
 Technologie-Peripheriegeräte
KI
Ein tiefer Einblick in Modelle, Daten und Frameworks: eine ausführliche 54-seitige Übersicht über effiziente große Sprachmodelle
Technologie-Peripheriegeräte
KI
Ein tiefer Einblick in Modelle, Daten und Frameworks: eine ausführliche 54-seitige Übersicht über effiziente große Sprachmodelle
Ein tiefer Einblick in Modelle, Daten und Frameworks: eine ausführliche 54-seitige Übersicht über effiziente große Sprachmodelle

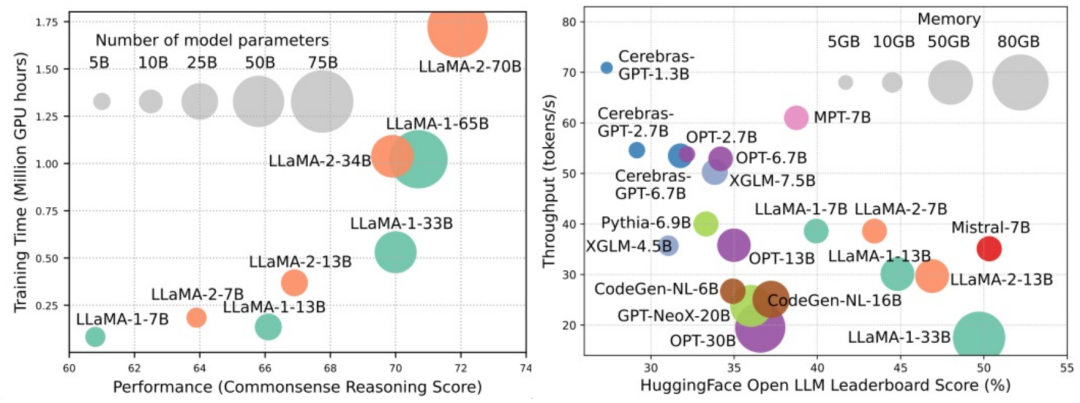
Groß angelegte Sprachmodelle (LLMs) haben überzeugende Fähigkeiten bei vielen wichtigen Aufgaben gezeigt, darunter das Verständnis natürlicher Sprache, die Sprachgenerierung und komplexes Denken, und hatten tiefgreifende Auswirkungen auf die Gesellschaft. Diese herausragenden Fähigkeiten erfordern jedoch erhebliche Schulungsressourcen (im linken Bild dargestellt) und lange Inferenzzeiten (im rechten Bild dargestellt). Daher müssen Forscher wirksame technische Mittel entwickeln, um ihre Effizienzprobleme zu lösen.
Darüber hinaus wurden, wie auf der rechten Seite der Abbildung zu sehen ist, einige effiziente LLMs (Sprachmodelle) wie Mistral-7B erfolgreich beim Entwurf und Einsatz von LLMs eingesetzt. Diese effizienten LLMs können die Nutzung des Inferenzspeichers erheblich reduzieren und die Inferenzlatenz reduzieren, während sie gleichzeitig eine ähnliche Genauigkeit wie LLaMA1-33B beibehalten. Dies zeigt, dass es bereits einige praktikable und effiziente Methoden gibt, die bei der Gestaltung und Nutzung von LLMs erfolgreich angewendet werden.
In diesem Bericht geben Forscher der Ohio State University, des Imperial College, der Michigan State University, der University of Michigan, Amazon, Google, Boson AI und Microsoft Asia Research umfassende Einblicke in die Forschung zu effizienten LLMs Überblick über das System. Sie teilten bestehende Technologien zur Optimierung der Effizienz von LLMs in drei Kategorien ein, darunter modellzentriert, datenzentriert und Framework-zentriert, und fassten die modernsten verwandten Technologien zusammen und diskutierten sie.
... LLM s -Umfrage 
- Um die an der Überprüfung beteiligten Papiere bequem zu organisieren und auf dem neuesten Stand zu halten, hat der Forscher ein GitHub-Repository erstellt und pflegt es aktiv. Sie hoffen, dass dieses Repositorium Forschern und Praktikern hilft, die Forschung und Entwicklung effizienter LLMs systematisch zu verstehen und sie dazu inspiriert, zu diesem wichtigen und spannenden Gebiet beizutragen.
