
 Technologie-Peripheriegeräte
KI
Zehn Indikatoren für die Leistung von Modellen für maschinelles Lernen
Technologie-Peripheriegeräte
KI
Zehn Indikatoren für die Leistung von Modellen für maschinelles Lernen
Zehn Indikatoren für die Leistung von Modellen für maschinelles Lernen

Obwohl große Modelle sehr leistungsfähig sind, ist die Lösung praktischer Probleme nicht unbedingt ausschließlich auf große Modelle angewiesen. Eine weniger präzise Analogie, um physikalische Phänomene in der Realität zu erklären, ohne unbedingt die Quantenmechanik zu verwenden. Für einige relativ einfache Probleme reicht möglicherweise eine statistische Verteilung aus. Für maschinelles Lernen sind selbstverständlich Deep Learning und neuronale Netze notwendig. Der Schlüssel liegt darin, die Grenzen des Problems zu klären.
Wie lässt sich also die Leistung eines Modells für maschinelles Lernen bewerten, wenn ML zur Lösung relativ einfacher Probleme verwendet wird? Hier sind 10 relativ häufig verwendete Bewertungsindikatoren, die für Studierende aus Industrie und Forschung hilfreich sein sollen.
1. Genauigkeit
Genauigkeit ist ein grundlegender Bewertungsindex im Bereich des maschinellen Lernens und wird normalerweise verwendet, um die Leistung des Modells schnell zu verstehen. Genauigkeit bietet eine intuitive Möglichkeit, die Genauigkeit eines Modells zu messen, indem einfach das Verhältnis der Anzahl der vom Modell korrekt vorhergesagten Instanzen zur Gesamtzahl der Instanzen im Datensatz berechnet wird.
 Bilder
Bilder
Allerdings kann die Genauigkeit als Bewertungsmaßstab beim Umgang mit unausgeglichenen Datensätzen unzureichend sein. Ein unausgeglichener Datensatz bezieht sich auf einen Datensatz, in dem die Anzahl der Instanzen einer bestimmten Kategorie die anderer Kategorien deutlich übersteigt. In diesem Fall tendiert das Modell möglicherweise dazu, eine größere Anzahl von Kategorien vorherzusagen, was zu einer falsch hohen Genauigkeit führt.
Außerdem kann die Genauigkeit keine Informationen über falsch-positive und falsch-negative Ergebnisse liefern. Ein falsch positives Ergebnis liegt vor, wenn das Modell eine negative Instanz fälschlicherweise als positive Instanz vorhersagt, während ein falsch negatives Ergebnis vorliegt, wenn das Modell eine positive Instanz fälschlicherweise als negative Instanz vorhersagt. Bei der Bewertung der Modellleistung ist es wichtig, zwischen falsch positiven und falsch negativen Ergebnissen zu unterscheiden, da diese unterschiedliche Auswirkungen auf die Leistung des Modells haben.
Zusammenfassend lässt sich sagen, dass Genauigkeit zwar eine einfache und leicht verständliche Bewertungsmetrik ist, wir jedoch beim Umgang mit unausgeglichenen Datensätzen bei der Interpretation der Genauigkeitsergebnisse vorsichtiger sein müssen.
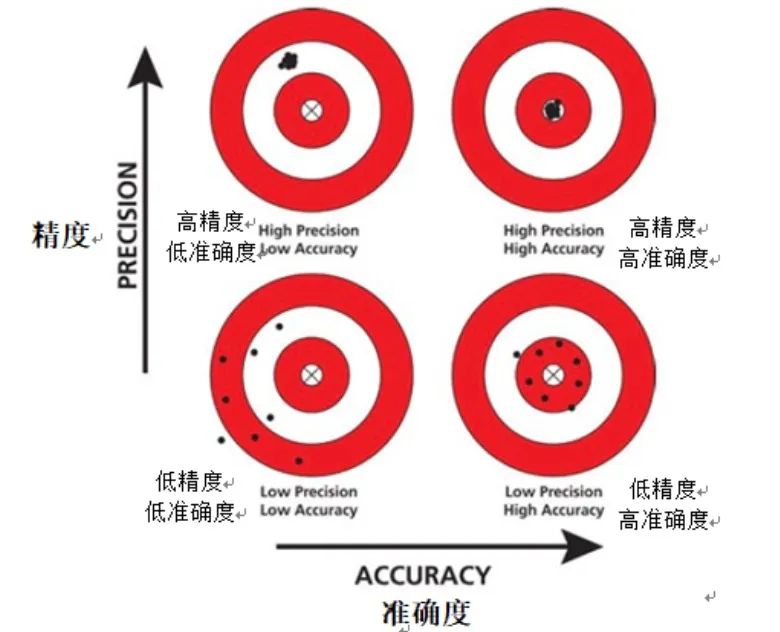
2. Genauigkeit
Genauigkeit ist ein wichtiger Bewertungsindex, der sich auf die Messung der Vorhersagegenauigkeit des Modells für positive Proben konzentriert. Im Gegensatz zur Genauigkeit wird bei der Genauigkeit der Anteil der tatsächlich positiven Instanzen unter den vom Modell als positiv vorhergesagten Instanzen berechnet. Mit anderen Worten: Genauigkeit beantwortet die Frage: „Wenn das Modell eine Instanz als positiv vorhersagt, wie groß ist die Wahrscheinlichkeit, dass diese Vorhersage korrekt ist?“ Ein hochpräzises Modell bedeutet, dass diese Instanz, wenn es eine Instanz als positiv vorhersagt, korrekt ist Es ist sehr wahrscheinlich, dass es sich tatsächlich um eine positive Probe handelt.
