

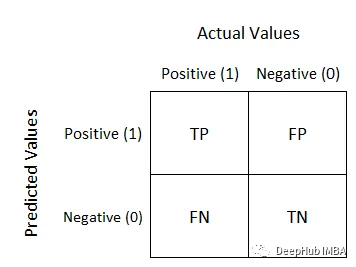
Die Modellbewertung ist ein sehr wichtiger Teil des Deep Learning und des maschinellen Lernens und wird zur Messung der Leistung und Wirksamkeit des Modells verwendet. In diesem Artikel werden die Verwirrungsmatrix, die Genauigkeit, die Präzision, der Rückruf und der F1-Score Schritt für Schritt aufgeschlüsselt Problem, es handelt sich um ein Demonstrationsmodell in der Beispielklassifizierungstabelle. Zeilen repräsentieren tatsächliche Kategorien und Spalten repräsentieren vorhergesagte Kategorien. Für ein binäres Klassifizierungsproblem ist die Struktur der Verwirrungsmatrix wie folgt:

Falsch Negativ (FN): Anzahl der Proben, die tatsächlich positiv sind und vom Modell als negativ vorhergesagt wurden. Abhängig von der Anwendung kann dies kritisch sein (z. B. konnten Sicherheitsbedrohungen nicht erkannt werden).
from sklearn.metrics import confusion_matrix import seaborn as sns import matplotlib.pyplot as plt # Example predictions and true labels y_true = [1, 0, 1, 1, 0, 1, 0, 0, 1, 0] y_pred = [1, 0, 1, 0, 0, 1, 0, 1, 1, 1] # Create a confusion matrix cm = confusion_matrix(y_true, y_pred) # Visualize the blueprint sns.heatmap(cm, annot=True, fmt="d", cmap="Blues", xticklabels=["Predicted 0", "Predicted 1"], yticklabels=["Actual 0", "Actual 1"]) plt.xlabel("Predicted") plt.ylabel("Actual") plt.show()Basierend auf der Verwirrungsmatrix können viele andere Bewertungsmetriken berechnet werden, wie z. Rückruf und F1-Ergebnis.
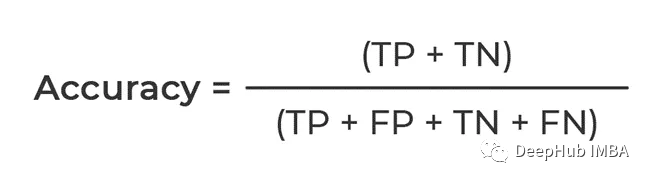
Genauigkeit
Was berechnet wird, ist der Anteil, der korrekt vorhergesagt werden kann. Der Zähler ist, dass sowohl TP als auch TN wahr sind, also die Gesamtzahl der korrekten Vorhersagen von Das Modell
Sie berechnet den Anteil der positiven Ergebnisse, d. h. wie viele positive Ergebnisse in den Daten korrekt vorhergesagt werden. Präzision wird daher auch als Präzisionsrate bezeichnet

F1-Score
Die Berechnungsformel des F1-Scores lautet: F1 = 2 * (Präzision * Rückruf) / (Präzision + Rückruf) Unter ihnen bezieht sich die Präzision auf den Anteil der vom Modell als positive Beispiele vorhergesagten Proben, die tatsächlich positive Beispiele sind; die Rückrufrate bezieht sich auf das Verhältnis der Anzahl der vom Modell korrekt als positive Beispiele vorhergesagten Proben zur Anzahl der tatsächlich positiven Beispiele positive Beispiele. Der F1-Score ist das harmonische Mittel aus Präzision und Erinnerung, das die Genauigkeit und Vollständigkeit des Modells umfassend berücksichtigen kann, um die Leistung des Modells zu bewerten
F1-Score ist wichtig, weil er Präzision und Erinnerung bietet. Ein Kompromiss zwischen den Tarifen. Wenn Sie ein Gleichgewicht zwischen Präzision und Erinnerung finden möchten oder für allgemeine Anwendungen, können Sie F1 Score
verwenden
In diesem Artikel haben wir die Verwirrungsmatrix, die Genauigkeit, die Präzision, den Rückruf und den F1-Score im Detail vorgestellt und darauf hingewiesen, dass diese Indikatoren die Leistung des Modells effektiv bewerten und verbessern können
Das obige ist der detaillierte Inhalt vonLesen Sie die Bewertungsindikatoren des Klassifizierungsmodells in einem Artikel. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Was tun, wenn die CHM-Datei nicht geöffnet werden kann?
Was tun, wenn die CHM-Datei nicht geöffnet werden kann?
 WeChat-Schritte
WeChat-Schritte
 Grundlegende Verwendung von FTP
Grundlegende Verwendung von FTP
 ps ausgewählten Bereich löschen
ps ausgewählten Bereich löschen
 JS-Array-Sortierung: Methode sort()
JS-Array-Sortierung: Methode sort()
 Was bedeutet URL?
Was bedeutet URL?
 So legen Sie die Transparenz der HTML-Schriftfarbe fest
So legen Sie die Transparenz der HTML-Schriftfarbe fest
 Methode zum Öffnen der Bereichsberechtigung
Methode zum Öffnen der Bereichsberechtigung
 Anforderungen an die Hardwarekonfiguration des Webservers
Anforderungen an die Hardwarekonfiguration des Webservers








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



