

Die Erfassung hochwertiger Daten ist zu einem großen Engpass im aktuellen Training großer Modelle geworden.
Vor einigen Tagen wurde OpenAI von der New York Times verklagt und forderte eine Entschädigung in Milliardenhöhe. In der Beschwerde werden mehrere Beweise für ein Plagiat von GPT-4 aufgeführt.
Sogar die New York Times forderte die Zerstörung fast aller großen Modelle wie GPT.

Viele große Namen in der KI-Branche glauben seit langem, dass „synthetische Daten“ die beste Lösung für dieses Problem sein könnten.

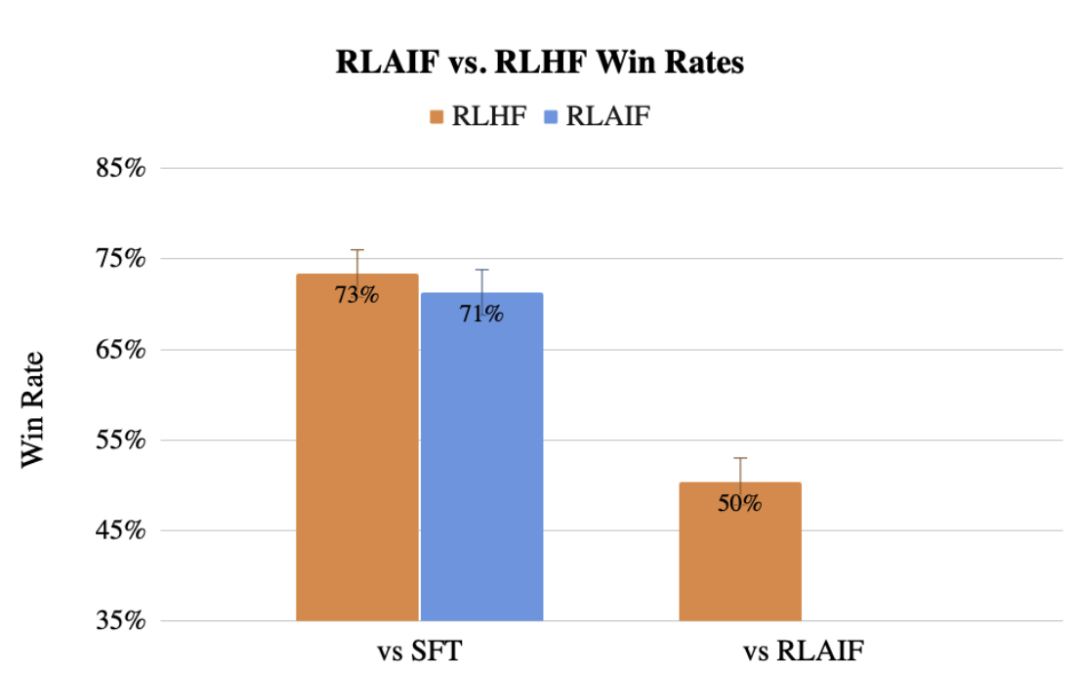
Zuvor schlug das Google-Team auch eine Methode zur Verwendung von LLM vor, um die menschlichen Kennzeichnungspräferenzen RLAIF zu ersetzen, und der Effekt ist dem des Menschen nicht einmal unterlegen.