 Bilder
Bilder
Bei manchen Anwendungen, etwa bei der medizinischen Diagnose oder Betrugserkennung, ist die Genauigkeit des Modells besonders wichtig. In diesen Szenarien können die Folgen falsch positiver Ergebnisse (d. h. der fälschlichen Vorhersage negativer Proben als positive Proben) sehr schwerwiegend sein. Beispielsweise kann in der medizinischen Diagnostik eine falsch positive Diagnose zu unnötigen Behandlungen oder Untersuchungen führen, was zu einer unnötigen psychischen und physischen Belastung des Patienten führt. Bei der Betrugserkennung können Fehlalarme dazu führen, dass unschuldige Benutzer fälschlicherweise als betrügerische Akteure eingestuft werden, was sich negativ auf das Benutzererlebnis und den Ruf des Unternehmens auswirkt.
Daher ist es bei diesen Anwendungen entscheidend, sicherzustellen, dass das Modell eine hohe Genauigkeit aufweist. Nur durch eine Verbesserung der Genauigkeit können wir das Risiko falsch positiver Ergebnisse und damit die negativen Auswirkungen von Fehleinschätzungen verringern.
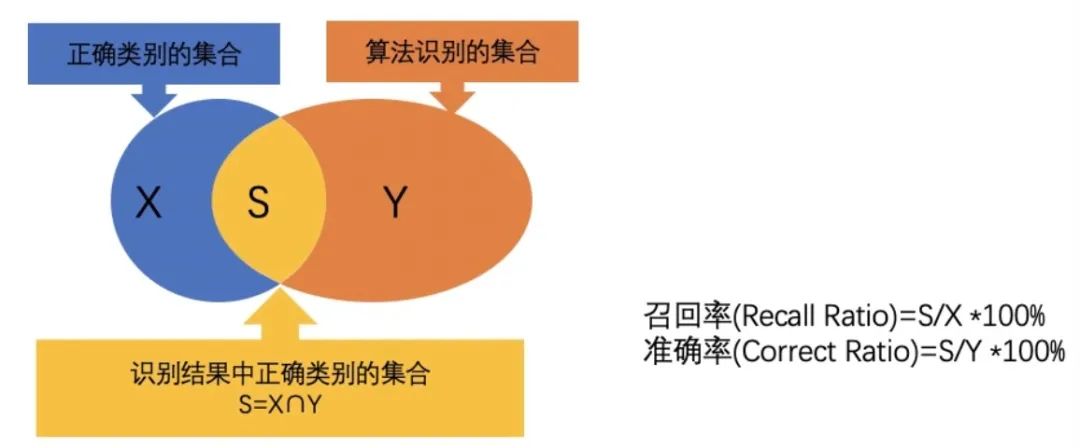
3. Rückrufrate
Die Rückrufrate ist ein wichtiger Bewertungsindex, der verwendet wird, um die Fähigkeit des Modells zu messen, alle tatsächlich positiven Proben korrekt vorherzusagen. Konkret wird der Rückruf als das Verhältnis der vom Modell vorhergesagten Fälle, die tatsächlich positiv sind, zur Gesamtzahl der tatsächlichen positiven Beispiele berechnet. Diese Metrik beantwortet die Frage: „Wie viele der tatsächlichen positiven Beispiele hat das Modell richtig vorhergesagt?“
Im Gegensatz zur Präzision konzentriert sich die Erinnerung auf die Fähigkeit des Modells, sich an tatsächliche positive Beispiele zu erinnern. Selbst wenn das Modell eine geringe Vorhersagewahrscheinlichkeit für eine bestimmte positive Probe aufweist, wird diese Vorhersage in die Berechnung der Rückrufrate einbezogen, solange es sich bei der Probe tatsächlich um eine positive Probe handelt und sie vom Modell korrekt als positive Probe vorhergesagt wird . Daher geht es beim Rückruf mehr darum, ob das Modell in der Lage ist, möglichst viele positive Stichproben zu finden, und nicht nur solche mit höheren vorhergesagten Wahrscheinlichkeiten.
 Bilder
Bilder
In einigen Anwendungsszenarien ist die Bedeutung der Erinnerungsrate besonders ausgeprägt. Wenn das Modell beispielsweise bei der Krankheitserkennung die tatsächlich erkrankten Patienten übersieht, kann dies zu Verzögerungen und einer Verschlechterung der Krankheit führen und schwerwiegende Folgen für die Patienten haben. Ein weiteres Beispiel ist die Vorhersage der Kundenabwanderung: Wenn das Modell Kunden, bei denen eine Abwanderung wahrscheinlich ist, nicht korrekt identifiziert, verliert das Unternehmen möglicherweise die Möglichkeit, Maßnahmen zur Kundenbindung zu ergreifen, und verliert dadurch wichtige Kunden.
Daher wird die Erinnerung in diesen Szenarien zu einer entscheidenden Messgröße. Ein Modell mit hohem Recall ist besser in der Lage, tatsächlich positive Proben zu finden, wodurch das Risiko von Auslassungen verringert und so mögliche schwerwiegende Folgen vermieden werden.
4. F1-Score
F1-Score ist ein umfassender Bewertungsindex, der darauf abzielt, ein Gleichgewicht zwischen Präzision und Erinnerung zu finden. Es handelt sich tatsächlich um das harmonische Mittel aus Präzision und Erinnerung, das diese beiden Metriken in einem einzigen Score kombiniert und so eine Bewertungsmethode bietet, die sowohl falsch-positive als auch falsch-negative Ergebnisse berücksichtigt.
 Bilder
Bilder
In vielen praktischen Anwendungen müssen wir oft einen Kompromiss zwischen Präzision und Erinnerung eingehen. Präzision konzentriert sich auf die Richtigkeit der Vorhersagen des Modells, während sich der Rückruf darauf konzentriert, ob das Modell in der Lage ist, alle tatsächlich positiven Proben zu finden. Allerdings kann die Überbetonung einer Kennzahl oft die Leistung der anderen beeinträchtigen. Um beispielsweise die Erinnerung zu verbessern, kann ein Modell die Vorhersagen für positive Proben erhöhen, dies kann jedoch auch die Anzahl falsch positiver Ergebnisse erhöhen und dadurch die Genauigkeit verringern.
