
 Technologie-Peripheriegeräte
KI
Durchgängiges, vorlagenfreies Antwortvorhersagemodell basierend auf Doppelaufgaben
Technologie-Peripheriegeräte
KI
Durchgängiges, vorlagenfreies Antwortvorhersagemodell basierend auf Doppelaufgaben
Durchgängiges, vorlagenfreies Antwortvorhersagemodell basierend auf Doppelaufgaben


Neu formatiert|.
Papierlink: https://doi.org/10.1007/s10489-023-05048-8Zugehöriger Code: https://github.com/AILBC/BiG2S Der Autor verwendet Ein Diagramm des aktuellen Aufstiegs auf dem Gebiet der templatfreien Retrosynthese. Basierend auf dem Sequenzmodell-Framework versuchen wir außerdem, ein Modell BiG2S (Bidirektionaler Graph zur Sequenz) zu erstellen, das gleichzeitig die Aufgaben der Retrosynthese-Vorhersage und der Vorwärtsreaktionsvorhersage in einem einzigen löst Modell auf derselben Parameterskala. Gleichzeitig untersucht der Autor auch die Mainstream-Inverse. Eine vorläufige Analyse wurde am synthetischen Datensatz USPTO-50k durchgeführt, um den Unterschied in der Vorhersageschwierigkeit verschiedener SMILES-Segmente während des Trainingsprozesses und der Fluktuation zu untersuchen der Top-k-Übereinstimmungsrate des Modells im Validierungssatz wurde ein Ungleichgewichtsverlust eingeführt, um diese Funktionsprobleme zu beheben und die Modellensemble- und Strahlsuchstrategien zu verbessern Reaktionsvorhersageaufgaben und durch umfassende Ablationsexperimente an den oben genannten Modulen ist BiG2S in der Lage, Retrosynthese- und Vorwärtsreaktionsvorhersageaufgaben mit einem einzigen Modell auf geeigneten Parameterskalen zu bewältigen. Im Vergleich zu bestehenden vorlagenfreien Methoden, die auf Vortraining und Datenverbesserung basieren, ist die allgemeine Vorhersagefähigkeit von BiG2S gleichermaßen hervorragend. Hintergrund der Forschung: Retrosynthese und Vorwärtssynthese sind organische Chemie, computergestützte Syntheseplanung (CASP). ) Und grundlegende Herausforderungen im Bereich des computergestützten Arzneimitteldesigns (CADD)
Der Autor verwendet Ein Diagramm des aktuellen Aufstiegs auf dem Gebiet der templatfreien Retrosynthese. Basierend auf dem Sequenzmodell-Framework versuchen wir außerdem, ein Modell BiG2S (Bidirektionaler Graph zur Sequenz) zu erstellen, das gleichzeitig die Aufgaben der Retrosynthese-Vorhersage und der Vorwärtsreaktionsvorhersage in einem einzigen löst Modell auf derselben Parameterskala. Gleichzeitig untersucht der Autor auch die Mainstream-Inverse. Eine vorläufige Analyse wurde am synthetischen Datensatz USPTO-50k durchgeführt, um den Unterschied in der Vorhersageschwierigkeit verschiedener SMILES-Segmente während des Trainingsprozesses und der Fluktuation zu untersuchen der Top-k-Übereinstimmungsrate des Modells im Validierungssatz wurde ein Ungleichgewichtsverlust eingeführt, um diese Funktionsprobleme zu beheben und die Modellensemble- und