- Die URL des Lagers lautet https://github.com/AIoT-MLSys-Lab/Efficient-LLMs-Survey. In diesem Repository finden Sie Inhalte zu einer Umfrage zu effizienten und stromsparenden maschinellen Lernsystemen. Dieses Repository stellt Forschungsarbeiten, Code und Dokumentation bereit, um Menschen dabei zu helfen, effiziente und energieeffiziente maschinelle Lernsysteme besser zu verstehen und zu erkunden. Wenn Sie sich für diesen Bereich interessieren, können Sie weitere Informationen erhalten, indem Sie dieses Repository besuchen.
- Modellzentriert Ein modellzentrierter Ansatz konzentriert sich auf effiziente Techniken auf Algorithmusebene und Systemebene, wobei das Modell selbst im Mittelpunkt steht. Da LLMs über Milliarden oder sogar Billionen von Parametern verfügen und im Vergleich zu kleineren Modellen einzigartige Eigenschaften wie Emergenz aufweisen, müssen neue Techniken entwickelt werden, um die Effizienz von LLMs zu optimieren. In diesem Artikel werden fünf Kategorien modellzentrierter Methoden im Detail erläutert, darunter „Modellkomprimierung“, „effizientes Vortraining“, „effiziente Feinabstimmung“, „effiziente Inferenz“ und „effizientes Modellarchitekturdesign“.
1. Kompressionsmodell Im Bereich des maschinellen Lernens ist die Modellgröße oft ein wichtiger Gesichtspunkt. Größere Modelle benötigen oft mehr Speicherplatz und Rechenressourcen und können bei der Ausführung auf mobilen Geräten auf Einschränkungen stoßen. Daher ist die Komprimierung des Modells eine häufig verwendete Technik zur Reduzierung der Modellgröße. Modellkomprimierungstechniken werden hauptsächlich in vier Kategorien unterteilt: Quantisierung, Parameterbereinigung, Low-Rank-Schätzung und Wissensdestillation (siehe Abbildung unten), darunter Quantisierung Komprimiert die Gewichte oder Aktivierungswerte des Modells von hoher Präzision auf niedrige Präzision. Durch die Parameterbereinigung werden die redundanteren Teile der Modellgewichte gesucht und gelöscht. Durch die Schätzung mit niedrigem Rang wird die Gewichtsmatrix des Modells in mehrere Niedrigpräzisionen umgewandelt. Bei der Destillation von Produktwissen wird ein großes Modell direkt zum Trainieren eines kleinen Modells verwendet, sodass das kleine Modell bei der Ausführung bestimmter Aufgaben das große Modell ersetzen kann.
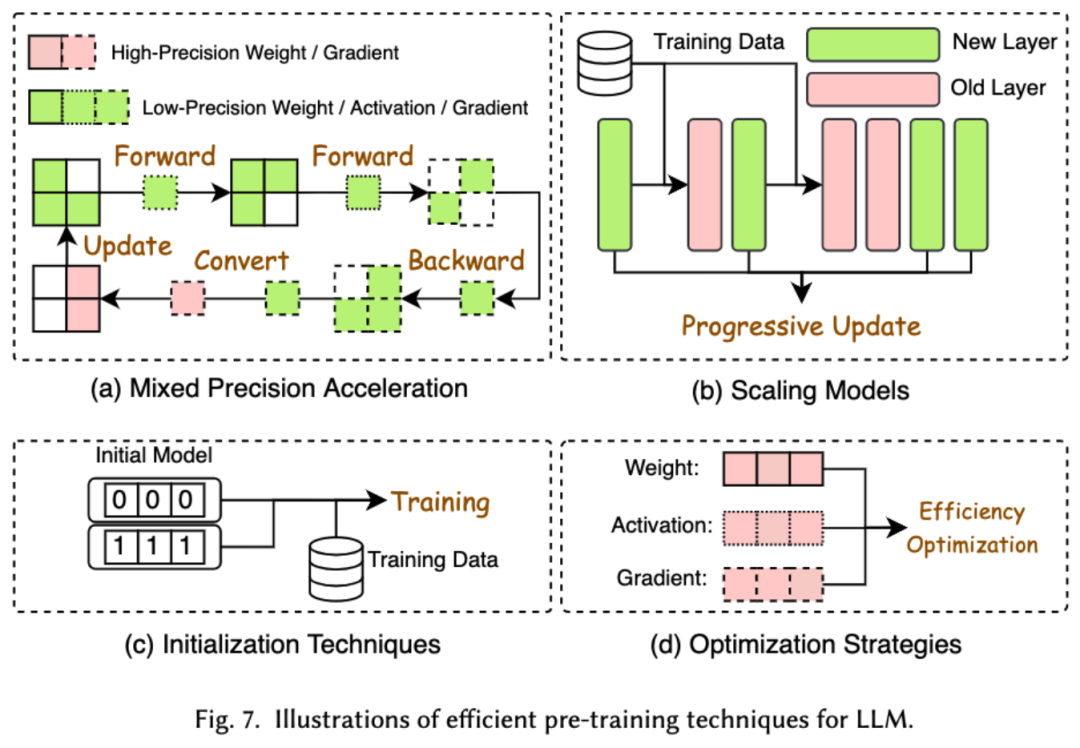
2. Effizientes Vortraining
Die Kosten für das Vortraining von LLMs sind sehr hoch. Eine effiziente Vorschulung zielt darauf ab, die Effizienz zu verbessern und die Kosten des Vorschulungsprozesses für LLMs zu senken. Effizientes Vortraining kann in gemischte Präzisionsbeschleunigung, Modellskalierung, Initialisierungstechnologie, Optimierungsstrategien und Beschleunigung auf Systemebene unterteilt werden.
