

Wann kommt GPT-5 und welche Fähigkeiten wird es haben?
Ein neues Modell des Allen Institute for AI gibt Ihnen die Antwort.
Unified-IO 2 wurde vom Allen Institute for Artificial Intelligence eingeführt und ist das erste Modell, das Text, Bilder, Audio-, Video- und Aktionssequenzen verarbeiten und generieren kann.
Dieses fortschrittliche KI-Modell wird mit Milliarden von Datenpunkten trainiert. Die Modellgröße beträgt nur 7 Milliarden, weist aber die bislang umfassendsten multimodalen Fähigkeiten auf.

Papieradresse: https://arxiv.org/pdf/2312.17172.pdf
Was ist also die Beziehung zwischen Unified-IO 2 und GPT-5?
Im Juni 2022 brachte das Allen Institute for Artificial Intelligence die erste Generation von Unified-IO auf den Markt und wurde damit zu einem der multimodalen Modelle, die Bilder und Sprache gleichzeitig verarbeiten können.
Etwa zur gleichen Zeit testet OpenAI GPT-4 intern und wird es im März 2023 offiziell veröffentlichen.
Unified-IO kann also als Vorschau auf zukünftige groß angelegte KI-Modelle gesehen werden.
Das heißt, OpenAI testet GPT-5 möglicherweise intern und wird es in ein paar Monaten veröffentlichen.
Auf die Fähigkeiten, die uns Unified-IO 2 dieses Mal zeigt, können wir uns auch im neuen Jahr freuen:
GPT-5 und andere neue KI-Modelle können mit mehr Modalitäten umgehen und umfangreiches Lernen ermöglichen Führen Sie viele Aufgaben lokal aus und verfügen Sie über ein grundlegendes Verständnis für die Interaktion mit Objekten und Robotern.
Die Trainingsdaten von Unified-IO 2 umfassen: 1 Milliarde Bild-Text-Paare, 1 Billion Text-Tags, 180 Millionen Videoclips, 130 Millionen Bilder mit Text, 3 Millionen 3D-Assets und 1 Million Roboteragenten-Bewegungssequenzen.
Das Forschungsteam hat insgesamt mehr als 120 Datensätze zu einem 600-TB-Paket zusammengefasst, das 220 visuelle, sprachliche, auditive und motorische Aufgaben abdeckt.
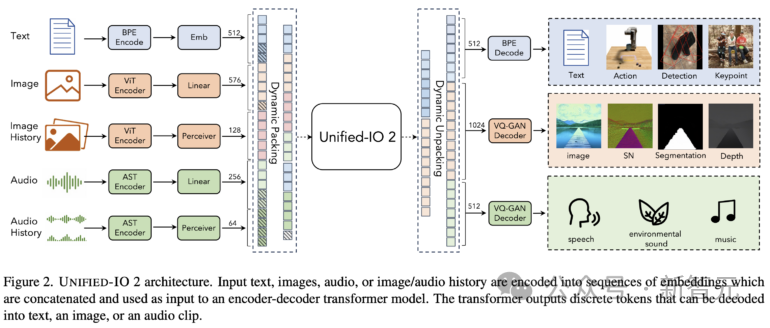
Unified-IO 2 verwendet eine Encoder-Decoder-Architektur mit einigen Änderungen, um das Training zu stabilisieren und multimodale Signale effektiv zu nutzen.
Das Modell kann Fragen beantworten, Texte gemäß Anweisungen schreiben und Textinhalte analysieren.
