
 Technologie-Peripheriegeräte
KI
Die von Huake, Ali und anderen Unternehmen gemeinsam entwickelte TF-T2V-Technologie reduziert die Kosten der KI-Videoproduktion!
Technologie-Peripheriegeräte
KI
Die von Huake, Ali und anderen Unternehmen gemeinsam entwickelte TF-T2V-Technologie reduziert die Kosten der KI-Videoproduktion!
Die von Huake, Ali und anderen Unternehmen gemeinsam entwickelte TF-T2V-Technologie reduziert die Kosten der KI-Videoproduktion!

In den letzten zwei Jahren ist mit der Öffnung großer Bild- und Textdatensätze wie LAION-5B eine Reihe von Methoden mit erstaunlichen Effekten im Bereich der Bilderzeugung entstanden, wie beispielsweise Stable Diffusion, DALL-E 2, ControlNet und Composer. Das Aufkommen dieser Methoden hat zu großen Durchbrüchen und Fortschritten auf dem Gebiet der Bilderzeugung geführt. Der Bereich der Bilderzeugung hat sich in den letzten zwei Jahren rasant entwickelt.
Allerdings steht die Videogenerierung immer noch vor großen Herausforderungen. Erstens muss die Videogenerierung im Vergleich zur Bildgenerierung höherdimensionale Daten verarbeiten und die zusätzliche Zeitdimension berücksichtigen, was das Problem der Zeitmodellierung mit sich bringt. Um das Lernen der zeitlichen Dynamik voranzutreiben, benötigen wir mehr Video-Text-Paardaten. Allerdings ist die genaue zeitliche Annotation von Videos sehr kostspielig, was die Größe von Videotext-Datensätzen begrenzt. Derzeit enthält der vorhandene WebVid10M-Videodatensatz nur 10,7 Millionen Videotextpaare. Im Vergleich zum LAION-5B-Bilddatensatz ist die Datengröße deutlich unterschiedlich. Dies schränkt die Möglichkeit einer groß angelegten Erweiterung von Videogenerierungsmodellen erheblich ein.
Um die oben genannten Probleme zu lösen, hat das gemeinsame Forschungsteam der Huazhong University of Science and Technology, der Alibaba Group, der Zhejiang University und der Ant Group kürzlich die TF-T2V-Videolösung veröffentlicht:

Paper Adresse: https://arxiv.org/abs/2312.15770
Projekthomepage: https://tf-t2v.github.io/
Quellcode wird bald veröffentlicht: https://github.com /ali-vilab/i2vgen -xl (VGen-Projekt).
Diese Lösung verfolgt einen neuen Ansatz und schlägt die Videogenerierung auf der Grundlage umfangreicher, textfreier, kommentierter Videodaten vor, die eine reichhaltige Bewegungsdynamik erlernen können.
Werfen wir zunächst einen Blick auf den Videogenerierungseffekt von TF-T2V:
Vincent-Videoaufgabe
Prompte Worte: Erzeugen Sie ein Video einer großen frostähnlichen Kreatur im Schnee. überdachtes Land.

Eingabewort: Erstellen Sie ein animiertes Video einer Cartoon-Biene.

Promptwort: Erstelle ein Video mit einem futuristischen Fantasy-Motorrad.

Promptwort: Erstellen Sie ein Video von einem kleinen Jungen, der glücklich lächelt.

Promptwort: Erstellen Sie ein Video von einem alten Mann, der Kopfschmerzen hat.

