
 Technologie-Peripheriegeräte
KI
Anwendung der Ursache-Wirkungs-Korrekturmethode in Empfehlungsszenarien für Ameisenmarketing
Technologie-Peripheriegeräte
KI
Anwendung der Ursache-Wirkungs-Korrekturmethode in Empfehlungsszenarien für Ameisenmarketing
Anwendung der Ursache-Wirkungs-Korrekturmethode in Empfehlungsszenarien für Ameisenmarketing

1. Hintergrund der kausalen Verzerrung
1. Entstehung von Verzerrungen
Im Empfehlungssystem wird das Empfehlungsmodell durch das Sammeln von Daten trainiert, um Benutzern geeignete Artikel zu empfehlen. Wenn Benutzer mit empfohlenen Elementen interagieren, werden die gesammelten Daten verwendet, um das Modell weiter zu trainieren und so einen geschlossenen Regelkreis zu bilden. Allerdings kann es in diesem geschlossenen Kreislauf verschiedene Einflussfaktoren geben, die zu Fehlern führen. Der Hauptgrund für den Fehler besteht darin, dass es sich bei den meisten zum Trainieren des Modells verwendeten Daten um Beobachtungsdaten und nicht um ideale Trainingsdaten handelt, die von Faktoren wie der Expositionsstrategie und der Benutzerauswahl beeinflusst werden. Der Kern dieser Verzerrung liegt im Unterschied zwischen den Erwartungen empirischer Risikoschätzungen und den Erwartungen echter idealer Risikoschätzungen.

2. Häufige Vorurteile
Zu den häufigeren Vorurteilen im Empfehlungsmarketingsystem gehören hauptsächlich die folgenden drei Arten:
- Selektive Voreingenommenheit: Dies ist darauf zurückzuführen, dass Benutzer sich aktiv dafür entscheiden, entsprechend zu interagieren zu ihren eigenen Präferenzen, die durch den Artikel verursacht werden.
- Belichtungsverzerrung: Empfohlene Elemente sind normalerweise nur eine Teilmenge des gesamten Elementkandidatenpools. Benutzer können bei der Auswahl nur mit den vom System empfohlenen Elementen interagieren, was zu einer Verzerrung der Beobachtungsdaten führt.
- Beliebtheitsbias: Der hohe Anteil einiger beliebter Elemente in den Trainingsdaten führt dazu, dass das Modell diese Leistung lernt und beliebtere Elemente empfiehlt, was den Matthew-Effekt verursacht.
Es gibt auch andere Abweichungen, wie z. B. Positionsabweichung, Konsistenzabweichung usw.
3. Kausale Korrektur
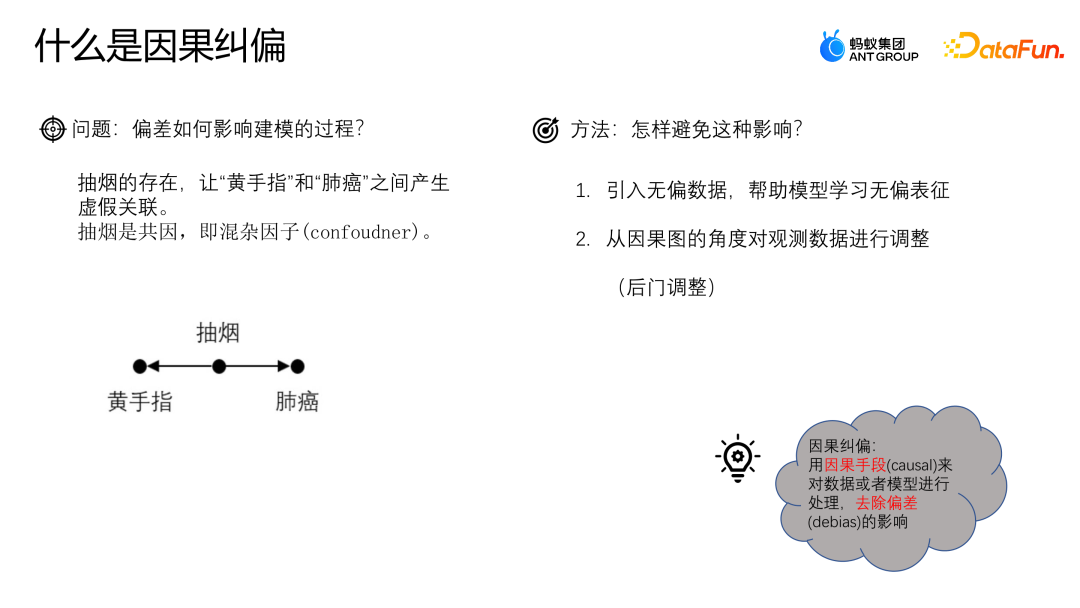
Lassen Sie uns anhand eines Beispiels die Auswirkungen der Abweichung auf den Modellierungsprozess verstehen. Angenommen, wir wollen den Zusammenhang zwischen Kaffeetrinken und Herzerkrankungen untersuchen. Wir haben herausgefunden, dass Kaffeetrinker ein höheres Risiko haben, an Herzerkrankungen zu erkranken. Daraus lässt sich schließen, dass ein direkter kausaler Zusammenhang zwischen Kaffeetrinken und Herzerkrankungen besteht. Wir müssen uns jedoch der Existenz von Störfaktoren bewusst sein. Angenommen, Kaffeetrinker sind mit größerer Wahrscheinlichkeit auch Raucher. Rauchen selbst ist mit Herzerkrankungen verbunden. Daher können wir den Zusammenhang zwischen Kaffeetrinken und Herzerkrankungen nicht einfach auf einen Kausalzusammenhang zurückführen, sondern können auf das Vorhandensein von Rauchen als Störfaktor zurückzuführen sein. Um den Zusammenhang zwischen Kaffeetrinken und Herzerkrankungen genauer zu untersuchen, müssen wir die Auswirkungen des Rauchens kontrollieren. Ein Ansatz besteht in der Durchführung von Matched-Studien, bei denen Raucher mit Nichtrauchern gepaart und dann hinsichtlich des Zusammenhangs zwischen Kaffeetrinken und Herzerkrankungen verglichen werden. Dadurch wird die verwirrende Wirkung des Rauchens auf die Ergebnisse eliminiert. Bei der Kausalität handelt es sich um die Frage, was wäre, wenn eine Änderung des Kaffeekonsums zu einer Änderung der Herzerkrankungen führen würde, während andere Bedingungen unverändert blieben. Erst nach Kontrolle der Auswirkungen von Störfaktoren können wir genauer bestimmen, ob ein kausaler Zusammenhang zwischen Kaffeetrinken und Herzerkrankungen besteht.
Wie kann dieses Problem vermieden werden? Eine gängige Methode besteht darin, unvoreingenommene Daten einzuführen und dem Modell beim Erlernen unvoreingenommener Darstellungen zu helfen. Eine andere Methode besteht darin, aus der Perspektive des Kausaldiagramms zu beginnen und die Abweichung durch Anpassen der Beobachtung zu korrigieren Daten später. Bei der Kausalkorrektur geht es darum, Daten oder Modelle mit kausalen Mitteln zu verarbeiten, um den Einfluss von Verzerrungen zu beseitigen.
