
 Technologie-Peripheriegeräte
KI
Die neue Methode der Tsinghua-Universität findet erfolgreich präzise Videoclips! SOTA wurde übertroffen und ist Open Source
Technologie-Peripheriegeräte
KI
Die neue Methode der Tsinghua-Universität findet erfolgreich präzise Videoclips! SOTA wurde übertroffen und ist Open Source
Die neue Methode der Tsinghua-Universität findet erfolgreich präzise Videoclips! SOTA wurde übertroffen und ist Open Source

Mit nur einem Satz Beschreibung können Sie den entsprechenden Clip in einem großen Video finden!
Bei der Beschreibung von „Eine Person trinkt Wasser, während sie die Treppe hinuntergeht“ kann die neue Methode durch den Abgleich von Videobildern und Schritten sofort die entsprechenden Start- und Endzeitstempel finden:

Sogar „lachende“ Semantik Auch schwer zu verstehende Elemente können genau positioniert werden:

Die Methode heißt Adaptive Dual Branch Promotion Network (ADPN) und wurde vom Forschungsteam der Tsinghua-Universität vorgeschlagen.
Konkret wird ADPN verwendet, um eine visuell-linguistische modalübergreifende Aufgabe namens Videoclip-Positionierung (Temporal Sentence Grounding, TSG) auszuführen, bei der relevante Clips aus dem Video basierend auf dem Abfragetext lokalisiert werden sollen.
ADPN zeichnet sich durch seine Fähigkeit aus, die Konsistenz und Komplementarität von visuellen und akustischen Modalitäten in Videos effizient zu nutzen, um die Positionierungsleistung von Videoclips zu verbessern.
Im Vergleich zu anderen TSG-Arbeiten PMI-LOC und UMT, die Audio verwenden, hat die ADPN-Methode im Audiomodus deutlichere Leistungsverbesserungen erzielt und in mehreren Tests neue SOTA gewonnen.
Derzeit wurde diese Arbeit von ACM Multimedia 2023 angenommen und ist vollständig Open Source.

Werfen wir einen Blick darauf, was ADPN ist ~
Videoclips in einem Satz positionieren
Videoclip-Positionierung (Temporal Sentence Grounding, TSG) ist eine wichtige visuell-linguistische modalübergreifende Aufgabe.
Ihr Zweck besteht darin, die Start- und Endzeitstempel von Segmenten zu finden, die semantisch mit ihnen in einem unbearbeiteten Video übereinstimmen, basierend auf Abfragen in natürlicher Sprache. Dazu muss die Methode über starke zeitliche, modalübergreifende Argumentationsfähigkeiten verfügen.
Die meisten bestehenden TSG-Methoden berücksichtigen jedoch nur die visuellen Informationen im Video, wie RGB, optischer Fluss(optische Flüsse), Tiefe(Tiefe) usw., während die Audioinformationen, die das Video natürlich begleiten, ignoriert werden. .
Audioinformationen enthalten oft eine reichhaltige Semantik und sind konsistent und ergänzend zu visuellen Informationen. Wie in der Abbildung unten gezeigt, helfen diese Eigenschaften der TSG-Aufgabe.
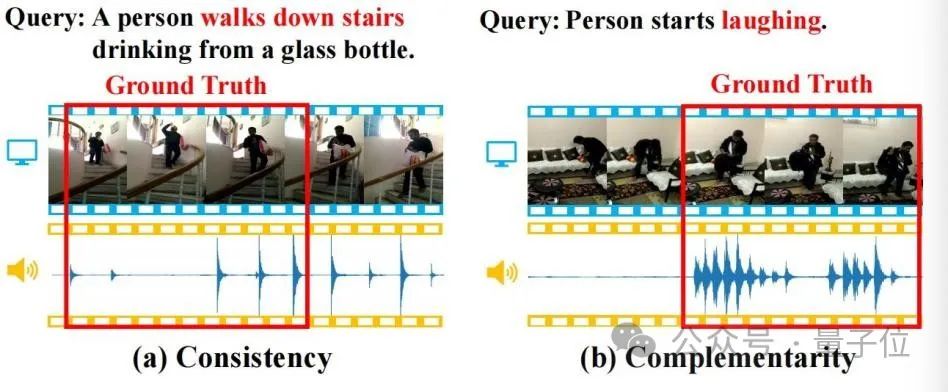
△Abbildung 1
(a) Konsistenz: Das Videobild und die Schritte stimmen durchweg mit der Semantik von „die Treppe hinunter“ in der Abfrage überein; (b) Komplementarität: Das Videobild ist schwer zu identifizieren Verhalten, um die semantische Bedeutung von „Lachen“ in der Abfrage zu lokalisieren, aber das Vorhandensein von Lachen liefert einen starken komplementären Positionierungshinweis.
