
 Technologie-Peripheriegeräte
KI
Eine neue Interpretation des sinkenden Intelligenzniveaus von GPT-4
Technologie-Peripheriegeräte
KI
Eine neue Interpretation des sinkenden Intelligenzniveaus von GPT-4
Eine neue Interpretation des sinkenden Intelligenzniveaus von GPT-4

GPT-4, das seit seiner Veröffentlichung als eines der leistungsstärksten Sprachmodelle der Welt gilt, hat leider eine Reihe von Vertrauenskrisen erlebt.
Die jüngsten Gerüchte, dass GPT-4 „faul“ geworden sei, werden noch interessanter, wenn wir den Vorfall mit der „intermittierenden Intelligenz“ Anfang dieses Jahres mit der Neugestaltung der GPT-4-Architektur durch OpenAI in Verbindung bringen. Jemand hat es getestet und festgestellt, dass GPT-4 faul wird, als ob es in den Ruhezustand übergegangen wäre, solange Sie GPT-4 sagen: „Es sind Winterferien“.
Um das Problem der schlechten Null-Stichproben-Leistung des Modells bei neuen Aufgaben zu lösen, können wir die folgenden Methoden anwenden: 1. Datenverbesserung: Erhöhen Sie die Generalisierungsfähigkeit des Modells durch Erweiterung und Transformation vorhandener Daten. Bilddaten können beispielsweise durch Drehung, Skalierung, Translation usw. oder durch Synthese neuer Datenproben verändert werden. 2. Lernen übertragen: Nutzen Sie Modelle, die für andere Aufgaben trainiert wurden, um ihre Parameter und ihr Wissen auf neue Aufgaben zu übertragen. Dies kann vorhandenes Wissen und Erfahrung nutzen, um die Leistung von GPT-4 zu verbessern. Kürzlich veröffentlichten Forscher der University of California, Santa Cruz, eine neue Entdeckung, die möglicherweise den tieferen Grund für die Leistungsverschlechterung von GPT-4 erklären kann .
 „Wir haben herausgefunden, dass LLM bei Datensätzen, die vor dem Erstellungsdatum der Trainingsdaten veröffentlicht wurden, überraschend besser abschneidet als bei Datensätzen, die danach veröffentlicht wurden.“
„Wir haben herausgefunden, dass LLM bei Datensätzen, die vor dem Erstellungsdatum der Trainingsdaten veröffentlicht wurden, überraschend besser abschneidet als bei Datensätzen, die danach veröffentlicht wurden.“
Man hat „gesehen“, dass sie bei Aufgaben gut und bei Aufgaben schlecht abschneiden neue Aufgaben. Das bedeutet, dass LLM lediglich eine Methode zur Nachahmung von Intelligenz ist, die auf ungefährem Abrufen basiert und hauptsächlich auf dem Auswendiglernen von Dingen ohne jegliches Verständnisniveau basiert.
Um es ganz klar auszudrücken: Die Generalisierungsfähigkeit von LLM ist „nicht so stark wie angegeben“ – das Fundament ist nicht solide und es wird im tatsächlichen Kampf immer Fehler geben.
Ein Hauptgrund für dieses Ergebnis ist die „Aufgabenverschmutzung“, eine Form der Datenverschmutzung. Die uns bekannte Datenverschmutzung ist die Testdatenverschmutzung, bei der es sich um die Aufnahme von Testdatenbeispielen und -bezeichnungen in die Daten vor dem Training handelt. Unter „Aufgabenkontamination“ versteht man das Hinzufügen von Beispielen für das Aufgabentraining zu den Daten vor dem Training, wodurch die Auswertung bei Methoden mit Null- oder wenigen Stichproben nicht mehr realistisch und effektiv ist.
Der Forscher führte in dem Artikel erstmals eine systematische Analyse des Problems der Datenverschmutzung durch:
 Link zum Artikel: https://arxiv.org/pdf/2312.16337.pdf
Link zum Artikel: https://arxiv.org/pdf/2312.16337.pdf
Nachdem ich das gelesen hatte, sagte jemand in der Zeitung „pessimistisch“:
Das ist das Schicksal aller Modelle des maschinellen Lernens (ML), die nicht über die Fähigkeit zum kontinuierlichen Lernen verfügen, d. h. Die Gewichte des ML-Modells werden nach dem Training eingefroren. Die Eingabeverteilung ändert sich jedoch weiterhin, und wenn sich das Modell nicht weiter an diese Änderung anpassen kann, verschlechtert es sich langsam.Das bedeutet, dass mit der ständigen Aktualisierung der Programmiersprachen auch LLM-basierte Codierungstools schlechter werden. Dies ist einer der Gründe, warum Sie sich nicht zu sehr auf ein so zerbrechliches Werkzeug verlassen müssen. Die kontinuierliche Umschulung dieser Modelle ist teuer und früher oder später wird jemand diese ineffizienten Methoden aufgeben.Derzeit gibt es keine ML-Modelle, die sich zuverlässig und kontinuierlich an sich ändernde Eingabeverteilungen anpassen können, ohne dass es zu schwerwiegenden Störungen oder Leistungseinbußen bei der vorherigen Codierungsaufgabe kommt.