4. Ursache-Wirkungs-Diagramm
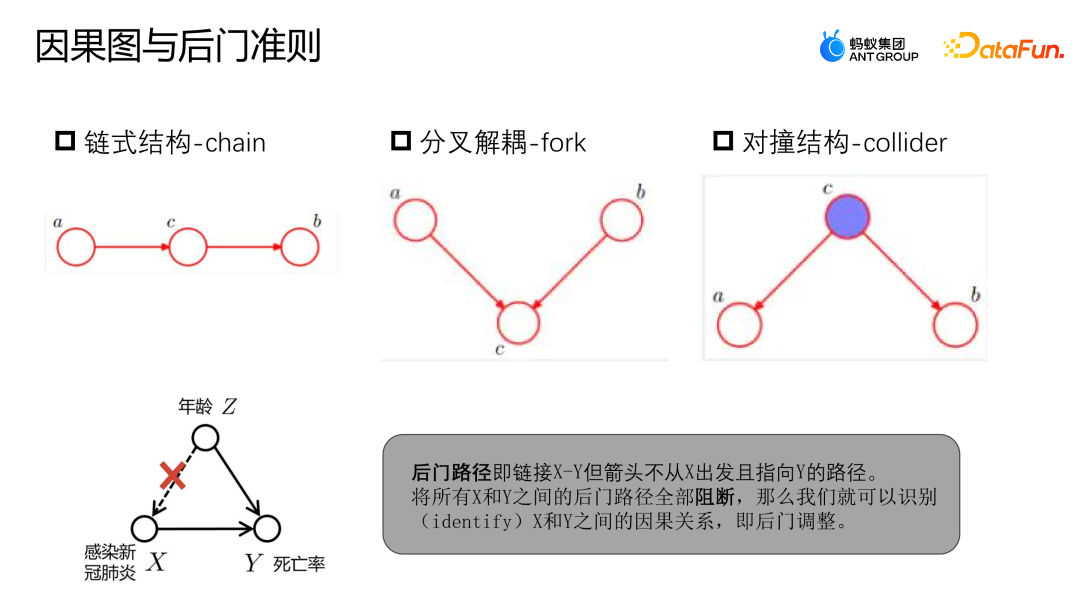
Ein Ursache-Wirkungs-Diagramm ist ein gerichteter azyklischer Graph, der zur Beschreibung der Kausalbeziehung zwischen Knoten in der Szene verwendet wird. Es besteht aus einer Kettenstruktur, einer Bifurkationsstruktur und einer Kollisionsstruktur.
- Kettenstruktur: Gegeben C, A und B sind unabhängig.
- Gegabelte Struktur: Wenn sich bei gegebenem C A ändert, ändert sich B nicht entsprechend.
- Kollisionsstruktur: In Abwesenheit von C kann nicht beobachtet werden, dass A und B unabhängig sind, aber nach Beobachtung von C sind A und B nicht unabhängig.
Sie können sich auf das Beispiel im Bild oben beziehen, um den Backdoor-Pfad und die Backdoor-Kriterien zu bestimmen. Der Backdoor-Pfad bezieht sich auf den Pfad, der X mit Y verbindet, aber bei Z beginnt und schließlich auf Y zeigt. Ähnlich wie im vorherigen Beispiel ist der Zusammenhang zwischen COVID-19-Infektion und Mortalität nicht rein kausal. Die Ansteckung mit COVID-19 hängt vom Alter ab. Ältere Menschen erkranken häufiger an COVID-19 und ihre Sterblichkeitsrate ist ebenfalls höher. Wenn wir jedoch über genügend Daten verfügen, um alle Hintertürpfade zwischen
2. Korrektur basierend auf Datenfusion
1. Einführung in das Datenfusionskorrekturmodell
welches in SIGIR2023 auf dem Industry Track veröffentlicht wurde. Die Idee der Arbeit besteht darin, unvoreingenommene Daten zu verwenden, um Daten zu erweitern und die Korrektur des Modells zu steuern.

Die Gesamtverteilung unverzerrter Daten unterscheidet sich von der Verteilung verzerrter Daten. Die verzerrten Daten konzentrieren sich auf einen bestimmten Teil des gesamten Probenraums und die fehlenden Proben konzentrieren sich auf einen Teil des Bereichs Wenn sich die erweiterte Stichprobe in der Nähe eines Bereichs mit mehr unverzerrten Daten befindet, spielen die unverzerrten Daten eine größere Rolle. Wenn die erweiterte Stichprobe in der Nähe eines Bereichs mit verzerrten Daten liegt, spielen die verzerrten Daten eine größere Rolle mehr Rollen. In diesem Artikel wird ein MDI-Modell entwickelt, um unvoreingenommene und voreingenommene Daten besser für die Datenerweiterung zu nutzen.

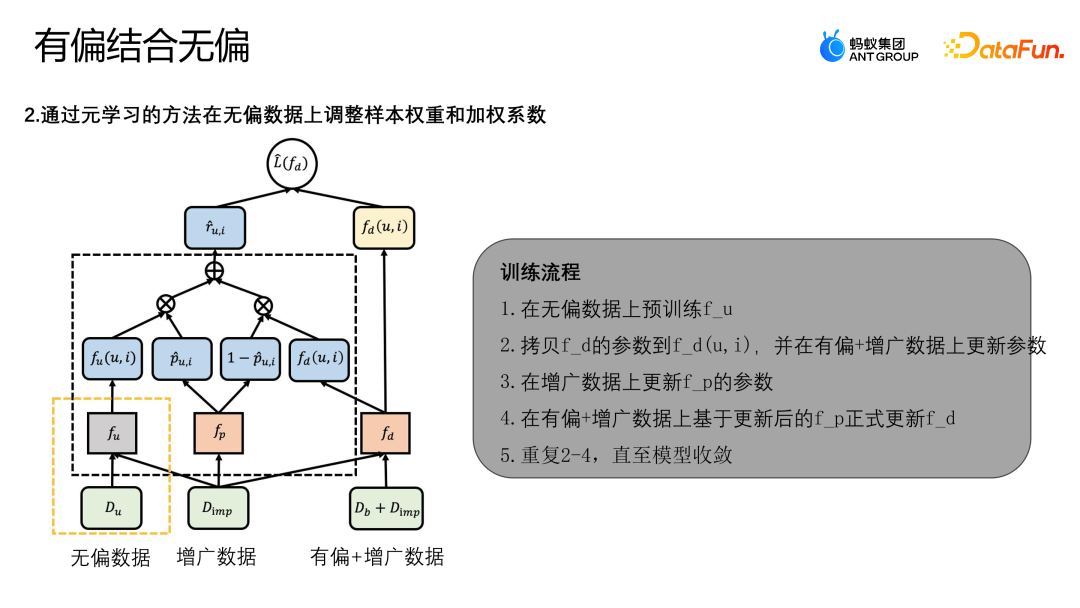
Die obige Abbildung zeigt das Rahmendiagramm des Algorithmus. Das MDI-Modell verwendet die Meta-Lernmethode, um das Gewicht der Stichprobe und den gewichteten Koeffizienten an unvoreingenommenen Daten anzupassen. Zunächst einmal gibt es beim MDI-Modelltraining zwei Phasen:
- Phase 1: Verwenden Sie unvoreingenommene Daten, um das unvoreingenommene Lehrermodell fu zu trainieren.
- Stufe 2: Verwenden Sie die ursprüngliche Lernmethode, um andere Strukturen im schematischen Diagramm zu aktualisieren.
