

Bei dieser ICASSP 2024 International Audio Challenge hat sich das ByteDance Streaming Audio Team mit dem Audio Speech and Language Processing Research Laboratory der Northwestern Polytechnical University zusammengetan, um in den beiden Challenges an der Paketverlustverdeckung (PLC) und der Klangqualitätsreparatur (Sprache) zu arbeiten Auf den Spuren der Signalverbesserung (SSI) schnitt es bei mehreren Indikatoren gut ab und erreichte den ersten bzw. zweiten Platz und erreichte damit das internationale Spitzenniveau.
Die Audio Challenge auf dem ICASSP Summit wurde gemeinsam von der führenden internationalen Audiokonferenz ICASSP und Microsoft ins Leben gerufen, um die Forschung zu Audioeffekten und der Verbesserung der Klangqualität durch verschiedene Forschungseinrichtungen anzuregen. Seit der ersten Sitzung hat sie Amazon, Tencent, angezogen. und Alibaba Viele bekannte Unternehmen und wissenschaftliche Forschungsinstitute auf der ganzen Welt, darunter Baba, Baidu, Kuaishou, die Chinesische Akademie der Wissenschaften und die NPU, nahmen teil. Mit der kontinuierlichen Weiterentwicklung der Technologie im Bereich Streaming Media ist die Schaffung eines klaren und authentischen Klangs zu einem unvermeidlichen Trend in der Entwicklung der Audiotechnologiebranche geworden. Um Benutzern ein besseres Audioerlebnis zu bieten, haben mehrere Forschungsteams eine durchgängige Optimierung des Audiomaterials von der Erfassung bis zur Weiterleitung durchgeführt. Dieser Prozess umfasst den Umgang mit Audioerfassungsfehlern, Algorithmusverarbeitungsfehlern sowie Codierungs- und Decodierungsfehlern , und Netzwerkübertragungsfehler. Warten Sie auf die integrierte Reparatur. Bei dieser Herausforderung nahm das ByteDance-Streaming-Audio-Team an zwei Herausforderungsstrecken teil: Kompensation von Paketverlusten und allgemeine Reparatur der Klangqualität, basierend auf realen Geschäftsimplementierungsszenarien.
ICASSP PLC Challenge zielt darauf ab, das Problem des Paketverlusts bei langen Intervallen und der Full-Band-Audioverarbeitung (48kHz-Abtastrate) bei Netzwerk-IP-Anrufen zu lösen. Die Herausforderung unterliegt strengen Latenzbeschränkungen und stellt gleichzeitig einen anspruchsvollen Datensatz bereit, der widrige Netzwerkbedingungen widerspiegelt. Die subjektive Bewertung erfolgt mit der mehrdimensionalen Audioqualitätsbewertungsmethode P.804, während WER auch zur Bewertung der Verständlichkeit der von den teilnehmenden Systemen erzeugten Sprache verwendet wird. Das Team für Streaming-Audio-Technologie reduzierte effektiv die Komplexität des Paketverlustkompensationsmodells durch Optimierung der Modellstruktur. Gleichzeitig kann das Paketverlustkompensationsmodell durch gegnerisches Training mit mehreren Diskriminatoren und Lernen mit mehreren Aufgaben Paketverlustfragmente mit hoher Qualität und hoher Verständlichkeit wiederherstellen und schließlich den ersten Platz erreichen.
