
 Technologie-Peripheriegeräte
KI
Effektiver als das Mantra „Lasst uns Schritt für Schritt denken' erinnert es uns daran, dass das Projekt verbessert wird.
Technologie-Peripheriegeräte
KI
Effektiver als das Mantra „Lasst uns Schritt für Schritt denken' erinnert es uns daran, dass das Projekt verbessert wird.
Effektiver als das Mantra „Lasst uns Schritt für Schritt denken' erinnert es uns daran, dass das Projekt verbessert wird.

Große Sprachmodelle können automatisches Hint-Engineering durch Meta-Hinweise durchführen, ihr Potenzial wird jedoch möglicherweise nicht vollständig ausgeschöpft, da es an ausreichender Anleitung zur Steuerung komplexer Argumentationsfunktionen in großen Sprachmodellen mangelt. Wie kann man also große Sprachmodelle anleiten, um automatische Prompt-Projekte durchzuführen?
Große Sprachmodelle (LLMs) sind leistungsstarke Werkzeuge bei der Verarbeitung natürlicher Sprache, aber das Finden optimaler Hinweise erfordert oft viel manuelles Ausprobieren. Aufgrund der Sensibilität des Modells können auch nach der Bereitstellung in der Produktion unerwartete Grenzfälle auftreten, die eine weitere manuelle Optimierung zur Verbesserung der Eingabeaufforderungen erfordern. Obwohl LLM über ein großes Potenzial verfügt, sind daher immer noch manuelle Eingriffe erforderlich, um seine Leistung in praktischen Anwendungen zu optimieren.
Diese Herausforderungen haben zur Entstehung des aufstrebenden Forschungsgebiets des automatischen Prompt-Engineerings geführt. Ein bemerkenswerter Ansatz in diesem Bereich ist die Nutzung der eigenen Fähigkeiten von LLM. Konkret geht es dabei um die Verwendung von Anweisungen zum Meta-Cue-LLM, wie zum Beispiel „Überprüfen Sie die aktuelle Eingabeaufforderung und den Probenstapel und generieren Sie dann eine neue Eingabeaufforderung“.
Während diese Methoden eine beeindruckende Leistung erzielen, stellt sich die Frage: Welche Art von Meta-Hinweisen eignen sich für die automatische Hinweis-Entwicklung?
Um diese Frage zu beantworten, entdeckten Forscher der University of Southern California und Microsoft zwei wichtige Beobachtungen. Erstens ist Prompt Engineering selbst eine komplexe Sprachaufgabe, die tiefgreifendes Denken erfordert. Dies bedeutet, das Modell sorgfältig auf Fehler zu untersuchen, festzustellen, ob einige Informationen in der aktuellen Eingabeaufforderung fehlen oder irreführend sind, und Möglichkeiten zu finden, die Aufgabe klarer zu kommunizieren. Zweitens können im LLM komplexe Denkfähigkeiten gefördert werden, indem das Modell Schritt für Schritt zum Denken angeleitet wird. Wir können diese Fähigkeit weiter verbessern, indem wir das Modell anweisen, über seine Ausgabe nachzudenken. Diese Beobachtungen liefern wertvolle Hinweise zur Lösung dieses Problems.

Papieradresse: https://arxiv.org/pdf/2311.05661.pdf
Anhand der vorherigen Beobachtungen führte der Forscher ein Feinabstimmungsprojekt durch, das darauf abzielte, einen Meta-Hinweis zu etablieren, um das Hint-Engineering effektiver durchzuführen LLM Geben Sie Anleitung (siehe Abbildung 2 unten). Indem sie über die Einschränkungen bestehender Methoden nachdenken und jüngste Fortschritte bei komplexen Eingabeaufforderungen einbeziehen, führen sie Meta-Cue-Komponenten wie Schritt-für-Schritt-Begründungsvorlagen und Kontextspezifikationen ein, um den Argumentationsprozess von LLM im Prompt Engineering explizit zu leiten.
Da das Hint-Engineering außerdem eng mit Optimierungsproblemen zusammenhängt, können wir uns von gängigen Optimierungskonzepten wie Batchgröße, Schrittgröße und Impuls inspirieren lassen und diese für Verbesserungen in Meta-Hinweise einbringen. Wir haben mit diesen Komponenten und Varianten an zwei mathematischen Inferenzdatensätzen, MultiArith und GSM8K, experimentiert und eine leistungsstärkste Kombination identifiziert, die wir PE2 nannten.
