
 Technologie-Peripheriegeräte
KI
Nutzung von Wissensgraphen, um die Fähigkeiten von RAG-Modellen zu verbessern und falsche Eindrücke von großen Modellen zu verringern
Technologie-Peripheriegeräte
KI
Nutzung von Wissensgraphen, um die Fähigkeiten von RAG-Modellen zu verbessern und falsche Eindrücke von großen Modellen zu verringern
Nutzung von Wissensgraphen, um die Fähigkeiten von RAG-Modellen zu verbessern und falsche Eindrücke von großen Modellen zu verringern

Illusion ist ein häufiges Problem bei der Verwendung großer Sprachmodelle (LLM). Obwohl LLM glatte und kohärente Texte erzeugen kann, sind die generierten Informationen oft ungenau oder inkonsistent. Um LLM-Halluzinationen vorzubeugen, können externe Wissensquellen wie Datenbanken oder Wissensgraphen zur Bereitstellung sachlicher Informationen genutzt werden. Auf diese Weise kann sich LLM auf diese zuverlässigen Datenquellen verlassen, was zu genaueren und zuverlässigeren Textinhalten führt.
Vektordatenbank und Wissensgraph
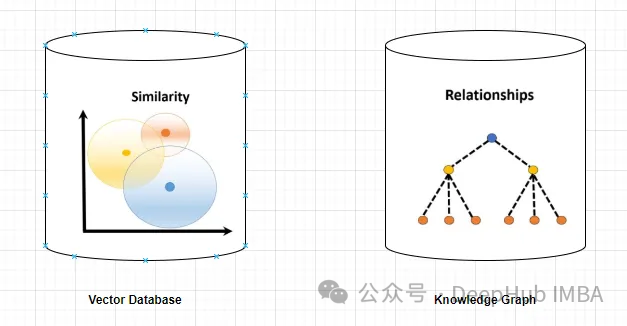
Vektordatenbank
Eine Vektordatenbank ist ein Satz hochdimensionaler Vektoren, die Entitäten oder Konzepte darstellen. Sie können verwendet werden, um die Ähnlichkeit oder Korrelation zwischen verschiedenen Entitäten oder Konzepten zu messen, die anhand ihrer Vektordarstellungen berechnet werden.
Eine Vektordatenbank kann Ihnen anhand der Vektorentfernung sagen, dass „Paris“ und „Frankreich“ stärker verwandt sind als „Paris“ und „Deutschland“.
Das Abfragen einer Vektordatenbank umfasst normalerweise die Suche nach ähnlichen Vektoren oder das Abrufen von Vektoren basierend auf bestimmten Kriterien. Das Folgende ist ein einfaches Beispiel für die Abfrage einer Vektordatenbank.
Angenommen, es gibt eine hochdimensionale Vektordatenbank, in der Kundenprofile gespeichert sind. Sie möchten Kunden finden, die einem bestimmten Referenzkunden ähneln.
Um einen Kunden als Vektordarstellung zu definieren, können wir zunächst relevante Merkmale oder Attribute extrahieren und in Vektorform umwandeln.
Eine Ähnlichkeitssuche kann in einer Vektordatenbank unter Verwendung eines geeigneten Algorithmus wie k-nächster Nachbar oder Kosinusähnlichkeit durchgeführt werden, um die ähnlichsten Nachbarn zu identifizieren.
Kundenprofile abrufen, die den ermittelten Vektoren für den nächsten Nachbarn entsprechen und Kunden darstellen, die dem Referenzkunden gemäß dem definierten Ähnlichkeitsmaß ähnlich sind.
Zeigen Sie dem Benutzer das abgerufene Kundenprofil oder zugehörige Informationen wie Name, demografische Daten oder Kaufhistorie.