Kombinierte Videogenerierungsaufgabe
Mit Text und Tiefenkarte oder Text und Skizzenskizze ist TF-T2V in der Lage, steuerbare Videos zu generieren:
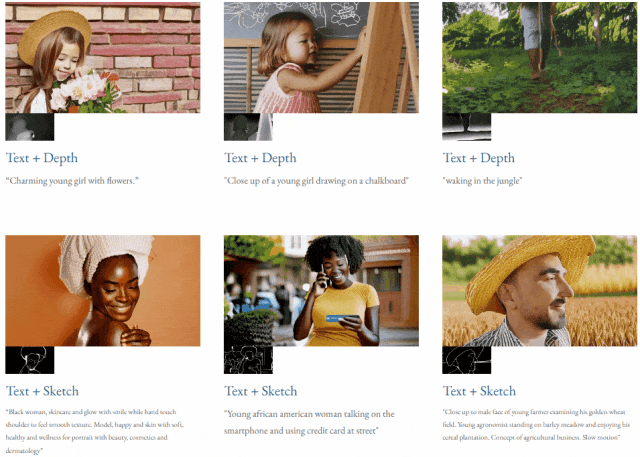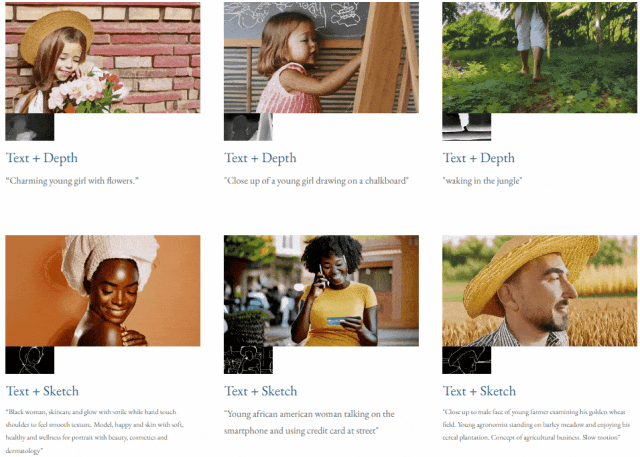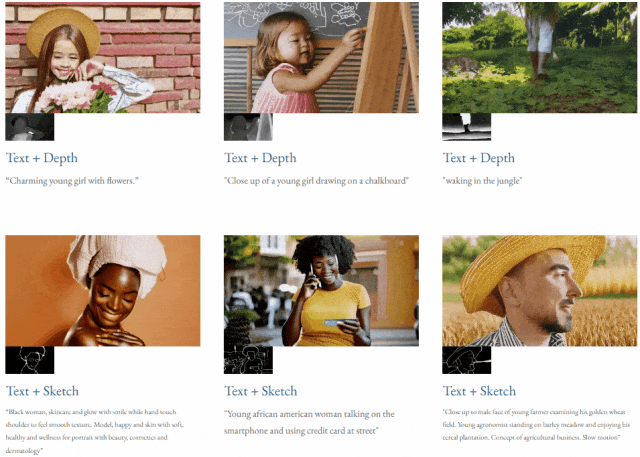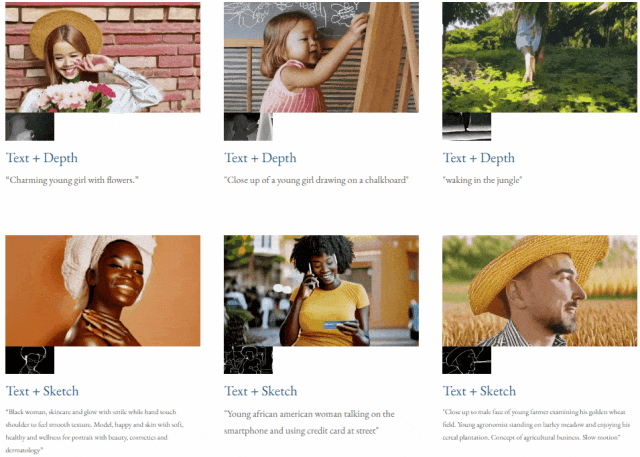
Auch verfügbar Auflösung der Videosynthese:
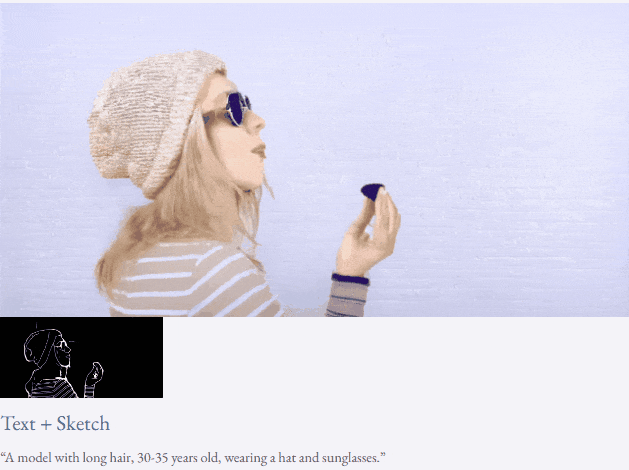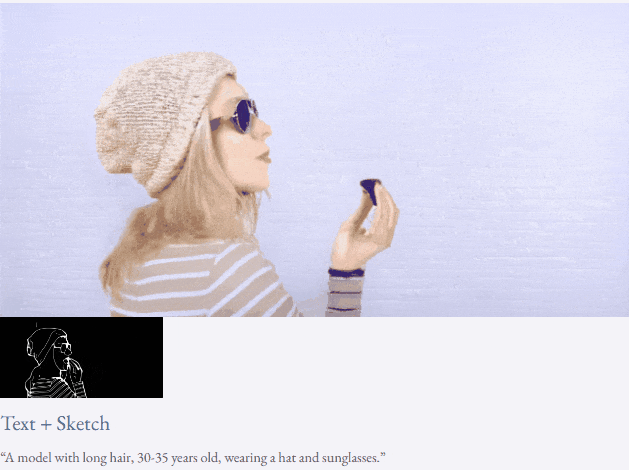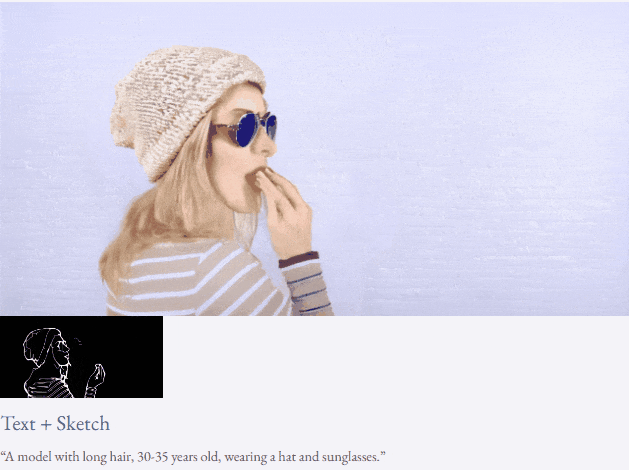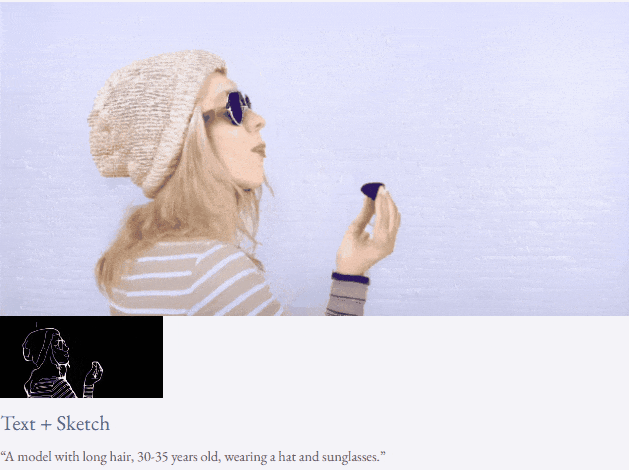
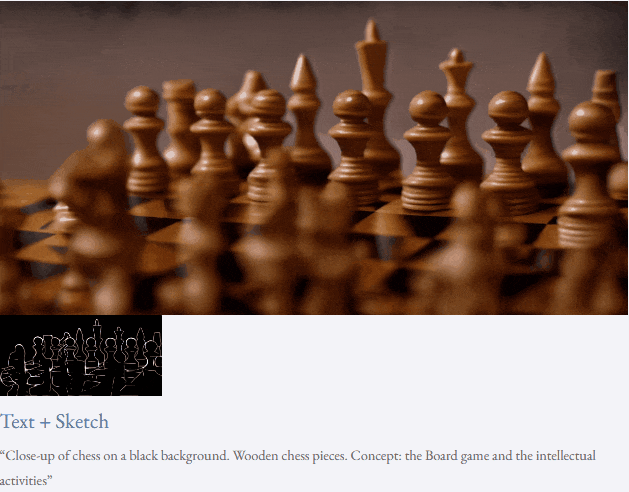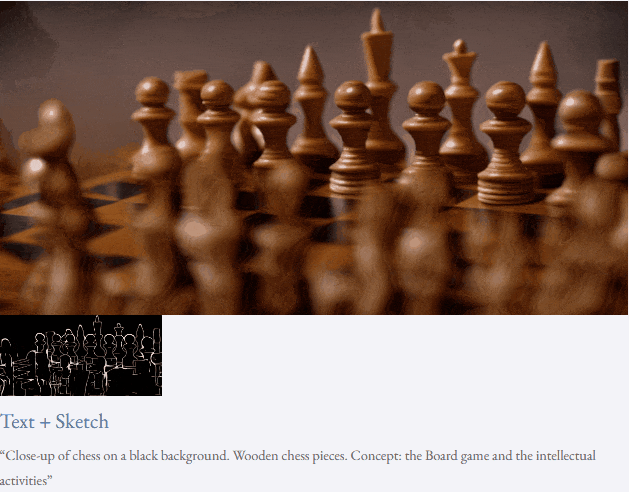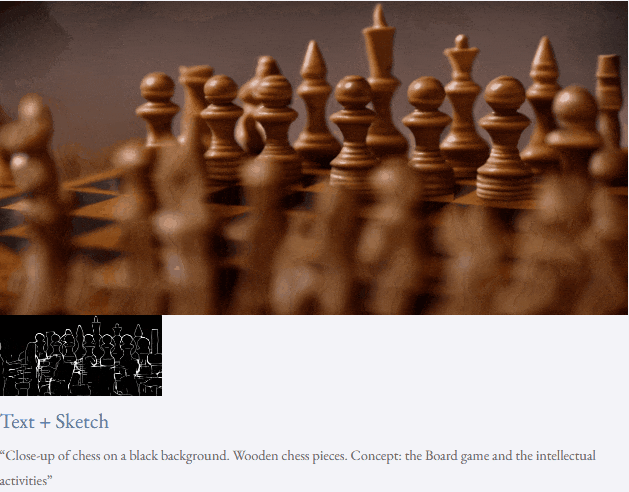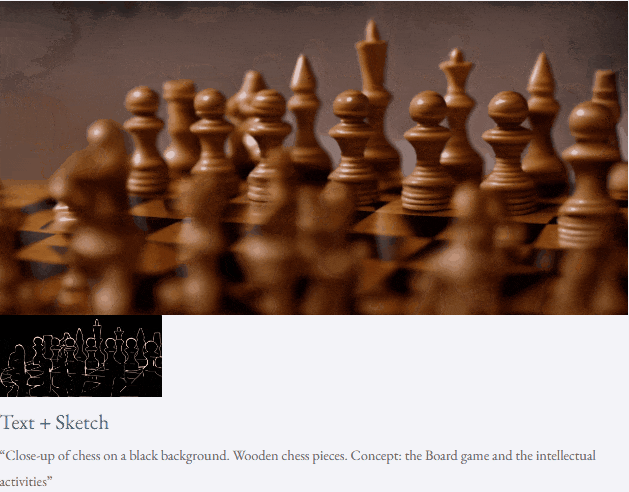
