
 Technologie-Peripheriegeräte
KI
Untersuchungen von Google DeepMind haben ergeben, dass gegnerische Angriffe die visuelle Erkennung von Menschen und KI beeinträchtigen und eine Vase mit einer Katze verwechseln können!
Technologie-Peripheriegeräte
KI
Untersuchungen von Google DeepMind haben ergeben, dass gegnerische Angriffe die visuelle Erkennung von Menschen und KI beeinträchtigen und eine Vase mit einer Katze verwechseln können!
Untersuchungen von Google DeepMind haben ergeben, dass gegnerische Angriffe die visuelle Erkennung von Menschen und KI beeinträchtigen und eine Vase mit einer Katze verwechseln können!

Welche Beziehung besteht zwischen dem menschlichen neuronalen Netzwerk (Gehirn) und dem künstlichen neuronalen Netzwerk (ANN)?
Ein Lehrer hat es einmal so verglichen: Es ist wie die Beziehung zwischen einer Maus und Mickey Mouse.
Reale neuronale Netze sind leistungsstark, aber völlig anders als die Art und Weise, wie Menschen wahrnehmen, lernen und verstehen.
Zum Beispiel weisen KNNs Schwachstellen auf, die in der menschlichen Wahrnehmung normalerweise nicht vorkommen, und sie sind anfällig für kontroverse Störungen.
Ein Bild muss möglicherweise nur die Werte einiger Pixel ändern oder einige Rauschdaten hinzufügen.
Aus menschlicher Sicht ist kein Unterschied zu beobachten, bei Bildklassifizierungsnetzwerken jedoch werden als völlig irrelevante Kategorie erkannt.
Die neuesten Untersuchungen von Google DeepMind zeigen jedoch, dass unsere bisherige Ansicht möglicherweise falsch ist!
Selbst subtile Veränderungen in digitalen Bildern können die menschliche Wahrnehmung beeinflussen.
Mit anderen Worten: Auch das menschliche Urteilsvermögen kann durch diese kontroverse Störung beeinträchtigt werden.

Papieradresse: https://www.nature.com/articles/s41467-023-40499-0
Dieser Artikel von Google DeepMind wurde in Nature Communications veröffentlicht.
In der Arbeit wird untersucht, ob Menschen unter kontrollierten Testbedingungen möglicherweise auch empfindlich auf dieselben Störungen reagieren.
Durch eine Reihe von Experimenten haben Forscher dies bewiesen.
Gleichzeitig zeigt sich hier auch die Gemeinsamkeit zwischen menschlichem und maschinellem Sehen.
Gegnerische Bilder
Gegnerische Bilder sind subtile Änderungen an einem Bild, die dazu führen, dass das KI-Modell den Inhalt des Bildes falsch klassifiziert – diese absichtliche Täuschung wird als gegnerischer Angriff bezeichnet.
Zum Beispiel könnte ein Angriff darauf abzielen, ein KI-Modell dazu zu bringen, eine Vase als Katze oder als alles andere als eine Vase zu klassifizieren.

Das obige Bild zeigt den Prozess eines gegnerischen Angriffs (zur Vereinfachung der menschlichen Beobachtung sind die zufälligen Störungen in der Mitte übertrieben dargestellt).
In digitalen Bildern hat jedes Pixel im RGB-Bild einen Wert zwischen 0 und 255 (bei 8-Bit-Tiefe) und der Wert stellt die Intensität eines einzelnen Pixels dar.
Bei gegnerischen Angriffen kann der Angriffseffekt durch Ändern des Pixelwerts in einem kleinen Bereich erzielt werden.
In der realen Welt können auch gegnerische Angriffe auf physische Objekte erfolgreich sein, etwa indem sie dazu führen, dass Stoppschilder fälschlicherweise als Geschwindigkeitsbegrenzungsschilder erkannt werden.
Aus Sicherheitsgründen arbeiten Forscher bereits an Möglichkeiten, sich gegen gegnerische Angriffe zu verteidigen und deren Risiken zu verringern.