F1-Scoring soll dieses Problem lösen. Es berücksichtigt Präzision und Erinnerung und verhindert, dass wir eine Metrik opfern, um eine andere zu optimieren. Durch die Berechnung des harmonischen Mittels aus Präzision und Erinnerung stellt der F1-Score ein Gleichgewicht zwischen beiden her und ermöglicht es uns, die Leistung des Modells zu bewerten, ohne Partei zu ergreifen.
Der F1-Score ist also ein sehr nützliches Tool, wenn Sie eine Metrik benötigen, die Präzision und Erinnerung kombiniert, und nicht eine Metrik gegenüber der anderen bevorzugen möchten. Es bietet einen einzigen Score, der den Prozess der Bewertung der Modellleistung vereinfacht und uns hilft, die Leistung des Modells in realen Anwendungen besser zu verstehen.
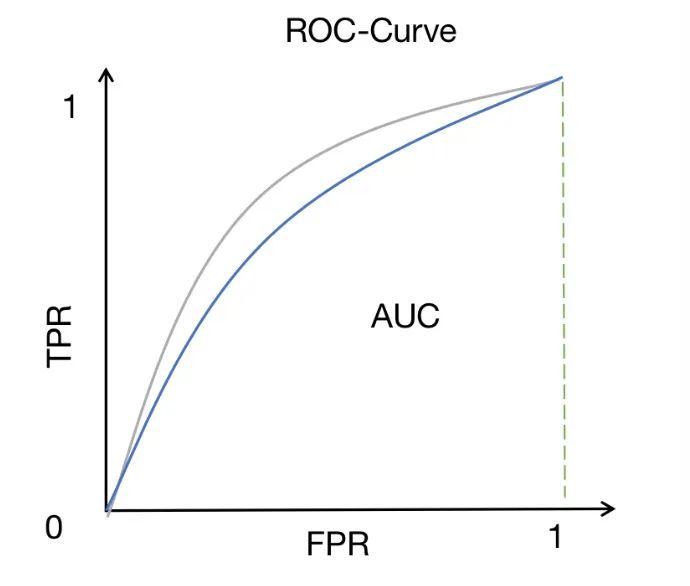
5. ROC-AUC
ROC-AUC ist eine weit verbreitete Methode zur Leistungsmessung bei binären Klassifizierungsproblemen. Es misst die Fläche unter der ROC-Kurve, die die Beziehung zwischen der True-Positive-Rate (auch Sensitivität oder Recall genannt) und der False-Positive-Rate bei verschiedenen Schwellenwerten darstellt.
 Bilder
Bilder
ROC-Kurven bieten eine intuitive Möglichkeit, die Leistung des Modells unter verschiedenen Schwellenwerteinstellungen zu beobachten. Durch Ändern des Schwellenwerts können wir die Richtig-Positiv-Rate und die Falsch-Positiv-Rate des Modells anpassen, um unterschiedliche Klassifizierungsergebnisse zu erhalten. Je näher die ROC-Kurve an der oberen linken Ecke liegt, desto besser ist die Leistung des Modells bei der Unterscheidung positiver und negativer Stichproben.
Die AUC (Fläche unter der Kurve) bietet einen quantitativen Indikator zur Bewertung der Unterscheidungsfähigkeit des Modells. Der AUC-Wert liegt zwischen 0 und 1. Je näher er bei 1 liegt, desto stärker ist die Unterscheidungsfähigkeit des Modells. Ein hoher AUC-Score bedeutet, dass das Modell gut zwischen positiven und negativen Proben unterscheiden kann, d. h. die vom Modell vorhergesagte Wahrscheinlichkeit für positive Proben ist höher als die vorhergesagte Wahrscheinlichkeit für negative Proben.
Daher ist ROC-AUC eine sehr nützliche Metrik, wenn wir die Fähigkeit eines Modells zur Unterscheidung zwischen Klassen bewerten möchten. Im Vergleich zu anderen Indikatoren bietet ROC-AUC einige einzigartige Vorteile. Es wird nicht durch die Schwellenwertauswahl beeinflusst und kann die Leistung des Modells unter verschiedenen Schwellenwerten umfassend berücksichtigen. Darüber hinaus ist ROC-AUC relativ robust gegenüber Klassenungleichgewichtsproblemen und kann auch dann noch aussagekräftige Bewertungsergebnisse liefern, wenn die Anzahl der positiven und negativen Stichproben unausgeglichen ist.
ROC-AUC ist ein sehr wertvolles Leistungsmaß, insbesondere für binäre Klassifizierungsprobleme. Durch Beobachtung und Vergleich der ROC-AUC-Werte verschiedener Modelle können wir ein umfassenderes Verständnis der Modellleistung erlangen und das Modell mit der besseren Unterscheidungsfähigkeit auswählen.
