
 Technologie-Peripheriegeräte
KI
Modell-Inferenzbeschleunigung: Die CPU-Leistung wird um das Fünffache erhöht. Apple nutzt Flash-Speicher für eine umfassende Inferenzbeschleunigung. Kommt Siri 2.0 auf den Markt?
Technologie-Peripheriegeräte
KI
Modell-Inferenzbeschleunigung: Die CPU-Leistung wird um das Fünffache erhöht. Apple nutzt Flash-Speicher für eine umfassende Inferenzbeschleunigung. Kommt Siri 2.0 auf den Markt?
Modell-Inferenzbeschleunigung: Die CPU-Leistung wird um das Fünffache erhöht. Apple nutzt Flash-Speicher für eine umfassende Inferenzbeschleunigung. Kommt Siri 2.0 auf den Markt?

Diese neue Arbeit von Apple wird grenzenlose Fantasie in die Möglichkeit bringen, große Modelle zu zukünftigen iPhones hinzuzufügen.
In den letzten Jahren haben große Sprachmodelle (LLM) wie GPT-3, OPT und PaLM eine starke Leistung bei einem breiten Spektrum von Aufgaben der Verarbeitung natürlicher Sprache (NLP) gezeigt. Das Erreichen dieser Leistungen erfordert jedoch umfangreiche Berechnungen und Speicherinferenzen, da diese großen Sprachmodelle Hunderte von Milliarden oder sogar Billionen von Parametern enthalten können, was das Laden und effiziente Ausführen auf Geräten mit begrenzten Ressourcen erschwert.
Derzeit ist das Laden die Standardlösung Das gesamte Modell wird zur Inferenz in den DRAM geschrieben. Dies schränkt jedoch die maximale Modellgröße, die ausgeführt werden kann, erheblich ein. Beispielsweise erfordert ein Modell mit 7 Milliarden Parametern mehr als 14 GB Speicher, um Parameter im Gleitkommaformat mit halber Genauigkeit zu laden, was die Fähigkeiten der meisten Edge-Geräte übersteigt.
Um diese Einschränkung zu lösen, schlugen Apple-Forscher vor, Modellparameter im Flash-Speicher zu speichern, der mindestens eine Größenordnung größer als DRAM ist. Während der Inferenz haben sie dann die erforderlichen Parameter direkt und geschickt per Flash geladen, sodass nicht mehr das gesamte Modell in den DRAM eingepasst werden musste.
Dieser Ansatz baut auf neueren Arbeiten auf, die zeigen, dass LLM einen hohen Grad an Sparsity in der Feedforward-Network-Schicht (FFN) aufweist, wobei Modelle wie OPT und Falcon eine Sparsity von über 90 % erreichen. Daher nutzen wir diese Sparsity aus, um selektiv nur Parameter aus dem Flash-Speicher zu laden, die Eingaben ungleich Null haben oder voraussichtlich Ausgaben ungleich Null haben.

Papieradresse: https://arxiv.org/pdf/2312.11514.pdf
Konkret diskutierten die Forscher ein Hardware-inspiriertes Kostenmodell, das Flash-Speicher, DRAM und Rechenkerne (CPU oder GPU) umfasst. Anschließend werden zwei komplementäre Techniken eingeführt, um die Datenübertragung zu minimieren und den Flash-Durchsatz zu maximieren:
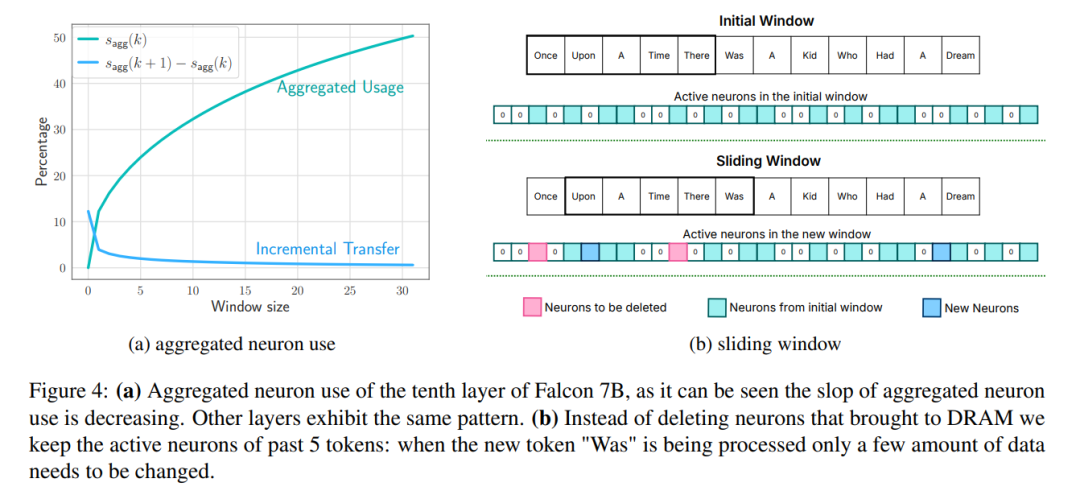
Windowing: Lädt nur die Parameter der ersten paar Tags und verwendet die Aktivierung des zuletzt berechneten Tags wieder. Dieser Schiebefenster-Ansatz reduziert die Anzahl der E/A-Anfragen zum Laden von Gewichtungen.