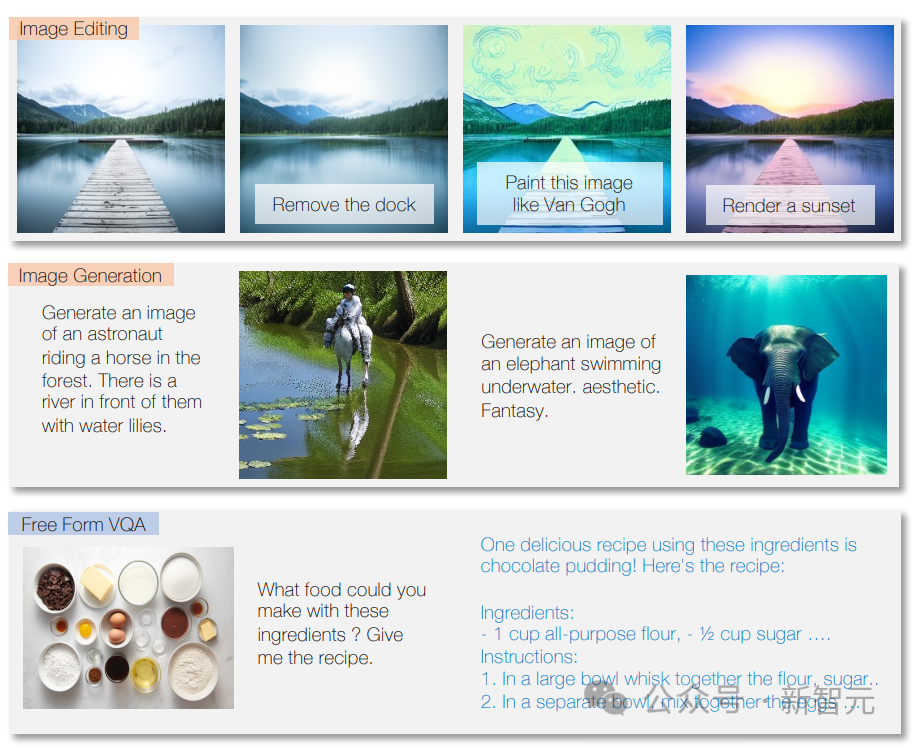
Das Modell kann außerdem Bildinhalte identifizieren, Bildbeschreibungen bereitstellen, Bildverarbeitungsaufgaben durchführen und neue Bilder basierend auf Textbeschreibungen erstellen.
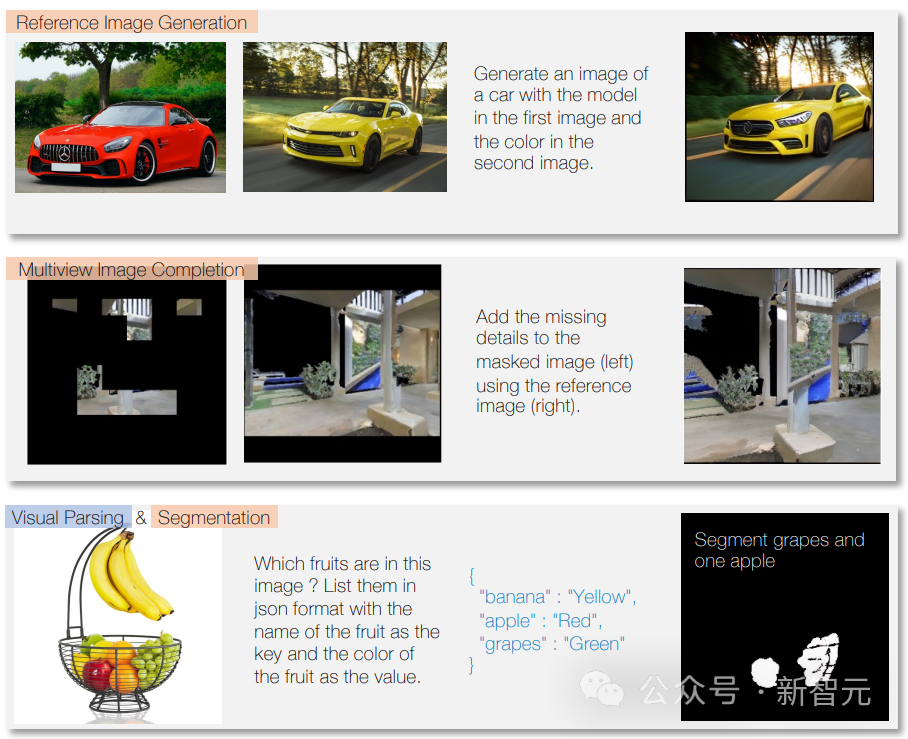
Es kann auch Musik oder Sounds basierend auf Beschreibungen oder Anweisungen erzeugen sowie Videos analysieren und Fragen dazu beantworten.