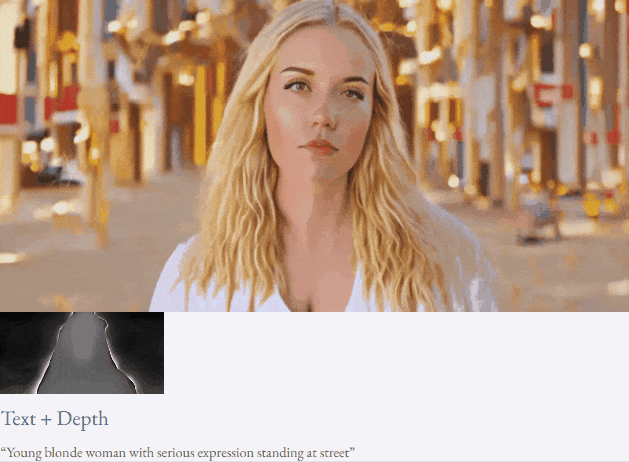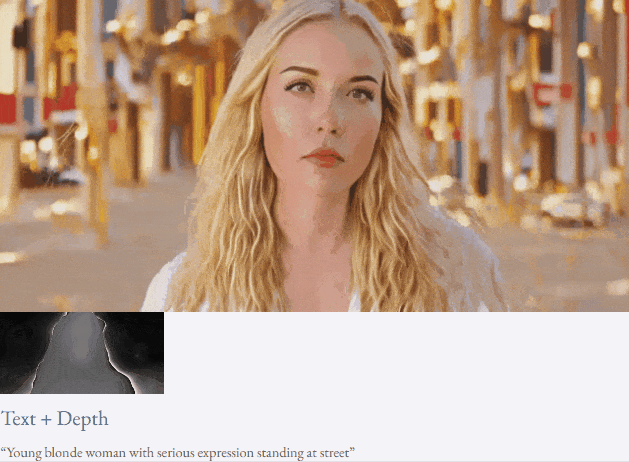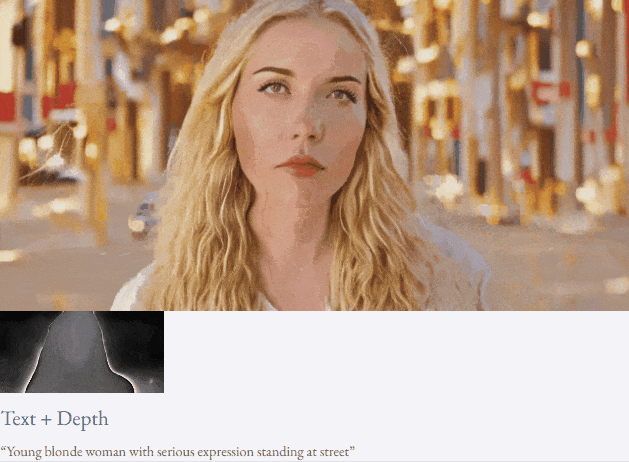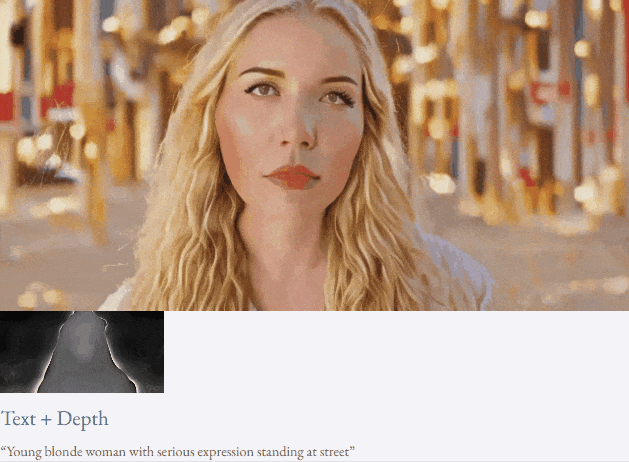
Halbüberwachte Einstellung
Mit der TF-T2V-Methode können in der halbüberwachten Einstellung auch Videos generiert werden, die der Textbeschreibung der Bewegung entsprechen, z. B. „Menschen laufen von rechts nach links.“


Einführung in die Methode
Die Kernidee von TF-T2V besteht darin, das Modell in einen Bewegungszweig und einen Erscheinungszweig zu unterteilen. Der