Die gemischte Präzisionsbeschleunigung verbessert die Effizienz des Vortrainings, indem Steigungen, Gewichte und Aktivierungen mithilfe von Gewichten mit geringer Präzision berechnet, diese dann wieder in hochpräzise umgewandelt und zur Aktualisierung der ursprünglichen Gewichte angewendet werden. Die Modellskalierung beschleunigt die Konvergenz vor dem Training und reduziert die Trainingskosten, indem die Parameter kleiner Modelle für die Skalierung auf große Modelle verwendet werden. Die Initialisierungstechnologie beschleunigt die Konvergenz des Modells, indem sie den Initialisierungswert des Modells gestaltet. Die Optimierungsstrategie konzentriert sich auf die Entwicklung leichter Optimierer, um den Speicherverbrauch während des Modelltrainings zu reduzieren. Die Beschleunigung auf Systemebene nutzt verteilte und andere Technologien, um das Modell-Vortraining auf Systemebene zu beschleunigen.
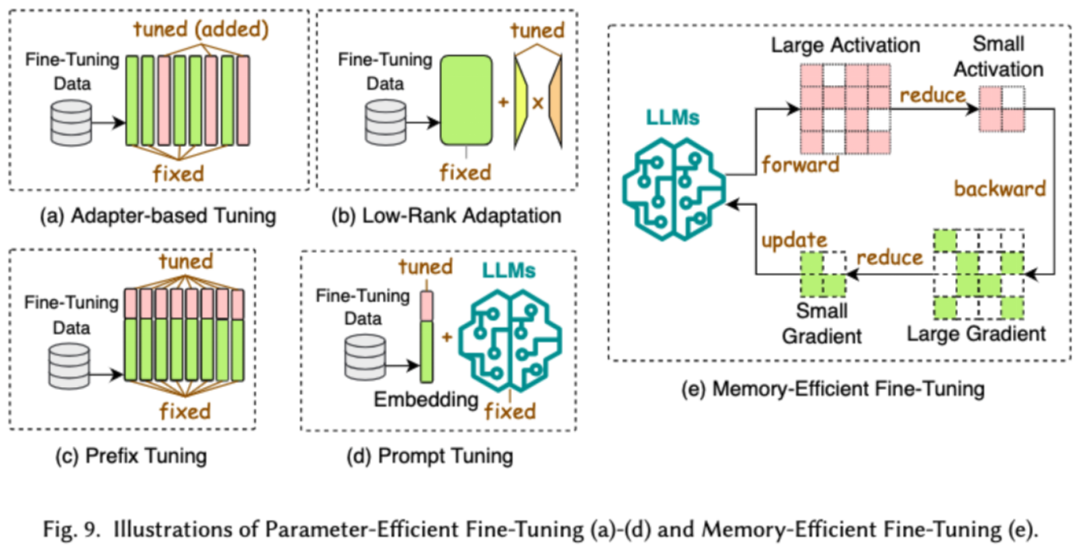
3. Effiziente Feinabstimmung
Effiziente Feinabstimmung soll die Effizienz des LLM-Feinabstimmungsprozesses verbessern. Gängige effiziente Feinabstimmungstechnologien werden in zwei Kategorien unterteilt: Die eine ist die Parameter-basierte effiziente Feinabstimmung und die andere die speichereffiziente Feinabstimmung.