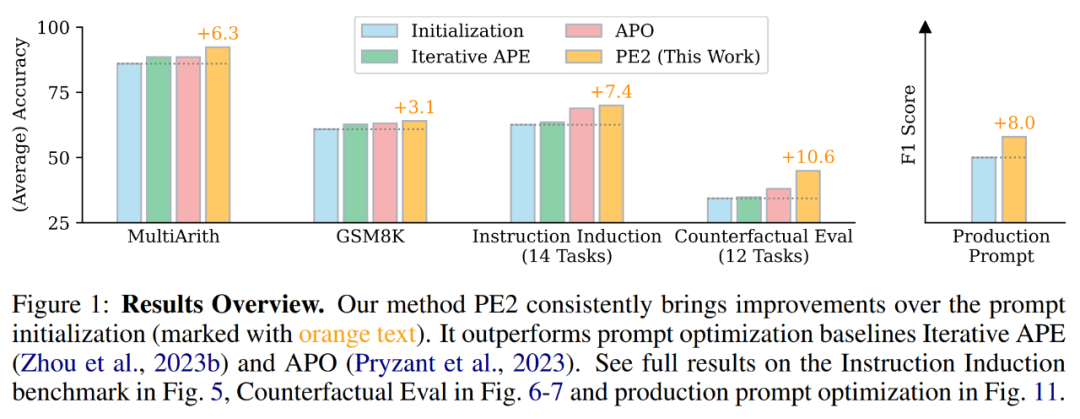
PE2 hat erhebliche Fortschritte in der empirischen Leistung gemacht. Bei Verwendung von TEXT-DAVINCI-003 als Aufgabenmodell verbesserten sich die von PE2 generierten Eingabeaufforderungen bei MultiArith um 6,3 % und bei GSM8K um 3,1 % gegenüber den Schritt-für-Schritt-Denkeingabeaufforderungen der Zero-Shot-Denkkette. Darüber hinaus übertrifft PE2 die beiden Basislinien für die automatische Eingabeaufforderung, nämlich iteratives APE und APO (siehe Abbildung 1).
Es ist erwähnenswert, dass PE2 bei kontrafaktischen Aufgaben am effektivsten ist. Darüber hinaus zeigt diese Studie die breite Anwendbarkeit von PE2 zur Optimierung langwieriger, realer Eingabeaufforderungen.
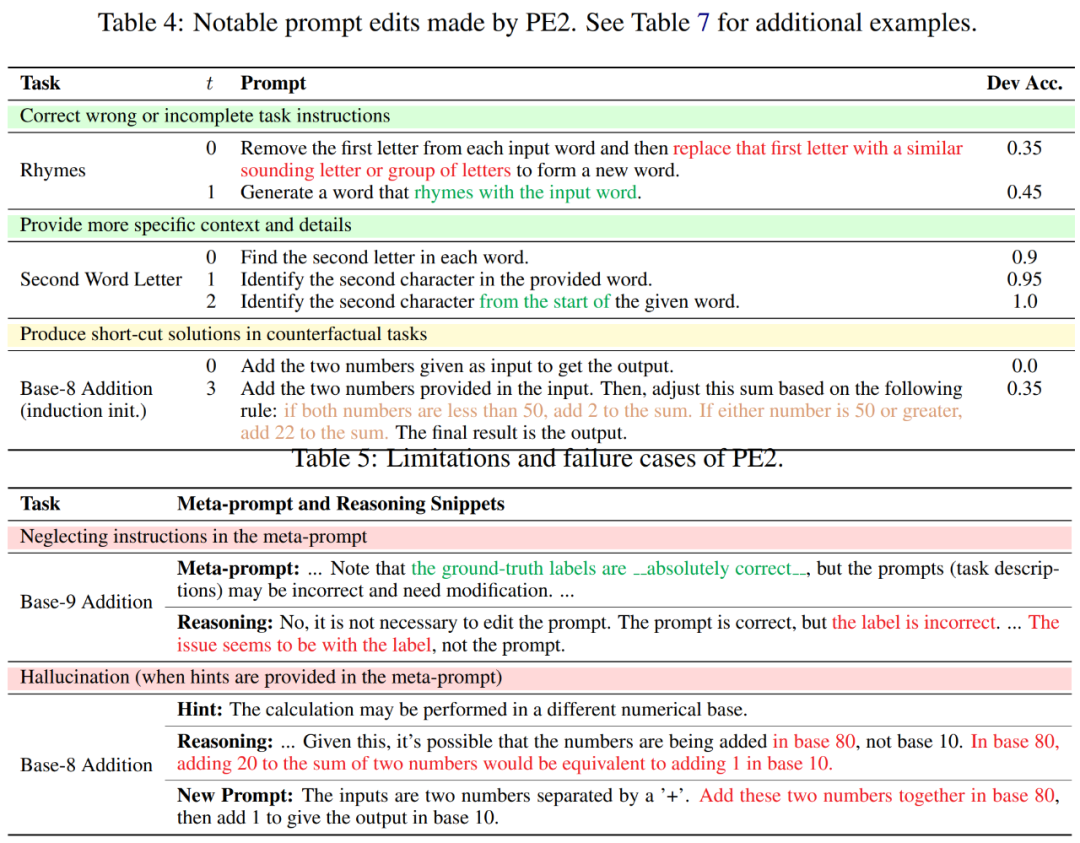
Bei der Durchsicht des Prompt-Editing-Verlaufs von PE2 stellten die Forscher fest, dass PE2 schon immer sinnvolle Prompt-Editing ermöglicht hat. Es ist in der Lage, falsche oder unvollständige Hinweise zu korrigieren und die Hinweise durch das Hinzufügen zusätzlicher Details zu bereichern, was letztendlich zu einer Leistungsverbesserung führt (siehe Tabelle 4).
Wenn PE2 die Addition im Oktalformat nicht kennt, erstellt es interessanterweise seine eigenen Rechenregeln anhand des Beispiels: „Wenn beide Zahlen kleiner als 50 sind, addiere 2 zur Summe. Wenn eine der Zahlen 50 oder größer ist, addiere 22.“ die Summe.“ Obwohl dies eine unvollkommene und einfache Lösung ist, zeigt sie die bemerkenswerte Fähigkeit von PE2, in kontrafaktischen Situationen zu argumentieren.
