
 Technologie-Peripheriegeräte
KI
Kann die KI-Forschung auch vom Impressionismus lernen? Bei diesen lebensechten Menschen handelt es sich tatsächlich um 3D-Modelle
Technologie-Peripheriegeräte
KI
Kann die KI-Forschung auch vom Impressionismus lernen? Bei diesen lebensechten Menschen handelt es sich tatsächlich um 3D-Modelle
Kann die KI-Forschung auch vom Impressionismus lernen? Bei diesen lebensechten Menschen handelt es sich tatsächlich um 3D-Modelle


Das 19. Jahrhundert war die Zeit, in der die Kunstbewegung des Impressionismus populär war. Die Bewegung hatte Einfluss auf die Bereiche Malerei, Bildhauerei, Druckgrafik und andere Künste. Der Impressionismus zeichnete sich durch die Verwendung kurzer Staccato-Pinselstriche mit geringem Streben nach formaler Präzision aus und entwickelte sich später zum impressionistischen Kunststil. Kurz gesagt, die Pinselstriche des impressionistischen Künstlers sind unverändert, weisen offensichtliche Merkmale auf, streben nicht nach formaler Präzision und sind sogar etwas vage. Impressionistische Künstler führten die wissenschaftlichen Konzepte von Licht und Farbe in Gemälde ein und revolutionierten traditionelle Farbkonzepte.
In D3GA hat der Autor ein einzigartiges Ziel. Er hofft, durch das Gegenteil einen fotorealistischen Leistungseffekt zu erzielen. Um dieses Ziel zu erreichen, nutzte der Autor auf kreative Weise die Gaußsche Splatter-Technologie in D3GA als modernen „Segmentpinselstrich“, um die Struktur und das Erscheinungsbild virtueller Charaktere aufzubauen und einen stabilen Echtzeiteffekt zu erzielen.

„Sunrise·Impression“ ist das repräsentative Werk des berühmten impressionistischen Malers Monet.

Um realistische menschliche Bilder zu erstellen, die neue Inhalte für Animationen generieren können, erfordert die Konstruktion von Avataren derzeit eine große Menge an Multiview-Daten. Dies liegt daran, dass monokulare Methoden nur eine begrenzte Genauigkeit aufweisen. Darüber hinaus erfordern bestehende Techniken eine komplexe Vorverarbeitung, einschließlich einer genauen 3D-Registrierung. Die Beschaffung dieser Registrierungsdaten erfordert jedoch eine Iteration und lässt sich nur schwer in einen End-to-End-Prozess integrieren. Darüber hinaus gibt es Methoden, die keine genaue Registrierung erfordern und auf neuronalen Strahlungsfeldern (NeRFs) basieren. Allerdings sind diese Methoden beim Echtzeit-Rendering oft langsam oder haben Schwierigkeiten bei der Kleidungsanimation.
Kerbl et al. schlugen eine Rendering-Methode namens 3D Gaussian Splatting (3DGS) vor, die auf der Grundlage der klassischen Surface Splatting-Rendering-Methode verbessert wurde. Im Vergleich zu modernsten Methoden, die auf neuronalen Strahlungsfeldern basieren, ist 3DGS in der Lage, qualitativ hochwertigere Bilder mit schnelleren Bildraten und ohne die Notwendigkeit einer hochpräzisen 3D-Initialisierung zu rendern.
Allerdings wurde 3DGS ursprünglich für statische Szenen entwickelt. Gegenwärtig haben einige Leute die auf Zeitbedingungen basierende Gaußsche Splating-Methode vorgeschlagen, mit der dynamische Szenen gerendert werden können. Diese Methode kann nur das wiedergeben, was zuvor beobachtet wurde, und ist daher nicht geeignet, neue oder bisher ungesehene Bewegungen auszudrücken.
Basierend auf dem angetriebenen neuronalen Strahlungsfeld modelliert der Autor das Aussehen und die Verformung von 3D-Menschen, indem er sie in einen normalisierten Raum platziert, aber 3D-Gaußsche Operatoren anstelle von Strahlungsfeldern verwendet. Neben einer besseren Leistung macht Gaussian Splatting die Verwendung der Kamerastrahl-Sampling-Heuristik überflüssig.
Das verbleibende Problem besteht darin, die Signale zu definieren, die diese Käfigverformungen auslösen. Aktuelle hochmoderne Technologien in fahrerbasierten Avataren erfordern dichte Eingangssignale, wie etwa RGB-D-Bilder oder sogar mehrere Kameras, aber diese Methoden sind möglicherweise nicht für Situationen geeignet, in denen die Übertragungsbandbreite relativ gering ist. In dieser Studie verwenden die Autoren kompaktere Eingaben, die auf menschlichen Posen basieren, einschließlich Skelettgelenkwinkeln und 3D-Gesichtsschlüsselpunkten in Form von Quaternionen.
Durch das Training individueller Modelle an neun hochwertigen Multi-View-Sequenzen, die eine Vielzahl von Körperformen, Bewegungen und Kleidung (nicht nur intime Kleidung) abdecken, können wir später neue Posen für jedes Motiv erstellen.
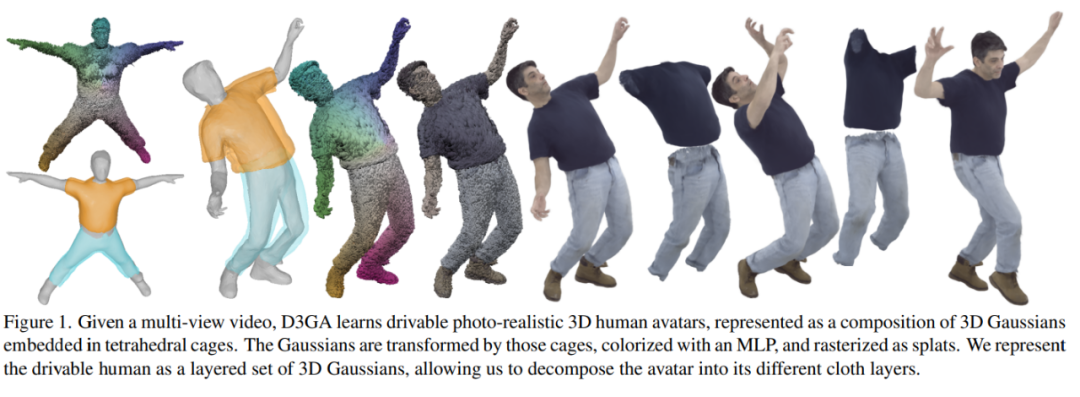