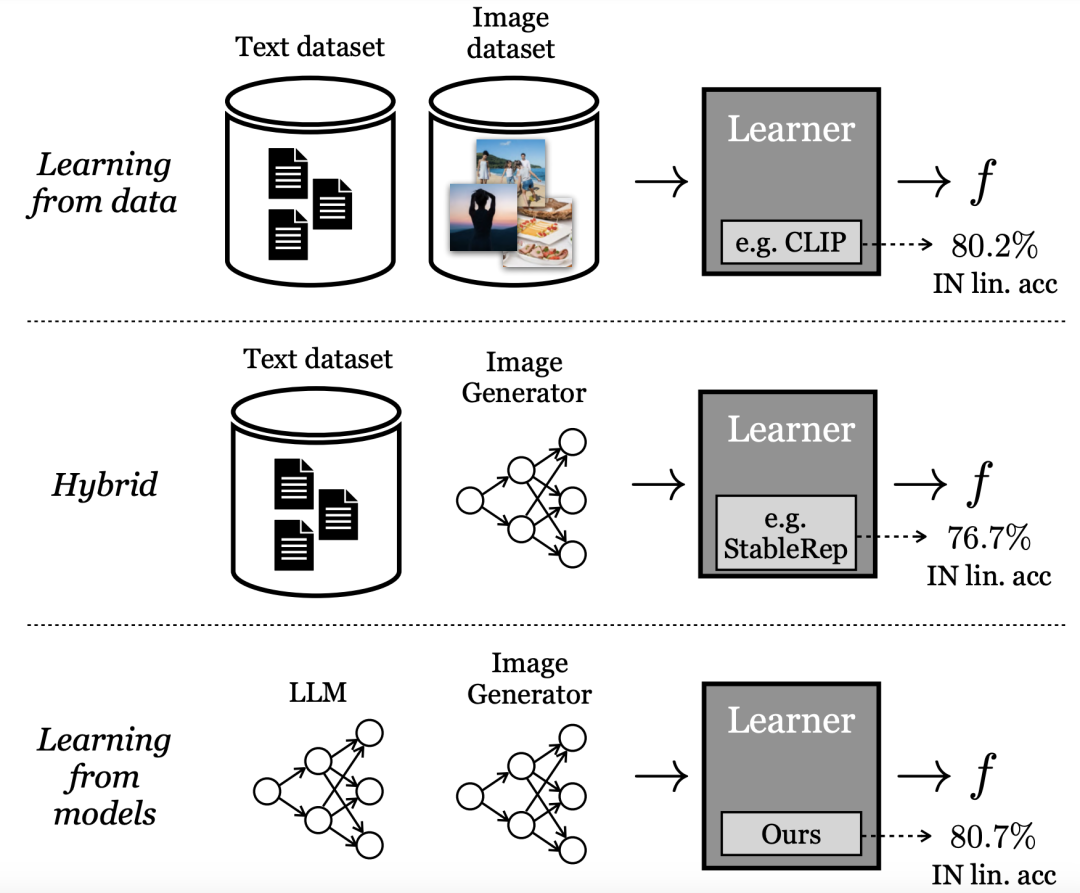
Jetzt haben Forscher von Google und MIT herausgefunden, dass das Lernen aus großen Modellen zu Darstellungen der besten Modelle führen kann, die mit echten Daten trainiert wurden.
Diese neueste Methode heißt SynCLR, eine Methode zum Lernen virtueller Darstellungen vollständig aus synthetischen Bildern und synthetischen Beschreibungen, ohne reale Daten.

Papieradresse: https://arxiv.org/abs/2312.17742
Die experimentellen Ergebnisse zeigen, dass die durch die SynCLR-Methode erlernte Darstellung genauso gut sein kann wie der Übertragungseffekt von OpenAIs CLIP auf ImageNet .
Die leistungsstärksten Lernmethoden zur „visuellen Darstellung“ basieren derzeit auf großen Datensätzen aus der realen Welt. Allerdings gibt es viele Schwierigkeiten bei der Erhebung realer Daten.
Um die Kosten für die Datenerfassung zu senken, stellen die Forscher in diesem Artikel die Frage:
Sind synthetische Daten, die aus handelsüblichen generativen Modellen entnommen werden, ein gangbarer Weg zu groß angelegten kuratierten Datensätzen? Schulung modernster visueller Darstellungen?
Anders als das direkte Lernen aus Daten nennen Google-Forscher diesen Modus „Lernen aus dem Modell“. Als Datenquelle für den Aufbau umfangreicher Trainingssätze bieten Modelle mehrere Vorteile:
– Durch ihre latenten Variablen, bedingten Variablen und Hyperparameter bieten sie neue Kontrollmethoden für das Datenmanagement.
