
 Technologie-Peripheriegeräte
KI
Großes Modell + Roboter, hier gibt es einen ausführlichen Testbericht unter Beteiligung vieler chinesischer Wissenschaftler
Technologie-Peripheriegeräte
KI
Großes Modell + Roboter, hier gibt es einen ausführlichen Testbericht unter Beteiligung vieler chinesischer Wissenschaftler
Großes Modell + Roboter, hier gibt es einen ausführlichen Testbericht unter Beteiligung vieler chinesischer Wissenschaftler

Die herausragenden Fähigkeiten großer Modelle sind für alle offensichtlich, und wenn sie in Roboter integriert werden, wird erwartet, dass Roboter ein intelligenteres Gehirn haben, was neue Möglichkeiten in den Bereich der Robotik bringt, wie zum Beispiel autonomes Fahren, Heimroboter und Industrieroboter Roboter, Hilfsroboter, Medizinroboter, Feldroboter und Multirobotersysteme.
Vorab trainiertes Large Language Model (LLM), Large Vision-Language Model (VLM), Large Audio-Language Model (ALM) und Large Visual Navigation Model (VNM) können verwendet werden, um verschiedene Probleme im Bereich der Robotik besser zu bewältigen Aufgabe. Die Integration grundlegender Modelle in die Robotik ist ein schnell wachsendes Feld, und die Robotik-Community hat vor kurzem damit begonnen, den Einsatz dieser großen Modelle in Robotikbereichen zu erforschen, die neu geschrieben werden müssen: Wahrnehmung, Vorhersage, Planung und Kontrolle.
Kürzlich hat ein gemeinsames Forschungsteam bestehend aus der Stanford University, der Princeton University, NVIDIA, Google DeepMind und anderen Unternehmen einen Übersichtsbericht veröffentlicht, der die Entwicklung und zukünftige Herausforderungen grundlegender Modelle im Bereich der Robotikforschung zusammenfasst

Papier Adresse: https://arxiv.org/pdf/2312.07843.pdf
Der neu geschriebene Inhalt ist: Papierbibliothek: https://github.com/robotics-survey/Awesome-Robotics-Foundation -Models
Unter den Teammitgliedern gibt es viele uns bekannte chinesische Gelehrte, darunter Zhu Yuke, Song Shuran, Wu Jiajun, Lu Cewu usw.
Grundlegende Modelle, die anhand umfangreicher Daten umfassend vorab trainiert wurden, können nach der Feinabstimmung auf verschiedene nachgelagerte Aufgaben angewendet werden. Diese Grundmodelle haben große Durchbrüche in den Bereichen Seh- und Sprachverarbeitung erzielt, einschließlich verwandter Modelle wie BERT, GPT-3, GPT-4, CLIP, DALL-E und PaLM-E
Vor dem Aufkommen der Grundmodelle für Roboter Herkömmliche Deep-Learning-Modelle werden mithilfe begrenzter Datensätze trainiert, die für verschiedene Aufgaben gesammelt wurden. Im Gegensatz dazu werden Basismodelle unter Verwendung einer breiten Palette unterschiedlicher Daten vorab trainiert und haben Anpassungsfähigkeit, Generalisierung und Gesamtleistung in anderen Bereichen wie der Verarbeitung natürlicher Sprache, Computer Vision und dem Gesundheitswesen bewiesen. Schließlich soll das Basismodell auch im Bereich der Robotik sein Potenzial zeigen. Abbildung 1 zeigt einen Überblick über das Grundmodell im Bereich Robotik.
