

Link zum Papier: https://arxiv.org/pdf/2401.03907.pdf
Der multimodale 3D-Detektor wurde entwickelt, um sichere und zuverlässige Wahrnehmungssysteme für autonomes Fahren zu untersuchen. Obwohl sie mit sauberen Benchmark-Datensätzen Spitzenleistung erzielen, werden die Komplexität und die rauen Bedingungen realer Umgebungen oft ignoriert. Gleichzeitig stehen mit dem Aufkommen des visuellen Basismodells (VFM) die Verbesserung der Robustheit und Generalisierungsfähigkeiten der multimodalen 3D-Erkennung vor Chancen und Herausforderungen beim autonomen Fahren. Daher schlagen die Autoren das RoboFusion-Framework vor, das VFM wie SAM nutzt, um Out-of-Distribution-Rauschenszenarien (OOD) zu bewältigen.
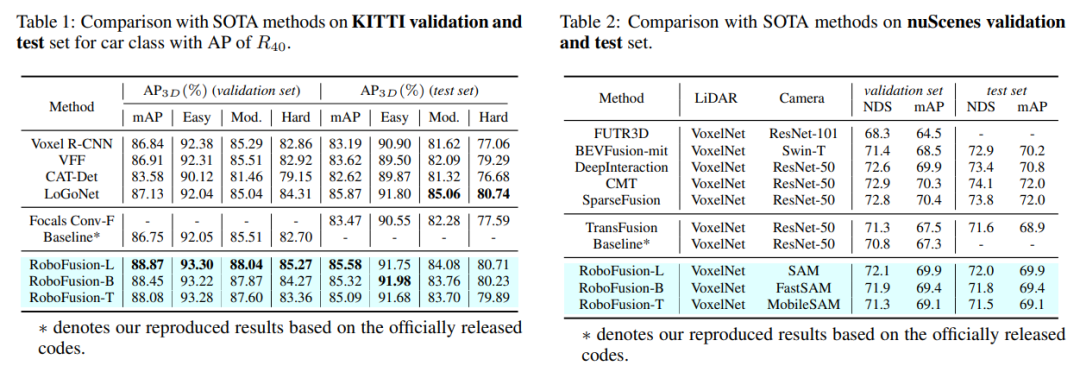
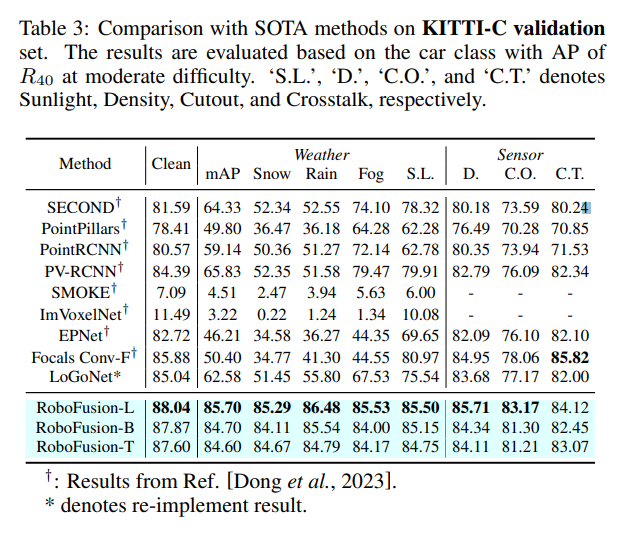
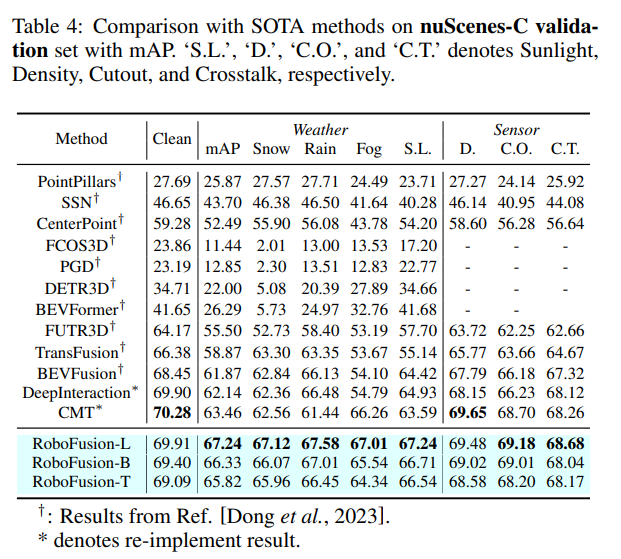
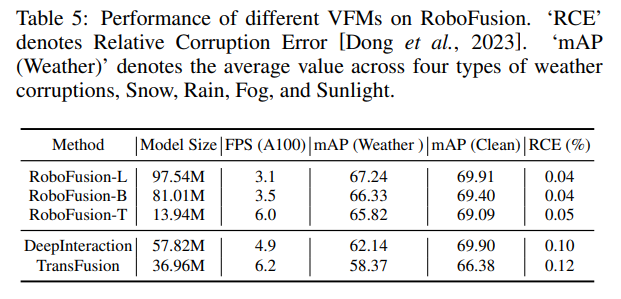
Zuerst wenden wir das ursprüngliche SAM auf ein autonomes Fahrszenario namens SAM-AD an. Um SAM oder SAMAD mit multimodalen Methoden auszurichten, führen wir AD-FPN ein, um die von SAM extrahierten Bildmerkmale hochzurechnen. Um Rauschen und Wetterstörungen weiter zu reduzieren, verwenden wir Wavelet-Zerlegung, um die tiefengeführten Bilder zu entrauschen. Schließlich verwenden wir einen Selbstaufmerksamkeitsmechanismus, um die zusammengeführten Merkmale adaptiv neu zu gewichten, um informative Merkmale zu verbessern und gleichzeitig übermäßiges Rauschen zu unterdrücken. RoboFusion verbessert die Widerstandsfähigkeit der multimodalen 3D-Objekterkennung, indem es die Generalisierung und Robustheit von VFM nutzt, um das Rauschen schrittweise zu reduzieren. Dadurch erreicht RoboFusion laut den Ergebnissen der KITTIC- und nuScenes-C-Benchmarks eine erstklassige Leistung in lauten Szenen.