Daher haben Forscher die Aufgabe der audiogestützten Videocliplokalisierung (Audio-enhanced Temporal Sentence Grounding, ATSG) eingehend untersucht, mit dem Ziel, Lokalisierungshinweise sowohl aus visuellen als auch aus akustischen Modalitäten besser zu erfassen Die Modalität bringt auch die folgenden Herausforderungen mit sich:
Die Konsistenz und Komplementarität von Audio- und visuellen Modalitäten hängen mit dem Abfragetext zusammen. Um die audiovisuelle Konsistenz und Komplementarität zu erfassen, ist daher die Modellierung der drei Modi für die zustandsbehaftete Interaktion zwischen Text, Bild und Audio erforderlich.- Es gibt erhebliche modale Unterschiede zwischen Audio und Bild. Die Informationsdichte und die Rauschintensität der beiden sind unterschiedlich, was sich auf die Leistung des audiovisuellen Lernens auswirkt.
- Um die oben genannten Herausforderungen zu lösen, schlugen Forscher eine neuartige ATSG-Methode „
“ (Adaptive Dual-branch Prompted Network, ADPN) vor. Durch ein Modellstrukturdesign mit zwei Zweigen kann diese Methode die Konsistenz und Komplementarität zwischen Audio und Bild adaptiv modellieren und modales Audiorauschen mithilfe einer Rauschunterdrückungsoptimierungsstrategie basierend auf Kurslerninterferenzen weiter eliminieren, was die Bedeutung von Audiosignalen für Video verdeutlicht Abruf.
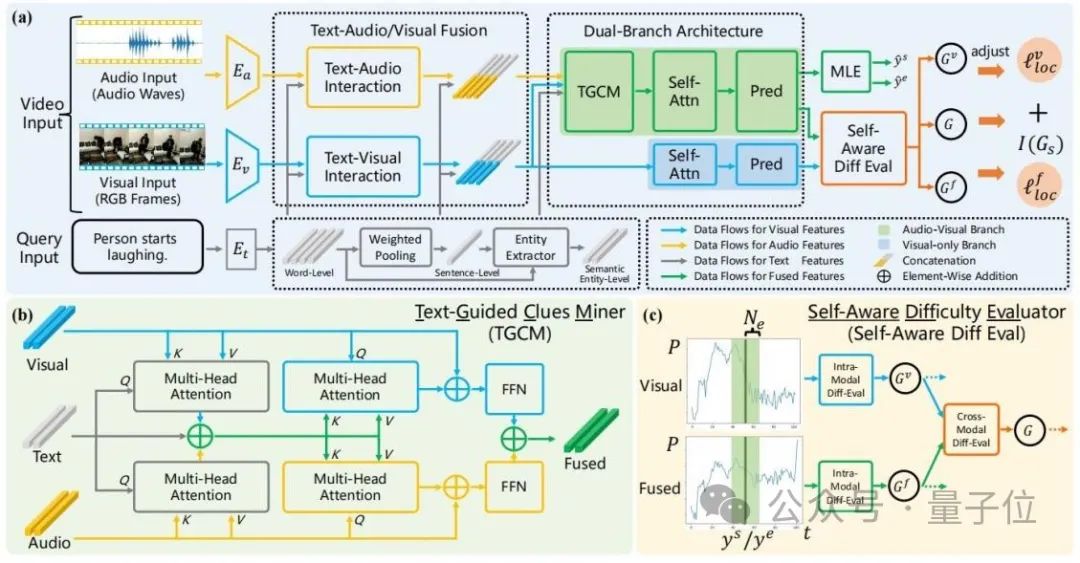
Die Gesamtstruktur von ADPN ist in der folgenden Abbildung dargestellt:
 △ Abbildung 2: Gesamtschema des Adaptive Dual Branch Promotion Network (ADPN)
△ Abbildung 2: Gesamtschema des Adaptive Dual Branch Promotion Network (ADPN)
 △ Abbildung 2: Gesamtschema des Adaptive Dual Branch Promotion Network (ADPN)
△ Abbildung 2: Gesamtschema des Adaptive Dual Branch Promotion Network (ADPN) Es umfasst hauptsächlich drei Designs:
1 Design der NetzwerkstrukturAngesichts der Tatsache, dass das Rauschen von Audio offensichtlicher ist und Audio für TSG-Aufgaben normalerweise redundantere Informationen enthält, muss dem Lernprozess von Audio- und visuellen Modalitäten eine unterschiedliche Bedeutung beigemessen werden. Daher handelt es sich bei diesem Artikel um eine Dualität branch Die Netzwerkstruktur nutzt Audio und Bild für multimodales Lernen und verbessert gleichzeitig die visuellen Informationen.