Widersprüchliche Auswirkungen auf die menschliche Wahrnehmung
Frühere Untersuchungen haben gezeigt, dass Menschen möglicherweise empfindlich auf große Bildstörungen reagieren, die klare Formhinweise liefern.
Welche Auswirkungen haben jedoch differenziertere gegnerische Angriffe auf Menschen? Nehmen Menschen Störungen in Bildern als harmloses zufälliges Bildrauschen wahr und beeinflussen sie die menschliche Wahrnehmung?
Um das herauszufinden, führten Forscher kontrollierte Verhaltensexperimente durch.
Zuerst wird eine Reihe von Rohbildern aufgenommen und auf jedes Bild werden zwei gegnerische Angriffe ausgeführt, um mehrere Paare gestörter Bilder zu erzeugen.
Im folgenden animierten Beispiel wird das Originalbild vom Modell als „Vase“ klassifiziert.
Aufgrund des gegnerischen Angriffs hat das Modell die beiden gestörten Bilder mit hoher Sicherheit fälschlicherweise als „Katze“ und „Lastwagen“ klassifiziert.

Als nächstes wurden menschlichen Teilnehmern diese beiden Bilder gezeigt und eine gezielte Frage gestellt: Welches Bild ähnelt eher einer Katze?
Obwohl keines der Fotos wie eine Katze aussah, mussten sie eine Wahl treffen.
Normalerweise denken Probanden, sie hätten eine zufällige Wahl getroffen, aber ist das wirklich der Fall?
Wenn das Gehirn gegenüber subtilen gegnerischen Angriffen unempfindlich ist, wählen die Probanden in 50 % der Fälle jedes Bild aus.
Experimente haben jedoch ergeben, dass die Auswahlrate (d. h. die Verzerrung der menschlichen Wahrnehmung) tatsächlich höher als der Zufall (50 %) ist und die Anpassung der Bildpixel tatsächlich sehr gering ist.
Aus Sicht des Teilnehmers fühlt es sich an, als ob er aufgefordert würde, zwischen zwei nahezu identischen Bildern zu unterscheiden. Frühere Untersuchungen haben jedoch gezeigt, dass Menschen bei Entscheidungen schwache Wahrnehmungssignale nutzen – auch wenn diese Signale zu schwach sind, um Vertrauen oder Bewusstsein zu vermitteln.
In diesem Beispiel sehen wir vielleicht eine Vase, aber eine Aktivität im Gehirn sagt uns, dass sie den Schatten einer Katze hat.
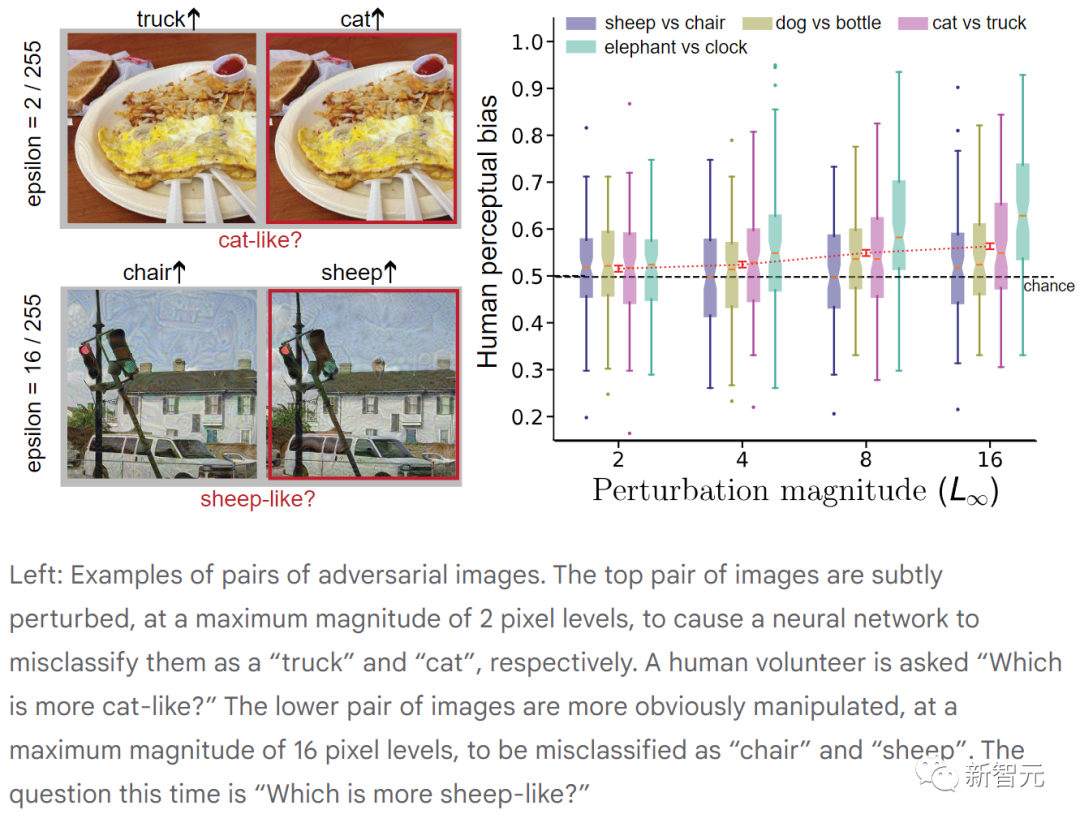
Das Bild oben zeigt Paare kontroverser Bilder. Das obere Bildpaar ist mit einer maximalen Amplitude von 2 Pixeln leicht gestört, was dazu führt, dass das neuronale Netzwerk sie fälschlicherweise als „Lkw“ bzw. „Katze“ klassifiziert. (Die Freiwilligen wurden gefragt: „Welches ähnelt eher einer Katze?“)