Trotz dieser Erfolge haben Forscher auch die Einschränkungen und Misserfolge von PE2 erkannt. PE2 unterliegt auch LLM-inhärenten Einschränkungen, wie z. B. der Plausibilität, gegebene Anweisungen zu ignorieren und Fehler zu erzeugen (siehe Tabelle 5 unten).
Hintergrundwissen
Tipps Projekt
Das Ziel des Prompt Engineering besteht darin, den Text-Prompt p∗ zu finden, der die beste Leistung für einen gegebenen Datensatz D erzielt, wenn ein gegebener LLM M_task als Aufgabenmodell verwendet wird (wie in der folgenden Formel gezeigt). Nehmen wir insbesondere an, dass alle Datensätze als Text-Eingabe-Ausgabe-Paare formatiert werden können, d. h. D = {(x, y)}. Ein Trainingssatz D_train für Optimierungshinweise, ein D_dev für die Validierung und ein D_test für die abschließende Bewertung. Gemäß der von den Forschern vorgeschlagenen symbolischen Darstellung kann das Prompt-Engineering-Problem wie folgt beschrieben werden:
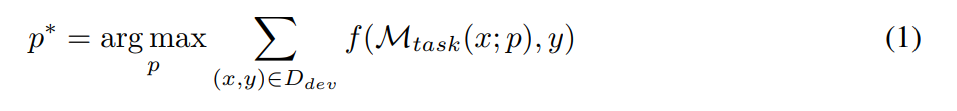
wobei M_task (x; p) die Ausgabe ist, die vom Modell bei gegebenem Prompt p generiert wird, und f für jedes Beispiel Bewertungsfunktion. Wenn beispielsweise die Bewertungsmetrik genau übereinstimmt, dann 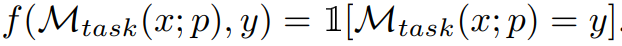
LLM für Auto-Prompt-Engineering verwenden
Anhand eines anfänglichen Satzes von Eingabeaufforderungen wird der Auto-Prompt-Ingenieur kontinuierlich neue und potenziell bessere Eingabeaufforderungen entwickeln. Zum Zeitstempel t erhält der Eingabeaufforderungsingenieur eine Eingabeaufforderung p^(t) und erwartet, eine neue Eingabeaufforderung p^(t+1) zu schreiben. Während der Generierung eines neuen Hinweises kann man optional eine Reihe von Beispielen B = {(x, y, y′ )} untersuchen. Hier repräsentiert y ′ = M_task (x; p) die vom Modell generierte Ausgabe und y repräsentiert die wahre Bezeichnung. Verwenden Sie p^meta, um eine Meta-Eingabeaufforderung darzustellen, die LLMs M_proposal anleitet, neue Vorschläge vorzuschlagen. Daher
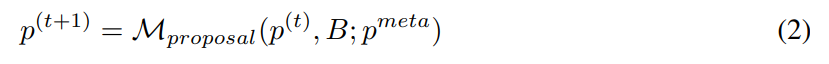
Die Konstruktion eines besseren Meta-Cues p^meta zur Verbesserung der Qualität des vorgeschlagenen Hinweises p^(t+1) ist der Hauptschwerpunkt dieser Studie.
Bessere Meta-Hinweise erstellen
So wie Hinweise eine wichtige Rolle bei der endgültigen Aufgabenerfüllung spielen, spielt der in Gleichung 2 eingeführte Meta-Hinweis p^meta eine wichtige Rolle für die Qualität der neu vorgeschlagenen Hinweise und des Gesamtbildes Die Qualität der Auto-Cue-Technik spielt eine wichtige Rolle.
Die Forscher konzentrieren sich hauptsächlich auf die Hinweiskonstruktion von Meta-Cue-p^meta, entwickelten Meta-Cue-Komponenten, die zur Verbesserung der Qualität der LLM-Hinweiskonstruktion beitragen können, und führten systematische Ablationsstudien zu diesen Komponenten durch.
Die Forscher haben die Grundlage dieser Komponenten auf der Grundlage der folgenden zwei Motivationen entworfen: (1) Bereitstellung detaillierter Anleitungen und Hintergrundinformationen (2) Einbeziehung gängiger Optimierungskonzepte; Anschließend beschreiben die Forscher diese Elemente detaillierter und erläutern die zugrunde liegenden Prinzipien. Abbildung 2 unten ist eine visuelle Darstellung.
