
 Technologie-Peripheriegeräte
KI
Die University of Science and Technology of China entwickelt die Methode „State Sequence Frequency Domain Prediction', die die Leistung um 20 % verbessert und die Probeneffizienz maximiert.
Technologie-Peripheriegeräte
KI
Die University of Science and Technology of China entwickelt die Methode „State Sequence Frequency Domain Prediction', die die Leistung um 20 % verbessert und die Probeneffizienz maximiert.
Die University of Science and Technology of China entwickelt die Methode „State Sequence Frequency Domain Prediction', die die Leistung um 20 % verbessert und die Probeneffizienz maximiert.

Der Trainingsprozess des Verstärkungslernalgorithmus (Reinforcement Learning, RL) erfordert normalerweise eine große Menge an Beispieldaten, die mit der Umgebung interagieren, um sie zu unterstützen. In der realen Welt ist es jedoch oft sehr kostspielig, eine große Anzahl von Interaktionsproben zu sammeln, oder die Sicherheit des Probenahmeprozesses kann nicht gewährleistet werden, wie beispielsweise beim UAV-Luftkampftraining und beim autonomen Fahrtraining. Dieses Problem schränkt den Umfang des verstärkenden Lernens in vielen praktischen Anwendungen ein. Daher haben Forscher intensiv daran gearbeitet, herauszufinden, wie ein Gleichgewicht zwischen Probeneffizienz und Sicherheit gefunden werden kann, um dieses Problem zu lösen. Eine mögliche Lösung besteht darin, Simulatoren oder virtuelle Umgebungen zu nutzen, um große Mengen an Beispieldaten zu generieren und so die Kosten und Sicherheitsrisiken realer Situationen zu vermeiden. Um die Stichprobeneffizienz von Reinforcement-Learning-Algorithmen während des Trainingsprozesses zu verbessern, haben einige Forscher außerdem Repräsentationslerntechnologien verwendet, um Hilfsaufgaben zur Vorhersage zukünftiger Zustandssignale zu entwerfen. Auf diese Weise können Algorithmen aus dem ursprünglichen Umweltzustand Merkmale extrahieren und kodieren, die für zukünftige Entscheidungen relevant sind. Der Zweck dieses Ansatzes besteht darin, die Leistung von Reinforcement-Learning-Algorithmen zu verbessern, indem mehr Informationen über die Umgebung gelernt und eine bessere Grundlage für die Entscheidungsfindung bereitgestellt werden. Auf diese Weise kann der Algorithmus Beispieldaten während des Trainingsprozesses effizienter nutzen, den Lernprozess beschleunigen und die Genauigkeit und Effizienz der Entscheidungsfindung verbessern.
Basierend auf dieser Idee wurde in dieser Arbeit eine Hilfsaufgabe entworfen, um die Zustandssequenz-Häufigkeitsbereichsverteilung
für mehrere Schritte in der Zukunft vorherzusagen, um längerfristige zukünftige Entscheidungsmerkmale zu erfassen und dadurch die Stichprobeneffizienz des Algorithmus zu verbessern .Diese Arbeit trägt den Titel State Sequences Prediction via Fourier Transform for Representation Learning, wurde in NeurIPS 2023 veröffentlicht und als Spotlight akzeptiert.
Autorenliste: Ye Mingxuan, Kuang Yufei, Wang Jie*, Yang Rui, Zhou Wengang, Li Houqiang, Wu Feng
Link zum Papier: https://openreview.net/forum?id= MvoMDD6emT
Code-Link: https://github.com/MIRALab-USTC/RL-SPF/
Forschungshintergrund und Motivation
Deep Reinforcement Learning-Algorithmus in der Robotersteuerung [1], Spielintelligenz [ 2], Große Erfolge wurden in Bereichen wie der kombinatorischen Optimierung [3] erzielt. Allerdings leidet der aktuelle Reinforcement-Learning-Algorithmus immer noch unter dem Problem der „geringen Stichprobeneffizienz“, d. h. der Roboter benötigt eine große Datenmenge, die mit der Umgebung interagiert, um eine Strategie mit hervorragender Leistung zu trainieren.
Um die Stichprobeneffizienz zu verbessern, haben Forscher begonnen, sich auf das Lernen von Darstellungen zu konzentrieren, in der Hoffnung, dass die durch Training erhaltenen Darstellungen umfangreiche und nützliche Merkmalsinformationen aus dem ursprünglichen Zustand der Umgebung extrahieren und so die Erkundungseffizienz des Roboters in der Umgebung verbessern können Zustandsraum.