Trainieren Sie das Fusions-Debiasing-Modell fd, indem Sie den Betriebsverlust von L(fd) optimieren. Der endgültige Verlustverlust besteht hauptsächlich aus zwei Arten, einer ist L-IPS und der andere ist L-IMP. L-IPS ist ein IPS-Modul, das wir zur Optimierung anhand von Originalstichproben verwenden. R-UI verwendet ein beliebiges Modell, um den Neigungswert abzuleiten (Bestimmung der Wahrscheinlichkeit, dass eine Stichprobe zu einer unverzerrten Stichprobe gehört, oder der Wahrscheinlichkeit, dass sie zu einer verzerrten Stichprobe gehört). ; das zweite Element ist L-IMP das Gewicht des voreingestellten Erweiterungsmoduls, R-UI ist der vom voreingestellten Erweiterungsmodul generierte Endindex und 1-P-UI sind das unvoreingenommene Lehrermodell und das aktuelle Fusionsmodell Der Neigungswert der Methode zum Erlernen komplexerer Musterinformationen wird durch Meta-Lernen gelöst.
Das Folgende ist der vollständige Trainingsprozess des Algorithmus:
- Fu auf unvoreingenommenen Daten vorab trainieren.
- Kopieren Sie die Parameter von fd nach fd(u,i) und aktualisieren Sie die Parameter für die voreingenommenen + erweiterten Daten.
- Aktualisieren Sie die Parameter von fp anhand der erweiterten Daten.
- Aktualisieren Sie fd offiziell basierend auf dem aktualisierten fp auf voreingenommenen + erweiterten Daten.
- Wiederholen Sie 2-4, bis das Modell konvergiert.
2. Experimentieren Sie mit dem Datenfusionskorrekturmodell
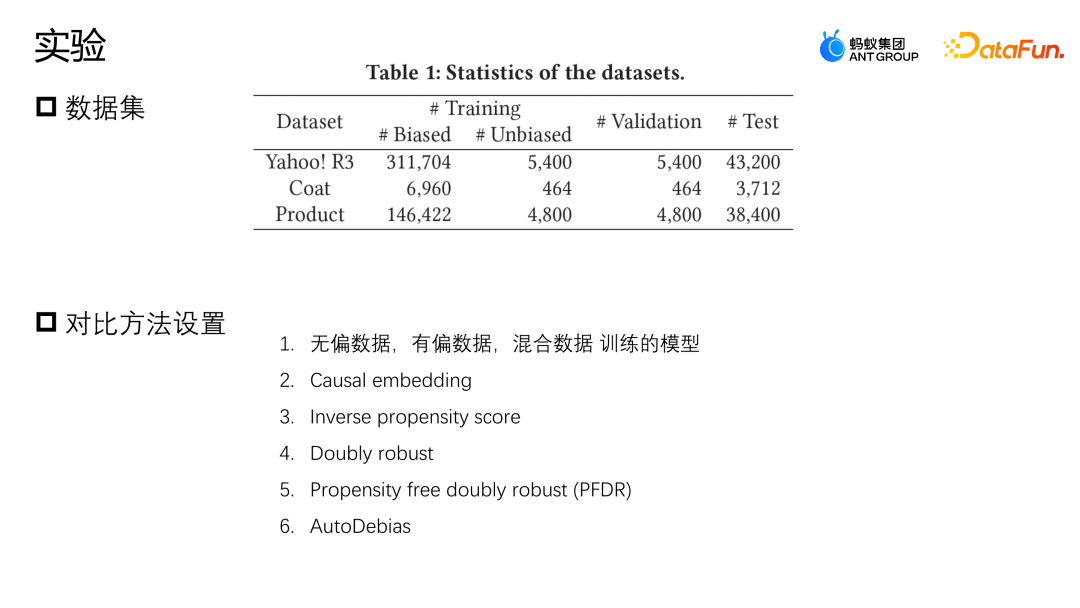
Wir haben eine Auswertung an zwei öffentlichen Datensätzen durchgeführt, Yahoo R3 und Coat. Yahoo R3 hat über 15.000 Benutzerbewertungen von 1.000 Songs gesammelt und insgesamt über 310.000 voreingenommene Daten und 5.400 unvoreingenommene Daten gesammelt. Der Coat-Datensatz sammelt über 6900 voreingenommene Daten und über 4600 unvoreingenommene Daten anhand von 290 Benutzerbewertungen von 300 Kleidungsstücken. Die Bewertungen der Benutzer in beiden Datensätzen reichen von 1 bis 5. Die voreingenommenen Daten stammen von den Datennutzern der Plattform, und die unvoreingenommenen Stichproben werden durch zufällige Auswahl und Bewertung von Benutzern gesammelt.
Zusätzlich zu zwei öffentlichen Datensätzen verwendete Ant auch einen Datensatz aus tatsächlichen Szenarien in der Branche. Um die Situation zu simulieren, in der es nur sehr wenige unvoreingenommene Datenstichproben gibt, haben wir alle voreingenommenen Daten und 10 % davon kombiniert unvoreingenommene Daten Für das Training werden 10 % der unvoreingenommenen Daten als Validierung beibehalten und die restlichen 80 % werden als Testsatz verwendet.Die von uns verwendeten Basisvergleichsmethoden sind hauptsächlich wie folgt: Die erste Methode besteht darin, Modelle zu verwenden, die durch unvoreingenommene Daten, einzelne voreingenommene Daten bzw. direkte Datenfusion trainiert wurden, und die zweite Methode darin, einen kleinen Teil unvoreingenommener Daten zu verwenden. Eine reguläre Darstellung soll die Ähnlichkeit von verzerrten Daten und unverzerrten Datendarstellungen einschränken, um Verzerrungskorrekturoperationen durchzuführen. Die dritte Methode ist die inverse Wahrscheinlichkeitsgewichtungsmethode, eine inverse Wahrscheinlichkeitsbewertung. Double Robust ist auch eine gängige Korrekturmethode; Propensity Free Double Robust ist eine Datenerweiterungsmethode, die zunächst unverzerrte Stichproben verwendet, um ein erweitertes Modell zu lernen, und dann die erweiterten Stichproben verwendet, um das gesamte Modell bei der Korrektur der Verzerrung zu unterstützen Unvoreingenommene Daten zur Erweiterung, um die Modellverzerrung zu korrigieren.
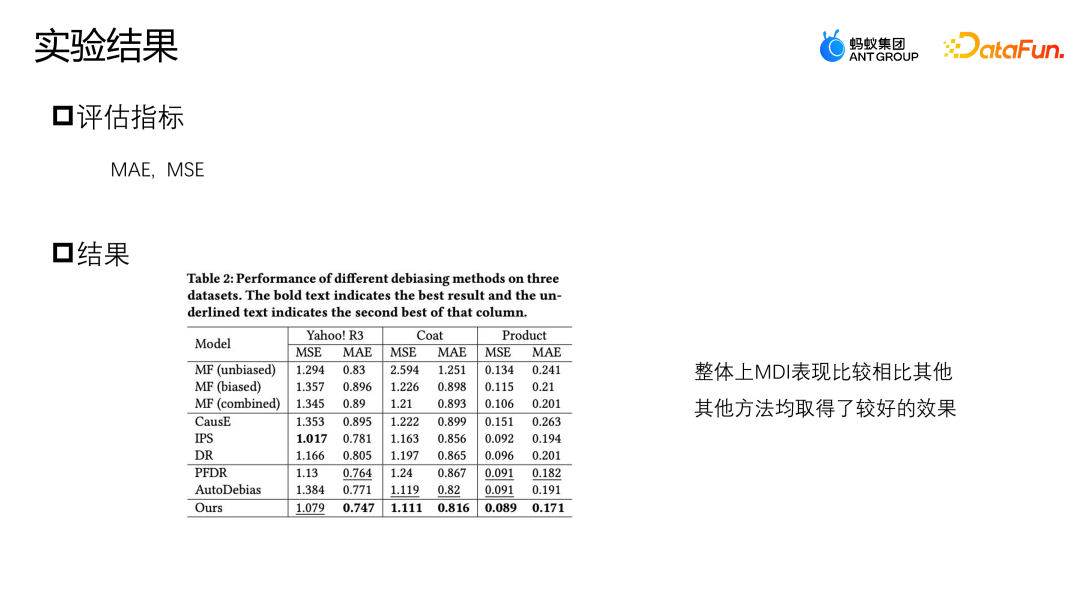
Im Yahoo R3-Datensatz weist die von uns vorgeschlagene Methode den besten Leistungsindex für MAE und die beste Leistung für MSE mit Ausnahme von IPS auf. Die drei Methoden zur Datenerweiterung, PFDR, Auto Debias und unser vorgeschlagenes MDI, werden in den meisten Fällen eine bessere Leistung erbringen. Da PFDR jedoch unvoreingenommene Daten verwendet, um das erweiterte Modell im Voraus zu trainieren, wird es daher stark auf die unvoreingenommene Datenqualität angewiesen sein Das Coat-Modell verfügt nur über 464 unvoreingenommene Trainingsdatenproben. Wenn weniger unvoreingenommene Proben vorhanden sind, ist das Erweiterungsmodul schlecht und die Datenleistung relativ schlecht.
