
 Technologie-Peripheriegeräte
KI
ReSimAD: Wie man die Generalisierungsleistung von Wahrnehmungsmodellen durch virtuelle Daten verbessert
Technologie-Peripheriegeräte
KI
ReSimAD: Wie man die Generalisierungsleistung von Wahrnehmungsmodellen durch virtuelle Daten verbessert
ReSimAD: Wie man die Generalisierungsleistung von Wahrnehmungsmodellen durch virtuelle Daten verbessert

Oben geschrieben und das persönliche Verständnis des Autors
Domänenänderungen auf der Sensorebene autonomer Fahrzeuge sind ein sehr häufiges Phänomen, wie z. B. autonome Fahrzeuge in verschiedenen Szenen und Orten, autonome Fahrzeuge unter unterschiedlichen Licht- und Wetterbedingungen, autonome Fahrzeuge, die mit ausgestattet sind Aufgrund der unterschiedlichen Sensorausstattung können die oben genannten als klassische Unterschiede im Bereich des autonomen Fahrens angesehen werden. Dieser Domänenunterschied stellt das autonome Fahren vor Herausforderungen, vor allem weil autonome Fahrmodelle, die auf altem Domänenwissen basieren, ohne zusätzliche Kosten nur schwer direkt in einer neuen, noch nie dagewesenen Domäne implementiert werden können. Daher schlagen wir in diesem Artikel ein Rekonstruktions-Simulations-Bewusstseinsschema (ReSimAD) vor, um eine neue Perspektive und Methode für die Domänenmigration bereitzustellen. Insbesondere verwenden wir die implizite Rekonstruktionstechnologie, um altes Domänenwissen in der Fahrszene zu erhalten. Der Zweck des Rekonstruktionsprozesses besteht darin, zu untersuchen, wie domänenbezogenes Wissen in der alten Domäne in domäneninvariante Darstellungen umgewandelt werden kann Beispielsweise glauben wir, dass 3D-Netzdarstellungen auf Szenenebene (3D-Netzdarstellungen) eine domäneninvariante Darstellung sind. Basierend auf den rekonstruierten Ergebnissen verwenden wir außerdem den Simulator, um eine realistischere Simulationspunktwolke ähnlich der Zieldomäne zu generieren. Dieser Schritt basiert auf den rekonstruierten Hintergrundinformationen und der Sensorlösung der Zieldomäne, wodurch die Erfassungs- und Kennzeichnungszeit verkürzt wird der anschließende Erfassungsprozess.
Wir haben im experimentellen Verifizierungsteil verschiedene domänenübergreifende Einstellungen berücksichtigt, darunter Waymo-to-KITTI, Waymo-to-nuScenes, Waymo-to-ONCE usw. Alle domänenübergreifenden Einstellungen übernehmen experimentelle Zero-Shot-Einstellungen und verlassen sich nur auf das Hintergrundnetz und die simulierten Sensoren der Quelldomäne, um Zieldomänenproben zu simulieren und so die Fähigkeiten zur Modellverallgemeinerung zu verbessern. Die Ergebnisse zeigen, dass ReSimAD die Generalisierungsfähigkeit des Wahrnehmungsmodells auf die Zieldomänenszene erheblich verbessern kann, sogar besser als einige unbeaufsichtigte Domänenanpassungsmethoden.
Papierinformationen

- Papiertitel: ReSimAD: Zero-Shot 3D Domain Transfer for Autonomous Driving with Source Reconstruction and Target Simulation
- ICLR-2024 akzeptiert
- Publikationseinheit: Shanghai Artificial Intelligence Laboratory, Shanghai Jiao Tong University, Fudan University, Beihang University
- Papieradresse: https://arxiv.org/abs/2309.05527
- Codeadresse: Simulationsdatensatz und Wahrnehmungsteil, https://github.com/PJLab-ADG /3DTrans #resimad; Quelldomänen-Rekonstruktionsteil, https://github.com/pjlab-ADG/neuralsim; Zieldomänen-Simulationsteil, https://github.com/PJLab-ADG/PCSim
Forschungsmotivation
Herausforderung: Obwohl 3D-Modelle selbstfahrenden Autos dabei helfen können, ihre Umgebung zu erkennen, lassen sich bestehende Basismodelle nur schwer auf neue Bereiche übertragen (z. B. unterschiedliche Sensoreinstellungen oder unsichtbare Städte). Die langfristige Vision im Bereich des autonomen Fahrens besteht darin, Modellen eine Domänenmigration zu geringeren Kosten zu ermöglichen, d Es gibt jeweils zwei Domänen mit offensichtlichen Datenverteilungsunterschieden. Beispielsweise ist die Quelldomäne ein 64-Strahl-Sensor und die Zieldomäne ein Regen-Sensor.
