
 System-Tutorial
LINUX
Verwendung von Netlink für die Kommunikation zwischen Userspace und Kernelspace
System-Tutorial
LINUX
Verwendung von Netlink für die Kommunikation zwischen Userspace und Kernelspace
Verwendung von Netlink für die Kommunikation zwischen Userspace und Kernelspace


Im Jahr 2001 führte das ForCES IETF-Komitee offiziell Standardisierungsarbeiten für Netlink durch. Jamal Hadi Salim schlug vor, Netlink als Protokoll für die Kommunikation zwischen der Routing-Engine-Komponente eines Netzwerkgeräts und seiner Steuerungs- und Verwaltungskomponente zu definieren. Sein Vorschlag wurde jedoch letztendlich nicht angenommen und durch das Muster ersetzt, das wir heute sehen: Netlink wurde als neue Protokolldomäne, Domäne, konzipiert.
Tobas, der Vater von Linux, sagte einmal: „Linux ist Evolution, nicht intelligentes Design.“ Was ist die Bedeutung? Mit anderen Worten, Netlink folgt auch bestimmten Designkonzepten von Linux, das heißt, es gibt kein vollständiges Spezifikationsdokument oder Designdokument. Was genau? Sie wissen schon: „Lesen Sie den verdammten Quellcode“.
Natürlich geht es in diesem Artikel nicht darum, den Implementierungsmechanismus von Netlink unter Linux zu analysieren, sondern um die Themen „Was ist Netlink“ und „Wie nutzt man Netlink sinnvoll?“ Sie müssen nur die Kernel-Quelle lesen Code, wenn Sie auf Probleme stoßen. Finden Sie heraus, warum.
Was ist Netlink? Um Netlink zu verstehen, müssen Sie mehrere wichtige Punkte verstehen:1. Verbindungsloses Messaging-Subsystem für Datagramme
2. Implementiert auf Basis der gängigen BSD-Socket-Architektur
Was den ersten Punkt betrifft, fällt es uns leicht, an das UDP-Protokoll zu denken. Es ist nicht unvernünftig, Netlink auf der Grundlage des UDP-Protokolls zu verstehen. Solange Sie Parallelen ziehen und durch Analogie lernen können, gut im Zusammenfassen und Verknüpfen sind und schließlich den Wissenstransfer realisieren können, ist dies die Essenz des Lernens. Netlink kann eine bidirektionale und asynchrone Datenkommunikation zwischen Kernel->Benutzer und Benutzer->Kernel realisieren. Es unterstützt auch die Datenkommunikation zwischen zwei Benutzerprozessen und sogar zwischen zwei Kernel-Subsystemen. In diesem Artikel werden wir die beiden letztgenannten nicht berücksichtigen und uns darauf konzentrieren, wie die Datenkommunikation zwischen Benutzern <-> implementiert wird.
Als Sie den zweiten Punkt gesehen haben, ist Ihnen folgendes Bild in den Sinn gekommen? Wenn ja, bedeutet das natürlich, dass Sie die Wurzel der Weisheit haben; wenn nicht, spielt das keine Rolle, die Wurzel der Weisheit kann langsam wachsen, haha.
Wir werden hauptsächlich socket(), bind(), sendmsg() verwenden, wenn wir später die Netlink-Socket-Programmierung üben
Systemaufrufe wie
und recvmsg() und natürlich der von Socket bereitgestellte Polling-Mechanismus.Netlink-Kommunikationstyp Netlink unterstützt zwei Arten von Kommunikationsmethoden: Unicast und Multicast.
Unicast: Wird häufig für die 1:1-Datenkommunikation zwischen einem Benutzerprozess und einem Kernel-Subsystem verwendet. Der Benutzerbereich sendet Befehle an den Kernel und empfängt dann die Ergebnisse der Befehle vom Kernel.
