
 Technologie-Peripheriegeräte
KI
PixelLM, ein multimodales Byte-Großmodell, das das Denken auf Pixelebene ohne SA-Abhängigkeit effizient implementiert
Technologie-Peripheriegeräte
KI
PixelLM, ein multimodales Byte-Großmodell, das das Denken auf Pixelebene ohne SA-Abhängigkeit effizient implementiert
PixelLM, ein multimodales Byte-Großmodell, das das Denken auf Pixelebene ohne SA-Abhängigkeit effizient implementiert

Multimodale große Modelle explodieren. Sind Sie bereit für praktische Anwendungen in feinkörnigen Aufgaben wie Bildbearbeitung, autonomes Fahren und Robotik?
Derzeit beschränken sich die Fähigkeiten der meisten Modelle noch auf die Generierung von Textbeschreibungen des Gesamtbildes oder bestimmter Bereiche, und ihre Fähigkeiten zum Verständnis auf Pixelebene (z. B. Objektsegmentierung) sind relativ begrenzt.
Als Reaktion auf dieses Problem haben einige Arbeiten begonnen, um die Verwendung multimodaler großer Modelle zur Verarbeitung von Benutzersegmentierungsanweisungen zu untersuchen (z. B. „Bitte segmentieren Sie die an Vitamin C reichen Früchte im Bild“).
Allerdings haben die Methoden auf dem Markt zwei Hauptnachteile:
1) Unfähigkeit, Aufgaben mit mehreren Zielobjekten zu bewältigen, was in realen Szenarien unverzichtbar ist;
2) Sich auf Tools wie SAM verlassen Dank des trainierten Bildsegmentierungsmodells reicht der für eine Vorwärtsausbreitung von SAM erforderliche Rechenaufwand aus, damit Llama-7B mehr als 500 Token generieren kann.
Um dieses Problem zu lösen, hat sich das intelligente Kreationsteam von ByteDance mit Forschern der Beijing Jiaotong University und der University of Science and Technology Beijing zusammengetan, um PixelLM vorzuschlagen, das erste groß angelegte effiziente Inferenzmodell auf Pixelebene, das nicht auf SAM angewiesen ist.
Bevor wir es im Detail vorstellen, lassen Sie uns die tatsächlichen Segmentierungseffekte mehrerer Gruppen von PixelLM erleben:
Im Vergleich zu früheren Arbeiten sind die Vorteile von PixelLM:
- Es kann eine beliebige Anzahl offener Domänenziele und verschiedene komplexe Überlegungen gekonnt verarbeiten Aufgaben aufteilen.
- Vermeidung zusätzlicher und kostspieliger Segmentierungsmodelle, Verbesserung der Effizienz und Migrationsmöglichkeiten zu verschiedenen Anwendungen.
Um das Modelltraining und die Bewertung in diesem Forschungsbereich zu unterstützen, hat das Forschungsteam außerdem einen MUSE-Datensatz für Segmentierungsszenarien mit mehreren Zielen erstellt, der auf dem LVIS-Datensatz und GPT-4V basiert. Er enthält 200.000 Frage-Antwort-Paare, die mehr als 900.000 Instanzsegmentierungsmasken umfassen.


Wie wurde diese Forschung durchgeführt, um die oben genannten Effekte zu erzielen?
