

Dieser Artikel wird mit Genehmigung des öffentlichen Kontos von Autonomous Driving Heart nachgedruckt. Bitte wenden Sie sich für einen Nachdruck an die Quelle.
Die 3D-Objekterkennung auf Basis der LiDAR-Punktwolke war schon immer ein sehr klassisches Problem. Sowohl die Wissenschaft als auch die Industrie haben verschiedene Modelle zur Verbesserung von Genauigkeit, Geschwindigkeit und Robustheit vorgeschlagen. Aufgrund der komplexen Außenumgebung ist die Leistung der Objekterkennung für Punktwolken im Freien jedoch nicht sehr gut. Lidar-Punktwolken sind von Natur aus spärlich. Wie kann dieses Problem gezielt gelöst werden? Das Papier gibt seine eigene Antwort: Extrahieren Sie Informationen basierend auf der Aggregation von Zeitreiheninformationen.
 2. Einführung
2. Einführung
Dieses Papier diskutiert eine zentrale Herausforderung beim autonomen Fahren: die genaue Erstellung einer dreidimensionalen Darstellung der Umgebung. Dies ist wichtig für die Zuverlässigkeit und Sicherheit selbstfahrender Autos. Insbesondere müssen autonome Fahrzeuge in der Lage sein, umliegende Objekte wie Fahrzeuge und Fußgänger zu erkennen und deren Position, Größe und Ausrichtung genau zu bestimmen. Typischerweise verwenden Menschen tiefe neuronale Netze, um LiDAR-Daten zu verarbeiten und diese Aufgabe zu erfüllen. 
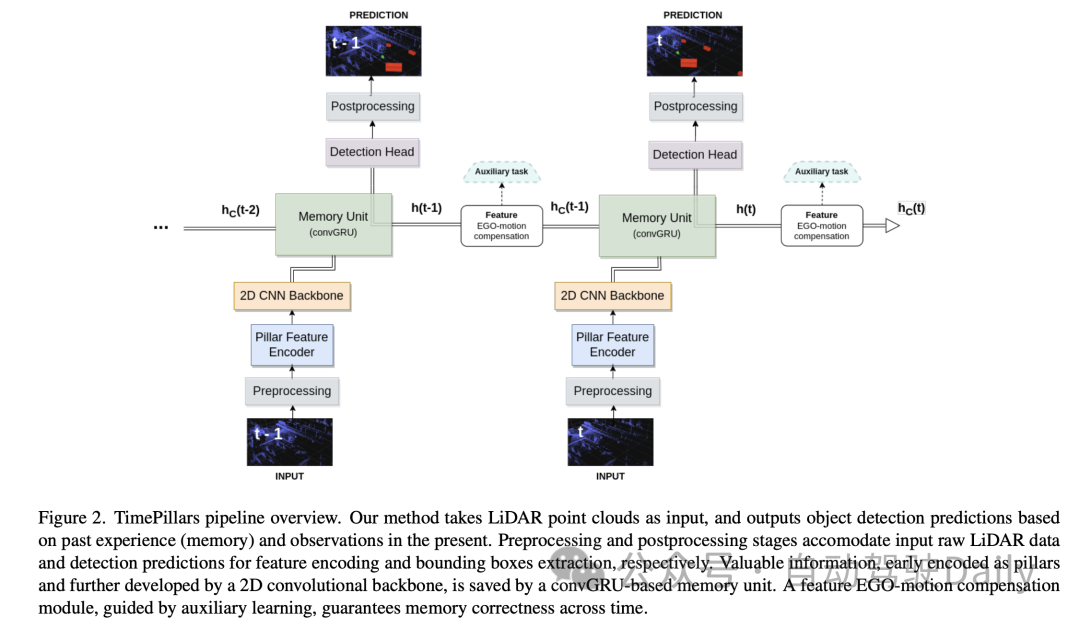
Im Teil „Eingabevorverarbeitung“ dieses Artikels verwendet der Autor die „Pillarization“-Technologie, um die Eingabepunktwolkendaten zu verarbeiten. Diese Methode unterscheidet sich von der herkömmlichen Voxelisierung, bei der die Punktwolke nur in horizontaler Richtung (x- und y-Achse) in vertikale Säulenstrukturen segmentiert wird, während in vertikaler Richtung (z-Achse) eine feste Höhe beibehalten wird. Dadurch bleiben die Netzwerkeingabeabmessungen konsistent und ermöglichen eine effiziente Verarbeitung mithilfe von 2D-Faltungen.