Zeilen- und Zeilenbündelung: Speichert verkettete Zeilen und Spalten von Auf- und Abwärtsprojektionsebenen, um größere zusammenhängende Blöcke des Flash-Speichers zu lesen. Dadurch wird der Durchsatz durch das Lesen größerer Blöcke erhöht.
Um die Anzahl der vom Flash zum DRAM übertragenen Gewichte weiter zu reduzieren, versuchten die Forscher, die Sparsität von FFN vorherzusagen und das Laden von Nullungsparametern zu vermeiden. Durch die Verwendung einer Kombination aus Fensterung und Sparsity-Vorhersage werden pro Inferenzabfrage nur 2 % der Flash-FFN-Schicht geladen. Sie schlugen außerdem eine statische Speichervorabzuweisung vor, um Intra-DRAM-Transfers zu minimieren und die Inferenzlatenz zu reduzieren
Das Flash-Ladekostenmodell dieses Artikels schafft ein Gleichgewicht zwischen dem Laden besserer Daten und dem Lesen größerer Blöcke. Eine Flash-Strategie, die dieses Kostenmodell optimiert und Parameter selektiv nach Bedarf lädt, kann Modelle mit der doppelten DRAM-Kapazität ausführen und die Inferenzgeschwindigkeit im Vergleich zu naiven Implementierungen in CPUs und GPUs um das 4- bis 5-fache bzw. 20- bis 25-fache verbessern.
Einige Leute haben kommentiert, dass diese Arbeit die iOS-Entwicklung interessanter machen wird.
Flash- und LLM-Inferenz
Bandbreiten- und Energiebeschränkungen
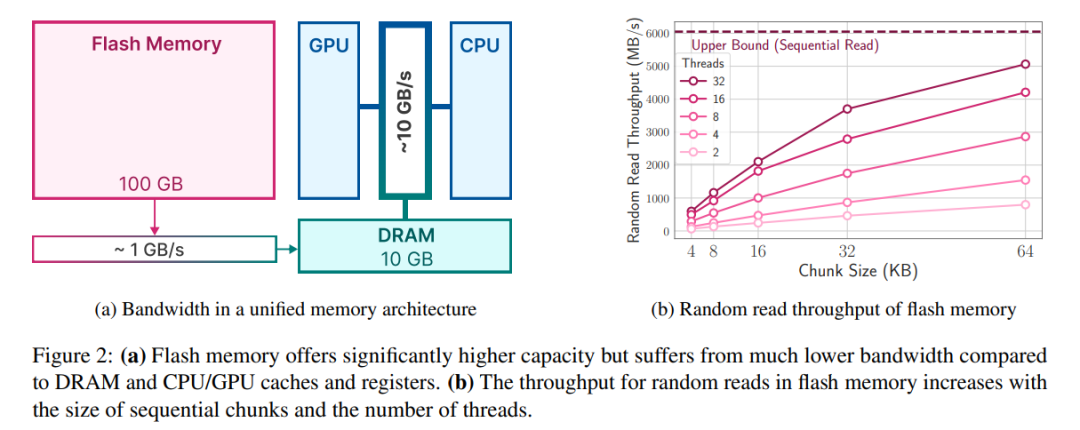
Während moderner NAND-Flash eine hohe Bandbreite und geringe Latenz bietet, bleibt er immer noch hinter den DRAM-Leistungsniveaus zurück, insbesondere in Systemen mit eingeschränktem Speicher. Abbildung 2a unten veranschaulicht diese Unterschiede.