Das Prinzip hinter
 Pictures
Pictures
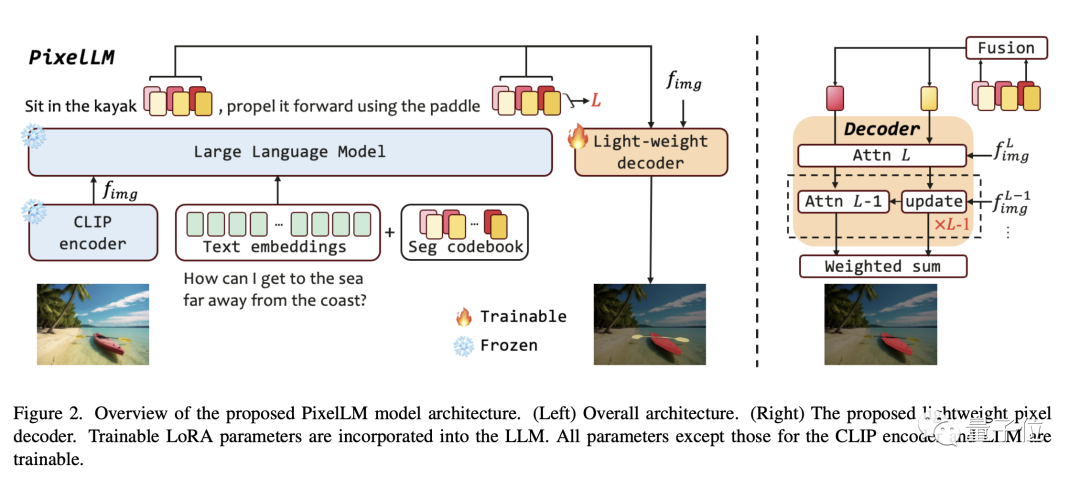
Wie im Rahmendiagramm im Artikel gezeigt, ist die PixelLM-Architektur sehr einfach und besteht aus vier Hauptteilen:
- Pre- trainierter CLIP-ViT-Vision-Encoder
- Großes Sprachmodell
- Leichter Pixeldecoder
- Segmentcodetabelle Seg-Codebuch
Seg-Codebuch enthält lernbare Token, die zum Codieren von Zielinformationen in verschiedenen Maßstäben von CLIP-ViT verwendet werden. Anschließend generiert der Pixeldecoder Objektsegmentierungsergebnisse basierend auf diesen Token und den Bildfunktionen von CLIP-ViT. Dank dieses Designs kann PixelLM qualitativ hochwertige Segmentierungsergebnisse ohne ein externes Segmentierungsmodell generieren, was die Modelleffizienz erheblich verbessert.
Laut der Beschreibung des Forschers können die Token im Seg-Codebuch in L Gruppen unterteilt werden, jede Gruppe enthält N Token und jede Gruppe entspricht einer Skala aus den visuellen Funktionen von CLIP-ViT.
Für das Eingabebild extrahiert PixelLM Merkmale im L-Maßstab aus den vom visuellen CLIP-ViT-Encoder erzeugten Bildmerkmalen. Die letzte Ebene deckt die globalen Bildinformationen ab und wird von LLM verwendet, um den Bildinhalt zu verstehen.
Die Token des Seg-Codebuchs werden zusammen mit den Textanweisungen und der letzten Ebene der Bildfunktionen in das LLM eingegeben, um eine Ausgabe in Form einer Autoregression zu erzeugen. Die Ausgabe umfasst auch die von LLM verarbeiteten Seg-Codebuch-Token, die zusammen mit den CLIP-ViT-Funktionen im L-Maßstab in den Pixeldecoder eingegeben werden, um das endgültige Segmentierungsergebnis zu erzeugen.
 Bilder
Bilder
 Bilder
Bilder
Warum müssen wir also jede Gruppe so einstellen, dass sie N Token enthält? Die Forscher erklärten in Verbindung mit der folgenden Abbildung:
In Szenarien mit mehreren Zielen oder wenn die in den Zielen enthaltene Semantik sehr komplex ist, kann LLM zwar eine detaillierte Textantwort bereitstellen, die Verwendung nur eines einzigen Tokens kann jedoch möglicherweise nicht die gesamte Zielsemantik vollständig erfassen Inhalt.
Um die Fähigkeit des Modells in komplexen Argumentationsszenarien zu verbessern, führten die Forscher mehrere Token innerhalb jeder Skalengruppe ein und führten eine lineare Fusionsoperation eines Tokens durch. Bevor der Token an den Decoder übergeben wird, wird eine lineare Projektionsschicht verwendet, um die Token innerhalb jeder Gruppe zusammenzuführen.
Das Bild unten zeigt den Effekt, wenn in jeder Gruppe mehrere Token vorhanden sind. Die Aufmerksamkeitskarte zeigt, wie jedes Token aussieht, nachdem es vom Decoder verarbeitet wurde. Diese Visualisierung zeigt, dass mehrere Token einzigartige und komplementäre Informationen liefern, was zu einer effektiveren Segmentierungsausgabe führt.
 Bilder
Bilder
Um die Fähigkeit des Modells zur Unterscheidung mehrerer Ziele zu verbessern, hat PixelLM außerdem einen zusätzlichen Zielverfeinerungsverlust entwickelt.