Multicast: Wird häufig für die 1:N-Datenkommunikation zwischen einem Kernelprozess und mehreren Benutzerprozessen verwendet. Der Kernel fungiert als Initiator der Sitzung und die User-Space-Anwendung ist der Empfänger. Um diese Funktion zu erreichen, erstellt das Kernel-Space-Programm eine Multicast-Gruppe. Anschließend treten alle Benutzerspace-Prozesse, die an den vom Kernel-Prozess gesendeten Nachrichten interessiert sind, der Gruppe bei, um vom Kernel gesendete Nachrichten zu empfangen. Wie folgt:
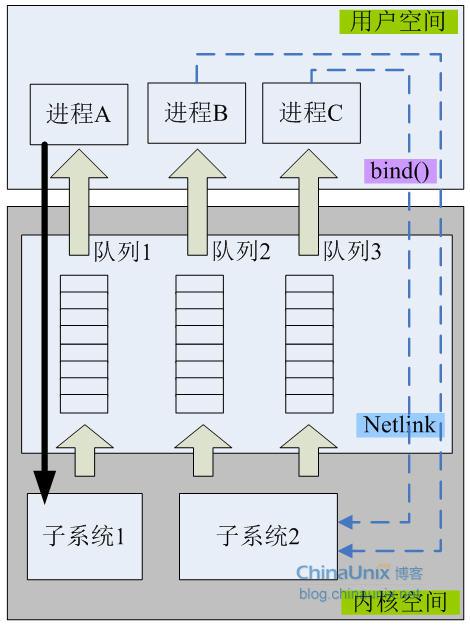
Netlink-Nachrichtenformat Netlink-Nachricht besteht aus zwei Teilen: Nachrichtenkopf und Nutzlast, und die gesamte Netlink-Nachricht ist 4-Byte-ausgerichtet und wird im Allgemeinen in der Host-Byte-Reihenfolge übertragen. Der Nachrichtenkopf ist auf 16 Byte festgelegt und die Länge des Nachrichtentexts ist variabel:

Klicken Sie (hier), um es zu verkleinern oder zu öffnen
- struct nlmsghdr
- {
- __u32 nlmsg_len; /* Länge der Nachricht inklusive Header */
- __u16 nlmsg_type; /* Nachrichteninhalt */
- __u16 nlmsg_flags; /* Zusätzliche Flags */
- __u32 nlmsg_seq; /* Sequenznummer */
- __u32 nlmsg_pid; /* Sendeprozess-PID */
- };
nlmsg_len: Die Länge der gesamten Nachricht in Bytes. Enthält den Netlink-Nachrichtenheader selbst.
nlmsg_type: Der Nachrichtentyp, d. h. ob es sich um eine Daten- oder Steuernachricht handelt. Derzeit (Kernel-Version 2.6.21) unterstützt Netlink nur vier Arten von Kontrollnachrichten:
NLMSG_NOOP – leere Nachricht, nichts tun
NLMSG_ERROR – Zeigt an, dass die Nachricht einen Fehler enthält
NLMSG_DONE – Wenn der Kernel mehrere Nachrichten über die Netlink-Warteschlange zurückgibt, ist die letzte Nachricht in der Warteschlange vom Typ NLMSG_DONE und für das nlmsg_flags-Attribut aller verbleibenden Nachrichten ist das NLM_F_MULTI-Bit auf gültig gesetzt.
NLMSG_OVERRUN – Noch nicht verwendet.
nlmsg_flags: Zusätzliche beschreibende Informationen, die an die Nachricht angehängt sind, wie z. B. das oben erwähnte NLM_F_MULTI. Der Auszug lautet wie folgt:
Solange Sie wissen, dass nlmsg_flags mehrere Werte hat, können Sie die Antwort auf die Rolle und Bedeutung jedes Werts definitiv über Google und den Quellcode finden, daher werde ich hier nicht auf Details eingehen. Alle Werte im vorherigen Kernel 2.6.21:

nlmsg_seq: Nachrichtensequenznummer. Da Netlink auf Datagramme ausgerichtet ist, besteht die Gefahr eines Datenverlusts. Netlink bietet jedoch einen Mechanismus, der sicherstellt, dass Nachrichten nicht verloren gehen, sodass Programmentwickler ihn entsprechend ihren tatsächlichen Anforderungen implementieren können. Nachrichtensequenznummern werden im Allgemeinen in Verbindung mit Nachrichten vom Typ NLM_F_ACK verwendet. Wenn die Anwendung des Benutzers sicherstellen muss, dass jede von ihr gesendete Nachricht erfolgreich vom Kernel empfangen wird, muss das Benutzerprogramm die Sequenznummer beim Senden der Nachricht selbst festlegen Der Kernel empfängt die Nachricht, extrahiert dann die Seriennummer und legt dann dieselbe Seriennummer in der an das Benutzerprogramm gesendeten Antwortnachricht fest. Etwas ähnlich dem Antwort- und Bestätigungsmechanismus von TCP.
