
 Technologie-Peripheriegeräte
KI
Wird die End-to-End-Technologie im Bereich des autonomen Fahrens Frameworks wie Apollo und Autoware ersetzen?
Technologie-Peripheriegeräte
KI
Wird die End-to-End-Technologie im Bereich des autonomen Fahrens Frameworks wie Apollo und Autoware ersetzen?
Wird die End-to-End-Technologie im Bereich des autonomen Fahrens Frameworks wie Apollo und Autoware ersetzen?

Überdenken der Open-Loop-Bewertung des durchgängigen autonomen Fahrens in nuScenes
- Autoreneinheit: Baidu
- Autor: Jiang-Tian Zhai, Ze Feng, Baidu Wang Jingdong Group
- Veröffentlicht auf: arXiv
- Papierlink : https://arxiv.org/abs/2305.10430
- Code-Link: https://github.com/E2E-AD/AD-MLP
Schlüsselwörter: End-to-End-Autonomes Fahren, nuScenes-Open-Loop-Bewertung
1. Zusammenfassung
Bestehende autonome Fahrsysteme sind normalerweise in drei Hauptaufgaben unterteilt: Wahrnehmung, Vorhersage und Planung; die Planungsaufgabe umfasst die Vorhersage der Flugbahn des Fahrzeugs auf der Grundlage interner Absichten und der externen Umgebung sowie die Steuerung des Fahrzeugs. Die meisten vorhandenen Lösungen bewerten ihre Methoden anhand des nuScenes-Datensatzes. Die Bewertungsindikatoren sind L2-Fehler und Kollisionsrate. In diesem Artikel werden die vorhandenen Bewertungsindikatoren neu bewertet, um zu untersuchen, ob sie die Überlegenheit verschiedener Methoden genau messen können. In diesem Artikel wurde auch eine MLP-basierte Methode entwickelt, die rohe Sensordaten (historische Flugbahn, Geschwindigkeit usw.) als Eingabe verwendet und die zukünftige Flugbahn des Fahrzeugs direkt ausgibt, ohne Wahrnehmungs- und Vorhersageinformationen wie Kamerabilder oder LiDAR zu verwenden. Überraschenderweise: Eine so einfache Methode erreicht die SOTA-Planungsleistung für den nuScenes-Datensatz und reduziert den L2-Fehler um 30 %. Unsere weitere eingehende Analyse liefert einige neue Erkenntnisse zu Faktoren, die für Planungsaufgaben auf dem nuScenes-Datensatz wichtig sind. Unsere Beobachtungen legen auch nahe, dass wir das Open-Loop-Bewertungsschema für durchgängiges autonomes Fahren in nuScenes überdenken müssen. 2. Zweck, Beitrag und Schlussfolgerung des Artikels Es werden erweiterte Befehle verwendet (insgesamt 21-dimensionale Vektoren), die als Eingabe verwendet werden können, um Plannings SOTA auf nuScenes zu erreichen. Der Autor wies daher auf die Unzuverlässigkeit der Open-Loop-Auswertung auf nuScenes hin und lieferte zwei Analysen: Die Fahrzeugtrajektorie im nuScenes-Datensatz verläuft tendenziell gerade oder weist eine sehr geringe Krümmung auf; die Erkennung der Kollisionsrate hängt mit der Gitterdichte zusammen , und Die Kollisionsanmerkung des Datensatzes ist ebenfalls verrauscht und die aktuelle Methode zur Bewertung der Kollisionsrate ist nicht robust und genau genug;
Bestehende autonome Fahrmodelle beinhalten viele unabhängige Aufgaben wie Wahrnehmung, Vorhersage und Planung. Dieses Design vereinfacht die Schwierigkeit des teamübergreifenden Schreibens, führt jedoch aufgrund der Unabhängigkeit der Optimierung und Schulung jeder Aufgabe auch zu Informationsverlust und Fehleranhäufung im gesamten System. Es werden End-to-End-Methoden vorgeschlagen, die vom Erlernen der räumlich-zeitlichen Merkmale des eigenen Fahrzeugs und der Umgebung profitieren.Verwandte Arbeit