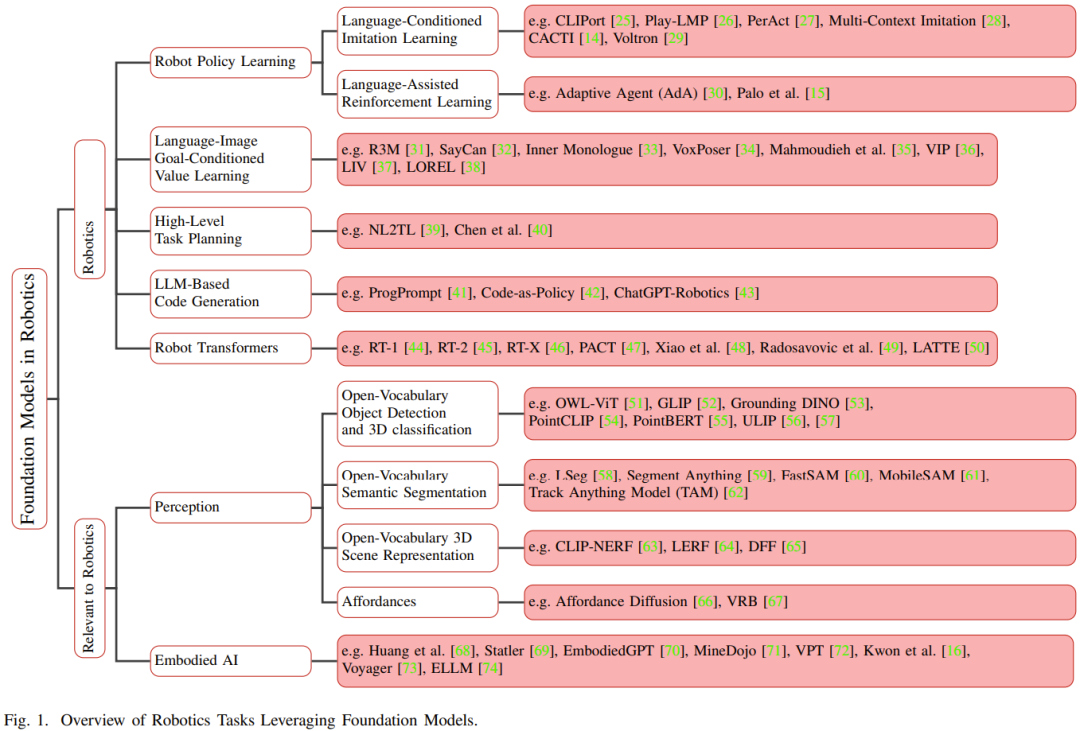
Im Vergleich zu aufgabenspezifischen Modellen hat der Wissenstransfer aus Basismodellen das Potenzial, Trainingszeit und Rechenressourcen zu reduzieren. Insbesondere in robotikbezogenen Bereichen können multimodale Basismodelle multimodale heterogene Daten, die von verschiedenen Sensoren gesammelt wurden, zu kompakten homogenen Darstellungen verschmelzen und ausrichten, die für das Verständnis und Denken von Robotern erforderlich sind. Die erlernten Darstellungen können in jedem Teil des Automatisierungstechnologie-Stacks verwendet werden, einschließlich derjenigen, die neu geschrieben werden müssen: Wahrnehmung, Entscheidungsfindung und Kontrolle.
Darüber hinaus kann das Basismodell auch Zero-Shot-Lernfunktionen bieten, die es dem KI-System ermöglichen, Aufgaben ohne Beispiele oder gezieltes Training auszuführen. Dadurch kann der Roboter das erlernte Wissen auf neue Anwendungsfälle übertragen und so seine Anpassungsfähigkeit und Flexibilität in unstrukturierten Umgebungen verbessern.
Die Integration des Grundmodells in das Robotersystem kann die Fähigkeit des Roboters verbessern, die Umgebung wahrzunehmen und mit der Umgebung zu interagieren. Es ist möglich, den Kontext zu erkennen, der neu geschrieben werden muss: das Wahrnehmungsrobotersystem.
Was beispielsweise neu geschrieben werden muss, ist: Im Bereich der Wahrnehmung können groß angelegte visuelle Sprachmodelle (VLM) die Assoziation zwischen visuellen und Textdaten lernen, um über modalübergreifende Verständnisfähigkeiten zu verfügen und so zu helfen Zero-Shot-Bildklassifizierung, Aufgaben wie Zero-Sample-Objekterkennung und 3D-Klassifizierung. Als weiteres Beispiel kann die Spracherdung (d. h. die Ausrichtung des VLM-Kontextverständnisses auf die reale 3D-Welt) in der 3D-Welt die räumlichen Bedürfnisse des Roboters verbessern, indem Äußerungen mit bestimmten Objekten, Orten oder Aktionen in der 3D-Umgebung verknüpft werden. Neu geschrieben: Wahrnehmungsfähigkeit .
Im Bereich der Entscheidungsfindung oder Planung hat die Forschung herausgefunden, dass LLM und VLM Roboter bei der Spezifizierung von Aufgaben unterstützen können, die eine Planung auf hoher Ebene erfordern.
Durch die Nutzung sprachlicher Hinweise im Zusammenhang mit Bedienung, Navigation und Interaktion können Roboter komplexere Aufgaben ausführen. Beispielsweise scheint das Grundmodell für Roboterpolitik-Lerntechnologien wie Nachahmungslernen und Verstärkungslernen in der Lage zu sein, die Dateneffizienz und das Kontextverständnis zu verbessern. Insbesondere sprachgesteuerte Belohnungen können Agenten des verstärkenden Lernens durch die Bereitstellung geformter Belohnungen anleiten.
