
 Technologie-Peripheriegeräte
KI
Kleine, aber feine Modelle sind auf dem Vormarsch: TinyLlama und LiteLlama erfreuen sich großer Beliebtheit
Technologie-Peripheriegeräte
KI
Kleine, aber feine Modelle sind auf dem Vormarsch: TinyLlama und LiteLlama erfreuen sich großer Beliebtheit
Kleine, aber feine Modelle sind auf dem Vormarsch: TinyLlama und LiteLlama erfreuen sich großer Beliebtheit

Derzeit beginnen Forscher, sich auf kompakte und leistungsstarke kleine Modelle zu konzentrieren, obwohl alle große Modelle mit Parameterskalen im zweistelligen oder sogar hunderten Milliardenbereich untersuchen.
Kleine Modelle werden häufig in Edge-Geräten wie Smartphones, IoT-Geräten und eingebetteten Systemen verwendet. Diese Geräte verfügen oft nur über begrenzte Rechenleistung und Speicherplatz und können große Sprachmodelle nicht effizient ausführen. Daher kommt der Untersuchung kleiner Modelle eine besondere Bedeutung zu.
Die beiden Studien, die wir als nächstes vorstellen, könnten Ihren Bedarf an kleinen Modellen decken.
TinyLlama-1.1B
Forscher der Singapore University of Technology and Design (SUTD) haben kürzlich TinyLlama veröffentlicht, ein Sprachmodell mit 1,1 Milliarden Parametern, das auf etwa 3 Billionen Zug-Tokens vorab trainiert wurde.

- Papieradresse: https://arxiv.org/pdf/2401.02385.pdf
- Projektadresse: https://github.com/jzhang38/TinyLlama/blob/main/ README_zh-CN.md
TinyLlama basiert auf der Llama 2-Architektur und dem Tokenizer, was die Integration in viele Open-Source-Projekte mit Llama erleichtert. Darüber hinaus verfügt TinyLlama nur über 1,1 Milliarden Parameter und ist klein, was es ideal für Anwendungen macht, die einen begrenzten Rechen- und Speicherbedarf erfordern.
Die Studie zeigt, dass nur 16 A100-40G-GPUs das Training von TinyLlama in 90 Tagen abschließen können.

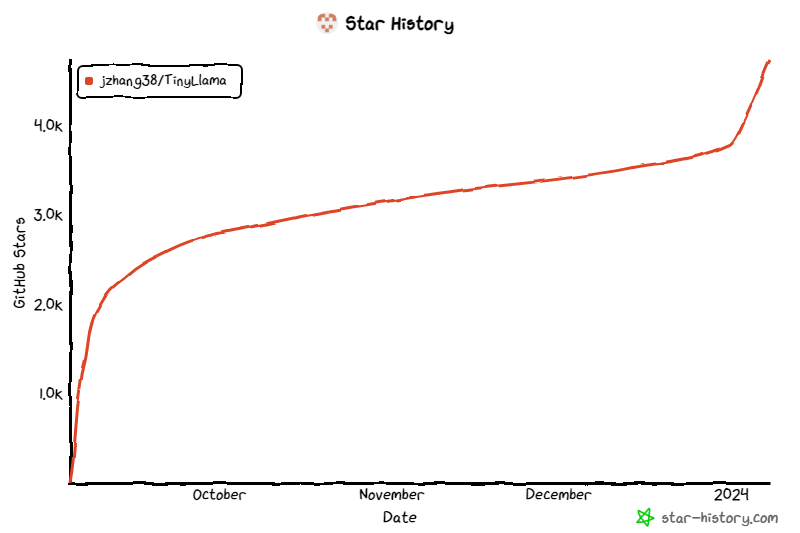
Das Projekt hat seit seiner Einführung weiterhin Aufmerksamkeit erhalten und die aktuelle Anzahl der Sterne hat 4,7.000 erreicht. Die Details zur TinyLlama-Modellarchitektur lauten wie folgt: die Verwendung größerer Daten Potenzial für das Training kleinerer Modelle. Sie konzentrierten sich auf die Untersuchung des Verhaltens kleinerer Modelle, wenn sie mit einer viel größeren Anzahl von Token trainiert wurden, als vom Skalierungsgesetz empfohlen.
 Konkret wurden in der Studie etwa 3 Billionen Token verwendet, um ein Transformer-Modell (nur Decoder) mit 1,1B-Parametern zu trainieren. Unseres Wissens ist dies der erste Versuch, eine so große Datenmenge zu verwenden, um ein Modell mit 1B Parametern zu trainieren.