Hinweis: Wenn der Kernel aktiv eine Broadcast-Nachricht an den Benutzerbereich sendet, ist dieses Feld in der Nachricht immer 0.
nlmsg_pid: Wenn über Netlink ein Datenaustauschkanal zwischen einem User-Space-Prozess und einem bestimmten Subsystem im Kernel-Space eingerichtet wird, weist Netlink jedem dieser Kanäle eine eindeutige digitale Identifikation zu. Seine Hauptfunktion besteht darin, Anforderungsnachrichten und Antwortnachrichten aus dem Benutzerbereich zu korrelieren. Um es ganz klar auszudrücken: Wenn es mehrere Benutzerprozesse im Benutzerbereich und mehrere Prozesse im Kernelbereich gibt, muss Netlink einen Mechanismus bereitstellen, um sicherzustellen, dass die Dateninteraktion zwischen jedem Paar von „Benutzer-Kernel“-Raumkommunikationsprozessen konsistent ist.
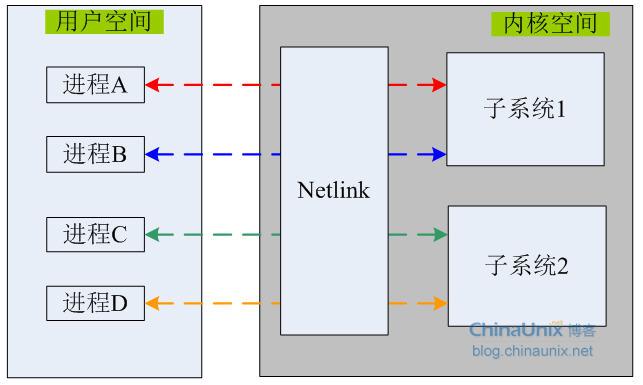
Das heißt, wenn die Prozesse A und B über Netlink Informationen von Subsystem 1 erhalten, muss Subsystem 1 sicherstellen, dass die an Prozess A zurückgesendeten Antwortdaten nicht an Prozess B gesendet werden. Es eignet sich hauptsächlich für Szenarien, in denen Benutzerraumprozesse Daten aus dem Kernelraum abrufen. Wenn ein User-Space-Prozess eine Nachricht an den Kernel sendet, weist er dieser Variablen normalerweise über den Systemaufruf getpid() die Prozess-ID des aktuellen Prozesses zu eine Antwort vom Kernel erhalten. Dieses Feld wird für Nachrichten, die aktiv vom Kernel an den Benutzerbereich gesendet werden, auf 0 gesetzt.
Netlink-NachrichtentextDer Nachrichtentext von Netlink verwendet das TLV-Format (Type-Length-Value):
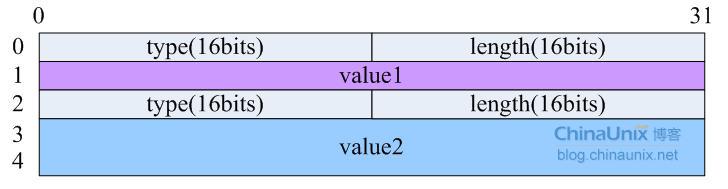
Jedes Attribut von Netlink wird durch struct nlattr{} in der Datei

Von Netlink bereitgestellte Fehlermeldung
Inhalt Wenn während der Kommunikation zwischen User-Space-Anwendungen und Kernel-Space-Prozessen über Netlink ein Fehler auftritt, muss Netlink den User-Space über solche Fehler informieren. Netlink kapselt die Fehlermeldung separat,Klicken Sie (hier), um es zu verkleinern oder zu öffnen
- struct nlmsgerr
- {
- int error; //Standardfehlercode, definiert in der Header-Datei errno.h. Es kann mit perror()
- erklärt werden struct nlmsghdr msg; //Gibt an, welche Nachricht den Fehlerwert in der Struktur ausgelöst hat
- };
1. Speicher erschöpft;
2. Pufferüberlauf im User-Space-Empfangsprozess. Die Hauptgründe für einen Pufferüberlauf können sein: Der User-Space-Prozess läuft zu langsam oder die Empfangswarteschlange ist zu kurz.