Insbesondere unter Bezugnahme auf Abbildung 2(a) trainiert ADPN gleichzeitig einen Zweig (visueller Zweig) , der nur visuelle Informationen verwendet, und einen Zweig (gemeinsamer Zweig) , der sowohl visuelle Informationen als auch Audioinformationen verwendet.
Die beiden Zweige haben ähnliche Strukturen, wobei der gemeinsame Zweig eine textgesteuerte Hinweis-Mining-Einheit (TGCM) hinzufügt, um die modale Interaktion zwischen Text, Bild und Audio zu modellieren. Während des Trainingsprozesses aktualisieren die beiden Zweige gleichzeitig die Parameter, und in der Inferenzphase wird das Ergebnis des gemeinsamen Zweigs als Modellvorhersageergebnis verwendet. 2. Text-Guided Clues Miner die Interaktion zwischen den drei Modalitäten Text-Bild-Audio zu modellieren.
Siehe Abbildung 2(b), TGCM ist in zwei Schritte unterteilt: „Extraktion“ und „Vermehrung“. Zuerst wird Text als Abfragebedingung verwendet und die zugehörigen Informationen werden aus den visuellen und akustischen Modalitäten extrahiert und integriert. Anschließend werden die visuellen und akustischen Modalitäten als Abfragebedingung verwendet und die integrierten Informationen werden auf die visuellen und akustischen Modalitäten übertragen Audiomodi durch Aufmerksamkeit. Ihre jeweiligen Modalitäten werden schließlich durch FFN funktionsverschmelzt.
3. Strategie zur Optimierung des Lehrplan-LernensDie Forscher stellten fest, dass die Audiodaten Rauschen enthalten, was sich auf die Wirkung des multimodalen Lernens auswirkt. Deshalb verwendeten sie die Intensität des Rauschens als Referenz für den Schwierigkeitsgrad der Beispiele und führten das Lernen im Lehrplan ein (Curriculum Learning, CL)
Entstören Sie den Optimierungsprozess, siehe Abbildung 2(c). Sie bewerten die Schwierigkeit des Samples anhand der Differenz in der vorhergesagten Ausgabe der beiden Zweige. Sie glauben, dass ein zu schwieriges Sample mit hoher Wahrscheinlichkeit darauf hinweist, dass sein Audio zu viel Rauschen enthält und nicht für das geeignet ist TSG-Aufgabe, daher basiert der Verlust für den Trainingsprozess auf der Bewertungsbewertung der Stichprobenschwierigkeit. Die Funktionsterme werden neu gewichtet, um durch Rauschen im Audio verursachte schlechte Gradienten zu verwerfen.(Weitere Informationen zur Modellstruktur und den Trainingsdetails finden Sie im Originaltext.)