Häufig verwendete Lösungsideen: Angesichts der oben genannten Domänenunterschiede besteht die häufigste Lösung darin, Daten für die Zieldomänenszene abzurufen und zu kommentieren. Mit dieser Methode kann die durch Domänenunterschiede verursachte Verschlechterung der Modellleistung bis zu einem gewissen Grad vermieden werden. Problem, aber es gibt enorme 1) Kosten für die Datenerfassung und 2) Kosten für die Datenkennzeichnung. Daher kann, wie in der folgenden Abbildung gezeigt (siehe die beiden Basismethoden (a) und (b)), die Simulations-Engine zum Rendern einiger Simulationen verwendet werden, um die Kosten für die Datenerfassung und Datenanmerkung für eine neue Domäne zu senken Punktwolkenbeispiele Dies sind gängige Lösungsideen für Sim-to-Real-Forschungsarbeiten. Eine weitere Idee ist die unbeaufsichtigte Domänenanpassung (UDA für 3D). Der Zweck dieser Art von Arbeit besteht darin, zu untersuchen, wie eine annähernd vollständig überwachte Feinabstimmung unter der Bedingung erreicht werden kann, dass nur unbeschriftete Zieldomänendaten verfügbar gemacht werden (beachten Sie, dass es sich um echte Daten handelt). ) Wenn dies erreicht werden kann, werden tatsächlich die Kosten für die Kennzeichnung der Zieldomäne eingespart. Die UDA-Methode muss jedoch immer noch eine große Menge realer Zieldomänendaten sammeln, um die Datenverteilung der Zieldomäne zu charakterisieren.
Abbildung 1: Vergleich verschiedener TrainingsparadigmenUnsere Idee: Anders als die Forschungsideen in den beiden oben genannten Kategorien, wie in der Abbildung unten dargestellt (siehe (c) Basisprozess), haben wir uns dem Datensimulations-Wahrnehmungs-Integrationsweg der Kombination von Virtuellem und Realem verschrieben. Darin bezieht sich die Realität auf: Erstellen einer domäneninvarianten Darstellung basierend auf massiven beschrifteten Quelldomänendaten. Diese Annahme ist für viele Szenarien von praktischer Bedeutung, da wir nach einer langfristigen historischen Datenakkumulation immer davon ausgehen können, dass diese kommentierten Quelldomänendaten vorhanden sind ; Andererseits bedeutet Simulation in der Kombination von virtuellen und realen Mitteln: Nachdem wir eine domäneninvariante Darstellung basierend auf den Quelldomänendaten erstellt haben, kann diese Darstellung in die vorhandene Rendering-Pipeline importiert werden, um eine Simulation der Zieldomänendaten durchzuführen. Im Vergleich zu aktuellen Sim-to-Real-Forschungsarbeiten wird unsere Methode durch reale Daten auf Szenenebene unterstützt, einschließlich realer Informationen wie Straßenstruktur, Steigungen und Gefälle usw. Diese Informationen allein durch die Simulations-Engine zu erhalten, ist schwierig selbst. Nachdem wir Daten in der Zieldomäne erhalten haben, integrieren wir die Daten zum Training in das beste aktuelle Wahrnehmungsmodell, wie z. B. PV-RCNN, und überprüfen dann die Genauigkeit des Modells in der Zieldomäne. Den gesamten detaillierten Arbeitsablauf finden Sie in der folgenden Abbildung:
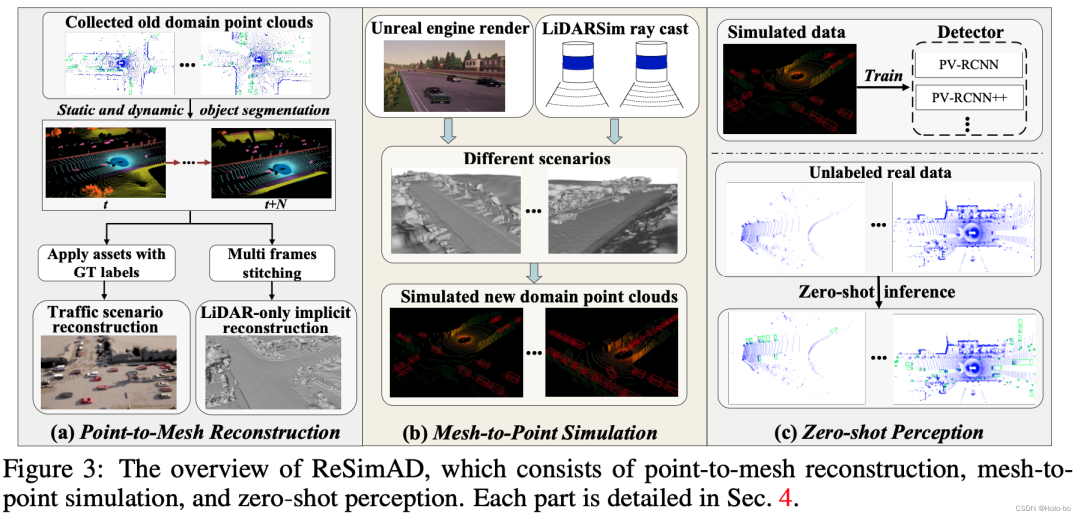 Abbildung 2 ReSimAD-Flussdiagramm
Abbildung 2 ReSimAD-Flussdiagramm
Das Flussdiagramm von ReSimAD ist in Abbildung 2 dargestellt, das hauptsächlich a) impliziten Point-to-Mesh-Rekonstruktionsprozess , umfasst b) Rendering-Prozess der Mesh-to-Point-Simulations-Engine , c) Zero-Sample-Wahrnehmungsprozess .