: ST-P3[1] schlägt ein interpretierbares visionsbasiertes End-to-End-System vor, das Feature-Learning für Wahrnehmung, Vorhersage und Planung vereint. UniAD[2] entwirft systematisch Planungsaufgaben, verwendet abfragebasiertes Design, um mehrere Zwischenaufgaben zu verbinden und kann die Beziehung zwischen mehreren Aufgaben modellieren und kodieren. Das Modul erfordert keine dichte Merkmalsdarstellung und ist rechnerisch effizienter. In diesem Artikel soll untersucht werden, ob vorhandene Bewertungsmetriken die Vor- und Nachteile verschiedener Methoden genau messen können. In diesem Artikel wird zur Durchführung von Experimenten nur der physische Zustand des Fahrzeugs während der Fahrt (eine Teilmenge der von vorhandenen Methoden verwendeten Informationen) verwendet, anstatt die von Kameras und Lidar bereitgestellten Wahrnehmungs- und Vorhersageinformationen zu verwenden. Kurz gesagt, das Modell in diesem Artikel verwendet keine visuellen oder Punktwolken-Feature-Encoder und codiert die physischen Informationen des Fahrzeugs direkt in einen eindimensionalen Vektor, der nach der Konkatierung an das MLP gesendet wird. Das Training verwendet GT-Trajektorien zur Überwachung, und das Modell sagt direkt die Trajektorienpunkte des Fahrzeugs innerhalb einer bestimmten Zeit in der Zukunft voraus. Befolgen Sie die vorherige Arbeit und verwenden Sie die L2-Fehler- und Kollisionsrate (Kollisionsrate) für die Bewertung des nuScenes-Datensatzes. Obwohl das Modelldesign einfach ist, werden die besten Planungsergebnisse erzielt. Dieser Artikel führt dies auf die Mängel der aktuellen Bewertung zurück Indikatoren. Tatsächlich kann durch die Verwendung der vergangenen Flugbahn, Geschwindigkeit, Beschleunigung und Zeitkontinuität des eigenen Fahrzeugs die zukünftige Bewegung des eigenen Fahrzeugs bis zu einem gewissen Grad widergespiegelt werden3.2 Modellstruktur
Übersicht über die Modellstruktur
Modell Die Eingabe besteht aus zwei Teilen: dem eigenen Fahrzeugstatus und übergeordneten Befehlen, die zukünftige kurzfristige Bewegungstrends darstellen. Status des eigenen Fahrzeugs: erfasst die Vergangenheit
=4 Bilder der Bewegungsbahn, der momentanen Geschwindigkeit und Beschleunigung des eigenen Fahrzeugs
Erweiterte Befehle
: Da unser Modell keine hochpräzisen Karten verwendet, sind erweiterte Befehle erforderlich werden für die Navigation benötigt. Gemäß der gängigen Praxis werden drei Arten von Befehlen definiert: nach links abbiegen, geradeaus fahren und nach rechts abbiegen. Insbesondere wenn sich das eigene Fahrzeug in den nächsten 3 Sekunden um mehr als 2 m nach links oder rechts bewegt, stellen Sie den entsprechenden Befehl zum Abbiegen nach links oder rechts ein, andernfalls fährt es geradeaus. Verwenden Sie One-Hot-Codierung mit der Dimension 1x3, um Befehle auf hoher Ebene darzustellenNetzwerkstruktur: Das Netzwerk ist ein einfaches dreischichtiges MLP (die Eingabe-zu-Ausgabe-Abmessungen betragen jeweils 21-512-512-18), die endgültige Anzahl der Ausgaberahmen = 6, jeder Rahmen gibt die Flugbahnposition des Fahrzeugs aus (x-, y-Koordinate) und Kurswinkel (Kurswinkel)
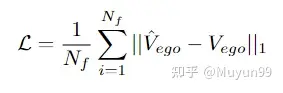
Verlustfunktion
Verlustfunktion: L1-Verlustfunktion für Strafe verwenden
4. Experimente des Papiers
4.1 Experimentelle Einstellungen
Datensatz : Experimente mit dem nuScenes-Datensatz, der aus 1.000 Szenen und etwa 40.000 Keyframes besteht, die hauptsächlich in Boston und Singapur mit Fahrzeugen gesammelt wurden, die mit LiDAR und Umfangskameras ausgestattet sind. Zu den für jedes Bild gesammelten Daten gehören Camear-Bilder mit mehreren Ansichten, LiDAR, Geschwindigkeit, Beschleunigung und mehr.