– Modelle lassen sich auch einfacher teilen und speichern (da Modelle einfacher zu komprimieren sind als Daten) und können eine unbegrenzte Anzahl von Datenbeispielen erzeugen.
Eine wachsende Zahl an Fachliteratur untersucht diese Eigenschaften und andere Vor- und Nachteile generativer Modelle als Datenquelle für das Training nachgelagerter Modelle.
Einige dieser Methoden verwenden ein Hybridmodell, d. h. sie mischen reale und synthetische Datensätze oder erfordern einen realen Datensatz, um einen anderen synthetischen Datensatz zu generieren.
Andere Methoden versuchen, Darstellungen aus rein „synthetischen Daten“ zu lernen, bleiben aber weit hinter den leistungsstärksten Modellen zurück.
In der Arbeit verwendet die neueste von den Forschern vorgeschlagene Methode ein generatives Modell, um die Granularität von Visualisierungsklassen neu zu definieren.
Wie in Abbildung 2 gezeigt, wurden vier Bilder mit zwei Tipps erstellt: „Ein Golden Retriever mit Sonnenbrille und Strandhut, der Fahrrad fährt“ und „Ein süßer Golden Retriever sitzt auf einem Haus aus Sushi“ im Inneren.
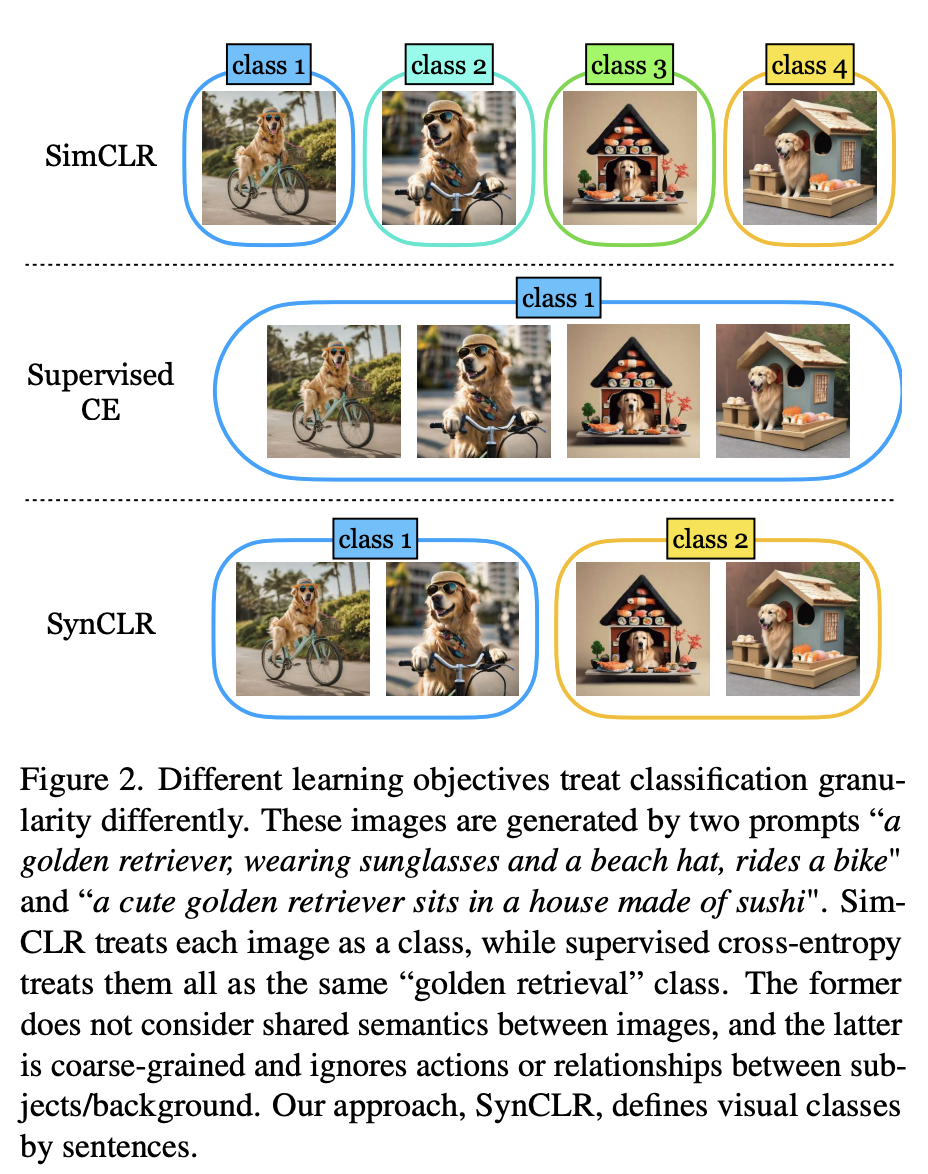
Herkömmliche selbstüberwachte Methoden (wie Sim-CLR) behandeln diese Bilder als unterschiedliche Klassen und die Einbettungen verschiedener Bilder werden getrennt, ohne die gemeinsame Semantik zwischen Bildern explizit zu berücksichtigen.