Mehrfachtests Neues SOTA
Die Forscher führten experimentelle Auswertungen an den Benchmark-Datensätzen Charades-STA und ActivityNet Captions des TSG durch Aufgabe erstellt und mit der Basismethode verglichen. Der Vergleich ist in Tabelle 1 dargestellt. Die ADPN-Methode kann eine SOTA-Leistung erzielen; im Vergleich zu anderen TSG-Arbeiten PMI-LOC und UMT, die Audio nutzen, erzielt die ADPN-Methode deutlichere Leistungsverbesserungen durch die Audiomodalität, was darauf hindeutet, dass die ADPN-Methode die Audiomodalität nutzt fördern die Überlegenheit der TSG.
△Tabelle 1: Experimentelle Ergebnisse zu Charades-STA und ActivityNet Captions
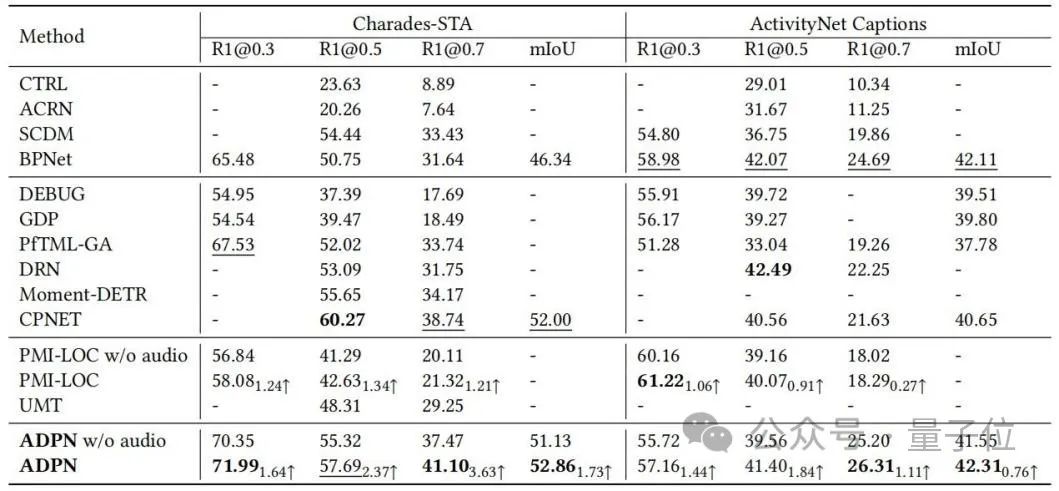
Die Forscher demonstrierten außerdem die Wirksamkeit verschiedener Designeinheiten bei ADPN durch Ablationsexperimente, wie in Tabelle 2 gezeigt.
△Tabelle 2: Ablationsexperiment an Charades-STA
 △Tabelle 2: Ablationsexperiment an Charades-STA
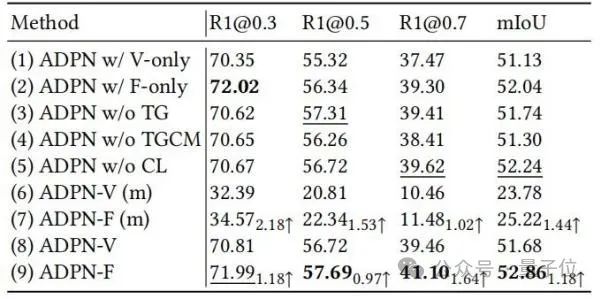
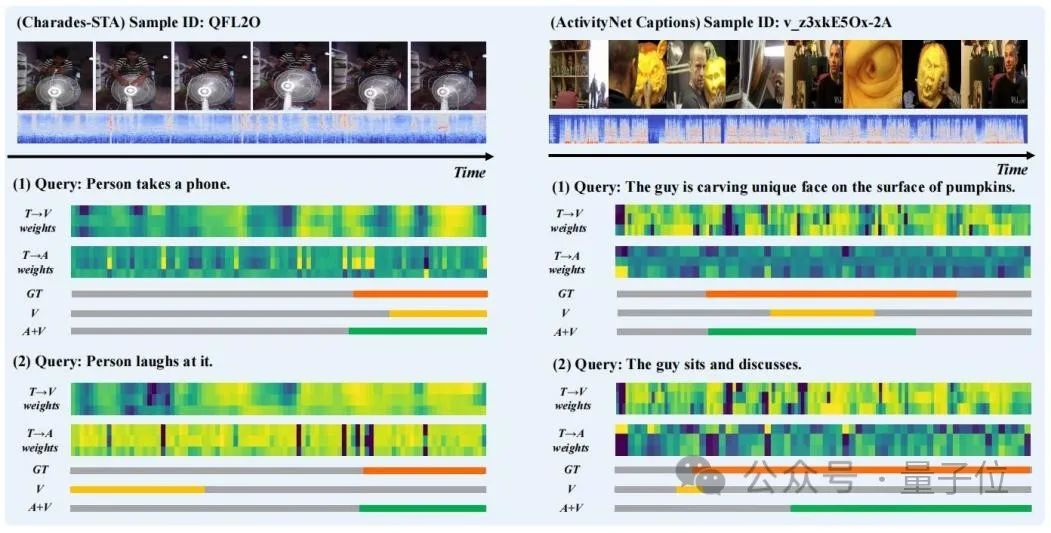
△Tabelle 2: Ablationsexperiment an Charades-STADie Forscher wählten die Vorhersageergebnisse einiger Proben zur Visualisierung aus und zeichneten den „Text zum Sehen“ (T→V) im „Extraktions“-Schritt in TGCM ) und „Text zu Audio“ (T→A) Aufmerksamkeitsgewichtsverteilung, wie in Abbildung 3 dargestellt.
Es ist zu beobachten, dass die Einführung der Audiomodalität die Vorhersageergebnisse verbessert. Aus dem Fall „Person lacht darüber“ können wir erkennen, dass die Aufmerksamkeitsgewichtsverteilung von T→A näher an der Grundwahrheit liegt, was die fehlgeleitete Führung der Modellvorhersage durch die Gewichtsverteilung von T→V korrigiert.