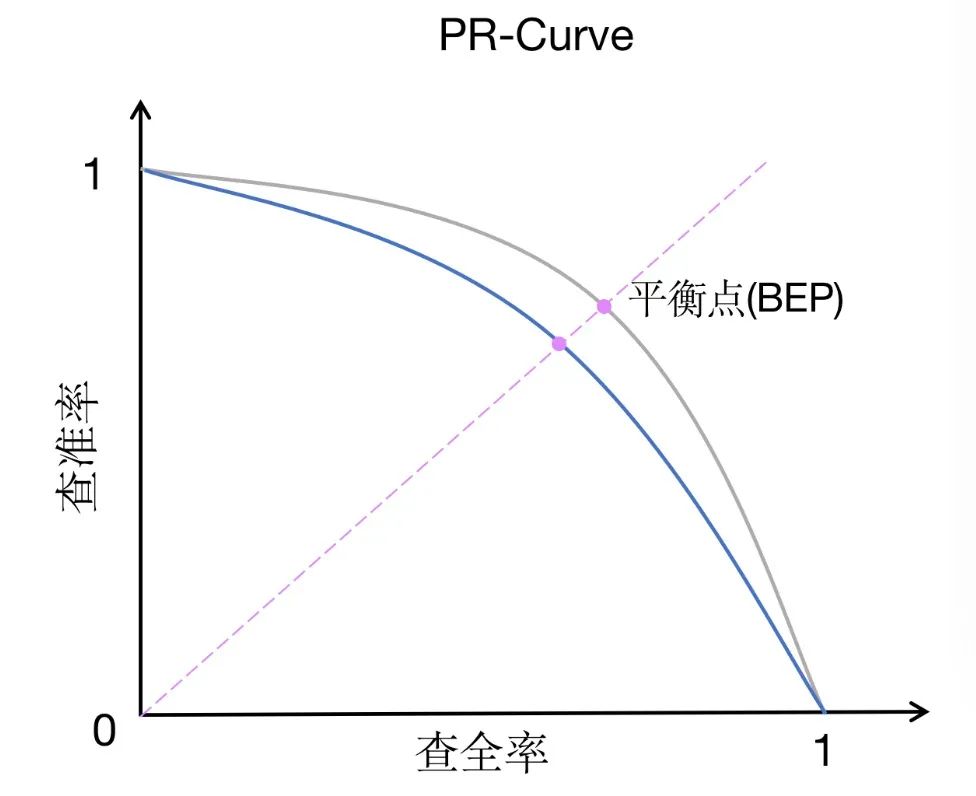
6. PR-AUC
PR-AUC (Fläche unter der Precision-Recall-Kurve) ist eine Leistungsmessungsmethode, die ROC-AUC ähnelt, jedoch einen etwas anderen Schwerpunkt hat. PR-AUC misst die Fläche unter der Präzisions-Erinnerungskurve, die die Beziehung zwischen Präzision und Erinnerung bei verschiedenen Schwellenwerten darstellt.
 Bilder
Bilder
Im Vergleich zu ROC-AUC legt PR-AUC mehr Wert auf den Kompromiss zwischen Präzision und Erinnerung. Präzision misst den Anteil der Instanzen, die das Modell als positiv vorhersagt, die tatsächlich positiv sind, während der Rückruf den Anteil der Instanzen misst, die das Modell korrekt als positiv vorhersagt, unter allen Instanzen, die tatsächlich positiv sind. Der Kompromiss zwischen Präzision und Erinnerung ist besonders wichtig bei unausgeglichenen Datensätzen oder wenn falsch-positive Ergebnisse ein größeres Problem darstellen als falsch-negative.
In einem unausgeglichenen Datensatz kann die Anzahl der Proben in einer Kategorie die Anzahl der Proben in einer anderen Kategorie bei weitem übersteigen. In diesem Fall spiegelt ROC-AUC die Leistung des Modells möglicherweise nicht genau wider, da es sich hauptsächlich auf die Beziehung zwischen der True-Positive-Rate und der False-Positive-Rate konzentriert, ohne das Klassenungleichgewicht direkt zu berücksichtigen. Im Gegensatz dazu bewertet PR-AUC die Leistung des Modells umfassender durch den Kompromiss zwischen Präzision und Rückruf und kann die Auswirkung des Modells auf unausgeglichene Datensätze besser widerspiegeln.
Außerdem ist PR-AUC eine geeignetere Kennzahl, wenn falsch-positive Ergebnisse besorgniserregender sind als falsch-negative. Denn in manchen Anwendungsszenarien kann die fälschliche Vorhersage negativer Proben als positive Proben (falsche Positive) zu größeren Verlusten oder negativen Auswirkungen führen. Beispielsweise kann in der medizinischen Diagnostik die fälschliche Diagnose einer gesunden Person als kranke Person zu unnötiger Behandlung und Ängsten führen. In diesem Fall würden wir eine hohe Genauigkeit des Modells bevorzugen, um die Anzahl falsch positiver Ergebnisse zu reduzieren.
Zusammenfassend ist PR-AUC eine Methode zur Leistungsmessung, die sich für unausgeglichene Datensätze oder Szenarien eignet, in denen falsch positive Ergebnisse ein Problem darstellen. Es kann uns helfen, den Kompromiss zwischen Präzision und Rückruf von Modellen besser zu verstehen und ein geeignetes Modell auszuwählen, das den tatsächlichen Anforderungen entspricht.
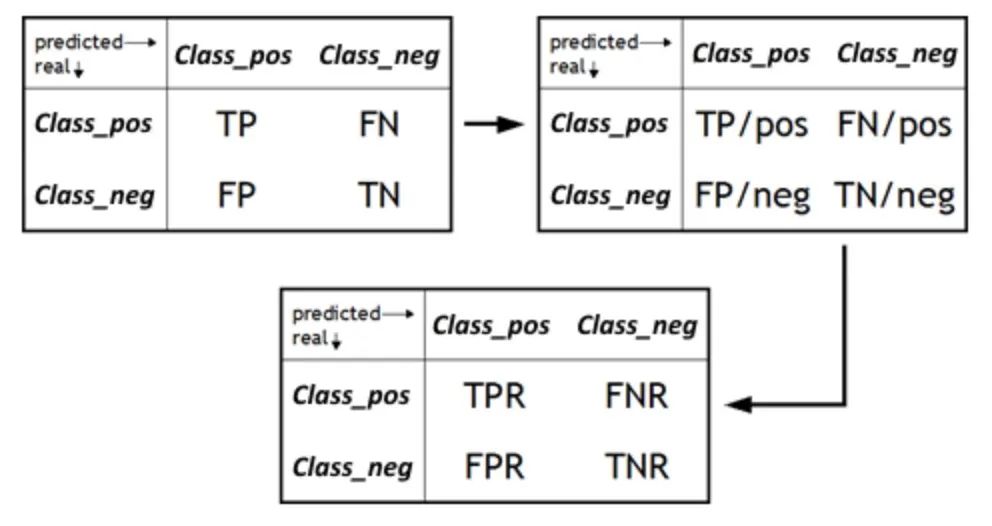
7. FPR/TNR
Die Falsch-Positiv-Rate (FPR) ist eine wichtige Kennzahl, die den Anteil der Proben misst, die das Modell fälschlicherweise als positiv unter allen tatsächlich negativen Proben vorhersagt. Es ist ein ergänzender Indikator für die Spezifität und entspricht der True Negative Rate (TNR). FPR wird zu einem Schlüsselelement, wenn wir die Fähigkeit eines Modells bewerten möchten, Fehlalarme zu vermeiden. Falsch positive Ergebnisse können zu unnötigen Sorgen oder Ressourcenverschwendung führen. Daher ist das Verständnis des FPR eines Modells von entscheidender Bedeutung, um seine Zuverlässigkeit in realen Anwendungen zu bestimmen. Durch die Senkung des FPR können wir die Präzision und Genauigkeit des Modells verbessern und sicherstellen, dass positive Vorhersagen nur dann ausgegeben werden, wenn tatsächlich positive Proben vorhanden sind.