Darüber hinaus nutzen Forscher bereits Sprachmodelle, um Feedback für die Politiklerntechnologie zu geben. Einige Studien haben gezeigt, dass die visuellen Fragebeantwortungsfunktionen (VQA) von VLM-Modellen für Anwendungsfälle in der Robotik genutzt werden können. Beispielsweise haben Forscher VLM verwendet, um Fragen zu visuellen Inhalten zu beantworten, um Robotern bei der Erledigung von Aufgaben zu helfen. Darüber hinaus verwenden einige Forscher VLM, um bei der Datenanmerkung zu helfen und Beschreibungsbezeichnungen für visuelle Inhalte zu generieren.
Obwohl das Basismodell über transformative Fähigkeiten in der Seh- und Sprachverarbeitung verfügt, ist die Verallgemeinerung und Feinabstimmung des Basismodells für reale Robotikaufgaben immer noch eine große Herausforderung.
Zu diesen Herausforderungen gehören:
1) Datenmangel: Wie erhält man Daten im Internetmaßstab zur Unterstützung von Aufgaben wie Roboterbetrieb, Positionierung und Navigation und wie nutzt man diese Daten für selbstüberwachtes Training
2) Riesige Unterschiede: Wie man mit der enormen Vielfalt physischer Umgebungen, physischer Roboterplattformen und potenzieller Roboteraufgaben umgeht und gleichzeitig die erforderliche Allgemeingültigkeit des zugrunde liegenden Modells beibehält
3) Das Problem der Quantifizierung der Unsicherheit: Wie man Unsicherheiten auf Instanzebene löst (wie Sprachmehrdeutigkeit oder LLM-Illusion), Unsicherheit auf Verteilungsebene und Verteilungsverschiebungsprobleme, insbesondere das Verteilungsverschiebungsproblem, das durch den Einsatz von Robotern mit geschlossenem Regelkreis verursacht wird.
4) Sicherheitsbewertung: So testen Sie das Robotersystem basierend auf dem Basismodell vor der Bereitstellung, während des Aktualisierungsprozesses und während des Arbeitsprozesses gründlich.
5) Echtzeitleistung: Wie man mit der langen Inferenzzeit einiger Basismodelle umgeht, die den Einsatz von Basismodellen auf Robotern behindert, und wie man die Inferenz von Basismodellen beschleunigt, die für Online-Entscheidungen erforderlich ist. Herstellung.
Dieses Übersichtspapier fasst die aktuelle Verwendung grundlegender Modelle im Bereich der Robotik zusammen. Die Forscher untersuchen aktuelle Methoden, Anwendungen und Herausforderungen und schlagen zukünftige Forschungsrichtungen vor, um diese Herausforderungen anzugehen. Sie wiesen auch auf die potenziellen Risiken hin, die bei der Verwendung des Basismodells zur Erreichung der Roboterautonomie bestehen können. Das Training eines so großen und komplexen Modells ist sehr kostspielig. Auch die Kosten für die Erfassung, Verarbeitung und Verwaltung von Daten können hoch sein. Sein Trainingsprozess erfordert eine große Menge an Rechenressourcen, erfordert den Einsatz dedizierter Hardware wie GPU oder TPU und erfordert außerdem Software und Infrastruktur für das Modelltraining, die alle finanzielle Investitionen erfordern. Zudem ist auch die Einarbeitungszeit des Basismodells sehr lang, was ebenfalls zu hohen Kosten führt. Daher werden diese Modelle häufig als steckbare Module verwendet, d. h. zur Integration des Basismodells in verschiedene Anwendungen ohne umfangreiche Anpassungsarbeiten.
Tabelle 1 enthält Einzelheiten zu häufig verwendeten Basismodellen.