Parameter Efficient Fine-Tuning (PEFT) zielt darauf ab, LLM an nachgelagerte Aufgaben anzupassen, indem das gesamte LLM-Backbone eingefroren und nur ein kleiner Satz zusätzlicher Parameter aktualisiert wird. In dem Artikel haben wir PEFT weiter in eine Adapter-basierte Feinabstimmung, eine Low-Rank-Anpassung, eine Präfix-Feinabstimmung und eine Prompt-Word-Feinabstimmung unterteilt.
Effiziente speicherbasierte Feinabstimmung konzentriert sich auf die Reduzierung des Speicherverbrauchs während des gesamten LLM-Feinabstimmungsprozesses, z. B. auf die Reduzierung des durch Optimiererstatus und Aktivierungswerte verbrauchten Speichers.
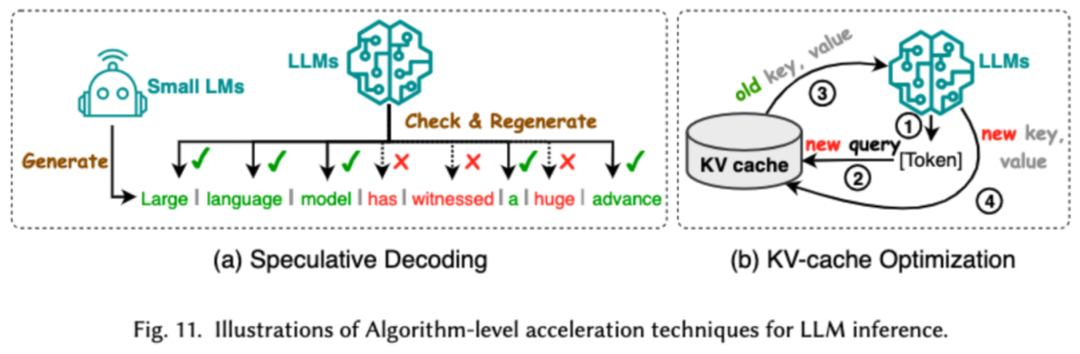
4. Effizientes Denken
Effizientes Denken zielt darauf ab, die Effizienz des Inferenzprozesses von LLMs zu verbessern. Forscher unterteilen gängige hocheffiziente Argumentationstechnologien in zwei Hauptkategorien: die eine ist die Beschleunigung des Denkens auf Algorithmusebene und die andere die Beschleunigung des Denkens auf Systemebene.
Die Inferenzbeschleunigung auf Algorithmusebene kann in zwei Kategorien unterteilt werden: spekulative Dekodierung und KV-Cache-Optimierung. Die spekulative Dekodierung beschleunigt den Sampling-Prozess, indem Token parallel mithilfe eines kleineren Entwurfsmodells berechnet werden, um spekulative Präfixe für das größere Zielmodell zu erstellen. KV – Cache-Optimierung bezieht sich auf die Optimierung der wiederholten Berechnung von Schlüssel-Wert-Paaren (KV) während des Inferenzprozesses von LLMs.
Inferenzbeschleunigung auf Systemebene dient dazu, die Anzahl der Speicherzugriffe auf bestimmter Hardware zu optimieren, den Grad der Algorithmusparallelität zu erhöhen usw., um die LLM-Inferenz zu beschleunigen. 5. Effizientes Modellarchitekturdesign Wir unterteilen den Entwurf effizienter Modellarchitekturen je nach Modelltyp in vier Hauptkategorien: effiziente Aufmerksamkeitsmodule, hybride Expertenmodelle, große Langtextmodelle und Architekturen, die Transformatoren ersetzen können.
 Das effiziente Aufmerksamkeitsmodul zielt darauf ab, die komplexen Berechnungen und die Speichernutzung im Aufmerksamkeitsmodul zu optimieren. Das Hybrid-Expertenmodell (MoE) ersetzt die Argumentationsentscheidungen einiger Module von LLMs durch mehrere kleine Expertenmodelle, um eine allgemeine Sparsamkeit zu erreichen Textgroße Modelle sind LLMs, die speziell für die effiziente Verarbeitung extrem langer Texte entwickelt wurden. Die Architektur, die den Transformator ersetzen kann, besteht darin, die Komplexität des Modells zu reduzieren und durch Neugestaltung der Modellarchitektur vergleichbare Argumentationsfunktionen zu erreichen.