 AutoDebias verhält sich bei verschiedenen Daten genau entgegengesetzt zu PFDR. Da MDI eine Erweiterungsmethode entwickelt hat, die sowohl unvoreingenommene als auch voreingenommene Daten verwendet, verfügt es über ein stärkeres Datenerweiterungsmodul, sodass in beiden Fällen bessere Ergebnisse erzielt werden können, wenn weniger unvoreingenommene Daten vorhanden sind.
AutoDebias verhält sich bei verschiedenen Daten genau entgegengesetzt zu PFDR. Da MDI eine Erweiterungsmethode entwickelt hat, die sowohl unvoreingenommene als auch voreingenommene Daten verwendet, verfügt es über ein stärkeres Datenerweiterungsmodul, sodass in beiden Fällen bessere Ergebnisse erzielt werden können, wenn weniger unvoreingenommene Daten vorhanden sind.
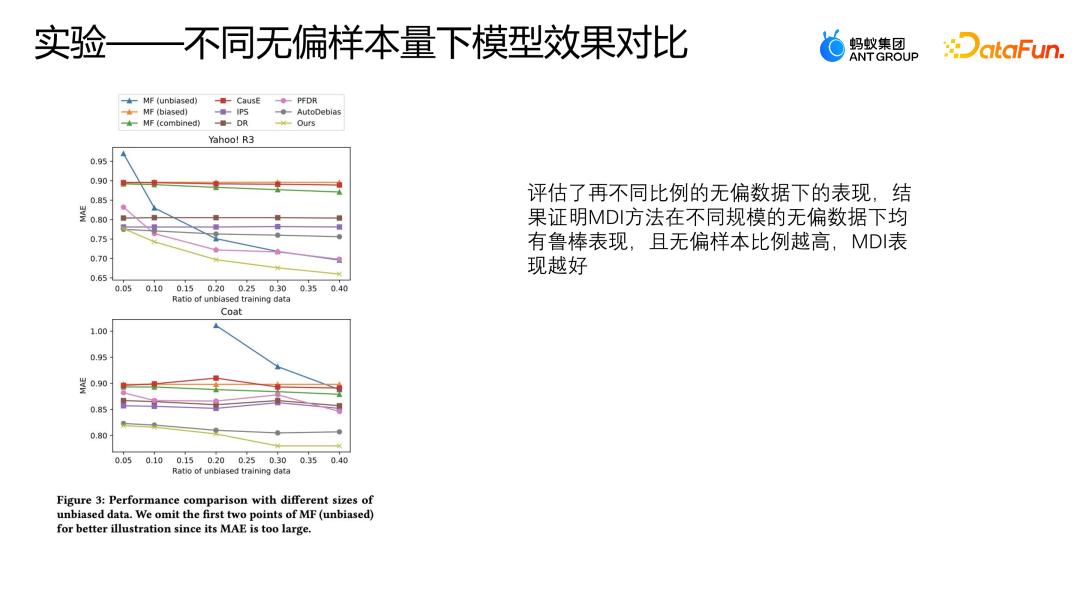
Wir haben auch die Leistung dieser Modelle unter verschiedenen Anteilen unvoreingenommener Daten in zwei öffentlichen Datensätzen bewertet, wobei wir jeweils 50 % bis 40 % der unvoreingenommenen Daten und alle voreingenommenen Daten für das Training verwendet haben. Die Logik wird mit den ersten 10 % davon überprüft Die unverzerrten Daten und die übrigen Daten werden getestet. Diese Einstellung ist die gleiche wie beim vorherigen Experiment.
Die obige Abbildung zeigt die Leistung von MAE bei unterschiedlichen Anteilen unvoreingenommener Daten. Die Abszisse stellt den Anteil unvoreingenommener Daten dar, und die Ordinate stellt die Auswirkung jeder Methode auf unvoreingenommene Daten dar. Dies kann als unvoreingenommen angesehen werden Daten nehmen zu. Da der Anteil der Teildaten zunimmt, weist die MAE von AutoDebias, IPS und DoubleRubus keinen offensichtlichen Rückgangsprozess auf. Anstatt jedoch der Debias-Methode zu folgen, wird die Methode der direkten Verwendung der Originaldatenfusion zum Lernen einen erheblichen Rückgang erfahren. Dies liegt daran, dass unsere Gesamtdatenqualität umso besser ist, je höher der Stichprobenanteil an unvoreingenommenen Daten ist, sodass das Modell lernen kann Bessere Leistung.
Wenn Yahoo R3-Daten mehr als 30 % unverzerrte Daten für das Training verwenden,
Diese Methode übertrifft sogar alle anderen Bias-Korrekturmethoden außer MDI. Allerdings kann die MDI-Methode eine relativ bessere Leistung erzielen, was auch beweisen kann, dass die MDI-Methode bei unvoreingenommenen Daten unterschiedlicher Größe relativ robuste Ergebnisse liefert.