Wissensgraph
Ein Wissensgraph ist eine Sammlung von Knoten und Kanten, die Entitäten oder Konzepte und ihre Beziehungen (z. B. Fakten, Attribute oder Kategorien) darstellen. Basierend auf ihren Knoten- und Kantenattributen können sie verwendet werden, um Sachinformationen über verschiedene Entitäten oder Konzepte abzufragen oder daraus abzuleiten.
Zum Beispiel kann Ihnen ein Wissensgraph anhand von Kantenbeschriftungen sagen, dass „Paris“ die Hauptstadt von „Frankreich“ ist.
Das Abfragen einer Diagrammdatenbank umfasst das Durchlaufen der Diagrammstruktur und das Abrufen von Knoten, Beziehungen oder Mustern basierend auf bestimmten Kriterien.
Angenommen, Sie verfügen über eine Diagrammdatenbank, die ein soziales Netzwerk darstellt, in dem Benutzer Knoten sind und ihre Beziehungen als Kanten dargestellt werden, die die Knoten verbinden. Wenn Freunde von Freunden (gemeinsame Verbindungen) für einen bestimmten Benutzer gefunden werden, sollten wir Folgendes tun:
1. Identifizieren Sie den Knoten, der den Referenzbenutzer in der Diagrammdatenbank darstellt. Dies kann durch die Abfrage einer bestimmten Benutzerkennung oder anderer relevanter Kriterien erreicht werden.
2. Verwenden Sie eine Diagrammabfragesprache wie Cypher (verwendet in Neo4j) oder Gremlin, um das Diagramm von einem Referenzbenutzerknoten aus zu durchlaufen. Geben Sie Muster oder Beziehungen an, die untersucht werden sollen.
MATCH (:User {userId: ‘referenceUser’})-[:FRIEND]->()-[:FRIEND]->(fof:User) RETURN fofDiese Abfrage beginnt mit dem Referenzbenutzer, folgt der FRIEND-Beziehung, um einen anderen Knoten zu finden (FRIEND), und folgt dann einer weiteren FRIEND-Beziehung, um Freunde von Freunden zu finden (fof).
3. Führen Sie eine Abfrage in der Diagrammdatenbank aus, rufen Sie die Ergebnisknoten (Freunde von Freunden) entsprechend dem Abfragemodus ab und rufen Sie bestimmte Attribute oder andere Informationen zu den abgerufenen Knoten ab.
Graphdatenbanken können erweiterte Abfragefunktionen bereitstellen, einschließlich Filterung, Aggregation und komplexer Mustervergleich. Die spezifische Abfragesprache und -syntax kann variieren, aber der allgemeine Prozess umfasst das Durchlaufen der Diagrammstruktur, um Knoten und Beziehungen abzurufen, die die erforderlichen Kriterien erfüllen.
Vorteile von Wissensgraphen bei der Lösung des „Illusions“-Problems
Wissensgraphen liefern präzisere und spezifischere Informationen als Vektordatenbanken. Eine Vektordatenbank stellt die Ähnlichkeit oder Korrelation zwischen zwei Entitäten oder Konzepten dar, während ein Wissensgraph ein besseres Verständnis der Beziehung zwischen ihnen ermöglicht. Der Wissensgraph kann Ihnen beispielsweise sagen, dass „Eiffelturm“ das Wahrzeichen von „Paris“ ist, während die Vektordatenbank nur die Ähnlichkeit der beiden Konzepte zeigen kann, aber nicht erklärt, wie sie zusammenhängen.
Knowledge Graph unterstützt vielfältigere und komplexere Abfragen als Vektordatenbanken. Vektordatenbanken können in erster Linie Anfragen beantworten, die auf Vektorabstand, Ähnlichkeit oder nächstem Nachbarn basieren und auf direkte Ähnlichkeitsmaße beschränkt sind. Und der Wissensgraph kann Abfragen basierend auf logischen Operatoren verarbeiten, z. B. „Was sind alle Entitäten mit dem Attribut Z?“ oder „Was ist die gemeinsame Kategorie von W und V?“ Dies kann LLM dabei helfen, vielfältigere und interessantere Texte zu generieren.