Reinforcement-Learning-Algorithmus-Framework basierend auf Repräsentationslernen
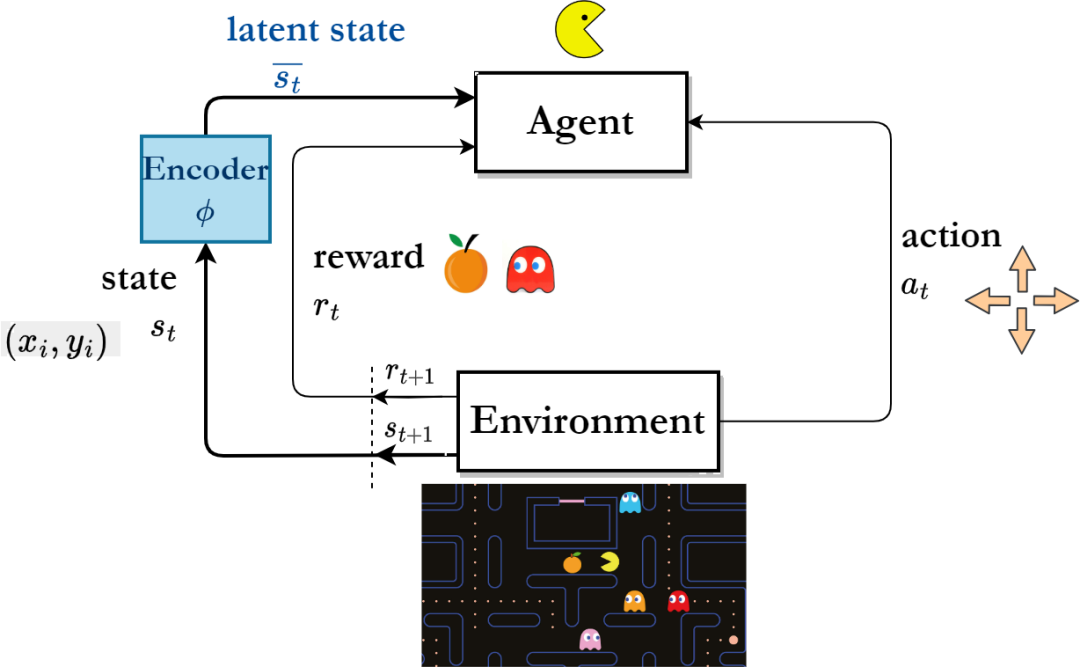
„Langzeitsequenzsignale“im Vergleich mehr zukünftige Informationen, die für die langfristige Entscheidungsfindung von Vorteil sind zu Einzelschrittsignalen. Inspiriert von dieser Sichtweise haben einige Forscher vorgeschlagen, das Repräsentationslernen durch die Vorhersage mehrstufiger Zustandssequenzsignale in der Zukunft zu unterstützen [4,5]. Es ist jedoch sehr schwierig, die Zustandssequenz direkt vorherzusagen, um das Repräsentationslernen zu unterstützen.
Unter den beiden vorhandenen Methoden generiert eine Methode schrittweise den zukünftigen Zustand in einem einzigen Moment, indem sie das „einstufige Wahrscheinlichkeitsübergangsmodell“ lernt, um die mehrstufige Zustandssequenz indirekt vorherzusagen [6,7]. Diese Art von Methode erfordert jedoch eine hohe Genauigkeit des trainierten Wahrscheinlichkeitsübertragungsmodells, da sich der Vorhersagefehler bei jedem Schritt mit zunehmender Länge der Vorhersagesequenz ansammelt.
Eine andere Art von Methode unterstützt das Repräsentationslernen [8] durchdirekte Vorhersage der Zustandssequenz mehrerer Schritte in der Zukunft[8], aber diese Art von Methode muss die mehrstufige reale Zustandssequenz als Bezeichnung speichern der Vorhersageaufgabe, die viel Speicherplatz verbraucht. Daher ist es ein Problem, das gelöst werden muss, wie aus der Zustandssequenz der Umgebung zukünftige Informationen, die für die langfristige Entscheidungsfindung von Vorteil sind, effektiv extrahiert und dadurch die Probeneffizienz während des kontinuierlichen Kontrollrobotertrainings verbessert werden kann.
