

Wir werden Möglichkeiten zum Aufbau eines Retrieval Augmented Generation (RAG)-Systems unter Verwendung des Open-Source-Multimodals „Large Language“ diskutieren. Unser Fokus liegt darauf, dies zu erreichen, ohne auf LangChain oder Lllama-Index angewiesen zu sein, um das Hinzufügen weiterer Framework-Abhängigkeiten zu vermeiden.

Im Bereich der künstlichen Intelligenz hat das Aufkommen der Retriever-Augmented Generation (RAG)-Technologie revolutionäre Verbesserungen für große Sprachmodelle (Large Language Models) gebracht. Der Kern von RAG besteht darin, die Reaktionsfähigkeit künstlicher Intelligenz zu verbessern, indem es Modellen ermöglicht, dynamisch Echtzeitinformationen aus externen Quellen abzurufen. Die Einführung dieser Technologie ermöglicht es der KI, gezielter auf Benutzerbedürfnisse einzugehen. Durch das Abrufen und Zusammenführen von Informationen aus externen Quellen ist RAG in der Lage, genauere und umfassendere Antworten zu generieren und den Benutzern wertvollere Inhalte bereitzustellen. Diese Verbesserung der Fähigkeiten hat breitere Perspektiven für die Anwendungsfelder der künstlichen Intelligenz eröffnet, darunter intelligenter Kundenservice, intelligente Suche und wissensbasierte Frage- und Antwortsysteme. Das Aufkommen von RAG markiert die Weiterentwicklung von Sprachmodellen und bringt
zur künstlichen Intelligenz. Diese Architektur kombiniert den dynamischen Abrufprozess nahtlos mit Generierungsfunktionen und ermöglicht es der künstlichen Intelligenz, sich an sich ändernde Informationen in verschiedenen Bereichen anzupassen. Im Gegensatz zu Feinabstimmung und Umschulung bietet RAG eine kostengünstige Lösung, die es der KI ermöglicht, die neuesten und relevanten Informationen zu erhalten, ohne das gesamte Modell zu ändern. Diese Kombination von Fähigkeiten verschafft RAG einen Vorteil bei der Reaktion auf sich schnell ändernde Informationsumgebungen.
1. Verbessern Sie die Genauigkeit und Zuverlässigkeit:
löst das Problem der Unvorhersehbarkeit großer Sprachmodelle (LLM), indem es auf zuverlässige Wissensquellen verweist und so das Risiko der Bereitstellung verringert Falsche oder veraltete Informationen machen Antworten genauer und zuverlässiger.
2. Transparenz und Vertrauen erhöhen:
Generative KI-Modelle wie LLM mangelt es oft an Transparenz, was es für Menschen schwierig macht, ihren Ergebnissen zu vertrauen. RAG begegnet Bedenken hinsichtlich Voreingenommenheit, Zuverlässigkeit und Compliance, indem es eine bessere Kontrolle bietet.
3. Halluzinationen reduzieren:
LLM ist anfällig für halluzinatorische Reaktionen – und liefert kohärente, aber ungenaue oder erfundene Informationen. RAG reduziert das Risiko irreführender Beratung für Schlüsselsektoren, indem es sich auf verlässliche Quellen verlässt, um die Reaktionsfähigkeit sicherzustellen.
4. Kostengünstige Anpassungsfähigkeit:
RAG bietet eine kostengünstige Möglichkeit, die KI-Ausgabe zu verbessern, ohne dass umfangreiche Umschulungen/Feinabstimmungen erforderlich sind. Informationen können durch den dynamischen Abruf spezifischer Details nach Bedarf aktuell und relevant gehalten werden, wodurch die Anpassungsfähigkeit der KI an sich ändernde Informationen sichergestellt wird. Multimodales modales Modell Lernen Sie passende Beziehungen zwischen Text-Bild-Paaren.
Multimodale
GPT4v und Gemini Vision erforschen und integrieren verschiedene Datentypen (einschließlich Bilder, Text, Sprache, Audio usw.) multimodales Sprachmodell (MLLM). Während große Sprachmodelle (LLMs) wie GPT-3, BERT und RoBERTa bei textbasierten Aufgaben gute Leistungen erbringen, stehen sie beim Verständnis und der Verarbeitung anderer Datentypen vor Herausforderungen. Um dieser Einschränkung zu begegnen, kombinieren multimodale Modelle verschiedene Modalitäten, um ein umfassenderes Verständnis verschiedener Daten zu ermöglichen. 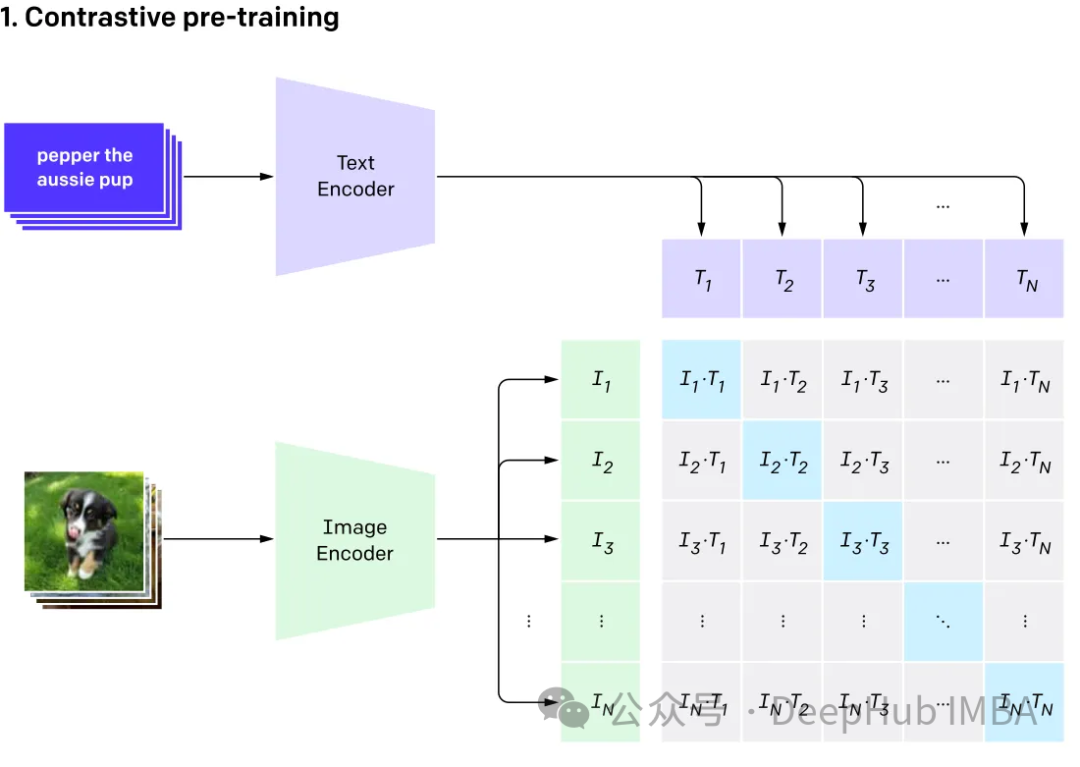
Kombiniert mit RAG
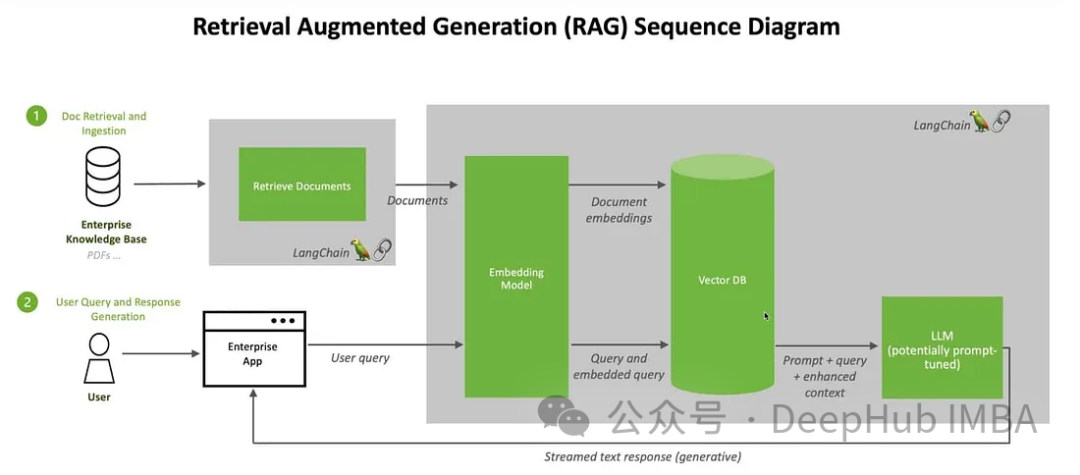
Hier verwenden wir Clip zum Einbetten von Bildern und Text und speichern diese Einbettungen in der ChromDB-Vektordatenbank. Das große Modell wird dann genutzt, um auf der Grundlage der abgerufenen Informationen an Benutzer-Chat-Sitzungen teilzunehmen.
Wir werden Bilder von Kaggle und Informationen von Wikipedia verwenden, um einen Chatbot für Blumenexperten zu erstellen
Zuerst installieren wir das Paket:
! pip install -q timm einops wikipedia chromadb open_clip_torch !pip install -q transformers==4.36.0 !pip install -q bitsandbytes==0.41.3 accelerate==0.25.0
Die Schritte zur Vorverarbeitung der Daten sind sehr einfach Legen Sie einfach Bilder und Text in einen Ordner
可以随意使用任何矢量数据库,这里我们使用ChromaDB。
import chromadb from chromadb.utils.embedding_functions import OpenCLIPEmbeddingFunction from chromadb.utils.data_loaders import ImageLoader from chromadb.config import Settings client = chromadb.PersistentClient(path="DB") embedding_function = OpenCLIPEmbeddingFunction() image_loader = ImageLoader() # must be if you reads from URIs
ChromaDB需要自定义嵌入函数
from chromadb import Documents, EmbeddingFunction, Embeddings class MyEmbeddingFunction(EmbeddingFunction):def __call__(self, input: Documents) -> Embeddings:# embed the documents somehow or imagesreturn embeddings
这里将创建2个集合,一个用于文本,另一个用于图像
collection_images = client.create_collection(name='multimodal_collection_images', embedding_functinotallow=embedding_function, data_loader=image_loader) collection_text = client.create_collection(name='multimodal_collection_text', embedding_functinotallow=embedding_function, ) # Get the Images IMAGE_FOLDER = '/kaggle/working/all_data' image_uris = sorted([os.path.join(IMAGE_FOLDER, image_name) for image_name in os.listdir(IMAGE_FOLDER) if not image_name.endswith('.txt')]) ids = [str(i) for i in range(len(image_uris))] collection_images.add(ids=ids, uris=image_uris) #now we have the images collection对于Clip,我们可以像这样使用文本检索图像
from matplotlib import pyplot as plt retrieved = collection_images.query(query_texts=["tulip"], include=['data'], n_results=3) for img in retrieved['data'][0]:plt.imshow(img)plt.axis("off")plt.show()
也可以使用图像检索相关的图像