Strahlsuchstrategien zu verbessern Reaktionsvorhersageaufgaben und durch umfassende Ablationsexperimente an den oben genannten Modulen ist BiG2S in der Lage, Retrosynthese- und Vorwärtsreaktionsvorhersageaufgaben mit einem einzigen Modell auf geeigneten Parameterskalen zu bewältigen. Im Vergleich zu bestehenden vorlagenfreien Methoden, die auf Vortraining und Datenverbesserung basieren, ist die allgemeine Vorhersagefähigkeit von BiG2S gleichermaßen hervorragend. Hintergrund der Forschung: Retrosynthese und Vorwärtssynthese sind organische Chemie, computergestützte Syntheseplanung (CASP). ) Und grundlegende Herausforderungen im Bereich des computergestützten Arzneimitteldesigns (CADD)
Derzeit sind die Eingabe und Ausgabe der meisten templatfreien Retrosynthesemodelle SMILES-Molekülketten, d. h. sie verwenden einen Sequenz-zu-Sequenz-Prozess (Seq2Seq). Diese Methode kann das vorhandene Modellgerüst im Bereich der Verarbeitung natürlicher Sprache sowie den ausgereiften Datenverarbeitungsfluss für die SMILES-Darstellungsmethode gut nutzen. Da SMILES jedoch eine eindimensionale Zeichenfolgenfolge nicht gut darstellen und nutzen kann In diesem Bereich tauchen nach und nach zweidimensionale/dreidimensionale Strukturinformationen auf, die in molekularen Graphen enthalten sind, Graph-to-Sequence (Graph2Seq)-Methoden, die molekulare Graphen anstelle von SMILES als Modelleingabe verwenden, oder die zusätzlichen strukturellen Informationen von molekularen Graphen werden eingebettet in SMILES-Sequenzen umwandeln. Beide Methoden können die reichhaltigen Strukturmerkmale molekularer Graphen gut nutzen
Auf dieser Grundlage basiert dieser Artikel auf der neuen Graph-to-Sequence-Methode und trainiert die Retrosynthese- und Vorwärtsreaktionsvorhersageaufgaben gleichzeitig auf dem ursprünglichen SMILES-basierten Modell Basierend auf den relevanten Explorations-Benchmarks untersuchen wir den Aufbau und die Experimente dieser Art von Dual-Task-Modell weiter und untersuchen und analysieren vorläufig auch das Schwierigkeitsungleichgewicht und die Top-k-Matching-Rate-Schwankungen, die das Modell während des Trainingsprozesses anzeigt. ;Das auf dieser Basis aufgebaute BiG2S-Modell kann Retrosynthese- und Vorwärtsreaktionsvorhersageaufgaben in Mainstream-Datensätzen besser bewältigen und erreicht Reaktionsvorhersagefunktionen, die mit anderen vorlagenfreien Retrosynthesemodellen konsistent sind, ohne Datenverbesserung zu verwenden
Das Gesamtgerüst muss neu geschrieben werdenDie Gesamtstruktur von BiG2S ist ein End-to-End-Encoder-Decoder, wie in Abbildung 1 dargestellt. Die Encoder-Seite verwendet ein lokal gerichtetes Message-Passing-Graph-Netzwerk und einen globalen Graph-Transformer, der Informationen zur Graphstruktur-Bias einbezieht, um die endgültige molekulare Graph-Knotendarstellung zu generieren. Der Decoder verwendet einen Standard-Transformer-Decoder, um die SMILES-Sequenz des Zielmoleküls auf autoregressive Weise zu generieren