Das Bildpaar unten weist offensichtlichere Störungen mit einer maximalen Amplitude von 16 Pixeln auf und wurde von uns fälschlicherweise als „Stuhl“ und „Schaf“ klassifiziert das neuronale Netzwerk. (Diesmal lautete die Frage „Welches ähnelt eher einem Schaf?“)
In jedem Experiment wählten die Teilnehmer in mehr als der Hälfte der Fälle zuverlässig das gegnerische Bild aus, das der Zielfrage entsprach. Während das menschliche Sehvermögen nicht so anfällig für kontroverse Störungen ist wie das maschinelle Sehen, können diese Störungen den Menschen dennoch zugunsten von Maschinenentscheidungen beeinflussen.
Wenn die menschliche Wahrnehmung durch gegnerische Bilder beeinträchtigt werden kann, dann wird dies ein neues, aber kritisches Sicherheitsproblem darstellen.
Dies erfordert eine eingehende Forschung, um die Ähnlichkeiten und Unterschiede zwischen dem Verhalten visueller Systeme mit künstlicher Intelligenz und der menschlichen Wahrnehmung zu untersuchen und sicherere Systeme mit künstlicher Intelligenz zu entwickeln.
Papierdetails
Das Standardverfahren zur Generierung kontradiktorischer Störungen beginnt mit einem vorab trainierten ANN-Klassifikator, der RGB-Bilder einer Wahrscheinlichkeitsverteilung über einen festen Satz von Klassen zuordnet.
Jede Änderung am Bild (z. B. die Erhöhung der Rotintensität eines bestimmten Pixels) führt zu einer geringfügigen Änderung der Ausgabewahrscheinlichkeitsverteilung.
Gegnerische Bilder werden durchsucht (Gradientenabstieg), um eine Störung des Originalbildes zu erhalten, die dazu führt, dass das ANN die Wahrscheinlichkeit verringert, der richtigen Klasse zugeordnet zu werden (nicht gezielter Angriff), oder einer bestimmten Klasse eine hohe Wahrscheinlichkeit zuweist alternative Klasse (gezielte Angriffe).
Um sicherzustellen, dass Störungen nicht zu weit vom Originalbild abweichen, wird in der Literatur zum kontradiktorischen maschinellen Lernen häufig die L(∞)-Normbeschränkung angewendet, die angibt, dass kein Pixel um mehr als ±ε von seinem Originalwert abweichen darf , wobei ε typischerweise viel kleiner ist als [ 0–255] Pixelintensitätsbereich.