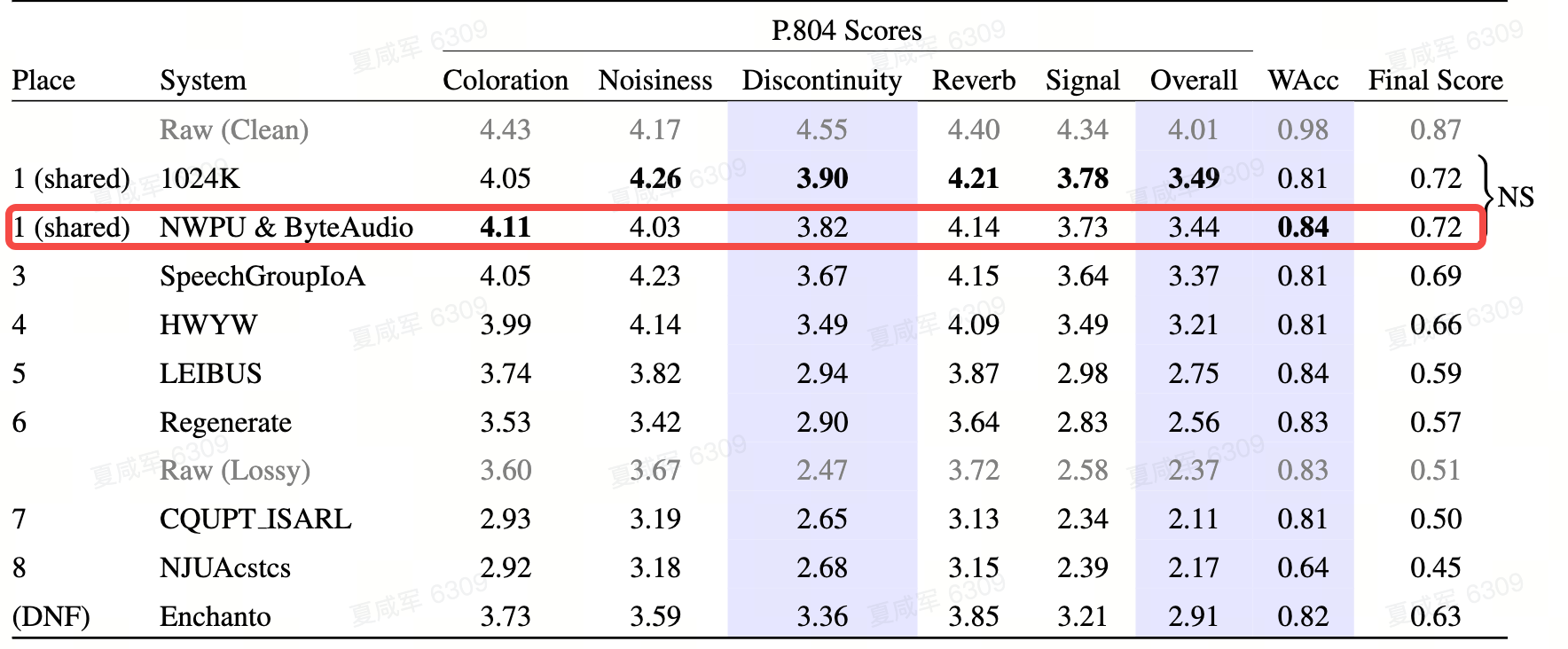
ICASSP SSI Challenge zielt darauf ab, fünf Arten von Problemen zu lösen, mit denen Sprachsignale in Kommunikationssystemen konfrontiert sind: Frequenzgangverzerrung, Diskontinuitätsverzerrung, Lautstärkeverzerrung, Rauschen und Nachhall. Diese Herausforderung nutzt subjektive Meinungswerte und Spracherkennungsraten gemäß dem ITU-TP.804-Standard, um die Rankings unter der Prämisse einer strengen Festlegung der Modellverzögerung und Kausalität umfassend zu beurteilen. Das Streaming-Technologie-Team verwendet eine zweistufige Modellstruktur, um das komplexe Reparaturproblem in mehrere Teilaufgaben zu zerlegen. In der ersten Stufe werden hauptsächlich Frequenzgangverzerrungen, Diskontinuitätsverzerrungen und Lautstärkeverzerrungen repariert und eine vorläufige Geräuschreduzierung und Enthallung durchgeführt Die zweite Stufe Diese Stufe entfernt die in der ersten Stufe erzeugten Artefakte sowie Restrauschen weiter. Am Ende erreichte das Team auf der Echtzeitstrecke den zweiten Platz.