Ein Problem bei der Pillarisierung besteht jedoch darin, dass sie viele leere Spalten erzeugt, was zu sehr spärlichen Daten führt. Um dieses Problem zu lösen, schlägt das Papier den Einsatz der dynamischen Voxelisierungstechnologie vor. Diese Technik vermeidet die Notwendigkeit, für jede Spalte eine vordefinierte Anzahl von Punkten zu haben, wodurch Kürzungs- oder Fülloperationen für jede Spalte entfallen. Stattdessen werden die gesamten Punktwolkendaten als Ganzes verarbeitet, um der erforderlichen Gesamtpunktzahl zu entsprechen, die hier auf 200.000 Punkte festgelegt ist. Der Vorteil dieser Vorverarbeitungsmethode besteht darin, dass sie den Informationsverlust minimiert und die generierte Datendarstellung stabiler und konsistenter macht.
Dann stellte der Autor für die Modellarchitektur detailliert eine neuronale Netzwerkarchitektur vor, die aus einem Pillar Feature Encoder, einem 2D Convolutional Neural Network (CNN)-Backbone und einem Erkennungskopf besteht.
In diesem Teil des Artikels diskutiert der Autor, wie die von der Faltungs-GRU ausgegebenen verborgenen Zustandsmerkmale verarbeitet werden, die durch das Koordinatensystem des vorherigen Frames dargestellt werden. Bei direkter Speicherung und Verwendung zur Berechnung der nächsten Vorhersage kommt es aufgrund der Eigenbewegung zu einer räumlichen Nichtübereinstimmung.
Für die Konvertierung können verschiedene Techniken angewendet werden. Im Idealfall würden die korrigierten Daten in das Netzwerk eingespeist und nicht innerhalb des Netzwerks transformiert. Dies ist jedoch nicht der in der Arbeit vorgeschlagene Ansatz, da er das Zurücksetzen der verborgenen Zustände bei jedem Schritt im Inferenzprozess, die Transformation der vorherigen Punktwolken und deren Verbreitung im gesamten Netzwerk erfordert. Dies ist nicht nur ineffizient, es macht auch den Zweck der Verwendung von RNNs zunichte. Daher muss in einem Schleifenkontext die Kompensation auf Feature-Ebene erfolgen. Dies macht die hypothetische Lösung effizienter, macht das Problem aber auch komplexer. Herkömmliche Interpolationsmethoden können verwendet werden, um Merkmale in transformierten Koordinatensystemen zu erhalten.
Im Gegensatz dazu schlägt das Papier, inspiriert von der Arbeit von Chen et al., vor, Faltungsoperationen und Hilfsaufgaben zur Durchführung von Transformationen zu verwenden. Unter Berücksichtigung der begrenzten Details der oben genannten Arbeit schlägt das Papier eine maßgeschneiderte Lösung für dieses Problem vor.
Der in der Arbeit verfolgte Ansatz besteht darin, das Netzwerk über eine zusätzliche Faltungsschicht mit den Informationen zu versorgen, die zur Durchführung der Merkmalstransformation erforderlich sind. Zuerst wird die relative Transformationsmatrix zwischen zwei aufeinanderfolgenden Frames berechnet, d. h. die Operationen, die für eine erfolgreiche Transformation von Merkmalen erforderlich sind. Anschließend werden die 2D-Informationen (Rotations- und Translationsanteil) daraus extrahiert:
Diese Vereinfachung vermeidet die Hauptmatrixkonstanten und funktioniert im 2D-Bereich (Pseudobild), wodurch die 16 Werte reduziert werden bis 6. Anschließend wird die Matrix abgeflacht und erweitert, um sie an die Form der zu kompensierenden verborgenen Merkmale anzupassen. Die erste Dimension stellt die Anzahl der Frames dar, die konvertiert werden müssen. Diese Darstellung eignet sich für die Verkettung jeder potenziellen Säule in der Kanaldimension des verborgenen Features.
