
 Web-Frontend
HTML-Tutorial
Vergleichende Analyse von fünf verschiedenen Arten der lokalen Speicherung zur Verbesserung der Datenspeichereffizienz
Web-Frontend
HTML-Tutorial
Vergleichende Analyse von fünf verschiedenen Arten der lokalen Speicherung zur Verbesserung der Datenspeichereffizienz
Vergleichende Analyse von fünf verschiedenen Arten der lokalen Speicherung zur Verbesserung der Datenspeichereffizienz


Verbesserung der Datenspeichereffizienz: Vergleichende Analyse von fünf verschiedenen Methoden der lokalen Speicherung
Einführung:
Im heutigen Zeitalter der Informationsexplosion sind Datenspeicherung und -verwaltung besonders wichtig geworden. Bei der Webentwicklung müssen wir häufig einige Daten für die Verwendung auf verschiedenen Seiten oder Sitzungen speichern. Eine der am weitesten verbreiteten Methoden zur Datenspeicherung ist die Verwendung von Localstorage.
Localstorage ist ein von HTML5 bereitgestellter lokaler Speichermechanismus, der Daten dauerhaft im Browser speichern kann. Es basiert auf der Speicherung von Schlüssel-Wert-Paaren und unterstützt die Speicherung einfacher Datentypen wie Zeichenfolgen, Zahlen und boolesche Werte. Als Nächstes führen wir eine vergleichende Analyse von fünf verschiedenen Möglichkeiten zur Verwendung von Localstorage zur Verbesserung der Datenspeichereffizienz durch.
1. Speicherung einzelner Schlüssel-Wert-Paare
Die einfachste Möglichkeit, Localstorage zu verwenden, besteht darin, Daten als einzelnes Schlüssel-Wert-Paar zu speichern. Der Beispielcode lautet wie folgt:
// 存储数据
localStorage.setItem("name", "John");
// 读取数据
var name = localStorage.getItem("name");
console.log(name); // 输出: JohnDiese Methode eignet sich zum Speichern eines einzelnen Datenelements und ist sehr einfach und intuitiv. Wenn jedoch mehrere Datenelemente gespeichert werden müssen, ist die Verwendung von Localstorage ineffizient.
2. Objektspeicherung
Um die Mängel einer einzelnen Schlüssel-Wert-Paar-Methode zu beheben, können wir mehrere Datenelemente in einem Objekt kapseln und sie dann im lokalen Speicher speichern. Der Beispielcode lautet wie folgt:
// 存储数据
var user = {
name: "John",
age: 20,
gender: "male"
};
localStorage.setItem("user", JSON.stringify(user));
// 读取数据
var storedUser = JSON.parse(localStorage.getItem("user"));
console.log(storedUser.name); // 输出: JohnDurch die Konsolidierung mehrerer Datenelemente in einem Objekt können wir Daten bequemer verwalten und darauf zugreifen. Wenn es jedoch viele Datenelemente gibt oder die Datenstruktur komplex ist, kann dieser Ansatz zu langwierigem und schwer zu wartendem Code führen.
3. Array-Speicherung
Zusätzlich zur Objektmethode können wir Datenelemente auch als Array speichern. Der Beispielcode lautet wie folgt:
// 存储数据
var fruits = ["apple", "banana", "orange"];
localStorage.setItem("fruits", JSON.stringify(fruits));
// 读取数据
var storedFruits = JSON.parse(localStorage.getItem("fruits"));
console.log(storedFruits); // 输出: ["apple", "banana", "orange"]Die Verwendung von Arrays zum Speichern von Daten eignet sich für Szenarien, in denen die Datenreihenfolge beibehalten werden muss oder Durchlaufvorgänge erforderlich sind. Der Nachteil besteht darin, dass auf das Datenelement nicht direkt über den Schlüssel, sondern nur über den Indexwert zugegriffen werden kann.
4. Stapelspeicherung
Wenn eine große Datenmenge gespeichert werden muss, führt der alleinige Aufruf von setItem zur Speicherung zu Leistungseinbußen. Zu diesem Zeitpunkt kann die Stapelspeicherung verwendet werden, um die Daten in einem großen Objekt zu kapseln und dann zu speichern. Der Beispielcode lautet wie folgt:
// 存储数据
var data = {
key1: value1,
key2: value2,
// ...
