

So lösen Sie das Problem des wiederholten Konsums in Kafka

Lösungen für das Problem des wiederholten Konsums von Kafka: 2. Verwendung der idempotenten Verarbeitung; 4. Verwendung von eindeutigen Nachrichten-IDs; 6. Optimierung der Kafka-Konfiguration; . Überwachen und alarmieren. Detaillierte Einführung: 1. Der Umgang mit Verbraucherfehlern kann dazu führen, dass verarbeitete Nachrichten erneut konsumiert werden. 2. Die idempotente Verarbeitung bezieht sich auf die Verarbeitung derselben Nachricht das Gleiche wie ein Prozess und so weiter.

Um das Problem des wiederholten Konsums von Kafka zu lösen, sind verschiedene Maßnahmen erforderlich, darunter der Umgang mit Verbraucherausfällen, die Verwendung idempotenter Verarbeitung, Nachrichtendeduplizierungstechnologie, die Verwendung eindeutiger Nachrichtenkennungen usw. Diese Maßnahmen werden im Folgenden im Detail vorgestellt:
1. Umgang mit Verbraucherausfällen
Kafka-Verbraucher können ausfallen oder abnormal beendet werden, was dazu führt, dass verarbeitete Nachrichten erneut konsumiert werden. Um diese Situation zu vermeiden, können Sie die folgenden Maßnahmen ergreifen:
Konsumenten die automatische Übermittlung von Offsets ermöglichen: Aktivieren Sie die Funktion zur automatischen Übermittlung von Offsets im Konsumentenprogramm, um sicherzustellen, dass jede erfolgreich konsumierte Nachricht korrekt an die Kafka-Mitte übermittelt wird. Dadurch wird sichergestellt, dass es selbst bei einem Ausfall des Verbrauchers nicht zu einem wiederholten Verbrauch verarbeiteter Nachrichten kommt.
Persistenten Speicher verwenden: Speichern Sie den Offset des Verbrauchers in einem persistenten Speicher, z. B. einer Datenbank oder RocksDB. Selbst wenn der Verbraucher ausfällt, kann auf diese Weise der Offset aus dem dauerhaften Speicher wiederhergestellt werden, um einen wiederholten Verbrauch zu vermeiden.
2. Idempotente Verarbeitung verwenden
Idempotente Verarbeitung bedeutet, dass dieselbe Nachricht mehrmals verarbeitet wird, und das Ergebnis ist das gleiche wie bei der einmaligen Verarbeitung. Bei Kafka-Konsumenten kann der wiederholte Konsum durch idempotente Verarbeitung von Nachrichten vermieden werden. Deduplizieren Sie beispielsweise Nachrichten während der Verarbeitung oder verwenden Sie eindeutige Kennungen, um doppelte Nachrichten zu identifizieren. Dadurch wird sichergestellt, dass selbst bei wiederholtem Konsum der Nachricht keine Nebenwirkungen auftreten.
3. Nachrichtendeduplizierungstechnologie
Die Nachrichtendeduplizierungstechnologie ist eine gängige Methode, um das Problem des wiederholten Verbrauchs zu lösen. Die Nachrichtendeduplizierung kann erreicht werden, indem eine Aufzeichnung der verarbeiteten Nachrichten innerhalb der Anwendung verwaltet wird oder indem ein externer Speicher wie eine Datenbank verwendet wird. Überprüfen Sie vor dem Verarbeiten einer Nachricht, ob die Nachricht verarbeitet wurde. Überspringen Sie die Nachricht. Dadurch kann das Problem des wiederholten Verzehrs wirksam vermieden werden.
4. Verwenden Sie eine eindeutige Nachrichtenkennung.
Fügen Sie jeder Nachricht eine eindeutige Kennung hinzu und zeichnen Sie die verarbeitete Kennung in der Anwendung auf. Überprüfen Sie vor dem Verarbeiten einer Nachricht, ob die eindeutige Kennung der Nachricht bereits im verarbeiteten Datensatz vorhanden ist, und überspringen Sie die Nachricht, falls sie vorhanden ist. Dadurch wird sichergestellt, dass eine Nachricht auch bei wiederholtem Versand anhand der eindeutigen Kennung identifiziert und verarbeitet werden kann.
5. Entwerfen Sie einen idempotenten Produzenten.
Implementieren Sie Idempotenz auf der Produktionsseite der Nachricht, um sicherzustellen, dass das wiederholte Senden derselben Nachricht nicht zu wiederholtem Konsum führt. Dies kann erreicht werden, indem jeder Nachricht eine eindeutige Kennung zugewiesen wird oder indem eine idempotente Nachrichtenstrategie verwendet wird. Dadurch wird sichergestellt, dass selbst wenn der Produzent doppelte Nachrichten sendet, es nicht zu Problemen mit dem doppelten Verbrauch kommt.