 Bilder
Bilder
Andererseits ist die wahre Negativrate (TNR), auch Spezifität genannt, ein Maß dafür, wie korrekt ein Modell negative Proben identifiziert. Es berechnet den Anteil der vom Modell vorhergesagten Fälle, die echte Negative sind, an der tatsächlichen Gesamtzahl der Negative. Bei der Bewertung eines Modells konzentrieren wir uns oft auf die Fähigkeit des Modells, positive Proben zu identifizieren, aber ebenso wichtig ist die Leistung des Modells bei der Identifizierung negativer Proben. Ein hoher TNR bedeutet, dass das Modell negative Proben genau identifizieren kann, d. h. unter den tatsächlich negativen Proben prognostiziert das Modell einen höheren Anteil negativer Proben. Dies ist entscheidend, um Fehlalarme zu vermeiden und die Gesamtleistung des Modells zu verbessern.
8. Matthews-Korrelationskoeffizient (MCC)
MCC (Matthews-Korrelationskoeffizient) ist ein Maß, das bei binären Klassifizierungsproblemen verwendet wird. Es bietet uns eine umfassende Betrachtung der wahren positiven und falschen negativen Beziehungen ausgewertet. Im Vergleich zu anderen Messmethoden besteht der Vorteil von MCC darin, dass es sich um einen einzelnen Wert im Bereich von -1 bis 1 handelt, wobei -1 bedeutet, dass die Vorhersage des Modells vollständig mit dem tatsächlichen Ergebnis übereinstimmt, und 1 bedeutet, dass die Vorhersage des Modells vollständig konsistent ist mit dem tatsächlichen Ergebnis.
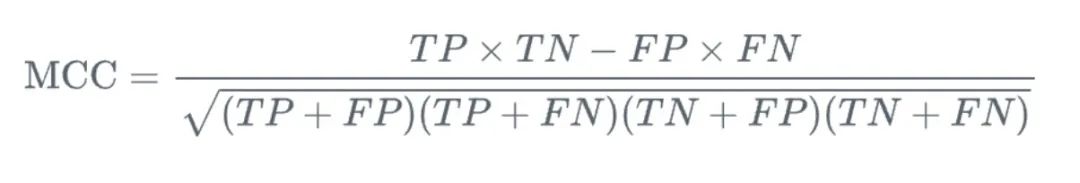 Bilder
Bilder
Noch wichtiger ist, dass MCC eine ausgewogene Möglichkeit bietet, die Qualität der binären Klassifizierung zu messen. Bei binären Klassifizierungsproblemen konzentrieren wir uns normalerweise auf die Fähigkeit des Modells, positive und negative Stichproben zu identifizieren, während MCC beide Aspekte berücksichtigt. Es konzentriert sich nicht nur auf die Fähigkeit des Modells, positive Proben (d. h. echte Positive) korrekt vorherzusagen, sondern auch auf die Fähigkeit des Modells, negative Proben (d. h. echte Negative) korrekt vorherzusagen. Gleichzeitig berücksichtigt MCC auch falsch-positive und falsch-negative Ergebnisse, um die Leistung des Modells umfassender zu bewerten.
In praktischen Anwendungen eignet sich MCC besonders für den Umgang mit unausgeglichenen Datensätzen. Da in einem unausgeglichenen Datensatz die Anzahl der Stichproben in einer Kategorie viel größer ist als die einer anderen Kategorie, führt dies häufig dazu, dass das Modell tendenziell eher die Kategorie mit einer größeren Anzahl vorhersagt. MCC ist jedoch in der Lage, alle vier Metriken (echt positiv, wahr negativ, falsch positiv und falsch negativ) ausgewogen zu berücksichtigen, sodass es im Allgemeinen eine genauere und umfassendere Leistungsbewertung für unausgeglichene Datensätze liefern kann.
Insgesamt ist MCC ein leistungsstarkes und umfassendes Leistungsmesstool für die binäre Klassifizierung. Es berücksichtigt nicht nur alle möglichen Vorhersageergebnisse, sondern liefert auch einen intuitiven, klar definierten numerischen Wert, um die Konsistenz zwischen Vorhersagen und tatsächlichen Ergebnissen zu messen. Unabhängig davon, ob es sich um ausgeglichene oder unausgeglichene Datensätze handelt, ist MCC eine nützliche Metrik, die uns helfen kann, die Leistung des Modells besser zu verstehen.