Im anderen Extremfall behandeln überwachte Lernmethoden (z. B. SupCE) alle diese Bilder als eine einzige Klasse (z. B. „Golden Retriever“). Dabei werden semantische Nuancen in den Bildern ignoriert, etwa ein Hund, der in einem Bildpaar Fahrrad fährt, und ein Hund, der in einem Sushi-Haus in einem anderen sitzt.
Im Gegensatz dazu behandelt der SynCLR-Ansatz Beschreibungen als Klassen, d. h. eine Visualisierungsklasse pro Beschreibung.
Auf diese Weise können wir die Bilder nach den beiden Konzepten „Fahrrad fahren“ und „in einem Sushi-Restaurant sitzen“ gruppieren.
Diese Art von Granularität ist in realen Daten schwer zu ermitteln, da das Sammeln mehrerer Bilder anhand einer bestimmten Beschreibung nicht trivial ist, insbesondere wenn die Anzahl der Beschreibungen zunimmt.
Das Text-zu-Bild-Diffusionsmodell verfügt jedoch grundsätzlich über diese Fähigkeit.
Durch die einfache Konditionierung derselben Beschreibung und die Verwendung unterschiedlicher Rauscheingaben kann das Text-zu-Bild-Diffusionsmodell verschiedene Bilder erzeugen, die derselben Beschreibung entsprechen.
Konkret untersuchen die Autoren das Problem des Erlernens visueller Encoder ohne echte Bild- oder Textdaten.
Der neueste Ansatz basiert auf der Nutzung von drei Schlüsselressourcen: einem generativen Sprachmodell (g1), einem generativen Text-zu-Bild-Modell (g2) und einer kuratierten Liste visueller Konzepte (c).
Die Vorverarbeitung umfasst drei Schritte:
(1) Verwenden Sie (g1), um einen umfassenden Satz von Bildbeschreibungen T zu synthetisieren, der verschiedene visuelle Konzepte in C abdeckt;
(2) Für Für jeden Titel in T, mehrere Bilder werden mit (g2) generiert, wodurch letztendlich ein umfangreicher synthetischer Bilddatensatz generiert wird.
(3) wird auf X trainiert, um einen visuellen Darstellungsencoder f zu erhalten.
Dann verwenden Sie aufgrund der schnellen Inferenzgeschwindigkeit Lama-27b und Stable Diffusion 1.5 jeweils als (g1) und (g2).
Synthetische Beschreibungen
Um die Leistungsfähigkeit leistungsstarker Text-zu-Bild-Modelle zur Generierung großer Trainingsbilddatensätze zu nutzen, benötigen wir zunächst eine Reihe von Beschreibungen, die Bilder nicht nur genau beschreiben, sondern auch Vielfalt aufweisen um ein breites Spektrum an visuellen Konzepten einzubeziehen.
Als Reaktion darauf entwickelten die Autoren eine skalierbare Methode zur Erstellung eines so großen Satzes von Beschreibungen und nutzten dabei die kontextbezogenen Lernfähigkeiten großer Modelle.