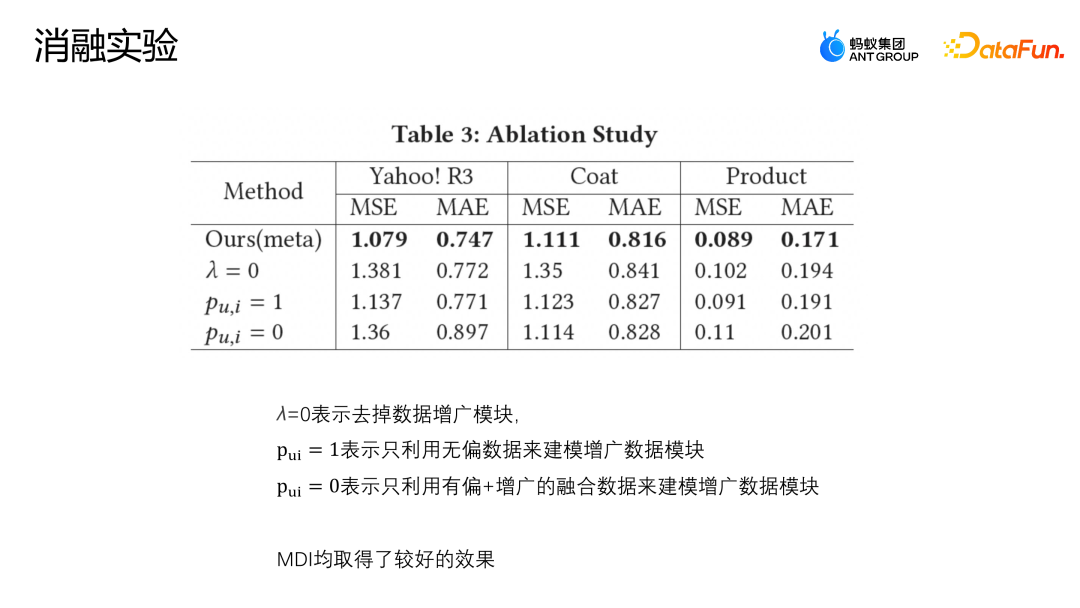
Die Einstellung λ=0 bedeutet, dass das erweiterte Modul direkt entfernt wird; Pu,i = 1 bedeutet, dass nur unverzerrte Daten zur Modellierung des erweiterten Datenmoduls verwendet werden; Pu,i = 0 bedeutet, dass nur verzerrte und erweiterte fusionierte Daten verwendet werden Wird zum Aufbau des Modells verwendet. Die obige Abbildung zeigt die Ergebnisse des Ablationsexperiments. Es ist ersichtlich, dass die MDI-Methode bei den drei Datensätzen relativ gute Ergebnisse erzielt hat, was darauf hinweist, dass das Erweiterungsmodul erforderlich ist. Ob es sich um öffentliche Datensätze oder Datensätze in tatsächlichen Geschäftsszenarien handelt, die von uns vorgeschlagene Erweiterungsmethode zur Zusammenführung unvoreingenommener und voreingenommener Daten liefert bessere Ergebnisse als frühere Datenfusionslösungen, und die Robustheit von MDI wurde auch durch Parameter überprüft Sensitivitätsexperimente und Ablationsexperimente.
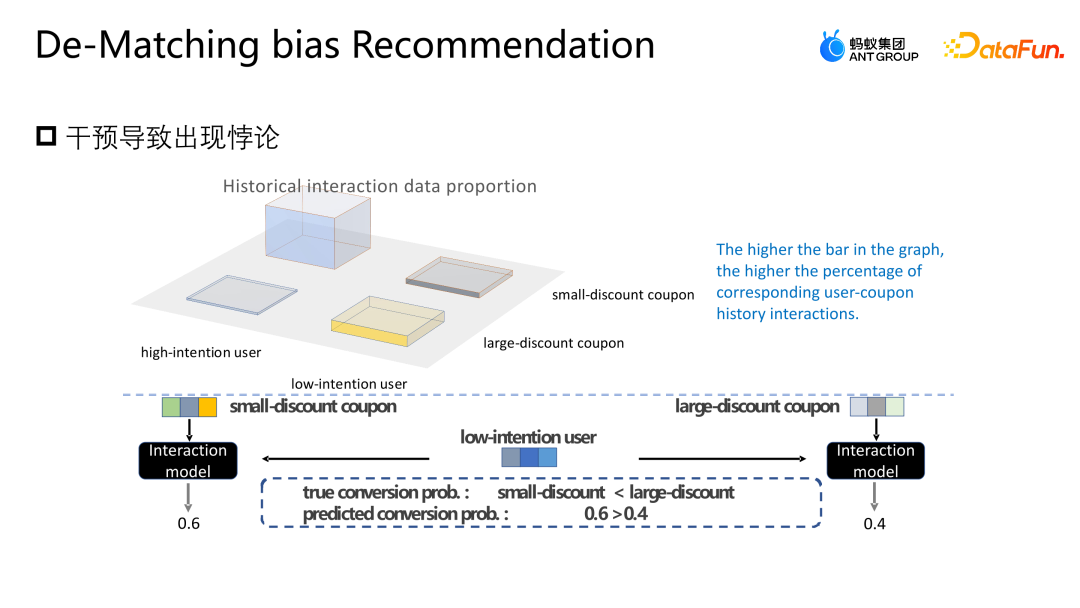
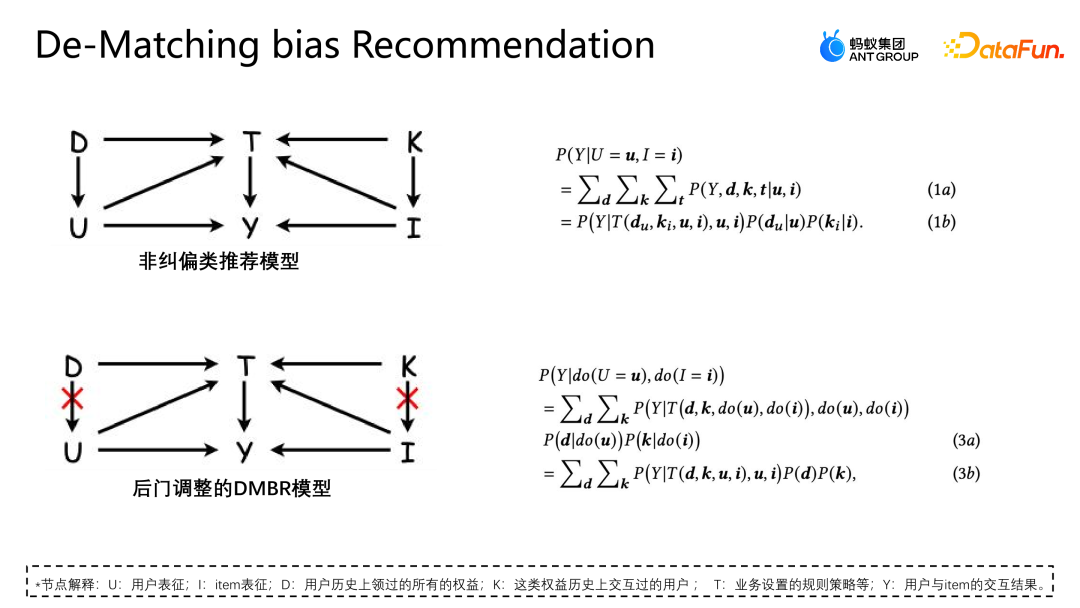
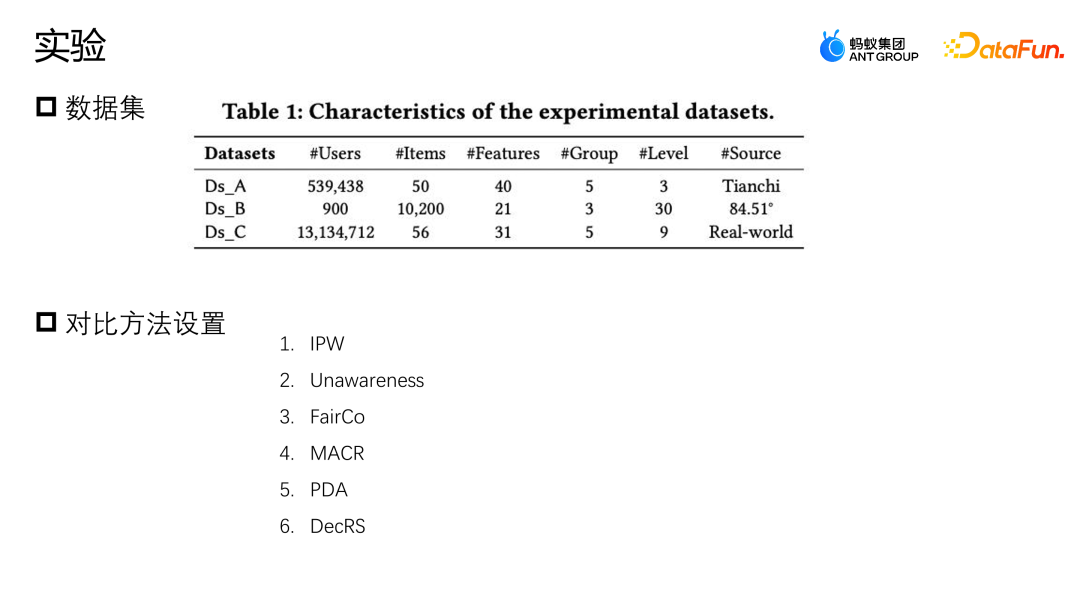
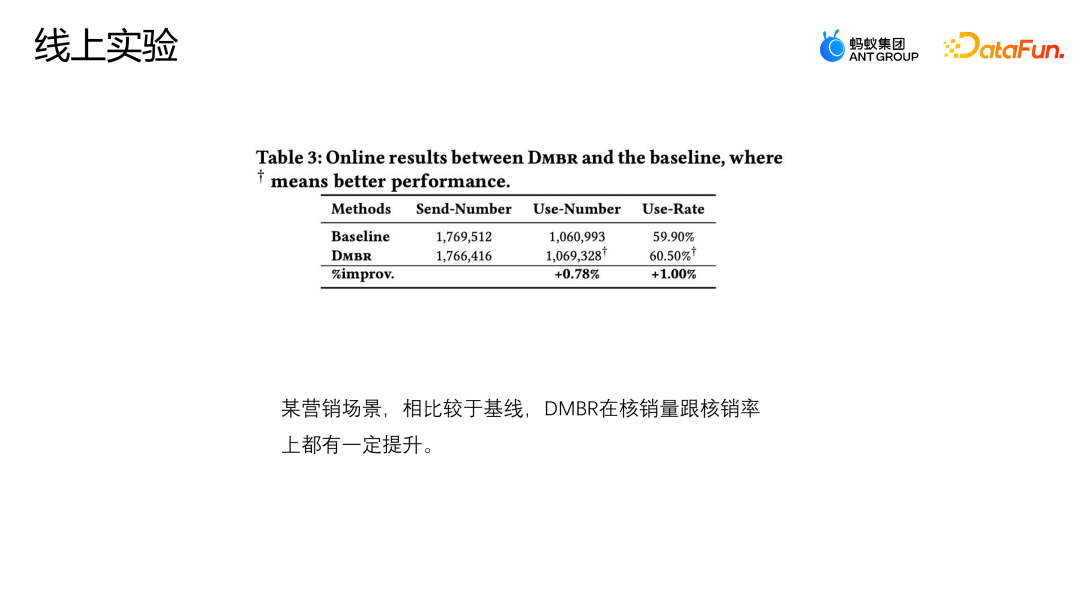
Lassen Sie uns eine weitere Arbeit des Teams vorstellen: Korrektur basierend auf der Hintertür-Anpassung. Diese Arbeit wurde auch auf dem Industry Track von SIGIR2023 veröffentlicht. Das Szenario der Hintertür-Anpassung und -Korrekturanwendung ist das Szenario der Marketingempfehlung. Wie in der folgenden Abbildung dargestellt, besteht keine gleiche Möglichkeit für die Interaktion zwischen dem Benutzer und dem Coupon oder dem Benutzer und einer Werbung oder einem Artikel jeder Interaktion, und jeder Coupon hat auch die gleiche Chance, jedem Benutzer angezeigt zu werden. Aber in tatsächlichen Geschäftsszenarien werden in der Regel eine Reihe von Richtlinienbeschränkungen eingerichtet, um einige kleine Händler zu schützen oder ihnen zu helfen, den Datenverkehr zu erhöhen Bestimmte Coupons werden stärker exponiert, und eine andere Gruppe von Benutzern wird stärker einem anderen Coupon ausgesetzt. Diese Art von Intervention ist der oben erwähnte Mitbegründer. Welche Probleme wird diese Art von Intervention im E-Commerce-Marketing-Szenario verursachen? Wie in der Abbildung oben gezeigt, teilen wir die Benutzer der Einfachheit halber einfach in zwei Kategorien ein: hohe Teilnahmebereitschaft und niedrige Teilnahmebereitschaft, und Gutscheine in zwei Kategorien: große Rabatte und kleine Rabatte. Die Höhe des Histogramms in der Abbildung stellt den globalen Anteil der entsprechenden Stichprobe dar. Je höher das Histogramm, desto größer ist der Anteil der entsprechenden Stichprobe an den gesamten Trainingsdaten. Die in der Abbildung gezeigten kleinen Rabattcoupons und Benutzerproben mit hoher Teilnahmeabsicht machen den Großteil aus, was dazu führt, dass das Modell die in der Abbildung gezeigte Verteilung lernt. Das Modell geht davon aus, dass Benutzer mit hoher Teilnahmeabsicht kleine Rabattcoupons bevorzugen. Tatsächlich werden Benutzer jedoch bei gleicher Nutzungsschwelle definitiv Gutscheine mit höheren Rabatten bevorzugen, damit sie mehr Geld sparen können. Das Modell im Bild zeigt, dass die tatsächliche Umwandlungswahrscheinlichkeit kleiner Rabattgutscheine geringer ist als die großer Rabattgutscheine. Die Schätzung des Modells für eine bestimmte Stichprobe geht jedoch davon aus, dass die Abschreibungswahrscheinlichkeit kleiner Rabattgutscheine höher ist Das Modell wird diese Punktzahl auch empfehlen, was ein Paradoxon darstellt. Analysieren Sie die Gründe für dieses Paradoxon aus der Perspektive eines Kausaldiagramms. Die Struktur des Kausaldiagramms ist in der Abbildung oben dargestellt und ich repräsentiert die Charakterisierung. D und K sind die historischen Wechselwirkungen zwischen der Benutzerperspektive bzw. der Eigenkapitalperspektive. T stellt einige durch das aktuelle Geschäft festgelegte Regelbeschränkungen dar. T kann nicht direkt quantifiziert werden, aber wir können seine Auswirkungen auf Benutzer und Elemente durch D und K erkennen. Auswirkungen. y stellt die Interaktion zwischen dem Benutzer und dem Artikel dar. Das