GPT-4 hat seine außergewöhnliche Fähigkeit unter Beweis gestellt, detaillierte und genaue Bildbeschreibungen zu erstellen, und markiert damit den Beginn einer neuen Ära der Sprach- und visuellen Verarbeitung. Daher sind in letzter Zeit multimodale große Sprachmodelle (MLLM) ähnlich wie GPT-4 entstanden und zu einem aufstrebenden Forschungsgebiet geworden. Der Kern ihrer Forschung besteht darin, leistungsstarkes LLM als Werkzeug zur Durchführung multimodaler Aufgaben zu verwenden . Die unerwartete und herausragende Leistung von MLLM übertrifft nicht nur herkömmliche Methoden, sondern macht es auch zu einer der potenziellen Möglichkeiten, allgemeine künstliche Intelligenz zu erreichen. Um nützliches MLLM zu erstellen, ist es notwendig, umfangreiche gepaarte Bild-Text-Daten und visuell-linguistische Feinabstimmungsdaten zu verwenden, um eingefrorenes LLM (wie LLaMA und Vicuna) und visuelle Darstellungen (wie z. B CLIP- und BLIP-2)-Anschlüsse (wie MiniGPT-4, LLaVA und LLaMA-Adapter). Das MLLM-Training ist normalerweise in zwei Phasen unterteilt: die Vortrainingsphase und die Feinabstimmungsphase. Der Zweck des Vortrainings besteht darin, dem MLLM den Erwerb einer großen Menge an Wissen zu ermöglichen, während die Feinabstimmung darin besteht, dem Modell beizubringen, menschliche Absichten besser zu verstehen und genaue Antworten zu generieren. Um die Fähigkeit von MLLM zu verbessern, visuelle Sprache zu verstehen und Anweisungen zu befolgen, wurde kürzlich eine leistungsstarke Feinabstimmungstechnologie namens Instruction Tuning entwickelt. Diese Technologie hilft dabei, Modelle an menschlichen Vorlieben auszurichten, sodass das Modell unter verschiedenen Anweisungen die vom Menschen gewünschten Ergebnisse liefert. Im Hinblick auf die Entwicklung der Technologie zur Feinabstimmung von Anweisungen besteht eine recht konstruktive Richtung darin, in der Feinabstimmungsphase Bildanmerkungen, visuelle Fragebeantwortung (VQA) und Datensätze zum visuellen Denken einzuführen. Frühere Techniken wie InstructBLIP und Otter verwendeten eine Reihe visuell-linguistischer Datensätze zur Feinabstimmung visueller Anweisungen und erzielten ebenfalls vielversprechende Ergebnisse. Es wurde jedoch beobachtet, dass häufig verwendete multimodale Befehlsfeinabstimmungsdatensätze eine große Anzahl von Fällen geringer Qualität enthalten, in denen die Antworten falsch oder irrelevant sind. Solche Daten sind irreführend und können sich negativ auf die Modellleistung auswirken. Diese Frage veranlasste Forscher, die Möglichkeit zu untersuchen: Kann eine robuste Leistung mit kleinen Mengen hochwertiger Folgeanweisungsdaten erreicht werden? Einige neuere Studien haben ermutigende Ergebnisse geliefert, die darauf hinweisen, dass diese Richtung Potenzial hat. Beispielsweise schlugen Zhou et al. LIMA vor, ein Sprachmodell, das anhand hochwertiger, von menschlichen Experten sorgfältig ausgewählter Daten verfeinert wurde. Diese Studie zeigt, dass große Sprachmodelle auch mit begrenzten Mengen hochwertiger Folgeanweisungsdaten zufriedenstellende Ergebnisse erzielen können. Daraus kamen die Forscher zu dem Schluss: Weniger ist mehr, wenn es um die Ausrichtung geht. Es gibt jedoch keine klare Richtlinie zur Auswahl geeigneter, qualitativ hochwertiger Datensätze zur Feinabstimmung multimodaler Sprachmodelle. Ein Forschungsteam des Qingyuan Research Institute der Shanghai Jiao Tong University und der Lehigh University hat diese Lücke geschlossen und einen robusten und effektiven Datenselektor vorgeschlagen. Dieser Datenselektor identifiziert und filtert automatisch visuell-verbale Daten von geringer Qualität und stellt so sicher, dass die relevantesten und informativsten Proben für das