Im Folgenden werden drei Beispiele für synthetische Vorlagen gezeigt.

Im Folgenden wird Llama-2 verwendet, um Kontextbeschreibungen zu generieren. Die Forscher haben in jedem Inferenzlauf zufällig drei Kontextbeispiele ausgewählt.
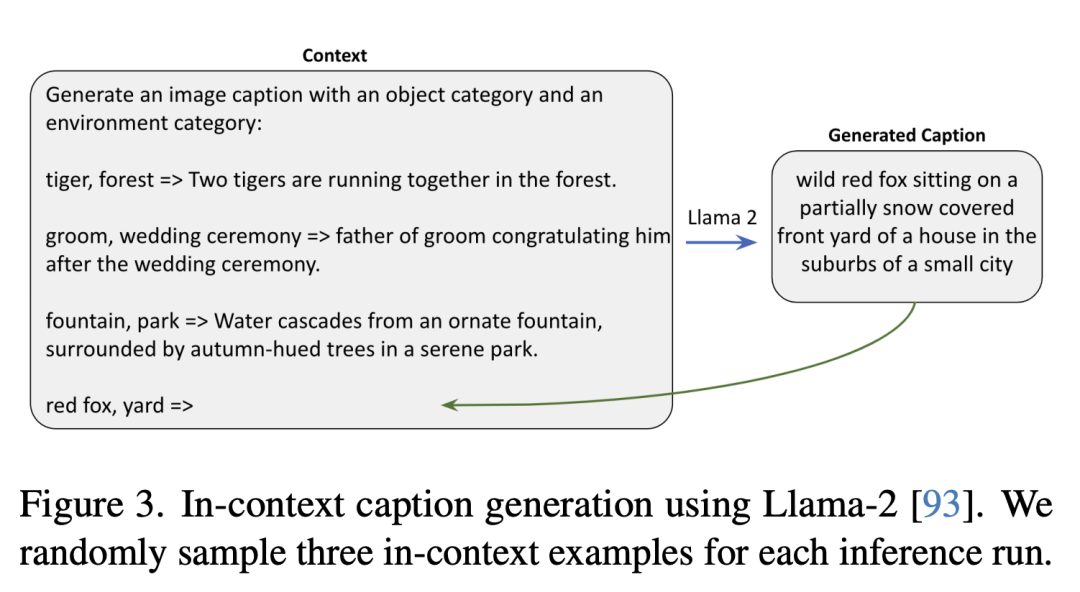
Synthetische Bilder
Für jede Textbeschreibung starteten die Forscher den Rückdiffusionsprozess mit unterschiedlichem Zufallsrauschen, was zu verschiedenen Bildern führte.
In diesem Prozess ist das Classifier-Free Bootstrapping (CFG)-Verhältnis ein Schlüsselfaktor.
Je höher die CFG-Skala, desto besser ist die Qualität der Beispiele und die Konsistenz zwischen Text und Bildern, während je niedriger die Skala, desto größer die Vielfalt der Beispiele und desto besser die Konsistenz zwischen Bildern basierend auf der gegebenen Originaltextbedingung Verteilung.

Repräsentationslernen
In der Arbeit basiert die Repräsentationslernmethode auf StableRep.
Die Schlüsselkomponente der von den Autoren vorgeschlagenen Methode ist der multipositive Kontrast-Lernverlust, der durch die Ausrichtung (im Einbettungsraum) von Bildern funktioniert, die aus derselben Beschreibung generiert wurden.
Darüber hinaus wurden in der Studie auch verschiedene Techniken aus anderen selbstüberwachten Lernmethoden kombiniert.
In der experimentellen Auswertung führten die Forscher zunächst Ablationsstudien durch, um die Wirksamkeit verschiedener Designs und Module innerhalb der Pipeline zu bewerten, und erweiterten dann die Menge an synthetischen Daten weiter.