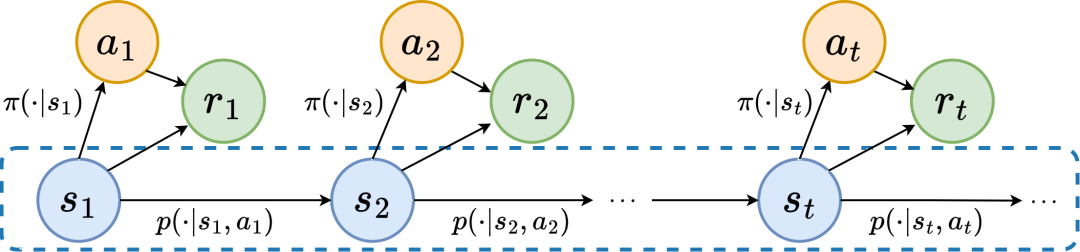
Um die oben genannten Probleme zu lösen, schlagen wir eine Repräsentationslernmethode vor, die auf der Vorhersage der Zustandssequenzfrequenzdomäne basiert (State Sequences Prediction via F
ourier Transform,SPF). „Frequenzbereichsverteilung der Zustandssequenz“ zu verwenden, um Trend- und Regelmäßigkeitsinformationen in Zustandssequenzdaten explizit zu extrahieren und so die Darstellung bei der effizienten Extraktion langfristiger zukünftiger Informationen zu unterstützen. Wir haben theoretisch bewiesen, dass es „zwei Arten von Strukturinformationen“ in der Zustandssequenz gibt, zum einen Trendinformationen im Zusammenhang mit der Strategieleistung und zum anderen Regelmäßigkeitsinformationen im Zusammenhang mit der Statusperiodizität. Bevor wir die beiden Strukturinformationen im Detail analysieren, stellen wir zunächst die relevanten Definitionen von Markov-Entscheidungsprozessen (MDP) vor, die Zustandssequenzen erzeugen. Wir betrachten den klassischen Markov-Entscheidungsprozess in einem kontinuierlichen Kontrollproblem, das durch ein Fünffach dargestellt werden kann. Darunter sind der entsprechende Zustand und Aktionsraum, die Belohnungsfunktion, die Zustandsübergangsfunktion der Umgebung, die Anfangsverteilung des Zustands und der Abzinsungsfaktor. Darüber hinaus verwenden wir zur Darstellung der Aktionsverteilung der Politik im Bundesstaat. Wir zeichnen den aktuellen Status des Agenten als auf und die ausgewählte Aktion als Nachdem der Agent die Aktion ausgeführt hat, wechselt die Umgebung im nächsten Moment in den Status und gibt Belohnungen an den Agenten zurück. Wir zeichnen die Trajektorie auf, die dem Zustand und der Aktion entspricht, die während der Interaktion zwischen dem Agenten und der Umgebung erhalten wird, und die Trajektorie folgt der Verteilung. Das Ziel des Reinforcement-Learning-Algorithmus besteht darin, die erwartete kumulative Rendite in der Zukunft zu maximieren. Wir verwenden, um die durchschnittliche kumulative Rendite unter dem aktuellen Strategie- und Umgebungsmodell darzustellen, und abgekürzt als , was wie folgt definiert ist: zeigt die Leistung der aktuellen Strategie. Im Folgenden stellen wir das „erste Strukturmerkmal“ der Zustandssequenz vor, das die Abhängigkeit zwischen der Zustandssequenz und der entsprechenden Belohnungssequenz beinhaltet und die Leistung der aktuellen Strategie zeigen kann. Trend . Bei Verstärkungslernaufgaben bestimmt die zukünftige Zustandssequenz weitgehend die Reihenfolge der Aktionen, die der Agent in der Zukunft durchführt, und bestimmt darüber hinaus die entsprechende Belohnungssequenz. Daher enthält die zukünftige Zustandssequenz nicht nur Informationen über die der Umgebung inhärente Wahrscheinlichkeitsübergangsfunktion, sondern kann auch dabei helfen, den Trend der aktuellen Strategie zu erfassen. Inspiriert von der obigen Struktur haben wir den folgenden Satz bewiesen, um die Existenz dieser