ReSimAD: Simulations-Rekonstruktions-Wahrnehmungsparadigma
a) Impliziter Point-to-Mesh-Rekonstruktionsprozess: Inspiriert von StreetSurf verwenden wir nur Lidar-Rekonstruktion, um realistische und vielfältige Straßenszenenhintergründe und dynamische Verkehrsflussinformationen zu rekonstruieren. Wir haben zunächst ein reines Punktwolken-SDF-Rekonstruktionsmodul (LiDAR-only Implicit Neural Reconstruction, LINR) entwickelt. Sein Vorteil besteht darin, dass es nicht von einigen Domänenunterschieden beeinflusst wird, die durch die Kameraerfassung verursacht werden, wie z. B. Änderungen der Beleuchtung, Änderungen der Wetterbedingungen. usw. . Das SDF-Rekonstruktionsmodul für reine Punktwolken verwendet LiDAR-Strahlen als Eingabe, sagt dann Tiefeninformationen voraus und erstellt schließlich eine 3D-Netzdarstellung der Szene.
Konkret wenden wir für das Licht 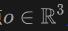 , das vom Ursprung
, das vom Ursprung 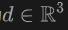 in die Richtung
in die Richtung 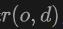 emittiert wird, Volumenrendering auf das Lidar an, um das Signed Distance Field (SDF)-Netzwerk zu trainieren, und die Renderingtiefe D kann wie folgt formuliert werden:
emittiert wird, Volumenrendering auf das Lidar an, um das Signed Distance Field (SDF)-Netzwerk zu trainieren, und die Renderingtiefe D kann wie folgt formuliert werden:
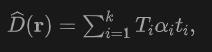
wo ist die Abtasttiefe 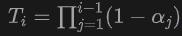 eines Abtastpunkts die akkumulierte Transmission, die durch Verwendung des Nahbereichsmodells in NeuS erhalten wird.
eines Abtastpunkts die akkumulierte Transmission, die durch Verwendung des Nahbereichsmodells in NeuS erhalten wird.
Inspiriert von StreetSurf stammt die Modelleingabe des in diesem Artikel vorgeschlagenen Rekonstruktionsprozesses aus Lidar-Strahlen und die Ausgabe ist die vorhergesagte Tiefe. Auf jeden abgetasteten Lidar-Strahl  wenden wir einen logarithmischen L1-Verlust auf
wenden wir einen logarithmischen L1-Verlust auf 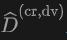 an, d. Aufgrund der inhärenten spärlichen Datenmenge, die von LIDAR erfasst wird, kann ein einzelner LIDAR-Punktwolkenrahmen nur einen Teil der in einem Standard-RGB-Bild enthaltenen Informationen erfassen. Dieser Unterschied verdeutlicht die potenziellen Mängel der Tiefendarstellung bei der Bereitstellung der notwendigen geometrischen Details für ein effektives Training. Dies kann daher zu einer großen Anzahl von Artefakten innerhalb des resultierenden rekonstruierten Netzes führen. Um dieser Herausforderung zu begegnen, schlagen wir vor, alle Frames in einer Waymo-Sequenz zusammenzufügen, um die Dichte der Punktwolke zu erhöhen.
an, d. Aufgrund der inhärenten spärlichen Datenmenge, die von LIDAR erfasst wird, kann ein einzelner LIDAR-Punktwolkenrahmen nur einen Teil der in einem Standard-RGB-Bild enthaltenen Informationen erfassen. Dieser Unterschied verdeutlicht die potenziellen Mängel der Tiefendarstellung bei der Bereitstellung der notwendigen geometrischen Details für ein effektives Training. Dies kann daher zu einer großen Anzahl von Artefakten innerhalb des resultierenden rekonstruierten Netzes führen. Um dieser Herausforderung zu begegnen, schlagen wir vor, alle Frames in einer Waymo-Sequenz zusammenzufügen, um die Dichte der Punktwolke zu erhöhen.