Und das ist einer der Bereiche, in denen biologische neuronale Netze gut sind. Aufgrund der starken Generalisierungsfähigkeit biologischer neuronaler Netze kann das Erlernen verschiedener Aufgaben die Leistung des Systems weiter verbessern, da das aus einer Aufgabe gewonnene Wissen dazu beiträgt, den gesamten Lernprozess selbst zu verbessern, was als „Meta-Lernen“ bezeichnet wird.
Wie ernst ist das Problem der „Aufgabenverschmutzung“? Werfen wir einen Blick auf den Inhalt des Papiers.
Modelle und Datensätze
Im Experiment werden 12 Modelle verwendet (siehe Tabelle 1), davon 5 proprietäre Modelle der GPT-3-Serie und 7 offene Modelle mit freien Gewichten.
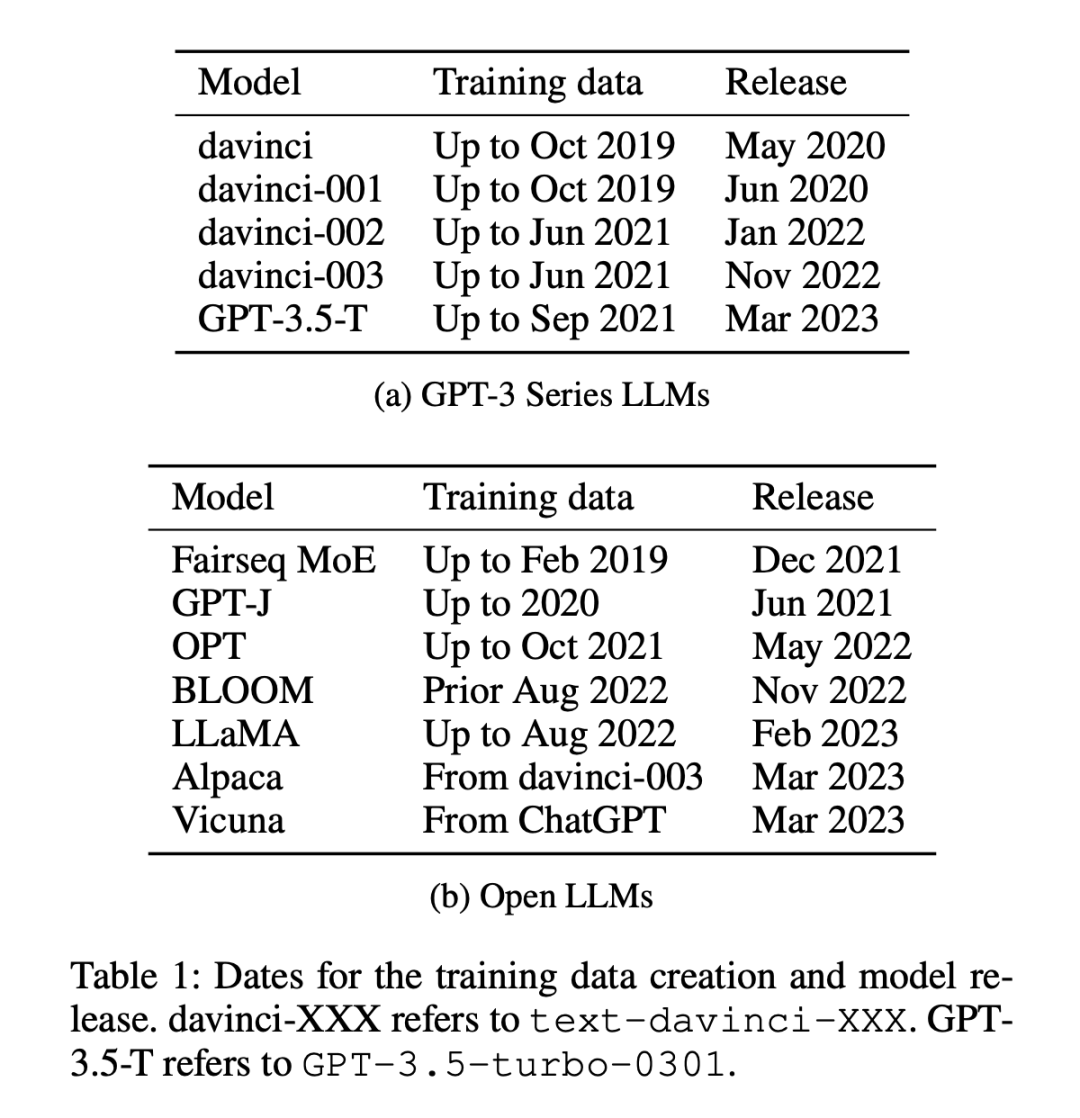
Datensätze werden in zwei Kategorien unterteilt: Datensätze, die vor oder nach dem 1. Januar 2021 veröffentlicht wurden. Forscher verwenden diese Aufteilungsmethode, um den Unterschied zwischen alten Datensätzen und neuen Datensätzen ohne Stichprobe zu analysieren Leistungsunterschiede bei wenigen Stichproben reduzieren und für alle LLMs die gleiche Partitionierungsmethode anwenden. In Tabelle 1 ist die Erstellungszeit der einzelnen Modelltrainingsdaten aufgeführt, und in Tabelle 2 ist das Veröffentlichungsdatum jedes Datensatzes aufgeführt.