Dieser Abschnitt konzentriert sich auf LLM, visuellen Transformer, VLM, verkörpertes multimodales Sprachmodell und visuelles generatives Modell. Darüber hinaus werden auch verschiedene Trainingsmethoden vorgestellt, die zum Trainieren des Basismodells verwendet werden. Zunächst werden einige verwandte Terminologien und mathematische Kenntnisse vorgestellt, darunter Tokenisierung, generative Modelle, diskriminierende Modelle, Transformatorarchitektur, autoregressive Modelle, maskierte automatische Kodierung und kontrastives Lernen und Diffusionsmodelle.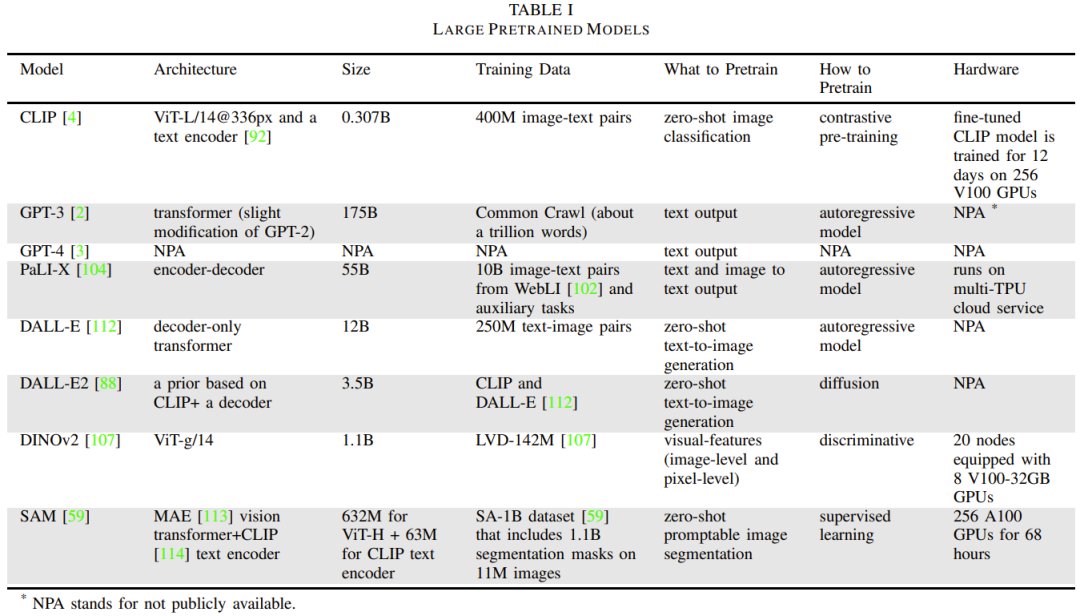 Dann stellen sie Beispiele und historische Hintergründe von Large Language Models (LLM) vor. Anschließend wurden der visuelle Transformer, das multimodale Vision-Sprachmodell (VLM), das verkörperte multimodale Sprachmodell und das visuelle generative Modell hervorgehoben.
Dann stellen sie Beispiele und historische Hintergründe von Large Language Models (LLM) vor. Anschließend wurden der visuelle Transformer, das multimodale Vision-Sprachmodell (VLM), das verkörperte multimodale Sprachmodell und das visuelle generative Modell hervorgehoben.
Dieser Abschnitt konzentriert sich auf die Entscheidungsfindung, Planung und Steuerung von Robotern. In diesem Bereich haben sowohl große Sprachmodelle (LLM) als auch visuelle Sprachmodelle (VLM) das Potenzial, die Fähigkeiten von Robotern zu verbessern. LLM kann beispielsweise den Aufgabenspezifikationsprozess erleichtern, sodass Roboter übergeordnete Anweisungen von Menschen empfangen und interpretieren können.
VLM wird voraussichtlich auch einen Beitrag zu diesem Bereich leisten. VLM zeichnet sich durch die Analyse visueller Daten aus. Damit Roboter fundierte Entscheidungen treffen und komplexe Aufgaben ausführen können, ist visuelles Verständnis von entscheidender Bedeutung. Jetzt können Roboter natürliche Sprachsignale nutzen, um ihre Fähigkeit zur Ausführung von Aufgaben im Zusammenhang mit Manipulation, Navigation und Interaktion zu verbessern. Zielbasiertes visuell-linguistisches Politiklernen (sei es durch Nachahmungslernen oder Verstärkungslernen) wird voraussichtlich durch das Basismodell verbessert. Sprachmodelle können auch Feedback für politische Lerntechniken liefern. Diese Rückkopplungsschleife trägt dazu bei, die Entscheidungsfähigkeit des Roboters kontinuierlich zu verbessern, da der Roboter seine Aktionen basierend auf dem Feedback, das er vom LLM erhält, optimieren kann.
Dieser Abschnitt konzentriert sich auf die Anwendung von LLM und VLM im Bereich der Roboterentscheidungsfindung.