Naive Inferenzimplementierungen, die auf NAND-Flash basieren, erfordern möglicherweise das Neuladen des gesamten Modells bei jedem Vorwärtsdurchlauf. Dies ist ein zeitaufwändiger Prozess, bei dem selbst die Komprimierung des Modells mehrere Sekunden dauert. Darüber hinaus erfordert die Übertragung von Daten vom DRAM zum CPU- oder GPU-Speicher mehr Energie.
In Szenarien, in denen DRAM ausreichend ist, werden die Kosten für das Laden von Daten reduziert und das Modell kann sich im DRAM befinden. Das anfängliche Laden des Modells verbraucht jedoch immer noch Energie, insbesondere wenn der erste Token eine schnelle Reaktionszeit erfordert. Unsere Methode nutzt die Aktivierungsparsität im LLM, um diese Herausforderungen durch selektives Lesen von Modellgewichten zu bewältigen und so Zeit- und Energiekosten zu reduzieren.
Umgedrückt als: Datenübertragungsrate abrufen
Flash-Systeme erzielen die beste Leistung bei vielen sequentiellen Lesevorgängen. Das Apple MacBook Pro M2 ist beispielsweise mit 2 TB Flash-Speicher ausgestattet und in Benchmark-Tests überstieg die lineare Lesegeschwindigkeit von 1 GB nicht zwischengespeicherter Dateien 6 GB/s. Allerdings können kleinere zufällige Lesevorgänge aufgrund der mehrstufigen Natur dieser Lesevorgänge, einschließlich des Betriebssystems, der Treiber, der Mittelklasse-Prozessoren und der Flash-Controller, keine derart hohen Bandbreiten erreichen. Jede Stufe führt zu einer Latenz, die einen größeren Einfluss auf kleinere Lesegeschwindigkeiten hat.
Um diese Einschränkungen zu umgehen, empfehlen Forscher zwei Hauptstrategien, die gleichzeitig verwendet werden können.
Die erste Strategie besteht darin, größere Datenblöcke zu lesen. Während der Anstieg des Durchsatzes nicht linear ist (größere Datenblöcke erfordern längere Übertragungszeiten), macht die Verzögerung der Anfangsbytes einen geringeren Anteil der gesamten Anforderungszeit aus, wodurch das Lesen von Daten effizienter wird. Abbildung 2b zeigt dieses Prinzip. Eine kontraintuitive, aber interessante Beobachtung ist, dass es in manchen Fällen schneller ist, mehr Daten als nötig zu lesen (aber in größeren Blöcken) und sie dann zu verwerfen, als nur das zu lesen, was benötigt wird, aber in kleineren Blöcken.
Die zweite Strategie besteht darin, die inhärente Parallelität des Speicherstapels und des Flash-Controllers zu nutzen, um parallele Lesevorgänge zu erreichen. Die Ergebnisse zeigen, dass es möglich ist, mit Multithread-Zufallslesevorgängen von 32 KB oder mehr auf Standardhardware einen für spärliche LLM-Inferenz geeigneten Durchsatz zu erreichen.
Der Schlüssel zur Maximierung des Durchsatzes liegt in der Art und Weise, wie die Gewichte gespeichert werden, da ein Layout, das die durchschnittliche Blocklänge erhöht, die Bandbreite erheblich erhöhen kann. In manchen Fällen kann es von Vorteil sein, überschüssige Daten zu lesen und anschließend zu verwerfen, anstatt die Daten in kleinere, weniger effiziente Blöcke aufzuteilen.
Flash-Laden
Inspiriert von den oben genannten Herausforderungen schlugen die Forscher eine Methode zur Optimierung des Datenübertragungsvolumens und zur Verbesserung der Datenübertragungsrate vor, die wie folgt ausgedrückt werden kann: Erhalten Sie eine Datenübertragungsrate, um die Inferenzgeschwindigkeit erheblich zu verbessern. In diesem Abschnitt werden die Herausforderungen bei der Durchführung von Inferenzen auf Geräten erläutert, bei denen der verfügbare Rechenspeicher viel kleiner ist als die Modellgröße.
Um diese Herausforderung zu analysieren, müssen die vollständigen Modellgewichte im Flash-Speicher gespeichert werden. Die von Forschern zur Bewertung verschiedener Flash-Ladestrategien verwendete Hauptmetrik ist die Latenz, die in drei verschiedene Komponenten unterteilt ist: die E/A-Kosten für die Durchführung des Flash-Ladevorgangs, den Speicheraufwand für die Verwaltung der neu geladenen Daten und die Rechenkosten dafür Inferenzoperation.