Konkret wurden in der Studie etwa 3 Billionen Token verwendet, um ein Transformer-Modell (nur Decoder) mit 1,1B-Parametern zu trainieren. Unseres Wissens ist dies der erste Versuch, eine so große Datenmenge zu verwenden, um ein Modell mit 1B Parametern zu trainieren.
Trotz seiner relativ geringen Größe schneidet TinyLlama bei einer Reihe nachgelagerter Aufgaben recht gut ab und übertrifft bestehende Open-Source-Sprachmodelle derselben Größe deutlich. Insbesondere übertrifft TinyLlama OPT-1.3B und Pythia1.4B bei verschiedenen nachgelagerten Aufgaben.

Mit der Unterstützung dieser Technologien erreicht der TinyLlama-Trainingsdurchsatz 24.000 Token pro Sekunde pro A100-40G-GPU. Beispielsweise benötigt das TinyLlama-1.1B-Modell nur 3.456 A100-GPU-Stunden für 300B-Tokens, verglichen mit 4.830 Stunden für Pythia und 7.920 Stunden für MPT. Dies zeigt die Wirksamkeit der Optimierung dieser Studie und das Potenzial, beim groß angelegten Modelltraining erhebliche Zeit- und Ressourceneinsparungen zu erzielen.
 TinyLlama erreicht eine Trainingsgeschwindigkeit von 24.000 Token/Sekunde/A100. Diese Geschwindigkeit entspricht einem Chinchilla-optimalen Modell mit 1,1 Milliarden Parametern und 22 Milliarden Token, die Benutzer in 32 Stunden auf 8 A100 trainieren können. Gleichzeitig reduzieren diese Optimierungen auch die Speichernutzung erheblich. Benutzer können ein 1,1-Milliarden-Parameter-Modell in eine 40-GB-GPU packen und dabei eine Stapelgröße von 16.000 Tokens pro GPU beibehalten. Ändern Sie einfach die Batch-Größe etwas kleiner, und Sie können TinyLlama auf RTX 3090/4090 trainieren.
TinyLlama erreicht eine Trainingsgeschwindigkeit von 24.000 Token/Sekunde/A100. Diese Geschwindigkeit entspricht einem Chinchilla-optimalen Modell mit 1,1 Milliarden Parametern und 22 Milliarden Token, die Benutzer in 32 Stunden auf 8 A100 trainieren können. Gleichzeitig reduzieren diese Optimierungen auch die Speichernutzung erheblich. Benutzer können ein 1,1-Milliarden-Parameter-Modell in eine 40-GB-GPU packen und dabei eine Stapelgröße von 16.000 Tokens pro GPU beibehalten. Ändern Sie einfach die Batch-Größe etwas kleiner, und Sie können TinyLlama auf RTX 3090/4090 trainieren.
In dem Experiment konzentrierte sich diese Forschung hauptsächlich auf Sprachmodelle mit reiner Decoder-Architektur, die etwa 1 Milliarde Parameter enthielten. Konkret verglich die Studie TinyLlama mit OPT-1.3B, Pythia-1.0B und Pythia-1.4B.
Die Leistung von TinyLlama bei Aufgaben zum gesunden Menschenverstand ist unten dargestellt. Es ist ersichtlich, dass TinyLlama bei vielen Aufgaben besser abschneidet und die höchste Durchschnittspunktzahl erzielt.

Darüber hinaus verfolgten die Forscher die Genauigkeit von TinyLlama anhand von Benchmarks zum gesunden Menschenverstand während des Vortrainings. Wie in Abbildung 2 gezeigt, verbessert sich die Leistung von TinyLlama mit der Erhöhung der Rechenressourcen und übertrifft in den meisten Benchmarks die Genauigkeit von Pythia-1.4B.