Die Überlegung für den oben genannten Ansatz besteht darin, dass das Modell bei Zero-Shot- und Fence-Shot-Bewertungen Vorhersagen zu Aufgaben trifft, die es während des Trainings noch nie oder nur ein paar Mal gesehen hat. Die wichtigste Voraussetzung ist, dass das Modell zuvor keinem Kontakt ausgesetzt war die spezifische Aufgabe, die erledigt werden soll, und stellen so eine faire Beurteilung ihrer Lernfähigkeit sicher. Allerdings können fehlerhafte Modelle den Eindruck einer Kompetenz erwecken, der sie nicht oder nur ein paar Mal ausgesetzt waren, weil sie während des Vortrainings anhand von Aufgabenbeispielen trainiert wurden. In einem chronologischen Datensatz lassen sich solche Inkonsistenzen relativ einfacher erkennen, da etwaige Überschneidungen oder Anomalien offensichtlich sind.
Messmethoden
Die Forscher verwendeten vier Methoden, um die „Aufgabenverschmutzung“ zu messen:
- Prüfung der Trainingsdaten: Suche nach Aufgabentrainingsbeispielen in den Trainingsdaten.
- Extrahieren von Aufgabenbeispielen: Extrahieren Sie Aufgabenbeispiele aus vorhandenen Modellen. Es können nur anweisungsabgestimmte Modelle extrahiert werden. Diese Analyse kann auch für Trainingsdaten oder Testdatenextraktion verwendet werden. Beachten Sie, dass die extrahierten Aufgabenbeispiele nicht genau mit vorhandenen Trainingsdatenbeispielen übereinstimmen müssen, um eine Aufgabenkontamination zu erkennen. Jedes Beispiel, das eine Aufgabe demonstriert, zeigt die mögliche Kontamination von Zero-Shot-Lernen und Fow-Shot-Lernen.
- Member-Inferenz: Diese Methode ist nur für Generierungsaufgaben geeignet. Überprüft, ob der vom Modell generierte Inhalt für die Eingabeinstanz genau mit dem Originaldatensatz übereinstimmt. Wenn es genau übereinstimmt, können wir daraus schließen, dass es sich um ein Mitglied der LLM-Trainingsdaten handelt. Dies unterscheidet sich von der Extraktion von Aufgabenbeispielen dadurch, dass die generierte Ausgabe auf eine genaue Übereinstimmung überprüft wird. Exakte Übereinstimmungen bei der offenen Generierungsaufgabe weisen stark darauf hin, dass das Modell diese Beispiele während des Trainings gesehen hat, es sei denn, das Modell ist „psychisch“ und kennt den genauen Wortlaut, der in den Daten verwendet wird. (Beachten Sie, dass dies nur für Build-Aufgaben verwendet werden kann.)
- Timing-Analyse: Messen Sie die Leistung eines Modellsatzes, bei dem Trainingsdaten über einen bekannten Zeitraum gesammelt wurden, anhand eines Datensatzes mit einem bekannten Veröffentlichungsdatum und prüfen Sie ihn mithilfe des Timings auf Kontamination Beweise Beweise.
Die ersten drei Methoden haben eine hohe Präzision, aber eine niedrige Rückrufrate. Wenn Sie die Daten in den Trainingsdaten der Aufgabe finden, können Sie sicher sein, dass das Modell das Beispiel gesehen hat. Aufgrund von Änderungen in den Datenformaten, Änderungen in den Schlüsselwörtern, die zur Definition von Aufgaben verwendet werden, und der Größe der Datensätze ist die Tatsache, dass mit den ersten drei Methoden keine Hinweise auf eine Kontamination gefunden werden, jedoch kein Beweis dafür, dass keine Kontamination vorliegt.
Die vierte Methode, die chronologische Analyse, hat eine hohe Erinnerungsrate, aber eine geringe Präzision. Wenn die Leistung aufgrund einer Aufgabenkontamination hoch ist, besteht eine gute Chance, dies durch eine chronologische Analyse zu erkennen. Aber auch andere Faktoren können dazu führen, dass sich die Leistung mit der Zeit verbessert und daher weniger genau ist.
Daher verwendeten die Forscher alle vier Methoden, um eine Aufgabenkontamination zu erkennen, und fanden starke Hinweise auf eine Aufgabenkontamination in bestimmten Modell- und Datensatzkombinationen.