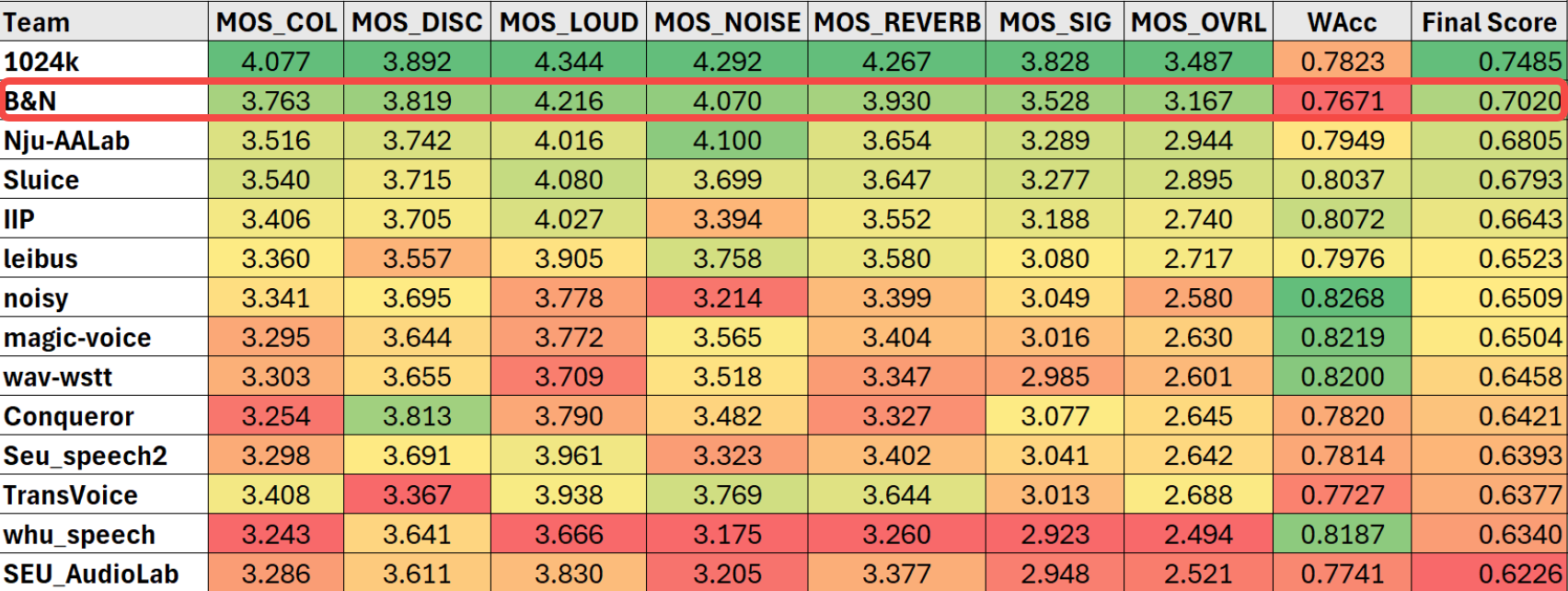
Paketverlustkompensationssystem
Um das Problem der Komplexität der 48-kHz-Vollband-Audioverarbeitung zu lösen, wird im Paketverlustkompensationssystem ein Frequenzbereichsmodell verwendet und das Audio in 0-8 kHz unterteilt , 8- Die beiden 24-kHz-Teilbänder werden parallel verarbeitet. Der Hauptberechnungsaufwand konzentriert sich auf das 0-8-kHz-Frequenzband, das einen größeren Einfluss auf den Hörsinn hat und eine Paketverlustkompensation mit geringer Komplexität und hoher Qualität erreicht. Um das Problem des Paketverlusts in langen Intervallen zu lösen, wird nach jeder Schicht des Codecs ein zeitfrequenzdilatiertes Faltungsmodul (TFDCM) hinzugefügt. Dabei bleibt die Größe des Faltungskerns gering, es erfasst jedoch langfristig kausal erweiterte Faltung Schicht für Schicht in Zeit- und Frequenzdimensionen. Zeitverlaufsinformationen und Frequenzkorrelation.