Diese Einschränkung gilt für Pixel in jeder RGB-Farbebene. Obwohl diese Einschränkung Einzelpersonen nicht daran hindert, Änderungen im Bild zu erkennen, bleibt das Hauptsignal, das die ursprüngliche Bildkategorie angibt, bei geeigneter Wahl von ε im gestörten Bild größtenteils intakt.
Experimente
In ersten Experimenten untersuchten die Autoren menschliche Klassifizierungsreaktionen auf kurze, maskierte gegnerische Bilder.
Durch die Begrenzung der Expositionszeit, um Klassifizierungsfehler zu erhöhen, sollte das Experiment die Sensibilität einer Person für Aspekte eines Reizes erhöhen, die sonst möglicherweise keinen Einfluss auf Klassifizierungsentscheidungen haben würden.
Eine gegnerische Störung wird am Bild der realen Klasse T durchgeführt. Durch die Optimierung der Störung neigt das ANN dazu, das Bild fälschlicherweise als A zu klassifizieren. Die Teilnehmer wurden gebeten, eine erzwungene Wahl zwischen T und A zu treffen.
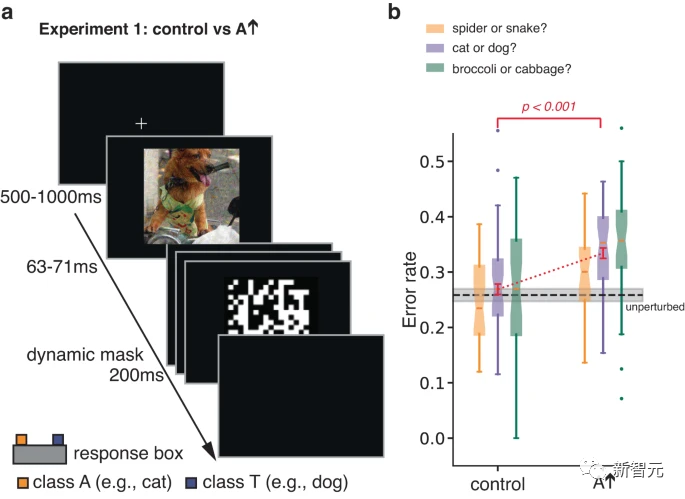
Die Forscher testeten die Teilnehmer auch an Kontrollbildern, die durch Umdrehen kontrovers gestörter Bilder, die im A-Zustand erhalten wurden, von oben nach unten erstellt wurden.
Diese einfache Transformation unterbricht die Pixel-zu-Pixel-Korrespondenz zwischen gegnerischen Störungen und Bildern, wodurch die Auswirkungen gegnerischer Störungen auf das ANN weitgehend eliminiert werden, während die Spezifikationen der Störung und andere Statistiken erhalten bleiben.
Die Ergebnisse zeigten, dass die Teilnehmer das gestörte Bild eher als Kategorie A einstuften als das Kontrollbild.
Experiment 1 oben nutzte eine kurze Maskierungsdemonstration, um den Einfluss der ursprünglichen Bildkategorie (Primärsignal) auf die Reaktion zu begrenzen und so die Empfindlichkeit gegenüber gegnerischen Störungen (untergeordnetes Signal) aufzudecken.
Die Forscher entwarfen außerdem drei zusätzliche Experimente mit den gleichen Zielen, verzichteten jedoch auf groß angelegte Störungen und eine Betrachtung bei begrenzter Belichtung.
In diesen Experimenten leitet das dominante Signal im Bild nicht systematisch die Antwortauswahl, sodass der Einfluss des untergeordneten Signals zum Vorschein kommt.