Sie führten zunächst eine Zeitanalyse für alle getesteten Modelle und Datensätze durch, da diese am wahrscheinlichsten war, um eine mögliche Kontamination zu erkennen. Anschließend nutzten sie die Inspektion von Trainingsdaten und die Extraktion von Aufgabenbeispielen, um weitere Hinweise auf eine Kontamination der Aufgabe zu finden Aufgaben und schließlich zusätzliche Analyse mithilfe von Mitgliedschaftsinferenzangriffen.
Die wichtigsten Schlussfolgerungen lauten wie folgt:
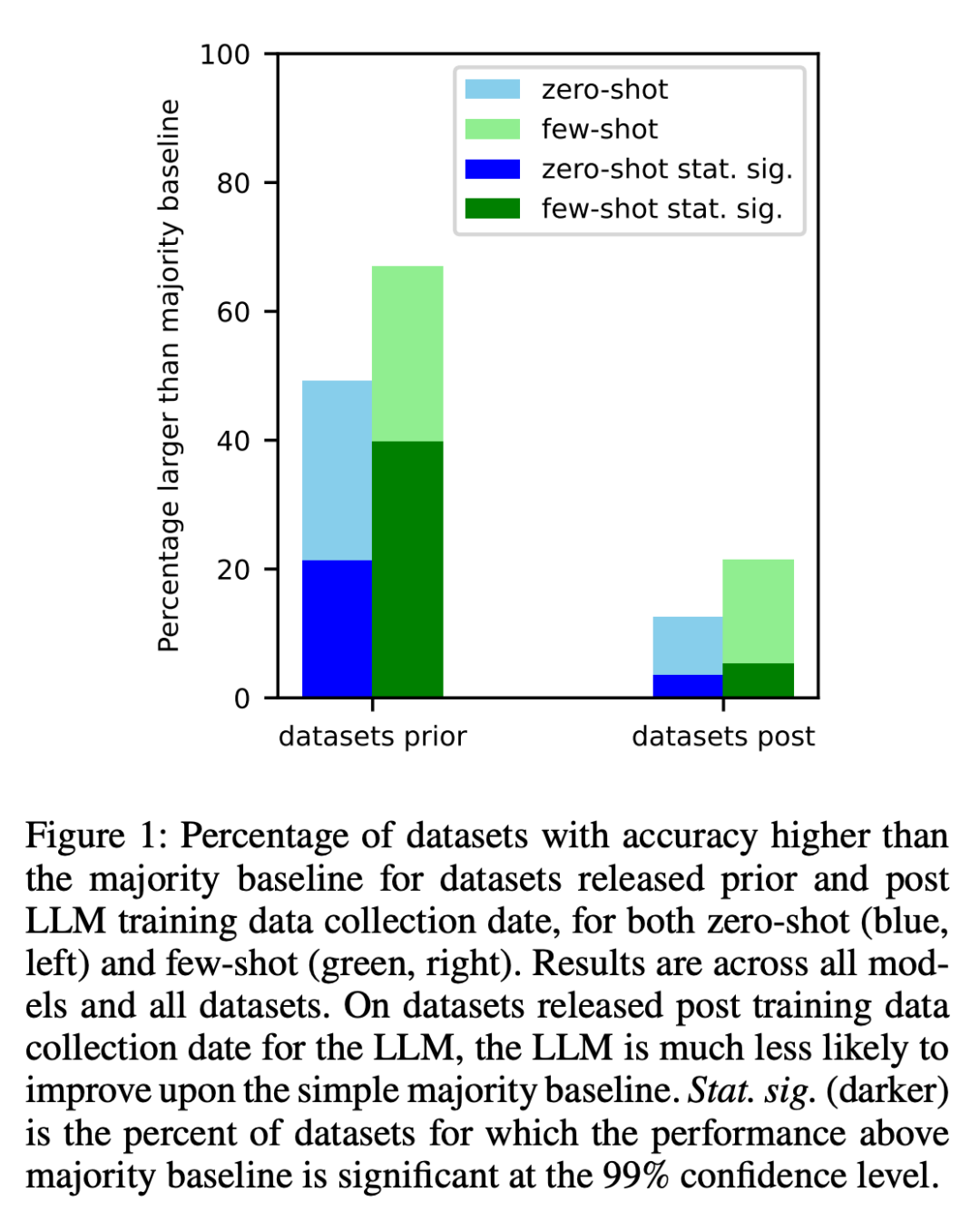
1 Die Forscher analysierten die Datensätze, die vor und nach dem Crawlen der Trainingsdaten jedes Modells im Internet erstellt wurden. Es wurde festgestellt, dass die Chancen, über den meisten Ausgangswerten zu liegen, bei Datensätzen, die vor der Erfassung der LLM-Trainingsdaten erstellt wurden, deutlich höher waren (Abbildung 1).