Wissensdiagramme eignen sich besser für Argumentationen und Schlussfolgerungen als Vektordatenbanken. Vektordatenbanken können nur direkt in der Datenbank gespeicherte Informationen bereitstellen. Wissensgraphen können indirekte Informationen liefern, die aus Beziehungen zwischen Entitäten oder Konzepten abgeleitet werden. Beispielsweise kann ein Wissensgraph auf der Grundlage der beiden Fakten „Paris ist die Hauptstadt Frankreichs“ und „Frankreich liegt in Europa“ auf „Der Eiffelturm liegt in Europa“ schließen. Dies kann LLM dabei helfen, logischeren und konsistenteren Text zu generieren.
Der Wissensgraph ist also eine bessere Lösung als die Vektordatenbank. Dies stellt LLMs genauere, relevantere, vielfältigere, interessantere, logischere und konsistentere Informationen zur Verfügung und macht sie zuverlässiger bei der Erstellung präziser und authentischer Texte. Der Schlüssel hier ist jedoch, dass eine klare Beziehung zwischen den Dokumentdokumenten bestehen muss, da der Wissensgraph diese sonst nicht erfassen kann.
但是,知识图谱的使用并没有向量数据库那么直接简单,不仅在内容的梳理(数据),应用部署,查询生成等方面都没有向量数据库那么方便,这也影响了它在实际应用中的使用频率。所以下面我们使用一个简单的例子来介绍如何使用知识图谱构建RAG。
代码实现
我们需要使用3个主要工具/组件:
1、LlamaIndex是一个编排框架,它简化了私有数据与公共数据的集成,它提供了数据摄取、索引和查询的工具,使其成为生成式人工智能需求的通用解决方案。
2、嵌入模型将文本转换为文本所提供的一条信息的数字表示形式。这种表示捕获了所嵌入内容的语义含义,使其对于许多行业应用程序都很健壮。这里使用“thenlper/gte-large”模型。
3、需要大型语言模型来根据所提供的问题和上下文生成响应。这里使用Zephyr 7B beta模型
下面我们开始进行代码编写,首先安装包
%%capture pip install llama_index pyvis Ipython langchain pypdf
启用日志Logging Level设置为“INFO”,我们可以输出有助于监视应用程序操作流的消息
import logging import sys # logging.basicConfig(stream=sys.stdout, level=logging.INFO) logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
导入依赖项
from llama_index import (SimpleDirectoryReader,LLMPredictor,ServiceContext,KnowledgeGraphIndex) # from llama_index.graph_stores import SimpleGraphStore from llama_index.storage.storage_context import StorageContext from llama_index.llms import HuggingFaceInferenceAPI from langchain.embeddings import HuggingFaceInferenceAPIEmbeddings from llama_index.embeddings import LangchainEmbedding from pyvis.network import Network
我们使用Huggingface推理api端点载入LLM
HF_TOKEN = "api key DEEPHUB 123456" llm = HuggingFaceInferenceAPI(model_name="HuggingFaceH4/zephyr-7b-beta", token=HF_TOKEN )
首先载入嵌入模型:
embed_model = LangchainEmbedding(HuggingFaceInferenceAPIEmbeddings(api_key=HF_TOKEN,model_name="thenlper/gte-large") )
加载数据集
documents = SimpleDirectoryReader("/content/Documents").load_data() print(len(documents)) ####Output### 44构建知识图谱索引
创建知识图谱通常涉及专业和复杂的任务。通过利用Llama Index (LLM)、KnowledgeGraphIndex和GraphStore,可以方便地任何数据源创建一个相对有效的知识图谱。