Modelltraining verwendet werden. Papieradresse: https://arxiv.org/abs/2308.12067Der Forscher sagte, dass der Schwerpunkt dieser Studie darin liegt, die Auswirkungen kleiner, aber hochwertiger Unterrichtseinheiten zu untersuchen. Optimierungsdaten zur Feinabstimmung von Multi-Mode-Modellen. Die Wirksamkeit dynamischer großer Sprachmodelle. Darüber hinaus werden in diesem Artikel mehrere neue Metriken vorgestellt, die speziell zur Bewertung der Qualität multimodaler Unterrichtsdaten entwickelt wurden. Nachdem das Bild spektral geclustert wurde, berechnet der Datenselektor einen gewichteten Score, der den CLIP-Score, den GPT-Score, den Bonus-Score und die Antwortlänge für jeden Teil der visuell-verbalen Daten kombiniert. Durch die Verwendung dieses Selektors bei 3400 Rohdaten, die zur Feinabstimmung von MiniGPT-4 verwendet wurden, stellten die Forscher fest, dass die meisten Daten Probleme mit geringer Qualität aufwiesen. Mit diesem Datenselektor erhielt der Forscher eine viel kleinere Teilmenge der kuratierten Daten – nur 200 Daten, nur 6 % des ursprünglichen Datensatzes. Dann verwendeten sie dieselbe Trainingskonfiguration wie MiniGPT-4 und optimierten sie, um ein neues Modell zu erhalten: InstructionGPT-4. Die Forscher sagten, dies sei eine aufregende Entdeckung, weil sie zeige, dass die Qualität der Daten wichtiger sei als die Quantität bei der Feinabstimmung visuell-verbaler Anweisungen. Darüber hinaus bietet diese Änderung mit stärkerer Betonung der Datenqualität ein neues und effektiveres Paradigma, das die MLLM-Feinabstimmung verbessern kann.Die Forscher führten strenge Experimente durch, und die experimentelle Bewertung des fein abgestimmten MLLM konzentrierte sich auf sieben verschiedene und komplexe multimodale Datensätze mit offener Domäne, darunter Flick-30k, ScienceQA, VSR usw. Sie verglichen die Inferenzleistung von Modellen, die mithilfe verschiedener Methoden zur Datensatzauswahl (unter Verwendung von Datenselektoren, zufälliger Stichprobenentnahme des Datensatzes, Verwendung des vollständigen Datensatzes) bei verschiedenen multimodalen Aufgaben optimiert wurden. Die Ergebnisse zeigten die Überlegenheit der Leistung von InstructionGPT-4 . Darüber hinaus ist zu beachten: Der vom Forscher zur Bewertung verwendete Evaluator ist GPT-4. Konkret nutzten die Forscher Prompt, um GPT-4 in einen Evaluator umzuwandeln, der die Antwortergebnisse von InstructionGPT-4 und dem ursprünglichen MiniGPT-4 mithilfe des Testsatzes in LLaVA-Bench vergleichen kann. Es wurde festgestellt, dass die von InstructionGPT-4 verwendeten feinabgestimmten Daten zwar nur 6 % unter den ursprünglichen von MiniGPT-4 verwendeten Daten zur Anweisungskonformität lagen, letzteres jedoch in 73 % der Fälle eine Antwort lieferte gleich oder besser. Die Hauptbeiträge dieses Papiers umfassen:
- Durch die Auswahl von 200 (ca. 6 %) hochwertigen Instruktionsfolgedaten zum Trainieren von InstructionGPT-4 zeigten die Forscher, dass es für mehrere Zwecke verwendet werden kann -modale groß angelegte Sprachmodelle verwenden weniger Befehlsdaten, um eine bessere Ausrichtung zu erreichen.
- Dieses Papier schlägt einen Datenselektor vor, der ein einfaches und interpretierbares Prinzip verwendet, um hochwertige multimodale Daten zur Befehlskonformität für die Feinabstimmung auszuwählen. Dieser Ansatz zielt darauf ab, Validität und Portabilität bei der Auswertung und Anpassung von Teildatenmengen zu erreichen.
- Forscher haben durch Experimente gezeigt, dass diese einfache Technologie verschiedene Aufgaben gut bewältigen kann. Im Vergleich zum ursprünglichen MiniGPT-4 erzielt InstructionGPT-4, das nur zu 6 % gefilterte Daten verwendet, eine bessere Leistung bei einer Vielzahl von Aufgaben.