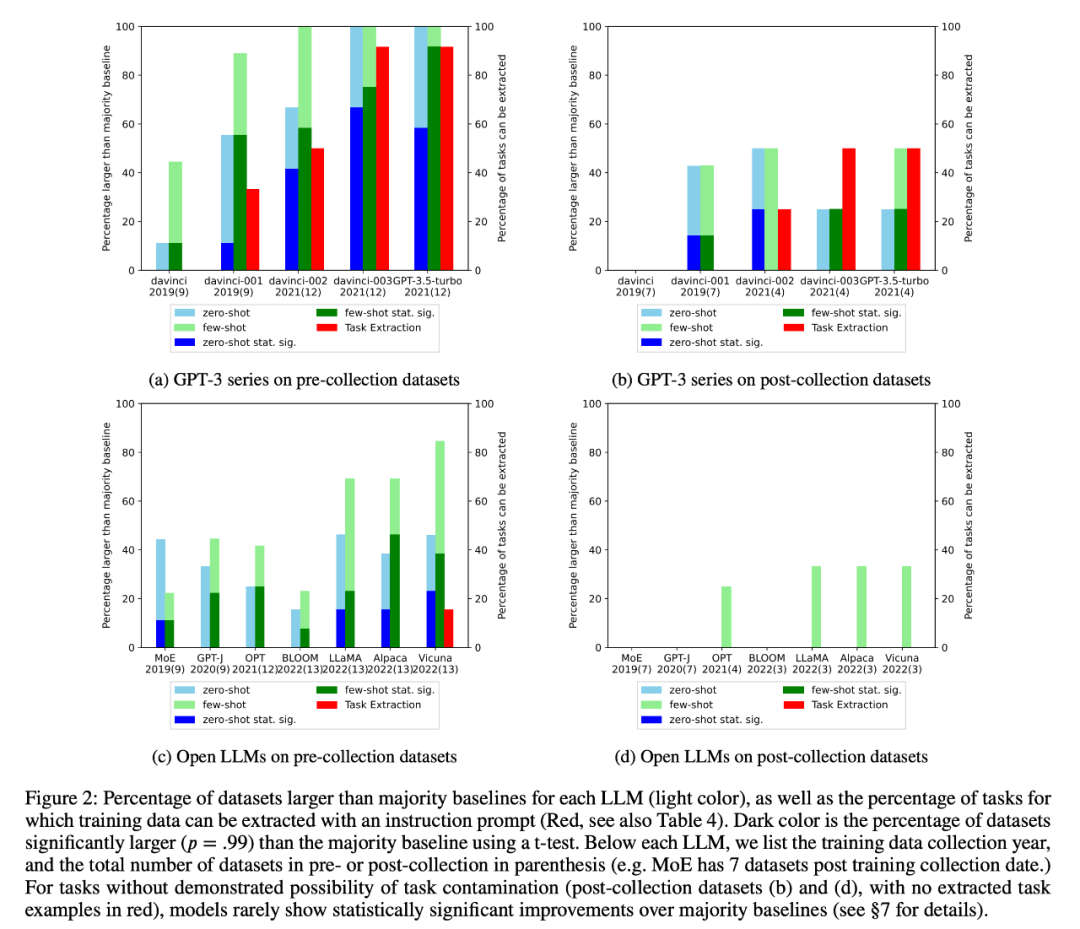
2 Der Forscher führte eine Inspektion der Trainingsdaten und eine Extraktion von Aufgabenbeispielen durch, um mögliche Aufgabenkontaminationen zu finden. Es wurde festgestellt, dass bei Klassifizierungsaufgaben, bei denen eine Aufgabenkontamination unwahrscheinlich ist, Modelle selten statistisch signifikante Verbesserungen gegenüber einfachen Mehrheitsbasislinien über eine Reihe von Aufgaben hinweg erzielen, unabhängig davon, ob es sich um Null- oder Wenig-Schuss-Aufgaben handelt (Abbildung 2).