Das Papier schlägt ein robustes Framework namens RoboFusion vor, das VFM wie SAM nutzt, um multimodale 3D-Objektdetektoren von sauberen Szenen an OOD-verrauschte Szenen anzupassen. Unter ihnen ist die Anpassungsstrategie von SAM der Schlüssel.
1) Verwenden Sie aus SAM extrahierte Features, anstatt auf Segmentierungsergebnisse zu schließen.
2) SAM-AD wird vorgeschlagen, ein vorab trainiertes SAM für AD-Szenarien.
3) Ein neues AD-FPN wird eingeführt, um das Feature-Upsampling-Problem für die Ausrichtung von VFM mit multimodalen 3D-Detektoren zu lösen.
Um Rauschstörungen zu reduzieren und die Signaleigenschaften beizubehalten, wird das Deep Guided Wavelet Attention (DGWA)-Modul eingeführt, um hoch- und niederfrequentes Rauschen effektiv zu dämpfen.
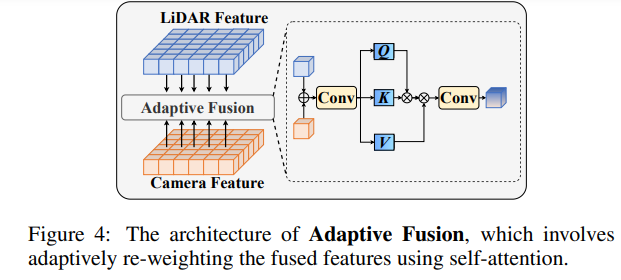
Nachdem Sie Punktwolken- und Bildmerkmale zusammengeführt haben, gewichten Sie die Merkmale durch adaptive Fusion neu, um die Robustheit und Rauschresistenz der Merkmale zu verbessern.
Das RoboFusion-Framework ist unten dargestellt, und sein Lidar-Zweig folgt der Basislinie [Chen et al., 2022; Bai et al., 2022], um Lidar-Funktionen zu generieren. Im Kamerazweig wird zunächst der hochoptimierte SAM-AD-Algorithmus zum Extrahieren robuster Bildmerkmale verwendet und mit AD-FPN kombiniert, um mehrskalige Merkmale zu erhalten. Als nächstes werden die Originalpunkte verwendet, um eine spärliche Tiefenkarte S zu generieren, die in den Tiefenencoder eingegeben wird, um Tiefenmerkmale zu erhalten, und mit mehrskaligen Bildmerkmalen fusioniert wird, um tiefengeführte Bildmerkmale zu erhalten. Anschließend wird das Mutationsrauschen durch den schwankenden Aufmerksamkeitsmechanismus entfernt. Schließlich wird die adaptive Fusion durch einen Selbstaufmerksamkeitsmechanismus erreicht, um Punktwolkenmerkmale mit robusten Bildmerkmalen mit Tiefeninformationen zu kombinieren.