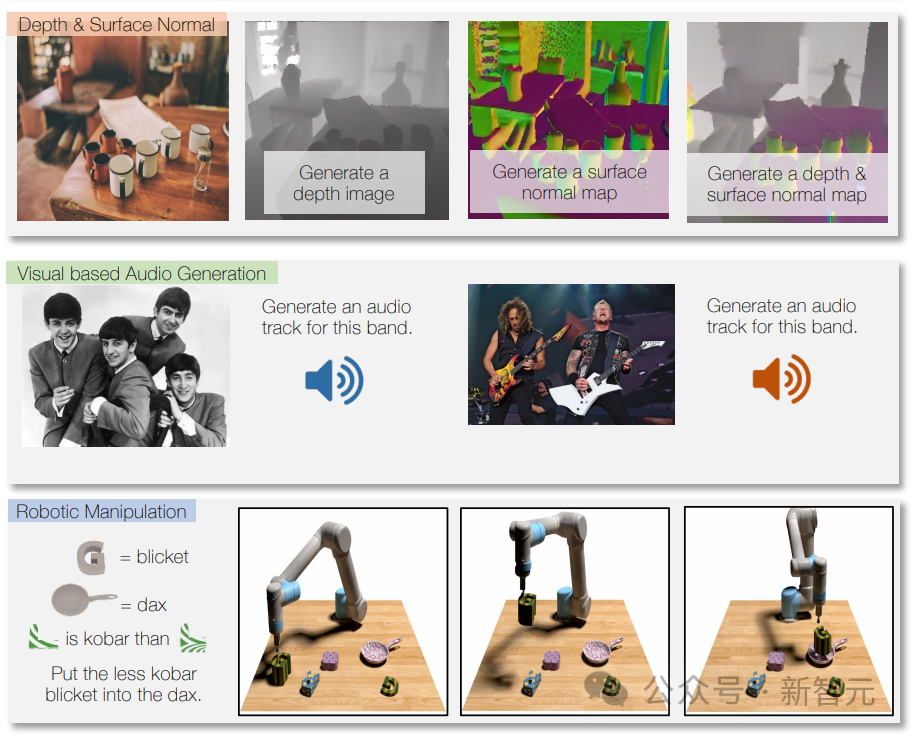
Durch die Verwendung von Roboterdaten für das Training kann Unified-IO 2 auch Aktionen für das Robotersystem generieren, beispielsweise Anweisungen in Aktionssequenzen für den Roboter umwandeln.
Dank multimodalem Training beherrscht es auch unterschiedliche Modalitäten, zum Beispiel die Beschriftung der verwendeten Instrumente in einem bestimmten Track auf dem Bild.

Unified-IO 2 schneidet bei mehr als 35 Benchmarks gut ab, darunter Bilderzeugung und -verständnis, Verständnis natürlicher Sprache, Video- und Audioverständnis sowie Robotermanipulation.
Bei den meisten Aufgaben ist es genauso gut oder besser als spezielle Modelle.
Unified-IO 2 erreichte die bisher höchste Punktzahl beim GRIT-Benchmark für Bildaufgaben (GRIT wird verwendet, um zu testen, wie ein Modell mit Bildrauschen und anderen Problemen umgeht).
Die Forscher planen nun, Unified-IO 2 weiter auszubauen, die Datenqualität zu verbessern und das Encoder-Decoder-Modell in eine branchenübliche Decoder-Modellarchitektur umzuwandeln.
Unified-IO 2 ist das erste autoregressive multimodale Modell, das Bilder, Text, Audio und Bewegung verstehen und generieren kann.
Um verschiedene Modalitäten zu vereinheitlichen, kennzeichnen Forscher Ein- und Ausgänge (Bilder, Text, Audio, Aktionen, Begrenzungsrahmen usw.) in einem gemeinsamen semantischen Raum und verarbeiten sie dann mit einem einzigen Encoder-Decoder-Transformatormodell.