};
localStorage.setItem("data", JSON.stringify(data));
// 读取数据
var storedData = JSON.parse(localStorage.getItem("data"));
console.log(storedData); // 输出: { key1: value1, key2: value2, ... }Die Stapelspeichermethode eignet sich für Situationen, in denen die Datenmenge groß ist oder auf alle Datenelemente häufig zugegriffen werden muss. Sie kann die Zugriffseffizienz und die Einfachheit des Codes verbessern.
5. Verwenden Sie Bibliotheken von Drittanbietern
Zusätzlich zum nativen lokalen Speicher gibt es viele Bibliotheken von Drittanbietern, die erweiterte Datenspeichermechanismen bieten. Beispielsweise können mit IndexedDB komplexere Abfrage- und Indizierungsfunktionen implementiert werden; mit PouchDB können erweiterte Funktionen wie Datensynchronisierung und Offline-Zugriff implementiert werden. Wenn Sie eine Bibliothek eines Drittanbieters auswählen, die Ihren Projektanforderungen entspricht, können Sie Daten flexibler speichern und verwalten.
Fazit:
Dieser Artikel führt eine vergleichende Analyse von fünf verschiedenen Arten der Verwendung von Localstorage durch, einschließlich der Speicherung einzelner Schlüssel-Wert-Paare, der Objektspeicherung, der Array-Speicherung, der Stapelspeicherung und der Verwendung von Bibliotheken von Drittanbietern. Für unterschiedliche Anwendungsszenarien und Anforderungen können wir die am besten geeignete Methode zur Verbesserung der Datenspeichereffizienz auswählen.
Es ist jedoch zu beachten, dass Localstorage zwar viele Vorteile hat, aber auch einige Einschränkungen aufweist, wie z. B. Einschränkungen der Speicherkapazität, Einschränkungen bei gleicher Herkunft usw. In praktischen Anwendungen sollten wir diese Faktoren umfassend berücksichtigen und die am besten geeignete Speicherlösung auswählen. Gleichzeitig wird zur Verbesserung der Datensicherheit empfohlen, die gespeicherten Daten zu verschlüsseln.
Kurz gesagt, im Zeitalter großer Datenmengen ist es sehr wichtig, die Effizienz der Datenspeicherung zu verbessern. Durch eine rationale Wahl der Verwendung von Localstorage können wir Daten effizienter speichern und verwalten und so die Projektentwicklung und das Benutzererlebnis besser unterstützen.
Das obige ist der detaillierte Inhalt vonVergleichende Analyse von fünf verschiedenen Arten der lokalen Speicherung zur Verbesserung der Datenspeichereffizienz. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

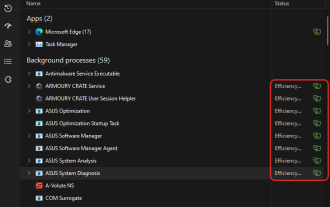 So aktivieren oder deaktivieren Sie den Produktivitätsmodus für eine App oder einen Prozess in Windows 11
Apr 14, 2023 pm 09:46 PM
So aktivieren oder deaktivieren Sie den Produktivitätsmodus für eine App oder einen Prozess in Windows 11
Apr 14, 2023 pm 09:46 PM
Der neue Task-Manager in Windows 11 22H2 ist ein Segen für Power-User. Es bietet jetzt eine bessere Benutzeroberfläche mit zusätzlichen Daten, um Ihre laufenden Prozesse, Aufgaben, Dienste und Hardwarekomponenten im Auge zu behalten. Wenn Sie den neuen Task-Manager verwendet haben, ist Ihnen möglicherweise der neue Produktivitätsmodus aufgefallen. Was ist das? Trägt es dazu bei, die Leistung von Windows 11-Systemen zu verbessern? Finden wir es heraus! Was ist der Produktivitätsmodus in Windows 11? Der Produktivitätsmodus ist eine der Aufgaben im Task-Manager