Dieser Abschnitt ist in sechs Teile unterteilt. Im ersten Teil wird das politische Lernen für Entscheidungsfindung und Kontrolle sowie Roboter vorgestellt, einschließlich sprachbasiertes Nachahmungslernen und sprachgestütztes Verstärkungslernen.
Der zweite Teil ist das zielorientierte Erlernen von Sprach-Bild-Werten.
Der dritte Teil stellt die Verwendung großer Sprachmodelle zur Planung von Roboteraufgaben vor. Dazu gehört die Erklärung von Aufgaben durch Sprachanweisungen und die Verwendung von Sprachmodellen zur Generierung von Code für die Aufgabenplanung.
Der vierte Teil ist kontextuelles Lernen (ICL) zur Entscheidungsfindung.
Als nächstes wird Robot Transformers vorgestellt.
Der sechste Teil ist die Roboternavigation und Bedienung der offenen Vokabularbibliothek.
Tabelle 2 enthält einige grundlegende roboterspezifische Modelle, meldet Modellgröße und -architektur, Aufgaben vor dem Training, Inferenzzeit und Hardware-Setup.
Was neu geschrieben werden muss ist: Wahrnehmung
Roboter, die mit der Umgebung interagieren, empfangen sensorische Informationen in verschiedenen Modalitäten, wie zum Beispiel Bilder, Videos, Audio und Sprache. Diese hochdimensionalen Daten sind für Roboter von entscheidender Bedeutung, um ihre Umgebung zu verstehen, zu denken und mit ihr zu interagieren. Einfache Modelle können diese hochdimensionalen Eingaben in abstrakte strukturierte Darstellungen umwandeln, die leicht zu interpretieren und zu manipulieren sind. Insbesondere multimodale Basismodelle ermöglichen es Robotern, Eingaben verschiedener Sinne in eine einheitliche Darstellung zu integrieren, die semantische, räumliche, zeitliche und Erschwinglichkeitsinformationen enthält. Diese multimodalen Modelle erfordern modalübergreifende Interaktionen und erfordern häufig die Ausrichtung von Elementen verschiedener Modalitäten, um Konsistenz und gegenseitige Übereinstimmung sicherzustellen. Bildbeschreibungsaufgaben erfordern beispielsweise die Ausrichtung von Text- und Bilddaten.
Dieser Abschnitt konzentriert sich auf das, was Roboter neu schreiben müssen: eine Reihe von Aufgaben im Zusammenhang mit der Wahrnehmung, die durch die Verwendung grundlegender Modelle zur Ausrichtung der Modalitäten verbessert werden können. Der Schwerpunkt liegt auf Vision und Sprache.
Dieser Abschnitt ist in fünf Teile unterteilt: Zuerst erfolgt die Zielerkennung und 3D-Klassifizierung des offenen Vokabulars, dann die semantische Segmentierung des offenen Vokabulars, dann die 3D-Szene und Zieldarstellung des offenen Vokabulars und dann die erlernte Angebote und schließlich Vorhersagemodelle.
Verkörperte KI
Kürzlich haben einige Studien gezeigt, dass LLM erfolgreich im Bereich der verkörperten KI eingesetzt werden kann, wobei sich „verkörpert“ normalerweise auf die virtuelle Verkörperung im Weltsimulator bezieht und nicht auf einen physischen Roboterkörper.
In diesem Bereich sind einige interessante Frameworks, Datensätze und Modelle entstanden. Besonders hervorzuheben ist die Nutzung des Minecraft-Spiels als Plattform für die Ausbildung verkörperter Agenten. Voyager verwendet beispielsweise GPT-4, um Agenten bei der Erkundung von Minecraft-Umgebungen anzuleiten. Es kann durch kontextbezogenes Eingabeaufforderungsdesign mit GPT-4 interagieren, ohne dass eine Feinabstimmung der Modellparameter von GPT-4 erforderlich ist.
Reinforcement Learning ist eine wichtige Forschungsrichtung im Bereich des Roboterlernens. Forscher versuchen, Basismodelle zu verwenden, um Belohnungsfunktionen zu entwerfen, um Reinforcement Learning zu optimieren.
Damit Roboter eine Planung auf hoher Ebene durchführen können, haben Forscher die Verwendung von Basismodellen untersucht Modelle zur Unterstützung. Darüber hinaus versuchen einige Forscher, auf der Denkkette basierende Methoden zur Argumentation und Handlungsgenerierung auf die verkörperte Intelligenz anzuwenden. Das Team wird auch zukünftige Forschungsrichtungen erkunden, die diese Herausforderungen angehen könnten.