#setup the service context service_context = ServiceContext.from_defaults(chunk_size=256,llm=llm,embed_model=embed_model ) #setup the storage context graph_store = SimpleGraphStore() storage_context = StorageContext.from_defaults(graph_store=graph_store) #Construct the Knowlege Graph Undex index = KnowledgeGraphIndex.from_documents( documents=documents,max_triplets_per_chunk=3,service_context=service_context,storage_context=storage_context,include_embeddings=True)
Max_triplets_per_chunk:它控制每个数据块处理的关系三元组的数量
Include_embeddings:切换在索引中包含嵌入以进行高级分析。
通过构建查询引擎对知识图谱进行查询
query = "What is ESOP?" query_engine = index.as_query_engine(include_text=True,response_mode ="tree_summarize",embedding_mode="hybrid",similarity_top_k=5,) # message_template =f"""Please check if the following pieces of context has any mention of the keywords provided in the Question.If not then don't know the answer, just say that you don't know.Stop there.Please donot try to make up an answer. Question: {query} Helpful Answer: """ # response = query_engine.query(message_template) # print(response.response.split("")[-1].strip()) #####OUTPUT ##################### ESOP stands for Employee Stock Ownership Plan. It is a retirement plan that allows employees to receive company stock or stock options as part of their compensation. In simpler terms, it is a plan that allows employees to own a portion of the company they work for. This can be a motivating factor for employees as they have a direct stake in the company's success. ESOPs can also be a tax-efficient way for companies to provide retirement benefits to their employees.可以看到,输出的结果已经很好了,可以说与向量数据库的结果非常一致。
最后还可以可视化我们生成的图谱,使用Pyvis库进行可视化展示
from pyvis.network import Network from IPython.display import display g = index.get_networkx_graph() net = Network(notebook=True,cdn_resources="in_line",directed=True) net.from_nx(g) net.show("graph.html") net.save_graph("Knowledge_graph.html") # import IPython IPython.display.HTML(filename="/content/Knowledge_graph.html")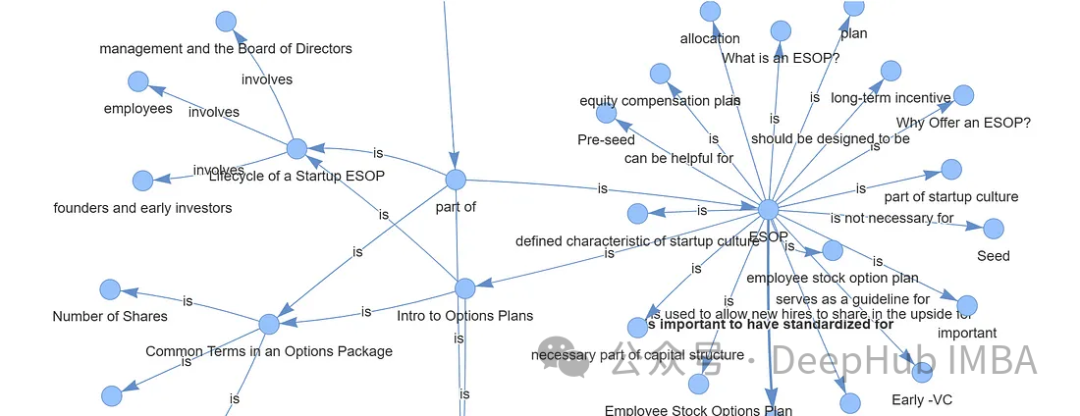

通过上面的代码我们可以直接通过LLM生成知识图谱,这样简化了我们非常多的人工操作。如果需要更精准更完整的知识图谱,还需要人工手动检查,这里就不细说了。
数据存储,通过持久化数据,可以将结果保存到硬盘中,供以后使用。
storage_context.persist()
存储的结果如下:

总结
向量数据库和知识图谱的区别在于它们存储和表示数据的方法。向量数据库擅长基于相似性的操作,依靠数值向量来测量实体之间的距离。知识图谱通过节点和边缘捕获复杂的关系和依赖关系,促进语义分析和高级推理。
对于语言模型(LLM)幻觉,知识图被证明优于向量数据库。知识图谱提供了更准确、多样、有趣、有逻辑性和一致性的信息,减少了LLM产生幻觉的可能性。这种优势源于它们能够提供实体之间关系的精确细节,而不仅仅是表明相似性,从而支持更复杂的查询和逻辑推理。
在以前知识图谱的应用难点在于图谱的构建,但是现在LLM的出现简化了这个过程,使得我们可以轻松的构建出可用的知识图谱,这使得他在应用方面又向前迈出了一大步。对于RAG,知识图谱是一个非常好的应用方向。
Das obige ist der detaillierte Inhalt vonNutzung von Wissensgraphen, um die Fähigkeiten von RAG-Modellen zu verbessern und falsche Eindrücke von großen Modellen zu verringern. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1371
1371
 52
52

 Warum verwenden große Sprachmodelle SwiGLU als Aktivierungsfunktion?