MUSE-Datensatz
Obwohl die oben genannten Lösungen vorgeschlagen wurden, benötigt das Modell dennoch geeignete Trainingsdaten, um die Fähigkeiten des Modells vollständig auszunutzen. Bei der Durchsicht derzeit verfügbarer öffentlicher Datensätze stellen wir fest, dass die vorhandenen Daten die folgenden wesentlichen Einschränkungen aufweisen:
1) Unzureichende Beschreibung von Objektdetails
2) Fehlen von Frage-Antwort-Paaren mit komplexer Begründung und unterschiedlichen Zielzahlen.
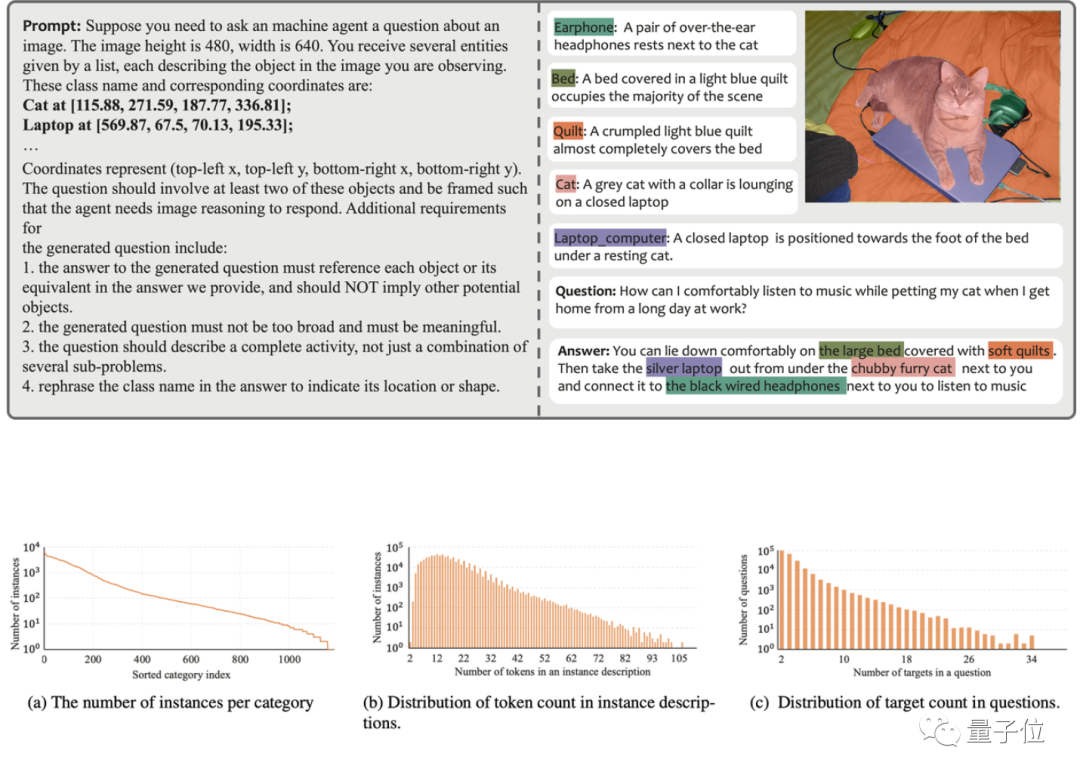
Um diese Probleme zu lösen, nutzte das Forschungsteam GPT-4V zum Aufbau einer automatisierten Datenannotationspipeline und generierte so den MUSE-Datensatz. Die folgende Abbildung zeigt ein Beispiel der Eingabeaufforderungen, die beim Generieren von MUSE verwendet werden, und der generierten Daten.
 Bilder
Bilder
In MUSE stammen alle Instanzmasken aus dem LVIS-Datensatz und zusätzlich werden detaillierte Textbeschreibungen hinzugefügt, die auf Basis des Bildinhalts generiert werden. MUSE enthält 246.000 Frage-Antwort-Paare, und jedes Frage-Antwort-Paar umfasst durchschnittlich 3,7 Zielobjekte. Darüber hinaus führte das Forschungsteam eine umfassende statistische Analyse des Datensatzes durch:
Kategoriestatistik: Es gibt mehr als 1000 Kategorien in MUSE aus dem ursprünglichen LVIS-Datensatz, und 900.000 Instanzen mit eindeutigen Beschreibungen basierend auf Frage-Antwort-Paaren variieren je nach Kontext. Abbildung (a) zeigt die Anzahl der Instanzen jeder Kategorie über alle Frage-Antwort-Paare hinweg.