Apple unterteilt Lösungen zur Reduzierung der Latenz bei Speicherbeschränkungen in drei strategische Bereiche, die jeweils auf einen bestimmten Aspekt der Latenz abzielen:
1. Reduzierung der Datenlast: Zielt darauf ab, die Latenz durch das Laden von weniger Daten zu reduzieren. Latenz im Zusammenhang mit Flash-I/O-Vorgängen.
2. Datenblockgröße optimieren: Verbessern Sie den Flash-Durchsatz, indem Sie die Größe der geladenen Datenblöcke erhöhen und dadurch die Latenz reduzieren.
Die folgende Strategie wird von Forschern verwendet, um die Datenblockgröße zu erhöhen, um die Flash-Leseeffizienz zu verbessern:
Bündelung von Spalten und Zeilen
Koaktivierungsbasierte Bündelung
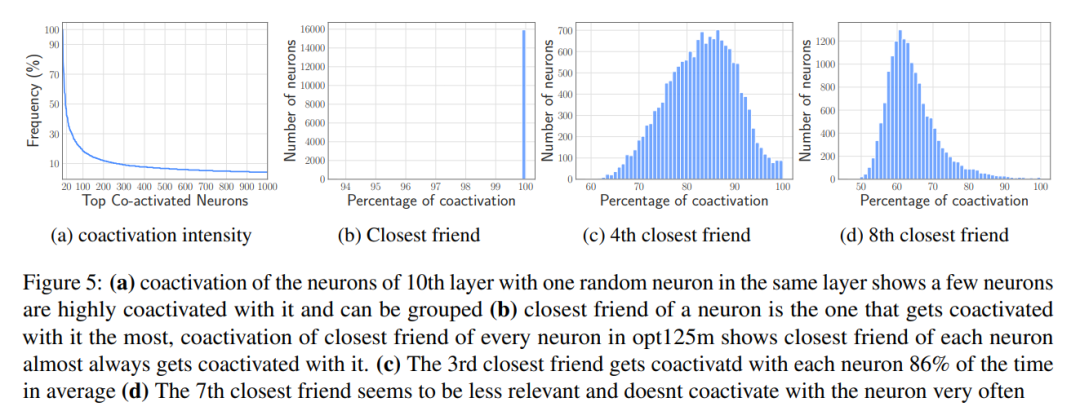
3. Effektive Verwaltung Geladene Daten: Vereinfachen Sie die Verwaltung von Daten nach dem Laden in den Speicher und minimieren Sie so den Overhead.
Die Übertragung von Daten im DRAM ist zwar effizienter als der Zugriff auf den Flash-Speicher, verursacht jedoch nicht zu vernachlässigende Kosten. Bei der Einführung von Daten für neue Neuronen kann die Neuzuweisung von Matrizen und das Hinzufügen neuer Matrizen einen erheblichen Mehraufwand verursachen, da vorhandene Neuronendaten im DRAM neu geschrieben werden müssen. Dies ist besonders kostspielig, wenn ein großer Teil (~25 %) des Feedforward-Netzwerks (FFN) im DRAM neu geschrieben werden muss.
Um dieses Problem zu lösen, haben die Forscher eine andere Strategie zur Speicherverwaltung übernommen. Diese Strategie beinhaltet die Vorabzuweisung des gesamten erforderlichen Speichers und die Einrichtung entsprechender Datenstrukturen für eine effiziente Verwaltung. Wie in Abbildung 6 dargestellt, umfasst die Datenstruktur Elemente wie Zeiger, Matrizen, Offsets, verwendete Zahlen und last_k_active Speicherblock und stapeln Sie dann die erforderlichen Elemente bis zum Ende, wodurch ein mehrfaches Kopieren der gesamten Daten vermieden wird.