Bewegungszweig wird zur Modellierung der Bewegungsdynamik verwendet Der Erscheinungszweig wird zum Erlernen scheinbarer Informationen verwendet. Diese beiden Zweige werden gemeinsam trainiert und können schließlich eine textgesteuerte Videogenerierung erreichen.
Um die zeitliche Konsistenz generierter Videos zu verbessern, schlug das Autorenteam außerdem einen zeitlichen Konsistenzverlust vor, um die Kontinuität zwischen Videobildern explizit zu lernen.
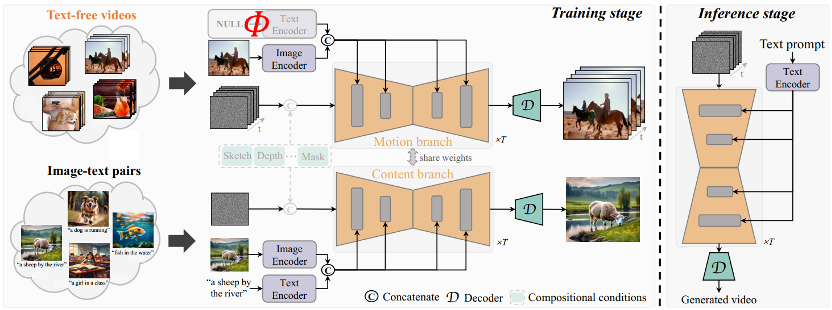
Es ist erwähnenswert, dass TF-T2V ein allgemeines Framework ist, das nicht nur für Vincent-Videoaufgaben, sondern auch für kombinierte Videogenerierungsaufgaben wie Sketch-to-Video, Video-Inpainting und erstes Bild geeignet ist -zu-Video usw.
Spezifische Details und weitere experimentelle Ergebnisse finden Sie im Originalpapier oder auf der Projekthomepage.
Darüber hinaus verwendete das Autorenteam auch TF-T2V als Lehrermodell und verwendete eine konsistente Destillationstechnologie, um das VideoLCM-Modell zu erhalten:

Papieradresse: https://arxiv.org/abs/ 2312.09109
Projekthomepage: https://tf-t2v.github.io/
Quellcode wird bald veröffentlicht: https://github.com/ali-vilab/i2vgen-xl (VGen-Projekt) .