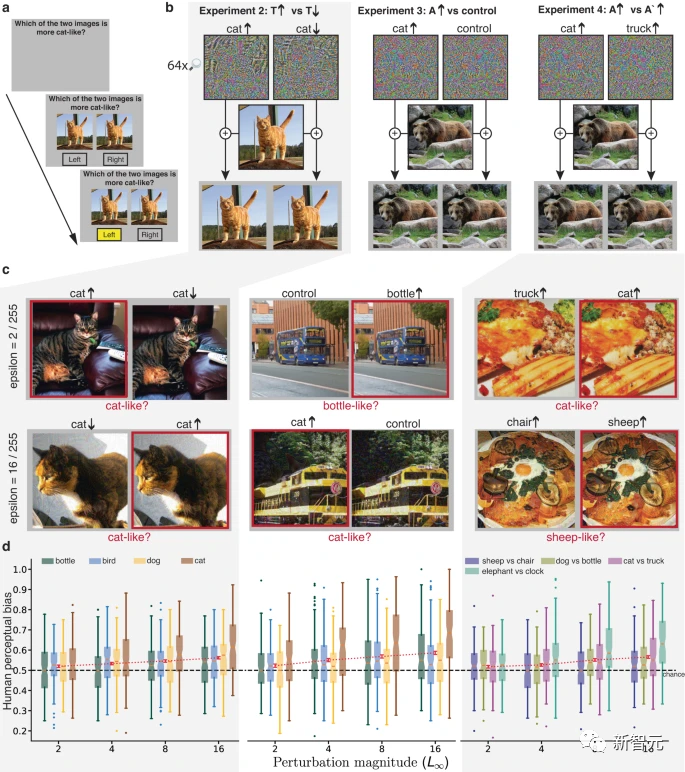
In jedem Experiment wurde ein nahezu identisches Paar unmaskierter Reize präsentiert und blieb sichtbar, bis eine Antwort ausgewählt wurde. Das Reizpaar hat das gleiche dominante Signal, sie sind beide Modulationen desselben zugrunde liegenden Bildes, haben aber unterschiedliche Slave-Signale. Die Teilnehmer wurden gebeten, Bilder auszuwählen, die eher Instanzen der Zielkategorie ähnelten.
In Experiment 2 waren beide Reize Bilder, die zur T-Kategorie gehörten. Einer von ihnen war gestört und das KNN sagte voraus, dass er eher der T-Kategorie ähnelte, und der andere war gestört und sagte voraus, dass er weniger der T-Kategorie ähnelte .
In Experiment 3 ist der Reiz ein Bild der realen Kategorie T, von dem eines gestört wird, um die KNN-Klassifizierung zu ändern, um es näher an die gegnerische Zielkategorie A zu bringen, und das andere die gleiche Störung verwendet. Aber als Kontrollbedingung nach links und rechts gedreht.
Der Effekt dieser Kontrolle besteht darin, die Norm und andere Statistiken der Störung beizubehalten, jedoch konservativer zu sein als die Kontrolle in Experiment 1, da die linke und rechte Seite des Bildes möglicherweise ähnlichere Statistiken aufweisen als die obere und unteren Teilen des Bildes.
Das Bildpaar in Experiment 4 ist ebenfalls eine Modulation der realen Kategorie T, eines ähnelt eher der Kategorie A und das andere ähnelt eher der Kategorie 3. Bei den Versuchen wurden die Teilnehmer abwechselnd gebeten, ein Bild auszuwählen, das eher der Kategorie A entsprach, oder ein Bild, das eher der Kategorie 3 entsprach.
In den Experimenten 2–4 korrelierte die menschliche Wahrnehmungsverzerrung jedes Bildes signifikant positiv mit der Verzerrung des KNN. Die Störungsamplituden lagen zwischen 2 und 16, was kleiner ist als die zuvor an menschlichen Teilnehmern untersuchten Störungen und denen ähnelt, die in Studien zum kontradiktorischen maschinellen Lernen verwendet werden.
Überraschenderweise reichen bereits Störungen von 2 Pixel-Intensitätsstufen aus, um die menschliche Wahrnehmung zuverlässig zu beeinflussen.
Der Vorteil von Experiment 2 besteht darin, dass die Teilnehmer intuitive Urteile fällen müssen (z. B. welches der beiden gestörten Katzenbilder eher einer Katze ähnelt);
Experiment 2 lässt jedoch nur kontradiktorische Störungen zu Indem Sie ein Bild schärfer oder unschärfer machen, können Sie es mehr oder weniger katzenartig wirken lassen.