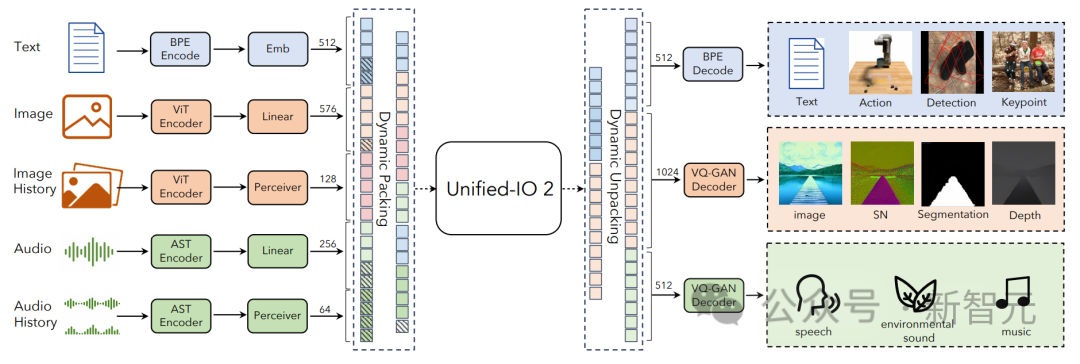
Aufgrund der großen Datenmenge, die zum Trainieren des Modells verwendet wird und aus verschiedenen Modalitäten stammt, haben Forscher eine Reihe von Techniken übernommen, um den gesamten Trainingsprozess zu verbessern.
Um das selbstüberwachte Lernen von Signalen über mehrere Modalitäten hinweg effektiv zu erleichtern, entwickelten die Forscher einen neuartigen multimodalen Hybrid von Denoiser-Zielen, der modalübergreifendes Entrauschen und Generieren kombiniert.
Dynamisches Packen wurde außerdem entwickelt, um den Trainingsdurchsatz um das Vierfache zu erhöhen und sehr variable Sequenzen zu bewältigen.
Um Stabilitäts- und Skalierbarkeitsprobleme beim Training zu überwinden, nahmen Forscher architektonische Änderungen am Perzeptron-Resampler vor, einschließlich 2D-Rotationseinbettung, QK-Normalisierung und skaliertem Kosinus-Aufmerksamkeitsmechanismus.
Stellen Sie bei Befehlsanpassungen sicher, dass jede Mission eine klare Eingabeaufforderung hat, unabhängig davon, ob Sie eine vorhandene Mission verwenden oder eine neue erstellen. Es sind auch offene Aufgaben enthalten, und für weniger verbreitete Muster werden synthetische Aufgaben erstellt, um die Aufgaben- und Unterrichtsvielfalt zu erhöhen.
kodiert multimodale Daten in Token-Sequenzen in einem gemeinsamen Darstellungsraum, einschließlich der folgenden Aspekte:
Texteingabe und -ausgabe Mithilfe der Bytepaar-Codierung in LLaMA tokenisiert, werden spärliche Strukturen wie Begrenzungsrahmen, Schlüsselpunkte und Kamerapositionen diskretisiert und dann mithilfe von 1000 speziellen Tokens codiert, die dem Vokabular hinzugefügt werden.
Punkte werden mit zwei Markern (x, y) codiert, Boxen werden mit einer Folge von vier Markern (oben links und unten rechts) codiert und 3D-Quader werden mit 12 Markern dargestellt (Codierung Projektionszentrum, virtuelle Tiefe, Paar). (Anzahl der normalisierten Boxgrößen und kontinuierliche konzentrische Rotation).
Für verkörperte Aufgaben werden diskrete Roboteraktionen als Textbefehle generiert (z. B. „vorwärts bewegen“). Spezielle Tags werden verwendet, um den Zustand des Roboters zu kodieren (z. B. Position und Drehung).
Bilder werden mit vorab trainierten visuellen Transformatoren (ViT) codiert. Die Patch-Funktionen der zweiten und vorletzten Ebene von ViT werden verkettet, um visuelle Informationen auf niedriger und hoher Ebene zu erfassen.
Verwenden Sie beim Generieren eines Bildes VQ-GAN, um das Bild in diskrete Markierungen umzuwandeln. Hier wird ein dichtes vorab trainiertes VQ-GAN-Modell mit einer Patchgröße von 8 × 8 verwendet, um das 256 × 256-Bild zu kodieren 1024 Token und Codebuch. Die Größe beträgt 16512.
Stellen Sie dann die Beschriftung jedes Pixels (einschließlich Tiefe, Oberflächennormale und binärer Segmentierungsmaske) als RGB-Bild dar.
U-IO 2 kodiert bis zu 4,08 Sekunden Audio in ein Spektrogramm, verwendet dann einen vorab trainierten Audio-Spektrogramm-Konverter (AST), um das Spektrogramm zu kodieren und verkettet die Funktionen der zweiten und vorletzten Schicht des AST und wenden Sie eine lineare Ebene an, um die Eingabeeinbettung zu erstellen, genau wie das Bild ViT.