Ergebnis ist, ob der Artikel angeklickt, abgeschrieben usw. wird. Die durch das Kausaldiagramm dargestellte bedingte Wahrscheinlichkeitsformel ist oben rechts in der Abbildung dargestellt. Die Ableitung der Formel folgt der Bayes'schen Wahrscheinlichkeitsformel. Unter den gegebenen Bedingungen von U und I hängt die endgültige Ableitung von P | besteht auch aus. Wenn ich gegeben werde, werde ich auf die gleiche Weise von Ki beeinflusst. Der Grund für diese Situation ist, dass die Existenz von D und K zur Existenz von Hintertürpfaden in der Szene führt. Das heißt, ein Backdoor-Pfad, der nicht bei U beginnt, sondern schließlich auf y zeigt (U-D-T-Y- oder I-K-T-Y-Pfad), stellt ein falsches Konzept dar, das heißt, U kann nicht nur y über T, sondern auch y über D beeinflussen. Die Anpassungsmethode besteht darin, den Weg von D nach U künstlich abzuschneiden, sodass U y nur über U-T-Y und U-Y direkt beeinflussen kann. Diese Methode kann falsche Korrelationen entfernen und den wahren Kausalzusammenhang modellieren. Die Hintertüranpassung besteht darin, eine Do-Berechnung für die Beobachtungsdaten durchzuführen und dann den Do-Operator zu verwenden, um die Leistung aller D und aller K zu aggregieren, um zu verhindern, dass U und I durch D und K beeinflusst werden. Auf diese Weise wird eine echte Ursache-Wirkungs-Beziehung modelliert. Die abgeleitete Näherungsform dieser Formel ist in der folgenden Abbildung dargestellt. 4a ist die gleiche Form wie das vorherige 3b, und 4b ist eine Näherung des Probenraums. Da der Probenraum von D und K theoretisch unendlich ist, kann eine Annäherung nur durch die gesammelten Daten erfolgen (D und K des Probenraums nehmen eine Größe an). 4c und 4d sind beide Ableitungen der gewünschten Näherung, so dass letztendlich nur eine zusätzliche erwartungstreue Darstellung T modelliert werden muss. T ist ein zusätzliches Modell der unvoreingenommenen Darstellung T, indem die Summe der Darstellungswahrscheinlichkeitsverteilungen von Benutzern und Elementen in allen Situationen durchlaufen wird, um dem Modell dabei zu helfen, die endgültige unvoreingenommene Datenschätzung zu erhalten. Das Experiment verwendet zwei Open-Source-Datensätze, Tianchi- und 84,51-(Coupon-)Datensätze. Simulieren Sie die Auswirkungen dieser Regelstrategie auf die Gesamtdaten durch Stichproben. Gleichzeitig wurden Daten aus einem realen E-Commerce-Marketing-Aktivitätsszenario genutzt, um gemeinsam die Qualität des Algorithmus zu bewerten. Wir haben einige gängige Korrekturmethoden verglichen, wie z. B. IPW, das eine inverse Wahrscheinlichkeitsgewichtung verwendet, um die Verzerrung zu korrigieren. FairCo erhält relativ unvoreingenommene Schätzungen durch die Einführung von Fehlerterm-Einschränkungsdarstellungen Die Aufgabe schätzt die Konsistenz des Benutzers bzw. die Beliebtheit des Elements und subtrahiert die Konsistenz und Beliebtheit in der Vorhersagephase, um eine unvoreingenommene Schätzung zu erzielen. Der PDA entfernt die Beliebtheit durch die Anpassung des Verlustelements durch kausale Intervention Hintertür-Anpassung, um Informationsverzerrungen zu beseitigen, aber sie korrigiert nur die Verzerrung der Benutzerperspektive. Der Bewertungsindex des Experiments ist AUC. Da es im Marketing-Promotion-Szenario nur einen empfohlenen Coupon oder ein Empfehlungskandidatenprodukt gibt, handelt es sich im Wesentlichen um ein Problem mit zwei Klassifizierungen. Daher ist es angemessener, AUC zur Bewertung zu verwenden . Beim Vergleich der Leistung von DNN und MMOE unter verschiedenen Architekturen ist ersichtlich, dass das von uns vorgeschlagene DMBR-Modell bessere Ergebnisse liefert als die ursprüngliche Nichtkorrekturmethode und andere Korrekturmethoden. Gleichzeitig haben Ds_A und Ds_B einen höheren Verbesserungseffekt auf den simulierten Datensatz erzielt als auf den realen Geschäftsdatensatz. Dies liegt daran, dass die Daten im realen Geschäftsdatensatz komplexer sind und nicht nur von Regeln und beeinflusst werden Richtlinien, sondern können auch durch andere Faktoren beeinflusst werden. Derzeit wurde das Modell in einem E-Commerce-Marketing-Event-Szenario eingeführt. Das obige Bild zeigt den Online-Effekt. Im Vergleich zum Basismodell weist das DMBR-Modell gewisse Verbesserungen bei der Abschreibungsrate und beim Umsatz auf Volumen.