Statistik der Token-Anzahl: Abbildung (b) zeigt die Verteilung der Anzahl der in den Beispielen beschriebenen Token, von denen einige mehr als 100 Token enthalten. Diese Beschreibungen beschränken sich nicht auf einfache Kategorienamen, sondern werden durch einen GPT-4V-basierten Datengenerierungsprozess mit detaillierten Informationen zu jeder Instanz angereichert, einschließlich Aussehen, Eigenschaften und Beziehungen zu anderen Objekten. Die Tiefe und Vielfalt der Informationen im Datensatz verbessert die Generalisierungsfähigkeit des trainierten Modells und ermöglicht es ihm, offene Domänenprobleme effektiv zu lösen.
Zielanzahlstatistik: Abbildung (c) zeigt die Statistik der Anzahl der Ziele für jedes Frage-Antwort-Paar. Die durchschnittliche Anzahl der Ziele beträgt 3,7 und die maximale Anzahl der Ziele kann 34 erreichen. Diese Zahl kann die meisten Zielinferenzszenarien für ein einzelnes Bild abdecken.
Algorithmusbewertung
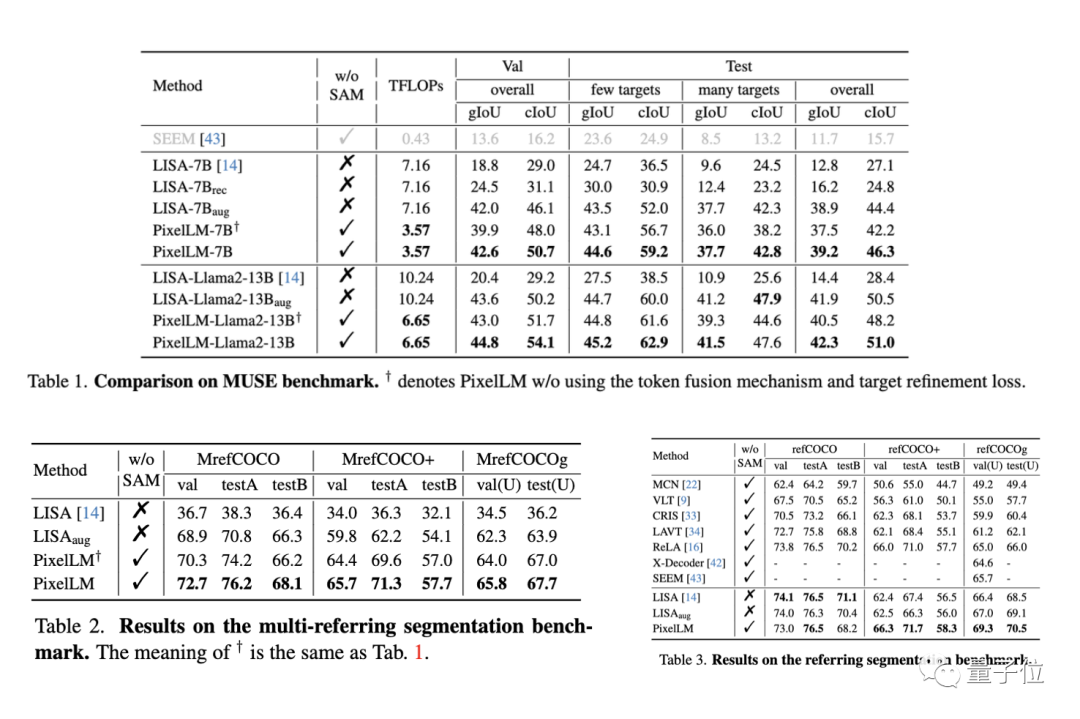
Das Forschungsteam bewertete die Leistung von PixelLM anhand von drei Benchmarks, darunter dem MUSE-Benchmark, dem Referenzsegmentierungs-Benchmark und dem Multi-Referring-Segmentierungs-Benchmark. Im Multi-Referring-Segmentierungs-Benchmark verlangt das Forschungsteam, dass das Modell vorhanden ist Ein Problem: Segmentieren Sie kontinuierlich mehrere in jedem Bild enthaltene Objekte im Referenzsegmentierungs-Benchmark.