Methodenübersicht

- Papierlink: https://arxiv.org/pdf/2311.08581.pdf
- Projektlink: https://zielon.github.io/d3ga/
Derzeit verwendete Methoden Für die dynamische Volumetrisierung virtueller Zeichen werden entweder Punkte vom Deformationsraum in den kanonischen Raum abgebildet oder ausschließlich auf Vorwärtsabbildung zurückgegriffen. Auf Backmapping basierende Methoden neigen dazu, Fehler im kanonischen Raum anzuhäufen, da sie einen fehleranfälligen Backpass erfordern und bei der Modellierung perspektivenabhängiger Effekte problematisch sind.
Daher hat sich der Autor für die reine Vorwärtszuordnungsmethode entschieden. D3GA basiert auf 3DGS und wird durch neuronale Darstellung und Käfig erweitert, um die Farbe und die geometrische Form jedes dynamischen Teils des virtuellen Charakters zu modellieren.
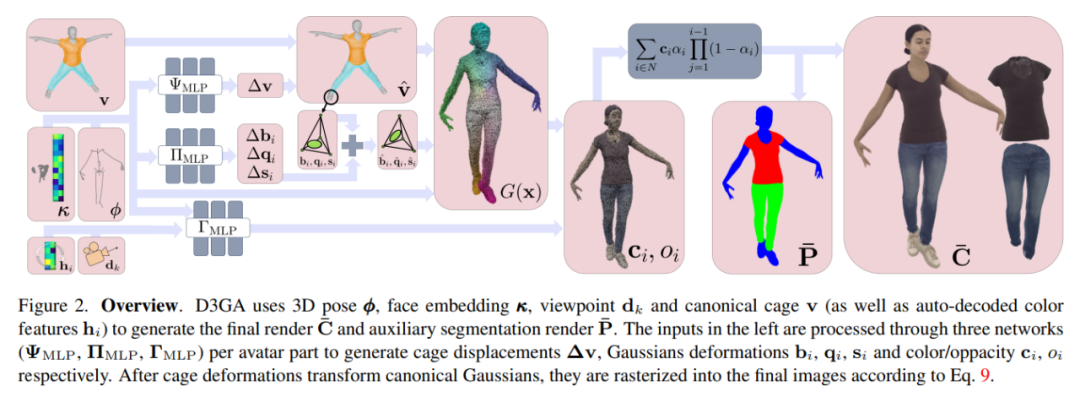
D3GA verwendet die 3D-Pose ϕ, die Gesichtseinbettung κ, den Blickwinkel dk und den kanonischen Käfig v (und automatisch dekodierte Farbmerkmale hi), um das endgültige Render C¯ und das Hilfssegmentierungsrendering P¯ zu generieren. Die Eingabe auf der linken Seite wird über drei Netzwerke (ΨMLP, ΠMLP, ΓMLP) pro virtuellem Zeichenteil verarbeitet, um Käfigverschiebung Δv, Gaußsche Verformungen bi, qi, si und Farbe/Transparenz ci, oi zu erzeugen.