3. Korrektur basierend auf der Hintertür-Anpassung



4. Anwendung in Ant Es können Einschränkungen festgelegt werden. Was die Zielgruppe der Werbung betrifft, so werden einige auf Haustiere ausgerichtete Anzeigen mit größerer Wahrscheinlichkeit an Nutzer geschaltet, die Haustiere haben. Im E-Commerce-Marketing-Szenario werden einige Strategien entwickelt, um den Traffic kleiner Händler sicherzustellen und zu vermeiden, dass der gesamte Traffic von großen Händlern verbraucht wird. Da das Gesamtbudget der Aktivität begrenzt ist, wird nicht nur die Benutzererfahrung bei der Teilnahme an Aktivitäten sichergestellt, sondern auch eine große Menge an Ressourcen in Anspruch genommen, wenn einige skrupellose Benutzer wiederholt an der Aktivität teilnehmen, was zu einer schlechten Aktivitätsteilnahmeerfahrung führt andere Benutzer. In solchen Szenarien gibt es Anwendungen zur Ursache-Wirkungs-Korrektur.
Das obige ist der detaillierte Inhalt vonAnwendung der Ursache-Wirkungs-Korrekturmethode in Empfehlungsszenarien für Ameisenmarketing. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 So implementieren Sie ein Empfehlungssystem mit der Go-Sprache und Redis
Oct 27, 2023 pm 12:54 PM
So implementieren Sie ein Empfehlungssystem mit der Go-Sprache und Redis
Oct 27, 2023 pm 12:54 PM
So verwenden Sie die Go-Sprache und Redis zur Implementierung eines Empfehlungssystems. Das Empfehlungssystem ist ein wichtiger Bestandteil der modernen Internetplattform. Es hilft Benutzern, interessante Informationen zu finden und zu erhalten. Die Go-Sprache und Redis sind zwei sehr beliebte Tools, die bei der Implementierung von Empfehlungssystemen eine wichtige Rolle spielen können. In diesem Artikel wird erläutert, wie Sie mithilfe der Go-Sprache und Redis ein einfaches Empfehlungssystem implementieren, und es werden spezifische Codebeispiele bereitgestellt. Redis ist eine Open-Source-In-Memory-Datenbank, die eine Speicherschnittstelle für Schlüssel-Wert-Paare bereitstellt und eine Vielzahl von Daten unterstützt
 In Java implementierte Algorithmen und Anwendungen von Empfehlungssystemen
Jun 19, 2023 am 09:06 AM
In Java implementierte Algorithmen und Anwendungen von Empfehlungssystemen
Jun 19, 2023 am 09:06 AM
Mit der kontinuierlichen Weiterentwicklung und Popularisierung der Internet-Technologie werden Empfehlungssysteme als wichtige Technologie zur Informationsfilterung immer häufiger eingesetzt und beachtet. Bei der Implementierung von Empfehlungssystemalgorithmen ist Java als schnelle und zuverlässige Programmiersprache weit verbreitet. In diesem Artikel werden die in Java implementierten Empfehlungssystemalgorithmen und -anwendungen vorgestellt und der Schwerpunkt auf drei gängige Empfehlungssystemalgorithmen gelegt: benutzerbasierter kollaborativer Filteralgorithmus, artikelbasierter kollaborativer Filteralgorithmus und inhaltsbasierter Empfehlungsalgorithmus. Der benutzerbasierte kollaborative Filteralgorithmus basiert auf benutzerbasierter kollaborativer Filterung
 Anwendungsbeispiel: Mit go-micro ein Microservice-Empfehlungssystem aufbauen
Jun 18, 2023 pm 12:43 PM
Anwendungsbeispiel: Mit go-micro ein Microservice-Empfehlungssystem aufbauen
Jun 18, 2023 pm 12:43 PM
Mit der Popularität von Internetanwendungen ist die Microservice-Architektur zu einer beliebten Architekturmethode geworden. Unter anderem besteht der Schlüssel zur Microservice-Architektur darin, die Anwendung in verschiedene Dienste aufzuteilen und über RPC zu kommunizieren, um eine lose gekoppelte Service-Architektur zu erreichen. In diesem Artikel stellen wir vor, wie man mit go-micro ein Microservice-Empfehlungssystem basierend auf tatsächlichen Fällen erstellt. 1. Was ist ein Microservice-Empfehlungssystem? Ein Microservice-Empfehlungssystem ist ein Empfehlungssystem, das auf einer Microservice-Architektur basiert. Es integriert verschiedene Module in das Empfehlungssystem (z. B. Feature-Engineering, Klassifizierung).