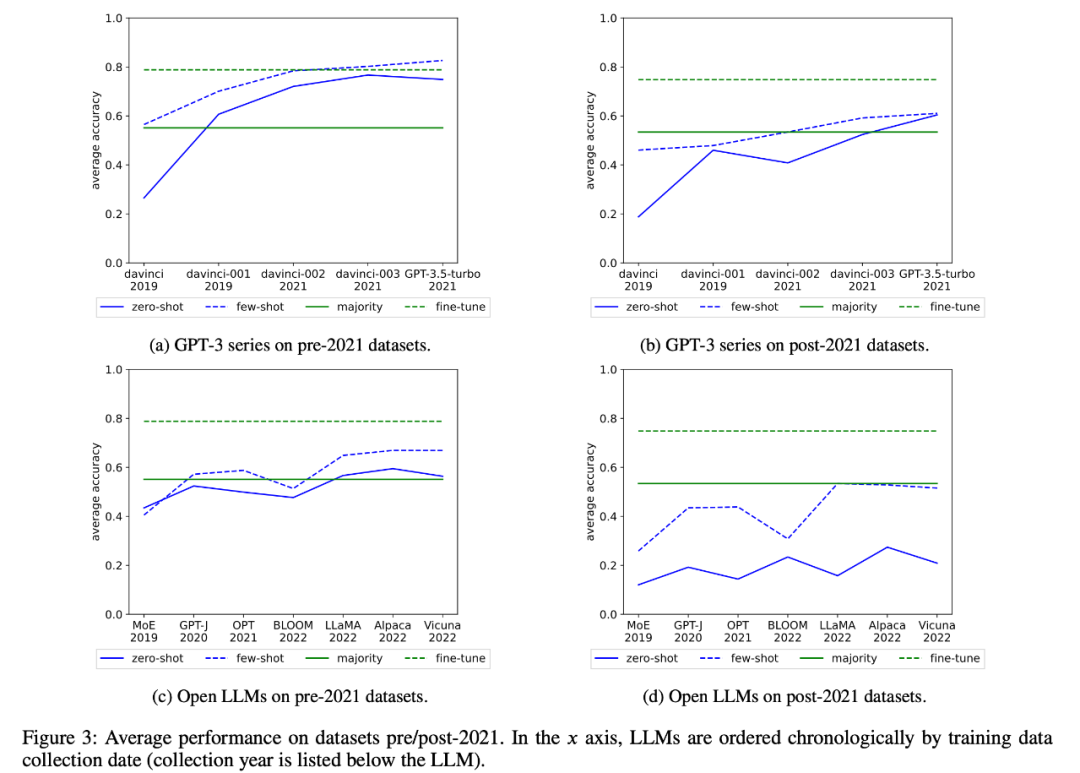
Die Forscher überprüften auch die durchschnittliche Leistung der GPT-3-Serie und des offenen LLM im Zeitverlauf, wie in Abbildung 3 dargestellt:
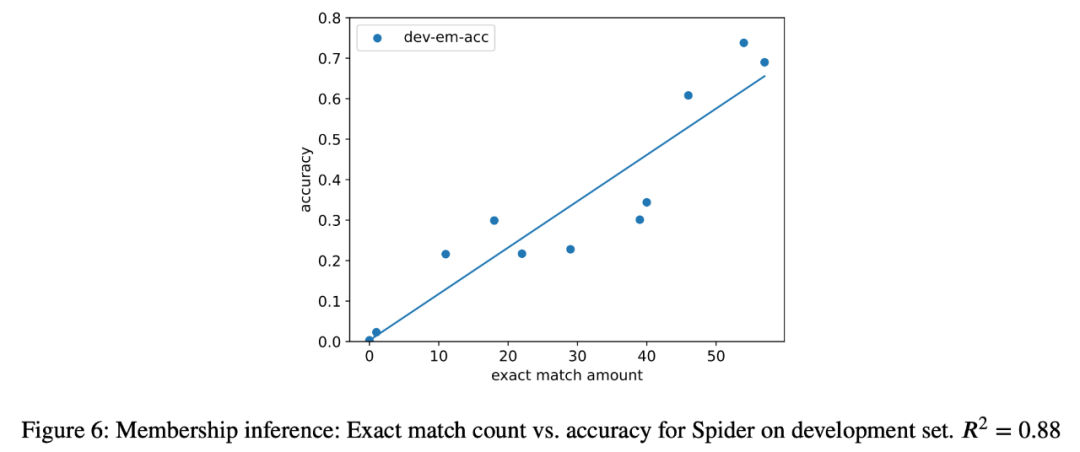
3. Die Forscher versuchten auch Member-Inferenzangriffe auf die semantische Parsing-Aufgabe bei allen Modellen in der Analyse und es wurde eine starke Korrelation (R=0,88) zwischen der Anzahl der extrahierten Instanzen und der Genauigkeit des Modells in der endgültigen Aufgabe festgestellt (Abbildung 6). ). Dies ist ein starker Beweis dafür, dass die Verbesserung der Nullschussleistung bei dieser Aufgabe auf eine Aufgabenkontamination zurückzuführen ist.
4. Die Forscher haben auch die Modelle der GPT-3-Serie sorgfältig untersucht und festgestellt, dass Trainingsbeispiele aus dem GPT-3-Modell extrahiert werden können, und in jeder Version von davinci bis GPT-3.5-turbo die Anzahl der Trainingsbeispiele, die sein können Die extrahierte Menge nimmt zu, was eng mit der Verbesserung der Zero-Shot-Leistung des GPT-3-Modells bei dieser Aufgabe zusammenhängt (Abbildung 2). Dies ist ein starker Beweis dafür, dass die Leistungsverbesserung der GPT-3-Modelle von Davinci bis GPT-3.5-Turbo bei diesen Aufgaben auf Aufgabenkontamination zurückzuführen ist.