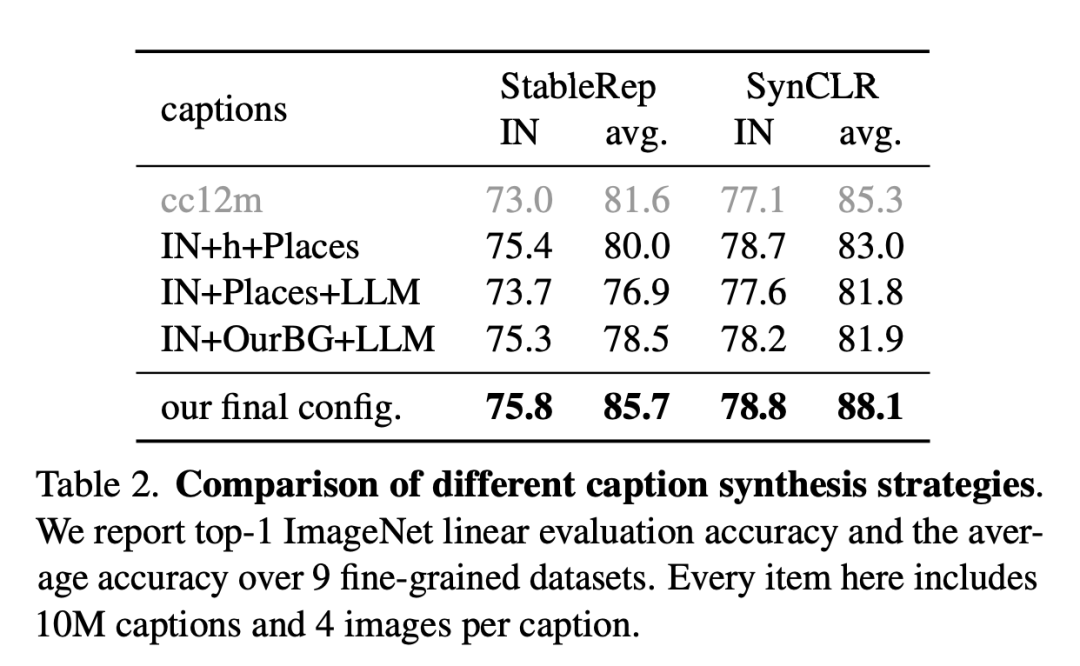
Das Bild unten ist ein Vergleich verschiedener Beschreibungssynthesestrategien.
Forscher berichten über die lineare Bewertungsgenauigkeit und die durchschnittliche Genauigkeit von ImageNet anhand von 9 feinkörnigen Datensätzen. Jeder Artikel hier enthält 10 Millionen Beschreibungen und 4 Bilder pro Beschreibung.
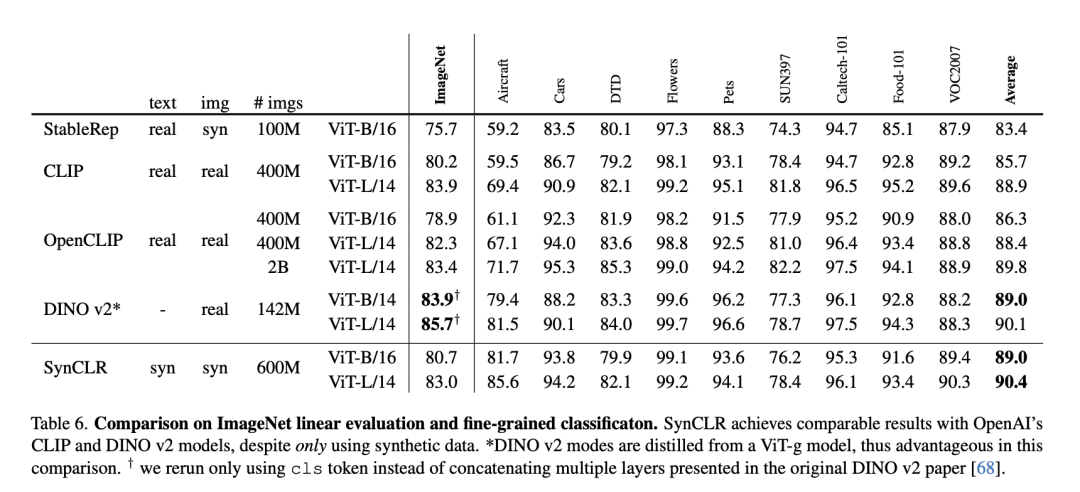
Die folgende Tabelle ist ein Vergleich der linearen ImageNet-Bewertung und der feinkörnigen Klassifizierung.