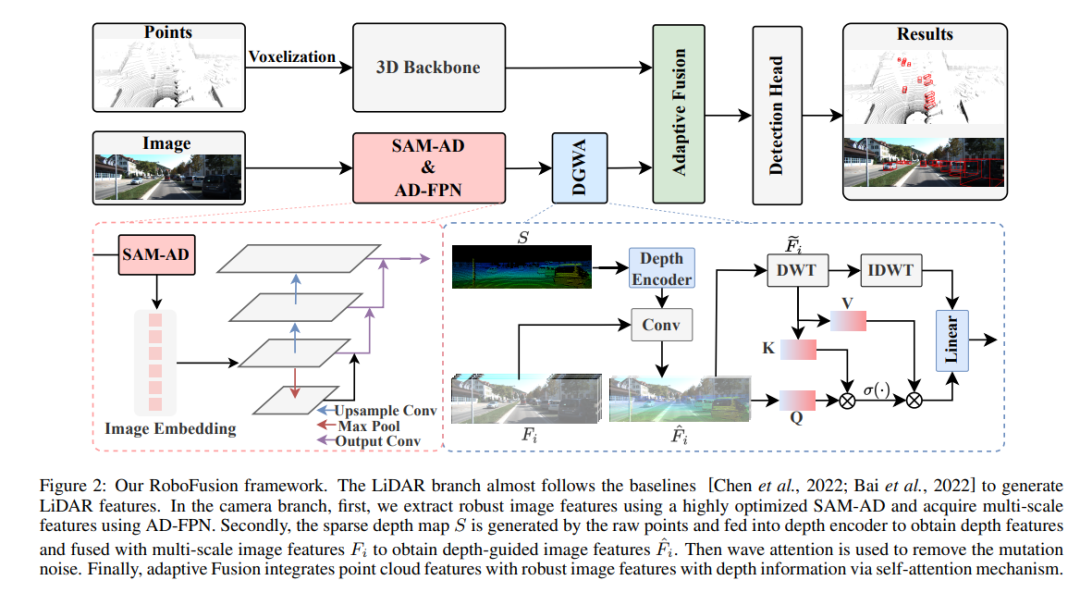
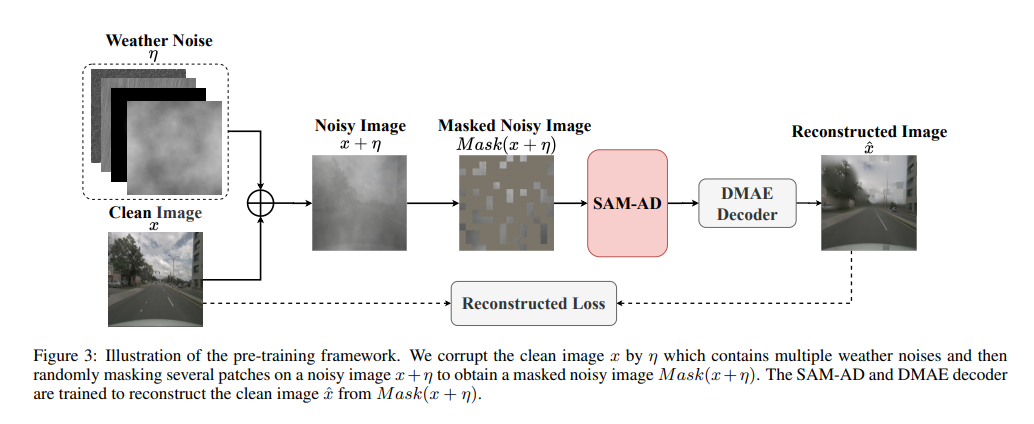
SAM-AD: Um SAM weiter an AD-Szenarien (autonomes Fahren) anzupassen, ist SAM vorab darauf trainiert, SAM-AD zu erhalten. Insbesondere sammeln wir eine große Anzahl von Bildbeispielen aus ausgereiften Datensätzen (d. h. KITTI und nuScenes), um den grundlegenden AD-Datensatz zu bilden. Nach DMAE wird SAM vorab trainiert, um SAM-AD in AD-Szenarien zu erhalten, wie in Abbildung 3 dargestellt. Bezeichnen Sie x als das saubere Bild aus dem AD-Datensatz (d. h. KITTI und nuScenes) und eta als das auf Basis von x generierte verrauschte Bild. Art und Schwere des Lärms wurden zufällig aus vier Wetterbedingungen (d. h. Regen, Schnee, Nebel und Sonnenschein) und fünf Schweregraden von 1 bis 5 ausgewählt. Wir verwenden SAM, den Bildencoder von MobileSAM, als unseren Encoder, während die Decoder- und Rekonstruktionsverluste die gleichen wie bei DMAE sind.