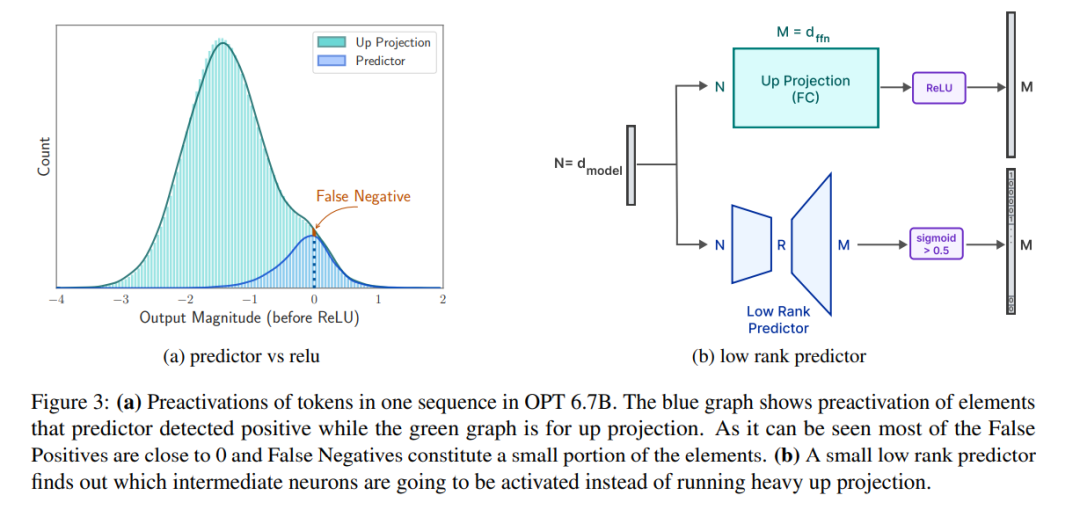
Neuschreiben der experimentellen Ergebnisse erforderlich. Ergebnisse des OPT 6.7B-Modells. Prädiktor. Wie in Abbildung 3a dargestellt, kann unser Prädiktor die meisten aktivierten Neuronen genau identifizieren, identifiziert jedoch gelegentlich nicht aktivierte Neuronen mit Werten nahe Null falsch. Es ist erwähnenswert, dass sich das endgültige Ausgabeergebnis nicht wesentlich ändert, nachdem diese falsch negativen Neuronen mit Werten nahe Null eliminiert wurden. Wie in Tabelle 1 gezeigt, wirkt sich diese Vorhersagegenauigkeit darüber hinaus nicht negativ auf die Leistung des Modells bei der Zero-Shot-Aufgabe aus.
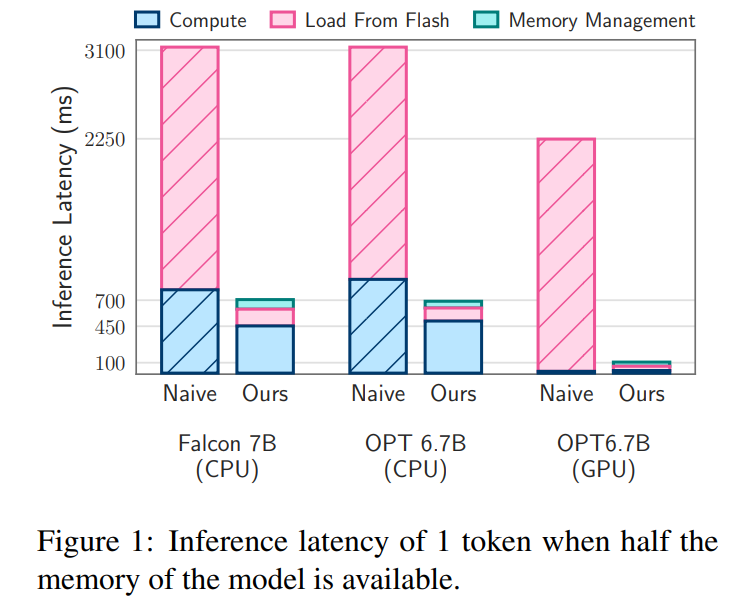
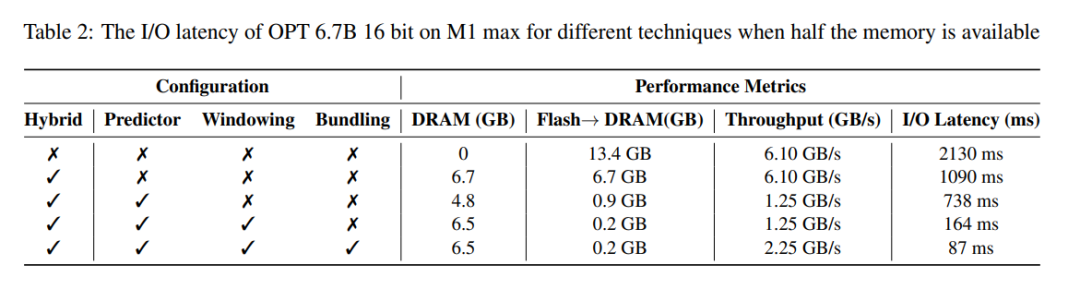
Latenzanalyse. Wenn die Fenstergröße 5 beträgt, muss jedes Token auf 2,4 % der Feedforward-Netzwerk-Neuronen (FFN) zugreifen. Für das 32-Bit-Modell beträgt die Datenblockgröße pro Lesevorgang 2dModell × 4 Byte = 32 KiB, da es sich um eine Verkettung von Zeilen und Spalten handelt. Beim M1 Max beträgt die Latenz für das Laden des Flashs pro Token 125 Millisekunden und die Latenz für die Speicherverwaltung (einschließlich Löschen und Hinzufügen von Neuronen) beträgt 65 Millisekunden. Daher beträgt die gesamte speicherbezogene Latenz weniger als 190 Millisekunden pro Token (siehe Abbildung 1). Im Vergleich dazu erfordert der Basisansatz das Laden von 13,4 GB Daten mit 6,1 GB/s, was zu einer Latenz von etwa 2330 Millisekunden pro Token führt. Daher ist unsere Methode im Vergleich zur Basismethode erheblich verbessert.
Beim 16-Bit-Modell auf einem GPU-Rechner wird die Flash-Ladezeit auf 40,5 ms reduziert und die Speicherverwaltungszeit beträgt 40 ms, mit einem leichten Anstieg aufgrund des zusätzlichen Overheads der Datenübertragung von der CPU zur GPU. Trotzdem beträgt die I/O-Zeit der Baseline-Methode immer noch über 2000 ms.
Tabelle 2 bietet einen detaillierten Vergleich der Leistungsauswirkungen der einzelnen Methoden.