Es ist zu beachten, dass die Eingabe in den Decoder zusätzlich Doppel- enthält, um gleichzeitig Retrosynthese und Vorwärtsreaktionsvorhersage zu lernen. Ziffernfolgen ohne Hinzufügen von Positionsinformationen. Gleichzeitig verfügen die Normalisierungsschicht und die letzte lineare Schicht auf der Decoderseite über zwei Parametersätze, die zum Erlernen der Retrosyntheseaufgabe bzw. der Vorwärtsreaktionsvorhersageaufgabe verwendet werden
Abbildung 1: BiG2S-GesamtrahmendiagrammErfordert einen Trainingsrahmen für zwei Aufgaben
Retrosynthese und Vorwärtsreaktionsvorhersage sind zwei verwandte Aufgaben. Die Retrosyntheseaufgabe verwendet Produkte als Eingabe und Reaktanten als Zielausgabe, während die Vorwärtsreaktionsvorhersageaufgabe das Gegenteil bewirkt. Es besteht eine enge Verbindung zwischen diesen beiden Aufgaben, da sie durch Austausch der Eingabe und Zielausgabe der Retrosyntheseaufgabe in eine Vorwärtsreaktionsvorhersageaufgabe umgewandelt werden können. Daher haben einige auf SMILES basierende vorlagenfreie Modelle versucht, Synthese und Weiterleitung durchzuführen Reaktionsvorhersagen werden als Trainingsziele verwendet, um das Verständnis chemischer Reaktionen zu verbessern und bestimmte Ergebnisse zu erzielen. Basierend auf dieser Idee versuchte der Autor außerdem, Dual-Task-Training in das Graph-to-Sequence-Modell einzuführen
Insbesondere basierte der Autor auf der Parameter-Sharing-Strategie, die zuvor bei anderen Methoden in der Normalisierungsschicht des Decoders verwendet wurde Letzte lineare Schicht Es werden zwei Sätze aufgabenspezifischer Parameter erstellt. In anderen Modulen teilen sich die beiden Aufgabentypen eine Reihe von Parametern. Gleichzeitig werden den Eingabeknoten des Molekulargraphen und der anfänglichen Eingabesequenz des Decoders zusätzliche Dual-Task-Markierungen hinzugefügt. Auf diese Weise kann das Modell auch bei gleichzeitiger Steuerung der Gesamtmodellgröße zwischen den beiden Aufgabentypen unterscheiden und ihre unterschiedlichen Datenverteilungen lernen
Erfordert Training und InferenzoptimierungWährend des Trainingsprozesses hat der Autor weiter aufgezeichnet und analysierte die beiden Arten von Problemen des Modells, die sich im Trainingsprozess widerspiegelten
Zuerst zeichnete der Autor die Häufigkeit des Auftretens verschiedener SMILES-Zeichen in USPTO-50k und ihre entsprechende Vorhersagegenauigkeit während des Trainings auf, wie in Abbildung 2 dargestellt. Während des Trainingsprozesses erreichte der absolute Unterschied in der Gesamtvorhersagegenauigkeit für S und Br, die 0,4 % bzw. 0,3 % im Trainingssatz ausmachten, 8 %. Dies zeigt zunächst, dass es offensichtliche Unterschiede in der Vorhersageschwierigkeit zwischen verschiedenen molekularen Strukturen/Fragmenten gibt. Daher lindert der Autor solche Probleme durch die Einführung einer unausgeglichenen Verlustfunktion (z. B. Focal Loss), damit das Modell dem mehr Aufmerksamkeit schenken kann Genauigkeit während des Trainings.