Bewertungsmetriken: Verwenden Sie den Bewertungscode des ST-P3-Papiers (https://github.com/OpenPerceptionX/ST-P3/blob/main/stp3/metrics.py). Bewerten Sie Ausgabespuren für Zeitbereiche von 1 s, 2 s und 3 s. Um die Qualität der vorhergesagten Flugbahn des eigenen Fahrzeugs zu bewerten, werden zwei häufig verwendete Indikatoren berechnet:
L2-Fehler: in Metern, berechnet zwischen der vorhergesagten Flugbahn des eigenen Fahrzeugs und der tatsächlichen Flugbahn in den nächsten 1 Sekunden, 2 Sekunden und 3 Sekunden Bereich bzw. Durchschnittlicher L2-Fehler;
Kollisionsrate: in Prozent. Um zu bestimmen, wie oft das eigene Fahrzeug mit anderen Objekten kollidiert, werden Kollisionen berechnet, indem an jedem Wegpunkt der vorhergesagten Flugbahn ein Kästchen platziert wird, das das eigene Fahrzeug darstellt, und dann ermittelt wird, ob es zu einer Kollision mit den Begrenzungsrahmen von Fahrzeugen und Fußgängern in der Flugbahn kommt aktuelle Szene.
Hyperparameter-Einstellungen und Hardware: PaddlePaddle- und PyTorch-Framework, AdamW-Optimierer (4e-6 lr und 1e-2 Gewichtsabfall), Cosinus-Scheduler, trainiert für 6 Epochen, Batch-Größe ist 4 und es wird ein V100 verwendet
4.2 Experimentelle Ergebnisse
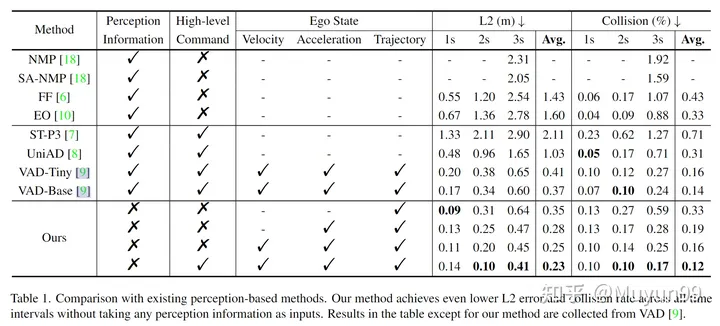
Tabelle 1 Vergleich mit vorhandenen wahrnehmungsbasierten Methoden
In Tabelle 1 wurden einige Ablationsexperimente durchgeführt. Um den Einfluss von Geschwindigkeit, Beschleunigung, Flugbahn und High-Level-Befehl auf die Leistung des Modells dieses Artikels zu analysieren. Überraschenderweise erzielt unser Basismodell bereits einen geringeren durchschnittlichen L2-Fehler als alle vorhandenen Methoden, da es nur Trajektorien als Eingabe und keine Wahrnehmungsinformationen verwendet.
Wenn wir der Eingabe schrittweise Beschleunigung, Geschwindigkeit und High-Level-Befehl hinzufügen, sinken der durchschnittliche L2-Fehler und die Kollisionsrate von 0,35 m auf 0,23 m und von 0,33 % auf 0,12 %. Das Modell, das sowohl Ego State als auch High-Level Command als Eingabe verwendet, erreicht die niedrigste L2-Fehler- und Kollisionsrate und übertrifft alle bisherigen hochmodernen wahrnehmungsbasierten Methoden, wie in der letzten Zeile gezeigt.
