
 Technologie-Peripheriegeräte
KI
Anwendung der Positionskodierung in Transformer: Erkundung der unendlichen Möglichkeiten der Längenextrapolation
Technologie-Peripheriegeräte
KI
Anwendung der Positionskodierung in Transformer: Erkundung der unendlichen Möglichkeiten der Längenextrapolation
Anwendung der Positionskodierung in Transformer: Erkundung der unendlichen Möglichkeiten der Längenextrapolation

Im Bereich der Verarbeitung natürlicher Sprache hat das Transformer-Modell aufgrund seiner hervorragenden Sequenzmodellierungsleistung große Aufmerksamkeit erregt. Aufgrund der Begrenzung der Kontextlänge während des Trainings können jedoch weder es noch das darauf basierende große Sprachmodell effektiv mit Sequenzen umgehen, die diese Längenbeschränkung überschreiten. Dies wird als fehlende Fähigkeit zur „effektiven Längenextrapolation“ bezeichnet. Dies führt dazu, dass große Sprachmodelle bei der Verarbeitung langer Texte schlecht abschneiden oder diese gar nicht verarbeiten können. Um dieses Problem zu lösen, haben Forscher eine Reihe von Methoden vorgeschlagen, beispielsweise die Trunkierungsmethode, die segmentierte Methode und die hierarchische Methode. Diese Methoden zielen darauf ab, die effektive Längenextrapolationsfähigkeit des Modells durch einige Tricks zu verbessern, sodass es extrem lange Sequenzen besser verarbeiten kann. Obwohl diese Methoden dieses Problem bis zu einem gewissen Grad lindern, sind noch weitere Untersuchungen erforderlich, um die Fähigkeit des Modells zur Extrapolation effektiver Längen weiter zu verbessern und sich besser an die Anforderungen tatsächlicher Anwendungsszenarien anzupassen.
Textfortsetzung und Spracherweiterung sind einer der wichtigen Aspekte der menschlichen Sprachfähigkeit. Im Zeitalter großer Modelle ist die Längenextrapolation zu einer wichtigen Methode geworden, um die Fähigkeiten des Modells effektiv auf Daten mit langen Sequenzen anzuwenden. Die Forschung zu diesem Thema hat theoretischen und praktischen Wert, daher entstehen weiterhin entsprechende Arbeiten. Gleichzeitig ist eine systematische Überprüfung erforderlich, um einen Überblick über dieses Gebiet zu geben und die Grenzen von Sprachmodellen kontinuierlich zu erweitern.
Forscher des Harbin Institute of Technology überprüften systematisch den Forschungsfortschritt des Transformer-Modells bei der Längenextrapolation aus der Perspektive der Positionskodierung. Die Forscher konzentrieren sich hauptsächlich auf extrapolierbare Positionscodes und auf diesen Codes basierende Erweiterungsmethoden, um die Längenextrapolationsfähigkeit des Transformer-Modells zu verbessern.

Papierlink: https://arxiv.org/abs/2312.17044
Extrapolierbare Positionskodierung
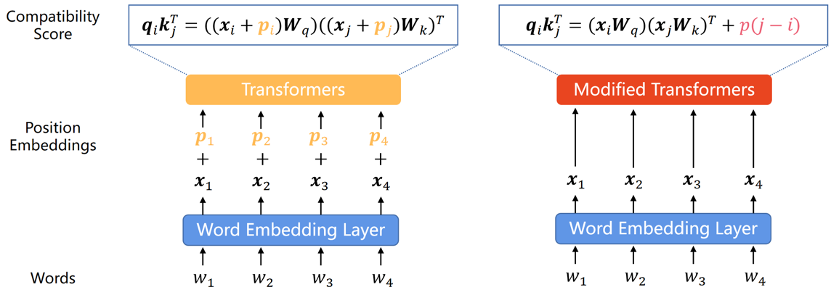
Da das Transformer-Modell selbst nicht die Positionsinformationen jedes Wortes in der Sequenz erfassen kann, Daher Die Positionskodierung ist zu einer häufigen Ergänzung geworden. Die Positionskodierung kann in zwei Typen unterteilt werden: absolute Positionskodierung und relative Positionskodierung. Bei der absoluten Positionskodierung wird jedem Wort in der Eingabesequenz ein Positionsvektor hinzugefügt, um die absolute Positionsinformation des Wortes in der Sequenz darzustellen. Die relative Positionskodierung kodiert den relativen Abstand zwischen jedem Wortpaar an unterschiedlichen Positionen. Beide Kodierungsmethoden können die Informationen zur Elementreihenfolge in der Sequenz in das Transformer-Modell integrieren, um die Leistung des Modells zu verbessern.