Apr 08, 2024 pm 09:31 PM
Warum verwenden große Sprachmodelle SwiGLU als Aktivierungsfunktion?
Apr 08, 2024 pm 09:31 PM
Wenn Sie sich mit der Architektur großer Sprachmodelle befasst haben, ist Ihnen möglicherweise der Begriff „SwiGLU“ in den neuesten Modellen und Forschungsarbeiten aufgefallen. Man kann sagen, dass SwiGLU die am häufigsten verwendete Aktivierungsfunktion in großen Sprachmodellen ist. Wir werden sie in diesem Artikel ausführlich vorstellen. SwiGLU ist eigentlich eine von Google im Jahr 2020 vorgeschlagene Aktivierungsfunktion, die die Eigenschaften von SWISH und GLU kombiniert. Der vollständige chinesische Name von SwiGLU lautet „bidirektionale Gated Linear Unit“. Es optimiert und kombiniert zwei Aktivierungsfunktionen, SWISH und GLU, um die nichtlineare Ausdrucksfähigkeit des Modells zu verbessern. SWISH ist eine sehr häufige Aktivierungsfunktion, die in großen Sprachmodellen weit verbreitet ist, während GLU bei Aufgaben zur Verarbeitung natürlicher Sprache eine gute Leistung gezeigt hat.
 Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Kontexterweiterter KI-Codierungsassistent mit Rag und Sem-Rag
Jun 10, 2024 am 11:08 AM
Verbessern Sie die Produktivität, Effizienz und Genauigkeit der Entwickler, indem Sie eine abrufgestützte Generierung und ein semantisches Gedächtnis in KI-Codierungsassistenten integrieren. Übersetzt aus EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, Autor JanakiramMSV. Obwohl grundlegende KI-Programmierassistenten natürlich hilfreich sind, können sie oft nicht die relevantesten und korrektesten Codevorschläge liefern, da sie auf einem allgemeinen Verständnis der Softwaresprache und den gängigsten Mustern beim Schreiben von Software basieren. Der von diesen Coding-Assistenten generierte Code eignet sich zur Lösung der von ihnen zu lösenden Probleme, entspricht jedoch häufig nicht den Coding-Standards, -Konventionen und -Stilen der einzelnen Teams. Dabei entstehen häufig Vorschläge, die geändert oder verfeinert werden müssen, damit der Code in die Anwendung übernommen wird
 Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Kann LLM durch Feinabstimmung wirklich neue Dinge lernen: Die Einführung neuen Wissens kann dazu führen, dass das Modell mehr Halluzinationen hervorruft
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) werden auf riesigen Textdatenbanken trainiert und erwerben dort große Mengen an realem Wissen. Dieses Wissen wird in ihre Parameter eingebettet und kann dann bei Bedarf genutzt werden. Das Wissen über diese Modelle wird am Ende der Ausbildung „verdinglicht“. Am Ende des Vortrainings hört das Modell tatsächlich auf zu lernen. Richten Sie das Modell aus oder verfeinern Sie es, um zu erfahren, wie Sie dieses Wissen nutzen und natürlicher auf Benutzerfragen reagieren können. Aber manchmal reicht Modellwissen nicht aus, und obwohl das Modell über RAG auf externe Inhalte zugreifen kann, wird es als vorteilhaft angesehen, das Modell durch Feinabstimmung an neue Domänen anzupassen. Diese Feinabstimmung erfolgt mithilfe von Eingaben menschlicher Annotatoren oder anderer LLM-Kreationen, wobei das Modell auf zusätzliches Wissen aus der realen Welt trifft und dieses integriert