Um eine höhere Audioqualität zu kompensieren, werden Frequenzbereichs-Mehrfachauflösungsdiskriminator, Zeitbereichs-Mehrperiodendiskriminator und MetricGAN in Kombination verwendet, um generatives gegnerisches Training durchzuführen, wodurch der erzeugte Audioklang ausgezeichnet klingt. Bei Paketverlusten über längere Zeiträume und Problemen mit der Verständlichkeit wird ein Multitasking-Lernframework verwendet. Zusätzlich zum üblichen Sprachsignal-Ähnlichkeitslernen werden auch grundlegende Frequenzvorhersagen und flüsterbasierte semantische Verständnisverlustfunktionen eingeführt. Das Modell kann Paketverlustfragmente, die länger als 100 ms sind, mit hoher Qualität wiederherstellen, und das wiederhergestellte Audio ist sehr verständlich. Der Indikator für die Wortgenauigkeitsrate (WAcc) führt alle teilnehmenden Teams an, und die Gesamtbewertung liegt auf dem ersten Platz.
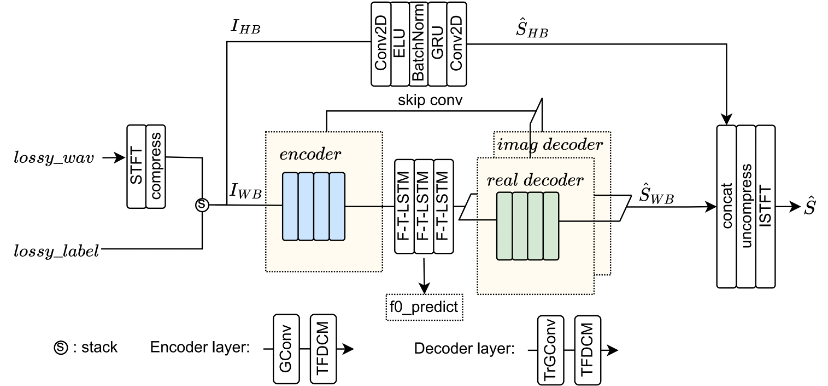
Schematisches Strukturdiagramm des Paketverlustkompensationsmodells
System zur Reparatur der Klangqualität
Um Audiodaten zu reparieren, die von mehreren Verzerrungen gleichzeitig betroffen sind, wird im Konstruktionssystem eine zweistufige Modellarchitektur verwendet, die sich auf die Verarbeitung verschiedener Verzerrungen in unterschiedlichen Phasen konzentriert. Das Modell der ersten Stufe verwendet Mapping, um das komplexe Spektrum des reparierten Audios direkt vorherzusagen, sodass das Modell in der Lage ist, fehlende Audiokomponenten zu generieren und gleichzeitig Interferenzsignale zu eliminieren, um die Fähigkeit des Modells zur Informationserfassung zu verbessern Aufgrund der Instabilität der Zuordnungsmethode kann es zu Artefakten kommen, weshalb ein zweistufiges Modell mit Maskierung (Mask) eingeführt wird - Die Band-zu-Vollband-Modellierungsmethode führt eine feinkörnige Modellierung von Frequenzbändern durch, um Artefakte und Restrauschen, die durch das Modell der ersten Stufe erzeugt werden, weiter zu eliminieren.
Um die Natürlichkeit der generierten Audiokomponenten zu verbessern, wird ein generatives kontradiktorisches Netzwerk-Framework eingeführt und ein Multi-Resolution-Diskriminator und ein Molekularband-Multi-Resolution-Diskriminator werden zur Unterstützung des Modelltrainings verwendet. Um gleichzeitig die Konvergenz des mehrstufigen Modells während des Trainings zu erleichtern, wird das zweistufige Modell zunächst auf die Aufgaben der Geräuschreduzierung und Nachhallbildung vorab trainiert, und dann werden die Parameter des trainierten einstufigen Modells ermittelt Eingefroren und mit dem vorab trainierten Modell der zweiten Stufe verglichen. Stufenmodelle werden für das gemeinsame Training kaskadiert, wodurch die Modellkonvergenz beschleunigt wird.