Die erste Herausforderung besteht darin, das Problem der Datenknappheit beim Training von Basismodellen für Roboter zu überwinden. Dazu gehört: 1 Erweiterung des Roboterlernens mithilfe unstrukturierter Spieldaten und unbeschrifteter menschlicher Videos
2
3. Überwinden Sie das Problem des Mangels an 3D-Daten beim Training von 3D-Basismodellen
4 Generieren Sie synthetische Daten durch High-Fidelity-Simulation
5 Die Verwendung von VLM zur Datenerweiterung ist eine effektive Methode .
Die dritte Herausforderung betrifft die Grenzen der multimodalen Darstellung.
Die vierte Herausforderung besteht darin, die Unsicherheit auf verschiedenen Ebenen zu quantifizieren, beispielsweise auf der Instanzebene und der Verteilungsebene. Dazu gehört auch das Problem der Kalibrierung und des Umgangs mit Verteilungsverschiebungen.
Die fünfte Herausforderung umfasst die Sicherheitsbewertung, einschließlich Sicherheitstests vor der Bereitstellung sowie Laufzeitüberwachung und Erkennung von Out-of-Distribution-Situationen.
Die sechste Herausforderung besteht darin, zu entscheiden: ein vorhandenes Basismodell verwenden oder ein neues Basismodell für den Roboter erstellen?
Die siebte Herausforderung beinhaltet eine hohe Variabilität im Roboter-Setup.
Die achte Herausforderung besteht darin, Benchmarking durchzuführen und die Reproduzierbarkeit in einer Roboterumgebung sicherzustellen.
Weitere Forschungsdetails finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonGroßes Modell + Roboter, hier gibt es einen ausführlichen Testbericht unter Beteiligung vieler chinesischer Wissenschaftler. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Der DeepMind-Roboter spielt Tischtennis und seine Vor- und Rückhand rutschen in die Luft, wodurch menschliche Anfänger völlig besiegt werden
Aug 09, 2024 pm 04:01 PM
Der DeepMind-Roboter spielt Tischtennis und seine Vor- und Rückhand rutschen in die Luft, wodurch menschliche Anfänger völlig besiegt werden
Aug 09, 2024 pm 04:01 PM
Aber vielleicht kann er den alten Mann im Park nicht besiegen? Die Olympischen Spiele in Paris sind in vollem Gange und Tischtennis hat viel Aufmerksamkeit erregt. Gleichzeitig haben Roboter auch beim Tischtennisspielen neue Durchbrüche erzielt. Gerade hat DeepMind den ersten lernenden Roboteragenten vorgeschlagen, der das Niveau menschlicher Amateurspieler im Tischtennis-Wettkampf erreichen kann. Papieradresse: https://arxiv.org/pdf/2408.03906 Wie gut ist der DeepMind-Roboter beim Tischtennisspielen? Vermutlich auf Augenhöhe mit menschlichen Amateurspielern: Sowohl Vorhand als auch Rückhand: Der Gegner nutzt unterschiedliche Spielstile, und auch der Roboter hält aus: Aufschlagannahme mit unterschiedlichem Spin: Allerdings scheint die Intensität des Spiels nicht so intensiv zu sein wie Der alte Mann im Park. Für Roboter, Tischtennis
 Die erste mechanische Klaue! Yuanluobao trat auf der Weltroboterkonferenz 2024 auf und stellte den ersten Schachroboter vor, der das Haus betreten kann
Aug 21, 2024 pm 07:33 PM
Die erste mechanische Klaue! Yuanluobao trat auf der Weltroboterkonferenz 2024 auf und stellte den ersten Schachroboter vor, der das Haus betreten kann
Aug 21, 2024 pm 07:33 PM
Am 21. August fand in Peking die Weltroboterkonferenz 2024 im großen Stil statt. Die Heimrobotermarke „Yuanluobot SenseRobot“ von SenseTime hat ihre gesamte Produktfamilie vorgestellt und kürzlich den Yuanluobot AI-Schachspielroboter – Chess Professional Edition (im Folgenden als „Yuanluobot SenseRobot“ bezeichnet) herausgebracht und ist damit der weltweit erste A-Schachroboter für heim. Als drittes schachspielendes Roboterprodukt von Yuanluobo hat der neue Guoxiang-Roboter eine Vielzahl spezieller technischer Verbesserungen und Innovationen in den Bereichen KI und Maschinenbau erfahren und erstmals die Fähigkeit erkannt, dreidimensionale Schachfiguren aufzunehmen B. durch mechanische Klauen an einem Heimroboter, und führen Sie Mensch-Maschine-Funktionen aus, z. B. Schach spielen, jeder spielt Schach, Überprüfung der Notation usw.