Da PixelLM das erste Modell ist, das komplexe Pixel-Argumentation-Aufgaben mit mehreren Zielen bewältigen kann, hat das Forschungsteam gleichzeitig vier Basislinien zur Durchführung einer vergleichenden Analyse der Modelle festgelegt.
Drei der Basislinien basieren auf LISA, der relevantesten Arbeit auf PixelLM, darunter:
1) Original-LISA;
2) LISA_rec: Geben Sie zuerst die Frage in LLAVA-13B ein, um die Textantwort des Ziels zu erhalten, und dann Verwenden Sie LISA, um den Text zu segmentieren ;
3) LISA_aug: Fügen Sie MUSE direkt zu den Trainingsdaten von LISA hinzu.
4) Das andere ist SEEM, ein allgemeines Segmentierungsmodell, das kein LLM verwendet.
 Bilder
Bilder
Bei den meisten Indikatoren der drei Benchmarks ist die Leistung von PixelLM besser als bei anderen Methoden, und da PixelLM nicht auf SAM angewiesen ist, sind seine TFLOPs weitaus niedriger als bei Modellen gleicher Größe.
Interessierte Freunde können zuerst aufpassen und warten, bis der Code Open Source ist~
Referenzlink:
[1]https://www.php.cn/link/9271858951e6fe9504d1f05ae8576001
[2]https:/ /www.php.cn/link/f1686b4badcf28d33ed632036c7ab0b8
Das obige ist der detaillierte Inhalt vonPixelLM, ein multimodales Byte-Großmodell, das das Denken auf Pixelebene ohne SA-Abhängigkeit effizient implementiert. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 Keine OpenAI-Daten erforderlich, schließen Sie sich der Liste der großen Codemodelle an! UIUC veröffentlicht StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Keine OpenAI-Daten erforderlich, schließen Sie sich der Liste der großen Codemodelle an! UIUC veröffentlicht StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
An der Spitze der Softwaretechnologie kündigte die Gruppe von UIUC Zhang Lingming zusammen mit Forschern der BigCode-Organisation kürzlich das StarCoder2-15B-Instruct-Großcodemodell an. Diese innovative Errungenschaft erzielte einen bedeutenden Durchbruch bei Codegenerierungsaufgaben, übertraf erfolgreich CodeLlama-70B-Instruct und erreichte die Spitze der Codegenerierungsleistungsliste. Die Einzigartigkeit von StarCoder2-15B-Instruct liegt in seiner reinen Selbstausrichtungsstrategie. Der gesamte Trainingsprozess ist offen, transparent und völlig autonom und kontrollierbar. Das Modell generiert über StarCoder2-15B Tausende von Anweisungen als Reaktion auf die Feinabstimmung des StarCoder-15B-Basismodells, ohne auf teure manuelle Annotationen angewiesen zu sein.
 Übertrifft DPO umfassend: Das Team von Chen Danqi schlug eine einfache Präferenzoptimierung (SimPO) vor und verfeinerte außerdem das stärkste 8B-Open-Source-Modell
Jun 01, 2024 pm 04:41 PM
Übertrifft DPO umfassend: Das Team von Chen Danqi schlug eine einfache Präferenzoptimierung (SimPO) vor und verfeinerte außerdem das stärkste 8B-Open-Source-Modell
Jun 01, 2024 pm 04:41 PM
Um große Sprachmodelle (LLMs) an menschlichen Werten und Absichten auszurichten, ist es wichtig, menschliches Feedback zu lernen, um sicherzustellen, dass sie nützlich, ehrlich und harmlos sind. Im Hinblick auf die Ausrichtung von LLM ist Reinforcement Learning basierend auf menschlichem Feedback (RLHF) eine wirksame Methode. Obwohl die Ergebnisse der RLHF-Methode ausgezeichnet sind, gibt es einige Herausforderungen bei der Optimierung. Dazu gehört das Training eines Belohnungsmodells und die anschließende Optimierung eines Richtlinienmodells, um diese Belohnung zu maximieren. Kürzlich haben einige Forscher einfachere Offline-Algorithmen untersucht, darunter die direkte Präferenzoptimierung (Direct Preference Optimization, DPO). DPO lernt das Richtlinienmodell direkt auf der Grundlage von Präferenzdaten, indem es die Belohnungsfunktion in RLHF parametrisiert, wodurch die Notwendigkeit eines expliziten Belohnungsmodells entfällt. Diese Methode ist einfach und stabil
 Yolov10: Ausführliche Erklärung, Bereitstellung und Anwendung an einem Ort!
