

Welche Rolle spielt die Kafka-Verbrauchergruppe?

Die Funktionen der Kafka-Verbrauchergruppe: 2. Fehlertoleranz; 5. Skalierbarkeit; 8. Transaktionsunterstützung; Detaillierte Einführung: 1. Lastausgleich: Die Verbrauchergruppe kann den Nachrichtenlastausgleich auf jeden Verbraucher in der Gruppe verteilen, sodass jeder Verbraucher die gleiche Last bewältigen kann, wodurch die Clusterressourcen vollständig genutzt und die Gesamtverarbeitungseffizienz verbessert werden Toleranz. Innerhalb einer Verbrauchergruppe konsumiert jeder Verbraucher unabhängig Nachrichten, die dieser Verbrauchergruppe zugewiesen sind. Warten Sie während des Verzehrvorgangs.

Das Betriebssystem dieses Tutorials: Windows 10-System, DELL G3-Computer.
Die Kafka-Verbrauchergruppe ist ein wichtiger Mechanismus für die Nachrichtenverteilung und den Lastausgleich in Kafka. Sie hat die folgenden Funktionen:
1. Die Verbrauchergruppe kann den Nachrichtenlastausgleich auf jeden Verbraucher in der Gruppe verteilen Dadurch kann der Verbraucher die gleiche Lastmenge bewältigen, wodurch die Clusterressourcen voll ausgenutzt und die Gesamtverarbeitungseffizienz verbessert wird. Durch die Organisation von Verbrauchern in Gruppen kann ein dynamischer Lastausgleich erreicht werden, indem die Menge der jedem Verbraucher zugewiesenen Nachrichten basierend auf der Verarbeitungsleistung des Verbrauchers angepasst wird.
2. Fehlertoleranz: In einer Verbrauchergruppe konsumiert jeder Verbraucher unabhängig die der Verbrauchergruppe zugewiesenen Nachrichten. Während des Konsumprozesses stören sich die Verbraucher nicht gegenseitig, konsumieren dieselbe Nachricht nicht wiederholt und verpassen keine Nachricht. Dieser Mechanismus stellt die Zuverlässigkeit und Konsistenz der Nachrichtenverarbeitung sicher. Wenn ein Verbraucher ausfällt, können andere Verbraucher weiterhin Nachrichten verarbeiten und so die Fehlertoleranz des Systems gewährleisten.
3. Flexibilität: Verbrauchergruppen sorgen für flexible Konsummuster. Durch Anpassen der Konfiguration der Verbrauchergruppe können verschiedene Verbrauchsmodi implementiert werden, z. B. der Publish-Subscribe-Modus und der Warteschlangenmodus. Im Publish-Subscribe-Modus kann eine Nachricht von mehreren Verbrauchern gleichzeitig konsumiert werden; im Warteschlangenmodus kann eine Nachricht nur von einem Verbraucher konsumiert werden. Diese Flexibilität ermöglicht es Kafka, sich an unterschiedliche Geschäftsanforderungen und Datenverarbeitungsszenarien anzupassen.
4. Hohe Verfügbarkeit: In Kafka verfügt jede Partition über mehrere Kopien, die auf verschiedene Broker verteilt sind. Wenn ein Broker ausfällt, kann die Verbrauchergruppe automatisch Nachrichten von anderen Replikaten erkennen und weiterhin konsumieren, um so die Systemverfügbarkeit sicherzustellen. Gleichzeitig bietet Kafka auch automatische Failover- und Leader-Wahlmechanismen, um die Stabilität und Verfügbarkeit des Systems bei einem Ausfall sicherzustellen.
5. Skalierbarkeit: Mit zunehmender Unternehmensgröße können Mitglieder der Verbrauchergruppe dynamisch hinzugefügt oder reduziert werden. Neu beitretende Verbraucher beziehen automatisch Daten aus vorhandenen Kopien und beginnen mit dem Konsum; austretende Verbraucher spüren dies automatisch und hören mit dem Konsum auf. Diese dynamische Skalierbarkeit ermöglicht es Kafka, die Verarbeitungskapazitäten flexibel zu erweitern, wenn sich das Unternehmen entwickelt.
6. Reihenfolgegarantie: Innerhalb einer einzelnen Verbrauchergruppe basiert die Verbrauchsreihenfolge der Nachrichten auf der Reihenfolge der Nachrichten in der Partition. Dadurch kann Kafka die Reihenfolge der Nachrichten innerhalb einer einzelnen Verbrauchergruppe garantieren. Wenn eine globale Reihenfolge erforderlich ist, können alle zugehörigen Nachrichten an dieselbe Partition gesendet und von einem einzelnen Verbraucher verarbeitet werden.