 Claude ist auch faul geworden! Netizen: Lernen Sie, sich einen Urlaub zu gönnen
Sep 02, 2024 pm 01:56 PM
Claude ist auch faul geworden! Netizen: Lernen Sie, sich einen Urlaub zu gönnen
Sep 02, 2024 pm 01:56 PM
Der Schulstart steht vor der Tür und nicht nur die Schüler, die bald ins neue Semester starten, sollten auf sich selbst aufpassen, sondern auch die großen KI-Modelle. Vor einiger Zeit war Reddit voller Internetnutzer, die sich darüber beschwerten, dass Claude faul werde. „Sein Niveau ist stark gesunken, es kommt oft zu Pausen und sogar die Ausgabe wird sehr kurz. In der ersten Woche der Veröffentlichung konnte es ein komplettes 4-seitiges Dokument auf einmal übersetzen, aber jetzt kann es nicht einmal eine halbe Seite ausgeben.“ !
 Auf der Weltroboterkonferenz wurde dieser Haushaltsroboter, der „die Hoffnung auf eine zukünftige Altenpflege' in sich trägt, umzingelt
Aug 22, 2024 pm 10:35 PM
Auf der Weltroboterkonferenz wurde dieser Haushaltsroboter, der „die Hoffnung auf eine zukünftige Altenpflege' in sich trägt, umzingelt
Aug 22, 2024 pm 10:35 PM
Auf der World Robot Conference in Peking ist die Präsentation humanoider Roboter zum absoluten Mittelpunkt der Szene geworden. Am Stand von Stardust Intelligent führte der KI-Roboterassistent S1 drei große Darbietungen mit Hackbrett, Kampfkunst und Kalligraphie auf Ein Ausstellungsbereich, der sowohl Literatur als auch Kampfkunst umfasst, zog eine große Anzahl von Fachpublikum und Medien an. Durch das elegante Spiel auf den elastischen Saiten demonstriert der S1 eine feine Bedienung und absolute Kontrolle mit Geschwindigkeit, Kraft und Präzision. CCTV News führte einen Sonderbericht über das Nachahmungslernen und die intelligente Steuerung hinter „Kalligraphie“ durch. Firmengründer Lai Jie erklärte, dass hinter den seidenweichen Bewegungen die Hardware-Seite die beste Kraftkontrolle und die menschenähnlichsten Körperindikatoren (Geschwindigkeit, Belastung) anstrebt. usw.), aber auf der KI-Seite werden die realen Bewegungsdaten von Menschen gesammelt, sodass der Roboter stärker werden kann, wenn er auf eine schwierige Situation stößt, und lernen kann, sich schnell weiterzuentwickeln. Und agil
 KI-Hardware fügt ein weiteres Mitglied hinzu! Kann NotePin länger halten, als Mobiltelefone zu ersetzen?
Sep 02, 2024 pm 01:40 PM
KI-Hardware fügt ein weiteres Mitglied hinzu! Kann NotePin länger halten, als Mobiltelefone zu ersetzen?