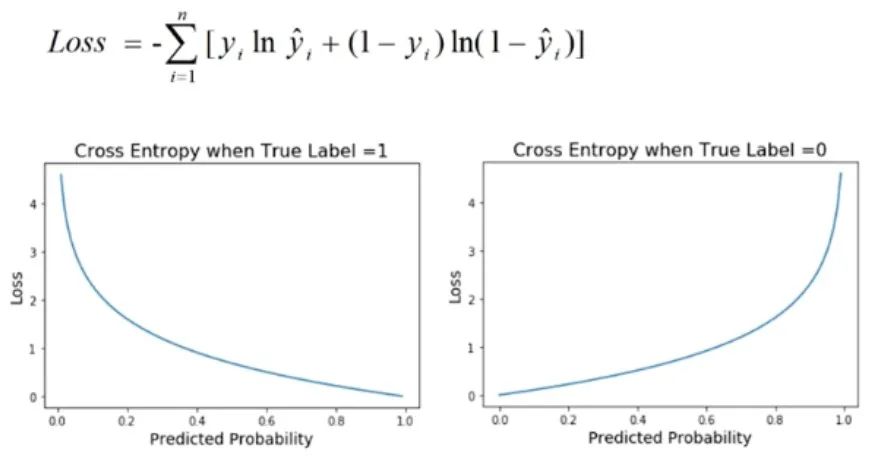
9. Kreuzentropieverlust
Kreuzentropieverlust ist eine häufig verwendete Leistungsmetrik bei Klassifizierungsproblemen, insbesondere wenn die Ausgabe des Modells ein Wahrscheinlichkeitswert ist. Diese Verlustfunktion wird verwendet, um den Unterschied zwischen der vom Modell vorhergesagten Wahrscheinlichkeitsverteilung und der tatsächlichen Etikettenverteilung zu quantifizieren.
 Bilder
Bilder
Bei Klassifizierungsproblemen besteht das Ziel des Modells normalerweise darin, die Wahrscheinlichkeit vorherzusagen, dass eine Stichprobe zu verschiedenen Kategorien gehört. Der Kreuzentropieverlust wird verwendet, um die Konsistenz zwischen vom Modell vorhergesagten Wahrscheinlichkeiten und tatsächlichen binären Ergebnissen zu bewerten. Es leitet den Verlustwert ab, indem es den Logarithmus der vorhergesagten Wahrscheinlichkeit nimmt und ihn mit der tatsächlichen Bezeichnung vergleicht. Daher wird der Kreuzentropieverlust auch als logarithmischer Verlust bezeichnet.
Der Vorteil des Kreuzentropieverlusts besteht darin, dass er ein gutes Maß für die Vorhersagegenauigkeit des Modells für Wahrscheinlichkeitsverteilungen ist. Wenn die vorhergesagte Wahrscheinlichkeitsverteilung des Modells der tatsächlichen Etikettenverteilung ähnelt, ist der Wert des Kreuzentropieverlusts gering. Wenn sich die vorhergesagte Wahrscheinlichkeitsverteilung jedoch erheblich von der tatsächlichen Etikettenverteilung unterscheidet, ist der Wert des Kreuzentropieverlusts gering hoch. Daher bedeutet ein niedrigerer Kreuzentropieverlustwert, dass die Vorhersagen des Modells genauer sind, d. h. das Modell weist eine bessere Kalibrierungsleistung auf.
In praktischen Anwendungen streben wir normalerweise nach niedrigeren Kreuzentropieverlustwerten, da dies bedeutet, dass die Vorhersagen des Modells für Klassifizierungsprobleme genauer und zuverlässiger sind. Durch die Optimierung des Kreuzentropieverlusts können wir die Leistung des Modells verbessern und ihm eine bessere Generalisierungsfähigkeit in praktischen Anwendungen verleihen. Daher ist der Kreuzentropieverlust einer der wichtigen Indikatoren zur Bewertung der Leistung eines Klassifizierungsmodells. Er kann uns dabei helfen, die Vorhersagegenauigkeit des Modells besser zu verstehen und festzustellen, ob eine weitere Optimierung der Parameter und der Struktur des Modells erforderlich ist.
10. Cohens Kappa-Koeffizient
Cohens Kappa-Koeffizient ist ein statistisches Tool zur Messung der Konsistenz zwischen Modellvorhersagen und tatsächlichen Etiketten. Er eignet sich besonders für die Bewertung von Klassifizierungsaufgaben. Im Vergleich zu anderen Messmethoden berechnet es nicht nur die einfache Übereinstimmung zwischen Modellvorhersagen und tatsächlichen Etiketten, sondern korrigiert auch die möglicherweise zufällig auftretende Übereinstimmung und liefert so ein genaueres und zuverlässigeres Bewertungsergebnis.
In praktischen Anwendungen, insbesondere wenn mehrere Bewerter an der Klassifizierung desselben Probensatzes beteiligt sind, ist der Kappa-Koeffizient von Cohen sehr nützlich. In diesem Fall müssen wir uns nicht nur auf die Konsistenz der Modellvorhersagen mit den tatsächlichen Etiketten konzentrieren, sondern auch die Konsistenz zwischen verschiedenen Bewertern berücksichtigen. Denn wenn zwischen den Bewertern erhebliche Inkonsistenzen bestehen, können die Bewertungsergebnisse der Modellleistung durch die Subjektivität der Bewerter beeinflusst werden, was zu ungenauen Bewertungsergebnissen führt.
Durch die Verwendung des Kappa-Koeffizienten von Cohen kann diese möglicherweise zufällig auftretende Konsistenz korrigiert werden, um eine genauere Bewertung der Modellleistung zu ermöglichen. Konkret wird ein Wert zwischen -1 und 1 berechnet, wobei 1 für perfekte Konsistenz, -1 für vollständige Inkonsistenz und 0 für zufällige Konsistenz steht. Daher bedeutet ein höherer Kappa-Wert, dass die Übereinstimmung zwischen den Modellvorhersagen und den tatsächlichen Bezeichnungen die zufällig erwartete Übereinstimmung übersteigt, was darauf hinweist, dass das Modell eine bessere Leistung aufweist.
 Bilder
Bilder
Der Kappa-Koeffizient von Cohen kann uns helfen, die Konsistenz zwischen Modellvorhersagen und tatsächlichen Bezeichnungen in Klassifizierungsaufgaben genauer zu beurteilen und gleichzeitig die Konsistenz zu korrigieren, die zufällig auftreten kann. Dies ist besonders wichtig in Szenarien mit mehreren Bewertern, da es eine objektivere und genauere Bewertung ermöglichen kann.