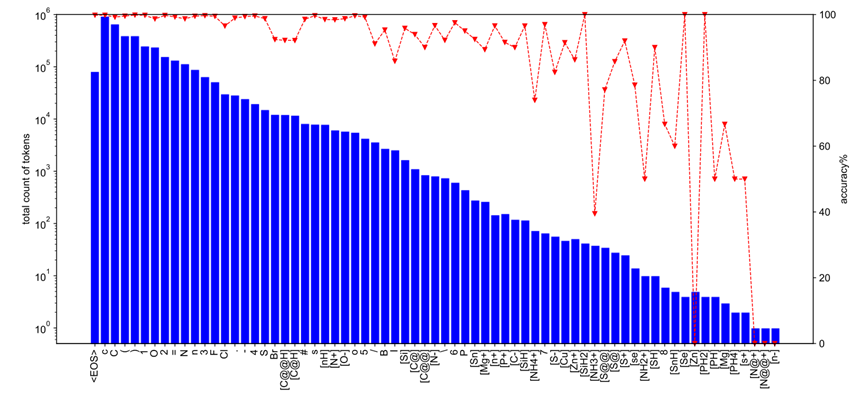 Abbildung 2: Im USPTO-50k-Trainingssatz die Häufigkeit des Auftretens verschiedener SMILES-Zeichen und ihre allgemeine Vorhersagegenauigkeit während des Trainings
Abbildung 2: Im USPTO-50k-Trainingssatz die Häufigkeit des Auftretens verschiedener SMILES-Zeichen und ihre allgemeine Vorhersagegenauigkeit während des Trainings
Darüber hinaus hat der Autor auch die Validierung aufgezeichnet Das Modell während des Trainings Die Qualität der Vorhersageergebnisse der Menge ändert sich, wie in Abbildung 3 dargestellt. Der Autor stellte fest, dass sich in der mittleren und späten Trainingsphase des USPTO-50k-Datensatzes die Top-1-Genauigkeit des Modells im Validierungssatz immer noch verbesserte, die Vorhersagequalität von Top-3 und Top-5 jedoch abnahm , und Top-10 Signifikanter Rückgang
Um die Top-1-Vorhersagequalität des Modells zu verbessern und gleichzeitig die Gesamtqualität der Top-10-Reaktantengenerierungsergebnisse des Modells beizubehalten, haben wir zusätzlich eine Art Modellintegrationsstrategie basierend auf benutzerdefinierten Bewertungsindikatoren entwickelt . Konkret erstellen wir eine Warteschlange zum Speichern von Modellen und sortieren die gespeicherten Modelle nach vordefinierten Bewertungsindikatoren (wie Top-1-Genauigkeit, gewichtete Top-k-Genauigkeit usw.). Während des gesamten Trainingsprozesses speichern wir Kandidatenmodelle dynamisch und generieren automatisch Ensemblemodelle basierend auf den Top 3–5 in der Warteschlange, wodurch die Top-k-Modelle mit der höchsten Vorhersagequalität beibehalten werden. In der Inferenzphase haben wir auch die Strahlsuchstrategie basierend auf dem neuen Framework neu aufgebaut und uns mehr auf die Suchbreite konzentriert, um die Gesamtqualität der von Top-k generierten Ergebnisse des Modells zu verbessern
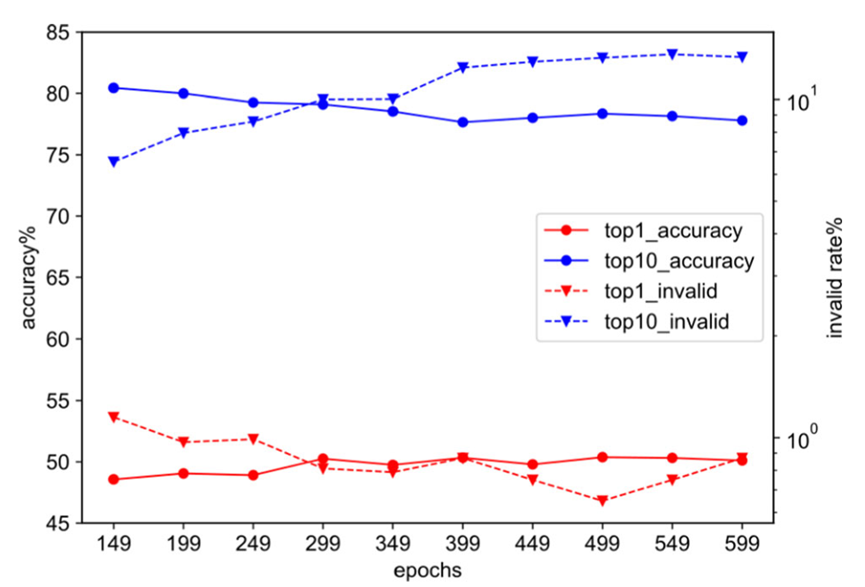 Abbildung 3: Während des Trainings im USPTO- 50k-Datensatz Die Änderungskurve der Top-k-Übereinstimmungsrate des Modells im Validierungssatz und der Anteil der Top-k-ungültig generierten Moleküle
Abbildung 3: Während des Trainings im USPTO- 50k-Datensatz Die Änderungskurve der Top-k-Übereinstimmungsrate des Modells im Validierungssatz und der Anteil der Top-k-ungültig generierten Moleküle
Der Autor hat durchgeführt es in der Retrosyntheseaufgabe und der Vorwärtsreaktionsvorhersageaufgabe. Das Experiment wurde unter Verwendung der Datensätze USPTO-50k, USPTO-MIT und USPTO-full durchgeführt, die 50.000, 500.000 und 1 Million chemische Reaktionsdaten enthielten. Im Experiment wurde die Leistung des Dual-Task-Modells und des Single-Task-Modells verglichen. Gemäß den Testergebnissen in Abbildung 4:
Im kleinen Datensatz erreichte BiG2S eine führende Vorhersagegenauigkeit bei der Retrosyntheseaufgabe basierend auf dem Dual-Task-Training und behielt gleichzeitig eine hohe Vorwärtsreaktionsvorhersagegenauigkeit bei, war jedoch verzerrt Im USPTO-MIT-Datensatz zur Reaktionsvorhersage und im groß angelegten Datensatz USPTO-full ist die Leistung des Modells nach dem Dual-Task-Training aufgrund der Begrenzung der Gesamtparametermenge beeinträchtigt verringert. Dennoch wurde die Fähigkeit, die Retrosyntheseaufgabe und die Vorwärtsreaktionsvorhersageaufgabe gleichzeitig zu verarbeiten, aus dem Dual-Task-Modell mit nahezu der gleichen Anzahl von Parametern und einer geringfügigen Verringerung der Antwortvorhersagefähigkeit erhalten (der absolute Unterschied in der Top-k-Genauigkeit beträgt ca 0,5 %). Aus Sicht der Fähigkeiten hat das BiG2S-Modell die erwarteten Ziele erreicht die Verwendung von Einzelaufgaben Das Modell führt jeweils zwei Arten von Aufgaben aus
Analysieren Sie das Ablationsexperiment erneut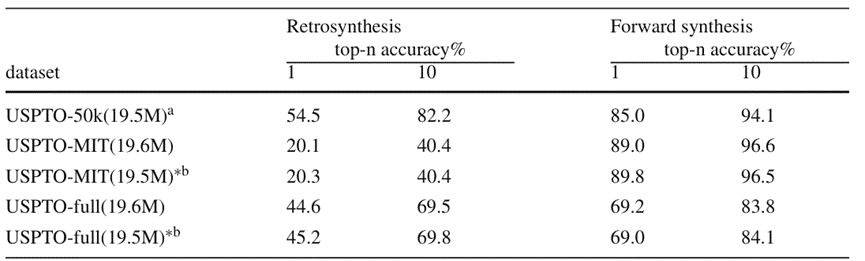
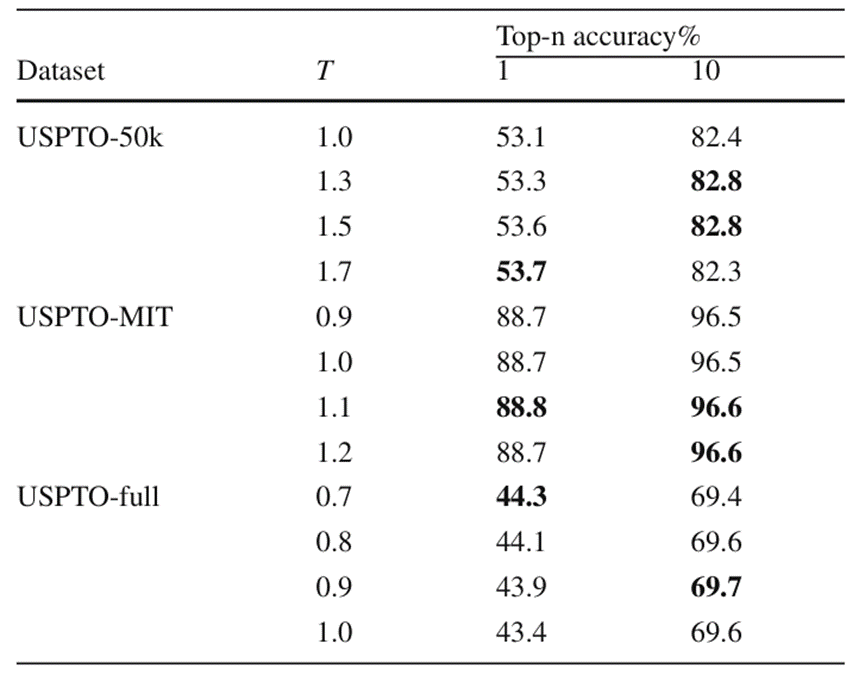
Der Autor verifizierte außerdem den neuen Strahlsuchalgorithmus und die optimalen Temperaturhyperparameter von BiG2S bei der Vorhersage in verschiedenen Datensätzen nach Verwendung von Ungleichgewichtsverlusten durch Ablationsexperimente. Der Temperatur-Hyperparameter bezieht sich hier auf den Temperaturparameter T, der in Softmax zur Steuerung der Ausgabewahrscheinlichkeitsverteilung verwendet wird. Die experimentellen Ergebnisse sind in Abbildung 5 und Abbildung 6 dargestellt
Im Experiment zum Strahlsuchalgorithmus kann beobachtet werden, dass OpenNMT die Suchbreite auf das Dreifache erweiterte, während sich die Suchzeit bei der neuen Strahlsuche nur auf das 1,74-fache erweiterte Algorithmus Wenn die Top-1-Genauigkeit mit OpenNMT übereinstimmt, erhöht sich die Gesamtsuchzeit um das 1-2-fache, aber in Bezug auf die Qualität der Top-10-Vorhersageergebnisse hat der neue Strahlsuchalgorithmus einen absoluten Genauigkeitsvorteil von mindestens 3 % im Vergleich zu OpenNMT. Neben einem effektiven Molekülverhältnisvorteil von 2 % kann man sagen, dass der neue Strahlsuchalgorithmus die Qualität der gesamten Top-k-Suchergebnisse des Modells auf Kosten der Suchzeit erheblich verbessert hat
Bei der Durchführung von Experimenten zu Temperatur-Hyperparametern stellten die Forscher fest, dass die Verwendung größerer Temperaturparameter in kleinen Datensätzen die Gesamtgenauigkeit der Top-k-Vorhersage erheblich verbessern kann. Da sich die BiG2S-Modellgröße bei größeren Datensätzen nicht vollständig an alle Reaktionsdaten anpassen kann, hilft die Auswahl kleinerer Temperaturparameter zu diesem Zeitpunkt oft bei der Modellsuche

 Die Schlussfolgerung der Studie zeigt...