Aufgrund der Einschränkung des vertikalen Sichtfelds des Top LiDAR im Waymo-Datensatz hat die ausschließliche Erfassung von Punktwolken zwischen -17,6° und 2,4° offensichtliche Einschränkungen bei der Rekonstruktion umliegender Hochhäuser. Um dieser Herausforderung zu begegnen, stellen wir eine Lösung vor, die Punktwolken von Side LiDAR in eine Abtastsequenz zur Rekonstruktion integriert. An der Vorder-, Rückseite und an zwei Seiten des autonomen Fahrzeugs sind vier blindfüllende Radare mit einem vertikalen Sichtfeld von [-90°, 30°] installiert, was die Mängel der unzureichenden Sichtfeldreichweite von wirksam ausgleicht das obere Lidar. Aufgrund der unterschiedlichen Punktwolkendichte zwischen seitlichem und oberem LIDAR entscheiden wir uns dafür, dem seitlichen LIDAR ein höheres Stichprobengewicht zuzuweisen, um die Rekonstruktionsqualität von Hochhausszenen zu verbessern.
Bewertung der Rekonstruktionsqualität: Aufgrund der durch dynamische Objekte verursachten Verdeckung und des Einflusses von LIDAR-Rauschen kann eine implizite Darstellung in einer bestimmten Menge an Rauschen für die Rekonstruktion vorhanden sein. Daher haben wir die Rekonstruktionsgenauigkeit bewertet. Da wir umfangreiche annotierte Punktwolkendaten aus der alten Domäne erhalten können, können wir die simulierten Punktwolkendaten der alten Domäne durch erneutes Rendern in der alten Domäne erhalten, um die Genauigkeit des rekonstruierten Netzes zu bewerten. Wir messen die simulierte Punktwolke und die ursprüngliche reale Punktwolke unter Verwendung des quadratischen Mittelfehlers (RMSE) und des Fasenabstands (CD):
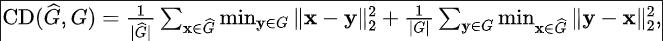
Die Rekonstruktionsbewertung jeder Sequenz und die Beschreibung einiger detaillierter Prozesse finden Sie hier zum Originalanhang.
b) Mesh-to-Point-Simulations-Engine-Rendering-Prozess: Nachdem wir das statische Hintergrundnetz über die obige LINR-Methode erhalten haben, verwenden wir die Blender Python API, um die Netzdaten vom .ply-Format in 3D in .fbx zu konvertieren Modelldateien formatieren und schließlich das Hintergrundnetz als Asset-Bibliothek in den Open-Source-Simulator CARLA laden.
Wir rufen zunächst die Anmerkungsdatei von Waymo ab, um die Begrenzungsrahmenkategorie und die dreidimensionale Objektgröße jedes Verkehrsteilnehmers zu ermitteln. Basierend auf diesen Informationen suchen wir in der digitalen Asset-Bibliothek von CARLA nach den Verkehrsteilnehmern derselben Kategorie mit der größten Größe Assets und importieren Sie dieses digitale Asset als Verkehrsteilnehmermodell. Basierend auf den im CARLA-Simulator verfügbaren Informationen zur Szenenauthentizität haben wir für jedes erkennbare Objekt in der Verkehrsszene ein Erkennungsbox-Extraktionstool entwickelt. Einzelheiten finden Sie unter PCSim Development Tools.
