzen. Dadurch können zweifellos mehr Ressourcen mobilisiert werden, wodurch die Reaktionszeit verkürzt, die Recheneffizienz verbessert und die Leistung des Servers erheblich gesteigert wird .
(3) Beispiel
Hier finden Sie eine ausführliche Erklärung zur Verwendung von Goroutine in der Go-Sprache.
In der Go-Sprache wird der Teil der Anwendung mit gleichzeitiger Verarbeitung als Goroutinen (Coroutinen) bezeichnet, die effizientere gleichzeitige Vorgänge ausführen können. Es gibt keine Eins-zu-eins-Beziehung zwischen Coroutinen und Betriebssystem-Threads: Coroutinen werden basierend auf ihrer Verfügbarkeit einem oder mehreren Threads zugeordnet (gemultiplext, ausgeführt). Die Go-Laufzeit erledigt diese Aufgabe sehr gut. Coroutinen sind leichtgewichtig, leichter als Threads. Sie sind sehr unauffällig (und verbrauchen wenig Speicher und Ressourcen): Sie können im Heap mit nur 4 KB Stapelspeicher erstellt werden. Da die Erstellung so kostengünstig ist, ist es bei Bedarf einfach, eine große Anzahl von Coroutinen (100.000 aufeinanderfolgende Coroutinen im selben Adressraum) zu erstellen und auszuführen. Und sie teilen den Stapel auf, um die Speichernutzung dynamisch zu erhöhen (oder zu reduzieren). Die Stapelverwaltung erfolgt automatisch, wird jedoch nicht vom Garbage Collector verwaltet, sondern nach dem Beenden der Coroutine automatisch freigegeben. Coroutinen können zwischen mehreren Betriebssystem-Threads oder innerhalb von Threads ausgeführt werden, sodass Sie eine große Anzahl von Aufgaben mit geringem Speicherbedarf verarbeiten können. Dank Coroutine-Time-Slicing auf Betriebssystem-Threads können Sie mit einer kleinen Anzahl von Betriebssystem-Threads so viele Serving-Coroutinen haben, wie Sie möchten, und die Go-Laufzeit kann intelligent erkennen, welche Coroutinen blockiert sind, sie in die Warteschleife legen und andere verarbeiten Coroutinen. Sogar Programme können verschiedene Codesegmente gleichzeitig auf verschiedenen Prozessoren und Computern ausführen.
Normalerweise möchten wir einen langen Berechnungsprozess in mehrere Teile aufteilen und dann jede Goroutine für einen Teil der Arbeit verantwortlich machen, sodass sich die Antwortzeit für eine einzelne Anfrage verdoppelt.
Zum Beispiel gibt es eine Aufgabe, die in drei Phasen unterteilt ist: Phase a geht zu Datenbank a, um Daten abzurufen, Phase b geht zu Datenbank b, um Daten abzurufen, und Phase c führt die Daten zusammen und gibt sie zurück. Nachdem wir die Goroutine gestartet haben, können die Phasen a und b gemeinsam ausgeführt werden, was die Reaktionszeit stark verkürzt.
Um es ganz klar auszudrücken: Ein Teil des Berechnungsprozesses wird von seriell in parallel umgewandelt. Eine Aufgabe muss nicht warten, bis die Ausführung anderer, nicht verwandter Aufgaben abgeschlossen ist, was bei tatsächlichen Berechnungen nützlicher ist.
Ich werde hier nicht zu sehr auf diesen Teil der unterstützenden Daten eingehen. Interessierte Studierende können sich diese Informationen selbst ansehen. Zum Beispiel die alte Geschichte über die 15-fache Leistungsverbesserung, als der Webserver von Ruby auf Go umgestellt wurde (Ruby verwendet grüne Threads, d. h. es wird nur eine CPU genutzt). Obwohl diese Geschichte vielleicht etwas übertrieben ist, besteht kein Zweifel an den Leistungssteigerungen, die die Parallelität mit sich bringt. (Ruby wechselt zu Go: http://www.vaikan.com/how-we-went-from-30-servers-to-2-go/).