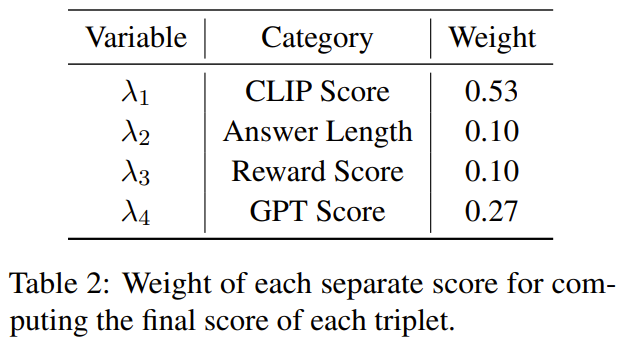
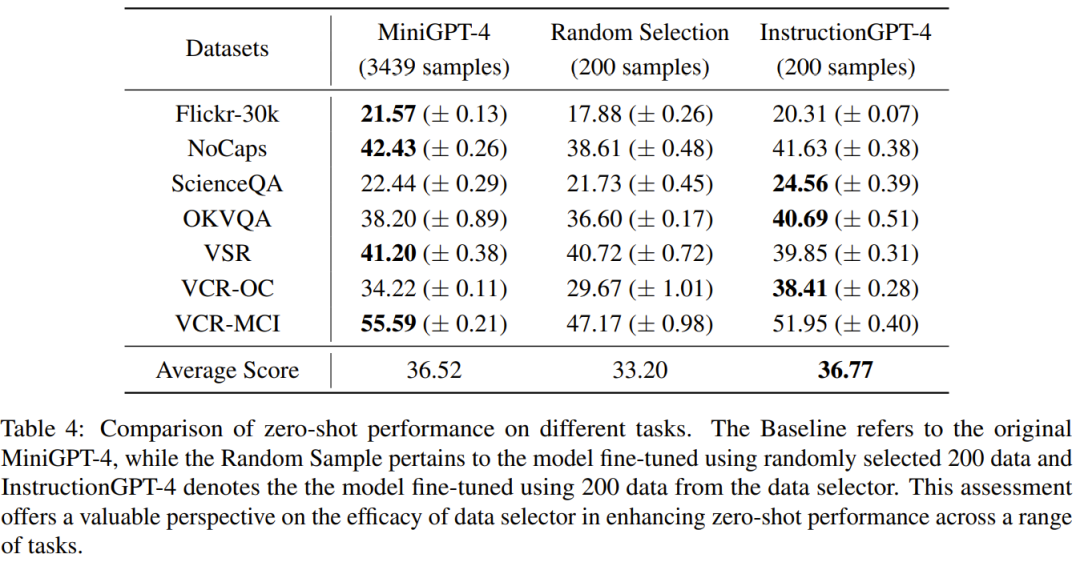
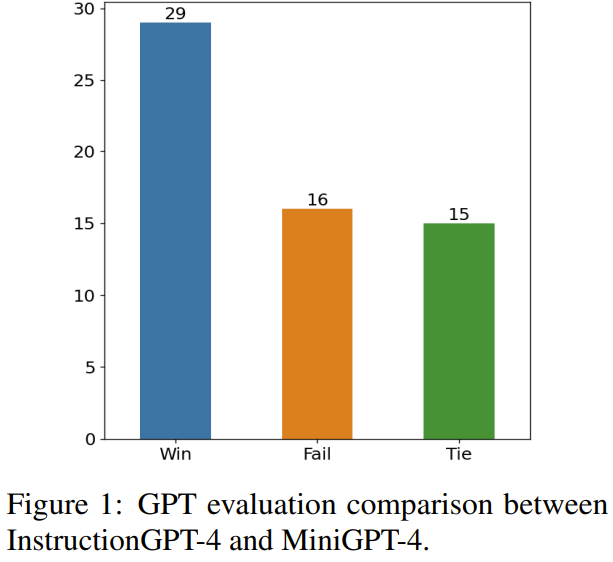
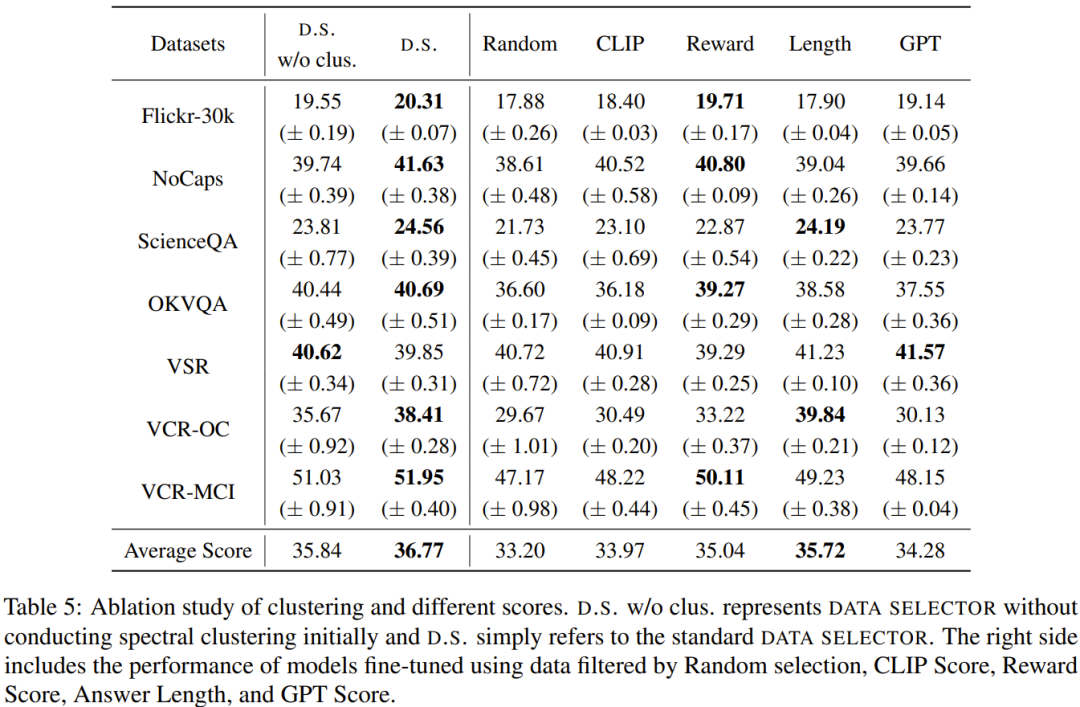
Das Ziel dieser Forschung ist es, einen einfachen und tragbaren Datenselektor vorzuschlagen, der automatisch eine Teilmenge aus dem ursprünglich fein abgestimmten Datensatz auswählen kann. Zu diesem Zweck definierten die Forscher ein Auswahlprinzip, das die Vielfalt und Qualität multimodaler Datensätze in den Mittelpunkt stellt. Im Folgenden erfolgt eine kurze Einführung. Um MLLM effektiv zu trainieren, ist es entscheidend, nützliche multimodale Unterrichtsdaten auszuwählen. Um die optimalen Unterrichtsdaten auszuwählen, schlugen die Forscher zwei Schlüsselprinzipien vor: Vielfalt und Qualität. Aus Gründen der Vielfalt besteht der Ansatz der Forscher darin, Bildeinbettungen zu gruppieren, um die Daten in verschiedene Gruppen zu unterteilen. Um die Qualität zu beurteilen, haben die Forscher einige Schlüsselmetriken für eine effiziente Auswertung multimodaler Daten übernommen. Anhand eines visuell-linguistischen Befehlsdatensatzes und eines vorab trainierten MLLM (wie MiniGPT-4 und LLaVA) besteht das ultimative Ziel des Datenselektors darin, a zu identifizieren Eine Teilmenge, die zur Feinabstimmung verwendet wird und es dieser Teilmenge ermöglicht, Verbesserungen an vorab trainiertem MLLM vorzunehmen. Um diese Teilmenge auszuwählen und ihre Vielfalt sicherzustellen, verwendeten die Forscher zunächst einen Clustering-Algorithmus, um den Originaldatensatz in mehrere Kategorien zu unterteilen. Um die Qualität der ausgewählten multimodalen Unterrichtsdaten sicherzustellen, entwickelten die Forscher eine Reihe von Indikatoren zur Bewertung, wie in Tabelle 1 unten dargestellt. Tabelle 2 zeigt die Gewichtung der einzelnen Punkte bei der Berechnung des Endpunktes. Algorithmus 1 zeigt den gesamten Workflow des Datenselektors. Der in der experimentellen Auswertung verwendete Datensatz ist in Tabelle 3 unten dargestellt. Tabelle 4 vergleicht die Leistung des MiniGPT-4-Basismodells, des MiniGPT-4, das mithilfe zufällig ausgewählter Daten verfeinert wurde, und des