Verwenden Sie beim Generieren von Audio ViT-VQGAN, um das Audio in diskrete Token umzuwandeln. Die Patchgröße des Modells beträgt 8 × 8, und das 256 × 128-Spektrogramm ist in 512 Token codiert.
Das Modell ermöglicht die Bereitstellung von bis zu vier zusätzlichen Bild- und Audiosegmenten als Eingabe. Diese Elemente werden auch mit ViT oder AST codiert und anschließend mit einem Perceptron-Resampler erweitert komprimiert auf eine niedrigere Zahl (32 für Bilder und 16 für Audio).
Dies reduziert die Sequenzlänge erheblich und ermöglicht es dem Modell, Bilder oder Audioclips im Detail zu untersuchen und dabei Elemente aus dem Verlauf als Kontext zu verwenden.
Forscher haben beobachtet, dass Standardimplementierungen nach der Verwendung von U-IO bei der Integration anderer Modi zu einem zunehmend instabilen Training führen.
Wie in (a) und (b) unten gezeigt, führt das Training nur auf die Bilderzeugung (grüne Kurve) zu einem stabilen Verlust und einer Konvergenz der Gradientennorm.
Die Einführung der Kombination von Bild- und Textaufgaben (orangefarbene Kurve) erhöht die Gradientennorm im Vergleich zur Einzelmodalität leicht, bleibt aber stabil. Allerdings führt die Einbeziehung der Videomodalität (blaue Kurve) zu einer unbegrenzten Erhöhung der Gradientennorm.
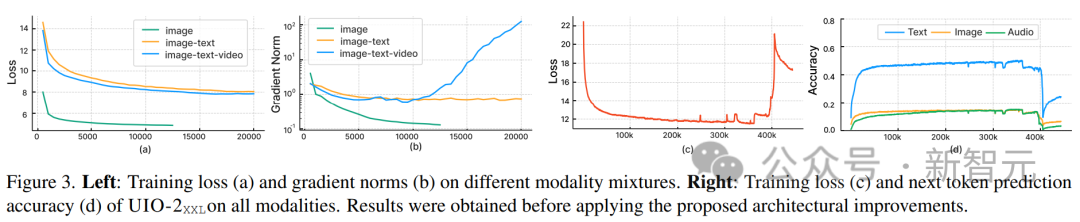
Wie in (c) und (d) der Abbildung gezeigt, explodiert der Verlust nach 350.000 Schritten, wenn die XXL-Version des Modells auf alle Modalitäten trainiert wird, und die Genauigkeit der Vorhersage der nächsten Markierung wird bei angezeigt 400.000 Schritte fallen.
Um dieses Problem zu lösen, nahmen die Forscher verschiedene architektonische Änderungen vor:
Wenden Sie Rotation Position Embedding (RoPE) auf jeder Transformer-Ebene an. Für Nicht-Text-Modalitäten wird RoPE auf 2D-Standorte erweitert; wenn Bild- und Audio-Modalitäten einbezogen werden, wird LayerNorm vor den Punktprodukt-Aufmerksamkeitsberechnungen auf Q und K angewendet.
Darüber hinaus wird mithilfe eines Perzeptron-Resamplers jedes Bild und jeder Audioclip in eine feste Anzahl von Token komprimiert und mithilfe der skalierten Kosinusaufmerksamkeit eine strengere Normalisierung im Perzeptron angewendet, was einen deutlich stabileren Zug ermöglicht.
Um numerische Instabilität zu vermeiden, ist auch der Float32-Aufmerksamkeitslogarithmus aktiviert, und ViT und AST werden während des Vortrainings eingefroren und am Ende der Anweisungsanpassung feinabgestimmt.