6. Optimieren Sie die Kafka-Konfiguration und die Verbraucherparameter
Durch die Optimierung der Kafka-Konfiguration und der Verbraucherparameter können die Leistung und Zuverlässigkeit von Kafka verbessert werden, wodurch das Auftreten wiederholter Verbrauchsprobleme verringert wird. Sie können beispielsweise die Anzahl der Kafka-Partitionen erhöhen und die Verbrauchsgeschwindigkeit des Verbrauchers erhöhen oder die Konfigurationsparameter des Verbrauchers anpassen, um seine Zuverlässigkeit und Stabilität zu verbessern.
7. Überwachung und Alarmierung
Durch die Überwachung der Leistungsindikatoren und des Alarmmechanismus von Kafka können wiederholte Konsumprobleme rechtzeitig erkannt und behoben werden. Sie können beispielsweise die Verbraucherverbrauchsgeschwindigkeit, die Offset-Übermittlung, die Kafka-Warteschlangengröße und andere Indikatoren überwachen und Alarmschwellenwerte basierend auf tatsächlichen Bedingungen festlegen. Bei Erreichen der Alarmschwelle kann das zuständige Personal umgehend per SMS, E-Mail usw. zur Bearbeitung benachrichtigt werden. Auf diese Weise können Probleme rechtzeitig erkannt und gelöst werden, um die Ausweitung wiederholter Verbrauchsprobleme zu vermeiden.
Zusammenfassend lässt sich sagen, dass die Lösung des Problems des wiederholten Kafka-Verbrauchs eine umfassende Betrachtung einer Vielzahl von Maßnahmen erfordert, einschließlich der Behandlung von Verbraucherausfällen, der Verwendung idempotenter Verarbeitung, der Nachrichtendeduplizierungstechnologie, der Verwendung eindeutiger Nachrichtenkennungen, der Gestaltung idempotenter Produzenten sowie der Optimierung der Kafka-Konfiguration und Verbraucherparameter B. Überwachung und Alarme usw. Es ist notwendig, die geeignete Methode zur Lösung des Problems des wiederholten Verbrauchs basierend auf der tatsächlichen Situation auszuwählen und diese kontinuierlich zu überwachen und zu optimieren, um die Gesamtleistung und Zuverlässigkeit zu verbessern.
Das obige ist der detaillierte Inhalt vonSo lösen Sie das Problem des wiederholten Konsums in Kafka. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
1205
24
52
1205
24

 So implementieren Sie eine Echtzeit-Aktienanalyse mit PHP und Kafka
Jun 28, 2023 am 10:04 AM
So implementieren Sie eine Echtzeit-Aktienanalyse mit PHP und Kafka
Jun 28, 2023 am 10:04 AM
Mit der Entwicklung des Internets und der Technologie sind digitale Investitionen zu einem Thema mit zunehmender Besorgnis geworden. Viele Anleger erforschen und studieren weiterhin Anlagestrategien in der Hoffnung, eine höhere Kapitalrendite zu erzielen. Im Aktienhandel ist die Aktienanalyse in Echtzeit für die Entscheidungsfindung sehr wichtig, und der Einsatz der Kafka-Echtzeit-Nachrichtenwarteschlange und der PHP-Technologie ist ein effizientes und praktisches Mittel. 1. Einführung in Kafka Kafka ist ein von LinkedIn entwickeltes verteiltes Publish- und Subscribe-Messagingsystem mit hohem Durchsatz. Die Hauptmerkmale von Kafka sind
 So geben Sie mit @KafkaListener in Springboot + Kafka dynamisch mehrere Themen an
May 20, 2023 pm 08:58 PM
So geben Sie mit @KafkaListener in Springboot + Kafka dynamisch mehrere Themen an
May 20, 2023 pm 08:58 PM
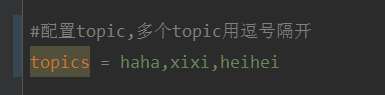
Erklären Sie, dass es sich bei diesem Projekt um ein Springboot+Kafak-Integrationsprojekt handelt und daher die Kafak-Verbrauchsanmerkung @KafkaListener in Springboot verwendet. Konfigurieren Sie zunächst mehrere durch Kommas getrennte Themen in application.properties. Methode: Verwenden Sie den SpEl-Ausdruck von Spring, um Themen wie folgt zu konfigurieren: @KafkaListener(topics="#{’${topics}’.split(',')}"), um das Programm auszuführen. Der Konsolendruckeffekt ist wie folgt
 Wie SpringBoot die Kafka-Konfigurationstoolklasse integriert
May 12, 2023 pm 09:58 PM
Wie SpringBoot die Kafka-Konfigurationstoolklasse integriert
May 12, 2023 pm 09:58 PM
Spring-Kafka basiert auf der Integration der Java-Version von Kafkaclient und Spring. Es bietet KafkaTemplate, das verschiedene Methoden für eine einfache Bedienung kapselt. Es kapselt den Kafka-Client von Apache und es ist nicht erforderlich, den Client zu importieren, um von der Organisation abhängig zu sein .springframework.kafkaspring-kafkaYML-Konfiguration. kafka:#bootstrap-servers:server1:9092,server2:9093#kafka-Entwicklungsadresse,#producer-Konfigurationsproduzent:#Serialisierungs- und Deserialisierungsklassenschlüssel, bereitgestellt von Kafka