Das effiziente Aufmerksamkeitsmodul zielt darauf ab, die komplexen Berechnungen und die Speichernutzung im Aufmerksamkeitsmodul zu optimieren. Das Hybrid-Expertenmodell (MoE) ersetzt die Argumentationsentscheidungen einiger Module von LLMs durch mehrere kleine Expertenmodelle, um eine allgemeine Sparsamkeit zu erreichen Textgroße Modelle sind LLMs, die speziell für die effiziente Verarbeitung extrem langer Texte entwickelt wurden. Die Architektur, die den Transformator ersetzen kann, besteht darin, die Komplexität des Modells zu reduzieren und durch Neugestaltung der Modellarchitektur vergleichbare Argumentationsfunktionen zu erreichen.
Datenzentriert
Der datenzentrierte Ansatz konzentriert sich auf die Rolle der Datenqualität und -struktur bei der Verbesserung der Effizienz von LLMs. In diesem Artikel diskutieren Forscher zwei Arten datenzentrierter Methoden im Detail, darunter Datenauswahl und Stichwort-Engineering
.
1. Datenauswahl 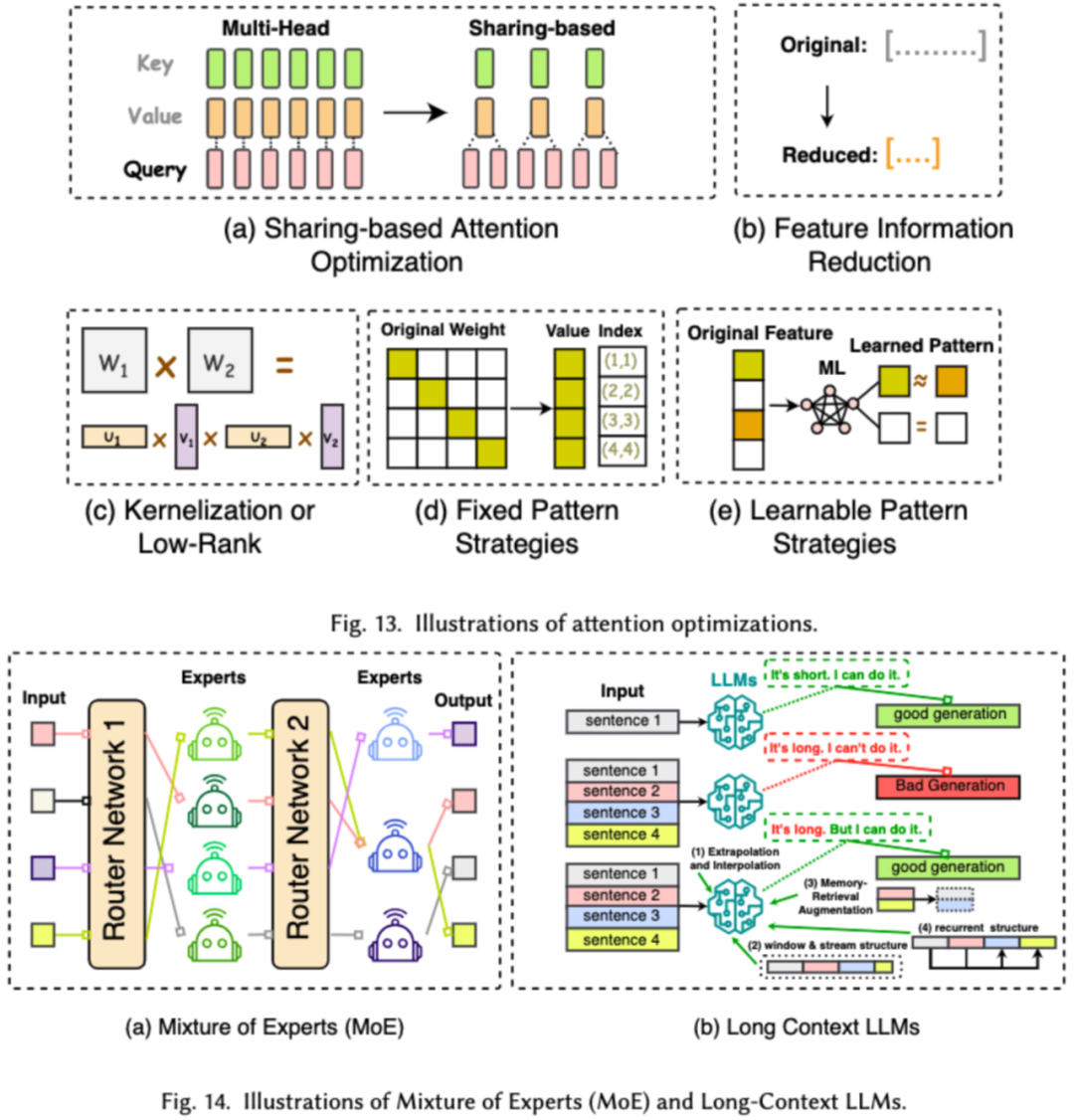
Die Datenauswahl von LLM zielt darauf ab, Daten vor dem Training zu bereinigen und zu optimieren, z. B. indem redundante und ungültige Daten entfernt werden, um den Trainingsprozess zu beschleunigen.