3. Einfluss von Festplatten-I/O auf die Leistung(1) Frage
Das Lesen von Daten von einer Festplatte beruht auf mechanischer Bewegung. Die Zeit, die jedes Mal zum Lesen von Daten aufgewendet wird, kann in drei Teile unterteilt werden: Suchzeit, Rotationsverzögerung und Übertragungszeit. Die Suchzeit bezieht sich auf die Zeit, die der Magnetarm benötigt, um sich zu bewegen Die angegebene Zeit beträgt bei Mainstream-Festplatten im Allgemeinen weniger als 5 ms. Eine Festplatte mit 7200 U/min bedeutet beispielsweise, dass sie sich 7200 Mal pro Sekunde drehen kann. und die Rotationsverzögerung beträgt 1/120/2 = 4,17 ms; die Übertragungszeit bezieht sich auf die Zeit zum Lesen von der Festplatte oder zum Schreiben von Daten auf die Festplatte, im Allgemeinen einige Zehntel einer Millisekunde, was im Vergleich zu den ersten beiden Zeiten vernachlässigbar ist. Dann beträgt die Zeit für den Zugriff auf eine Festplatte, also die Zeit für den Zugriff auf eine Festplatten-E/A, etwa 9 ms (5 ms + 4,17 ms), was ziemlich gut klingt, aber Sie müssen wissen, dass eine 500-MIPS-Maschine 500 Millionen Elemente ausführen kann Anweisungen pro Sekunde, da Anweisungen von der Natur der Elektrizität abhängen, d dauert 9 Millisekunden, es ist offensichtlich eine Katastrophe.
(2) Lösung
Es gibt keine grundsätzliche Lösung für die Auswirkungen von Festplatten-I/O auf die Serverleistung, es sei denn, Sie werfen die Festplatte weg und ersetzen sie durch etwas anderes. Wir können die Reaktionsgeschwindigkeit und den Preis verschiedener Speichermedien online recherchieren. Wenn Sie Geld haben, können Sie die Speichermedien nach Belieben wechseln.
Ohne das Speichermedium zu ändern, können wir die Anzahl der Festplattenzugriffe durch die Anwendung reduzieren, z. B. durch das Einrichten des Caches, und wir können auch einige Festplatten-E/A außerhalb des Anforderungszyklus platzieren, z. B. durch die Verwendung von Warteschlangen und Stapeln zur Verarbeitung von Daten I /O. O et al.
4. Datenbankabfrage optimierenMit den Veränderungen in den Geschäftsentwicklungsmodellen wird die agile Entwicklung von immer mehr Teams übernommen und der Zyklus wird immer kürzer. Viele Datenbankabfrageanweisungen werden im Laufe der Zeit oft ignoriert .Problem, das zu einem erhöhten Druck auf die Datenbank führt und die Antwort auf Datenbankabfragen verlangsamt. Hier ist eine kurze Einführung in mehrere häufige Probleme und Optimierungsmethoden, die wir in der MySQL-Datenbank ignoriert haben:
Das Prinzip des Präfixabgleichs ganz links ist ein sehr wichtiges Prinzip. MySQL führt den Abgleich nach rechts fort, bis eine Bereichsabfrage (>, 3 und d = 4 Wenn Sie einen Index in der Reihenfolge (a, b, c, d) erstellen, verwendet d den Index nicht. , Sie können sowohl a als auch b verwenden, die Reihenfolge von d kann beliebig angepasst werden.
Versuchen Sie, Spalten mit hoher Unterscheidung als Indizes auszuwählen. Die Formel für die Unterscheidung lautet count(distinct col)/count(*). Je größer das Verhältnis, desto weniger Datensätze werden gescannt Anzahl eindeutiger Schlüssel ist 1. Einige Status- und Geschlechtsfelder können angesichts von Big Data einen Unterschied von 0 haben. Dann könnte sich jemand fragen, ob dieses Verhältnis einen empirischen Wert hat. Verschiedene Nutzungsszenarien erschweren die Bestimmung dieses Werts. Im Allgemeinen erfordern wir, dass Felder, die zusammengeführt werden müssen, über 0,1 liegen, d. h. es werden durchschnittlich 10 Datensätze pro Datensatz gescannt.
Versuchen Sie, numerische Felder zu verwenden, versuchen Sie, sie nicht als Zeichenfelder zu gestalten. Dies verringert die Leistung von Abfragen und Verbindungen und erhöht den Speicheraufwand. Dies liegt daran, dass die Engine bei der Verarbeitung von Abfragen und Verbindungen jedes Zeichen in der Zeichenfolge einzeln vergleicht und für numerische Typen nur ein Vergleich ausreicht.