Nachdem die Käfigverformung die kanonische Gaußsche Funktion verformt, werden sie über Gleichung 9 in das endgültige Bild gerastert.
Experimentelle Ergebnisse
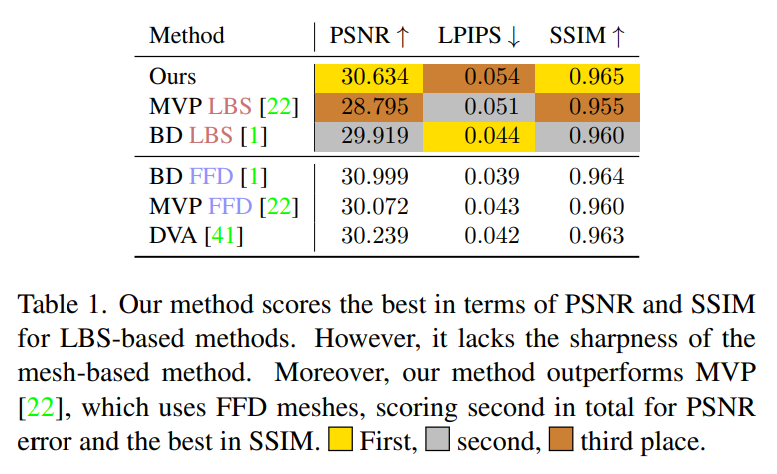
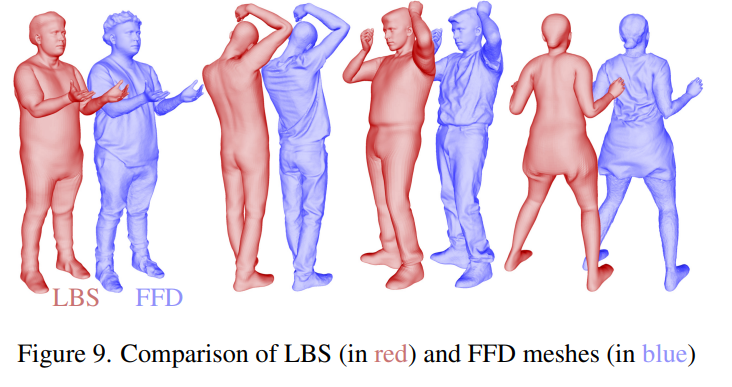
D3GA wird anhand von Metriken wie SSIM, PSNR und der Wahrnehmungsmetrik LPIPS bewertet. Tabelle 1 zeigt, dass D3GA unter den Methoden, die nur LBS verwenden (d. h. es besteht keine Notwendigkeit, 3D-Daten für jeden Frame zu scannen), die beste Leistung bei PSNR und SSIM aufweist und bei diesen Indikatoren alle FFD-Methoden übertrifft, nur an zweiter Stelle nach BD FFD, trotz schlechtem Trainingssignal und fehlender Testbilder (DVA wurde mit allen 200 Kameras getestet).
Der qualitative Vergleich zeigt, dass D3GA Kleidung besser modellieren kann als andere hochmoderne Methoden, insbesondere lockere Kleidung wie Röcke oder Jogginghosen (Abbildung 4). FFD steht für Free Deformation Mesh und enthält umfangreichere Trainingssignale als LBS-Netze (Abbildung 9).

Im Vergleich zur volumenbasierten Methode kann die Methode des Autors die Kleidung des virtuellen Charakters trennen, und die Kleidung ist auch fahrbar. Abbildung 5 zeigt, dass jede einzelne Kleidungsstückschicht allein durch die Winkel der Knochengelenke gesteuert werden kann, ohne dass ein spezielles Kleidungsstückregistrierungsmodul erforderlich ist.