Obwohl nur synthetische Daten verwendet wurden, erzielte SynCLR vergleichbare Ergebnisse mit den CLIP- und DINO v2-Modellen von OpenAI.
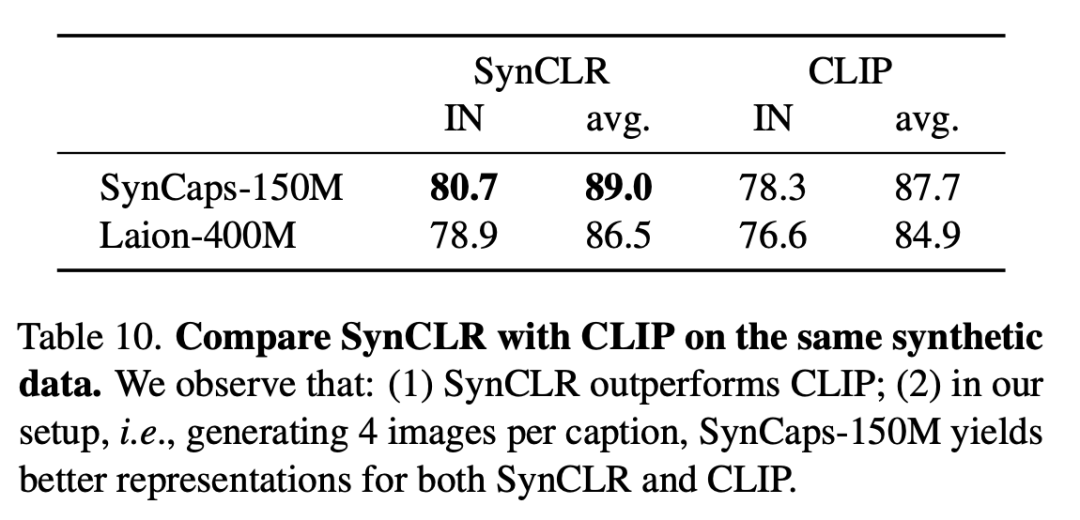
Die folgende Tabelle vergleicht SynCLR und CLIP anhand derselben synthetischen Daten. Es ist ersichtlich, dass SynCLR deutlich besser als CLIP ist.
SynCaps-150M ist speziell auf die Generierung von 4 Bildern pro Titel eingestellt und bietet eine bessere Darstellung für SynCLR und CLIP.
PCA-Visualisierung ist wie folgt. Nach DINO v2 berechneten die Forscher die PCA zwischen Patches desselben Bildsatzes und färbten sie basierend auf ihren ersten drei Komponenten ein.
Im Vergleich zu DINO v2 ist SynCLR bei Zeichnungen von Autos und Flugzeugen genauer, bei Zeichnungen, die gezeichnet werden können, jedoch etwas schlechter.