InstructionGPT-4, das mithilfe von Datenselektoren verfeinert wurde. .Es ist zu beobachten, dass die durchschnittliche Leistung von InstructionGPT-4 am besten ist. Insbesondere übertrifft InstructionGPT-4 das Basismodell bei ScienceQA um 2,12 % und übertrifft das Basismodell bei OKVQA und VCR-OC um 2,49 % bzw. 4,19 %. Darüber hinaus übertrifft InstructionGPT-4 Modelle, die mit Zufallsstichproben bei allen anderen Aufgaben außer VSR trainiert wurden. Durch die Bewertung und den Vergleich dieser Modelle für eine Reihe von Aufgaben ist es möglich, ihre jeweiligen Fähigkeiten zu erkennen und die Wirksamkeit neu vorgeschlagener Datenselektoren zu bestimmen, die qualitativ hochwertige Daten effektiv identifizieren. Eine solch umfassende Analyse zeigt, dass eine kluge Datenauswahl die Zero-Shot-Leistung des Modells bei einer Vielzahl unterschiedlicher Aufgaben verbessern kann. LLM selbst hat eine inhärente Positionsverzerrung. Hierzu können Sie sich auf den Artikel auf dieser Website beziehen „Sprachmodell ist leise faul?“ Neue Forschung: Wenn der Kontext zu lang ist, überspringt das Modell die Mitte und liest ihn nicht》. Daher haben die Forscher Maßnahmen ergriffen, um dieses Problem zu lösen. Sie haben insbesondere zwei Reihenfolgen der Antwortanordnung verwendet, um die Auswertung gleichzeitig durchzuführen, d. h. die von InstructionGPT-4 generierten Antworten vor oder nach den von MiniGPT-4 generierten Antworten zu platzieren. Um klare Bewertungskriterien zu entwickeln, haben sie das „Win-Tie-Lose“-System übernommen: 1) Sieg: InstructionGPT-4 Gewinnen Sie in beiden Situationen oder gewinnen Sie einmal und unentschieden einmal 2) Unentschieden: InstructionGPT -4 und MiniGPT-4 ziehen zweimal oder gewinnen einmal und verlieren einmal 3) Verlieren: AnleitungGPT-4 verliert zweimal oder verliert einmal und verliert einmal. Abbildung 1 zeigt die Ergebnisse dieser Bewertungsmethode. Bei 60 Fragen gewann InstructionGPT-4 29 Spiele, verlor 16 Spiele und blieb in den verbleibenden 15 Spielen unentschieden. Dies reicht aus, um zu beweisen, dass InstructionGPT-4 hinsichtlich der Antwortqualität deutlich besser ist als