

| Einführung | In der von DBA optimierten Datenbankumgebung werden die meisten Leistungsprobleme tatsächlich durch unsachgemäßes SQL-Schreiben verursacht. Die Welt von SQL ist voller Wunder. Heute werfen wir einen Blick auf ein Killer-SQL, das Sie zum Bluterbrechen bringen wird. |
Bei einem Versicherungskunden dauerte ETL mehrere Stunden. Wir haben einen SQL-Bericht erstellt und festgestellt, dass der Druck hauptsächlich auf einem der SQLs lag.
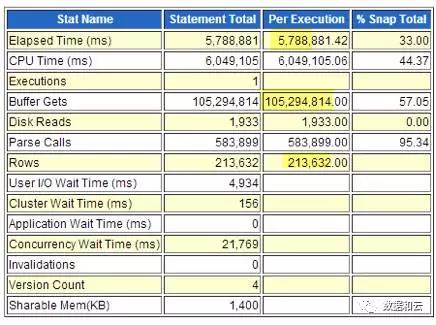
Einzelausführungszeit: 5788 (Sekunden)
Einzelner logischer Lesevorgang: 1 Milliarde (Blöcke)
Anzahl der gleichzeitig zurückgegebenen Zeilen: 210.000 (Zeilen)
Schauen wir uns zuerst die SQL-Anweisung an, da sie ziemlich lang ist, deshalb stellen wir hier nur einen Auszug dar

Sehen Sie sich den Ausführungsplan an:
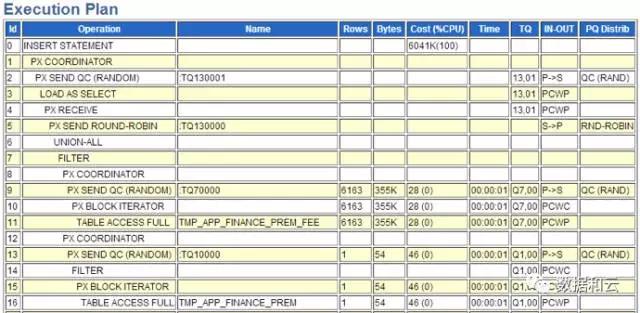
Wir konzentrieren uns hauptsächlich auf die Zeilen 7 bis 16: Wir haben festgestellt, dass es zwei vollständige Tabellenscans gibt. In der Mitte wurde ein Filter angebracht.
Aus langjähriger Erfahrung weiß ich, dass der Filter, der aus zwei vollständigen Tabellenscans besteht, ernsthafte Probleme aufweist, da die Daten einzeln verarbeitet werden müssen. In diesem Ausführungsplan wird die gesteuerte Tabelle weiterhin vollständig gescannt.
Not In/In-Operationen erzeugen manchmal Filteroperationen. In Versionen vor 11g muss die Not-In-Anweisung in eine Anti-Join-Spalte umgewandelt werden, oder es muss Not Null enthalten sein in der Anweisung. Andernfalls können Sie mit Filter nur einzeln filtern.
Lass uns ein Beispiel geben:
Es wurde festgestellt, dass es für die drei Spalten keine Einschränkung gibt, nicht null zu sein.
 Wir geben derzeit vor, ein 10G-Optimierer zu sein.
Wir geben derzeit vor, ein 10G-Optimierer zu sein.
SQL> alter session setoptimierer_features_enable=”10.2.0.5″;
Führen Sie das folgende SQL aus:
SQL> Autotracetrace exp festlegen
SQL> SELECT * FROM T_TABLE WHERE TABLE_NAME NOT IN(SELECT OBJECT_NAME FROM T_OBJ);
Als wir uns den Ausführungsplan zu diesem Zeitpunkt ansahen, stellten wir fest, dass folgender Filter verwendet wird:
Aber in der 11g-Version kann der Optimierer den Not in operation automatisch vom teuren Filter in Null-Aware-Anti-Join umwandeln. 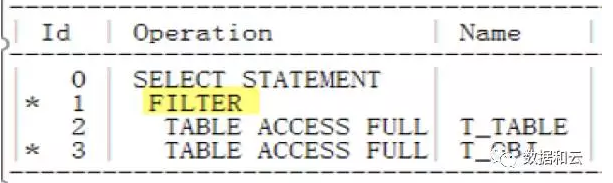
Wenn Sie eine Nicht-Null-Bedingung hinzufügen oder das Feldattribut auf „Nicht-Null“ setzen SQL> Tabelle T_OBJ ändern(OBJECT_NAME NOT NULL);
Führen Sie dieselbe Anweisung noch einmal aus:
SQL> SELECT * FROM T_TABLE WHERE TABLE_NAME
NICHT IN(SELECT OBJECT_NAME FROM T_OBJ
WHEREOBJECT_NAME IST NICHT NULL);
Sehen Sie sich den Ausführungsplan noch einmal an:
Zu diesem Zeitpunkt haben wir festgestellt, dass im Ausführungsplan Hash-Join-Anti enthalten ist.
 Und in 11g sind Nicht-in-Spalten ohne Nicht-Null-Einschränkungen zulässig, und Anti-Join kann auch konvertiert werden.
Und in 11g sind Nicht-in-Spalten ohne Nicht-Null-Einschränkungen zulässig, und Anti-Join kann auch konvertiert werden.
SQL> alter session setoptimierer_features_enable=”11.2.0.4″;
SQL> Tabelle T_OBJ ändern(OBJECT_NAME NULL);
SQ> SELECT * FROM T_TABLE WHERE TABLE_NAME
NOT IN (SELECTOBJECT_NAMEFROM T_OBJ);
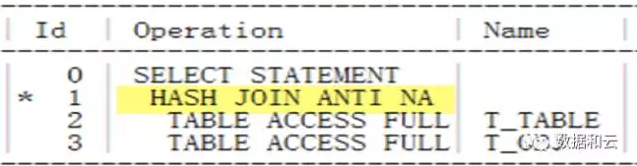
Ausführungsplan anzeigen:
Wir sehen, dass Hash Join Anti.
derzeit auch ohne die nicht leere Einschränkung verwendet wird.
 Diese Funktion kann über Optimierungsparameter gesteuert werden.
Diese Funktion kann über Optimierungsparameter gesteuert werden.
SQL>alter session set „_optimizer_null_aware_antijoin“=FALSE;
Führen Sie die obige Anweisung erneut aus und sehen Sie sich den Ausführungsplan an:
SQL> SELECT * FROM T_TABLE WHERE TABLE_NAME
NOT IN (SELECTOBJECT_NAMEFROM T_OBJ);
Ich habe festgestellt, dass ich immer noch Hash Join Anti verwende.
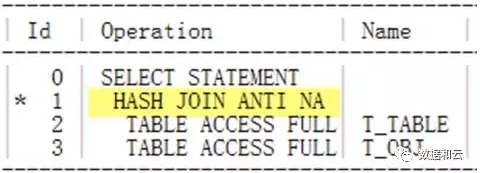 Es wurde bestätigt, dass es sich bei dieser Parametereinstellung nicht um ein Problem handelt
Es wurde bestätigt, dass es sich bei dieser Parametereinstellung nicht um ein Problem handelt
Nicht in ist der gegenseitige Ausschluss zwischen Ergebnismengen. Tatsächlich gibt es viele Möglichkeiten, es umzuschreiben, wie zum Beispiel:
– Nicht vorhanden
– Outer Join + ist null
– Minus
Der Unterschied zwischen not in und den oben genannten drei Schreibweisen ist: not in schließt Nullwerte aus.Wir versuchen umzuschreiben.
Dann, gerade als Sie dachten, dass ein Wunder geschehen würde, meldete die Aussage einen Fehler!
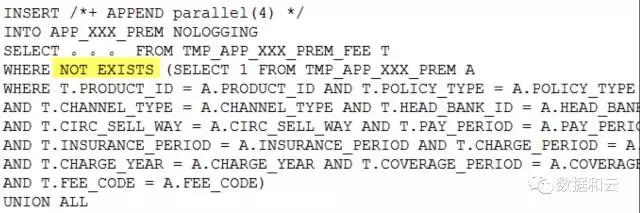
Warum wird ein Fehler gemeldet?
Wenn wir diese Aussage in nicht in umwandeln:

Nach der Logik von „not in“ sollte zu diesem Zeitpunkt „A.“ vor fee_code hinzugefügt werden. Dies ist natürlich kein Problem, aber wenn Sie sich diese Aussage noch einmal ansehen, wird daraus:

Da es in TMP_APP_xxx_PREM A kein FEE_CODE-Feld gibt, kann Not in nicht automatisch in Null Aware ANTI JOIN geändert werden.
Also, nachdem die Antwort enthüllt wurde, stellte sich heraus, dass es sich um einen Fehler handelte? ! Ich habe den Anfang erraten, aber nicht das Ende.
Aber in diesem Fall wurde dieser Fehler während des frühen Analyseprozesses nie entdeckt, da die SQL-Anweisung keine explizite Anweisung enthielt.
Sind Sie auch sprachlos? Eigentlich möchte ich noch mehr fragen: Schreiben Sie oft Killer-SQL? Wenn Sie krank sind, habe ich Medikamente. (Unschuldiges Gesicht, schlag mich nicht)
Wir alle wissen, dass in der durch DBA optimierten Datenbankumgebung die überwiegende Mehrheit der Leistungsprobleme tatsächlich durch unsachgemäßes SQL-Schreiben verursacht wird.
Bei Systemen, die nicht online sind, werden durch frühzeitige SQL-Prüfung und -Kontrolle 80 % der SQL-Probleme in der Entstehungsphase beseitigt. Bei online laufenden Systemen können potenzielle Leistungsprobleme erkannt und gelöst werden, um sie im Keim zu ersticken.
SQL-Audit ermöglicht es dem DBA, sich vom Notarzt des Systems zum Gesundheitsarzt des Systems zu wandeln
1. DBA beteiligt sich am Anwendungscode-Entwicklungs- und Testprozess: Stellen Sie Entwicklern professionelle Datenbankentwicklungs- und Optimierungsvorschläge zur Verfügung
2. Optimieren Sie das Frontend: Entwerfen Sie effizientes SQL und indexieren Sie es entsprechend den Geschäftsanforderungen, bevor der Anwendungscode online geht
3. Änderungsrisiken kontrollieren: Bewerten Sie vorab die Auswirkungen von Tabellenstrukturänderungen und SQL-Änderungen während der Anwendungsentwicklung auf laufende Anwendungen und legen Sie geeignete Änderungsfenster und Änderungspläne fest.
Das obige ist der detaillierte Inhalt vonOptimieren Sie SQL-Abfragen, um die „Nicht in'-Laufzeit zu reduzieren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