Ergebnisse des Falcon 7B-Modells
Latenzanalyse. Bei einer Fenstergröße von 4 in unserem Modell muss jeder Token auf 3,1 % der Neuronen des Feedforward-Netzwerks (FFN) zugreifen. Im 32-Bit-Modell entspricht dies einer Blockgröße von 35,5 KiB pro Lesevorgang (berechnet als 2dmodel × 4 Bytes). Auf einem M1 Max-Gerät dauert das Flash-Laden dieser Daten etwa 161 Millisekunden, und der Speicherverwaltungsprozess fügt weitere 90 Millisekunden hinzu, sodass die Gesamtlatenz pro Token 250 Millisekunden beträgt. Im Vergleich dazu ist unsere Methode mit einer Basislatenz von etwa 2330 Millisekunden etwa 9 bis 10 Mal schneller.
Das obige ist der detaillierte Inhalt vonModell-Inferenzbeschleunigung: Die CPU-Leistung wird um das Fünffache erhöht. Apple nutzt Flash-Speicher für eine umfassende Inferenzbeschleunigung. Kommt Siri 2.0 auf den Markt?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Der Autor von ControlNet hat einen weiteren Hit! Der gesamte Prozess der Generierung eines Gemäldes aus einem Bild, der in zwei Tagen 1,4.000 Sterne verdient
Jul 17, 2024 am 01:56 AM
Der Autor von ControlNet hat einen weiteren Hit! Der gesamte Prozess der Generierung eines Gemäldes aus einem Bild, der in zwei Tagen 1,4.000 Sterne verdient
Jul 17, 2024 am 01:56 AM
Es ist ebenfalls ein Tusheng-Video, aber PaintsUndo ist einen anderen Weg gegangen. ControlNet-Autor LvminZhang begann wieder zu leben! Dieses Mal ziele ich auf den Bereich der Malerei. Das neue Projekt PaintsUndo hat nicht lange nach seinem Start 1,4.000 Sterne erhalten (die immer noch wahnsinnig steigen). Projektadresse: https://github.com/lllyasviel/Paints-UNDO Bei diesem Projekt gibt der Benutzer ein statisches Bild ein, und PaintsUndo kann Ihnen dabei helfen, automatisch ein Video des gesamten Malprozesses zu erstellen, vom Linienentwurf bis zum fertigen Produkt . Während des Zeichenvorgangs sind die Linienänderungen erstaunlich. Das Endergebnis des Videos ist dem Originalbild sehr ähnlich: Schauen wir uns eine vollständige Zeichnung an.