Im Gegensatz zur vorherigen Videogenerierungsmethode, die etwa 50 DDIM-Entrauschungsschritte erforderte, kann die auf TF-T2V basierende VideoLCM-Methode High-Fidelity-Videos mit nur etwa 4 Inferenzentrauschungsschritten erzeugen, was die Effizienz der Videogenerierung erheblich verbessert. Effizienz.
Werfen wir einen Blick auf die Ergebnisse der 4-stufigen Rauschunterdrückungsinferenz von VideoLCM:

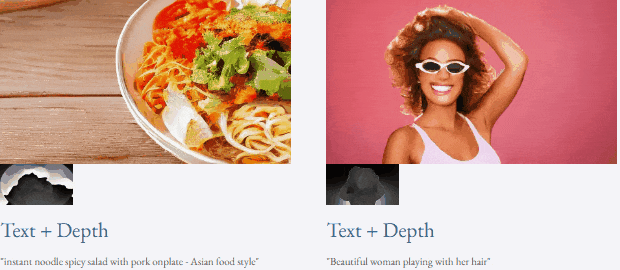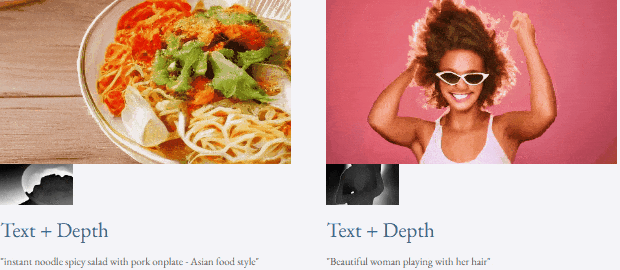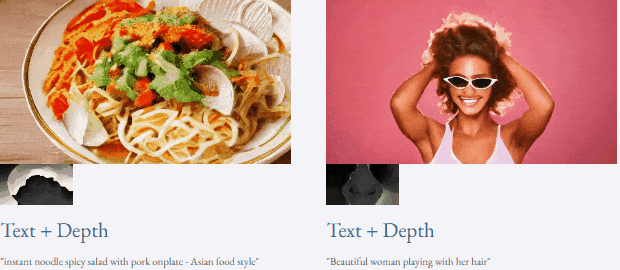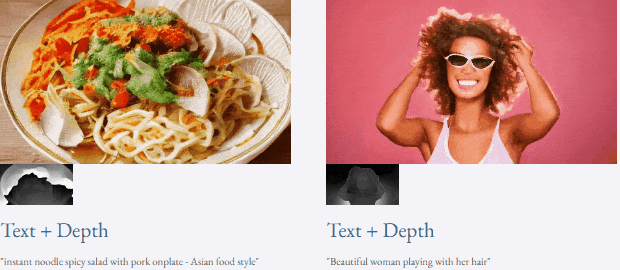

Für spezifische Details und weitere experimentelle Ergebnisse lesen Sie bitte das Originalpapier von VideoLCM oder das Projekt Startseite.
Alles in allem bringt die TF-T2V-Lösung neue Ideen in den Bereich der Videogenerierung und überwindet die Herausforderungen, die durch Probleme mit der Datensatzgröße und der Kennzeichnung entstehen. TF-T2V nutzt große, textfreie Anmerkungsvideodaten und ist in der Lage, qualitativ hochwertige Videos zu generieren, und kann für eine Vielzahl von Videogenerierungsaufgaben eingesetzt werden. Diese Innovation wird die Entwicklung der Videoerzeugungstechnologie vorantreiben und umfassendere Anwendungsszenarien und Geschäftsmöglichkeiten für alle Lebensbereiche eröffnen.
Das obige ist der detaillierte Inhalt vonDie von Huake, Ali und anderen Unternehmen gemeinsam entwickelte TF-T2V-Technologie reduziert die Kosten der KI-Videoproduktion!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1386
1386
 52
52

 Ist es ein Verstoß, die Videos anderer Leute auf Douyin zu posten? Wie werden Videos ohne Rechtsverletzung bearbeitet?
Mar 21, 2024 pm 05:57 PM
Ist es ein Verstoß, die Videos anderer Leute auf Douyin zu posten? Wie werden Videos ohne Rechtsverletzung bearbeitet?