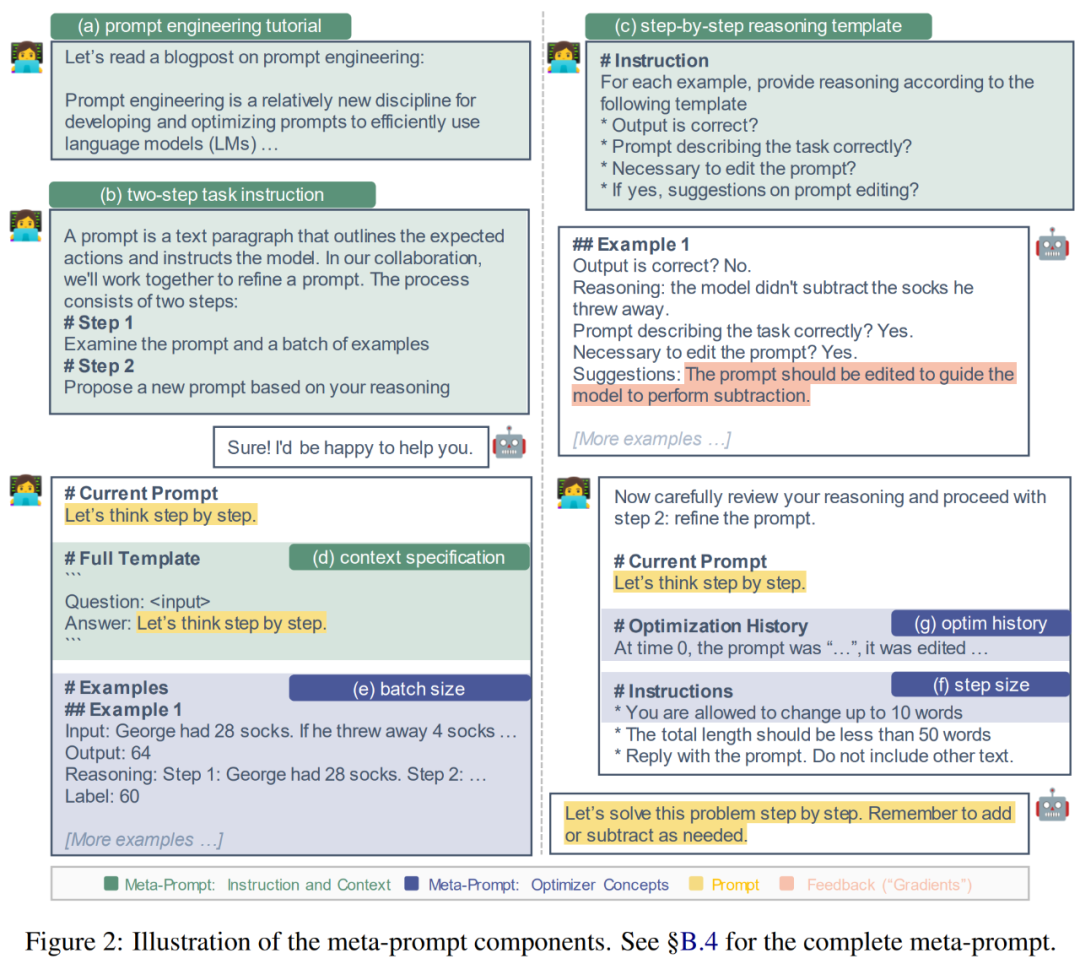
Bietet detaillierte Anweisungen und Kontext. In früheren Studien wiesen Meta-Hinweise das vorgeschlagene Modell entweder an, eine Paraphrase der Eingabeaufforderung zu generieren, oder enthielten nur minimale Anweisungen zur Untersuchung einer Reihe von Beispielen. Daher kann es von Vorteil sein, zusätzliche Anweisungen und Kontext zu Meta-Hinweisen hinzuzufügen.
(a) Prompt Engineering Tutorial. Um LLM dabei zu helfen, die Aufgabe des Prompt Engineering besser zu verstehen, stellen die Forscher ein Online-Tutorial zum Prompt Engineering in Meta-Click bereit.
(b) Zweistufige Aufgabenbeschreibung. Die Prompt-Engineering-Aufgabe kann wie von Pryzant et al. in zwei Schritte zerlegt werden: Im ersten Schritt sollte das Modell den aktuellen Prompt und eine Reihe von Beispielen untersuchen. Im zweiten Schritt soll das Modell eine verbesserte Eingabeaufforderung aufbauen. Beim Ansatz von Pryzant et al. wird jedoch jeder Schritt spontan erklärt. Stattdessen erwogen die Forscher, diese beiden Schritte im Metacue zu klären und Erwartungen im Voraus zu vermitteln.
(c) Schritt-für-Schritt-Argumentationsvorlage. Um das Modell zu ermutigen, jedes Beispiel in Charge B sorgfältig zu untersuchen und über die Einschränkungen der aktuellen Eingabeaufforderung nachzudenken, haben wir das Eingabeaufforderungsvorschlagsmodell M_proposal zur Beantwortung einer Reihe von Fragen geleitet. Zum Beispiel: Ist die Ausgabe korrekt? Beschreibt die Eingabeaufforderung die Aufgabe richtig? Ist es notwendig, die Eingabeaufforderung zu bearbeiten?
(d) Kontextspezifikation. In der Praxis besteht Flexibilität bei der Einfügung von Hinweisen in die gesamte Eingabesequenz. Es kann die Aufgabe beschreiben, bevor der Text eingegeben wird, z. B. „Englisch ins Französische übersetzen“. Es kann auch nach der Texteingabe erscheinen, z. B. „Schritt für Schritt denken“, um Denkfähigkeiten anzuregen. Um diese unterschiedlichen Kontexte zu erkennen, spezifizieren Forscher explizit die Interaktion zwischen Hinweisen und Eingaben. Zum Beispiel: „F:
Beziehen Sie gängige Optimierungskonzepte ein. Das zuvor in Gleichung 1 beschriebene Cue-Engineering-Problem ist im Wesentlichen ein Optimierungsproblem, während der Cue-Vorschlag in Gleichung 2 als einem Optimierungsschritt unterworfen angesehen werden kann. Daher betrachten Forscher die folgenden Konzepte, die häufig in der Gradienten-basierten Optimierung verwendet werden, und entwickeln ihre Gegenstücke zur Verwendung in Meta-Hinweisen.