 Das Geheimnis einer genauen Empfehlung: Detaillierte Erläuterung des unvoreingenommenen Rückrufmodells für die entkoppelte Domänenanpassung von Alibaba
Jun 05, 2023 am 08:55 AM
Das Geheimnis einer genauen Empfehlung: Detaillierte Erläuterung des unvoreingenommenen Rückrufmodells für die entkoppelte Domänenanpassung von Alibaba
Jun 05, 2023 am 08:55 AM
1. Einführung in das Szenario Zunächst stellen wir das in diesem Artikel beschriebene Szenario vor – das Szenario „Gute Waren sind verfügbar“. Seine Position befindet sich im Vierquadratraster auf der Homepage von Taobao, die in eine One-Hop-Auswahlseite und eine Two-Hop-Akzeptanzseite unterteilt ist. Es gibt zwei Hauptformen von Akzeptanzseiten: eine ist die Bild- und Text-Akzeptanzseite und die andere ist die kurze Video-Akzeptanzseite. Das Ziel dieses Szenarios besteht hauptsächlich darin, den Benutzern zufriedenstellende Waren bereitzustellen und das Wachstum des GMV voranzutreiben, wodurch das Angebot an Experten weiter genutzt wird. 2. Was ist ein Beliebtheitsbias und warum befassen wir uns als nächstes mit dem Beliebtheitsbias? Was ist ein Beliebtheitsbias? Warum kommt es zu einem Beliebtheitsbias? 1. Was ist Popularitätsbias? Es gibt viele Pseudonyme, wie zum Beispiel Matthew-Effekt und Informationskokonraum. Intuitiv gesehen ist es ein Karneval hochexplosiver Produkte. Je beliebter das Produkt ist, desto einfacher ist es. Dies wird dazu führen
 Wie implementiert die Go-Sprache Cloud-Such- und Empfehlungssysteme?
May 16, 2023 pm 11:21 PM
Wie implementiert die Go-Sprache Cloud-Such- und Empfehlungssysteme?
May 16, 2023 pm 11:21 PM
Mit der kontinuierlichen Weiterentwicklung und Popularisierung der Cloud-Computing-Technologie werden Cloud-Such- und Empfehlungssysteme immer beliebter. Als Antwort auf diese Nachfrage bietet die Go-Sprache ebenfalls eine gute Lösung. In der Go-Sprache können wir die Funktionen zur gleichzeitigen Hochgeschwindigkeitsverarbeitung und die umfangreichen Standardbibliotheken nutzen, um ein effizientes Cloud-Such- und Empfehlungssystem zu implementieren. Im Folgenden wird vorgestellt, wie die Go-Sprache ein solches System implementiert. 1. Suche in der Cloud Zunächst müssen wir die Vorgehensweise und die Prinzipien der Suche verstehen. Die Suchposition bezieht sich auf die Suchmaschinen-Matching-Seiten basierend auf den vom Benutzer eingegebenen Schlüsselwörtern.
 Empfehlungssystem für die NetEase Cloud Music-Kaltstarttechnologie
Nov 14, 2023 am 08:14 AM
Empfehlungssystem für die NetEase Cloud Music-Kaltstarttechnologie
Nov 14, 2023 am 08:14 AM
1. Problemhintergrund: Die Notwendigkeit und Bedeutung der Kaltstartmodellierung. Als Content-Plattform stellt Cloud Music täglich eine große Menge neuer Inhalte online. Obwohl die Menge an neuen Inhalten auf der Cloud-Musikplattform im Vergleich zu anderen Plattformen, wie etwa Kurzvideos, relativ gering ist, kann die tatsächliche Menge die Vorstellungskraft eines jeden bei weitem übersteigen. Gleichzeitig unterscheiden sich Musikinhalte deutlich von kurzen Videos, Nachrichten und Produktempfehlungen. Der Lebenszyklus von Musik erstreckt sich über extrem lange Zeiträume, oft gemessen in Jahren. Manche Songs können explodieren, nachdem sie monate- oder jahrelang inaktiv waren, und klassische Songs können auch nach mehr als zehn Jahren noch eine starke Vitalität haben. Daher ist es für das Empfehlungssystem von Musikplattformen wichtiger, unpopuläre und qualitativ hochwertige Long-Tail-Inhalte zu entdecken und sie den richtigen Nutzern zu empfehlen, als andere Kategorien zu empfehlen.
 Anwendung der Ursache-Wirkungs-Korrekturmethode in Empfehlungsszenarien für Ameisenmarketing
Jan 13, 2024 pm 12:15 PM
Anwendung der Ursache-Wirkungs-Korrekturmethode in Empfehlungsszenarien für Ameisenmarketing
Jan 13, 2024 pm 12:15 PM
1. Hintergrund der Ursache-Wirkungs-Korrektur 1. Abweichungen treten im Empfehlungssystem auf. Das Empfehlungsmodell wird durch das Sammeln von Daten trainiert, um Benutzern geeignete Elemente zu empfehlen. Wenn Benutzer mit empfohlenen Elementen interagieren, werden die gesammelten Daten verwendet, um das Modell weiter zu trainieren und so einen geschlossenen Regelkreis zu bilden. Allerdings kann es in diesem geschlossenen Kreislauf verschiedene Einflussfaktoren geben, die zu Fehlern führen. Der Hauptgrund für den Fehler besteht darin, dass es sich bei den meisten zum Trainieren des Modells verwendeten Daten um Beobachtungsdaten und nicht um ideale Trainingsdaten handelt, die von Faktoren wie der Expositionsstrategie und der Benutzerauswahl beeinflusst werden. Der Kern dieser Verzerrung liegt im Unterschied zwischen den Erwartungen empirischer Risikoschätzungen und den Erwartungen echter idealer Risikoschätzungen. 2. Häufige Vorurteile Es gibt drei Haupttypen häufiger Vorurteile in Empfehlungsmarketingsystemen: Selektive Voreingenommenheit: Sie ist auf die Herkunft des Benutzers zurückzuführen
 Empfehlungssystem und kollaborative Filtertechnologie in PHP
May 11, 2023 pm 12:21 PM
Empfehlungssystem und kollaborative Filtertechnologie in PHP
May 11, 2023 pm 12:21 PM
Mit der rasanten Entwicklung des Internets gewinnen Empfehlungssysteme immer mehr an Bedeutung. Ein Empfehlungssystem ist ein Algorithmus, der zur Vorhersage von Elementen verwendet wird, die für einen Benutzer von Interesse sind. In Internetanwendungen können Empfehlungssysteme personalisierte Vorschläge und Empfehlungen bereitstellen und so die Benutzerzufriedenheit und Konversionsraten verbessern. PHP ist eine in der Webentwicklung weit verbreitete Programmiersprache. In diesem Artikel werden Empfehlungssysteme und kollaborative Filtertechnologie in PHP untersucht. Prinzip des Empfehlungssystems Das Empfehlungssystem basiert auf maschinellen Lernalgorithmen und Datenanalysen. Es analysiert und prognostiziert das historische Verhalten des Benutzers.