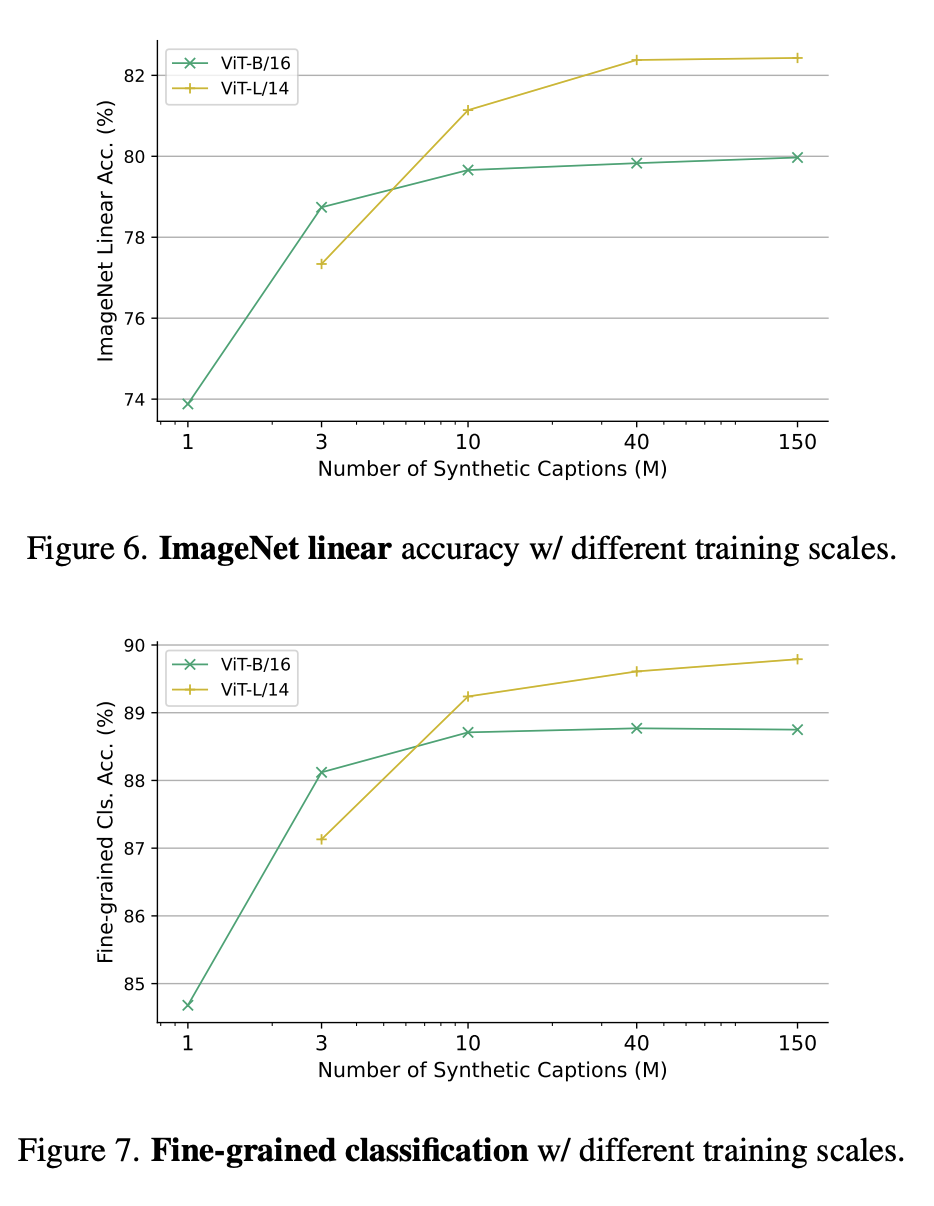
Abbildung 6 und Abbildung 7 zeigen jeweils die lineare Genauigkeit von ImageNet unter verschiedenen Trainingsskalen und die Feinklassifizierung unter verschiedenen Trainingsparameterskalen.
Warum aus generativen Modellen lernen?
Ein überzeugender Grund dafür ist, dass generative Modelle Hunderte von Datensätzen gleichzeitig bearbeiten können, was eine bequeme und effiziente Möglichkeit zur Kuratierung von Trainingsdaten darstellt.
Zusammenfassend untersucht die neueste Arbeit ein neues Paradigma des visuellen Repräsentationslernens – das Lernen aus generativen Modellen.
Die von SynCLR erlernten visuellen Darstellungen sind vergleichbar mit denen, die von hochmodernen, allgemeinen visuellen Darstellungslernern gelernt werden, ohne dass tatsächliche Daten verwendet werden.
Das obige ist der detaillierte Inhalt vonDie neuesten Untersuchungen von Google MIT zeigen: Hochwertige Daten zu erhalten ist nicht schwierig, große Modelle sind die Lösung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