(e) Losgröße. Die Batch-Größe ist die Anzahl der (fehlgeschlagenen) Beispiele, die in jedem Tippvorschlagsschritt verwendet werden (Gleichung 2). Die Autoren haben in ihrer Analyse Chargengrößen von {1, 2, 4, 8} ausprobiert.
(f) Schrittgröße. Bei der gradientenbasierten Optimierung bestimmt die Schrittgröße, wie stark die Modellgewichte aktualisiert werden. In einem Prompt-Projekt könnte das Gegenstück die Anzahl der Wörter (Tokens) sein, die geändert werden können. Der Autor gibt direkt an: „Sie können bis zu s Wörter in der ursprünglichen Eingabeaufforderung ändern“, wobei s ∈ {5, 10, 15, None}.
(g) Optimieren Sie Verlauf und Dynamik. Momentum (Qian, 1999) ist eine Technik, die die Optimierung beschleunigt und Schwankungen vermeidet, indem ein gleitender Durchschnitt vergangener Gradienten beibehalten wird. Um das sprachliche Gegenstück zu Momentum zu entwickeln, enthält dieses Papier eine Zusammenfassung aller vergangenen Eingabeaufforderungen (mit Zeitstempel 0, 1, ..., t − 1), ihrer Leistung auf dem Entwicklungssatz und Eingabeaufforderungsänderungen.
Experiment
Die Autoren verwendeten die folgenden vier Aufgabensätze, um die Wirksamkeit und Grenzen von PE2 zu bewerten:
1. Mathematische Argumentation; 3. Kontrafaktische Bewertung;
Verbesserte Benchmarks und aktualisierte LLMs. In den ersten beiden Teilen von Tabelle 2 stellen die Autoren erhebliche Leistungsverbesserungen bei der Verwendung von TEXT-DAVINCI-003 fest, was darauf hindeutet, dass TEXT-DAVINCI-003 besser zur Lösung mathematischer Argumentationsprobleme im Zero-Shot-CoT geeignet ist. Darüber hinaus verringerte sich die Lücke zwischen den beiden Hinweisen (MultiArith: 3,3 % → 1,0 %, GSM8K: 2,3 % → 0,6 %), was auf eine verringerte Empfindlichkeit von TEXT-DAVINCI-003 gegenüber der Hinweisinterpretation hinweist. Aus diesem Grund sind Methoden, die auf einfachen Paraphrasen basieren, wie z. B. Iterative APE, möglicherweise nicht wirksam bei der Verbesserung der Endergebnisse. Um die Leistung zu verbessern, ist eine präzisere und gezieltere Eingabeaufforderungsbearbeitung erforderlich.
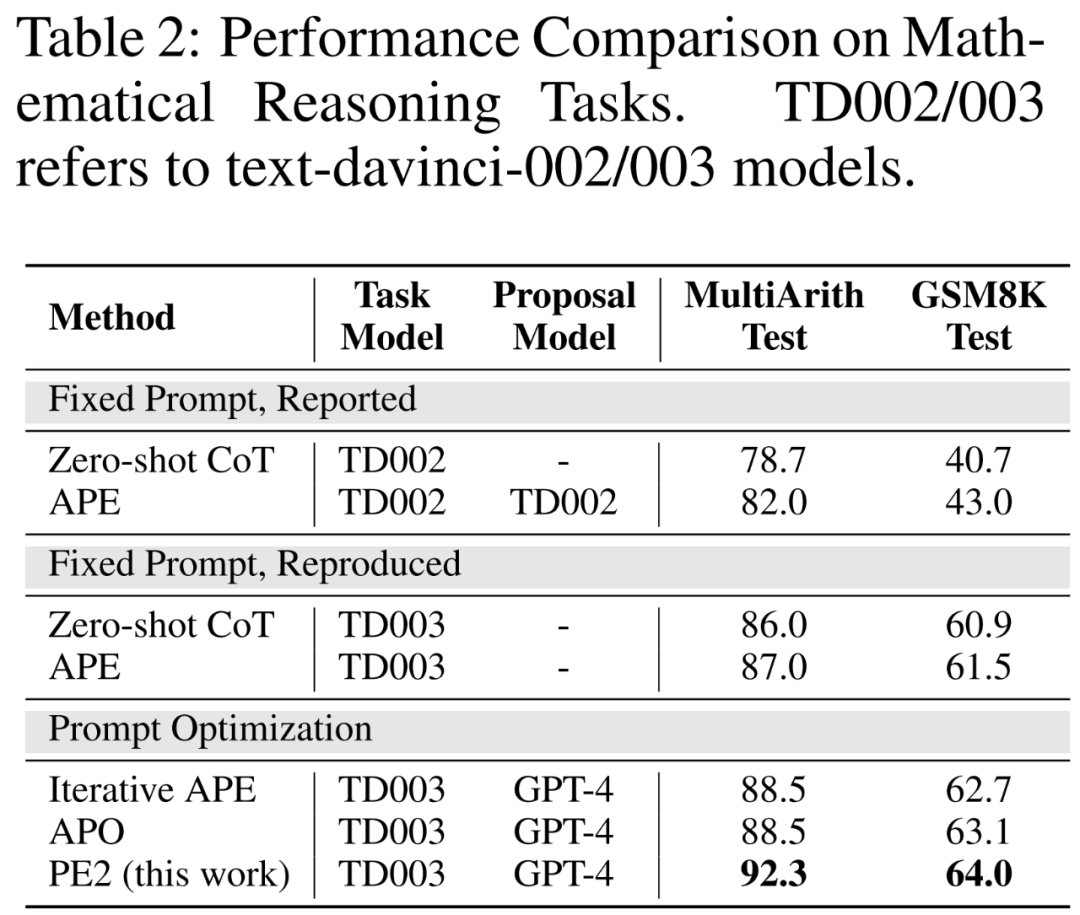
PE2 übertrifft Iterative APE und APO bei verschiedenen Aufgaben. PE2 ist in der Lage, einen Tipp mit einer Genauigkeit von 92,3 % auf MultiArith (6,3 % besser als Zero-shot CoT) und 64,0 % auf GSM8K (+3,1 %) zu finden. Darüber hinaus fand PE2 Hinweise, die Iterative APE und APO in Bezug auf den Instruktionsinduktions-Benchmark, die kontrafaktische Bewertung und die Produktionshinweise übertrafen.