2. Prompt Word Engineering
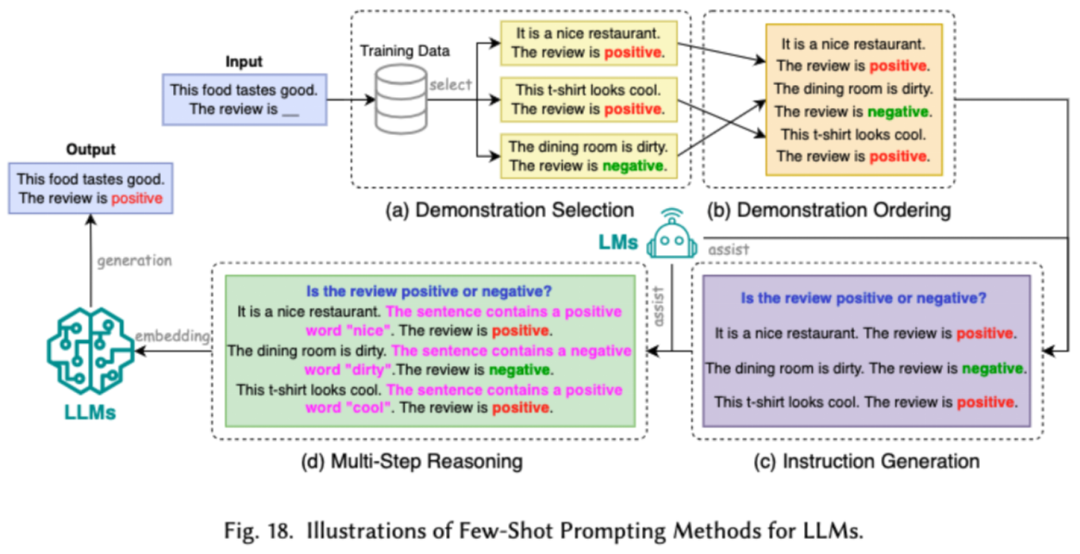
Prompt Word Engineering leitet LLMs an, durch die Gestaltung effektiver Eingaben (Prompt Words) eine beträchtliche Modellleistung zu erzielen . Forscher unterteilen gängige Prompt-Word-Engineering-Technologien in drei Hauptkategorien: Prompt-Word-Engineering mit wenigen Stichproben, Prompt-Word-Komprimierung und Prompt-Word-Generierung.