AD-FPN. Als Cue-fähiges Segmentierungsmodell besteht SAM aus drei Teilen: Bild-Encoder, Cue-Encoder und Masken-Decoder. Im Allgemeinen ist es notwendig, den Bildcodierer zu verallgemeinern, um das VFM zu trainieren und dann den Decoder zu trainieren. Mit anderen Worten: Der Bildencoder kann qualitativ hochwertige und äußerst robuste Bilderinbettungen für nachgeschaltete Modelle bereitstellen, während der Maskendecoder nur für die Bereitstellung von Decodierungsdiensten für die semantische Segmentierung ausgelegt ist. Darüber hinaus benötigen wir robuste Bildfunktionen und nicht die Verarbeitung von Cue-Informationen durch den Cue-Encoder. Daher verwenden wir den Bildencoder von SAM, um robuste Bildmerkmale zu extrahieren. SAM verwendet jedoch die ViT-Serie als Bildencoder, der Multiskalenfunktionen ausschließt und nur hochdimensionale Funktionen mit niedriger Auflösung bereitstellt. Um Multiskalenfunktionen zu generieren, die für die Zielerkennung erforderlich sind, wurde, inspiriert von [Li et al., 2022a], ein AD-FPN entworfen, das Multiskalenfunktionen basierend auf ViT bereitstellt!
Trotz der Fähigkeit von SAM-AD oder SAM, robuste Bildmerkmale zu extrahieren, besteht immer noch die Lücke zwischen der 2D-Domäne und der 3D-Domäne, und Kameras, denen geometrische Informationen in beschädigten Umgebungen fehlen, verstärken oft das Rauschen und verursachen negative Übertragungsprobleme. Um dieses Problem zu lindern, schlagen wir das Modul Deep Guided Wavelet Attention (DGWA) vor, das in die folgenden zwei Schritte unterteilt werden kann. 1) Ein Tiefenführungsnetzwerk soll durch die Kombination von Bildmerkmalen und Tiefenmerkmalen von Punktwolken Geometrie vor Bildmerkmalen hinzufügen. 2) Verwenden Sie die Haar-Wavelet-Transformation, um die Merkmale des Bildes in vier Unterbänder zu zerlegen, und dann ermöglicht der Aufmerksamkeitsmechanismus die Entrauschung der Informationsmerkmale in den Unterbändern!


Originallink: https://mp.weixin.qq.com/s/78y 1 KyipHeUSh5sLQZy-ng
Das obige ist der detaillierte Inhalt vonRoboFusion für zuverlässige multimodale 3D-Erkennung mittels SAM. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Einführung in das von vscode verwendete Framework
Einführung in das von vscode verwendete Framework
 So erstellen Sie einen neuen Ordner in Webstorm
So erstellen Sie einen neuen Ordner in Webstorm
 So konfigurieren Sie JDK-Umgebungsvariablen
So konfigurieren Sie JDK-Umgebungsvariablen
 So rufen Sie das BIOS auf dem Thinkpad auf
So rufen Sie das BIOS auf dem Thinkpad auf
 Ouyi-Handelsplattform-App
Ouyi-Handelsplattform-App
 Was sind die Python-Bibliotheken für künstliche Intelligenz?
Was sind die Python-Bibliotheken für künstliche Intelligenz?
 Lösung für Java-Erfolg und Javac-Fehler
Lösung für Java-Erfolg und Javac-Fehler
 So verwenden Sie die Print()-Funktion in Python
So verwenden Sie die Print()-Funktion in Python
 Vorteile des Herunterladens der offiziellen Website der Yiou Exchange App
Vorteile des Herunterladens der offiziellen Website der Yiou Exchange App







![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