 Von RLHF über DPO bis TDPO sind große Modellausrichtungsalgorithmen bereits auf „Token-Ebene'
Jun 24, 2024 pm 03:04 PM
Von RLHF über DPO bis TDPO sind große Modellausrichtungsalgorithmen bereits auf „Token-Ebene'
Jun 24, 2024 pm 03:04 PM
Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. Einreichungs-E-Mail: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com Im Entwicklungsprozess der künstlichen Intelligenz war die Steuerung und Führung großer Sprachmodelle (LLM) schon immer eine der zentralen Herausforderungen, um sicherzustellen, dass diese Modelle beides sind kraftvoll und sicher dienen der menschlichen Gesellschaft. Frühe Bemühungen konzentrierten sich auf Methoden des verstärkenden Lernens durch menschliches Feedback (RL
 Die agentenlose Lösung von UIUC steht ganz oben auf der Liste der Open-Source-KI-Softwareentwickler und löst problemlos echte Programmierprobleme im SWE-Bench
Jul 17, 2024 pm 10:02 PM
Die agentenlose Lösung von UIUC steht ganz oben auf der Liste der Open-Source-KI-Softwareentwickler und löst problemlos echte Programmierprobleme im SWE-Bench
Jul 17, 2024 pm 10:02 PM
Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. Einreichungs-E-Mail: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com Die Autoren dieses Artikels stammen alle aus dem Team von Lehrer Zhang Lingming an der University of Illinois in Urbana-Champaign, darunter: Steven Code Repair; Doktorand im vierten Jahr, Forscher
 Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Wenn die Antwort des KI-Modells überhaupt unverständlich ist, würden Sie es wagen, sie zu verwenden? Da maschinelle Lernsysteme in immer wichtigeren Bereichen eingesetzt werden, wird es immer wichtiger zu zeigen, warum wir ihren Ergebnissen vertrauen können und wann wir ihnen nicht vertrauen sollten. Eine Möglichkeit, Vertrauen in die Ausgabe eines komplexen Systems zu gewinnen, besteht darin, vom System zu verlangen, dass es eine Interpretation seiner Ausgabe erstellt, die für einen Menschen oder ein anderes vertrauenswürdiges System lesbar ist, d. h. so vollständig verständlich, dass mögliche Fehler erkannt werden können gefunden. Um beispielsweise Vertrauen in das Justizsystem aufzubauen, verlangen wir von den Gerichten, dass sie klare und lesbare schriftliche Stellungnahmen abgeben, die ihre Entscheidungen erläutern und stützen. Für große Sprachmodelle können wir auch einen ähnlichen Ansatz verfolgen. Stellen Sie bei diesem Ansatz jedoch sicher, dass das Sprachmodell generiert wird
 Axiomatisches Training ermöglicht es LLM, kausales Denken zu erlernen: Das 67-Millionen-Parameter-Modell ist vergleichbar mit der Billionen-Parameter-Ebene GPT-4
Jul 17, 2024 am 10:14 AM
Axiomatisches Training ermöglicht es LLM, kausales Denken zu erlernen: Das 67-Millionen-Parameter-Modell ist vergleichbar mit der Billionen-Parameter-Ebene GPT-4
Jul 17, 2024 am 10:14 AM
Zeigen Sie LLM die Kausalkette und es lernt die Axiome. KI hilft Mathematikern und Wissenschaftlern bereits bei der Forschung. Beispielsweise hat der berühmte Mathematiker Terence Tao wiederholt seine Forschungs- und Forschungserfahrungen mit Hilfe von KI-Tools wie GPT geteilt. Damit KI in diesen Bereichen konkurrenzfähig sein kann, sind starke und zuverlässige Fähigkeiten zum kausalen Denken unerlässlich. Die in diesem Artikel vorgestellte Forschung ergab, dass ein Transformer-Modell, das auf die Demonstration des kausalen Transitivitätsaxioms für kleine Graphen trainiert wurde, auf das Transitivitätsaxiom für große Graphen verallgemeinern kann. Mit anderen Worten: Wenn der Transformer lernt, einfache kausale Überlegungen anzustellen, kann er für komplexere kausale Überlegungen verwendet werden. Der vom Team vorgeschlagene axiomatische Trainingsrahmen ist ein neues Paradigma zum Erlernen des kausalen Denkens auf der Grundlage passiver Daten, nur mit Demonstrationen