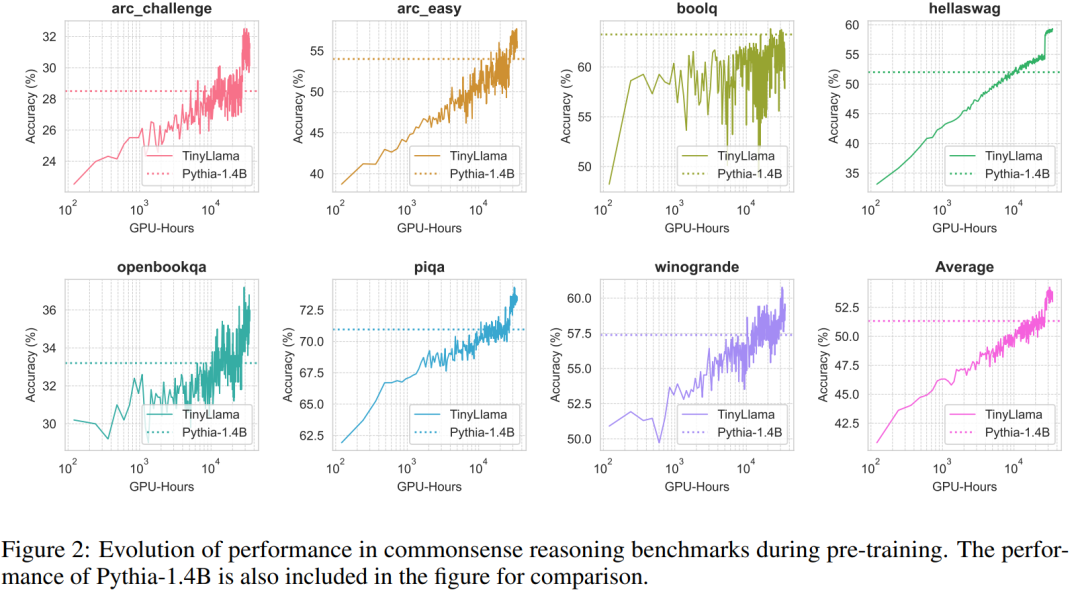
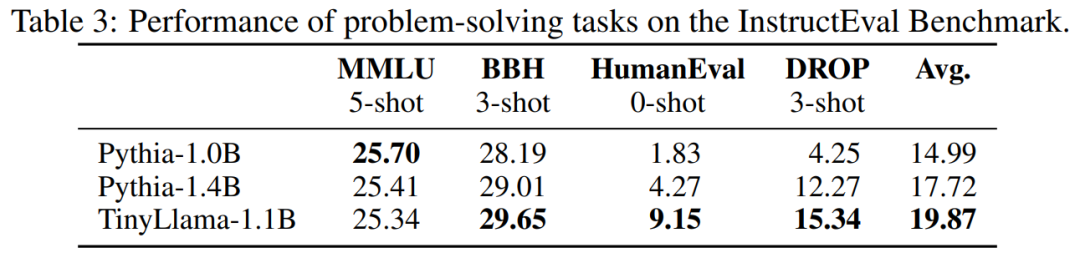
Tabelle 3 zeigt, dass TinyLlama im Vergleich zu bestehenden Modellen bessere Problemlösungsfähigkeiten aufweist.
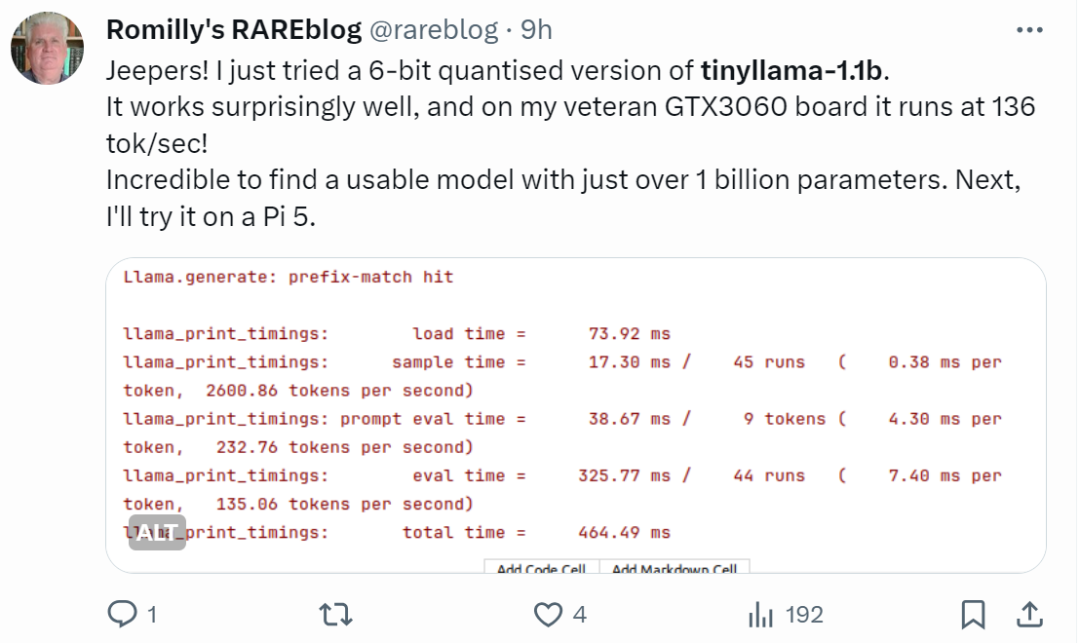
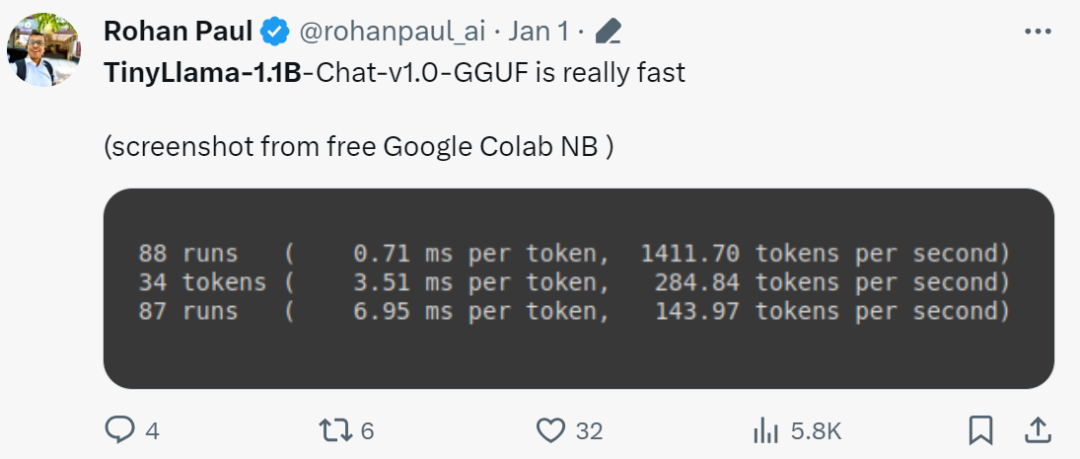
Netizens mit schnellen Händen haben bereits begonnen: Der Laufeffekt ist überraschend gut, mit GTX3060 kann es mit einer Geschwindigkeit von 136 Tok/Sekunde laufen. „Es ist wirklich schnell!“ große Aufmerksamkeit erregen. Xiaotian Han von der Texas Tech und A&M University hat SLM-LiteLlama veröffentlicht. Es verfügt über 460 Millionen Parameter und wird mit 