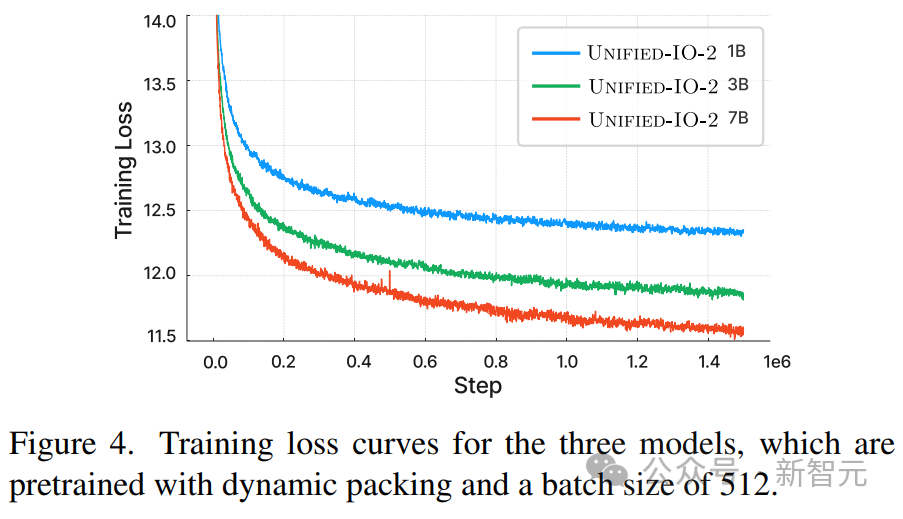
Die obige Abbildung zeigt, dass der Verlust des Modells vor dem Training trotz der Heterogenität der Eingabe- und Ausgabemodalitäten stabil ist.
Dieser Artikel folgt dem UL2-Paradigma. Für Bild- und Audioziele werden hier zwei ähnliche Paradigmen definiert:
[R]: Rauschunterdrückung, zufälliges Maskieren von x % der Eingabebild- oder Audio-Patch-Funktionen und Rekonstruktion durch das Modell
[S] : Erfordert, dass das Modell die Zielmodalität unter anderen Eingabemodalbedingungen generiert.
Stellen Sie während des Trainings dem Eingabetext eine modale Markierung ([Text], [Bild] oder [Audio]) und eine Paradigmenmarkierung ([R], [S] oder [X]) voran, um die Aufgabe anzuzeigen und verwenden Sie dynamische Maskierung für die Autoregression.
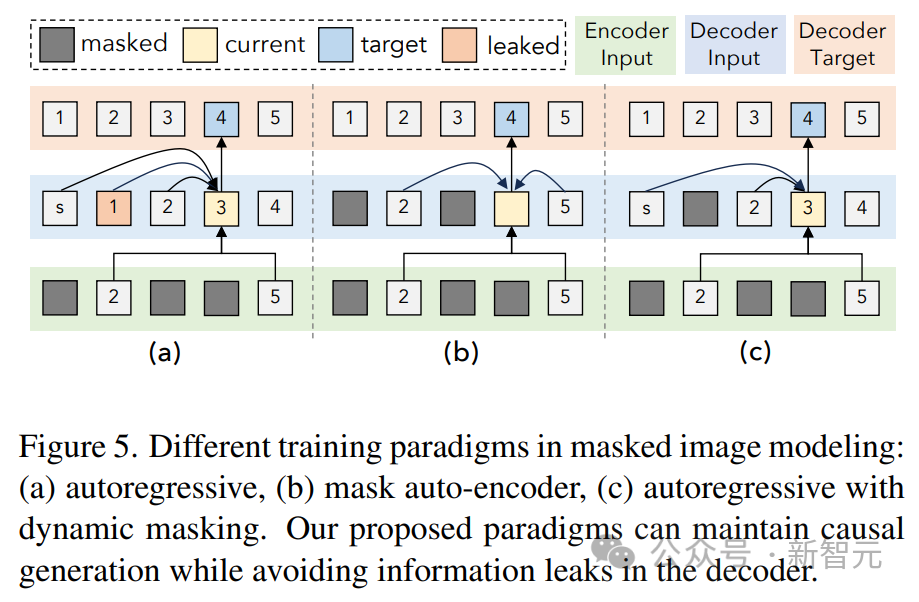
Wie in der Abbildung oben gezeigt, ist ein Problem bei der Rauschunterdrückung durch Bild- und Audiomaskierung der Informationsverlust auf der Decoderseite.
Die Lösung hier besteht darin, das Token im Decoder zu maskieren (es sei denn, dieses Token wird vorhergesagt), was die kausale Vorhersage nicht beeinträchtigt und gleichzeitig Datenlecks verhindert.
Das Training mit einer großen Menge multimodaler Daten führt zu stark variablen Sequenzlängen für den Konvertereingang und -ausgang.
Packen wird hier verwendet, um dieses Problem zu lösen: Tags für mehrere Beispiele werden in eine Sequenz gepackt und die Aufmerksamkeit wird abgeschirmt, um zu verhindern, dass Konverter sich zwischen Beispielen gegenseitig engagieren.