Indexspalten können nicht an Berechnungen teilnehmen. Wenn beispielsweise from_unixtime(create_time) = „2014-05-29“ ist, ist der Grund dafür sehr einfach in der Datentabelle, aber beim Abrufen müssen Sie Funktionen auf alle zu vergleichenden Elemente anwenden, was offensichtlich zu kostspielig ist. Daher sollte die Anweisung wie folgt geschrieben werden: create_time = unix_timestamp(’2014-05-29’); Versuchen Sie zu vermeiden, den Nullwert des Felds in der where-Klausel zu beurteilen, da die Engine sonst die Verwendung aufgibt.
Führen Sie einen vollständigen Tabellenscan mithilfe des Index durch, z. B.:
Wählen Sie die ID aus t aus, wobei die Nummer null ist.
Sie können den Standardwert 0 für „num“ festlegen, sicherstellen, dass in der Spalte „num“ der Tabelle kein Nullwert vorhanden ist, und dann eine Abfrage wie folgt durchführen:
Wählen Sie die ID aus t aus, wobei num=0 ist
Vermeiden Sie die Verwendung von oder in der where-Klausel zum Verknüpfen von Bedingungen, da die Engine sonst die Verwendung des Index aufgibt und einen vollständigen Tabellenscan durchführt, z. B.:
Wählen Sie die ID aus t aus, wobei Anzahl = 10 oder Anzahl = 20
Sie können so abfragen:
Wählen Sie die ID aus t aus, wobei Anzahl = 10, und vereinen Sie alle ID aus t, wobei die Anzahl = 20 ist.
Die folgende Abfrage führt ebenfalls zu einem vollständigen Tabellenscan (kein führendes Prozentzeichen):
Wählen Sie eine ID aus, wobei der Name „%abc%“ lautet
Um die Effizienz zu verbessern, sollten Sie die Volltextsuche in Betracht ziehen.
In und nicht in sollten ebenfalls mit Vorsicht verwendet werden, da es sonst zu einem vollständigen Tabellenscan führt, wie zum Beispiel:
Wählen Sie die ID aus t aus, wobei die Nummer in(1,2,3)
ist
Verwenden Sie für kontinuierliche Werte nicht in, wenn Sie zwischen verwenden können:
Wählen Sie die ID aus t aus, wobei die Nummer zwischen 1 und 3 liegt
Das obige ist der detaillierte Inhalt vonMethoden zur Verbesserung der Webserverleistung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Unterschied zwischen CentOS und Ubuntu
Apr 14, 2025 pm 09:09 PM
Unterschied zwischen CentOS und Ubuntu
Apr 14, 2025 pm 09:09 PM
Die wichtigsten Unterschiede zwischen CentOS und Ubuntu sind: Ursprung (CentOS stammt von Red Hat, für Unternehmen; Ubuntu stammt aus Debian, für Einzelpersonen), Packungsmanagement (CentOS verwendet yum, konzentriert sich auf Stabilität; Ubuntu verwendet apt, für hohe Aktualisierungsfrequenz), Support Cycle (Centos) (CENTOS bieten 10 Jahre. Tutorials und Dokumente), Verwendungen (CentOS ist auf Server voreingenommen, Ubuntu ist für Server und Desktops geeignet). Weitere Unterschiede sind die Einfachheit der Installation (CentOS ist dünn)
 CentOS stoppt die Wartung 2024
Apr 14, 2025 pm 08:39 PM
CentOS stoppt die Wartung 2024
Apr 14, 2025 pm 08:39 PM
CentOS wird 2024 geschlossen, da seine stromaufwärts gelegene Verteilung RHEL 8 geschlossen wurde. Diese Abschaltung wirkt sich auf das CentOS 8 -System aus und verhindert, dass es weiterhin Aktualisierungen erhalten. Benutzer sollten eine Migration planen, und empfohlene Optionen umfassen CentOS Stream, Almalinux und Rocky Linux, um das System sicher und stabil zu halten.
 So installieren Sie CentOs
Apr 14, 2025 pm 09:03 PM
So installieren Sie CentOs
Apr 14, 2025 pm 09:03 PM
CentOS -Installationsschritte: Laden Sie das ISO -Bild herunter und verbrennen Sie bootfähige Medien. Starten und wählen Sie die Installationsquelle; Wählen Sie das Layout der Sprache und Tastatur aus. Konfigurieren Sie das Netzwerk; Partition die Festplatte; Setzen Sie die Systemuhr; Erstellen Sie den Root -Benutzer; Wählen Sie das Softwarepaket aus; Starten Sie die Installation; Starten Sie nach Abschluss der Installation von der Festplatte neu und starten Sie von der Festplatte.
 Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Was sind die Backup -Methoden für Gitlab auf CentOS?
Apr 14, 2025 pm 05:33 PM
Backup- und Wiederherstellungsrichtlinie von GitLab im Rahmen von CentOS -System Um die Datensicherheit und Wiederherstellung der Daten zu gewährleisten, bietet GitLab on CentOS eine Vielzahl von Sicherungsmethoden. In diesem Artikel werden mehrere gängige Sicherungsmethoden, Konfigurationsparameter und Wiederherstellungsprozesse im Detail eingeführt, um eine vollständige GitLab -Sicherungs- und Wiederherstellungsstrategie aufzubauen. 1. Manuell Backup Verwenden Sie den GitLab-RakegitLab: Backup: Befehl erstellen, um die manuelle Sicherung auszuführen. Dieser Befehl unterstützt wichtige Informationen wie GitLab Repository, Datenbank, Benutzer, Benutzergruppen, Schlüssel und Berechtigungen. Die Standardsicherungsdatei wird im Verzeichnis/var/opt/gitlab/backups gespeichert. Sie können /etc /gitlab ändern
 Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Docker verwendet Linux -Kernel -Funktionen, um eine effiziente und isolierte Anwendungsumgebung zu bieten. Sein Arbeitsprinzip lautet wie folgt: 1. Der Spiegel wird als schreibgeschützte Vorlage verwendet, die alles enthält, was Sie für die Ausführung der Anwendung benötigen. 2. Das Union File System (UnionFS) stapelt mehrere Dateisysteme, speichert nur die Unterschiede, speichert Platz und beschleunigt. 3. Der Daemon verwaltet die Spiegel und Container, und der Kunde verwendet sie für die Interaktion. 4. Namespaces und CGroups implementieren Container -Isolation und Ressourcenbeschränkungen; 5. Mehrere Netzwerkmodi unterstützen die Containerverbindung. Nur wenn Sie diese Kernkonzepte verstehen, können Sie Docker besser nutzen.
 So verwenden Sie Docker Desktop
Apr 15, 2025 am 11:45 AM
So verwenden Sie Docker Desktop
Apr 15, 2025 am 11:45 AM
Wie benutze ich Docker Desktop? Docker Desktop ist ein Werkzeug zum Ausführen von Docker -Containern auf lokalen Maschinen. Zu den zu verwendenden Schritten gehören: 1.. Docker Desktop installieren; 2. Start Docker Desktop; 3.. Erstellen Sie das Docker -Bild (mit Dockerfile); 4. Build Docker Image (mit Docker Build); 5. Docker -Container ausführen (mit Docker Run).
 Wie man in CentOS fester Festplatten montiert
Apr 14, 2025 pm 08:15 PM
Wie man in CentOS fester Festplatten montiert
Apr 14, 2025 pm 08:15 PM
CentOS -Festplattenhalterung ist in die folgenden Schritte unterteilt: Bestimmen Sie den Namen der Festplattengeräte (/dev/sdx); Erstellen Sie einen Mountspunkt (es wird empfohlen, /mnt /newDisk zu verwenden). Führen Sie den Befehl montage (mont /dev /sdx1 /mnt /newdisk) aus; Bearbeiten Sie die Datei /etc /fstab, um eine permanente Konfiguration des Montings hinzuzufügen. Verwenden Sie den Befehl uMount, um das Gerät zu deinstallieren, um sicherzustellen, dass kein Prozess das Gerät verwendet.
 Was zu tun ist, nachdem CentOS die Wartung gestoppt hat
Apr 14, 2025 pm 08:48 PM
Was zu tun ist, nachdem CentOS die Wartung gestoppt hat
Apr 14, 2025 pm 08:48 PM
Nachdem CentOS gestoppt wurde, können Benutzer die folgenden Maßnahmen ergreifen, um sich damit zu befassen: Wählen Sie eine kompatible Verteilung aus: wie Almalinux, Rocky Linux und CentOS Stream. Migrieren Sie auf kommerzielle Verteilungen: wie Red Hat Enterprise Linux, Oracle Linux. Upgrade auf CentOS 9 Stream: Rolling Distribution und bietet die neueste Technologie. Wählen Sie andere Linux -Verteilungen aus: wie Ubuntu, Debian. Bewerten Sie andere Optionen wie Container, virtuelle Maschinen oder Cloud -Plattformen.