In Abbildung 1 oben fasst der Autor die von PE2 erzielten Leistungsverbesserungen beim Instruktionsinduktions-Benchmark, der kontrafaktischen Bewertung und den Produktionsaufforderungen zusammen und zeigt, dass PE2 bei verschiedenen Sprachaufgaben eine starke Leistung erzielt. Bemerkenswert ist, dass PE2 bei Verwendung der induktiven Initialisierung APO bei 11 von 12 kontrafaktischen Aufgaben übertrifft (dargestellt in Abbildung 6), was die Fähigkeit von PE2 demonstriert, über paradoxe und kontrafaktische Situationen nachzudenken.
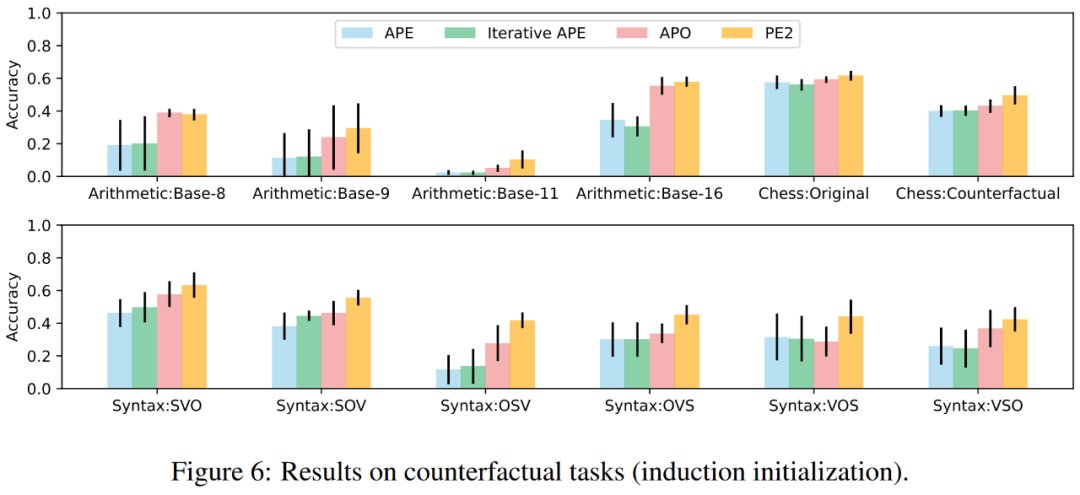
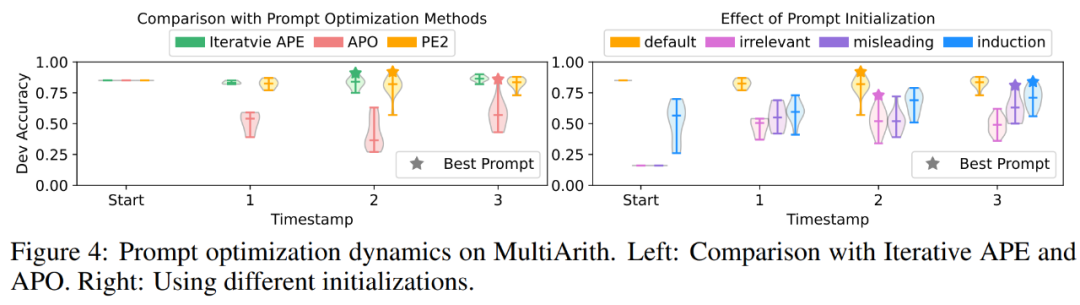
PE2 generiert gezielte Eingabeaufforderungen und qualitativ hochwertige Eingabeaufforderungen. In Abbildung 4(a) zeichnen die Autoren die Qualität der Cue-Vorschläge während des Cue-Optimierungsprozesses auf. In den Experimenten wurde bei den drei Methoden zur Cue-Optimierung ein sehr klares Muster beobachtet: Iteratives APE basiert auf Paraphrasierung, sodass die neu generierten Cues eine geringere Varianz aufweisen. APO wird einer drastischen sofortigen Bearbeitung unterzogen, sodass die Leistung beim ersten Schritt sinkt. PE2 ist die stabilste der drei Methoden. In Tabelle 3 listen die Autoren die besten Tipps auf, die mit diesen Methoden gefunden wurden. Sowohl APO als auch PE2 können Anweisungen zum Berücksichtigen aller Teile/Details bereitstellen. Darüber hinaus ist PE2 darauf ausgelegt, Stapel doppelt zu prüfen, sodass über einfache Paraphrasierungsänderungen hinaus auch sehr spezifische Eingabeaufforderungsänderungen wie „Denken Sie daran, nach Bedarf zu addieren oder zu subtrahieren“ möglich sind.