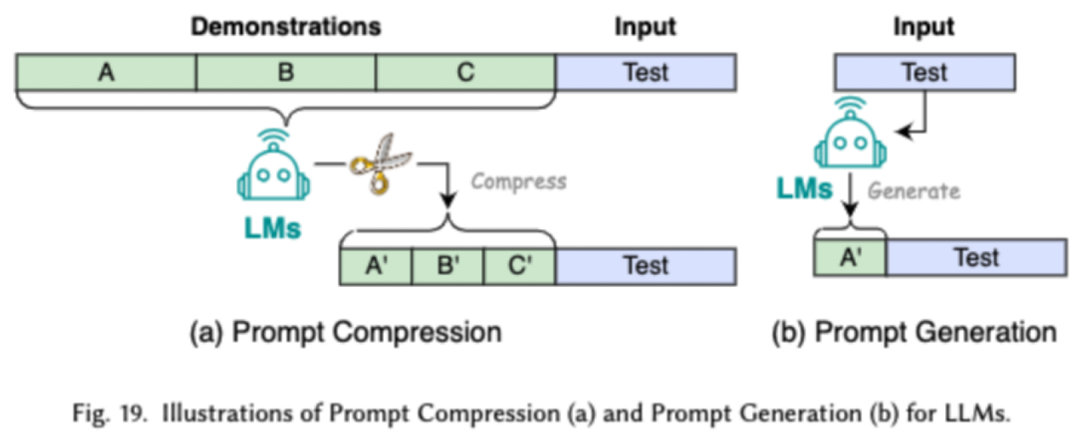
Das Prompt-Word-Engineering mit wenigen Beispielen bietet LLM eine begrenzte Anzahl von Beispielen, die ihm beim Verständnis der auszuführenden Aufgaben helfen. Die Komprimierung von Prompt-Worten beschleunigt die Verarbeitung von Eingaben durch LLMs, indem lange Prompt-Eingaben oder das Lernen komprimiert und Prompt-Darstellungen verwendet werden. Die Generierung von Eingabeaufforderungswörtern zielt darauf ab, automatisch wirksame Eingabeaufforderungen zu erstellen, die das Modell anleiten, spezifische und relevante Antworten zu generieren, anstatt manuell annotierte Daten zu verwenden.
Framework-zentriert
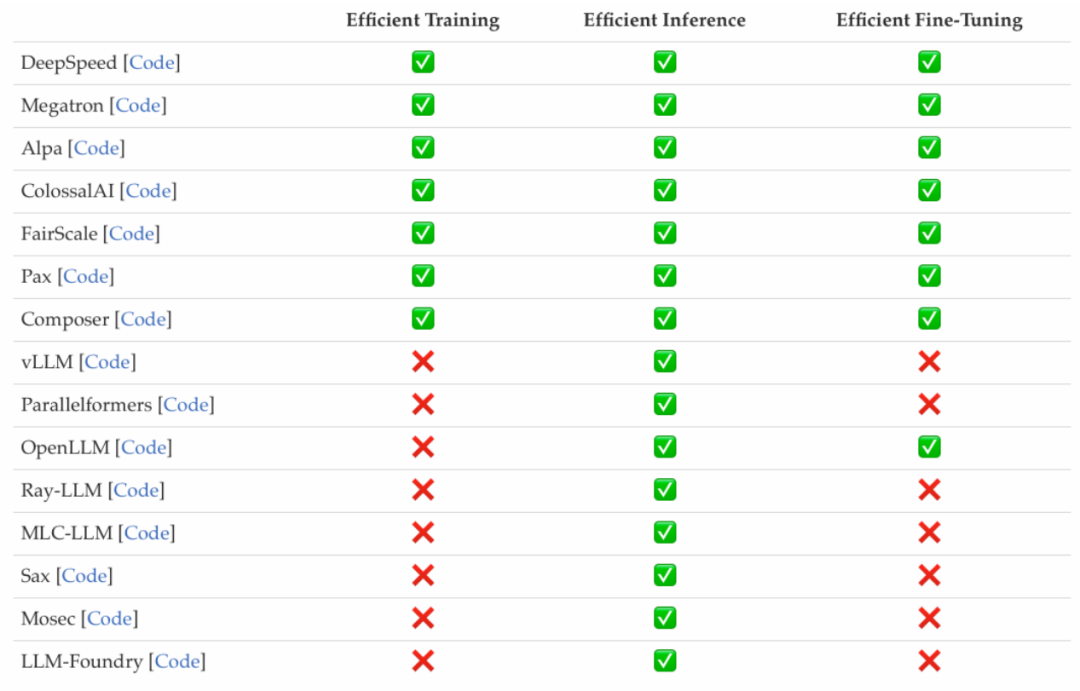
Die Forscher untersuchten die kürzlich beliebten effizienten LLMs-Frameworks und listeten die effizienten Aufgaben auf, die sie optimieren können, einschließlich Vortraining, Feinabstimmung und Inferenz (wie folgt). in der Abbildung dargestellt).