△ Abbildung 3: Falldarstellung
Zusammenfassend schlugen die Forscher in diesem Artikel ein neuartiges adaptives Dual-Branch-Facilitation-Netzwerk
(ADPN)vor, um die Frage der audioverstärkten Videoclip-Lokalisierung
(ATSG) zu lösen.
Sie entwarfen eine Modellstruktur mit zwei Zweigen, um den visuellen Zweig und den audiovisuellen gemeinsamen Zweig gemeinsam zu trainieren und den Informationsunterschied zwischen Audio- und visuellen Modalitäten aufzulösen.
 Sie entwarfen eine Modellstruktur mit zwei Zweigen, um den visuellen Zweig und den audiovisuellen gemeinsamen Zweig gemeinsam zu trainieren und den Informationsunterschied zwischen Audio- und visuellen Modalitäten aufzulösen.
Sie entwarfen eine Modellstruktur mit zwei Zweigen, um den visuellen Zweig und den audiovisuellen gemeinsamen Zweig gemeinsam zu trainieren und den Informationsunterschied zwischen Audio- und visuellen Modalitäten aufzulösen. Sie schlugen außerdem eine textgesteuerte Hinweis-Mining-Einheit
(TGCM)vor, die die Textsemantik als Leitfaden für die Modellierung der Interaktion zwischen Text und audiovisueller Kommunikation nutzt. Schließlich entwarfen die Forscher eine auf Kurslernen basierende Optimierungsstrategie, um Audiorauschen weiter zu eliminieren, die Probenschwierigkeit als Maß für die Rauschintensität auf selbstbewusste Weise zu bewerten und den Optimierungsprozess adaptiv anzupassen. Sie führten zunächst eine eingehende Untersuchung der Audioeigenschaften in ATSG durch, um den Leistungsverbesserungseffekt der Audiomodi besser zu verbessern.
In Zukunft hoffen sie, einen geeigneteren Bewertungsmaßstab für ATSG zu erstellen, um tiefergehende Forschung in diesem Bereich zu fördern.