Weitere Informationen finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonEffektiver als das Mantra „Lasst uns Schritt für Schritt denken' erinnert es uns daran, dass das Projekt verbessert wird.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Der Autor von ControlNet hat einen weiteren Hit! Der gesamte Prozess der Generierung eines Gemäldes aus einem Bild, der in zwei Tagen 1,4.000 Sterne verdient
Jul 17, 2024 am 01:56 AM
Der Autor von ControlNet hat einen weiteren Hit! Der gesamte Prozess der Generierung eines Gemäldes aus einem Bild, der in zwei Tagen 1,4.000 Sterne verdient
Jul 17, 2024 am 01:56 AM
Es ist ebenfalls ein Tusheng-Video, aber PaintsUndo ist einen anderen Weg gegangen. ControlNet-Autor LvminZhang begann wieder zu leben! Dieses Mal ziele ich auf den Bereich der Malerei. Das neue Projekt PaintsUndo hat nicht lange nach seinem Start 1,4.000 Sterne erhalten (die immer noch wahnsinnig steigen). Projektadresse: https://github.com/lllyasviel/Paints-UNDO Bei diesem Projekt gibt der Benutzer ein statisches Bild ein, und PaintsUndo kann Ihnen dabei helfen, automatisch ein Video des gesamten Malprozesses zu erstellen, vom Linienentwurf bis zum fertigen Produkt . Während des Zeichenvorgangs sind die Linienänderungen erstaunlich. Das Endergebnis des Videos ist dem Originalbild sehr ähnlich: Schauen wir uns eine vollständige Zeichnung an.
 Von RLHF über DPO bis TDPO sind große Modellausrichtungsalgorithmen bereits auf „Token-Ebene'
Jun 24, 2024 pm 03:04 PM
Von RLHF über DPO bis TDPO sind große Modellausrichtungsalgorithmen bereits auf „Token-Ebene'
Jun 24, 2024 pm 03:04 PM
Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. Einreichungs-E-Mail: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com Im Entwicklungsprozess der künstlichen Intelligenz war die Steuerung und Führung großer Sprachmodelle (LLM) schon immer eine der zentralen Herausforderungen, um sicherzustellen, dass diese Modelle beides sind kraftvoll und sicher dienen der menschlichen Gesellschaft. Frühe Bemühungen konzentrierten sich auf Methoden des verstärkenden Lernens durch menschliches Feedback (RL
 Die agentenlose Lösung von UIUC steht ganz oben auf der Liste der Open-Source-KI-Softwareentwickler und löst problemlos echte Programmierprobleme im SWE-Bench
Jul 17, 2024 pm 10:02 PM
Die agentenlose Lösung von UIUC steht ganz oben auf der Liste der Open-Source-KI-Softwareentwickler und löst problemlos echte Programmierprobleme im SWE-Bench
Jul 17, 2024 pm 10:02 PM
Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. Einreichungs-E-Mail: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com Die Autoren dieses Artikels stammen alle aus dem Team von Lehrer Zhang Lingming an der University of Illinois in Urbana-Champaign, darunter: Steven Code Repair; Doktorand im vierten Jahr, Forscher
 Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Wenn die Antwort des KI-Modells überhaupt unverständlich ist, würden Sie es wagen, sie zu verwenden? Da maschinelle Lernsysteme in immer wichtigeren Bereichen eingesetzt werden, wird es immer wichtiger zu zeigen, warum wir ihren Ergebnissen vertrauen können und wann wir ihnen nicht vertrauen sollten. Eine Möglichkeit, Vertrauen in die Ausgabe eines komplexen Systems zu gewinnen, besteht darin, vom System zu verlangen, dass es eine Interpretation seiner Ausgabe erstellt, die für einen Menschen oder ein anderes vertrauenswürdiges System lesbar ist, d. h. so vollständig verständlich, dass mögliche Fehler erkannt werden können gefunden. Um beispielsweise Vertrauen in das Justizsystem aufzubauen, verlangen wir von den Gerichten, dass sie klare und lesbare schriftliche Stellungnahmen abgeben, die ihre Entscheidungen erläutern und stützen. Für große Sprachmodelle können wir auch einen ähnlichen Ansatz verfolgen. Stellen Sie bei diesem Ansatz jedoch sicher, dass das Sprachmodell generiert wird
 Axiomatisches Training ermöglicht es LLM, kausales Denken zu erlernen: Das 67-Millionen-Parameter-Modell ist vergleichbar mit der Billionen-Parameter-Ebene GPT-4
Jul 17, 2024 am 10:14 AM
Axiomatisches Training ermöglicht es LLM, kausales Denken zu erlernen: Das 67-Millionen-Parameter-Modell ist vergleichbar mit der Billionen-Parameter-Ebene GPT-4
Jul 17, 2024 am 10:14 AM