Wenn Netlink die Nachricht nicht korrekt an den empfangenden Prozess im Benutzerbereich übermitteln kann, gibt der empfangende Prozess im Benutzerbereich beim Aufruf des Systemaufrufs recvmsg() einen Fehler wegen unzureichendem Arbeitsspeicher zurück. Mit anderen Worten, die Pufferüberlaufsituation wird nicht im sendmsg()-Systemaufruf von user->kernel gesendet. Bitte denken Sie selbst darüber nach.
Wenn die Socket-Kommunikation blockiert wird, besteht natürlich keine versteckte Gefahr einer Speichererschöpfung. Warum ist das so? Gehen Sie schnell zu Google und schauen Sie nach, was ein blockierender Socket ist. Wenn Sie ohne nachzudenken lernen, werden Sie vergeblich sein; wenn Sie ohne zu lernen denken, werden Sie in Gefahr sein.
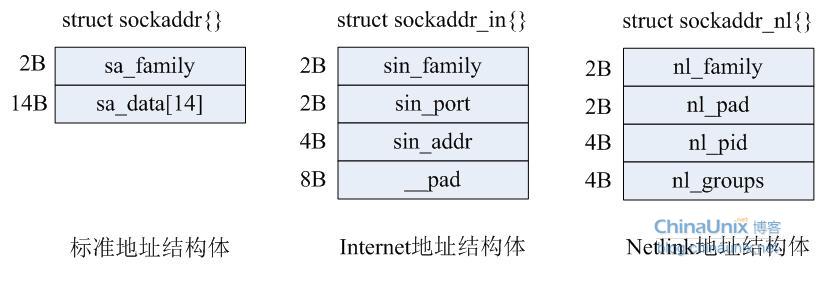
Netlink-AdressstrukturIm TCP-Blogbeitrag haben wir die im Internetprogrammierungsprozess verwendete Adressstruktur und Standardadressstruktur erwähnt. Ihre Beziehung zur Netlink-Adressstruktur ist wie folgt:
Die detaillierte Definition und Beschreibung von struct sockaddr_nl{} lautet wie folgt:
Klicken Sie (hier), um es zu verkleinern oder zu öffnen
- struct sockaddr_nl
- {
- sa_family_t nl_family; /*Dieses Feld ist immer AF_NETLINK */
- unsigned short nl_pad; /* Derzeit nicht verwendet, gefüllt mit 0*/
- __u32 nl_pid; /* Prozess-PID */
- __u32 nl_groups; /* Multicast-Gruppenmaske */
- };
nl_pid: Dieses Attribut ist die Prozess-ID zum Senden oder Empfangen von Nachrichten. Netlink kann nicht nur die Benutzer-Kernel-Raumkommunikation realisieren, sondern auch die Echtzeitkommunikation zwischen zwei Prozessen im Benutzerraum oder zwischen zwei Prozessen in ermöglichen Kernelraumkommunikation. Wenn dieses Attribut 0 ist, gilt es im Allgemeinen für die folgenden zwei Situationen:
Erstens ist das Ziel, das wir senden möchten, der Kernel. Wenn wir also vom Benutzerbereich zum Kernelbereich senden, wird nl_pid in der von uns erstellten Netlink-Adressstruktur normalerweise auf 0 gesetzt. Eine Sache, die ich Ihnen hier erklären muss, ist, dass in der Netlink-Spezifikation der vollständige Name der PID Port-ID (32 Bit) lautet und ihre Hauptfunktion darin besteht, einen Netlink-basierten Socket-Kanal eindeutig zu identifizieren. Normalerweise wird nl_pid auf die Prozess-ID des aktuellen Prozesses gesetzt. Für den Fall, dass mehrere Threads eines Prozesses jedoch gleichzeitig den Netlink-Socket verwenden, wird die Einstellung von nl_pid im Allgemeinen wie folgt implementiert:
Klicken Sie (hier), um es zu verkleinern oder zu öffnen
- pthread_self() << 16 |
nl_groups: Wenn ein User-Space-Prozess einer Multicast-Gruppe beitreten möchte, muss er den Systemaufruf bind() ausführen. Dieses Feld gibt die
Maske der Multicast-Gruppennummer an, der der Anrufer beitreten möchte (beachten Sie, dass es sich nicht um die Gruppennummer handelt, wir werden dieses Feld später im Detail erklären). Wenn dieses Feld 0 ist, bedeutet dies, dass der Anrufer keiner Multicast-Gruppe beitreten möchte. Für jedes Protokoll, das zur Netlink-Protokolldomäne gehört, können bis zu 32 Multicast-Gruppen unterstützt werden (da die Länge von nl_groups 32 Bit beträgt), und jede Multicast-Gruppe wird durch ein Bit dargestellt.