1T-Tokens trainiert. Dies ist ein Open-Source-Fork von LLaMa 2 von Meta AI, jedoch mit einer deutlich kleineren Modellgröße.
Projektadresse: https://huggingface.co/ahxt/LiteLlama-460M-1T
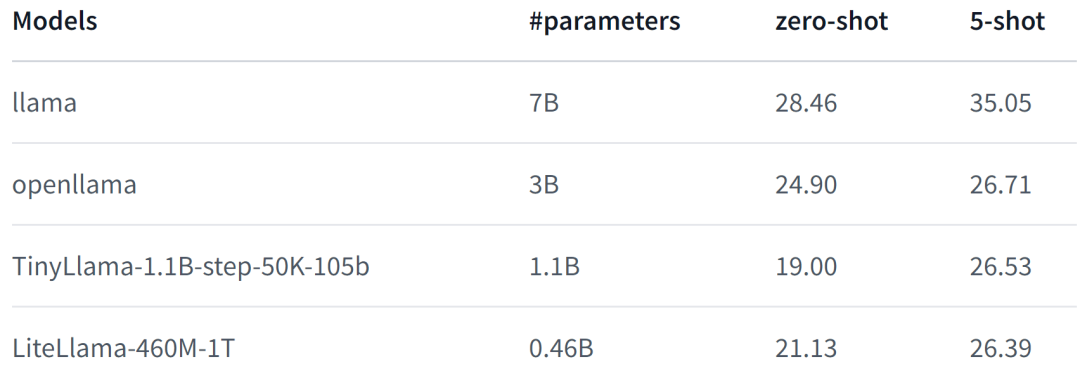
 LiteLlama-460M-1T wird auf dem RedPajama-Datensatz trainiert und verwendet GPT2Tokenizer, um den Text zu tokenisieren. Der Autor hat das Modell anhand der MMLU-Aufgabe bewertet. Die Ergebnisse sind in der folgenden Abbildung dargestellt. Selbst mit einer deutlich reduzierten Anzahl von Parametern kann LiteLlama-460M-1T immer noch Ergebnisse erzielen, die mit anderen Modellen vergleichbar oder besser sind.