7. Datenkomprimierung: Kafka unterstützt die Nachrichtenkomprimierungsfunktion, die den für die Speicherung erforderlichen Speicherplatz reduzieren kann, wenn der Speicherplatz begrenzt ist. Durch die Komprimierung mehrerer aufeinanderfolgender Nachrichten und deren Schreiben in nur einem Festplatten-E/A-Vorgang können Durchsatz und Effizienz erheblich verbessert werden.
8. Transaktionsunterstützung: Kafka unterstützt die Verarbeitung von Transaktionsnachrichten, wodurch die Atomizität und Konsistenz der Vorgänge beim Schreiben und Lesen von Nachrichten sichergestellt werden kann. Dies trägt dazu bei, eine zuverlässige Datenübertragung und einen konsistenten Datenstatus in verteilten Systemen zu erreichen.
Zusammenfassend lässt sich sagen, dass Kafka-Verbrauchergruppen eine wichtige Rolle bei der Lastverteilung, Fehlertoleranz, Flexibilität, Hochverfügbarkeit, Skalierbarkeit, Bestellgarantien, Datenkomprimierung und Transaktionsunterstützung spielen. Durch die ordnungsgemäße Konfiguration und Verwendung von Verbrauchergruppen können die Gesamtleistung und Zuverlässigkeit von Kafka verbessert werden, um verschiedenen Geschäftsanforderungen und Datenverarbeitungsszenarien gerecht zu werden.Das obige ist der detaillierte Inhalt vonWelche Rolle spielt die Kafka-Verbrauchergruppe?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1392
1392
 52
52

 So implementieren Sie eine Echtzeit-Aktienanalyse mit PHP und Kafka
Jun 28, 2023 am 10:04 AM
So implementieren Sie eine Echtzeit-Aktienanalyse mit PHP und Kafka
Jun 28, 2023 am 10:04 AM
Mit der Entwicklung des Internets und der Technologie sind digitale Investitionen zu einem Thema mit zunehmender Besorgnis geworden. Viele Anleger erforschen und studieren weiterhin Anlagestrategien in der Hoffnung, eine höhere Kapitalrendite zu erzielen. Im Aktienhandel ist die Aktienanalyse in Echtzeit für die Entscheidungsfindung sehr wichtig, und der Einsatz der Kafka-Echtzeit-Nachrichtenwarteschlange und der PHP-Technologie ist ein effizientes und praktisches Mittel. 1. Einführung in Kafka Kafka ist ein von LinkedIn entwickeltes verteiltes Publish- und Subscribe-Messagingsystem mit hohem Durchsatz. Die Hauptmerkmale von Kafka sind
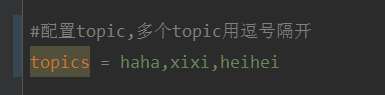 So geben Sie mit @KafkaListener in Springboot + Kafka dynamisch mehrere Themen an
May 20, 2023 pm 08:58 PM
So geben Sie mit @KafkaListener in Springboot + Kafka dynamisch mehrere Themen an
May 20, 2023 pm 08:58 PM
Erklären Sie, dass es sich bei diesem Projekt um ein Springboot+Kafak-Integrationsprojekt handelt und daher die Kafak-Verbrauchsanmerkung @KafkaListener in Springboot verwendet. Konfigurieren Sie zunächst mehrere durch Kommas getrennte Themen in application.properties. Methode: Verwenden Sie den SpEl-Ausdruck von Spring, um Themen wie folgt zu konfigurieren: @KafkaListener(topics="#{’${topics}’.split(',')}"), um das Programm auszuführen. Der Konsolendruckeffekt ist wie folgt
 Wie SpringBoot die Kafka-Konfigurationstoolklasse integriert
May 12, 2023 pm 09:58 PM
Wie SpringBoot die Kafka-Konfigurationstoolklasse integriert
May 12, 2023 pm 09:58 PM
Spring-Kafka basiert auf der Integration der Java-Version von Kafkaclient und Spring. Es bietet KafkaTemplate, das verschiedene Methoden für eine einfache Bedienung kapselt. Es kapselt den Kafka-Client von Apache und es ist nicht erforderlich, den Client zu importieren, um von der Organisation abhängig zu sein .springframework.kafkaspring-kafkaYML-Konfiguration. kafka:#bootstrap-servers:server1:9092,server2:9093#kafka-Entwicklungsadresse,#producer-Konfigurationsproduzent:#Serialisierungs- und Deserialisierungsklassenschlüssel, bereitgestellt von Kafka
 So erstellen Sie Echtzeit-Datenverarbeitungsanwendungen mit React und Apache Kafka
Sep 27, 2023 pm 02:25 PM
So erstellen Sie Echtzeit-Datenverarbeitungsanwendungen mit React und Apache Kafka
