
 Technologie-Peripheriegeräte
KI
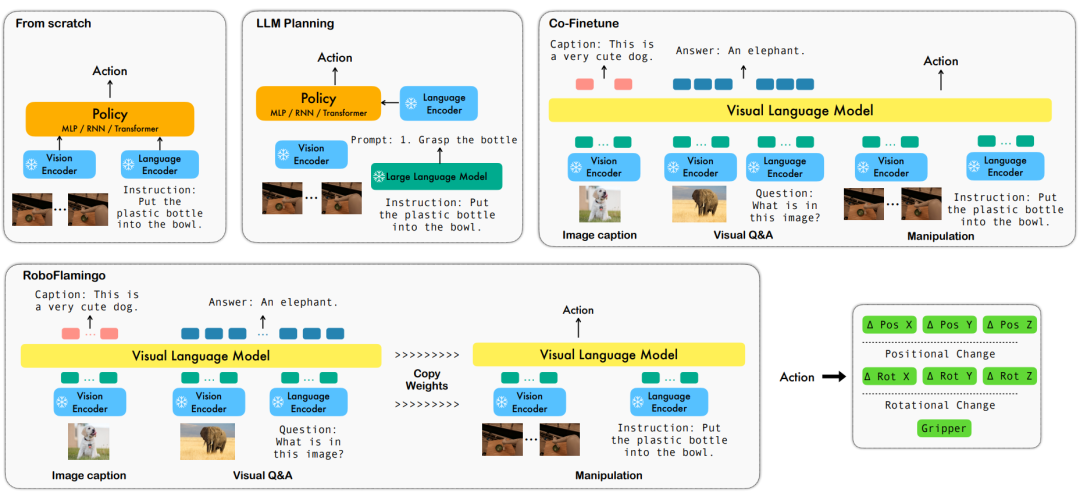
Das Potenzial von Open-Source-VLMs wird durch das RoboFlamingo-Framework freigesetzt
Technologie-Peripheriegeräte
KI
Das Potenzial von Open-Source-VLMs wird durch das RoboFlamingo-Framework freigesetzt
Das Potenzial von Open-Source-VLMs wird durch das RoboFlamingo-Framework freigesetzt

In den letzten Jahren hat sich die Forschung an großen Modellen beschleunigt und es wurden nach und nach multimodales Verständnis sowie Fähigkeiten zum zeitlichen und räumlichen Denken bei verschiedenen Aufgaben nachgewiesen. Verschiedene verkörperte Betriebsaufgaben von Robotern stellen natürlich hohe Anforderungen an das Sprachbefehlsverständnis, die Szenenwahrnehmung und die räumlich-zeitliche Planung. Dies führt natürlich zu der Frage: Können die Fähigkeiten großer Modelle vollständig genutzt und auf den Bereich der Robotik übertragen werden? die zugrunde liegende Handlungssequenz direkt planen?
ByteDance Research verwendet das Open-Source-Multimodal-Language-Vision-Großmodell OpenFlamingo, um ein benutzerfreundliches RoboFlamingo-Roboterbetriebsmodell zu entwickeln, das nur das Training einer einzelnen Maschine erfordert. VLM kann durch einfache Feinabstimmung in Robotics VLM umgewandelt werden, das für Sprachinteraktionsroboter-Betriebsaufgaben geeignet ist.
Verifiziert durch OpenFlamingo am Roboteroperationsdatensatz CALVIN. Experimentelle Ergebnisse zeigen, dass RoboFlamingo nur 1 % der Daten mit Sprachanmerkungen verwendet und bei einer Reihe von Roboterbetriebsaufgaben SOTA-Leistung erreicht. Mit der Eröffnung des RT-X-Datensatzes wird erwartet, dass RoboFlamingo, das auf Open-Source-Daten vorab trainiert und für verschiedene Roboterplattformen optimiert wurde, zu einem einfachen und effektiven groß angelegten Robotermodellprozess wird. Das Papier testete auch die Feinabstimmungsleistung von VLM mit unterschiedlichen Strategieköpfen, unterschiedlichen Trainingsparadigmen und unterschiedlichen Flamingo-Strukturen bei Roboteraufgaben und kam zu einigen interessanten Schlussfolgerungen.