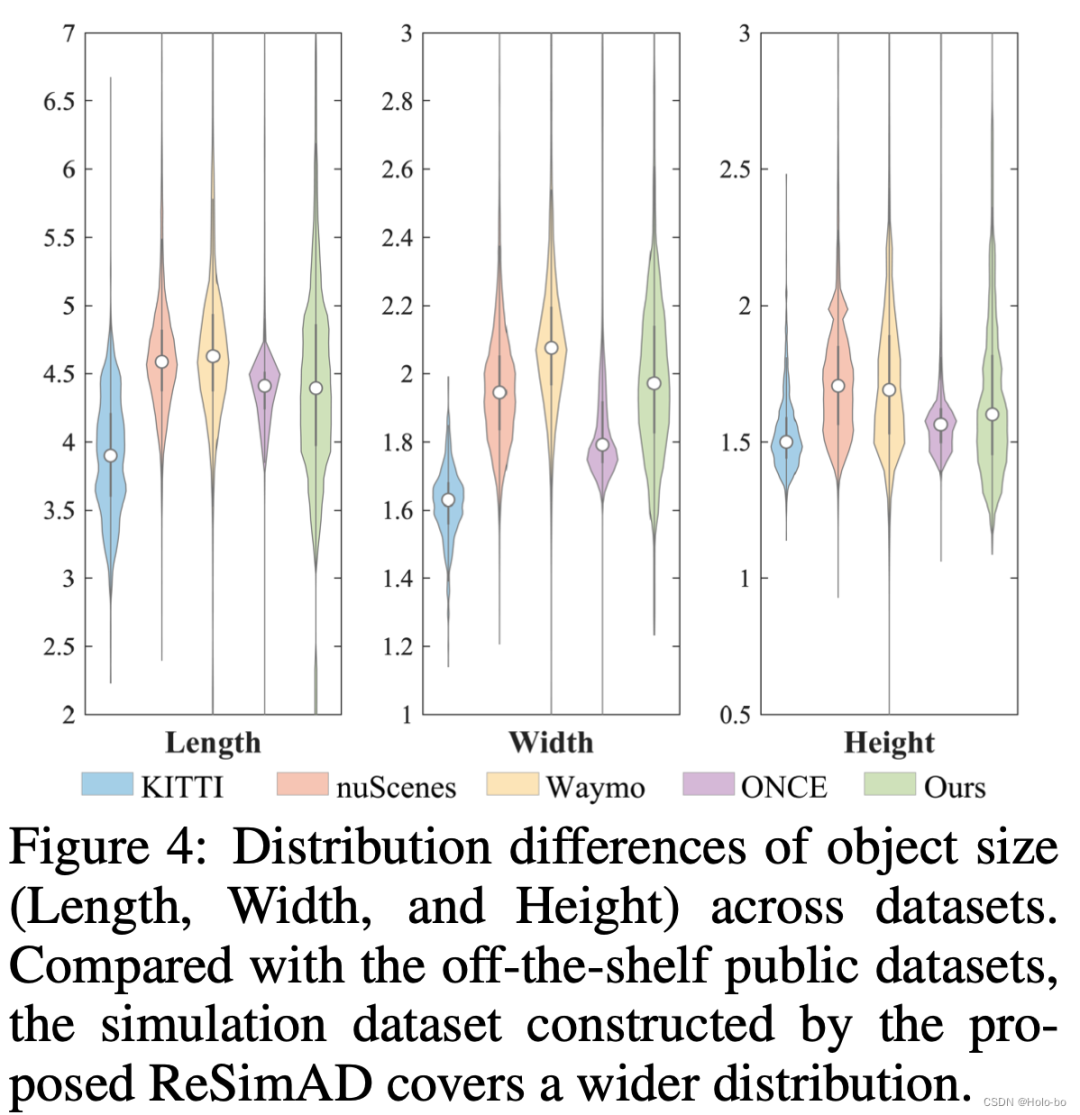 Abbildung 3 Verteilung der Objektgrößen (Länge, Breite, Höhe) von Verkehrsteilnehmern in verschiedenen Datensätzen. Wie aus Abbildung 3 ersichtlich ist, ist die Verteilungsvielfalt der mit dieser Methode simulierten Objektgrößen sehr groß und übertrifft derzeit veröffentlichte Datensätze wie KITTI, nuScenes, Waymo, ONCE usw.
Abbildung 3 Verteilung der Objektgrößen (Länge, Breite, Höhe) von Verkehrsteilnehmern in verschiedenen Datensätzen. Wie aus Abbildung 3 ersichtlich ist, ist die Verteilungsvielfalt der mit dieser Methode simulierten Objektgrößen sehr groß und übertrifft derzeit veröffentlichte Datensätze wie KITTI, nuScenes, Waymo, ONCE usw.
Wir verwenden Waymo als Quelldomänendaten und rekonstruieren sie auf Waymo, um ein realistischeres 3D-Netz zu erhalten. Gleichzeitig verwenden wir KITTI, nuScenes und ONCE als Zieldomänenszenarien und überprüfen die von unserer Methode erzielte Zero-Shot-Leistung in diesen Zieldomänenszenarien.
Wir generieren 3D-Netzdaten auf Szenenebene basierend auf dem Waymo-Datensatz gemäß der Einführung im obigen Kapitel und verwenden die oben genannten Bewertungskriterien, um zu bestimmen, welche 3D-Netze unter der Waymo-Domäne von hoher Qualität sind, und wählen die höchsten 146 aus Netze basierend auf den Ergebnissen. Der anschließende Simulationsprozess der Zieldomäne.