strukturellen Abhängigkeit weiter zu demonstrieren: Satz 1: Wenn die Belohnungsfunktion nur mit dem Zustand zusammenhängt, dann für zwei beliebige Strategien und ihre Leistungsunterschiede können durch den Unterschied in den durch diese beiden Strategien erzeugten Zustandssequenzverteilungen gesteuert werden: Stellt in der obigen Formel die Wahrscheinlichkeitsverteilung der Zustandssequenz unter den Bedingungen der angegebenen Strategie und Übergangswahrscheinlichkeitsfunktion dar, und stellt die Norm dar. Der obige Satz zeigt, dass der Verteilungsunterschied zwischen den beiden entsprechenden Zustandssequenzen umso größer ist, je größer der Leistungsunterschied zwischen den beiden Strategien ist. Dies bedeutet, dass eine gute und eine schlechte Strategie zwei völlig unterschiedliche Zustandssequenzen erzeugen, was weiter verdeutlicht, dass die in der Zustandssequenz enthaltenen langfristigen Strukturinformationen möglicherweise die Effizienz der Suchstrategie bei hervorragender Leistung beeinflussen können. Andererseits kann die Frequenzbereichsverteilungsdifferenz der Zustandssequenz unter bestimmten Bedingungen auch eine Obergrenze für die entsprechende Richtlinienleistungsdifferenz liefern, wie im folgenden Satz gezeigt: Satz 2 : Wenn der Zustand Der Raum ist endlichdimensional und die Belohnungsfunktion ist ein Polynom n-Grades, das sich auf den Zustand bezieht, dann kann der Leistungsunterschied zwischen zwei beliebigen Strategien und durch den Unterschied in der Frequenzbereichsverteilung der erzeugten Zustandssequenzen gesteuert werden durch diese beiden Strategien: Stellt in der obigen Formel die Fourier-Funktion der Potenzfolge der durch die Richtlinie erzeugten Zustandsfolge dar und stellt die te Komponente der Fourier-Funktion dar. Dieses Theorem zeigt, dass die Frequenzbereichsverteilung der Zustandssequenz immer noch Merkmale enthält, die für die aktuelle Richtlinienleistung relevant sind. Regelmäßige Informationen vor, das in der Zustandssequenz existiert und die Zeitabhängigkeit zwischen Zustandssignalen beinhaltet, also die Zustandssequenz über einen langen Zeitraum normales Muster ausgestellt. Bei vielen realen Aufgaben zeigen Agenten auch periodisches Verhalten, da die Zustandsübergangsfunktion ihrer Umgebung selbst periodisch ist. Nehmen Sie als Beispiel einen industriellen Montageroboter. Der Roboter wird darauf trainiert, Teile zusammenzubauen, um ein Endprodukt zu erstellen. Wenn das Strategietraining Stabilität erreicht, führt er eine periodische Aktionssequenz aus, die es ihm ermöglicht, Teile effizient zusammenzubauen. Inspiriert durch das obige Beispiel liefern wir einige theoretische Analysen, um zu beweisen, dass im endlichen Zustandsraum, wenn die Übergangswahrscheinlichkeitsmatrix bestimmte Annahmen erfüllt, die entsprechende Zustandssequenz „allmählich“ angezeigt werden kann, wenn der Agent eine stabile Strategie erreicht . „Fast periodisch“, der spezifische Satz lautet