Zusammenfassung
In dieser Umfrage bieten Ihnen die Forscher einen systematischen Überblick über effiziente LLMs, einen wichtigen Forschungsbereich, der sich der Demokratisierung von LLMs widmet. Sie erklären zunächst, warum effiziente LLMs erforderlich sind. In einem geordneten Rahmen untersucht dieser Artikel effiziente Technologien auf der algorithmischen Ebene und der Systemebene von LLMs aus modellzentrierter, datenzentrierter bzw. rahmenzentrierter Perspektive.
Forscher gehen davon aus, dass Effizienz in LLMs und LLM-orientierten Systemen eine immer wichtigere Rolle spielen wird. Sie hoffen, dass diese Umfrage Forschern und Praktikern einen schnellen Einstieg in dieses Gebiet ermöglicht und als Katalysator für die Anregung neuer Forschung zu effizienten LLMs dient.
Das obige ist der detaillierte Inhalt vonEin tiefer Einblick in Modelle, Daten und Frameworks: eine ausführliche 54-seitige Übersicht über effiziente große Sprachmodelle. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
 So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
Um die Zeitüberschreitung für Vue Axios festzulegen, können wir eine Axios -Instanz erstellen und die Zeitleitungsoption angeben: in globalen Einstellungen: vue.Prototyp. $ Axios = axios.create ({Timeout: 5000}); In einer einzigen Anfrage: this. $ axios.get ('/api/user', {timeout: 10000}).
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Standort: Remote-Büro-Jobtyp: Vollzeitgehalt: 130.000 bis 140.000 US-Dollar Stellenbeschreibung Nehmen Sie an der Forschung und Entwicklung von Mobilfunkanwendungen und öffentlichen API-bezogenen Funktionen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken. Die Hauptaufgaben erledigen die Entwicklungsarbeit unabhängig von RubyonRails und arbeiten mit dem Front-End-Team von React/Redux/Relay zusammen. Erstellen Sie die Kernfunktionalität und -verbesserungen für Webanwendungen und arbeiten Sie eng mit Designer und Führung während des gesamten funktionalen Designprozesses zusammen. Fördern Sie positive Entwicklungsprozesse und priorisieren Sie die Iterationsgeschwindigkeit. Erfordert mehr als 6 Jahre komplexes Backend für Webanwendungen
 Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
MySQL kann JSON -Daten zurückgeben. Die JSON_EXTRACT -Funktion extrahiert Feldwerte. Über komplexe Abfragen sollten Sie die Where -Klausel verwenden, um JSON -Daten zu filtern, aber auf die Leistungsauswirkungen achten. Die Unterstützung von MySQL für JSON nimmt ständig zu, und es wird empfohlen, auf die neuesten Versionen und Funktionen zu achten.
 So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
Die MySQL -Leistungsoptimierung muss von drei Aspekten beginnen: Installationskonfiguration, Indexierung und Abfrageoptimierung, Überwachung und Abstimmung. 1. Nach der Installation müssen Sie die my.cnf -Datei entsprechend der Serverkonfiguration anpassen, z. 2. Erstellen Sie einen geeigneten Index, um übermäßige Indizes zu vermeiden und Abfrageanweisungen zu optimieren, z. B. den Befehl Erklärung zur Analyse des Ausführungsplans; 3. Verwenden Sie das eigene Überwachungstool von MySQL (ShowProcessList, Showstatus), um die Datenbankgesundheit zu überwachen und die Datenbank regelmäßig zu sichern und zu organisieren. Nur durch kontinuierliche Optimierung dieser Schritte kann die Leistung der MySQL -Datenbank verbessert werden.
 Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Detaillierte Erläuterung von Datenbanksäureattributen Säureattribute sind eine Reihe von Regeln, um die Zuverlässigkeit und Konsistenz von Datenbanktransaktionen sicherzustellen. Sie definieren, wie Datenbanksysteme Transaktionen umgehen, und sorgen dafür, dass die Datenintegrität und -genauigkeit auch im Falle von Systemabstürzen, Leistungsunterbrechungen oder mehreren Benutzern gleichzeitiger Zugriff. Säureattributübersicht Atomizität: Eine Transaktion wird als unteilbare Einheit angesehen. Jeder Teil schlägt fehl, die gesamte Transaktion wird zurückgerollt und die Datenbank behält keine Änderungen bei. Wenn beispielsweise eine Banküberweisung von einem Konto abgezogen wird, jedoch nicht auf ein anderes erhöht wird, wird der gesamte Betrieb widerrufen. begintransaktion; updateAccountsSetBalance = Balance-100WH