Bewertungsergebnisse
 Einige Visualisierungsbeispiele für den ResimAD-Datensatz sind unten aufgeführt:
Einige Visualisierungsbeispiele für den ResimAD-Datensatz sind unten aufgeführt:
Bewertungsergebnisse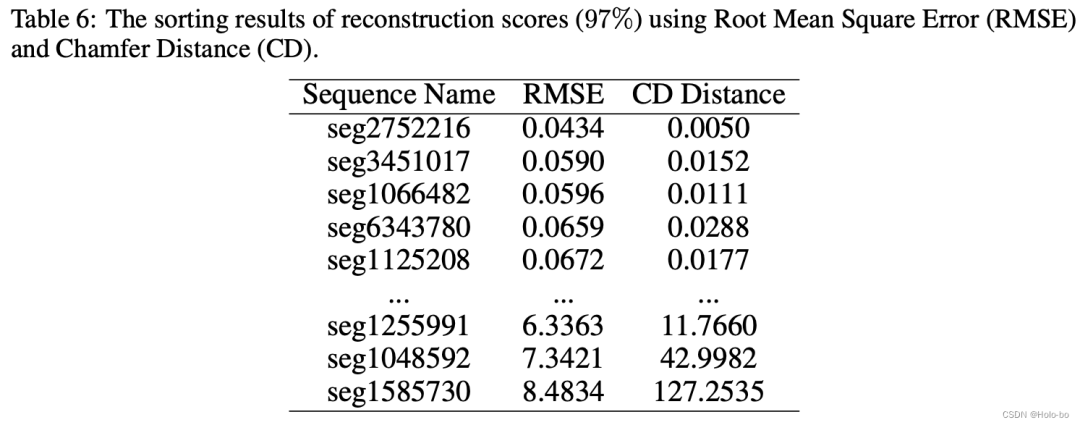 Einige Visualisierungsbeispiele für den ResimAD-Datensatz sind unten aufgeführt:
Einige Visualisierungsbeispiele für den ResimAD-Datensatz sind unten aufgeführt: 
Experimenteller Aufbau
Basisauswahl: Wir vergleichen die vorgeschlagenen ReSim AD mit drei typischen Kreuzen -Domänen-Basislinien werden verglichen: a) eine Basislinie, die die Simulations-Engine direkt für die Datensimulation verwendet; b) eine Basislinie, die eine Datensimulation durchführt, indem die Sensorparametereinstellungen in der Simulations-Engine geändert werden; c) Domänenanpassungs-Baseline (UDA). Metrik: Wir gleichen die aktuellen Bewertungsstandards für die domänenübergreifende 3D-Objekterkennung aus und verwenden BEV-basierte bzw. 3D-basierte AP als Bewertungsmetriken.
- Parametereinstellungen: Einzelheiten finden Sie im Dokument.
- Experimentelle Ergebnisse
Nur die wichtigsten experimentellen Ergebnisse finden Sie in unserem Dokument.
Anpassungsleistung von PV-RCNN/PV-RCNN++-Modellen unter drei domänenübergreifenden Einstellungen
Aus der obigen Tabelle können wir Folgendes beobachten: Der Hauptunterschied zwischen UDA und ReSimAD unter Verwendung der UDA-Technologie (Unsupervised Domain Adaptation) besteht darin, dass erstere Beispiele der Zieldomäne „echte Szenen“ für die Modelldomänenmigration verwendet, während die experimentellen Einstellungen von ReSimAD It erfordert, dass es nicht auf echte Punktwolkendaten in der Zieldomäne zugreifen kann. Wie aus der obigen Tabelle ersichtlich ist, sind die von unserem ReSimAD erzielten domänenübergreifenden Ergebnisse mit denen der UDA-Methode vergleichbar. Dieses Ergebnis zeigt, dass unsere Methode die Kosten für die Datenerfassung erheblich senken und den Umschulungs- und Neuentwicklungszyklus des Modells aufgrund von Domänenunterschieden weiter verkürzen kann, wenn der Lidar-Sensor für kommerzielle Zwecke aufgerüstet werden muss. ReSimAD-Daten werden als Kaltstartdaten der Zieldomäne verwendet, und der Effekt, der auf die Zieldomäne erzielt werden kann
Ein weiterer Vorteil der Verwendung der von ReSimAD generierten Daten besteht darin, dass sie ohne Zugriff verwendet werden können Gleichzeitig kann jede reale Datenverteilung der Zieldomäne erreicht werden. Dieser Prozess ähnelt tatsächlich dem „Kaltstart“-Prozess des autonomen Fahrmodells in neuen Szenarien.