Abschließend werden die verborgenen Zustandsmerkmale in eine 2D-Faltungsschicht eingespeist, die an den Transformationsprozess angepasst ist. Ein wichtiger Aspekt ist, dass die Durchführung einer Faltung nicht garantiert, dass die Transformation stattfindet. Durch die Kanalverkettung erhält das Netzwerk lediglich zusätzliche Informationen darüber, wie die Transformation durchgeführt werden könnte. In diesem Fall bietet sich der Einsatz von assistiertem Lernen an. Während des Trainings wird parallel zum Hauptziel (Objekterkennung) ein zusätzliches Lernziel (Koordinatentransformation) hinzugefügt. Es wird eine Hilfsaufgabe entworfen, deren Zweck darin besteht, das Netzwerk unter Aufsicht durch den Transformationsprozess zu führen, um die Korrektheit der Kompensation sicherzustellen. Die Hilfsaufgabe ist auf den Trainingsprozess beschränkt. Sobald das Netzwerk lernt, Features korrekt zu transformieren, verliert es seine Anwendbarkeit. Daher wird diese Aufgabe bei der Inferenz nicht berücksichtigt. Im nächsten Abschnitt werden weitere Experimente durchgeführt, um die Auswirkungen zu vergleichen.
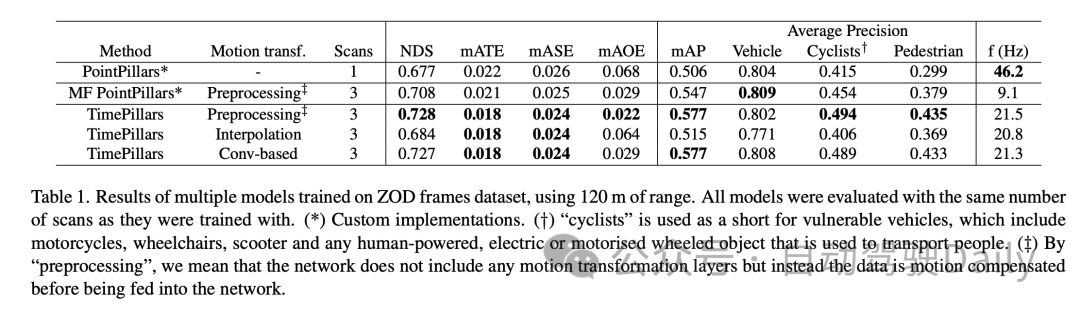
Experimentelle Ergebnisse zeigen, dass das TimePillars-Modell bei der Verarbeitung des Zenseact Open Dataset (ZOD)-Frame-Datensatzes eine gute Leistung erbringt, insbesondere bei der Verarbeitung von Entfernungen bis zu 120 Metern. Diese Ergebnisse verdeutlichen die Leistungsunterschiede von TimePillars bei verschiedenen Bewegungstransformationsmethoden und vergleichen sie mit anderen Methoden.
Nach dem Vergleich des Basismodells PointPillars und des Multi-Frame (MF) PointPillars ist ersichtlich, dass TimePillars bei mehreren wichtigen Leistungsindikatoren erhebliche Verbesserungen erzielt hat. Insbesondere beim NuScenes Detection Score (NDS) weist TimePillars eine höhere Gesamtpunktzahl auf, was seine Vorteile bei der Erkennungsleistung und Positionierungsgenauigkeit widerspiegelt. Darüber hinaus erzielte TimePillars auch niedrigere Werte beim durchschnittlichen Konvertierungsfehler (mATE), dem durchschnittlichen Skalenfehler (mASE) und dem durchschnittlichen Orientierungsfehler (mAOE), was darauf hinweist, dass es präziser in der Positionierungsgenauigkeit und Orientierungsschätzung ist. Besonders hervorzuheben ist, dass die unterschiedlichen Implementierungen von TimePillars im Hinblick auf die Bewegungskonvertierung einen erheblichen Einfluss auf die Leistung haben. Bei Verwendung der faltungsbasierten