LiteLlama-460M-1T wird auf dem RedPajama-Datensatz trainiert und verwendet GPT2Tokenizer, um den Text zu tokenisieren. Der Autor hat das Modell anhand der MMLU-Aufgabe bewertet. Die Ergebnisse sind in der folgenden Abbildung dargestellt. Selbst mit einer deutlich reduzierten Anzahl von Parametern kann LiteLlama-460M-1T immer noch Ergebnisse erzielen, die mit anderen Modellen vergleichbar oder besser sind.
Das Folgende ist die Leistung des Modells. Weitere Details finden Sie unter:
https://www.php.cn/link/05ec1d748d9e3bbc975a057f7cd02fb6
Angesichts der Größe wurde LiteLlama stark verkleinert, und einige Internetnutzer sind neugierig, ob es mit 4 GB Speicher ausgeführt werden kann. Wenn Sie es auch wissen wollen, probieren Sie es doch einfach selbst aus.
Das obige ist der detaillierte Inhalt vonKleine, aber feine Modelle sind auf dem Vormarsch: TinyLlama und LiteLlama erfreuen sich großer Beliebtheit. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1379
1379
 52
52

 Debian Mail Server Firewall -Konfigurationstipps
Apr 13, 2025 am 11:42 AM
Debian Mail Server Firewall -Konfigurationstipps
Apr 13, 2025 am 11:42 AM
Das Konfigurieren der Firewall eines Debian -Mailservers ist ein wichtiger Schritt zur Gewährleistung der Serversicherheit. Im Folgenden sind mehrere häufig verwendete Firewall -Konfigurationsmethoden, einschließlich der Verwendung von Iptables und Firewalld. Verwenden Sie Iptables, um Firewall so zu konfigurieren, dass Iptables (falls bereits installiert) installiert werden:
 So setzen Sie die Debian Apache -Protokollebene fest
Apr 13, 2025 am 08:33 AM
So setzen Sie die Debian Apache -Protokollebene fest
Apr 13, 2025 am 08:33 AM
In diesem Artikel wird beschrieben, wie Sie die Protokollierungsstufe des Apacheweb -Servers im Debian -System anpassen. Durch Ändern der Konfigurationsdatei können Sie die ausführliche Ebene der von Apache aufgezeichneten Protokollinformationen steuern. Methode 1: Ändern Sie die Hauptkonfigurationsdatei, um die Konfigurationsdatei zu finden: Die Konfigurationsdatei von Apache2.x befindet sich normalerweise im Verzeichnis/etc/apache2/. Der Dateiname kann je nach Installationsmethode Apache2.conf oder httpd.conf sein. Konfigurationsdatei bearbeiten: Öffnen Sie die Konfigurationsdatei mit Stammberechtigungen mit einem Texteditor (z. B. Nano): Sudonano/etc/apache2/apache2.conf
 Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Wie Debian Readdir sich in andere Tools integriert
Apr 13, 2025 am 09:42 AM
Die Readdir -Funktion im Debian -System ist ein Systemaufruf, der zum Lesen des Verzeichnisgehalts verwendet wird und häufig in der C -Programmierung verwendet wird. In diesem Artikel wird erläutert, wie Readdir in andere Tools integriert wird, um seine Funktionalität zu verbessern. Methode 1: Kombinieren Sie C -Sprachprogramm und Pipeline zuerst ein C -Programm, um die Funktion der Readdir aufzurufen und das Ergebnis auszugeben:#include#include#includeIntmain (intargc, char*argv []) {Dir*Dir; structDirent*Eintrag; if (argc! = 2) {{
 So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
In Debian -Systemen werden Readdir -Systemaufrufe zum Lesen des Verzeichnisinhalts verwendet. Wenn seine Leistung nicht gut ist, probieren Sie die folgende Optimierungsstrategie aus: Vereinfachen Sie die Anzahl der Verzeichnisdateien: Teilen Sie große Verzeichnisse so weit wie möglich in mehrere kleine Verzeichnisse auf und reduzieren Sie die Anzahl der gemäß Readdir -Anrufe verarbeiteten Elemente. Aktivieren Sie den Verzeichnis -Inhalt Caching: Erstellen Sie einen Cache -Mechanismus, aktualisieren Sie den Cache regelmäßig oder bei Änderungen des Verzeichnisinhalts und reduzieren Sie häufige Aufrufe an Readdir. Speicher -Caches (wie Memcached oder Redis) oder lokale Caches (wie Dateien oder Datenbanken) können berücksichtigt werden. Nehmen Sie eine effiziente Datenstruktur an: Wenn Sie das Verzeichnis -Traversal selbst implementieren, wählen Sie effizientere Datenstrukturen (z.