wie folgt: Satz 3: Für einen endlichdimensionalen Zustandsraum mit einer Zustandsübergangsmatrix, vorausgesetzt, es gibt zyklische Klassen, die entsprechende Zustandsübergangsuntermatrix ist. Angenommen, die Anzahl der Eigenwerte dieser Matrix mit Modul 1 beträgt, dann zeigt die Zustandsverteilung für die Anfangsverteilung eines beliebigen Zustands eine asymptotische Periodizität mit der Periode. Wenn in der MuJoCo-Aufgabe das Richtlinientraining Stabilität erreicht, zeigt der Agent auch periodische Bewegungen. Die folgende Abbildung zeigt ein Beispiel für die Zustandssequenz des HalfCheetah-Agenten in der MuJoCo-Aufgabe über einen bestimmten Zeitraum, wobei eine offensichtliche Periodizität beobachtet werden kann. (Weitere Beispiele für periodische Zustandssequenzen in der MuJoCo-Aufgabe finden Sie in Abschnitt E im Anhang dieses Dokuments.) Die Periodizität des Zustands des HalfCheetah-Agenten in der MuJoCo-Aufgabe über einen bestimmten Zeitraum Die durch Zeitreihen im Zeitbereich dargestellten Informationen sind relativ verstreut, im Frequenzbereich werden die regulären Informationen in der Sequenz jedoch in konzentrierterer Form dargestellt. Durch die Analyse der Frequenzkomponenten im Frequenzbereich können wir die in der Zustandssequenz vorhandenen periodischen Eigenschaften explizit erfassen. Im vorherigen Teil haben wir theoretisch bewiesen, dass die Frequenzbereichsverteilung der Zustandssequenz die Leistung der Strategie widerspiegeln kann, und durch die Analyse der Frequenzkomponenten im Frequenzbereich können wir dies explizit Erfassen Sie die periodischen Merkmale der Zustandssequenz. Inspiriert von der obigen Analyse haben wir die Hilfsaufgabe „Vorhersage der Fourier-Transformation einer unendlichstufigen zukünftigen Zustandsfolge“ entworfen, um die Darstellung zum Extrahieren von Strukturinformationen in der Zustandsfolge zu ermutigen. Im Folgenden wird unsere Modellierung dieser Hilfsaufgabe vorgestellt. Angesichts des aktuellen Zustands und der aktuellen Aktion definieren wir die zukünftige Zustandssequenzerwartung wie folgt: Unsere Hilfsaufgabe trainiert eine Darstellung, um die diskrete Zeit-Fourier-Transformation (DTFT) der obigen Zustandssequenzerwartung vorherzusagen ist, Die obige Fourier-Transformationsformel kann in die folgende rekursive Form umgeschrieben werden: wo, wo , Dimensionen des Zustandsraums, ist die Anzahl der Diskretisierungspunkte der Fourier-Funktion der vorhergesagten Zustandsfolge. Inspiriert von der TD-Fehler-Verlustfunktion [9], die Q-Wert-Netzwerke im Q-Learning optimiert, haben wir die folgende Verlustfunktion entworfen: Dazu gehören die neuronalen Netzwerkparameter des Repräsentationsencoders (Encoder) und des Fourier-Funktionsprädiktors (Prädiktor), für die die Verlustfunktion optimiert werden muss, und der Erfahrungspool zum Speichern von Beispieldaten. Darüber hinaus können wir beweisen, dass die obige rekursive Formel als Komprimierungskarte ausgedrückt