 Vergleichende Analyse der Funktionen und Leistung von JPA und MyBatis
Feb 19, 2024 pm 05:43 PM
Vergleichende Analyse der Funktionen und Leistung von JPA und MyBatis
Feb 19, 2024 pm 05:43 PM
JPA und MyBatis: Vergleichende Analyse von Funktion und Leistung Einführung: In der Java-Entwicklung spielt das Persistenz-Framework eine sehr wichtige Rolle. Zu den gängigen Persistenz-Frameworks gehören JPA (JavaPersistenceAPI) und MyBatis. In diesem Artikel wird eine vergleichende Analyse der Funktionen und Leistung der beiden Frameworks durchgeführt und spezifische Codebeispiele bereitgestellt. 1. Funktionsvergleich: JPA: JPA ist Teil von JavaEE und bietet eine objektorientierte Datenpersistenzlösung. Es wird eine Annotation oder X übergeben
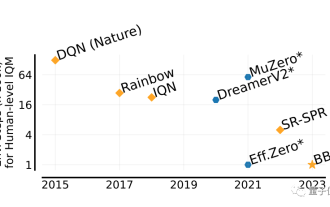 Er kann Menschen in zwei Stunden übertreffen! Die neueste KI von DeepMind führt 26 Atari-Spiele im Speedrun aus
Jul 03, 2023 pm 08:57 PM
Er kann Menschen in zwei Stunden übertreffen! Die neueste KI von DeepMind führt 26 Atari-Spiele im Speedrun aus
Jul 03, 2023 pm 08:57 PM
Der KI-Agent von DeepMind ist wieder am Werk! Achtung, dieser Typ namens BBF hat 26 Atari-Spiele in nur 2 Stunden gemeistert. Seine Effizienz ist der von Menschen ebenbürtig und übertrifft alle seine Vorgänger. Wissen Sie, KI-Agenten waren bei der Lösung von Problemen durch verstärkendes Lernen schon immer effektiv, aber das größte Problem besteht darin, dass diese Methode sehr ineffizient ist und lange Zeit zum Erkunden benötigt. Bild Der Durchbruch von BBF liegt im Hinblick auf die Effizienz. Kein Wunder, dass der vollständige Name Bigger, Better oder Faster lauten kann. Darüber hinaus kann das Training auf nur einer einzigen Karte durchgeführt werden, und auch der Bedarf an Rechenleistung wird deutlich reduziert. BBF wurde gemeinsam von Google DeepMind und der Universität Montreal vorgeschlagen und die Daten und der Code sind derzeit Open Source. Der höchstmögliche Mensch
 Welches ist für Sie besser geeignet, Vivox100 oder Vivox100Pro? Detaillierte vergleichende Analyse.
Mar 23, 2024 pm 01:12 PM
Welches ist für Sie besser geeignet, Vivox100 oder Vivox100Pro? Detaillierte vergleichende Analyse.
Mar 23, 2024 pm 01:12 PM
Mit der Popularität von Smartphones sind Kopfhörer zu einem unverzichtbaren Accessoire im Leben der Menschen geworden. Unter vielen Kopfhörermarken haben Vivox100 und Vivox100Pro große Aufmerksamkeit erregt. Welches ist also besser für Sie geeignet: Vivox100 oder Vivox100Pro? Als nächstes führen wir eine detaillierte Vergleichsanalyse in Bezug auf Erscheinungsbild, Klangqualität, Stromverbrauch, Kostenleistung usw. durch. In Bezug auf das Erscheinungsbild weisen Vivox100 und Vivox100Pro offensichtliche Unterschiede im Erscheinungsbild auf. V
 Praktischer Leitfaden zur PyCharm-Remote-Entwicklung: Verbessern Sie die Entwicklungseffizienz
Feb 23, 2024 pm 01:30 PM
Praktischer Leitfaden zur PyCharm-Remote-Entwicklung: Verbessern Sie die Entwicklungseffizienz
Feb 23, 2024 pm 01:30 PM