- Projekthomepage: https://roboflamingo.github.io
- Codeadresse: https://github.com/RoboFlamingo/RoboFlamingo
- Papieradresse: https://arxiv.org/abs/2311.01378
Forschungshintergrund
Sprachbasierte Roboterbedienung ist eine wichtige Anwendung im Bereich der verkörperten Intelligenz, die multimodales Datenverständnis umfasst und Verarbeitung, einschließlich Sehen, Sprache und Kontrolle. In den letzten Jahren haben visuelle sprachbasierte Modelle (VLMs) erhebliche Fortschritte in Bereichen wie Bildbeschreibung, visuelle Beantwortung von Fragen und Bildgenerierung gemacht. Die Anwendung dieser Modelle auf Roboteroperationen steht jedoch noch vor Herausforderungen, beispielsweise bei der Integration visueller und sprachlicher Informationen und bei der Bewältigung der zeitlichen Abfolge von Roboteroperationen. Die Lösung dieser Herausforderungen erfordert Verbesserungen in mehreren Aspekten, wie z. B. die Verbesserung der multimodalen Darstellungsfähigkeiten des Modells, die Entwicklung effektiverer Modellfusionsmechanismen und die Einführung von Modellstrukturen und Algorithmen, die sich an die sequentielle Natur von Roboteroperationen anpassen. Darüber hinaus besteht Bedarf an der Entwicklung umfangreicherer Robotik-Datensätze, um diese Modelle zu trainieren und zu bewerten. Durch kontinuierliche Forschung und Innovation wird erwartet, dass sprachbasierte Roboteroperationen eine größere Rolle in praktischen Anwendungen spielen und dem Menschen intelligentere und komfortablere Dienste bieten.
Um diese Probleme zu lösen, hat das Robotik-Forschungsteam von ByteDance Research das bestehende Open-Source-VLM (Visual Language Model) – OpenFlamingo – verfeinert und ein neues visuelles Sprachmanipulations-Framework namens RoboFlamingo entworfen. Das Merkmal dieses Frameworks besteht darin, dass es VLM verwendet, um ein einstufiges visuelles Sprachverständnis zu erreichen, und historische Informationen über ein zusätzliches Richtlinienkopfmodul verarbeitet. Durch einfache Feinabstimmungsmethoden kann RoboFlamingo an sprachbasierte Roboterbedienungsaufgaben angepasst werden. Es wird erwartet, dass die Einführung dieses Frameworks eine Reihe von Problemen lösen wird, die bei aktuellen Roboteroperationen bestehen.
RoboFlamingo wurde anhand des sprachbasierten Roboteroperationsdatensatzes CALVIN verifiziert. Die experimentellen Ergebnisse zeigen, dass RoboFlamingo nur 1 % der sprachannotierten Daten nutzt und bei einer Reihe von Roboteroperationen eine SOTA-Leistung erreicht (mehr als 10 %). Die Erfolgsrate der Aufgabenfolge beim Aufgabenlernen beträgt 66 %, die durchschnittliche Anzahl der Aufgabenerledigungen beträgt 4,09, die durchschnittliche Anzahl der Aufgabenerledigungen beträgt 3,06; %, die durchschnittliche Anzahl der erledigten Aufgaben beträgt 2,48, die Basislinie Die Methode beträgt 1 %, die durchschnittliche Anzahl der erledigten Aufgaben beträgt 0,67) und kann durch Steuerung im offenen Regelkreis eine Echtzeitreaktion erreichen und kann flexibel auf niedrigeren Ebenen eingesetzt werden. Leistungsplattformen. Diese Ergebnisse zeigen, dass RoboFlamingo eine effektive Robotermanipulationsmethode ist und eine nützliche Referenz für zukünftige Roboteranwendungen bieten kann.