Zusammenfassung
Es gibt viele Indikatoren für die Bewertung von Modellen für maschinelles Lernen. In diesem Artikel werden einige der Hauptindikatoren aufgeführt:
- Genauigkeit (Genauigkeit): Das Verhältnis der Anzahl korrekt vorhergesagter Stichproben zur Gesamtzahl der Stichproben.
- Präzision: Das Verhältnis der wirklich positiven (TP) Proben zu allen vorhergesagten positiven (TP und FP) Proben, was die Fähigkeit des Modells widerspiegelt, positive Proben zu identifizieren.
- Rückruf: Das Verhältnis der wirklich positiven (TP) Proben zu allen wirklich positiven (TP und FN) Proben, was die Fähigkeit des Modells widerspiegelt, positive Proben zu entdecken.
- F1-Wert: Der harmonische Durchschnitt von Präzision und Erinnerung, der sowohl Präzision als auch Erinnerung berücksichtigt.
- ROC-AUC: Die Fläche unter der ROC-Kurve ist eine Funktion der True Positive Rate (True Positive Rate, TPR) und der False Positive Rate (False Positive Rate, FPR). Je größer die AUC, desto besser ist die Klassifizierungsleistung des Modells.
- PR-AUC: Bereich unter der Präzisions-Erinnerungskurve, der sich auf den Kompromiss zwischen Präzision und Erinnerung konzentriert und besser für unausgeglichene Datensätze geeignet ist.
- FPR/TNR: FPR misst die Fähigkeit des Modells, falsch positive Proben zu melden, und TNR misst die Fähigkeit des Modells, negative Proben korrekt zu identifizieren.
- Kreuzentropieverlust: Wird verwendet, um den Unterschied zwischen der vom Modell vorhergesagten Wahrscheinlichkeit und der tatsächlichen Bezeichnung zu bewerten. Niedrigere Werte weisen auf eine bessere Modellkalibrierung und -genauigkeit hin.
- Matthews-Korrelationskoeffizient (MCC): Eine Metrik, die die Beziehungen zwischen echten Positiven, wahren Negativen, falschen Positiven und falschen Negativen berücksichtigt und so ein ausgewogenes Maß für die Qualität der binären Klassifizierung liefert.
- Cohens Kappa: Ein wichtiges Tool zur Bewertung der Modellleistung bei Klassifizierungsaufgaben. Es kann die Konsistenz zwischen Vorhersagen und Beschriftungen genau messen und versehentliche Konsistenz korrigieren, insbesondere in Szenarien mit mehreren Bewertern.
Jeder der oben genannten Indikatoren hat seine eigenen Eigenschaften und eignet sich für verschiedene Problemszenarien. In praktischen Anwendungen müssen möglicherweise mehrere Indikatoren kombiniert werden, um die Leistung des Modells umfassend zu bewerten.
Das obige ist der detaillierte Inhalt vonZehn Indikatoren für die Leistung von Modellen für maschinelles Lernen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Zu den häufigsten Herausforderungen, mit denen Algorithmen für maschinelles Lernen in C++ konfrontiert sind, gehören Speicherverwaltung, Multithreading, Leistungsoptimierung und Wartbarkeit. Zu den Lösungen gehören die Verwendung intelligenter Zeiger, moderner Threading-Bibliotheken, SIMD-Anweisungen und Bibliotheken von Drittanbietern sowie die Einhaltung von Codierungsstilrichtlinien und die Verwendung von Automatisierungstools. Praktische Fälle zeigen, wie man die Eigen-Bibliothek nutzt, um lineare Regressionsalgorithmen zu implementieren, den Speicher effektiv zu verwalten und leistungsstarke Matrixoperationen zu nutzen.
 Keine OpenAI-Daten erforderlich, schließen Sie sich der Liste der großen Codemodelle an! UIUC veröffentlicht StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Keine OpenAI-Daten erforderlich, schließen Sie sich der Liste der großen Codemodelle an! UIUC veröffentlicht StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
An der Spitze der Softwaretechnologie kündigte die Gruppe von UIUC Zhang Lingming zusammen mit Forschern der BigCode-Organisation kürzlich das StarCoder2-15B-Instruct-Großcodemodell an. Diese innovative Errungenschaft erzielte einen bedeutenden Durchbruch bei Codegenerierungsaufgaben, übertraf erfolgreich CodeLlama-70B-Instruct und erreichte die Spitze der Codegenerierungsleistungsliste. Die Einzigartigkeit von StarCoder2-15B-Instruct liegt in seiner reinen Selbstausrichtungsstrategie. Der gesamte Trainingsprozess ist offen, transparent und völlig autonom und kontrollierbar. Das Modell generiert über StarCoder2-15B Tausende von Anweisungen als Reaktion auf die Feinabstimmung des StarCoder-15B-Basismodells, ohne auf teure manuelle Annotationen angewiesen zu sein.
 Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Übersetzer |. Rezensiert von Li Rui |. Chonglou Modelle für künstliche Intelligenz (KI) und maschinelles Lernen (ML) werden heutzutage immer komplexer, und die von diesen Modellen erzeugten Ergebnisse sind eine Blackbox, die den Stakeholdern nicht erklärt werden kann. Explainable AI (XAI) zielt darauf ab, dieses Problem zu lösen, indem es Stakeholdern ermöglicht, die Funktionsweise dieser Modelle zu verstehen, sicherzustellen, dass sie verstehen, wie diese Modelle tatsächlich Entscheidungen treffen, und Transparenz in KI-Systemen, Vertrauen und Verantwortlichkeit zur Lösung dieses Problems gewährleistet. In diesem Artikel werden verschiedene Techniken der erklärbaren künstlichen Intelligenz (XAI) untersucht, um ihre zugrunde liegenden Prinzipien zu veranschaulichen. Mehrere Gründe, warum erklärbare KI von entscheidender Bedeutung ist. Vertrauen und Transparenz: Damit KI-Systeme allgemein akzeptiert und vertrauenswürdig sind, müssen Benutzer verstehen, wie Entscheidungen getroffen werden
 Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Maschinelles Lernen ist ein wichtiger Zweig der künstlichen Intelligenz, der Computern die Möglichkeit gibt, aus Daten zu lernen und ihre Fähigkeiten zu verbessern, ohne explizit programmiert zu werden. Maschinelles Lernen hat ein breites Anwendungsspektrum in verschiedenen Bereichen, von der Bilderkennung und der Verarbeitung natürlicher Sprache bis hin zu Empfehlungssystemen und Betrugserkennung, und es verändert unsere Lebensweise. Im Bereich des maschinellen Lernens gibt es viele verschiedene Methoden und Theorien, von denen die fünf einflussreichsten Methoden als „Fünf Schulen des maschinellen Lernens“ bezeichnet werden. Die fünf Hauptschulen sind die symbolische Schule, die konnektionistische Schule, die evolutionäre Schule, die Bayes'sche Schule und die Analogieschule. 1. Der Symbolismus, auch Symbolismus genannt, betont die Verwendung von Symbolen zum logischen Denken und zum Ausdruck von Wissen. Diese Denkrichtung glaubt, dass Lernen ein Prozess der umgekehrten Schlussfolgerung durch das Vorhandene ist
 Yolov10: Ausführliche Erklärung, Bereitstellung und Anwendung an einem Ort!