Während des Trainings wird ein heuristischer Algorithmus verwendet, um die an das Modell gestreamten Daten neu anzuordnen, sodass lange Stichproben mit kurzen Stichproben abgeglichen werden, die gepackt werden können. Die dynamische Verpackung dieses Artikels erhöht den Trainingsdurchsatz um fast das Vierfache.
Die multimodale Anweisungsoptimierung ist ein Schlüsselprozess, um das Modell mit unterschiedlichen Fertigkeiten und Fähigkeiten für verschiedene Modalitäten auszustatten und es sogar an neue und einzigartige Anweisungen anzupassen.
Forscher erstellen einen multimodalen Datensatz zur Befehlsoptimierung, indem sie eine breite Palette überwachter Datensätze und Aufgaben kombinieren.
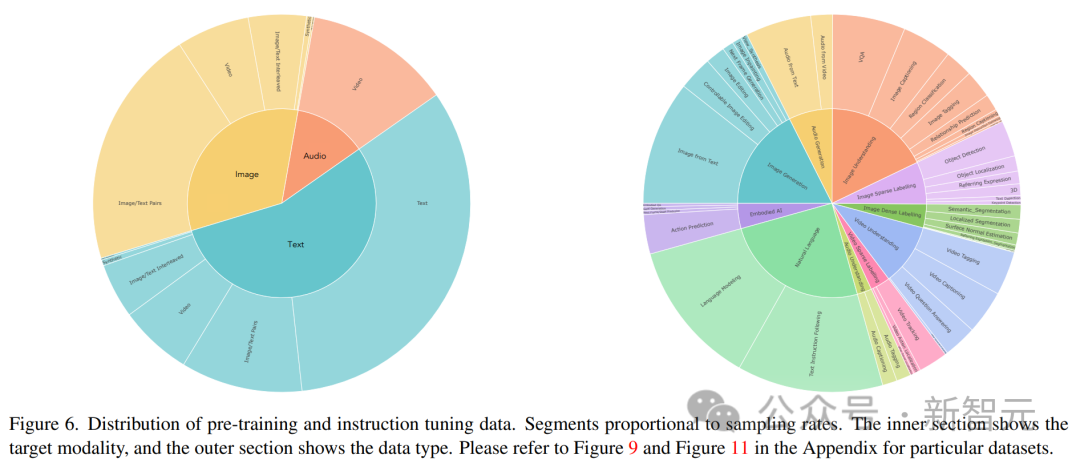
Die Verteilung der Befehlsoptimierungsdaten ist in der Abbildung oben dargestellt. Insgesamt bestand der Anweisungsoptimierungsmix aus 60 % Hinweisdaten, 30 % aus Vortraining geerbten Daten (um katastrophales Vergessen zu vermeiden), 6 % Aufgabenerweiterungsdaten, die unter Verwendung vorhandener Datenquellen erstellt wurden, und 4 % Freiformtext (um Chat zu ermöglichen). -ähnliche Antworten).
Das obige ist der detaillierte Inhalt vonGPT-5-Vorschau! Das Allen Institute for Artificial Intelligence veröffentlicht das stärkste multimodale Modell zur Vorhersage neuer Fähigkeiten von GPT-5. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So öffnen Sie HTML-Dateien
So öffnen Sie HTML-Dateien
 Tutorial zur Linux-Systeminstallation
Tutorial zur Linux-Systeminstallation
 Analyse der ICP-Münzaussichten
Analyse der ICP-Münzaussichten
 Thunder VIP-Patch
Thunder VIP-Patch
 Fehlerberichtslösung für den MySQL-Import einer SQL-Datei
Fehlerberichtslösung für den MySQL-Import einer SQL-Datei
 So lösen Sie das Problem, wenn der Computer eingeschaltet wird, der Bildschirm schwarz wird und der Desktop nicht aufgerufen werden kann
So lösen Sie das Problem, wenn der Computer eingeschaltet wird, der Bildschirm schwarz wird und der Desktop nicht aufgerufen werden kann
 Einführung in die Verwendung von vscode
Einführung in die Verwendung von vscode
 Virtuelle Währungsumtauschplattform
Virtuelle Währungsumtauschplattform








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