文本集合如下所示
# now the text DB from chromadb.utils import embedding_functions default_ef = embedding_functions.DefaultEmbeddingFunction() text_pth = sorted([os.path.join(IMAGE_FOLDER, image_name) for image_name in os.listdir(IMAGE_FOLDER) if image_name.endswith('.txt')]) list_of_text = [] for text in text_pth:with open(text, 'r') as f:text = f.read()list_of_text.append(text) ids_txt_list = ['id'+str(i) for i in range(len(list_of_text))] ids_txt_list collection_text.add(documents = list_of_text,ids =ids_txt_list )然后使用上面的文本集合获取嵌入
results = collection_text.query(query_texts=["What is the bellflower?"],n_results=1 ) results
结果如下:
{'ids': [['id0']],'distances': [[0.6072186183744086]],'metadatas': [[None]],'embeddings': None,'documents': [['Campanula () is the type genus of the Campanulaceae family of flowering plants. Campanula are commonly known as bellflowers and take both their common and scientific names from the bell-shaped flowers—campanula is Latin for "little bell".\nThe genus includes over 500 species and several subspecies, distributed across the temperate and subtropical regions of the Northern Hemisphere, with centers of diversity in the Mediterranean region, Balkans, Caucasus and mountains of western Asia. The range also extends into mountains in tropical regions of Asia and Africa.\nThe species include annual, biennial and perennial plants, and vary in habit from dwarf arctic and alpine species under 5 cm high, to large temperate grassland and woodland species growing to 2 metres (6 ft 7 in) tall.']],'uris': None,'data': None}或使用图片获取文本
query_image = '/kaggle/input/flowers/flowers/rose/00f6e89a2f949f8165d5222955a5a37d.jpg' raw_image = Image.open(query_image) doc = collection_text.query(query_embeddings=embedding_function(query_image), n_results=1, )['documents'][0][0]