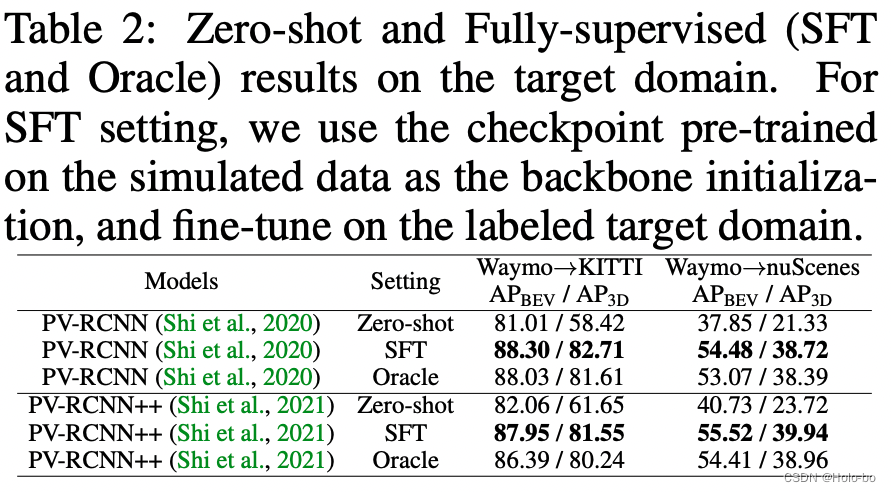 Die obige Tabelle zeigt die experimentellen Ergebnisse unter der vollständig überwachten Zieldomäne. Oracle stellt das Ergebnis des Modelltrainings auf der gesamten Menge der gekennzeichneten Zieldomänendaten dar, während SFT darstellt, dass die Netzwerkinitialisierungsparameter des Basismodells durch die Gewichtungen bereitgestellt werden, die auf den ReSimAD-Simulationsdaten trainiert werden. Die obige experimentelle Tabelle zeigt, dass die mit unserer ReSimAD-Methode simulierte Punktwolke höhere Initialisierungsgewichtungsparameter erhalten kann und ihre Leistung die experimentellen Oracle-Einstellungen übertrifft.
Die obige Tabelle zeigt die experimentellen Ergebnisse unter der vollständig überwachten Zieldomäne. Oracle stellt das Ergebnis des Modelltrainings auf der gesamten Menge der gekennzeichneten Zieldomänendaten dar, während SFT darstellt, dass die Netzwerkinitialisierungsparameter des Basismodells durch die Gewichtungen bereitgestellt werden, die auf den ReSimAD-Simulationsdaten trainiert werden. Die obige experimentelle Tabelle zeigt, dass die mit unserer ReSimAD-Methode simulierte Punktwolke höhere Initialisierungsgewichtungsparameter erhalten kann und ihre Leistung die experimentellen Oracle-Einstellungen übertrifft.
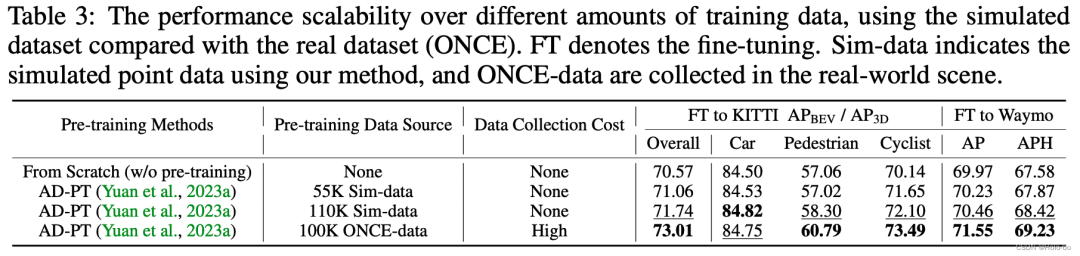
Um zu überprüfen, ob ReSimAD mehr Punktwolkendaten generieren kann, um die 3D-Vorbereitung zu unterstützen -Training, wir entwerfen Die folgenden Experimente wurden durchgeführt: AD-PT (eine kürzlich vorgeschlagene Methode zum Vortraining von Backbone-Netzwerken in autonomen Fahrszenarien) wurde verwendet, um das 3D-Backbone auf der simulierten Punktwolke vorab zu trainieren und dann das Downstream-Real Szenendaten wurden für die Feinabstimmung der vollständigen Parameter verwendet.