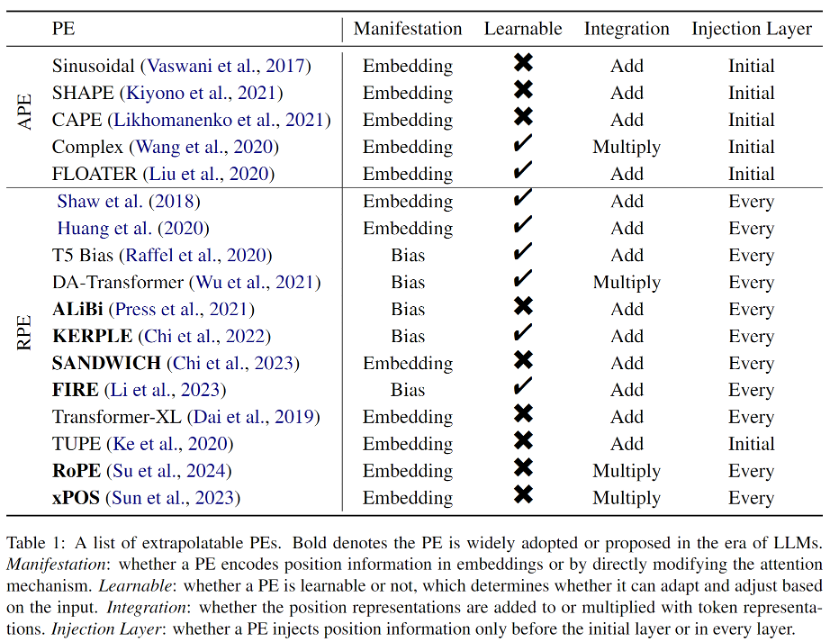
Da bestehende Forschungsergebnisse zeigen, dass diese Klassifizierung für die Extrapolationsfähigkeit des Modells von entscheidender Bedeutung ist, werden wir diesen Abschnitt entsprechend dieser Klassifizierung unterteilen.
Absolute Positionskodierung
Im Original-Transformer-Papier wurde die Positionskodierung durch Sinus- und Kosinusfunktionen generiert, obwohl sich herausstellte, dass sie nicht gut extrapoliert werden konnte, diente sie als erstes Transformer-A-PE, Sinus-APE hatte einen tiefgreifenden Einfluss auf die spätere PE.
Um die Extrapolationsfähigkeiten von Transformer-Modellen zu verbessern, integrieren Forscher entweder die Verschiebungsinvarianz über zufällige Verschiebungen in die sinusförmige APE oder erzeugen Positionseinbettungen, die sich gleichmäßig mit der Position ändern, und erwarten, dass das Modell lernt, diese variierende Funktion abzuleiten. Auf diesen Ideen basierende Methoden weisen eine stärkere Extrapolationsfähigkeit auf als sinusförmiges APE, können aber immer noch nicht das Niveau von RPE erreichen. Ein Grund dafür ist, dass APE unterschiedliche Positionen unterschiedlichen Positionseinbettungen zuordnet und die Extrapolation bedeutet, dass das Modell auf unsichtbare Positionseinbettungen schließen muss. Dies ist jedoch eine schwierige Aufgabe für das Modell. Da es eine begrenzte Anzahl von Positionseinbettungen gibt, die während des umfangreichen Vortrainings wiederholt auftreten, insbesondere im Fall von LLM, ist das Modell sehr anfällig für eine Überanpassung an diese Positionskodierungen.
Relative Positionskodierung
Da die Leistung von APE bei der Längenextrapolation unbefriedigend ist, verfügt RPE aufgrund seiner Verschiebungsinvarianz natürlich über bessere Extrapolationsfähigkeiten, und es wird allgemein angenommen, dass im Kontext die relative Reihenfolge der Wörter wichtiger ist . In den letzten Jahren hat sich RPE zur dominierenden Methode zur Kodierung von Positionsinformationen entwickelt.