Jun 07, 2024 pm 12:05 PM
Yolov10: Ausführliche Erklärung, Bereitstellung und Anwendung an einem Ort!
Jun 07, 2024 pm 12:05 PM
1. Einleitung In den letzten Jahren haben sich YOLOs aufgrund ihres effektiven Gleichgewichts zwischen Rechenkosten und Erkennungsleistung zum vorherrschenden Paradigma im Bereich der Echtzeit-Objekterkennung entwickelt. Forscher haben das Architekturdesign, die Optimierungsziele, Datenerweiterungsstrategien usw. von YOLO untersucht und erhebliche Fortschritte erzielt. Gleichzeitig behindert die Verwendung von Non-Maximum Suppression (NMS) bei der Nachbearbeitung die End-to-End-Bereitstellung von YOLO und wirkt sich negativ auf die Inferenzlatenz aus. In YOLOs fehlt dem Design verschiedener Komponenten eine umfassende und gründliche Prüfung, was zu erheblicher Rechenredundanz führt und die Fähigkeiten des Modells einschränkt. Es bietet eine suboptimale Effizienz und ein relativ großes Potenzial zur Leistungsverbesserung. Ziel dieser Arbeit ist es, die Leistungseffizienzgrenze von YOLO sowohl in der Nachbearbeitung als auch in der Modellarchitektur weiter zu verbessern. zu diesem Zweck
 Leistungsvergleich verschiedener Java-Frameworks
Jun 05, 2024 pm 07:14 PM
Leistungsvergleich verschiedener Java-Frameworks
Jun 05, 2024 pm 07:14 PM
Leistungsvergleich verschiedener Java-Frameworks: REST-API-Anforderungsverarbeitung: Vert.x ist am besten, mit einer Anforderungsrate von 2-mal SpringBoot und 3-mal Dropwizard. Datenbankabfrage: HibernateORM von SpringBoot ist besser als ORM von Vert.x und Dropwizard. Caching-Vorgänge: Der Hazelcast-Client von Vert.x ist den Caching-Mechanismen von SpringBoot und Dropwizard überlegen. Geeignetes Framework: Wählen Sie entsprechend den Anwendungsanforderungen. Vert.x eignet sich für leistungsstarke Webdienste, SpringBoot eignet sich für datenintensive Anwendungen und Dropwizard eignet sich für Microservice-Architekturen.
 LLM ist fertig! OmniDrive: Integration von 3D-Wahrnehmung und Argumentationsplanung (NVIDIAs neueste Version)
May 09, 2024 pm 04:55 PM
LLM ist fertig! OmniDrive: Integration von 3D-Wahrnehmung und Argumentationsplanung (NVIDIAs neueste Version)
May 09, 2024 pm 04:55 PM
Oben geschrieben und persönliches Verständnis des Autors: Dieses Papier widmet sich der Lösung der wichtigsten Herausforderungen aktueller multimodaler großer Sprachmodelle (MLLMs) in autonomen Fahranwendungen, nämlich dem Problem der Erweiterung von MLLMs vom 2D-Verständnis auf den 3D-Raum. Diese Erweiterung ist besonders wichtig, da autonome Fahrzeuge (AVs) genaue Entscheidungen über 3D-Umgebungen treffen müssen. Das räumliche 3D-Verständnis ist für AVs von entscheidender Bedeutung, da es sich direkt auf die Fähigkeit des Fahrzeugs auswirkt, fundierte Entscheidungen zu treffen, zukünftige Zustände vorherzusagen und sicher mit der Umgebung zu interagieren. Aktuelle multimodale große Sprachmodelle (wie LLaVA-1.5) können häufig nur Bildeingaben mit niedrigerer Auflösung verarbeiten (z. B. aufgrund von Auflösungsbeschränkungen des visuellen Encoders und Einschränkungen der LLM-Sequenzlänge). Allerdings erfordern autonome Fahranwendungen