Bewegungstransformation (Conv-basiert) schneidet TimePillars besonders gut bei NDS, mATE, mASE und mAOE ab und beweist die Wirksamkeit dieser Methode bei der Bewegungskompensation und der Verbesserung der Erkennungsgenauigkeit. Im Gegensatz dazu übertrifft TimePillars mit der Interpolationsmethode ebenfalls das Basismodell, ist jedoch in einigen Indikatoren der Faltungsmethode unterlegen. Die Ergebnisse der durchschnittlichen Präzision (mAP) zeigen, dass TimePillars bei der Erkennung von Fahrzeugen, Radfahrern und Fußgängerkategorien gut abschneidet, insbesondere bei anspruchsvolleren Kategorien wie Radfahrern und Fußgängern ist die Leistungsverbesserung deutlicher. Aus Sicht der Verarbeitungsfrequenz (f (Hz)) sind TimePillars zwar nicht so schnell wie Single-Frame-PointPillars, aber schneller als Multi-Frame-PointPillars und behalten gleichzeitig eine hohe Erkennungsleistung bei. Dies zeigt, dass TimePillars eine effektive Fernerkennung und Bewegungskompensation durchführen und gleichzeitig die Echtzeitverarbeitung aufrechterhalten kann. Mit anderen Worten: Das TimePillars-Modell weist erhebliche Vorteile bei der Fernerkennung, Bewegungskompensation und Verarbeitungsgeschwindigkeit auf, insbesondere bei der Verarbeitung von Multiframe-Daten und der Verwendung einer faltungsbasierten Bewegungskonvertierungstechnologie. Diese Ergebnisse verdeutlichen das Anwendungspotenzial von TimePillars im Bereich der 3D-Lidar-Objekterkennung für autonome Fahrzeuge.

Die oben genannten experimentellen Ergebnisse zeigen, dass das TimePillars-Modell bei der Objekterkennung in verschiedenen Entfernungsbereichen eine hervorragende Leistung erbringt, insbesondere im Vergleich zum Benchmark-Modell PointPillars. Diese Ergebnisse sind in drei Haupterkennungsbereiche unterteilt: 0 bis 50 Meter, 50 bis 100 Meter und über 100 Meter.
Zuallererst sind der NuScenes Detection Score (NDS) und die Average Precision (mAP) die Gesamtleistungsindikatoren. TimePillars übertrifft PointPillars in beiden Metriken und weist insgesamt höhere Erkennungsfähigkeiten und Positionierungsgenauigkeit auf. Konkret liegt der NDS von TimePillars bei 0,723, was viel höher ist als der von PointPillars mit 0,657. In Bezug auf den mAP übertrifft TimePillars mit 0,570 auch deutlich den Wert von 0,475.
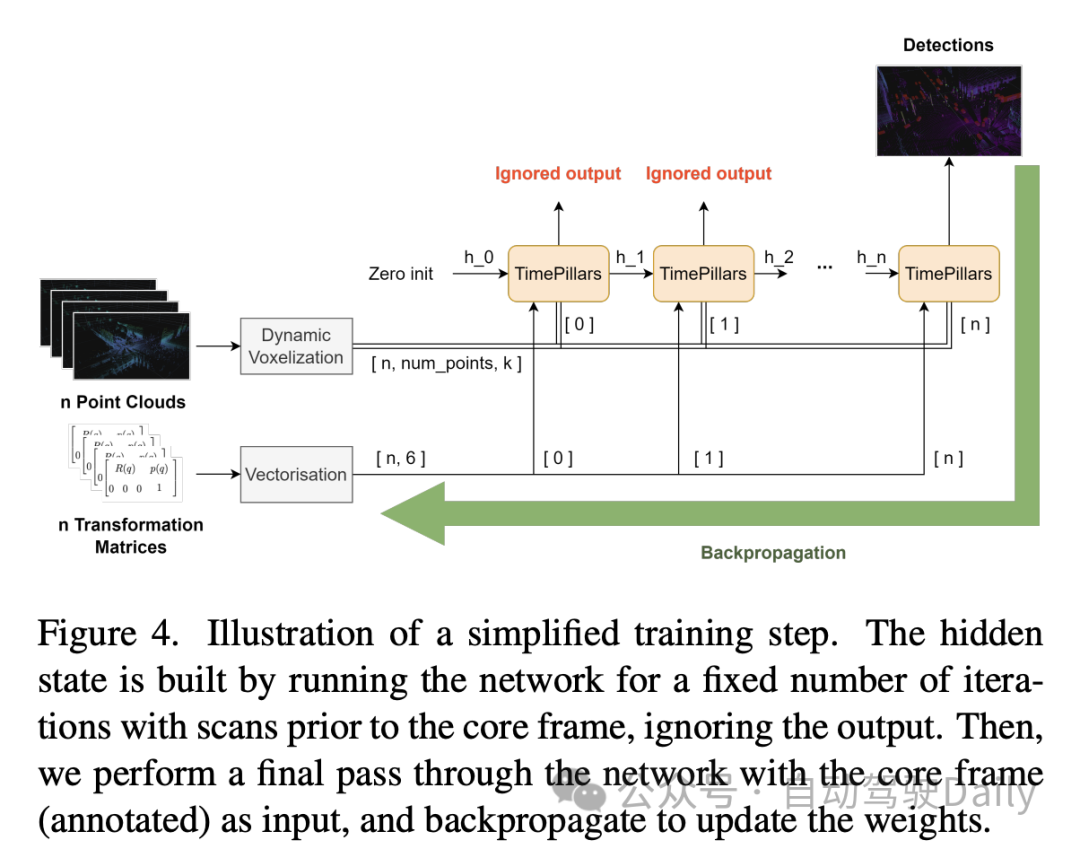