4.3 Experimentelle Analyse
Der Artikel analysiert die Verteilung des eigenen Fahrzeugstatus im nuScenes-Trainingssatz aus zwei Perspektiven: Flugbahnpunkte in den nächsten 3 Sekunden;
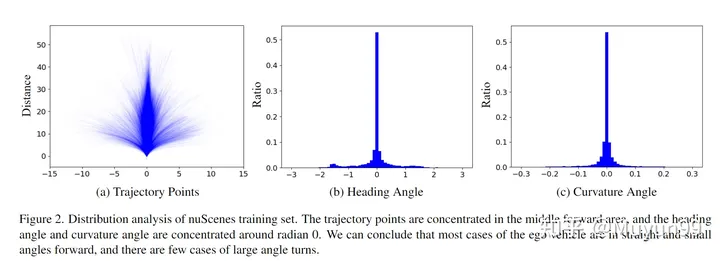
nuScenes Verteilungsanalyse des Trainingssatzes.
Alle zukünftigen 3s-Trajektorienpunkte im Trainingssatz sind in Abbildung 2(a) dargestellt. Wie aus der Abbildung ersichtlich ist, konzentriert sich die Flugbahn hauptsächlich auf den mittleren Teil (gerade) und ist hauptsächlich eine gerade Linie oder eine Kurve mit sehr geringer Krümmung.
Der Kurswinkel stellt die zukünftige Fahrtrichtung relativ zur aktuellen Zeit dar, während der Krümmungswinkel die Wendegeschwindigkeit des Fahrzeugs widerspiegelt. Wie in Abbildung 2 (b) und (c) dargestellt, liegen fast 70 % der Kurs- und Krümmungswinkel im Bereich von -0,2 bis 0,2 bzw. -0,02 bis 0,02 Bogenmaß. Dieser Befund steht im Einklang mit den Schlussfolgerungen, die aus der Flugbahnpunktverteilung gezogen werden.
Basierend auf der obigen Analyse der Verteilung von Flugbahnpunkten, Kurswinkeln und Krümmungswinkeln geht dieser Artikel davon aus, dass das eigene Fahrzeug im nuScenes-Trainingssatz dazu neigt, sich beim Fahren innerhalb des nuScenes-Trainingssatzes geradlinig und in einem kleinen Winkel vorwärts zu bewegen eine kurze Zeitspanne.
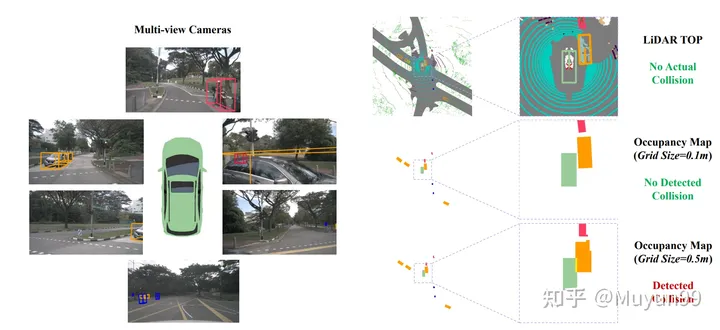
Die unterschiedlichen Rastergrößen der Belegungskarte führen zu Kollisionen in den GT-Trajektorien.
Bei der Berechnung der Kollisionsrate besteht eine gängige Praxis bei bestehenden Methoden darin, Objekte wie Fahrzeuge und Fußgänger in die Vogelperspektive (BEV) zu projizieren ) Platz und wandeln Sie sie dann in belegte Bereiche im Diagramm um. Und hier geht die Genauigkeit verloren. Wir haben festgestellt, dass ein kleiner Teil der GT-Trajektorienproben (etwa 2 %) sich auch mit Hindernissen im Belegungsraster überlappten, aber das Selbstauto kollidierte beim Sammeln tatsächlich nicht mit irgendetwas anderem data , was dazu führt, dass Kollisionen falsch erkannt werden. Verursacht falsche Kollisionen, wenn sich das Ego-Fahrzeug in der Nähe bestimmter Objekte befindet, z. B. kleiner als die Größe eines einzelnen Belegungskartenpixels.