Mar 21, 2024 pm 05:57 PM
Mit dem Aufkommen von Kurzvideoplattformen ist Douyin zu einem unverzichtbaren Bestandteil des täglichen Lebens eines jeden geworden. Auf TikTok können wir interessante Videos aus aller Welt sehen. Manche Leute posten gerne die Videos anderer Leute, was die Frage aufwirft: Verstößt Douyin gegen das Posten der Videos anderer Leute? In diesem Artikel wird dieses Problem erörtert und Ihnen erklärt, wie Sie Videos ohne Rechtsverletzung bearbeiten und Probleme mit Rechtsverletzungen vermeiden können. 1. Verstößt es gegen Douyins Veröffentlichung von Videos anderer Personen? Gemäß den Bestimmungen des Urheberrechtsgesetzes meines Landes stellt die unbefugte Nutzung der Werke des Urheberrechtsinhabers ohne die Erlaubnis des Urheberrechtsinhabers einen Verstoß dar. Daher stellt das Posten von Videos anderer Personen auf Douyin ohne die Erlaubnis des ursprünglichen Autors oder Urheberrechtsinhabers einen Verstoß dar. 2. Wie bearbeite ich ein Video ohne Urheberrechtsverletzung? 1. Verwendung von gemeinfreien oder lizenzierten Inhalten: Öffentlich
 Verwenden Sie ddrescue, um Daten unter Linux wiederherzustellen
Mar 20, 2024 pm 01:37 PM
Verwenden Sie ddrescue, um Daten unter Linux wiederherzustellen
Mar 20, 2024 pm 01:37 PM
DDREASE ist ein Tool zum Wiederherstellen von Daten von Datei- oder Blockgeräten wie Festplatten, SSDs, RAM-Disks, CDs, DVDs und USB-Speichergeräten. Es kopiert Daten von einem Blockgerät auf ein anderes, wobei beschädigte Blöcke zurückbleiben und nur gute Blöcke verschoben werden. ddreasue ist ein leistungsstarkes Wiederherstellungstool, das vollständig automatisiert ist, da es während der Wiederherstellungsvorgänge keine Unterbrechungen erfordert. Darüber hinaus kann es dank der ddasue-Map-Datei jederzeit gestoppt und fortgesetzt werden. Weitere wichtige Funktionen von DDREASE sind: Es überschreibt die wiederhergestellten Daten nicht, füllt aber die Lücken im Falle einer iterativen Wiederherstellung. Es kann jedoch gekürzt werden, wenn das Tool explizit dazu aufgefordert wird. Stellen Sie Daten aus mehreren Dateien oder Blöcken in einer einzigen wieder her
 Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
0.Was bewirkt dieser Artikel? Wir schlagen DepthFM vor: ein vielseitiges und schnelles generatives monokulares Tiefenschätzungsmodell auf dem neuesten Stand der Technik. Zusätzlich zu herkömmlichen Tiefenschätzungsaufgaben demonstriert DepthFM auch hochmoderne Fähigkeiten bei nachgelagerten Aufgaben wie dem Tiefen-Inpainting. DepthFM ist effizient und kann Tiefenkarten innerhalb weniger Inferenzschritte synthetisieren. Lassen Sie uns diese Arbeit gemeinsam lesen ~ 1. Titel der Papierinformationen: DepthFM: FastMonocularDepthEstimationwithFlowMatching Autor: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Wie kann man mit dem Posten von Videos auf Douyin Geld verdienen? Wie kann ein Neuling mit Douyin Geld verdienen?
Mar 21, 2024 pm 08:17 PM
Wie kann man mit dem Posten von Videos auf Douyin Geld verdienen? Wie kann ein Neuling mit Douyin Geld verdienen?
Mar 21, 2024 pm 08:17 PM
Douyin, die nationale Kurzvideoplattform, ermöglicht uns nicht nur, in unserer Freizeit eine Vielzahl interessanter und neuartiger Kurzvideos zu genießen, sondern gibt uns auch eine Bühne, um uns zu zeigen und unsere Werte zu verwirklichen. Wie kann man also Geld verdienen, indem man Videos auf Douyin veröffentlicht? Dieser Artikel wird diese Frage ausführlich beantworten und Ihnen dabei helfen, mit TikTok mehr Geld zu verdienen. 1. Wie kann man mit dem Posten von Videos auf Douyin Geld verdienen? Nachdem Sie ein Video gepostet und eine bestimmte Anzahl an Aufrufen auf Douyin erreicht haben, haben Sie die Möglichkeit, am Werbe-Sharing-Plan teilzunehmen. Diese Einkommensmethode ist eine der bekanntesten unter Douyin-Benutzern und stellt auch für viele YouTuber die Haupteinnahmequelle dar. Douyin entscheidet anhand verschiedener Faktoren wie Kontogewicht, Videoinhalt und Publikumsfeedback, ob Möglichkeiten zum Teilen von Werbung bereitgestellt werden sollen. Die TikTok-Plattform ermöglicht es Zuschauern, ihre Lieblingsschöpfer durch das Versenden von Geschenken zu unterstützen.