Papier-Link: https://dl.acm.org/doi/pdf/10.1145/3581783.3612504
Lager-Link: https://github.com/hlchen23/ADPN-MM
Das obige ist der detaillierte Inhalt vonDie neue Methode der Tsinghua-Universität findet erfolgreich präzise Videoclips! SOTA wurde übertroffen und ist Open Source. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Detaillierte Erläuterung von Datenbanksäureattributen Säureattribute sind eine Reihe von Regeln, um die Zuverlässigkeit und Konsistenz von Datenbanktransaktionen sicherzustellen. Sie definieren, wie Datenbanksysteme Transaktionen umgehen, und sorgen dafür, dass die Datenintegrität und -genauigkeit auch im Falle von Systemabstürzen, Leistungsunterbrechungen oder mehreren Benutzern gleichzeitiger Zugriff. Säureattributübersicht Atomizität: Eine Transaktion wird als unteilbare Einheit angesehen. Jeder Teil schlägt fehl, die gesamte Transaktion wird zurückgerollt und die Datenbank behält keine Änderungen bei. Wenn beispielsweise eine Banküberweisung von einem Konto abgezogen wird, jedoch nicht auf ein anderes erhöht wird, wird der gesamte Betrieb widerrufen. begintransaktion; updateAccountsSetBalance = Balance-100WH
 Master SQL Limit -Klausel: Steuern Sie die Anzahl der Zeilen in einer Abfrage
Apr 08, 2025 pm 07:00 PM
Master SQL Limit -Klausel: Steuern Sie die Anzahl der Zeilen in einer Abfrage
Apr 08, 2025 pm 07:00 PM
SQllimit -Klausel: Steuern Sie die Anzahl der Zeilen in Abfrageergebnissen. Die Grenzklausel in SQL wird verwendet, um die Anzahl der von der Abfrage zurückgegebenen Zeilen zu begrenzen. Dies ist sehr nützlich, wenn große Datensätze, paginierte Anzeigen und Testdaten verarbeitet werden und die Abfrageeffizienz effektiv verbessern können. Grundlegende Syntax der Syntax: SelectColumn1, Spalte2, ... Fromtable_Namelimitnumber_of_rows; number_of_rows: Geben Sie die Anzahl der zurückgegebenen Zeilen an. Syntax mit Offset: SelectColumn1, Spalte2, ... Fromtable_NamelimitOffset, Number_of_rows; Offset: Skip überspringen
 Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Die MySQL-Datenbankleistung Optimierungshandbuch In ressourcenintensiven Anwendungen spielt die MySQL-Datenbank eine entscheidende Rolle und ist für die Verwaltung massiver Transaktionen verantwortlich. Mit der Erweiterung der Anwendung werden jedoch die Datenbankleistung Engpässe häufig zu einer Einschränkung. In diesem Artikel werden eine Reihe effektiver Strategien zur Leistungsoptimierung von MySQL -Leistung untersucht, um sicherzustellen, dass Ihre Anwendung unter hohen Lasten effizient und reaktionsschnell bleibt. Wir werden tatsächliche Fälle kombinieren, um eingehende Schlüsseltechnologien wie Indexierung, Abfrageoptimierung, Datenbankdesign und Caching zu erklären. 1. Das Design der Datenbankarchitektur und die optimierte Datenbankarchitektur sind der Eckpfeiler der MySQL -Leistungsoptimierung. Hier sind einige Kernprinzipien: Die Auswahl des richtigen Datentyps und die Auswahl des kleinsten Datentyps, der den Anforderungen entspricht, kann nicht nur Speicherplatz speichern, sondern auch die Datenverarbeitungsgeschwindigkeit verbessern.
 Navicat -Methode zum Anzeigen von MongoDB -Datenbankkennwort
Apr 08, 2025 pm 09:39 PM
Navicat -Methode zum Anzeigen von MongoDB -Datenbankkennwort
Apr 08, 2025 pm 09:39 PM
Es ist unmöglich, das MongoDB -Passwort direkt über Navicat anzuzeigen, da es als Hash -Werte gespeichert ist. So rufen Sie verlorene Passwörter ab: 1. Passwörter zurücksetzen; 2. Überprüfen Sie die Konfigurationsdateien (können Hash -Werte enthalten). 3. Überprüfen Sie Codes (May Hardcode -Passwörter).