Frühe RPEs entstanden aus einfachen Modifikationen sinusförmiger Positionskodierungen, oft kombiniert mit Pruning- oder Binning-Strategien, um Positionseinbettungen außerhalb der Verteilung zu vermeiden, die als vorteilhaft für die Extrapolation angesehen wurden. Da RPE außerdem die Eins-zu-Eins-Entsprechung zwischen Position und Positionsdarstellung entkoppelt, wird das direkte Hinzufügen des Bias-Terms zur Aufmerksamkeitsformel zu einer praktikablen oder sogar besseren Möglichkeit, Positionsinformationen in Transformer zu integrieren. Dieser Ansatz ist viel einfacher und entwirrt auf natürliche Weise den Wertvektor und die Positionsinformationen. Obwohl diese Bias-Methoden starke Extrapolationseigenschaften haben, können sie jedoch keine komplexen Abstandsfunktionen wie bei RoPE (Rotary Position Embedding) darstellen. Obwohl RoPE eine schlechte Extrapolation aufweist, hat es sich aufgrund seiner hervorragenden Gesamtleistung in letzter Zeit zur gängigsten Positionscodierung für LLMs entwickelt. Alle im Papier eingeführten extrapolierbaren PEs sind in Tabelle 1 aufgeführt.
Extrapolationsmethoden im Zeitalter großer Modelle
Um die Längenextrapolationsfähigkeiten von LLMs zu verbessern, haben Forscher eine Vielzahl von Methoden vorgeschlagen, die auf der vorhandenen Positionscodierung basieren und hauptsächlich in Positionsinterpolation (Position) unterteilt sind Interpolation) und randomisierte Positionskodierung (Randomized Position Encoding) sind zwei Kategorien.
Positionsinterpolationsmethode
Die Positionsinterpolationsmethode skaliert die Positionscodes während der Inferenz, sodass die Positionscodes, die ursprünglich die Modelltrainingslänge überschreiten, nach der Interpolation in das trainierte Positionsintervall fallen. Positionsinterpolationsmethoden haben aufgrund ihrer hervorragenden Extrapolationsleistung und ihres äußerst geringen Overheads großes Interesse in der Forschungsgemeinschaft geweckt. Darüber hinaus werden Positionsinterpolationsmethoden im Gegensatz zu anderen Extrapolationsmethoden häufig in Open-Source-Modellen wie Code Llama, Qwen-7B und Llama2 verwendet. Aktuelle Interpolationsmethoden konzentrieren sich jedoch nur auf RoPE, und es muss noch erforscht werden, wie LLM mithilfe anderer PEs bessere Extrapolationsfähigkeiten durch Interpolation erhalten kann.
Randomisierte Positionskodierung
Einfach ausgedrückt entkoppelt Randomized PE einfach die vorab trainierten Kontextfenster von längeren Inferenzlängen, indem es während des Trainings zufällige Positionen einführt, wodurch die langfristige Leistung verbessert wird Kontextfenster. Es ist erwähnenswert, dass sich die Idee der randomisierten PE stark von der Positionsinterpolationsmethode unterscheidet. Erstere zielt darauf ab, dass das Modell während des Trainings alle möglichen Positionen beobachtet, während letztere versucht, die Positionen während der Inferenz so zu interpolieren, dass sie hineinfallen einem vorher festgelegten Ort. Aus dem gleichen Grund sind Positionsinterpolationsmethoden meist Plug-and-Play-Methoden, während randomisierte PE häufig eine weitere Feinabstimmung erfordert, was die Positionsinterpolation attraktiver macht. Diese beiden Methodenkategorien schließen sich jedoch nicht gegenseitig aus und können daher kombiniert werden, um die Extrapolationsfähigkeiten des Modells weiter zu verbessern.
Herausforderungen und zukünftige Richtungen
Bewertungs- und Benchmark-Datensätze: In frühen Untersuchungen erfolgte die Bewertung der Extrapolationsfähigkeiten von Transformer anhand der Leistungsbewertungsindikatoren verschiedener nachgelagerter Aufgaben, wie z. B. BLEU der maschinellen Übersetzung; Da Sprachmodelle wie T5 und GPT2 schrittweise Aufgaben zur Verarbeitung natürlicher Sprache vereinheitlichen, ist die bei der Sprachmodellierung verwendete Verwirrung zu einem Bewertungsindex für die Extrapolation geworden. Die neuesten Untersuchungen haben jedoch gezeigt, dass Perplexität nicht die Leistung nachgelagerter Aufgaben aufzeigen kann. Daher besteht ein dringender Bedarf an dedizierten Benchmark-Datensätzen und Bewertungsmetriken, um die weitere Entwicklung im Bereich der Längenextrapolation voranzutreiben.
Theoretische Erklärung: Die aktuellen Arbeiten zur Längenextrapolation sind größtenteils empirisch. Obwohl es einige vorläufige Versuche gibt, die erfolgreiche Extrapolation des Modells zu erklären, wurde noch keine solide theoretische Grundlage geschaffen Und wie die Leistung der Längenextrapolation beeinflusst wird, bleibt eine offene Frage.