Abbildung 3 zeigt ein Beispiel dieses Phänomens zusammen mit Kollisionserkennungsergebnissen für Ground-Truth-Trajektorien mit zwei unterschiedlichen Gittergrößen. Orange sind Fahrzeuge, die fälschlicherweise als Kollisionen erkannt werden könnten. Bei der kleineren Gittergröße (0,1 m), die in der unteren rechten Ecke angezeigt wird, identifiziert das Auswertungssystem die GT-Trajektorie korrekt als nicht kollidierend, bei der größeren Gittergröße unten rechts jedoch Ecke (0,5 m) kommt es zu einer falschen Kollisionserkennung.
Nachdem wir den Einfluss der besetzten Gittergröße auf die Erkennung von Flugbahnkollisionen beobachtet hatten, testeten wir eine Gittergröße von 0,6 m. Der nuScenes-Trainingssatz hat 4,8 % Kollisionsproben, während der Validierungssatz 3,0 % hat. Es ist erwähnenswert, dass bei der vorherigen Verwendung einer Gittergröße von 0,5 m nur 2,0 % der Stichproben im Validierungssatz fälschlicherweise als Kollisionen klassifiziert wurden. Dies zeigt einmal mehr, dass aktuelle Methoden zur Schätzung von Kollisionsraten nicht robust und genau genug sind.
Zusammenfassung des Autors: Der Hauptzweck dieses Papiers besteht darin, unsere Beobachtungen darzustellen und nicht, ein neues Modell vorzuschlagen. Obwohl unser Modell im nuScenes-Datensatz gut funktioniert, erkennen wir an, dass es sich um ein unpraktisches Spielzeug handelt, das in der realen Welt nicht verwendet werden kann. Fahren ohne eigenen Fahrzeugstatus ist eine unüberwindbare Herausforderung. Dennoch hoffen wir, dass unsere Erkenntnisse die weitere Forschung in diesem Bereich anregen und eine Neubewertung der Fortschritte beim durchgängig autonomen Fahren ermöglichen werden.
5. Artikelbewertung
Dieser Artikel ist ein ausführlicher Überblick über die aktuelle End-to-End-Bewertung des autonomen Fahrens im nuScenes-Datensatz. Unabhängig davon, ob es sich um eine implizite End-to-End-Direktausgabe von Planungssignalen oder eine explizite End-to-End-Ausgabe mit Zwischenverbindungen handelt, handelt es sich bei vielen davon um Planungsindikatoren, die anhand des nuScenes-Datensatzes ausgewertet werden. In Baidus Artikel wurde auf diese Art der Auswertung hingewiesen ist nicht zuverlässig. Diese Art von Artikel ist eigentlich sehr interessant, wenn er veröffentlicht wird, aber er fördert auch aktiv die Weiterentwicklung der Branche. Vielleicht ist keine umfassende Planung erforderlich Ende-zu-Ende), vielleicht jeder. Die Durchführung weiterer Closed-Loop-Tests (CARLA-Simulator usw.) bei der Leistungsbewertung kann den Fortschritt der autonomen Fahrgemeinschaft besser fördern und das Papier in tatsächliche Fahrzeuge umsetzen. Der Weg zum autonomen Fahren hat noch einen langen Weg vor sich
^VAD: Vektorisierte Szenendarstellung für effizientes autonomes Fahren
- Originallink: https://mp.weixin.qq.com/s/skNDMk4B1rtvJ_o2CM9f8w
Das obige ist der detaillierte Inhalt vonWird die End-to-End-Technologie im Bereich des autonomen Fahrens Frameworks wie Apollo und Autoware ersetzen?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Was ist das Modellkontextprotokoll (MCP)?
Mar 03, 2025 pm 07:09 PM
Was ist das Modellkontextprotokoll (MCP)?