 GraphRAG verbessert für den Abruf von Wissensgraphen (implementiert basierend auf Neo4j-Code)
Jun 12, 2024 am 10:32 AM
GraphRAG verbessert für den Abruf von Wissensgraphen (implementiert basierend auf Neo4j-Code)
Jun 12, 2024 am 10:32 AM
Graph Retrieval Enhanced Generation (GraphRAG) erfreut sich zunehmender Beliebtheit und hat sich zu einer leistungsstarken Ergänzung zu herkömmlichen Vektorsuchmethoden entwickelt. Diese Methode nutzt die strukturellen Merkmale von Graphdatenbanken, um Daten in Form von Knoten und Beziehungen zu organisieren und dadurch die Tiefe und kontextbezogene Relevanz der abgerufenen Informationen zu verbessern. Diagramme haben einen natürlichen Vorteil bei der Darstellung und Speicherung vielfältiger und miteinander verbundener Informationen und können problemlos komplexe Beziehungen und Eigenschaften zwischen verschiedenen Datentypen erfassen. Vektordatenbanken können diese Art von strukturierten Informationen nicht verarbeiten und konzentrieren sich mehr auf die Verarbeitung unstrukturierter Daten, die durch hochdimensionale Vektoren dargestellt werden. In RAG-Anwendungen können wir durch die Kombination strukturierter Diagrammdaten und unstrukturierter Textvektorsuche gleichzeitig die Vorteile beider nutzen, worauf in diesem Artikel eingegangen wird. Struktur
 Visualisieren Sie den FAISS-Vektorraum und passen Sie die RAG-Parameter an, um die Ergebnisgenauigkeit zu verbessern
Mar 01, 2024 pm 09:16 PM
Visualisieren Sie den FAISS-Vektorraum und passen Sie die RAG-Parameter an, um die Ergebnisgenauigkeit zu verbessern
Mar 01, 2024 pm 09:16 PM
Da sich die Leistung groß angelegter Open-Source-Sprachmodelle weiter verbessert, hat sich auch die Leistung beim Schreiben und Analysieren von Code, Empfehlungen, Textzusammenfassungen und Frage-Antwort-Paaren (QA) verbessert. Aber wenn es um die Qualitätssicherung geht, mangelt es LLM oft an Problemen im Zusammenhang mit ungeschulten Daten, und viele interne Dokumente werden im Unternehmen aufbewahrt, um Compliance, Geschäftsgeheimnisse oder Datenschutz zu gewährleisten. Wenn diese Dokumente abgefragt werden, kann LLM Halluzinationen hervorrufen und irrelevante, erfundene oder inkonsistente Inhalte produzieren. Eine mögliche Technik zur Bewältigung dieser Herausforderung ist Retrieval Augmented Generation (RAG). Dabei geht es darum, die Antworten durch Verweise auf maßgebliche Wissensdatenbanken über die Trainingsdatenquelle hinaus zu verbessern, um die Qualität und Genauigkeit der Generierung zu verbessern. Das RAG-System umfasst ein Retrieval-System zum Abrufen relevanter Dokumentfragmente aus dem Korpus
 Optimierung von LLM mithilfe der SPIN-Technologie für das Feinabstimmungstraining für das Selbstspiel
Jan 25, 2024 pm 12:21 PM
Optimierung von LLM mithilfe der SPIN-Technologie für das Feinabstimmungstraining für das Selbstspiel
Jan 25, 2024 pm 12:21 PM