PyCharm ist eine leistungsstarke integrierte Python-Entwicklungsumgebung (IDE), die von Python-Entwicklern häufig zum Schreiben von Code, zum Debuggen und zum Projektmanagement verwendet wird. Im eigentlichen Entwicklungsprozess werden die meisten Entwickler mit unterschiedlichen Problemen konfrontiert sein, z. B. wie die Entwicklungseffizienz verbessert werden kann, wie mit Teammitgliedern bei der Entwicklung zusammengearbeitet werden kann usw. In diesem Artikel wird ein praktischer Leitfaden zur Remote-Entwicklung von PyCharm vorgestellt, der Entwicklern dabei hilft, PyCharm besser für die Remote-Entwicklung zu nutzen und die Arbeitseffizienz zu verbessern. 1. Vorbereitungsarbeit in PyCh
 Daten-Caching und lokaler Speicher-Erfahrungsaustausch bei der Vue-Projektentwicklung
Nov 03, 2023 am 09:15 AM
Daten-Caching und lokaler Speicher-Erfahrungsaustausch bei der Vue-Projektentwicklung
Nov 03, 2023 am 09:15 AM
Erfahrungsaustausch über Daten-Caching und lokale Speicherung in der Vue-Projektentwicklung Im Entwicklungsprozess eines Vue-Projekts sind Daten-Caching und lokale Speicherung zwei sehr wichtige Konzepte. Daten-Caching kann die Anwendungsleistung verbessern, während lokaler Speicher eine dauerhafte Speicherung von Daten ermöglichen kann. In diesem Artikel werde ich einige Erfahrungen und Praktiken bei der Verwendung von Daten-Caching und lokaler Speicherung in Vue-Projekten teilen. 1. Daten-Caching Beim Daten-Caching werden Daten im Speicher gespeichert, sodass sie schnell abgerufen und später verwendet werden können. In Vue-Projekten gibt es zwei häufig verwendete Daten-Caching-Methoden:
 Auswahl der MySQL-Speicher-Engine in Big-Data-Szenarien: Vergleichende Analyse von MyISAM, InnoDB und Aria
Jul 24, 2023 pm 07:18 PM
Auswahl der MySQL-Speicher-Engine in Big-Data-Szenarien: Vergleichende Analyse von MyISAM, InnoDB und Aria
Jul 24, 2023 pm 07:18 PM
Auswahl der MySQL-Speicher-Engine in Big-Data-Szenarien: Vergleichende Analyse von MyISAM, InnoDB und Aria Mit dem Aufkommen des Big-Data-Zeitalters sind herkömmliche Speicher-Engines angesichts hoher Parallelität und großer Datenmengen oft nicht in der Lage, die Geschäftsanforderungen zu erfüllen. Als eines der beliebtesten relationalen Datenbankverwaltungssysteme ist die Auswahl der Speicher-Engine von MySQL besonders wichtig. In diesem Artikel führen wir eine vergleichende Analyse von MyISAM, InnoDB und Aria durch, den Speicher-Engines, die MySQL häufig in Big-Data-Szenarien verwendet, und geben Folgendes an
 Privater Einsatz von Stable Diffusion zum Spielen mit KI-Zeichnung
Mar 12, 2024 pm 05:49 PM
Privater Einsatz von Stable Diffusion zum Spielen mit KI-Zeichnung
Mar 12, 2024 pm 05:49 PM
StableDiffusion ist ein Open-Source-Deep-Learning-Modell. Seine Hauptfunktion besteht in der Generierung hochwertiger Bilder durch Textbeschreibungen und unterstützt Funktionen wie Diagrammgenerierung, Modellzusammenführung und Modelltraining. Die Bedienoberfläche des Modells ist in der Abbildung unten zu sehen. So erstellen Sie ein Bild: Beim Erstellen eines Bildes wird es in Aufforderungswörter und negative Aufforderungswörter unterteilt Versuchen Sie, die gewünschte Szene, das gewünschte Objekt, den gewünschten Stil und die gewünschte Farbe klar zu beschreiben. Anstatt nur zu sagen: „Der Hirsch trinkt Wasser“, heißt es „ein Bach, umgeben von dichten Bäumen, und neben dem Bach gibt es Hirsche, die Wasser trinken“. Die negativen Aufforderungswörter lauten beispielsweise in der entgegengesetzten Richtung: Keine Gebäude, keine Menschen, keine Brücken, keine Zäune und eine zu vage Beschreibung können zu ungenauen Ergebnissen führen.