Zeigen Sie LLM die Kausalkette und es lernt die Axiome. KI hilft Mathematikern und Wissenschaftlern bereits bei der Forschung. Beispielsweise hat der berühmte Mathematiker Terence Tao wiederholt seine Forschungs- und Forschungserfahrungen mit Hilfe von KI-Tools wie GPT geteilt. Damit KI in diesen Bereichen konkurrenzfähig sein kann, sind starke und zuverlässige Fähigkeiten zum kausalen Denken unerlässlich. Die in diesem Artikel vorgestellte Forschung ergab, dass ein Transformer-Modell, das auf die Demonstration des kausalen Transitivitätsaxioms für kleine Graphen trainiert wurde, auf das Transitivitätsaxiom für große Graphen verallgemeinern kann. Mit anderen Worten: Wenn der Transformer lernt, einfache kausale Überlegungen anzustellen, kann er für komplexere kausale Überlegungen verwendet werden. Der vom Team vorgeschlagene axiomatische Trainingsrahmen ist ein neues Paradigma zum Erlernen des kausalen Denkens auf der Grundlage passiver Daten, nur mit Demonstrationen
 arXiv-Artikel können als „Barrage' gepostet werden, die Diskussionsplattform von Stanford alphaXiv ist online, LeCun gefällt es
Aug 01, 2024 pm 05:18 PM
arXiv-Artikel können als „Barrage' gepostet werden, die Diskussionsplattform von Stanford alphaXiv ist online, LeCun gefällt es
Aug 01, 2024 pm 05:18 PM
Prost! Wie ist es, wenn es bei einer Papierdiskussion auf Worte ankommt? Kürzlich haben Studenten der Stanford University alphaXiv erstellt, ein offenes Diskussionsforum für arXiv-Artikel, das es ermöglicht, Fragen und Kommentare direkt zu jedem arXiv-Artikel zu posten. Website-Link: https://alphaxiv.org/ Tatsächlich ist es nicht erforderlich, diese Website speziell zu besuchen. Ändern Sie einfach arXiv in einer beliebigen URL in alphaXiv, um den entsprechenden Artikel direkt im alphaXiv-Forum zu öffnen: Sie können die Absätze darin genau lokalisieren das Papier, Satz: Im Diskussionsbereich auf der rechten Seite können Benutzer Fragen stellen, um dem Autor Fragen zu den Ideen und Details des Papiers zu stellen. Sie können beispielsweise auch den Inhalt des Papiers kommentieren, wie zum Beispiel: „Gegeben an.“
 Ein bedeutender Durchbruch in der Riemann-Hypothese! Tao Zhexuan empfiehlt dringend neue Arbeiten vom MIT und Oxford, und der 37-jährige Fields-Medaillengewinner nahm daran teil
Aug 05, 2024 pm 03:32 PM
Ein bedeutender Durchbruch in der Riemann-Hypothese! Tao Zhexuan empfiehlt dringend neue Arbeiten vom MIT und Oxford, und der 37-jährige Fields-Medaillengewinner nahm daran teil
Aug 05, 2024 pm 03:32 PM
Kürzlich gelang der Riemann-Hypothese, die als eines der sieben großen Probleme des Jahrtausends bekannt ist, ein neuer Durchbruch. Die Riemann-Hypothese ist ein sehr wichtiges ungelöstes Problem in der Mathematik, das sich auf die genauen Eigenschaften der Verteilung von Primzahlen bezieht (Primzahlen sind Zahlen, die nur durch 1 und sich selbst teilbar sind, und sie spielen eine grundlegende Rolle in der Zahlentheorie). In der heutigen mathematischen Literatur gibt es mehr als tausend mathematische Thesen, die auf der Aufstellung der Riemann-Hypothese (oder ihrer verallgemeinerten Form) basieren. Mit anderen Worten: Sobald die Riemann-Hypothese und ihre verallgemeinerte Form bewiesen sind, werden diese mehr als tausend Sätze als Theoreme etabliert, die einen tiefgreifenden Einfluss auf das Gebiet der Mathematik haben werden, und wenn sich die Riemann-Hypothese als falsch erweist, dann unter anderem Auch diese Sätze werden teilweise ihre Gültigkeit verlieren. Neuer Durchbruch kommt von MIT-Mathematikprofessor Larry Guth und der Universität Oxford
 Unbegrenzte Videogenerierung, Planung und Entscheidungsfindung, erzwungene Verbreitung der nächsten Token-Vorhersage und vollständige Sequenzverbreitung
Jul 23, 2024 pm 02:05 PM
Unbegrenzte Videogenerierung, Planung und Entscheidungsfindung, erzwungene Verbreitung der nächsten Token-Vorhersage und vollständige Sequenzverbreitung
Jul 23, 2024 pm 02:05 PM
Derzeit sind autoregressive groß angelegte Sprachmodelle, die das nächste Token-Vorhersageparadigma verwenden, auf der ganzen Welt populär geworden. Gleichzeitig haben uns zahlreiche synthetische Bilder und Videos im Internet bereits die Leistungsfähigkeit von Diffusionsmodellen gezeigt. Kürzlich hat ein Forschungsteam am MITCSAIL (darunter Chen Boyuan, ein Doktorand am MIT) erfolgreich die leistungsstarken Fähigkeiten des Vollsequenz-Diffusionsmodells und des nächsten Token-Modells integriert und ein Trainings- und Sampling-Paradigma vorgeschlagen: Diffusion Forcing (DF). ). Papiertitel: DiffusionForcing:Next-tokenPredictionMeetsFull-SequenceDiffusion Papieradresse: https:/