 arXiv-Artikel können als „Barrage' gepostet werden, die Diskussionsplattform von Stanford alphaXiv ist online, LeCun gefällt es
Aug 01, 2024 pm 05:18 PM
arXiv-Artikel können als „Barrage' gepostet werden, die Diskussionsplattform von Stanford alphaXiv ist online, LeCun gefällt es
Aug 01, 2024 pm 05:18 PM
Prost! Wie ist es, wenn es bei einer Papierdiskussion auf Worte ankommt? Kürzlich haben Studenten der Stanford University alphaXiv erstellt, ein offenes Diskussionsforum für arXiv-Artikel, das es ermöglicht, Fragen und Kommentare direkt zu jedem arXiv-Artikel zu posten. Website-Link: https://alphaxiv.org/ Tatsächlich ist es nicht erforderlich, diese Website speziell zu besuchen. Ändern Sie einfach arXiv in einer beliebigen URL in alphaXiv, um den entsprechenden Artikel direkt im alphaXiv-Forum zu öffnen: Sie können die Absätze darin genau lokalisieren das Papier, Satz: Im Diskussionsbereich auf der rechten Seite können Benutzer Fragen stellen, um dem Autor Fragen zu den Ideen und Details des Papiers zu stellen. Sie können beispielsweise auch den Inhalt des Papiers kommentieren, wie zum Beispiel: „Gegeben an.“
 Ein bedeutender Durchbruch in der Riemann-Hypothese! Tao Zhexuan empfiehlt dringend neue Arbeiten vom MIT und Oxford, und der 37-jährige Fields-Medaillengewinner nahm daran teil
Aug 05, 2024 pm 03:32 PM
Ein bedeutender Durchbruch in der Riemann-Hypothese! Tao Zhexuan empfiehlt dringend neue Arbeiten vom MIT und Oxford, und der 37-jährige Fields-Medaillengewinner nahm daran teil
Aug 05, 2024 pm 03:32 PM
Kürzlich gelang der Riemann-Hypothese, die als eines der sieben großen Probleme des Jahrtausends bekannt ist, ein neuer Durchbruch. Die Riemann-Hypothese ist ein sehr wichtiges ungelöstes Problem in der Mathematik, das sich auf die genauen Eigenschaften der Verteilung von Primzahlen bezieht (Primzahlen sind Zahlen, die nur durch 1 und sich selbst teilbar sind, und sie spielen eine grundlegende Rolle in der Zahlentheorie). In der heutigen mathematischen Literatur gibt es mehr als tausend mathematische Thesen, die auf der Aufstellung der Riemann-Hypothese (oder ihrer verallgemeinerten Form) basieren. Mit anderen Worten: Sobald die Riemann-Hypothese und ihre verallgemeinerte Form bewiesen sind, werden diese mehr als tausend Sätze als Theoreme etabliert, die einen tiefgreifenden Einfluss auf das Gebiet der Mathematik haben werden, und wenn sich die Riemann-Hypothese als falsch erweist, dann unter anderem Auch diese Sätze werden teilweise ihre Gültigkeit verlieren. Neuer Durchbruch kommt von MIT-Mathematikprofessor Larry Guth und der Universität Oxford
 Unbegrenzte Videogenerierung, Planung und Entscheidungsfindung, erzwungene Verbreitung der nächsten Token-Vorhersage und vollständige Sequenzverbreitung
Jul 23, 2024 pm 02:05 PM
Unbegrenzte Videogenerierung, Planung und Entscheidungsfindung, erzwungene Verbreitung der nächsten Token-Vorhersage und vollständige Sequenzverbreitung
Jul 23, 2024 pm 02:05 PM
Derzeit sind autoregressive groß angelegte Sprachmodelle, die das nächste Token-Vorhersageparadigma verwenden, auf der ganzen Welt populär geworden. Gleichzeitig haben uns zahlreiche synthetische Bilder und Videos im Internet bereits die Leistungsfähigkeit von Diffusionsmodellen gezeigt. Kürzlich hat ein Forschungsteam am MITCSAIL (darunter Chen Boyuan, ein Doktorand am MIT) erfolgreich die leistungsstarken Fähigkeiten des Vollsequenz-Diffusionsmodells und des nächsten Token-Modells integriert und ein Trainings- und Sampling-Paradigma vorgeschlagen: Diffusion Forcing (DF). ). Papiertitel: DiffusionForcing:Next-tokenPredictionMeetsFull-SequenceDiffusion Papieradresse: https:/