Das obige ist der detaillierte Inhalt vonEine neue Interpretation des sinkenden Intelligenzniveaus von GPT-4. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1374
1374
 52
52

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 Wählen Sie das Einbettungsmodell, das am besten zu Ihren Daten passt: Ein Vergleichstest von OpenAI und mehrsprachigen Open-Source-Einbettungen
Feb 26, 2024 pm 06:10 PM
Wählen Sie das Einbettungsmodell, das am besten zu Ihren Daten passt: Ein Vergleichstest von OpenAI und mehrsprachigen Open-Source-Einbettungen
Feb 26, 2024 pm 06:10 PM
OpenAI kündigte kürzlich die Einführung seines Einbettungsmodells embeddingv3 der neuesten Generation an, das seiner Meinung nach das leistungsstärkste Einbettungsmodell mit höherer Mehrsprachenleistung ist. Diese Reihe von Modellen ist in zwei Typen unterteilt: das kleinere Text-Embeddings-3-Small und das leistungsfähigere und größere Text-Embeddings-3-Large. Es werden nur wenige Informationen darüber offengelegt, wie diese Modelle entworfen und trainiert werden, und auf die Modelle kann nur über kostenpflichtige APIs zugegriffen werden. Es gab also viele Open-Source-Einbettungsmodelle. Aber wie schneiden diese Open-Source-Modelle im Vergleich zum Closed-Source-Modell von OpenAI ab? In diesem Artikel wird die Leistung dieser neuen Modelle empirisch mit Open-Source-Modellen verglichen. Wir planen, Daten zu erstellen
 Ein neues Programmierparadigma, wenn Spring Boot auf OpenAI trifft
Feb 01, 2024 pm 09:18 PM
Ein neues Programmierparadigma, wenn Spring Boot auf OpenAI trifft
Feb 01, 2024 pm 09:18 PM
Im Jahr 2023 ist die KI-Technologie zu einem heißen Thema geworden und hat enorme Auswirkungen auf verschiedene Branchen, insbesondere im Programmierbereich. Die Bedeutung der KI-Technologie wird den Menschen zunehmend bewusst, und die Spring-Community bildet da keine Ausnahme. Mit der kontinuierlichen Weiterentwicklung der GenAI-Technologie (General Artificial Intelligence) ist es entscheidend und dringend geworden, die Erstellung von Anwendungen mit KI-Funktionen zu vereinfachen. Vor diesem Hintergrund entstand „SpringAI“ mit dem Ziel, den Prozess der Entwicklung von KI-Funktionsanwendungen zu vereinfachen, ihn einfach und intuitiv zu gestalten und unnötige Komplexität zu vermeiden. Durch „SpringAI“ können Entwickler einfacher Anwendungen mit KI-Funktionen erstellen, wodurch diese einfacher zu verwenden und zu bedienen sind.
 Der Ameca der zweiten Generation ist da! Er kann fließend mit dem Publikum kommunizieren, sein Gesichtsausdruck ist realistischer und er kann Dutzende Sprachen sprechen.
Mar 04, 2024 am 09:10 AM
Der Ameca der zweiten Generation ist da! Er kann fließend mit dem Publikum kommunizieren, sein Gesichtsausdruck ist realistischer und er kann Dutzende Sprachen sprechen.
Mar 04, 2024 am 09:10 AM
Der humanoide Roboter Ameca wurde auf die zweite Generation aufgerüstet! Kürzlich erschien auf der World Mobile Communications Conference MWC2024 erneut der weltweit fortschrittlichste Roboter Ameca. Rund um den Veranstaltungsort lockte Ameca zahlreiche Zuschauer an. Mit dem Segen von GPT-4 kann Ameca in Echtzeit auf verschiedene Probleme reagieren. „Lass uns tanzen.“ Auf die Frage, ob sie Gefühle habe, antwortete Ameca mit einer Reihe von Gesichtsausdrücken, die sehr lebensecht aussahen. Erst vor wenigen Tagen stellte EngineeredArts, das britische Robotikunternehmen hinter Ameca, die neuesten Entwicklungsergebnisse des Teams vor. Im Video verfügt der Roboter Ameca über visuelle Fähigkeiten und kann den gesamten Raum und bestimmte Objekte sehen und beschreiben. Das Erstaunlichste ist, dass sie es auch kann
 Nach 750.000 Runden Einzelkampf zwischen großen Modellen gewann GPT-4 die Meisterschaft und Llama 3 belegte den fünften Platz
Apr 23, 2024 pm 03:28 PM
Nach 750.000 Runden Einzelkampf zwischen großen Modellen gewann GPT-4 die Meisterschaft und Llama 3 belegte den fünften Platz
Apr 23, 2024 pm 03:28 PM