Was die verbleibenden Wissenspunkte von Netlink betrifft, werden wir sie später besprechen, wenn sie in praktischen Sitzungen nützlich sind.Noch nicht fertig, Fortsetzung folgt...
Das obige ist der detaillierte Inhalt vonVerwendung von Netlink für die Kommunikation zwischen Userspace und Kernelspace. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Wofür ist Linux eigentlich gut?
Apr 12, 2025 am 12:20 AM
Wofür ist Linux eigentlich gut?
Apr 12, 2025 am 12:20 AM
Linux eignet sich für Server, Entwicklungsumgebungen und eingebettete Systeme. 1. Als Serverbetriebssystem ist Linux stabil und effizient und wird häufig zur Bereitstellung von Anwendungen mit hoher Konreise verwendet. 2. Als Entwicklungsumgebung bietet Linux effiziente Befehlszeilen -Tools und Paketmanagementsysteme, um die Entwicklungseffizienz zu verbessern. 3. In eingebetteten Systemen ist Linux leicht und anpassbar und für Umgebungen mit begrenzten Ressourcen geeignet.
 Verwenden von Docker mit Linux: eine umfassende Anleitung
Apr 12, 2025 am 12:07 AM
Verwenden von Docker mit Linux: eine umfassende Anleitung
Apr 12, 2025 am 12:07 AM
Die Verwendung von Docker unter Linux kann die Entwicklung und die Bereitstellungseffizienz verbessern. 1. Installieren Sie Docker: Verwenden Sie Skripte, um Docker auf Ubuntu zu installieren. 2. Überprüfen Sie die Installation: Führen Sie die Sudodockerrunhello-Welt aus. 3. Basisnutzung: Erstellen Sie einen Nginx-Container-Dockerrun-Namemy-Nginx-P8080: 80-DNGinx. 4. Erweiterte Verwendung: Erstellen Sie ein benutzerdefiniertes Bild, erstellen und führen Sie mit Dockerfile aus. 5. Optimierung und Best Practices: Befolgen Sie Best Practices zum Schreiben von Dockerfiles mit mehrstufigen Builds und DockerComponpose.
 So starten Sie Apache
Apr 13, 2025 pm 01:06 PM
So starten Sie Apache
Apr 13, 2025 pm 01:06 PM
Die Schritte zum Starten von Apache sind wie folgt: Installieren Sie Apache (Befehl: sudo apt-Get-Get-Installieren Sie Apache2 oder laden Sie ihn von der offiziellen Website herunter). (Optional, Linux: sudo systemctl
 Was tun, wenn der Port Apache80 belegt ist
Apr 13, 2025 pm 01:24 PM
Was tun, wenn der Port Apache80 belegt ist
Apr 13, 2025 pm 01:24 PM
Wenn der Port -80 -Port der Apache 80 besetzt ist, lautet die Lösung wie folgt: Finden Sie den Prozess, der den Port einnimmt, und schließen Sie ihn. Überprüfen Sie die Firewall -Einstellungen, um sicherzustellen, dass Apache nicht blockiert ist. Wenn die obige Methode nicht funktioniert, konfigurieren Sie Apache bitte so, dass Sie einen anderen Port verwenden. Starten Sie den Apache -Dienst neu.