MiniGPT-4. Tabelle 5 enthält die Analyseergebnisse der Ablationsexperimente, aus denen die Bedeutung des Clustering-Algorithmus und verschiedener Bewertungsergebnisse ersichtlich ist. Um ein tieferes Verständnis der Fähigkeit von InstructionGPT-4 zu erlangen, visuelle Eingaben zu verstehen und vernünftige Antworten zu generieren, führten die Forscher auch eine Evaluierung von InstructionGPT-4 durch. 4 und MiniGPT-4 Bildverständnis und Konversationsfähigkeiten wurden vergleichend bewertet. Die Analyse basiert auf einem eindrucksvollen Beispiel, das die Beschreibung und das weitere Verständnis des Bildes umfasst. Die Ergebnisse sind in Tabelle 6 aufgeführt. AnleitungGPT-4 ist besser darin, umfassende Bildbeschreibungen bereitzustellen und interessante Aspekte in Bildern zu identifizieren. Im Vergleich zu MiniGPT-4 ist InstructionGPT-4 besser in der Lage, in Bildern vorhandenen Text zu erkennen. Hier kann InstructionGPT-4 korrekt darauf hinweisen, dass das Bild einen Satz enthält: Montag, nur Montag.Weitere Einzelheiten finden Sie im Originalpapier. Das obige ist der detaillierte Inhalt vonNach der Auswahl von 200 Daten wurde MiniGPT-4 durch den Abgleich desselben Modells übertroffen.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!






 Unetbootin-Nutzung
Unetbootin-Nutzung
 Einführung in die Stufen der Python-Prüfungen
Einführung in die Stufen der Python-Prüfungen
 So lösen Sie das Problem, dass die Win11-Antivirensoftware nicht geöffnet werden kann
So lösen Sie das Problem, dass die Win11-Antivirensoftware nicht geöffnet werden kann
 HTML-Webseitenproduktion
HTML-Webseitenproduktion
 So runden Sie in Matlab
So runden Sie in Matlab
 So legen Sie ein PPT-Hintergrundbild fest
So legen Sie ein PPT-Hintergrundbild fest
 Was sind die Unterschiede zwischen C++ und der C-Sprache?
Was sind die Unterschiede zwischen C++ und der C-Sprache?
 Python-Entwicklungstools
Python-Entwicklungstools


![Erste Schritte mit der praktischen PHP-Entwicklung: Schnelle PHP-Erstellung [Small Business Forum]](https://img.php.cn/upload/course/000/000/035/5d27fb58823dc974.jpg)






![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