Zu Llama3 wurden neue Testergebnisse veröffentlicht – die große Modellbewertungs-Community LMSYS veröffentlichte eine große Modell-Rangliste, die Llama3 auf dem fünften Platz belegte und mit GPT-4 den ersten Platz in der englischen Kategorie belegte. Das Bild unterscheidet sich von anderen Benchmarks. Diese Liste basiert auf Einzelkämpfen zwischen Modellen, und die Bewerter aus dem gesamten Netzwerk machen ihre eigenen Vorschläge und Bewertungen. Am Ende belegte Llama3 den fünften Platz auf der Liste, gefolgt von drei verschiedenen Versionen von GPT-4 und Claude3 Super Cup Opus. In der englischen Einzelliste überholte Llama3 Claude und punktgleich mit GPT-4. Über dieses Ergebnis war Metas Chefwissenschaftler LeCun sehr erfreut und leitete den Tweet weiter
 Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Wenn die Antwort des KI-Modells überhaupt unverständlich ist, würden Sie es wagen, sie zu verwenden? Da maschinelle Lernsysteme in immer wichtigeren Bereichen eingesetzt werden, wird es immer wichtiger zu zeigen, warum wir ihren Ergebnissen vertrauen können und wann wir ihnen nicht vertrauen sollten. Eine Möglichkeit, Vertrauen in die Ausgabe eines komplexen Systems zu gewinnen, besteht darin, vom System zu verlangen, dass es eine Interpretation seiner Ausgabe erstellt, die für einen Menschen oder ein anderes vertrauenswürdiges System lesbar ist, d. h. so vollständig verständlich, dass mögliche Fehler erkannt werden können gefunden. Um beispielsweise Vertrauen in das Justizsystem aufzubauen, verlangen wir von den Gerichten, dass sie klare und lesbare schriftliche Stellungnahmen abgeben, die ihre Entscheidungen erläutern und stützen. Für große Sprachmodelle können wir auch einen ähnlichen Ansatz verfolgen. Stellen Sie bei diesem Ansatz jedoch sicher, dass das Sprachmodell generiert wird
 Der Rust-basierte Zed-Editor ist Open Source und bietet integrierte Unterstützung für OpenAI und GitHub Copilot
Feb 01, 2024 pm 02:51 PM
Der Rust-basierte Zed-Editor ist Open Source und bietet integrierte Unterstützung für OpenAI und GitHub Copilot
Feb 01, 2024 pm 02:51 PM
Autor丨Zusammengestellt von TimAnderson丨Produziert von Noah|51CTO Technology Stack (WeChat-ID: blog51cto) Das Zed-Editor-Projekt befindet sich noch in der Vorabversionsphase und wurde unter AGPL-, GPL- und Apache-Lizenzen als Open Source bereitgestellt. Der Editor zeichnet sich durch hohe Leistung und mehrere KI-gestützte Optionen aus, ist jedoch derzeit nur auf der Mac-Plattform verfügbar. Nathan Sobo erklärte in einem Beitrag, dass in der Codebasis des Zed-Projekts auf GitHub der Editor-Teil unter der GPL lizenziert ist, die serverseitigen Komponenten unter der AGPL lizenziert sind und der GPUI-Teil (GPU Accelerated User) die Schnittstelle übernimmt Apache2.0-Lizenz. GPUI ist ein vom Zed-Team entwickeltes Produkt
 Das leistungsstärkste Modell der Welt wechselte über Nacht den Besitzer und markierte damit das Ende der GPT-4-Ära! Claude 3 hat GPT-5 im Voraus durchgelesen und einen Aufsatz mit 10.000 Wörtern in 3 Sekunden gelesen. Sein Verständnis kommt dem des Menschen nahe.
Mar 06, 2024 pm 12:58 PM
Das leistungsstärkste Modell der Welt wechselte über Nacht den Besitzer und markierte damit das Ende der GPT-4-Ära! Claude 3 hat GPT-5 im Voraus durchgelesen und einen Aufsatz mit 10.000 Wörtern in 3 Sekunden gelesen. Sein Verständnis kommt dem des Menschen nahe.
Mar 06, 2024 pm 12:58 PM
Die Lautstärke ist verrückt, die Lautstärke ist verrückt und das große Modell hat sich wieder verändert. Gerade eben wechselte das leistungsstärkste KI-Modell der Welt über Nacht den Besitzer und GPT-4 wurde vom Altar genommen. Anthropic hat die neueste Claude3-Modellreihe veröffentlicht. Eine Satzbewertung: Sie zerschmettert GPT-4 wirklich! In Bezug auf multimodale Indikatoren und Sprachfähigkeitsindikatoren gewinnt Claude3. In den Worten von Anthropic haben die Modelle der Claude3-Serie neue Branchenmaßstäbe in den Bereichen Argumentation, Mathematik, Codierung, Mehrsprachenverständnis und Vision gesetzt! Anthropic ist ein Startup-Unternehmen, das von Mitarbeitern gegründet wurde, die aufgrund unterschiedlicher Sicherheitskonzepte von OpenAI „abgelaufen“ sind. Ihre Produkte haben OpenAI immer wieder hart getroffen. Dieses Mal musste sich Claude3 sogar einer großen Operation unterziehen.