werden kann: Theorem 4: Stellen Sie die Funktionsfamilie dar und definieren Sie die Norm auf wobei stellt den Zeilenvektor der Matrix dar. Wir definieren die Zuordnung als und es kann bewiesen werden, dass es sich um eine Kompressionszuordnung handelt. Gemäß dem Komprimierungszuordnungsprinzip können wir den Operator iterativ verwenden, um die Frequenzbereichsverteilung der realen Zustandssequenz anzunähern, und haben eine Konvergenzgarantie in der tabellarischen Einstellung. Darüber hinaus hängt die von uns entworfene Verlustfunktion nur vom Zustand des aktuellen Moments und des nächsten Moments ab, sodass die Zustandsdaten mehrerer Schritte in der Zukunft nicht als Vorhersageetiketten gespeichert werden müssen, was Vorteile hat von „einfache Implementierung und geringes Speichervolumen“ . Im Folgenden stellen wir das Algorithmus-Framework der Methode (SPF) in diesem Artikel vor. Wir geben die Zustandsaktionsdaten des aktuellen Moments und des nächsten Moments online (online) und im Ziel ein ( Ziel) bzw. ) Im Darstellungsencoder (Encoder) werden die Zustandsaktionsdarstellungsdaten erhalten und dann werden die Darstellungsdaten in den Fourier-Funktionsprädiktor (Prädiktor) eingegeben, um zum aktuellen Zeitpunkt zwei Sätze von Zustandssequenz-Fourier-Funktionsvorhersagen zu erhalten und im nächsten Moment. Durch Ersetzen dieser beiden Sätze von Fourier-Funktionsvorhersagen können wir den Verlustfunktionswert berechnen. Wir optimieren und aktualisieren den Repräsentationsencoder und den Fourier-Funktionsprädiktor, indem wir die Verlustfunktion minimieren, sodass die Ausgabe des Prädiktors die Fourier-Transformation der realen Zustandssequenz annähern kann, wodurch der Repräsentationsencoder dazu angeregt wird, Merkmale zu extrahieren, die das enthalten langfristige zukünftige Eigenschaften der Strukturinformationen von Zustandssequenzen. Wir geben den ursprünglichen Zustand und die ursprüngliche Aktion in den Repräsentationsencoder ein, verwenden die erhaltenen Merkmale als Eingabe des Akteurnetzwerks und Kritikernetzwerks im Verstärkungslernalgorithmus und verwenden den klassischen Verstärkungslernalgorithmus, um das Akteursnetzwerk und den Kritiker zu optimieren Netzwerk. Experimentelle Ergebnisse (Hinweis: In diesem Abschnitt wird nur ein Teil der experimentellen Ergebnisse ausgewählt. Ausführlichere Ergebnisse finden Sie in Abschnitt 6 und im Anhang des Originalpapiers.) Wir werden die SPF-Methode in der MuJoCo-Simulationsrobotersteuerungsumgebung testen und die folgenden sechs Methoden vergleichen: Die obige Abbildung zeigt die Leistungskurven unserer vorgeschlagenen SPF-Methode (rote Linie und orange Linie) und anderer Vergleichsmethoden in 6 MuJoCo-Aufgaben. Die Ergebnisse zeigen, dass unsere vorgeschlagene Methode im Vergleich zu anderen Methoden eine Leistungsverbesserung von 19,5 % erreichen kann. Wir führten Ablationsexperimente für jedes Modul der SPF-Methode durch und verglichen diese