上图的结果如下:
A rose is either a woody perennial flowering plant of the genus Rosa (), in the family Rosaceae (), or the flower it bears. There are over three hundred species and tens of thousands of cultivars. They form a group of plants that can be erect shrubs, climbing, or trailing, with stems that are often armed with sharp prickles. Their flowers vary in size and shape and are usually large and showy, in colours ranging from white through yellows and reds. Most species are native to Asia, with smaller numbers native to Europe, North America, and northwestern Africa. Species, cultivars and hybrids are all widely grown for their beauty and often are fragrant. Roses have acquired cultural significance in many societies. Rose plants range in size from compact, miniature roses, to climbers that can reach seven meters in height. Different species hybridize easily, and this has been used in the development of the wide range of garden roses.
这样我们就完成了文本和图像的匹配工作,其实这里都是CLIP的工作,下面我们开始加入LLM。
from huggingface_hub import hf_hub_download hf_hub_download(repo_, filename="configuration_llava.py", local_dir="./", force_download=True) hf_hub_download(repo_, filename="configuration_phi.py", local_dir="./", force_download=True) hf_hub_download(repo_, filename="modeling_llava.py", local_dir="./", force_download=True) hf_hub_download(repo_, filename="modeling_phi.py", local_dir="./", force_download=True) hf_hub_download(repo_, filename="processing_llava.py", local_dir="./", force_download=True)
我们是用visheratin/LLaVA-3b
from modeling_llava import LlavaForConditionalGeneration import torch model = LlavaForConditionalGeneration.from_pretrained("visheratin/LLaVA-3b") model = model.to("cuda")加载tokenizer
from transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained("visheratin/LLaVA-3b")然后定义处理器,方便我们以后调用
from processing_llava import LlavaProcessor, OpenCLIPImageProcessor image_processor = OpenCLIPImageProcessor(model.config.preprocess_config) processor = LlavaProcessor(image_processor, tokenizer)
下面就可以直接使用了
question = 'Answer with organized answers: What type of rose is in the picture? Mention some of its characteristics and how to take care of it ?' query_image = '/kaggle/input/flowers/flowers/rose/00f6e89a2f949f8165d5222955a5a37d.jpg' raw_image = Image.open(query_image) doc = collection_text.query(query_embeddings=embedding_function(query_image), n_results=1, )['documents'][0][0] plt.imshow(raw_image) plt.show() imgs = collection_images.query(query_uris=query_image, include=['data'], n_results=3) for img in imgs['data'][0][1:]:plt.imshow(img)plt.axis("off")plt.show()得到的结果如下:

结果还包含了我们需要的大部分信息

这样我们整合就完成了,最后就是创建聊天模板,
prompt = """system A chat between a curious human and an artificial intelligence assistant. The assistant is an exprt in flowers , and gives helpful, detailed, and polite answers to the human's questions. The assistant does not hallucinate and pays very close attention to the details. user <image> {question} Use the following article as an answer source. Do not write outside its scope unless you find your answer better {article} if you thin your answer is better add it after document. assistant """.format(questinotallow='question', article=doc)</image>如何创建聊天过程我们这里就不详细介绍了,完整代码在这里:
https://www.php.cn/link/71eee742e4c6e094e6af364597af3f05
Das obige ist der detaillierte Inhalt vonMethoden zum Aufbau multimodaler RAG-Systeme: Verwendung von CLIP und LLM. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Anwendung künstlicher Intelligenz im Leben
Anwendung künstlicher Intelligenz im Leben
 Was ist das Grundkonzept der künstlichen Intelligenz?
Was ist das Grundkonzept der künstlichen Intelligenz?
 Welche Software ist Premiere?
Welche Software ist Premiere?
 So exportieren Sie Word aus Powerdesigner
So exportieren Sie Word aus Powerdesigner
 Was sind die Hauptunterschiede zwischen Linux und Windows?
Was sind die Hauptunterschiede zwischen Linux und Windows?
 oncontextmenu-Ereignis
oncontextmenu-Ereignis
 Ouyi-App herunterladen
Ouyi-App herunterladen
 So ersetzen Sie ppt-Hintergrundbilder einheitlich
So ersetzen Sie ppt-Hintergrundbilder einheitlich








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