Jun 07, 2024 pm 12:05 PM
Yolov10: Ausführliche Erklärung, Bereitstellung und Anwendung an einem Ort!
Jun 07, 2024 pm 12:05 PM
1. Einleitung In den letzten Jahren haben sich YOLOs aufgrund ihres effektiven Gleichgewichts zwischen Rechenkosten und Erkennungsleistung zum vorherrschenden Paradigma im Bereich der Echtzeit-Objekterkennung entwickelt. Forscher haben das Architekturdesign, die Optimierungsziele, Datenerweiterungsstrategien usw. von YOLO untersucht und erhebliche Fortschritte erzielt. Gleichzeitig behindert die Verwendung von Non-Maximum Suppression (NMS) bei der Nachbearbeitung die End-to-End-Bereitstellung von YOLO und wirkt sich negativ auf die Inferenzlatenz aus. In YOLOs fehlt dem Design verschiedener Komponenten eine umfassende und gründliche Prüfung, was zu erheblicher Rechenredundanz führt und die Fähigkeiten des Modells einschränkt. Es bietet eine suboptimale Effizienz und ein relativ großes Potenzial zur Leistungsverbesserung. Ziel dieser Arbeit ist es, die Leistungseffizienzgrenze von YOLO sowohl in der Nachbearbeitung als auch in der Modellarchitektur weiter zu verbessern. zu diesem Zweck
 Leistungsvergleich verschiedener Java-Frameworks
Jun 05, 2024 pm 07:14 PM
Leistungsvergleich verschiedener Java-Frameworks
Jun 05, 2024 pm 07:14 PM
Leistungsvergleich verschiedener Java-Frameworks: REST-API-Anforderungsverarbeitung: Vert.x ist am besten, mit einer Anforderungsrate von 2-mal SpringBoot und 3-mal Dropwizard. Datenbankabfrage: HibernateORM von SpringBoot ist besser als ORM von Vert.x und Dropwizard. Caching-Vorgänge: Der Hazelcast-Client von Vert.x ist den Caching-Mechanismen von SpringBoot und Dropwizard überlegen. Geeignetes Framework: Wählen Sie entsprechend den Anwendungsanforderungen. Vert.x eignet sich für leistungsstarke Webdienste, SpringBoot eignet sich für datenintensive Anwendungen und Dropwizard eignet sich für Microservice-Architekturen.
 Maschinelles Lernen in C++: Ein Leitfaden zur Implementierung gängiger Algorithmen für maschinelles Lernen in C++
Jun 03, 2024 pm 07:33 PM
Maschinelles Lernen in C++: Ein Leitfaden zur Implementierung gängiger Algorithmen für maschinelles Lernen in C++
Jun 03, 2024 pm 07:33 PM
In C++ umfasst die Implementierung von Algorithmen für maschinelles Lernen: Lineare Regression: Wird zur Vorhersage kontinuierlicher Variablen verwendet. Zu den Schritten gehören das Laden von Daten, das Berechnen von Gewichtungen und Verzerrungen, das Aktualisieren von Parametern und die Vorhersage. Logistische Regression: Wird zur Vorhersage diskreter Variablen verwendet. Der Prozess ähnelt der linearen Regression, verwendet jedoch die Sigmoidfunktion zur Vorhersage. Support Vector Machine: Ein leistungsstarker Klassifizierungs- und Regressionsalgorithmus, der die Berechnung von Support-Vektoren und die Vorhersage von Beschriftungen umfasst.
 Die Tsinghua-Universität übernahm und YOLOv10 kam heraus: Die Leistung wurde erheblich verbessert und es stand auf der GitHub-Hotlist
Jun 06, 2024 pm 12:20 PM
Die Tsinghua-Universität übernahm und YOLOv10 kam heraus: Die Leistung wurde erheblich verbessert und es stand auf der GitHub-Hotlist
Jun 06, 2024 pm 12:20 PM
Die Benchmark-Zielerkennungssysteme der YOLO-Serie haben erneut ein großes Upgrade erhalten. Seit der Veröffentlichung von YOLOv9 im Februar dieses Jahres wurde der Staffelstab der YOLO-Reihe (YouOnlyLookOnce) in die Hände von Forschern der Tsinghua-Universität übergeben. Letztes Wochenende erregte die Nachricht vom Start von YOLOv10 die Aufmerksamkeit der KI-Community. Es gilt als bahnbrechendes Framework im Bereich Computer Vision und ist für seine End-to-End-Objekterkennungsfunktionen in Echtzeit bekannt. Es führt das Erbe der YOLO-Serie fort und bietet eine leistungsstarke Lösung, die Effizienz und Genauigkeit vereint. Papieradresse: https://arxiv.org/pdf/2405.14458 Projektadresse: https://github.com/THU-MIG/yo