Methode mit der Nichtverwendung des Projektormoduls (noproj), der Nichtverwendung des Zielnetzwerkmoduls (notarg) und der Änderung des Vorhersageverlusts (nofreqloss) Vergleichen Sie die Leistung beim Ändern der Feature-Encoder-Netzwerkstruktur (mlp, mlp_cat). Ablationsexperiment-Ergebnisdiagramm der SPF-Methode, angewendet auf den SAC-Algorithmus, getestet mit der HalfCheetah-Aufgabe Wir verwenden die SPF-Methodetrainierter Prädiktor, um das Fu von auszugeben Die Zustandssequenz-Fourier-Funktion und die durch die Inverse Fourier-Transformation wiederhergestellte 200-Schritte-Zustandssequenz werden mit der echten 200-Schritte-Zustandssequenz verglichen. Die Ergebnisse zeigen, dass die wiederhergestellte Zustandssequenz der realen Zustandssequenz sehr ähnlich ist, selbst wenn ein längerer Zustand als Eingabe verwendet wird. Dies zeigt, dass die durch die SPF-Methode erlernte Darstellung die im Zustand enthaltene Struktur effektiv kodieren kann Reihenfolge. Strukturelle Informationsanalyse in der Zustandssequenz
Markov-Entscheidungsprozess
Trendinformationen
Jetzt stellen wir das
"zweite Strukturmerkmal"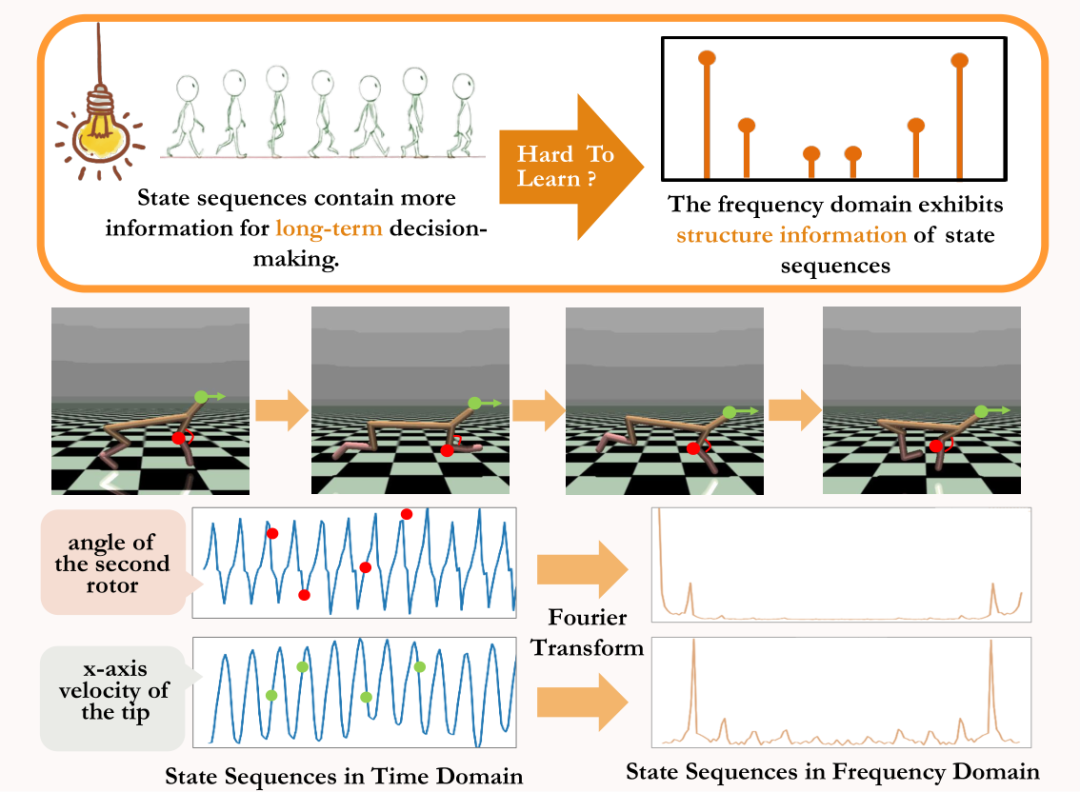
Einführung in die Methode
SPF-Methodenverlustfunktion
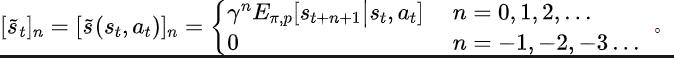
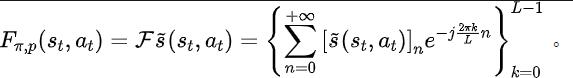
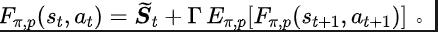
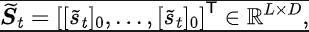

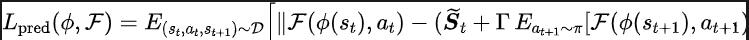
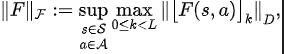
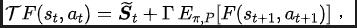
Algorithmus-Framework der SPF-Methode
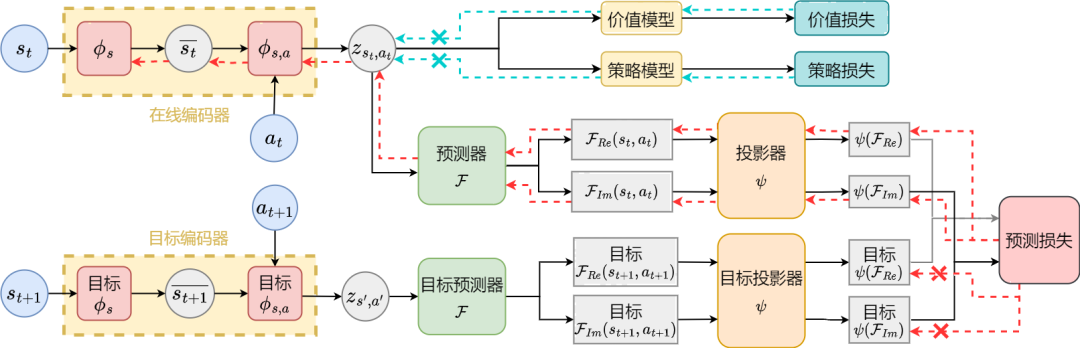 Algorithmusrahmendiagramm der Repräsentationslernmethode (SPF) basierend auf der Vorhersage der Zustandssequenzfrequenzdomäne
Algorithmusrahmendiagramm der Repräsentationslernmethode (SPF) basierend auf der Vorhersage der Zustandssequenzfrequenzdomäne
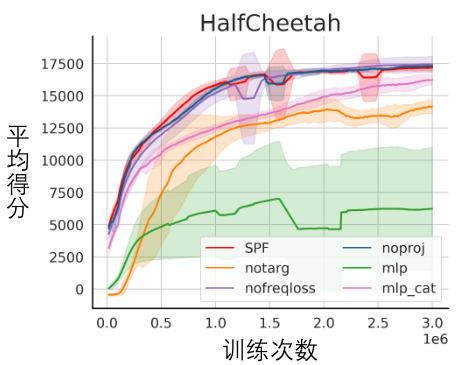
Vergleich der Algorithmusleistung
Ablationsexperiment
Visualisierungsexperiment
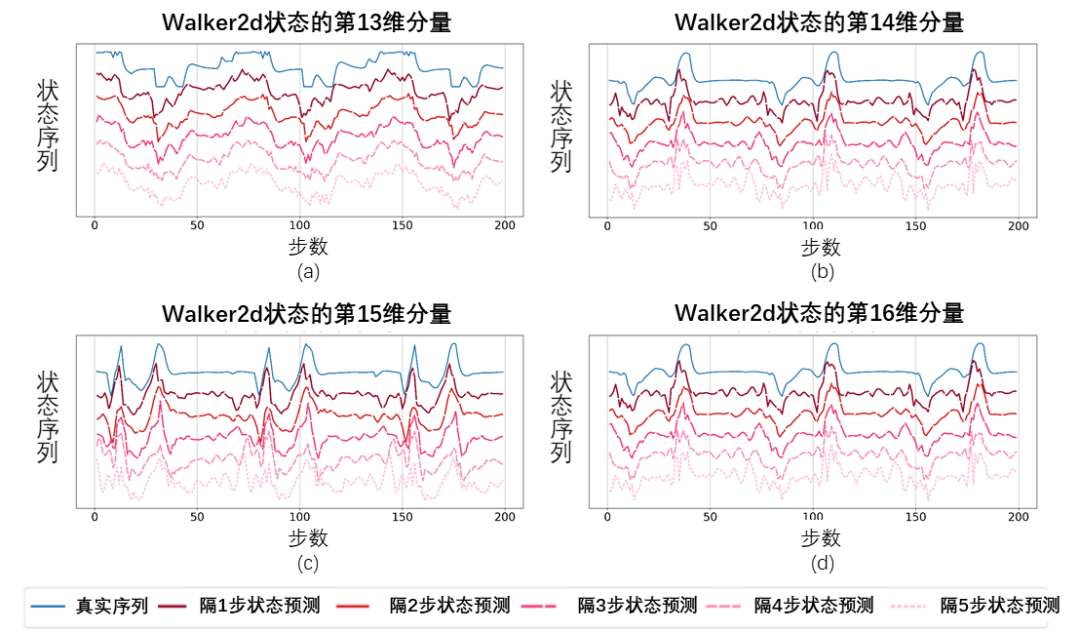 Schematisches Diagramm der wiederhergestellten Zustandssequenz basierend auf dem vorhergesagten Wert der Fourier-Funktion, getestet mit der Walker2d-Aufgabe. Darunter ist die blaue Linie ein schematisches Diagramm der realen Zustandssequenz und die fünf roten Linien sind ein schematisches Diagramm der wiederhergestellten Zustandssequenz. Die unteren und helleren roten Linien stellen die unter Verwendung des längeren historischen Zustands wiederhergestellte Zustandssequenz dar.
Schematisches Diagramm der wiederhergestellten Zustandssequenz basierend auf dem vorhergesagten Wert der Fourier-Funktion, getestet mit der Walker2d-Aufgabe. Darunter ist die blaue Linie ein schematisches Diagramm der realen Zustandssequenz und die fünf roten Linien sind ein schematisches Diagramm der wiederhergestellten Zustandssequenz. Die unteren und helleren roten Linien stellen die unter Verwendung des längeren historischen Zustands wiederhergestellte Zustandssequenz dar.