Mar 03, 2025 pm 07:09 PM
Das Modellkontextprotokoll (MCP): ein universeller Anschluss für KI und Daten Wir alle vertraut mit der Rolle von AI bei der täglichen Codierung. Replit, Github Copilot, Black Box AI und Cursor IDE sind nur einige Beispiele dafür, wie KI unsere Workflows optimiert. Aber stell dir vor
 Aufbau eines lokalen Vision Agents mit Omniparser V2 und Omnitool
Mar 03, 2025 pm 07:08 PM
Aufbau eines lokalen Vision Agents mit Omniparser V2 und Omnitool
Mar 03, 2025 pm 07:08 PM
Microsoft's Omniparser V2 und Omnitool: Revolutionierung der GUI -Automatisierung mit KI Stellen Sie sich AI vor, das nicht nur versteht, sondern auch mit Ihrer Windows 11 -Oberfläche wie ein erfahrener Profi interagiert. Microsofts Omniparser V2 und Omnitool machen dies zu einer Re
 Replit Agent: Ein Leitfaden mit praktischen Beispielen
Mar 04, 2025 am 10:52 AM
Replit Agent: Ein Leitfaden mit praktischen Beispielen
Mar 04, 2025 am 10:52 AM
Revolutionierung der App -Entwicklung: Ein tiefes Eintauchen in den Replit Agent Müde, mit komplexen Entwicklungsumgebungen und dunklen Konfigurationsdateien zu ringen? Replit Agent zielt darauf ab, den Prozess der Umwandlung von Ideen in funktionale Apps zu vereinfachen. Diese AI-P
 Ich habe versucht, die Vibe -Codierung mit Cursor AI und es ist erstaunlich!
Mar 20, 2025 pm 03:34 PM
Ich habe versucht, die Vibe -Codierung mit Cursor AI und es ist erstaunlich!
Mar 20, 2025 pm 03:34 PM
Die Vibe -Codierung verändert die Welt der Softwareentwicklung, indem wir Anwendungen mit natürlicher Sprache anstelle von endlosen Codezeilen erstellen können. Inspiriert von Visionären wie Andrej Karpathy, lässt dieser innovative Ansatz Dev
 Runway Act-One Guide: Ich habe mich gefilmt, um es zu testen
Mar 03, 2025 am 09:42 AM
Runway Act-One Guide: Ich habe mich gefilmt, um es zu testen
Mar 03, 2025 am 09:42 AM
Dieser Blog-Beitrag teilt mit meiner Erfahrung mit dem neuen Animation-Tool von Runway ML von ML und dem Deckung sowohl der Weboberfläche als auch der Python-API. Während der Versprechen waren meine Ergebnisse weniger beeindruckend als erwartet. Möchten Sie generative KI erkunden? Lernen Sie, LLMs in p zu verwenden
 Top 5 Genai Starts vom Februar 2025: GPT-4,5, GROK-3 & MEHR!
Mar 22, 2025 am 10:58 AM
Top 5 Genai Starts vom Februar 2025: GPT-4,5, GROK-3 & MEHR!
Mar 22, 2025 am 10:58 AM
Februar 2025 war ein weiterer bahnbrechender Monat für die Generative KI, die uns einige der am meisten erwarteten Modell-Upgrades und bahnbrechenden neuen Funktionen gebracht hat. Von Xais Grok 3 und Anthropics Claude 3.7 -Sonett, um g zu eröffnen
 Wie benutze ich Yolo V12 zur Objekterkennung?
Mar 22, 2025 am 11:07 AM
Wie benutze ich Yolo V12 zur Objekterkennung?
Mar 22, 2025 am 11:07 AM
Yolo (Sie schauen nur einmal) war ein führender Echtzeit-Objekterkennungsrahmen, wobei jede Iteration die vorherigen Versionen verbessert. Die neueste Version Yolo V12 führt Fortschritte vor, die die Genauigkeit erheblich verbessern
 Elon Musk & Sam Altman kämpfen über 500 Milliarden US -Dollar Stargate -Projekt
Mar 08, 2025 am 11:15 AM
Elon Musk & Sam Altman kämpfen über 500 Milliarden US -Dollar Stargate -Projekt
Mar 08, 2025 am 11:15 AM
Das 500 -Milliarden -Dollar -Stargate AI -Projekt, das von Tech -Giganten wie Openai, Softbank, Oracle und Nvidia unterstützt und von der US -Regierung unterstützt wird, zielt darauf ab, die amerikanische KI -Führung zu festigen. Dieses ehrgeizige Unternehmen verspricht eine Zukunft, die von AI Advanceme geprägt ist