 Debian Mail Server SSL -Zertifikat -Installationsmethode
Apr 13, 2025 am 11:39 AM
Debian Mail Server SSL -Zertifikat -Installationsmethode
Apr 13, 2025 am 11:39 AM
Die Schritte zur Installation eines SSL -Zertifikats auf dem Debian Mail -Server sind wie folgt: 1. Installieren Sie zuerst das OpenSSL -Toolkit und stellen Sie sicher, dass das OpenSSL -Toolkit bereits in Ihrem System installiert ist. Wenn nicht installiert, können Sie den folgenden Befehl installieren: sudoapt-getupdatesudoapt-getinstallopenssl2. Generieren Sie den privaten Schlüssel und die Zertifikatanforderung als nächst
 So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
So implementieren Sie die Dateisortierung nach Debian Readdir
Apr 13, 2025 am 09:06 AM
In Debian -Systemen wird die Readdir -Funktion zum Lesen des Verzeichnisinhalts verwendet, aber die Reihenfolge, in der sie zurückgibt, ist nicht vordefiniert. Um Dateien in einem Verzeichnis zu sortieren, müssen Sie zuerst alle Dateien lesen und dann mit der QSORT -Funktion sortieren. Der folgende Code zeigt, wie Verzeichnisdateien mithilfe von Readdir und QSORT in Debian System sortiert werden:#include#include#include#include // benutzerdefinierte Vergleichsfunktion, verwendet für QSortIntCompare (constvoid*a, constvoid*b) {rettrcmp (*(*(*(
 So führen Sie die digitale Signaturüberprüfung mit Debian OpenSSL durch
Apr 13, 2025 am 11:09 AM
So führen Sie die digitale Signaturüberprüfung mit Debian OpenSSL durch
Apr 13, 2025 am 11:09 AM
Unter Verwendung von OpenSSL für die digitale Signaturüberprüfung im Debian -System können Sie folgende Schritte befolgen: Vorbereitung für die Installation von OpenSSL: Stellen Sie sicher, dass Ihr Debian -System OpenSSL installiert hat. Wenn nicht installiert, können Sie den folgenden Befehl verwenden, um es zu installieren: sudoaptupdatesudoaptininTallopenSSL, um den öffentlichen Schlüssel zu erhalten: Die digitale Signaturüberprüfung erfordert den öffentlichen Schlüssel des Unterzeichners. In der Regel wird der öffentliche Schlüssel in Form einer Datei wie Public_key.pe bereitgestellt
 Wie Debian OpenSSL verhindert, dass Mann-in-the-Middle-Angriffe
Apr 13, 2025 am 10:30 AM
Wie Debian OpenSSL verhindert, dass Mann-in-the-Middle-Angriffe
Apr 13, 2025 am 10:30 AM
In Debian Systems ist OpenSSL eine wichtige Bibliothek für Verschlüsselung, Entschlüsselung und Zertifikatverwaltung. Um einen Mann-in-the-Middle-Angriff (MITM) zu verhindern, können folgende Maßnahmen ergriffen werden: Verwenden Sie HTTPS: Stellen Sie sicher, dass alle Netzwerkanforderungen das HTTPS-Protokoll anstelle von HTTP verwenden. HTTPS verwendet TLS (Transport Layer Security Protocol), um Kommunikationsdaten zu verschlüsseln, um sicherzustellen, dass die Daten während der Übertragung nicht gestohlen oder manipuliert werden. Überprüfen Sie das Serverzertifikat: Überprüfen Sie das Serverzertifikat im Client manuell, um sicherzustellen, dass es vertrauenswürdig ist. Der Server kann manuell durch die Delegate -Methode der URLSession überprüft werden