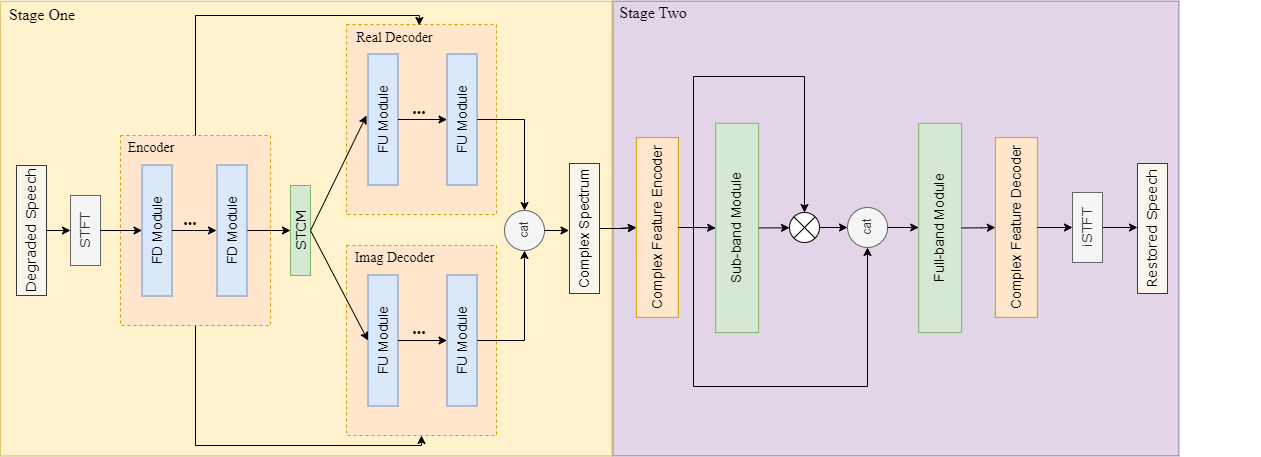
Schematische Darstellung der Modellstruktur zur Reparatur der Klangqualität
Teamvorstellung
Das Bytedance-Streaming-Audio-Team ist bestrebt, qualitativ hochwertige Echtzeit-Audio- und Videokommunikationsfunktionen mit geringer Latenz im gesamten globalen Internet bereitzustellen Helfen Sie Entwicklern schnell. Es wurden umfangreiche Szenariofunktionen wie Sprachanrufe, Videoanrufe, interaktive Live-Übertragungen, Retweet-Live-Übertragungen usw. entwickelt. Derzeit werden interaktive Echtzeit-Audio- und Video-Szenarien wie gegenseitige Unterhaltung, Bildung, Konferenzen, Spiele und Autos abgedeckt , Finanzen und IoT und bedient Hunderte Millionen Benutzer.
Das obige ist der detaillierte Inhalt von2024 ICASSP|Innovative Lösung vom ByteDance-Streaming-Audio-Team: Lösung von Paketverlustkompensation und allgemeinen Reparaturproblemen bei der Klangqualität. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So öffnen Sie HTML-Dateien
So öffnen Sie HTML-Dateien
 Tutorial zur Linux-Systeminstallation
Tutorial zur Linux-Systeminstallation
 Analyse der ICP-Münzaussichten
Analyse der ICP-Münzaussichten
 Thunder VIP-Patch
Thunder VIP-Patch
 Fehlerberichtslösung für den MySQL-Import einer SQL-Datei
Fehlerberichtslösung für den MySQL-Import einer SQL-Datei
 So lösen Sie das Problem, wenn der Computer eingeschaltet wird, der Bildschirm schwarz wird und der Desktop nicht aufgerufen werden kann
So lösen Sie das Problem, wenn der Computer eingeschaltet wird, der Bildschirm schwarz wird und der Desktop nicht aufgerufen werden kann
 Einführung in die Verwendung von vscode
Einführung in die Verwendung von vscode
 Virtuelle Währungsumtauschplattform
Virtuelle Währungsumtauschplattform








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