2024 ist ein Jahr der rasanten Entwicklung für große Sprachmodelle (LLM). In der Ausbildung von LLM sind Alignment-Methoden ein wichtiges technisches Mittel, einschließlich Supervised Fine-Tuning (SFT) und Reinforcement Learning mit menschlichem Feedback, das auf menschlichen Präferenzen basiert (RLHF). Diese Methoden haben eine entscheidende Rolle bei der Entwicklung von LLM gespielt, aber Alignment-Methoden erfordern eine große Menge manuell annotierter Daten. Angesichts dieser Herausforderung ist die Feinabstimmung zu einem dynamischen Forschungsgebiet geworden, in dem Forscher aktiv an der Entwicklung von Methoden arbeiten, mit denen menschliche Daten effektiv genutzt werden können. Daher wird die Entwicklung von Ausrichtungsmethoden weitere Durchbrüche in der LLM-Technologie fördern. Die University of California hat kürzlich eine Studie zur Einführung einer neuen Technologie namens SPIN (SelfPlayfInetuNing) durchgeführt. S
 Nutzung von Wissensgraphen, um die Fähigkeiten von RAG-Modellen zu verbessern und falsche Eindrücke von großen Modellen zu verringern
Jan 14, 2024 pm 06:30 PM
Nutzung von Wissensgraphen, um die Fähigkeiten von RAG-Modellen zu verbessern und falsche Eindrücke von großen Modellen zu verringern
Jan 14, 2024 pm 06:30 PM
Halluzinationen sind ein häufiges Problem bei der Arbeit mit großen Sprachmodellen (LLMs). Obwohl LLM glatte und kohärente Texte erzeugen kann, sind die generierten Informationen oft ungenau oder inkonsistent. Um LLM vor Halluzinationen zu schützen, können externe Wissensquellen wie Datenbanken oder Wissensgraphen zur Bereitstellung sachlicher Informationen genutzt werden. Auf diese Weise kann sich LLM auf diese zuverlässigen Datenquellen verlassen, was zu genaueren und zuverlässigeren Textinhalten führt. Vektordatenbank und Wissensgraph-Vektordatenbank Eine Vektordatenbank ist ein Satz hochdimensionaler Vektoren, die Entitäten oder Konzepte darstellen. Sie können verwendet werden, um die Ähnlichkeit oder Korrelation zwischen verschiedenen Entitäten oder Konzepten zu messen, die anhand ihrer Vektordarstellungen berechnet werden. Eine Vektordatenbank kann Ihnen anhand der Vektorentfernung sagen, dass „Paris“ und „Frankreich“ näher beieinander liegen als „Paris“ und
 GraphRAG verstehen (1): Herausforderungen von RAG
Apr 30, 2024 pm 07:10 PM
GraphRAG verstehen (1): Herausforderungen von RAG
Apr 30, 2024 pm 07:10 PM
RAG (RiskAssessmentGrid) ist eine Methode, die bestehende große Sprachmodelle (LLM) mit externen Wissensquellen erweitert, um kontextbezogenere Antworten zu liefern. In RAG erfasst die Abrufkomponente zusätzliche Informationen und Antworten auf der Grundlage spezifischer Quellen und speist diese Informationen dann in die LLM-Eingabeaufforderung ein, sodass die Antwort des LLM auf diesen Informationen basiert (Verbesserungsphase). RAG ist im Vergleich zu anderen Techniken wie dem Trimmen wirtschaftlicher. Es hat auch den Vorteil, Halluzinationen zu reduzieren, indem zusätzlicher Kontext basierend auf diesen Informationen bereitgestellt wird (Augmentationsphase) – Ihr RAG wird zur Workflow-Methode für die heutigen LLM-Aufgaben (wie Empfehlung, Textextraktion, Stimmungsanalyse usw.). Wenn wir diese Idee basierend auf der Benutzerabsicht weiter aufschlüsseln, betrachten wir normalerweise Folgendes