Sep 27, 2023 pm 02:25 PM
So verwenden Sie React und Apache Kafka zum Erstellen von Echtzeit-Datenverarbeitungsanwendungen. Einführung: Mit dem Aufkommen von Big Data und Echtzeit-Datenverarbeitung ist die Erstellung von Echtzeit-Datenverarbeitungsanwendungen für viele Entwickler zum Ziel geworden. Die Kombination von React, einem beliebten Front-End-Framework, und Apache Kafka, einem leistungsstarken verteilten Messaging-System, kann uns beim Aufbau von Echtzeit-Datenverarbeitungsanwendungen helfen. In diesem Artikel wird erläutert, wie Sie mit React und Apache Kafka Echtzeit-Datenverarbeitungsanwendungen erstellen
 Fünf Auswahlmöglichkeiten an Visualisierungstools zur Erkundung von Kafka
Feb 01, 2024 am 08:03 AM
Fünf Auswahlmöglichkeiten an Visualisierungstools zur Erkundung von Kafka
Feb 01, 2024 am 08:03 AM
Fünf Optionen für Kafka-Visualisierungstools ApacheKafka ist eine verteilte Stream-Verarbeitungsplattform, die große Mengen an Echtzeitdaten verarbeiten kann. Es wird häufig zum Aufbau von Echtzeit-Datenpipelines, Nachrichtenwarteschlangen und ereignisgesteuerten Anwendungen verwendet. Die Visualisierungstools von Kafka können Benutzern dabei helfen, Kafka-Cluster zu überwachen und zu verwalten und Kafka-Datenflüsse besser zu verstehen. Im Folgenden finden Sie eine Einführung in fünf beliebte Kafka-Visualisierungstools: ConfluentControlCenterConfluent
 Vergleichende Analyse der Kafka-Visualisierungstools: Wie wählt man das am besten geeignete Tool aus?
Jan 05, 2024 pm 12:15 PM
Vergleichende Analyse der Kafka-Visualisierungstools: Wie wählt man das am besten geeignete Tool aus?
Jan 05, 2024 pm 12:15 PM
Wie wählt man das richtige Kafka-Visualisierungstool aus? Vergleichende Analyse von fünf Tools Einführung: Kafka ist ein leistungsstarkes verteiltes Nachrichtenwarteschlangensystem mit hohem Durchsatz, das im Bereich Big Data weit verbreitet ist. Mit der Popularität von Kafka benötigen immer mehr Unternehmen und Entwickler ein visuelles Tool zur einfachen Überwachung und Verwaltung von Kafka-Clustern. In diesem Artikel werden fünf häufig verwendete Kafka-Visualisierungstools vorgestellt und ihre Merkmale und Funktionen verglichen, um den Lesern bei der Auswahl des Tools zu helfen, das ihren Anforderungen entspricht. 1. KafkaManager
 Beispielcode für ein Springboot-Projekt zum Konfigurieren mehrerer Kafka
May 14, 2023 pm 12:28 PM
Beispielcode für ein Springboot-Projekt zum Konfigurieren mehrerer Kafka
May 14, 2023 pm 12:28 PM
1.spring-kafkaorg.springframework.kafkaspring-kafka1.3.5.RELEASE2. Informationen zur Konfigurationsdatei kafka.bootstrap-servers=localhost:9092kafka.consumer.group.id=20230321#Die Anzahl der Threads, die gleichzeitig verwendet werden können (normalerweise konsistent). mit der Anzahl der Partitionen )kafka.consumer.concurrency=10kafka.consumer.enable.auto.commit=falsekafka.boo
 Die Praxis von Go-Zero und Kafka+Avro: Aufbau eines leistungsstarken interaktiven Datenverarbeitungssystems
Jun 23, 2023 am 09:04 AM
Die Praxis von Go-Zero und Kafka+Avro: Aufbau eines leistungsstarken interaktiven Datenverarbeitungssystems
Jun 23, 2023 am 09:04 AM
In den letzten Jahren haben mit dem Aufkommen von Big Data und aktiven Open-Source-Communities immer mehr Unternehmen begonnen, nach leistungsstarken interaktiven Datenverarbeitungssystemen zu suchen, um den wachsenden Datenanforderungen gerecht zu werden. In dieser Welle von Technologie-Upgrades werden Go-Zero und Kafka+Avro von immer mehr Unternehmen beachtet und übernommen. go-zero ist ein auf der Golang-Sprache entwickeltes Microservice-Framework. Es zeichnet sich durch hohe Leistung, Benutzerfreundlichkeit, einfache Erweiterung und einfache Wartung aus und soll Unternehmen dabei helfen, schnell effiziente Microservice-Anwendungssysteme aufzubauen. sein schnelles Wachstum