Der Vorteil von Experiment 3 besteht darin, dass alle Statistiken der verglichenen Störungen übereinstimmen, nicht nur die maximale Amplitude der Störungen.
Abgleich der Störungsstatistiken stellt jedoch nicht sicher, dass die Störung beim Hinzufügen zum Bild gleichermaßen wahrnehmbar ist, und daher können die Teilnehmer Entscheidungen basierend auf der Bildverzerrung treffen.
Die Stärke von Experiment 4 besteht darin, dass es zeigt, dass die Teilnehmer sensibel auf die ihnen gestellten Fragen reagieren, da dieselben Bildpaare je nach gestellter Frage systematisch unterschiedliche Antworten hervorrufen.
Allerdings wurden die Teilnehmer in Experiment 4 gebeten, eine scheinbar absurde Frage zu beantworten (z. B. welches der beiden Omelettbilder eher wie eine Katze aussieht?), was zu unterschiedlichen Interpretationen der Frage führte.
Zusammenfassend liefern die Experimente 2-4 konvergierende Beweise dafür, dass selbst wenn die Störungsamplitude sehr klein ist und die Betrachtungszeit nicht begrenzt ist, Slave-Gegnersignale, die einen starken Einfluss auf das KI-Netzwerk haben, die menschliche Wahrnehmung beeinflussen und Urteil in die gleiche Richtung.
Darüber hinaus ist die Verlängerung der Beobachtungszeit (natürlich wahrgenommene Umgebung) entscheidend dafür, dass kontradiktorische Störungen echte Konsequenzen haben.
Das obige ist der detaillierte Inhalt vonUntersuchungen von Google DeepMind haben ergeben, dass gegnerische Angriffe die visuelle Erkennung von Menschen und KI beeinträchtigen und eine Vase mit einer Katze verwechseln können!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 So verschönern Sie das XML -Format
Apr 02, 2025 pm 09:57 PM
So verschönern Sie das XML -Format
Apr 02, 2025 pm 09:57 PM
Die XML -Verschönerung verbessert im Wesentlichen seine Lesbarkeit, einschließlich angemessener Einkerbung, Zeilenpausen und Tag -Organisation. Das Prinzip besteht darin, den XML -Baum zu durchqueren, die Eindrücke entsprechend der Ebene hinzuzufügen und leere Tags und Tags, die Text enthalten, zu verarbeiten. Pythons xml.etree.elementtree -Bibliothek bietet eine bequeme Funktion hübsch_xml (), die den oben genannten Verschönerungsprozess implementieren kann.
 So überprüfen Sie das XML -Format
Apr 02, 2025 pm 10:00 PM
So überprüfen Sie das XML -Format
Apr 02, 2025 pm 10:00 PM
Die Validierung des XML -Formats umfasst die Überprüfung der Struktur und der Einhaltung von DTD oder Schema. Ein XML -Parser ist erforderlich, wie z. Der Überprüfungsprozess umfasst das Parsen der XML -Datei, das Laden des XSD -Schemas und das Ausführen der AssertValid -Methode, um eine Ausnahme auszuführen, wenn ein Fehler erkannt wird. Das Überprüfen des XML -Formats erfordert auch die Handhabung verschiedener Ausnahmen und einen Einblick in die Sprache des XSD -Schemas.
 So verwenden Sie char Array in C -Sprache
Apr 03, 2025 pm 03:24 PM
So verwenden Sie char Array in C -Sprache
Apr 03, 2025 pm 03:24 PM
Das Char -Array speichert Zeichensequenzen in der C -Sprache und wird als char Array_name [Größe] deklariert. Das Zugriffselement wird durch den Einweisoperator weitergeleitet, und das Element endet mit dem Null -Terminator '\ 0', der den Endpunkt der Zeichenfolge darstellt. Die C -Sprache bietet eine Vielzahl von String -Manipulationsfunktionen wie Strlen (), Strcpy (), Strcat () und strcmp ().