Das obige ist der detaillierte Inhalt vonKann die KI-Forschung auch vom Impressionismus lernen? Bei diesen lebensechten Menschen handelt es sich tatsächlich um 3D-Modelle. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Detaillierte Erläuterung von Datenbanksäureattributen Säureattribute sind eine Reihe von Regeln, um die Zuverlässigkeit und Konsistenz von Datenbanktransaktionen sicherzustellen. Sie definieren, wie Datenbanksysteme Transaktionen umgehen, und sorgen dafür, dass die Datenintegrität und -genauigkeit auch im Falle von Systemabstürzen, Leistungsunterbrechungen oder mehreren Benutzern gleichzeitiger Zugriff. Säureattributübersicht Atomizität: Eine Transaktion wird als unteilbare Einheit angesehen. Jeder Teil schlägt fehl, die gesamte Transaktion wird zurückgerollt und die Datenbank behält keine Änderungen bei. Wenn beispielsweise eine Banküberweisung von einem Konto abgezogen wird, jedoch nicht auf ein anderes erhöht wird, wird der gesamte Betrieb widerrufen. begintransaktion; updateAccountsSetBalance = Balance-100WH
 Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Standort: Remote-Büro-Jobtyp: Vollzeitgehalt: 130.000 bis 140.000 US-Dollar Stellenbeschreibung Nehmen Sie an der Forschung und Entwicklung von Mobilfunkanwendungen und öffentlichen API-bezogenen Funktionen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken. Die Hauptaufgaben erledigen die Entwicklungsarbeit unabhängig von RubyonRails und arbeiten mit dem Front-End-Team von React/Redux/Relay zusammen. Erstellen Sie die Kernfunktionalität und -verbesserungen für Webanwendungen und arbeiten Sie eng mit Designer und Führung während des gesamten funktionalen Designprozesses zusammen. Fördern Sie positive Entwicklungsprozesse und priorisieren Sie die Iterationsgeschwindigkeit. Erfordert mehr als 6 Jahre komplexes Backend für Webanwendungen
 Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
MySQL kann JSON -Daten zurückgeben. Die JSON_EXTRACT -Funktion extrahiert Feldwerte. Über komplexe Abfragen sollten Sie die Where -Klausel verwenden, um JSON -Daten zu filtern, aber auf die Leistungsauswirkungen achten. Die Unterstützung von MySQL für JSON nimmt ständig zu, und es wird empfohlen, auf die neuesten Versionen und Funktionen zu achten.
 MySQL kann nach dem Herunterladen nicht installiert werden
Apr 08, 2025 am 11:24 AM
MySQL kann nach dem Herunterladen nicht installiert werden
Apr 08, 2025 am 11:24 AM
Die Hauptgründe für den Fehler bei MySQL -Installationsfehlern sind: 1. Erlaubnisprobleme, Sie müssen als Administrator ausgeführt oder den Sudo -Befehl verwenden. 2. Die Abhängigkeiten fehlen, und Sie müssen relevante Entwicklungspakete installieren. 3. Portkonflikte müssen Sie das Programm schließen, das Port 3306 einnimmt, oder die Konfigurationsdatei ändern. 4. Das Installationspaket ist beschädigt. Sie müssen die Integrität herunterladen und überprüfen. 5. Die Umgebungsvariable ist falsch konfiguriert und die Umgebungsvariablen müssen korrekt entsprechend dem Betriebssystem konfiguriert werden. Lösen Sie diese Probleme und überprüfen Sie jeden Schritt sorgfältig, um MySQL erfolgreich zu installieren.
 Master SQL Limit -Klausel: Steuern Sie die Anzahl der Zeilen in einer Abfrage
Apr 08, 2025 pm 07:00 PM
Master SQL Limit -Klausel: Steuern Sie die Anzahl der Zeilen in einer Abfrage
Apr 08, 2025 pm 07:00 PM
SQllimit -Klausel: Steuern Sie die Anzahl der Zeilen in Abfrageergebnissen. Die Grenzklausel in SQL wird verwendet, um die Anzahl der von der Abfrage zurückgegebenen Zeilen zu begrenzen. Dies ist sehr nützlich, wenn große Datensätze, paginierte Anzeigen und Testdaten verarbeitet werden und die Abfrageeffizienz effektiv verbessern können. Grundlegende Syntax der Syntax: SelectColumn1, Spalte2, ... Fromtable_Namelimitnumber_of_rows; number_of_rows: Geben Sie die Anzahl der zurückgegebenen Zeilen an. Syntax mit Offset: SelectColumn1, Spalte2, ... Fromtable_NamelimitOffset, Number_of_rows; Offset: Skip überspringen