- Rekonstruierte Simulation mit ReSimAD vs. visueller Vergleich mit CARLA-Standardsimulation
Visueller Vergleich des Netzes, das wir basierend auf dem Waymo-Datensatz rekonstruiert haben, mit dem mit VDBFusion rekonstruierten Netz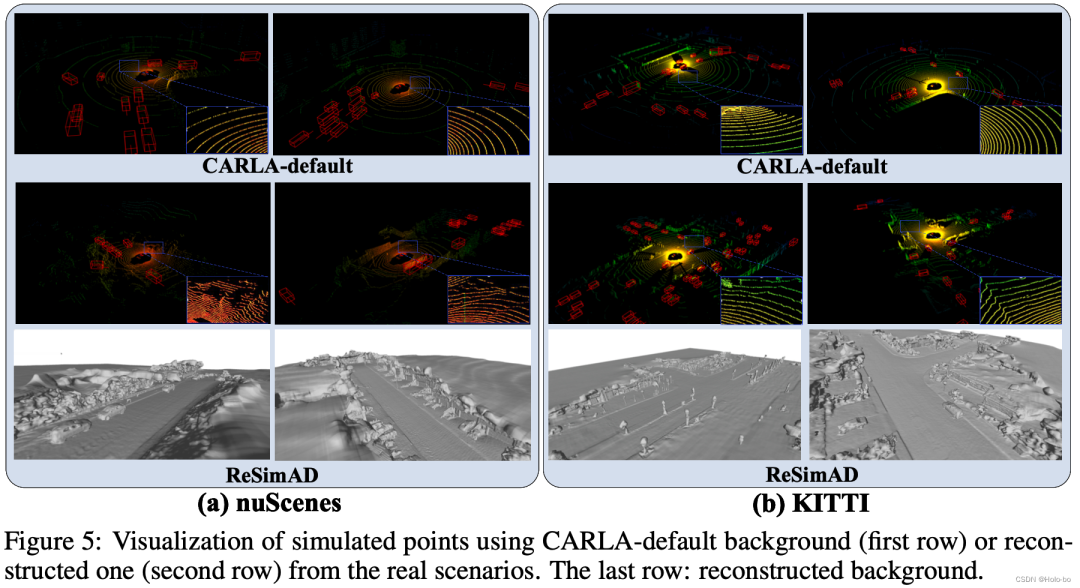
Zusammenfassung 
at In dieser Arbeit konzentrieren wir uns darauf, zu untersuchen, wie man mit Zero-Sample-Zieldomänenmodellübertragungsaufgaben experimentiert. Diese Aufgabe erfordert, dass das Modell das vorab trainierte Modell der Quelldomäne erfolgreich auf das Ziel übertragen kann, ohne dass es irgendwelchen ausgesetzt wird Beispieldateninformationen aus dem Zieldomänenszenario. Im Gegensatz zu früheren Arbeiten haben wir zum ersten Mal eine 3D-Datengenerierungstechnologie untersucht, die auf der impliziten Rekonstruktion der Quelldomäne und der Diversitätssimulation der Zieldomäne basiert, und überprüft, dass diese Technologie ein besseres Modell erzielen kann, ohne der Datenverteilung ausgesetzt zu sein Die Migrationsleistung ist sogar besser als bei einigen unüberwachten Domänenanpassungsmethoden (UDA).
Originallink: https://mp.weixin.qq.com/s/pmHFDvS7nXy-6AQBhvVzSwDas obige ist der detaillierte Inhalt vonReSimAD: Wie man die Generalisierungsleistung von Wahrnehmungsmodellen durch virtuelle Daten verbessert. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1384
1384
 52
52

 Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Gestern wurde ich während des Interviews gefragt, ob ich irgendwelche Long-Tail-Fragen gestellt hätte, also dachte ich, ich würde eine kurze Zusammenfassung geben. Das Long-Tail-Problem des autonomen Fahrens bezieht sich auf Randfälle bei autonomen Fahrzeugen, also mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. Das wahrgenommene Long-Tail-Problem ist einer der Hauptgründe, die derzeit den betrieblichen Designbereich intelligenter autonomer Einzelfahrzeugfahrzeuge einschränken. Die zugrunde liegende Architektur und die meisten technischen Probleme des autonomen Fahrens wurden gelöst, und die verbleibenden 5 % der Long-Tail-Probleme wurden nach und nach zum Schlüssel zur Einschränkung der Entwicklung des autonomen Fahrens. Zu diesen Problemen gehören eine Vielzahl fragmentierter Szenarien, Extremsituationen und unvorhersehbares menschliches Verhalten. Der „Long Tail“ von Randszenarien beim autonomen Fahren bezieht sich auf Randfälle in autonomen Fahrzeugen (AVs). Randfälle sind mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. diese seltenen Ereignisse
 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