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Stehen Sie vor einer Verzögerung oder einer langsamen mobilen Datenverbindung auf dem iPhone? Normalerweise hängt die Stärke des Mobilfunk-Internets auf Ihrem Telefon von mehreren Faktoren ab, wie z. B. der Region, dem Mobilfunknetztyp, dem Roaming-Typ usw. Es gibt einige Dinge, die Sie tun können, um eine schnellere und zuverlässigere Mobilfunk-Internetverbindung zu erhalten. Fix 1 – Neustart des iPhone erzwingen Manchmal werden durch einen erzwungenen Neustart Ihres Geräts viele Dinge zurückgesetzt, einschließlich der Mobilfunkverbindung. Schritt 1 – Drücken Sie einfach einmal die Lauter-Taste und lassen Sie sie los. Drücken Sie anschließend die Leiser-Taste und lassen Sie sie wieder los. Schritt 2 – Der nächste Teil des Prozesses besteht darin, die Taste auf der rechten Seite gedrückt zu halten. Lassen Sie das iPhone den Neustart abschließen. Aktivieren Sie Mobilfunkdaten und überprüfen Sie die Netzwerkgeschwindigkeit. Überprüfen Sie es erneut. Fix 2 – Datenmodus ändern 5G bietet zwar bessere Netzwerkgeschwindigkeiten, funktioniert jedoch besser, wenn das Signal schwächer ist
 Wie veröffentliche ich Xiaohongshu-Videowerke? Worauf sollte ich beim Posten von Videos achten?
Mar 23, 2024 pm 08:50 PM
Wie veröffentliche ich Xiaohongshu-Videowerke? Worauf sollte ich beim Posten von Videos achten?
Mar 23, 2024 pm 08:50 PM
Mit dem Aufkommen von Kurzvideoplattformen ist Xiaohongshu für viele Menschen zu einer Plattform geworden, auf der sie ihr Leben teilen, sich ausdrücken und Traffic gewinnen können. Auf dieser Plattform ist die Veröffentlichung von Videoarbeiten eine sehr beliebte Art der Interaktion. Wie veröffentlicht man also Xiaohongshu-Videoarbeiten? 1. Wie veröffentliche ich Xiaohongshu-Videowerke? Stellen Sie zunächst sicher, dass Sie einen Videoinhalt zum Teilen bereit haben. Sie können zum Fotografieren Ihr Mobiltelefon oder eine andere Kameraausrüstung verwenden, Sie müssen jedoch auf die Bildqualität und die Klarheit des Tons achten. 2. Bearbeiten Sie das Video: Um die Arbeit attraktiver zu gestalten, können Sie das Video bearbeiten. Sie können professionelle Videobearbeitungssoftware wie Douyin, Kuaishou usw. verwenden, um Filter, Musik, Untertitel und andere Elemente hinzuzufügen. 3. Wählen Sie ein Cover: Das Cover ist der Schlüssel, um Benutzer zum Klicken zu bewegen. Wählen Sie ein klares und interessantes Bild als Cover, um Benutzer zum Klicken zu bewegen.
 So posten Sie Videos auf Weibo, ohne die Bildqualität zu komprimieren_So posten Sie Videos auf Weibo, ohne die Bildqualität zu komprimieren
Mar 30, 2024 pm 12:26 PM
So posten Sie Videos auf Weibo, ohne die Bildqualität zu komprimieren_So posten Sie Videos auf Weibo, ohne die Bildqualität zu komprimieren
Mar 30, 2024 pm 12:26 PM
1. Öffnen Sie zunächst Weibo auf Ihrem Mobiltelefon und klicken Sie unten rechts auf [Ich] (wie im Bild gezeigt). 2. Klicken Sie dann oben rechts auf [Zahnrad], um die Einstellungen zu öffnen (wie im Bild gezeigt). 3. Suchen und öffnen Sie dann [Allgemeine Einstellungen] (wie im Bild gezeigt). 4. Geben Sie dann die Option [Video Follow] ein (wie im Bild gezeigt). 5. Öffnen Sie dann die Einstellung [Video-Upload-Auflösung] (wie im Bild gezeigt). 6. Wählen Sie abschließend [Originalbildqualität] aus, um eine Komprimierung zu vermeiden (wie im Bild gezeigt).