Andere Methoden: Wie in diesem Artikel erwähnt, konzentrieren sich die meisten vorhandenen Arbeiten zur Längenextrapolation auf die Positionskodierungsperspektive, es ist jedoch nicht schwer zu verstehen, dass die Längenextrapolation ein systematisches Design erfordert. Die Positionskodierung ist eine Schlüsselkomponente, aber keineswegs die einzige, und eine umfassendere Betrachtung wird das Problem noch weiter verschärfen.
Das obige ist der detaillierte Inhalt vonAnwendung der Positionskodierung in Transformer: Erkundung der unendlichen Möglichkeiten der Längenextrapolation. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Standort: Remote-Büro-Jobtyp: Vollzeitgehalt: 130.000 bis 140.000 US-Dollar Stellenbeschreibung Nehmen Sie an der Forschung und Entwicklung von Mobilfunkanwendungen und öffentlichen API-bezogenen Funktionen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken. Die Hauptaufgaben erledigen die Entwicklungsarbeit unabhängig von RubyonRails und arbeiten mit dem Front-End-Team von React/Redux/Relay zusammen. Erstellen Sie die Kernfunktionalität und -verbesserungen für Webanwendungen und arbeiten Sie eng mit Designer und Führung während des gesamten funktionalen Designprozesses zusammen. Fördern Sie positive Entwicklungsprozesse und priorisieren Sie die Iterationsgeschwindigkeit. Erfordert mehr als 6 Jahre komplexes Backend für Webanwendungen
 Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
MySQL kann JSON -Daten zurückgeben. Die JSON_EXTRACT -Funktion extrahiert Feldwerte. Über komplexe Abfragen sollten Sie die Where -Klausel verwenden, um JSON -Daten zu filtern, aber auf die Leistungsauswirkungen achten. Die Unterstützung von MySQL für JSON nimmt ständig zu, und es wird empfohlen, auf die neuesten Versionen und Funktionen zu achten.
 Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Detaillierte Erläuterung von Datenbanksäureattributen Säureattribute sind eine Reihe von Regeln, um die Zuverlässigkeit und Konsistenz von Datenbanktransaktionen sicherzustellen. Sie definieren, wie Datenbanksysteme Transaktionen umgehen, und sorgen dafür, dass die Datenintegrität und -genauigkeit auch im Falle von Systemabstürzen, Leistungsunterbrechungen oder mehreren Benutzern gleichzeitiger Zugriff. Säureattributübersicht Atomizität: Eine Transaktion wird als unteilbare Einheit angesehen. Jeder Teil schlägt fehl, die gesamte Transaktion wird zurückgerollt und die Datenbank behält keine Änderungen bei. Wenn beispielsweise eine Banküberweisung von einem Konto abgezogen wird, jedoch nicht auf ein anderes erhöht wird, wird der gesamte Betrieb widerrufen. begintransaktion; updateAccountsSetBalance = Balance-100WH
 MySQL kann nach dem Herunterladen nicht installiert werden
Apr 08, 2025 am 11:24 AM
MySQL kann nach dem Herunterladen nicht installiert werden
Apr 08, 2025 am 11:24 AM
Die Hauptgründe für den Fehler bei MySQL -Installationsfehlern sind: 1. Erlaubnisprobleme, Sie müssen als Administrator ausgeführt oder den Sudo -Befehl verwenden. 2. Die Abhängigkeiten fehlen, und Sie müssen relevante Entwicklungspakete installieren. 3. Portkonflikte müssen Sie das Programm schließen, das Port 3306 einnimmt, oder die Konfigurationsdatei ändern. 4. Das Installationspaket ist beschädigt. Sie müssen die Integrität herunterladen und überprüfen. 5. Die Umgebungsvariable ist falsch konfiguriert und die Umgebungsvariablen müssen korrekt entsprechend dem Betriebssystem konfiguriert werden. Lösen Sie diese Probleme und überprüfen Sie jeden Schritt sorgfältig, um MySQL erfolgreich zu installieren.
 Der Hauptschlüssel von MySQL kann null sein
Apr 08, 2025 pm 03:03 PM
Der Hauptschlüssel von MySQL kann null sein
Apr 08, 2025 pm 03:03 PM
Der MySQL -Primärschlüssel kann nicht leer sein, da der Primärschlüssel ein Schlüsselattribut ist, das jede Zeile in der Datenbank eindeutig identifiziert. Wenn der Primärschlüssel leer sein kann, kann der Datensatz nicht eindeutig identifiziert werden, was zu Datenverwirrung führt. Wenn Sie selbstsinkrementelle Ganzzahlsspalten oder UUIDs als Primärschlüssel verwenden, sollten Sie Faktoren wie Effizienz und Raumbelegung berücksichtigen und eine geeignete Lösung auswählen.