 Vermeiden Sie in C -Switch -Anweisungen standardmäßige Fehler
Apr 03, 2025 pm 03:45 PM
Vermeiden Sie in C -Switch -Anweisungen standardmäßige Fehler
Apr 03, 2025 pm 03:45 PM
Eine Strategie zur Vermeidung von Fehlern, die in C -Switch -Anweisungen standardmäßig verursacht wurden: Verwenden Sie die Umgebungen anstelle von Konstanten, wodurch der Wert der Fallerklärung auf ein gültiges Mitglied des Enum beschränkt wird. Verwenden Sie in der letzten Fallanweisung Falsch, um das Programm weiterhin den folgenden Code auszuführen. Fügen Sie für Switch -Anweisungen ohne Falle immer eine Standardanweisung für die Fehlerbehandlung hinzu oder geben Sie das Standardverhalten an.
 Was ist die Funktion der C -Sprachsumme?
Apr 03, 2025 pm 02:21 PM
Was ist die Funktion der C -Sprachsumme?
Apr 03, 2025 pm 02:21 PM
Es gibt keine integrierte Summenfunktion in der C-Sprache, daher muss sie selbst geschrieben werden. Die Summe kann erreicht werden, indem das Array durchquert und Elemente akkumulieren: Schleifenversion: Die Summe wird für die Schleifen- und Arraylänge berechnet. Zeigerversion: Verwenden Sie Zeiger, um auf Array-Elemente zu verweisen, und eine effiziente Summierung wird durch Selbststillstandszeiger erzielt. Dynamisch Array -Array -Version zuweisen: Zuordnen Sie Arrays dynamisch und verwalten Sie selbst den Speicher selbst, um sicherzustellen, dass der zugewiesene Speicher befreit wird, um Speicherlecks zu verhindern.
 Was ist der Unterschied zwischen Null- und Null -Charakteren in der C -Sprache
Apr 03, 2025 am 11:12 AM
Was ist der Unterschied zwischen Null- und Null -Charakteren in der C -Sprache
Apr 03, 2025 am 11:12 AM
Null (Zeiger) und \ 0 (Nullzeichen) unterscheiden sich in der C -Sprache völlig unterschiedlich: Null bedeutet, dass ungültige Zeigerpunkte (Speicheradresse 0), während \ 0 eine Zeichenkonstante ist und das Ende der Zeichenfolge markiert; Die gemischte Verwendung wirft einen Fehler (Compiler Warnung).
 Was bedeutet C -Sprache null
Apr 03, 2025 pm 12:00 PM
Was bedeutet C -Sprache null
Apr 03, 2025 pm 12:00 PM
Null in C -Sprache repräsentiert einen Nullzeiger, der auf eine Speicheradresse hinweist, die nicht existiert. Es wird für die Fehlerbehandlung und die Strukturmarkierung des Datums am Ende der Daten verwendet. Es sollte jedoch darauf geachtet werden, die Gültigkeit von Nullzeiger zu überprüfen, um Probleme wie SEGFAULTS und Programmabstürze zu vermeiden.
 Was ist null nützlich in der C -Sprache
Apr 03, 2025 pm 12:03 PM
Was ist null nützlich in der C -Sprache
Apr 03, 2025 pm 12:03 PM
Null ist ein besonderer Wert in der C -Sprache, der einen Nullzeiger darstellt, der identifiziert wird, dass die Zeigervariable nicht auf eine gültige Speicheradresse verweist. Das Verständnis von NULL ist entscheidend, da es hilft, Programmabstürze zu vermeiden und Code -Robustheit zu gewährleisten. Zu den gemeinsamen Verwendungen gehören Parameterüberprüfung, Speicherzuweisung und optionale Parameter für das Funktionsdesign. Wenn Sie NULL verwenden, sollten Sie vorsichtig sein, um Fehler wie baumelnde Zeiger zu vermeiden und zu vergessen, NULL zu überprüfen, und effiziente Nullprüfungen und löschliche Benennungen zur Optimierung der Codeleistung und der Lesbarkeit durchzuführen.