Das obige ist der detaillierte Inhalt vonDie University of Science and Technology of China entwickelt die Methode „State Sequence Frequency Domain Prediction', die die Leistung um 20 % verbessert und die Probeneffizienz maximiert.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
0.Was bewirkt dieser Artikel? Wir schlagen DepthFM vor: ein vielseitiges und schnelles generatives monokulares Tiefenschätzungsmodell auf dem neuesten Stand der Technik. Zusätzlich zu herkömmlichen Tiefenschätzungsaufgaben demonstriert DepthFM auch hochmoderne Fähigkeiten bei nachgelagerten Aufgaben wie dem Tiefen-Inpainting. DepthFM ist effizient und kann Tiefenkarten innerhalb weniger Inferenzschritte synthetisieren. Lassen Sie uns diese Arbeit gemeinsam lesen ~ 1. Titel der Papierinformationen: DepthFM: FastMonocularDepthEstimationwithFlowMatching Autor: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Stehen Sie vor einer Verzögerung oder einer langsamen mobilen Datenverbindung auf dem iPhone? Normalerweise hängt die Stärke des Mobilfunk-Internets auf Ihrem Telefon von mehreren Faktoren ab, wie z. B. der Region, dem Mobilfunknetztyp, dem Roaming-Typ usw. Es gibt einige Dinge, die Sie tun können, um eine schnellere und zuverlässigere Mobilfunk-Internetverbindung zu erhalten. Fix 1 – Neustart des iPhone erzwingen Manchmal werden durch einen erzwungenen Neustart Ihres Geräts viele Dinge zurückgesetzt, einschließlich der Mobilfunkverbindung. Schritt 1 – Drücken Sie einfach einmal die Lauter-Taste und lassen Sie sie los. Drücken Sie anschließend die Leiser-Taste und lassen Sie sie wieder los. Schritt 2 – Der nächste Teil des Prozesses besteht darin, die Taste auf der rechten Seite gedrückt zu halten. Lassen Sie das iPhone den Neustart abschließen. Aktivieren Sie Mobilfunkdaten und überprüfen Sie die Netzwerkgeschwindigkeit. Überprüfen Sie es erneut. Fix 2 – Datenmodus ändern 5G bietet zwar bessere Netzwerkgeschwindigkeiten, funktioniert jedoch besser, wenn das Signal schwächer ist
 Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Ich weine zu Tode. Die Daten im Internet reichen überhaupt nicht aus. Das Trainingsmodell sieht aus wie „Die Tribute von Panem“, und KI-Forscher auf der ganzen Welt machen sich Gedanken darüber, wie sie diese datenhungrigen Esser ernähren sollen. Dieses Problem tritt insbesondere bei multimodalen Aufgaben auf. Zu einer Zeit, als sie ratlos waren, nutzte ein Start-up-Team der Abteilung der Renmin-Universität von China sein eigenes neues Modell, um als erstes in China einen „modellgenerierten Datenfeed selbst“ in die Realität umzusetzen. Darüber hinaus handelt es sich um einen zweigleisigen Ansatz auf der Verständnisseite und der Generierungsseite. Beide Seiten können hochwertige, multimodale neue Daten generieren und Datenrückmeldungen an das Modell selbst liefern. Was ist ein Modell? Awaker 1.0, ein großes multimodales Modell, das gerade im Zhongguancun-Forum erschienen ist. Wer ist das Team? Sophon-Motor. Gegründet von Gao Yizhao, einem Doktoranden an der Hillhouse School of Artificial Intelligence der Renmin University.
 Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Kürzlich wurde die Militärwelt von der Nachricht überwältigt: US-Militärkampfflugzeuge können jetzt mithilfe von KI vollautomatische Luftkämpfe absolvieren. Ja, erst kürzlich wurde der KI-Kampfjet des US-Militärs zum ersten Mal der Öffentlichkeit zugänglich gemacht und sein Geheimnis gelüftet. Der vollständige Name dieses Jägers lautet „Variable Stability Simulator Test Aircraft“ (VISTA). Er wurde vom Minister der US-Luftwaffe persönlich geflogen, um einen Eins-gegen-eins-Luftkampf zu simulieren. Am 2. Mai startete US-Luftwaffenminister Frank Kendall mit einer X-62AVISTA auf der Edwards Air Force Base. Beachten Sie, dass während des einstündigen Fluges alle Flugaktionen autonom von der KI durchgeführt wurden! Kendall sagte: „In den letzten Jahrzehnten haben wir über das unbegrenzte Potenzial des autonomen Luft-Luft-Kampfes nachgedacht, aber es schien immer unerreichbar.“ Nun jedoch,