Die Schlussfolgerung der Studie zeigt...
Um die Probleme der ungleichmäßigen Vorhersageschwierigkeit verschiedener SMILES-Zeichen und der Schwankungen der Top-k-Vorhersagegenauigkeit während des Modelltrainings zu lösen, führte der Autor einen Ungleichgewichtsverlust, eine automatische Modellintegrationsstrategie basierend auf benutzerdefinierten Bewertungsindikatoren und einen Strahlsuchalgorithmus basierend auf a ein Neues Framework zur Linderung dieser Probleme
BiG2S hat gute Dual-Task-Vorhersagefähigkeiten für drei Mainstream-Datensätze unterschiedlicher Größe gezeigt, und weitere Ablationsexperimente haben auch die Wirksamkeit der zusätzlich eingeführten Trainings- und Inferenzstrategien bewiesenDas obige ist der detaillierte Inhalt vonDurchgängiges, vorlagenfreies Antwortvorhersagemodell basierend auf Doppelaufgaben. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Jenseits von ORB-SLAM3! SL-SLAM: Szenen mit wenig Licht, starkem Jitter und schwacher Textur werden verarbeitet
May 30, 2024 am 09:35 AM
Heute diskutieren wir darüber, wie Deep-Learning-Technologie die Leistung von visionbasiertem SLAM (Simultaneous Localization and Mapping) in komplexen Umgebungen verbessern kann. Durch die Kombination von Methoden zur Tiefenmerkmalsextraktion und Tiefenanpassung stellen wir hier ein vielseitiges hybrides visuelles SLAM-System vor, das die Anpassung in anspruchsvollen Szenarien wie schlechten Lichtverhältnissen, dynamischer Beleuchtung, schwach strukturierten Bereichen und starkem Jitter verbessern soll. Unser System unterstützt mehrere Modi, einschließlich erweiterter Monokular-, Stereo-, Monokular-Trägheits- und Stereo-Trägheitskonfigurationen. Darüber hinaus wird analysiert, wie visuelles SLAM mit Deep-Learning-Methoden kombiniert werden kann, um andere Forschungen zu inspirieren. Durch umfangreiche Experimente mit öffentlichen Datensätzen und selbst abgetasteten Daten demonstrieren wir die Überlegenheit von SL-SLAM in Bezug auf Positionierungsgenauigkeit und Tracking-Robustheit.
 „Defect Spectrum' durchbricht die Grenzen der herkömmlichen Fehlererkennung und erreicht erstmals eine hochpräzise und umfassende semantische Fehlererkennung in der Industrie.
Jul 26, 2024 pm 05:38 PM
„Defect Spectrum' durchbricht die Grenzen der herkömmlichen Fehlererkennung und erreicht erstmals eine hochpräzise und umfassende semantische Fehlererkennung in der Industrie.
Jul 26, 2024 pm 05:38 PM
In der modernen Fertigung ist die genaue Fehlererkennung nicht nur der Schlüssel zur Sicherstellung der Produktqualität, sondern auch der Kern für die Verbesserung der Produktionseffizienz. Allerdings mangelt es vorhandenen Datensätzen zur Fehlererkennung häufig an der Genauigkeit und dem semantischen Reichtum, die für praktische Anwendungen erforderlich sind, was dazu führt, dass Modelle bestimmte Fehlerkategorien oder -orte nicht identifizieren können. Um dieses Problem zu lösen, hat ein Spitzenforschungsteam bestehend aus der Hong Kong University of Science and Technology Guangzhou und Simou Technology innovativ den „DefectSpectrum“-Datensatz entwickelt, der eine detaillierte und semantisch reichhaltige groß angelegte Annotation von Industriedefekten ermöglicht. Wie in Tabelle 1 gezeigt, bietet der Datensatz „DefectSpectrum“ im Vergleich zu anderen Industriedatensätzen die meisten Fehleranmerkungen (5438 Fehlerproben) und die detaillierteste Fehlerklassifizierung (125 Fehlerkategorien).