 So beginnen Sie mit der Überwachung von Oracle
Apr 12, 2025 am 06:00 AM
So beginnen Sie mit der Überwachung von Oracle
Apr 12, 2025 am 06:00 AM
Die Schritte zum Starten eines Oracle -Listeners sind wie folgt: Überprüfen
 So überwachen Sie die NGINX SSL -Leistung auf Debian
Apr 12, 2025 pm 10:18 PM
So überwachen Sie die NGINX SSL -Leistung auf Debian
Apr 12, 2025 pm 10:18 PM
In diesem Artikel wird beschrieben, wie die SSL -Leistung von NGINX -Servern auf Debian -Systemen effektiv überwacht wird. Wir werden Nginxexporter verwenden, um Nginx -Statusdaten in Prometheus zu exportieren und sie dann visuell über Grafana anzeigen. Schritt 1: Konfigurieren von Nginx Erstens müssen wir das Modul stub_status in der nginx -Konfigurationsdatei aktivieren, um die Statusinformationen von Nginx zu erhalten. Fügen Sie das folgende Snippet in Ihre Nginx -Konfigurationsdatei hinzu (normalerweise in /etc/nginx/nginx.conf oder deren inklusive Datei): location/nginx_status {stub_status
 So richten Sie im Debian -System einen Recyclingbehälter ein
Apr 12, 2025 pm 10:51 PM
So richten Sie im Debian -System einen Recyclingbehälter ein
Apr 12, 2025 pm 10:51 PM
In diesem Artikel werden zwei Methoden zur Konfiguration eines Recycling -Bin in einem Debian -System eingeführt: eine grafische Schnittstelle und eine Befehlszeile. Methode 1: Verwenden Sie die grafische Schnittstelle Nautilus, um den Dateimanager zu öffnen: Suchen und starten Sie den Nautilus -Dateimanager (normalerweise als "Datei") im Menü Desktop oder Anwendungen. Suchen Sie den Recycle Bin: Suchen Sie nach dem Ordner recycelner Behälter in der linken Navigationsleiste. Wenn es nicht gefunden wird, klicken Sie auf "Andere Speicherort" oder "Computer", um sie zu suchen. Konfigurieren Sie Recycle Bin-Eigenschaften: Klicken Sie mit der rechten Maustaste auf "Recycle Bin" und wählen Sie "Eigenschaften". Im Eigenschaftenfenster können Sie die folgenden Einstellungen einstellen: Maximale Größe: Begrenzen Sie den im Recycle -Behälter verfügbaren Speicherplatz. Aufbewahrungszeit: Legen Sie die Erhaltung fest, bevor die Datei automatisch im Recyclingbehälter gelöscht wird
 So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
So optimieren Sie die Leistung von Debian Readdir
Apr 13, 2025 am 08:48 AM
In Debian -Systemen werden Readdir -Systemaufrufe zum Lesen des Verzeichnisinhalts verwendet. Wenn seine Leistung nicht gut ist, probieren Sie die folgende Optimierungsstrategie aus: Vereinfachen Sie die Anzahl der Verzeichnisdateien: Teilen Sie große Verzeichnisse so weit wie möglich in mehrere kleine Verzeichnisse auf und reduzieren Sie die Anzahl der gemäß Readdir -Anrufe verarbeiteten Elemente. Aktivieren Sie den Verzeichnis -Inhalt Caching: Erstellen Sie einen Cache -Mechanismus, aktualisieren Sie den Cache regelmäßig oder bei Änderungen des Verzeichnisinhalts und reduzieren Sie häufige Aufrufe an Readdir. Speicher -Caches (wie Memcached oder Redis) oder lokale Caches (wie Dateien oder Datenbanken) können berücksichtigt werden. Nehmen Sie eine effiziente Datenstruktur an: Wenn Sie das Verzeichnis -Traversal selbst implementieren, wählen Sie effizientere Datenstrukturen (z.