Im Leistungsvergleich innerhalb verschiedener Distanzbereiche zeigt sich, dass TimePillars in jedem Bereich besser abschneidet. Für die Fahrzeugkategorie beträgt die Erkennungsgenauigkeit von TimePillars in den Bereichen 0 bis 50 Meter, 50 bis 100 Meter und über 100 Meter 0,884, 0,776 bzw. 0,591, was allesamt höher ist als die Leistung von PointPillars im gleichen Bereich. Dies zeigt, dass TimePillars eine höhere Genauigkeit bei der Fahrzeugerkennung aufweist, sowohl im Nah- als auch im Fernbereich. TimePillars zeigte auch eine bessere Erkennungsleistung beim Umgang mit gefährdeten Fahrzeugen (wie Motorrädern, Rollstühlen, Elektrorollern usw.). Insbesondere im Bereich von mehr als 100 Metern beträgt die Erkennungsgenauigkeit von TimePillars 0,178, während PointPillars nur 0,036 beträgt, was erhebliche Vorteile bei der Erkennung über große Entfernungen zeigt. Bei der Fußgängererkennung zeigte TimePillars ebenfalls eine bessere Leistung, insbesondere im Bereich von 50 bis 100 Metern, mit einer Erkennungsgenauigkeit von 0,350, während PointPillars nur 0,211 betrug. Selbst auf größere Entfernungen (über 100 Meter) erreicht TimePillars noch eine gewisse Erkennungsgenauigkeit (Genauigkeit von 0,032), während PointPillars in dieser Entfernung keine Leistung erbringt.
Diese experimentellen Ergebnisse unterstreichen die überlegene Leistung von TimePillars bei der Bewältigung von Objekterkennungsaufgaben in verschiedenen Entfernungsbereichen. Ob im Nahbereich oder im anspruchsvolleren Fernbereich, TimePillars liefern genauere und zuverlässigere Erkennungsergebnisse, die für die Sicherheit und Effizienz autonomer Fahrzeuge von entscheidender Bedeutung sind.

Der Hauptvorteil des TimePillars-Modells ist zunächst seine Wirksamkeit bei der Objekterkennung über große Entfernungen. Durch den Einsatz dynamischer Voxelisierung und Faltungs-GRU-Strukturen ist das Modell besser in der Lage, spärliche LIDAR-Daten zu verarbeiten, insbesondere bei der Objekterkennung über große Entfernungen. Dies ist entscheidend für den sicheren Betrieb autonomer Fahrzeuge in komplexen und sich verändernden Straßenumgebungen. Darüber hinaus zeigt das Modell auch eine gute Leistung hinsichtlich der Verarbeitungsgeschwindigkeit, was für Echtzeitanwendungen unerlässlich ist. Andererseits verwendet TimePillars eine faltungsbasierte Methode zur Bewegungskompensation, was eine wesentliche Verbesserung gegenüber herkömmlichen Methoden darstellt. Dieser Ansatz stellt die Korrektheit der Transformation durch Hilfsaufgaben während des Trainings sicher und verbessert so die Genauigkeit des Modells beim Umgang mit bewegten Objekten.