 Das NVIDIA-Dialogmodell ChatQA wurde auf Version 2.0 weiterentwickelt, wobei die angegebene Kontextlänge 128 KB beträgt
Jul 26, 2024 am 08:40 AM
Das NVIDIA-Dialogmodell ChatQA wurde auf Version 2.0 weiterentwickelt, wobei die angegebene Kontextlänge 128 KB beträgt
Jul 26, 2024 am 08:40 AM
Die offene LLM-Community ist eine Ära, in der hundert Blumen blühen und konkurrieren. Sie können Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 und viele andere sehen hervorragende Darsteller. Allerdings weisen offene Modelle im Vergleich zu den proprietären Großmodellen GPT-4-Turbo in vielen Bereichen noch erhebliche Lücken auf. Zusätzlich zu allgemeinen Modellen wurden einige offene Modelle entwickelt, die sich auf Schlüsselbereiche spezialisieren, wie etwa DeepSeek-Coder-V2 für Programmierung und Mathematik und InternVL für visuelle Sprachaufgaben.
 Google AI gewann die Silbermedaille der IMO Mathematical Olympiad, das mathematische Argumentationsmodell AlphaProof wurde eingeführt und Reinforcement Learning ist zurück
Jul 26, 2024 pm 02:40 PM
Google AI gewann die Silbermedaille der IMO Mathematical Olympiad, das mathematische Argumentationsmodell AlphaProof wurde eingeführt und Reinforcement Learning ist zurück
Jul 26, 2024 pm 02:40 PM
Für KI ist die Mathematikolympiade kein Problem mehr. Am Donnerstag hat die künstliche Intelligenz von Google DeepMind eine Meisterleistung vollbracht: Sie nutzte KI, um meiner Meinung nach die eigentliche Frage der diesjährigen Internationalen Mathematikolympiade zu lösen, und war nur einen Schritt davon entfernt, die Goldmedaille zu gewinnen. Der IMO-Wettbewerb, der gerade letzte Woche zu Ende ging, hatte sechs Fragen zu Algebra, Kombinatorik, Geometrie und Zahlentheorie. Das von Google vorgeschlagene hybride KI-System beantwortete vier Fragen richtig und erzielte 28 Punkte und erreichte damit die Silbermedaillenstufe. Anfang dieses Monats hatte der UCLA-Professor Terence Tao gerade die KI-Mathematische Olympiade (AIMO Progress Award) mit einem Millionenpreis gefördert. Unerwarteterweise hatte sich das Niveau der KI-Problemlösung vor Juli auf dieses Niveau verbessert. Beantworten Sie die Fragen meiner Meinung nach gleichzeitig. Am schwierigsten ist es meiner Meinung nach, da sie die längste Geschichte, den größten Umfang und die negativsten Fragen haben
 Training mit Millionen von Kristalldaten zur Lösung kristallographischer Phasenprobleme, die Deep-Learning-Methode PhAI wird in Science veröffentlicht
Aug 08, 2024 pm 09:22 PM
Training mit Millionen von Kristalldaten zur Lösung kristallographischer Phasenprobleme, die Deep-Learning-Methode PhAI wird in Science veröffentlicht
Aug 08, 2024 pm 09:22 PM
Herausgeber |KX Bis heute sind die durch die Kristallographie ermittelten Strukturdetails und Präzision, von einfachen Metallen bis hin zu großen Membranproteinen, mit keiner anderen Methode zu erreichen. Die größte Herausforderung, das sogenannte Phasenproblem, bleibt jedoch die Gewinnung von Phaseninformationen aus experimentell bestimmten Amplituden. Forscher der Universität Kopenhagen in Dänemark haben eine Deep-Learning-Methode namens PhAI entwickelt, um Kristallphasenprobleme zu lösen. Ein Deep-Learning-Neuronales Netzwerk, das mithilfe von Millionen künstlicher Kristallstrukturen und den entsprechenden synthetischen Beugungsdaten trainiert wird, kann genaue Elektronendichtekarten erstellen. Die Studie zeigt, dass diese Deep-Learning-basierte Ab-initio-Strukturlösungsmethode das Phasenproblem mit einer Auflösung von nur 2 Angström lösen kann, was nur 10 bis 20 % der bei atomarer Auflösung verfügbaren Daten im Vergleich zur herkömmlichen Ab-initio-Berechnung entspricht
 Der Standpunkt der Natur: Die Erprobung künstlicher Intelligenz in der Medizin ist im Chaos. Was ist zu tun?