 So erstellen Sie Echtzeit-Datenverarbeitungsanwendungen mit React und Apache Kafka
Sep 27, 2023 pm 02:25 PM
So erstellen Sie Echtzeit-Datenverarbeitungsanwendungen mit React und Apache Kafka
Sep 27, 2023 pm 02:25 PM
So verwenden Sie React und Apache Kafka zum Erstellen von Echtzeit-Datenverarbeitungsanwendungen. Einführung: Mit dem Aufkommen von Big Data und Echtzeit-Datenverarbeitung ist die Erstellung von Echtzeit-Datenverarbeitungsanwendungen für viele Entwickler zum Ziel geworden. Die Kombination von React, einem beliebten Front-End-Framework, und Apache Kafka, einem leistungsstarken verteilten Messaging-System, kann uns beim Aufbau von Echtzeit-Datenverarbeitungsanwendungen helfen. In diesem Artikel wird erläutert, wie Sie mit React und Apache Kafka Echtzeit-Datenverarbeitungsanwendungen erstellen
 Fünf Auswahlmöglichkeiten an Visualisierungstools zur Erkundung von Kafka
Feb 01, 2024 am 08:03 AM
Fünf Auswahlmöglichkeiten an Visualisierungstools zur Erkundung von Kafka
Feb 01, 2024 am 08:03 AM
Fünf Optionen für Kafka-Visualisierungstools ApacheKafka ist eine verteilte Stream-Verarbeitungsplattform, die große Mengen an Echtzeitdaten verarbeiten kann. Es wird häufig zum Aufbau von Echtzeit-Datenpipelines, Nachrichtenwarteschlangen und ereignisgesteuerten Anwendungen verwendet. Die Visualisierungstools von Kafka können Benutzern dabei helfen, Kafka-Cluster zu überwachen und zu verwalten und Kafka-Datenflüsse besser zu verstehen. Im Folgenden finden Sie eine Einführung in fünf beliebte Kafka-Visualisierungstools: ConfluentControlCenterConfluent
 Vergleichende Analyse der Kafka-Visualisierungstools: Wie wählt man das am besten geeignete Tool aus?
Jan 05, 2024 pm 12:15 PM
Vergleichende Analyse der Kafka-Visualisierungstools: Wie wählt man das am besten geeignete Tool aus?
Jan 05, 2024 pm 12:15 PM
Wie wählt man das richtige Kafka-Visualisierungstool aus? Vergleichende Analyse von fünf Tools Einführung: Kafka ist ein leistungsstarkes verteiltes Nachrichtenwarteschlangensystem mit hohem Durchsatz, das im Bereich Big Data weit verbreitet ist. Mit der Popularität von Kafka benötigen immer mehr Unternehmen und Entwickler ein visuelles Tool zur einfachen Überwachung und Verwaltung von Kafka-Clustern. In diesem Artikel werden fünf häufig verwendete Kafka-Visualisierungstools vorgestellt und ihre Merkmale und Funktionen verglichen, um den Lesern bei der Auswahl des Tools zu helfen, das ihren Anforderungen entspricht. 1. KafkaManager
 Beispielcode für ein Springboot-Projekt zum Konfigurieren mehrerer Kafka
May 14, 2023 pm 12:28 PM
Beispielcode für ein Springboot-Projekt zum Konfigurieren mehrerer Kafka
May 14, 2023 pm 12:28 PM
1.spring-kafkaorg.springframework.kafkaspring-kafka1.3.5.RELEASE2. Informationen zur Konfigurationsdatei kafka.bootstrap-servers=localhost:9092kafka.consumer.group.id=20230321#Die Anzahl der Threads, die gleichzeitig verwendet werden können (normalerweise konsistent). mit der Anzahl der Partitionen )kafka.consumer.concurrency=10kafka.consumer.enable.auto.commit=falsekafka.boo
 Die Praxis von Go-Zero und Kafka+Avro: Aufbau eines leistungsstarken interaktiven Datenverarbeitungssystems
Jun 23, 2023 am 09:04 AM
Die Praxis von Go-Zero und Kafka+Avro: Aufbau eines leistungsstarken interaktiven Datenverarbeitungssystems
Jun 23, 2023 am 09:04 AM
In den letzten Jahren haben mit dem Aufkommen von Big Data und aktiven Open-Source-Communities immer mehr Unternehmen begonnen, nach leistungsstarken interaktiven Datenverarbeitungssystemen zu suchen, um den wachsenden Datenanforderungen gerecht zu werden. In dieser Welle von Technologie-Upgrades werden Go-Zero und Kafka+Avro von immer mehr Unternehmen beachtet und übernommen. go-zero ist ein auf der Golang-Sprache entwickeltes Microservice-Framework. Es zeichnet sich durch hohe Leistung, Benutzerfreundlichkeit, einfache Erweiterung und einfache Wartung aus und soll Unternehmen dabei helfen, schnell effiziente Microservice-Anwendungssysteme aufzubauen. sein schnelles Wachstum