 Beherrschen Sie die Reihenfolge nach Klausel in SQL: Daten effektiv sortieren
Apr 08, 2025 pm 07:03 PM
Beherrschen Sie die Reihenfolge nach Klausel in SQL: Daten effektiv sortieren
Apr 08, 2025 pm 07:03 PM
Detaillierte Erläuterung der SQLORDSBY -Klausel: Die effiziente Sortierung der Datenreihenfolge -Klausel ist eine Schlüsselanweisung in SQL, die zur Sortierung von Abfrageergebnissen verwendet wird. Es kann in einzelnen Spalten oder mehreren Spalten in den Aufstieg (ASC) oder absteigender Reihenfolge (Desc) angeordnet werden, wodurch die Datenlesbarkeit und die Effizienz der Datenverwaltung erheblich verbessert werden. OrderBy syntax SelectColumn1, Spalte2, ... fromTable_NameOrDByColumn_Name [ASC | Desc]; Column_Name: Sortieren nach Spalte. ASC: Ascending Order Sort (Standard). Desc: Sortieren Sie in absteigender Reihenfolge. OrderBy Hauptmerkmale: Multi-Sortier-Sortierung: Unterstützt mehrere Spaltensortierungen, und die Reihenfolge der Spalten bestimmt die Priorität der Sortierung. seit
 Navicat stellt eine Verbindung zu Datenbankfehlercode und Lösung her
Apr 08, 2025 pm 11:06 PM
Navicat stellt eine Verbindung zu Datenbankfehlercode und Lösung her
Apr 08, 2025 pm 11:06 PM
Häufige Fehler und Lösungen beim Anschließen mit Datenbanken: Benutzername oder Kennwort (Fehler 1045) Firewall -Blocks -Verbindungsverbindung (Fehler 2003) Timeout (Fehler 10060) Die Verwendung von Socket -Verbindung kann nicht verwendet werden (Fehler 1042).
 So schreiben Sie das neueste Tutorial zur SQL Insertion -Erklärung
Apr 09, 2025 pm 01:48 PM
So schreiben Sie das neueste Tutorial zur SQL Insertion -Erklärung
Apr 09, 2025 pm 01:48 PM
Mit der SQL -Insert -Anweisung wird eine Datenbanktabelle neue Zeilen hinzufügen, und ihre Syntax ist: Intable_Name (Spalte1, Spalte2, ..., Columnn) Werte (Value1, Value2, ..., Valuen);. Diese Anweisung unterstützt das Einfügen mehrerer Werte und ermöglicht es, Nullwerte in Spalten eingefügt zu werden. Es ist jedoch erforderlich, sicherzustellen, dass die eingefügten Werte mit dem Datentyp der Spalte kompatibel sind, um zu vermeiden, dass Einzigartigkeitsbeschränkungen verstoßen.
 Gibt es eine gespeicherte Prozedur in MySQL?
Apr 08, 2025 pm 03:45 PM
Gibt es eine gespeicherte Prozedur in MySQL?
Apr 08, 2025 pm 03:45 PM
MySQL bietet gespeicherte Prozeduren, die ein vorkompilierter SQL -Codeblock sind, der die komplexe Logik zusammenfasst, die Wiederverwendbarkeit und Sicherheit des Codes verbessert. Zu den Kernfunktionen gehören Schleifen, bedingte Aussagen, Cursoren und Transaktionskontrolle. Durch das Aufrufen gespeicherter Prozeduren können Benutzer Datenbankvorgänge ausführen, indem sie einfach eingeben und ausgeben, ohne auf interne Implementierungen zu achten. Es ist jedoch notwendig, auf häufige Probleme wie Syntaxfehler, Berechtigungsprobleme und Logikfehler zu achten und die Leistungsoptimierung und Best -Practice -Prinzipien zu befolgen.