Allerdings weist die Forschung dieser Arbeit auch einige Einschränkungen auf. Erstens schneidet TimePillars zwar gut bei der Erkennung entfernter Objekte ab, diese Leistungssteigerung kann jedoch zu Lasten einer gewissen Verarbeitungsgeschwindigkeit gehen. Die Geschwindigkeit des Modells ist zwar immer noch für Echtzeitanwendungen geeignet, im Vergleich zu Single-Frame-Methoden ist sie jedoch immer noch geringer. Darüber hinaus konzentriert sich das Papier hauptsächlich auf LiDAR-Daten und berücksichtigt keine anderen Sensoreingaben wie Kameras oder Radare, was die Anwendung des Modells in komplexeren Multisensorumgebungen einschränken könnte.
Das heißt, TimePillars hat erhebliche Vorteile bei der 3D-Lidar-Objekterkennung für autonome Fahrzeuge gezeigt, insbesondere bei der Fernerkennung und Bewegungskompensation. Trotz des leichten Kompromisses bei der Verarbeitungsgeschwindigkeit und Einschränkungen bei der Verarbeitung von Multisensordaten stellt TimePillars immer noch einen wichtigen Fortschritt auf diesem Gebiet dar.
Diese Arbeit zeigt, dass die Berücksichtigung früherer Sensordaten der alleinigen Nutzung aktueller Informationen überlegen ist. Der Zugriff auf frühere Fahrumgebungsinformationen kann die spärliche Beschaffenheit von LIDAR-Punktwolken bewältigen und zu genaueren Vorhersagen führen. Wir zeigen, dass rekurrente Netzwerke als Mittel geeignet sind, Letzteres zu erreichen. Die Bereitstellung von Systemspeicher führt zu einer robusteren Lösung im Vergleich zu Punktwolken-Aggregationsmethoden, die durch umfangreiche Verarbeitung dichtere Datendarstellungen erstellen. Unsere vorgeschlagene Methode, TimePillars, implementiert eine Möglichkeit zur Lösung des rekursiven Problems. Indem wir einfach drei zusätzliche Faltungsschichten zum Inferenzprozess hinzufügen, zeigen wir, dass grundlegende Netzwerkbausteine ausreichen, um signifikante Ergebnisse zu erzielen und sicherzustellen, dass bestehende Effizienz- und Hardware-Integrationsspezifikationen erfüllt werden. Nach unserem besten Wissen liefert diese Arbeit die ersten Benchmark-Ergebnisse für die 3D-Objekterkennungsaufgabe auf dem neu eingeführten offenen Zenseact-Datensatz. Wir hoffen, dass unsere Arbeit in Zukunft zu sichereren und nachhaltigeren Straßen beitragen kann.

Originallink: https://mp.weixin.qq.com/s/94JQcvGXFWfjlDCT77gjlA
Das obige ist der detaillierte Inhalt vonVerbessern Sie die Erkennungsfähigkeiten effizient: Durchbrechen Sie die Erkennung kleiner Ziele über 200 Metern. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Formel des mechanischen Energieeinsparungsgesetzes
Formel des mechanischen Energieeinsparungsgesetzes
 Was ist Löwenzahn?
Was ist Löwenzahn?
 Die Funktion des Zwischenrelais
Die Funktion des Zwischenrelais
 So bezahlen Sie mit WeChat auf Douyin
So bezahlen Sie mit WeChat auf Douyin
 Alle Verwendungen von Cloud-Servern
Alle Verwendungen von Cloud-Servern
 So beantragen Sie eine geschäftliche E-Mail-Adresse
So beantragen Sie eine geschäftliche E-Mail-Adresse
 Können Douyin-Kurzvideos nach dem Löschen wiederhergestellt werden?
Können Douyin-Kurzvideos nach dem Löschen wiederhergestellt werden?
 Verwendung der Formatierungsfunktion
Verwendung der Formatierungsfunktion
 So verwenden Sie „months_between' in SQL
So verwenden Sie „months_between' in SQL








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