Sep 02, 2024 pm 01:40 PM
Bisher hat kein Produkt im Bereich der tragbaren KI-Geräte besonders gute Ergebnisse erzielt. AIPin, das Anfang dieses Jahres auf dem MWC24 vorgestellt wurde, begann nach der Auslieferung des Evaluierungsprototyps mit dem „KI-Mythos“, der zum Zeitpunkt seiner Veröffentlichung hochgejubelt wurde, zu zerplatzen, und es erlebte innerhalb von nur wenigen Tagen große Erfolge Das RabbitR1, das sich anfangs ebenfalls gut verkaufte, war relativ gut, erhielt aber auch negative Bewertungen, ähnlich wie „Android-Hüllen“, als es in großen Mengen ausgeliefert wurde. Jetzt ist ein anderes Unternehmen in die Branche der tragbaren KI-Geräte eingestiegen. Das Technologiemedium TheVerge hat gestern einen Blogbeitrag veröffentlicht, in dem es heißt, dass das KI-Startup Plaud ein Produkt namens NotePin auf den Markt gebracht hat. Im Gegensatz zu AIFriend, das sich noch in der „Malerei“-Phase befindet, ist NotePin jetzt gestartet
 Bekanntgabe der ACL 2024 Awards: Eines der besten Papers zum Thema Oracle Deciphering von HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
Bekanntgabe der ACL 2024 Awards: Eines der besten Papers zum Thema Oracle Deciphering von HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
Bei dieser ACL-Konferenz haben die Teilnehmer viel gewonnen. Die sechstägige ACL2024 findet in Bangkok, Thailand, statt. ACL ist die führende internationale Konferenz im Bereich Computerlinguistik und Verarbeitung natürlicher Sprache. Sie wird von der International Association for Computational Linguistics organisiert und findet jährlich statt. ACL steht seit jeher an erster Stelle, wenn es um akademischen Einfluss im Bereich NLP geht, und ist außerdem eine von der CCF-A empfohlene Konferenz. Die diesjährige ACL-Konferenz ist die 62. und hat mehr als 400 innovative Arbeiten im Bereich NLP eingereicht. Gestern Nachmittag gab die Konferenz den besten Vortrag und weitere Auszeichnungen bekannt. Diesmal gibt es 7 Best Paper Awards (zwei davon unveröffentlicht), 1 Best Theme Paper Award und 35 Outstanding Paper Awards. Die Konferenz verlieh außerdem drei Resource Paper Awards (ResourceAward) und einen Social Impact Award (
 Hongmeng Smart Travel S9 und die umfassende Einführungskonferenz für neue Produkte wurden gemeinsam mit einer Reihe neuer Blockbuster-Produkte veröffentlicht
Aug 08, 2024 am 07:02 AM
Hongmeng Smart Travel S9 und die umfassende Einführungskonferenz für neue Produkte wurden gemeinsam mit einer Reihe neuer Blockbuster-Produkte veröffentlicht
Aug 08, 2024 am 07:02 AM
Heute Nachmittag begrüßte Hongmeng Zhixing offiziell neue Marken und neue Autos. Am 6. August veranstaltete Huawei die Hongmeng Smart Xingxing S9 und die Huawei-Konferenz zur Einführung neuer Produkte mit umfassendem Szenario und brachte die Panorama-Smart-Flaggschiff-Limousine Xiangjie S9, das neue M7Pro und Huawei novaFlip, MatePad Pro 12,2 Zoll, das neue MatePad Air und Huawei Bisheng mit Mit vielen neuen Smart-Produkten für alle Szenarien, darunter die Laserdrucker der X1-Serie, FreeBuds6i, WATCHFIT3 und der Smart Screen S5Pro, von Smart Travel über Smart Office bis hin zu Smart Wear baut Huawei weiterhin ein Smart-Ökosystem für alle Szenarien auf, um Verbrauchern ein Smart-Erlebnis zu bieten Internet von allem. Hongmeng Zhixing: Huawei arbeitet mit chinesischen Partnern aus der Automobilindustrie zusammen, um die Modernisierung der Smart-Car-Industrie voranzutreiben
 Das Team von Li Feifei schlug ReKep vor, um Robotern räumliche Intelligenz zu verleihen und GPT-4o zu integrieren
Sep 03, 2024 pm 05:18 PM
Das Team von Li Feifei schlug ReKep vor, um Robotern räumliche Intelligenz zu verleihen und GPT-4o zu integrieren
Sep 03, 2024 pm 05:18 PM
Tiefe Integration von Vision und Roboterlernen. Wenn zwei Roboterhände reibungslos zusammenarbeiten, um Kleidung zu falten, Tee einzuschenken und Schuhe zu packen, gepaart mit dem humanoiden 1X-Roboter NEO, der in letzter Zeit für Schlagzeilen gesorgt hat, haben Sie vielleicht das Gefühl: Wir scheinen in das Zeitalter der Roboter einzutreten. Tatsächlich sind diese seidigen Bewegungen das Produkt fortschrittlicher Robotertechnologie + exquisitem Rahmendesign + multimodaler großer Modelle. Wir wissen, dass nützliche Roboter oft komplexe und exquisite Interaktionen mit der Umgebung erfordern und die Umgebung als Einschränkungen im räumlichen und zeitlichen Bereich dargestellt werden kann. Wenn Sie beispielsweise möchten, dass ein Roboter Tee einschenkt, muss der Roboter zunächst den Griff der Teekanne ergreifen und sie aufrecht halten, ohne den Tee zu verschütten, und ihn dann sanft bewegen, bis die Öffnung der Kanne mit der Öffnung der Tasse übereinstimmt , und neigen Sie dann die Teekanne in einem bestimmten Winkel. Das