Aug 22, 2024 pm 04:37 PM
Der Standpunkt der Natur: Die Erprobung künstlicher Intelligenz in der Medizin ist im Chaos. Was ist zu tun?
Aug 22, 2024 pm 04:37 PM
Herausgeber | ScienceAI Basierend auf begrenzten klinischen Daten wurden Hunderte medizinischer Algorithmen genehmigt. Wissenschaftler diskutieren darüber, wer die Werkzeuge testen soll und wie dies am besten geschieht. Devin Singh wurde Zeuge, wie ein pädiatrischer Patient in der Notaufnahme einen Herzstillstand erlitt, während er lange auf eine Behandlung wartete, was ihn dazu veranlasste, den Einsatz von KI zu erforschen, um Wartezeiten zu verkürzen. Mithilfe von Triage-Daten aus den Notaufnahmen von SickKids erstellten Singh und Kollegen eine Reihe von KI-Modellen, um mögliche Diagnosen zu stellen und Tests zu empfehlen. Eine Studie zeigte, dass diese Modelle die Zahl der Arztbesuche um 22,3 % verkürzen können und die Verarbeitung der Ergebnisse pro Patient, der einen medizinischen Test benötigt, um fast drei Stunden beschleunigt. Der Erfolg von Algorithmen der künstlichen Intelligenz in der Forschung bestätigt dies jedoch nur
 Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Um ein neues wissenschaftliches und komplexes Frage-Antwort-Benchmark- und Bewertungssystem für große Modelle bereitzustellen, haben UNSW, Argonne, die University of Chicago und andere Institutionen gemeinsam das SciQAG-Framework eingeführt
Jul 25, 2024 am 06:42 AM
Herausgeber | Der Frage-Antwort-Datensatz (QA) von ScienceAI spielt eine entscheidende Rolle bei der Förderung der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hochwertige QS-Datensätze können nicht nur zur Feinabstimmung von Modellen verwendet werden, sondern auch effektiv die Fähigkeiten großer Sprachmodelle (LLMs) bewerten, insbesondere die Fähigkeit, wissenschaftliche Erkenntnisse zu verstehen und zu begründen. Obwohl es derzeit viele wissenschaftliche QS-Datensätze aus den Bereichen Medizin, Chemie, Biologie und anderen Bereichen gibt, weisen diese Datensätze immer noch einige Mängel auf. Erstens ist das Datenformular relativ einfach, die meisten davon sind Multiple-Choice-Fragen. Sie sind leicht auszuwerten, schränken jedoch den Antwortauswahlbereich des Modells ein und können die Fähigkeit des Modells zur Beantwortung wissenschaftlicher Fragen nicht vollständig testen. Im Gegensatz dazu offene Fragen und Antworten
 AlphaFold 3 wird auf den Markt gebracht und sagt die Wechselwirkungen und Strukturen von Proteinen und allen Lebensmolekülen umfassend und mit weitaus größerer Genauigkeit als je zuvor voraus
Jul 16, 2024 am 12:08 AM
AlphaFold 3 wird auf den Markt gebracht und sagt die Wechselwirkungen und Strukturen von Proteinen und allen Lebensmolekülen umfassend und mit weitaus größerer Genauigkeit als je zuvor voraus
Jul 16, 2024 am 12:08 AM
Herausgeber | Rettichhaut Seit der Veröffentlichung des leistungsstarken AlphaFold2 im Jahr 2021 verwenden Wissenschaftler Modelle zur Proteinstrukturvorhersage, um verschiedene Proteinstrukturen innerhalb von Zellen zu kartieren, Medikamente zu entdecken und eine „kosmische Karte“ jeder bekannten Proteininteraktion zu zeichnen. Gerade hat Google DeepMind das AlphaFold3-Modell veröffentlicht, das gemeinsame Strukturvorhersagen für Komplexe wie Proteine, Nukleinsäuren, kleine Moleküle, Ionen und modifizierte Reste durchführen kann. Die Genauigkeit von AlphaFold3 wurde im Vergleich zu vielen dedizierten Tools in der Vergangenheit (Protein-Ligand-Interaktion, Protein-Nukleinsäure-Interaktion, Antikörper-Antigen-Vorhersage) deutlich verbessert. Dies zeigt, dass dies innerhalb eines einzigen einheitlichen Deep-Learning-Frameworks möglich ist