Methode
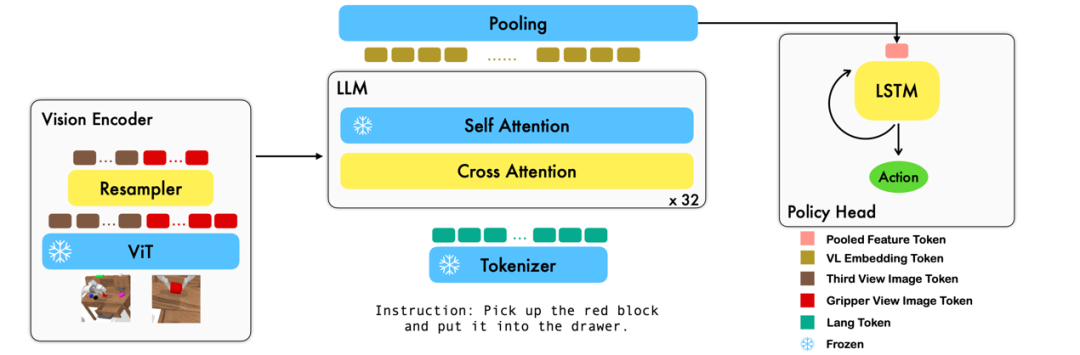
Diese Arbeit nutzt das vorhandene Grundmodell der visuellen Sprache basierend auf Bild-Text-Paaren, um die relativen Aktionen jedes Schritts des Roboters durch durchgängiges Training zu generieren. Das Modell besteht aus drei Hauptmodulen: Vision Encoder, Feature Fusion Decoder und Policy Head. Im Vision-Encoder-Modul wird die aktuelle visuelle Beobachtung zunächst in ViT eingegeben und dann wird der von ViT ausgegebene Token durch den Resampler heruntergesampelt. Dieser Schritt trägt dazu bei, die Eingabedimension des Modells zu reduzieren und dadurch die Trainingseffizienz zu verbessern. Das Feature-Fusion-Decoder-Modul verwendet Text-Tokens als Eingabe und verwendet die Ausgabe des visuellen Encoders als Abfrage über einen Kreuzaufmerksamkeitsmechanismus, wodurch die Fusion von visuellen und sprachlichen Features erreicht wird. In jeder Schicht führt der Feature-Fusion-Decoder zunächst die Queraufmerksamkeitsoperation und dann die Selbstaufmerksamkeitsoperation durch. Diese Operationen helfen dabei, Korrelationen zwischen Sprache und visuellen Merkmalen zu extrahieren, um Roboteraktionen besser zu generieren. Basierend auf den aktuellen und historischen Token-Sequenzen, die vom Feature-Fusion-Decoder ausgegeben werden, gibt der Policy-Kopf direkt die aktuellen 7 DoF-Relativaktionen aus, einschließlich der 6-Dim-Endposition des Roboterarms und des 1-Dim-Greifers Öffnen/Schließen. Führen Sie abschließend ein maximales Pooling für den Feature-Fusion-Decoder durch und senden Sie es an den Policy-Head, um relative Aktionen zu generieren. Auf diese Weise ist unser Modell in der Lage, visuelle und sprachliche Informationen effektiv zu verschmelzen, um präzise Roboterbewegungen zu erzeugen. Dies bietet breite Anwendungsaussichten in Bereichen wie der Robotersteuerung und der autonomen Navigation.
Während des Trainingsprozesses nutzt RoboFlamingo die vorab trainierten Parameter ViT, LLM und Cross Attention und passt nur die Parameter Resampler, Cross Attention und Policy Head fein an. Experimentelle Ergebnisse Im Vergleich zu vorhandenen Datensätzen zu visuell-linguistischen Aufgaben sind die Aufgaben von CALVIN hinsichtlich Sequenzlänge, Aktionsraum und Sprache komplexer und unterstützen eine flexible Spezifikation von Sensoreingaben. CALVIN ist in vier Abschnitte ABCD unterteilt, wobei jeder Abschnitt einem anderen Kontext und Layout entspricht.
Quantitative Analyse:
RoboFlamingo weist in allen Einstellungen und Indikatoren die beste Leistung auf, was zeigt, dass es über eine starke Nachahmungsfähigkeit, visuelle Generalisierungsfähigkeit und Sprachgeneralisierungsfähigkeit verfügt. Full und Lang geben an, ob das Modell mit ungepaarten visuellen Daten trainiert wurde (d. h. visuelle Daten ohne Sprachpaarung); „Enriched“ bezieht sich auf das Einfrieren der Einbettungsschicht des fusionierten Decoders; 
Ablationsexperimente:
Verschiedene Richtlinienköpfe: 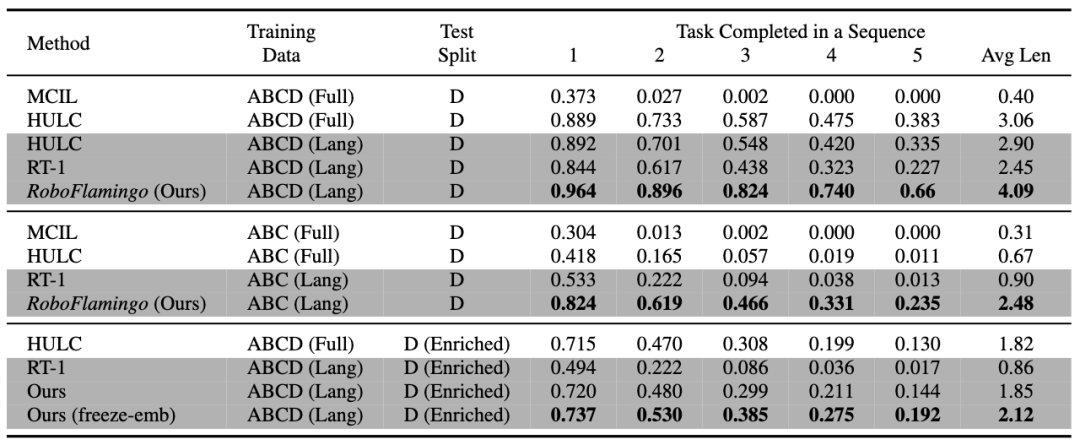
Die Experimente untersuchten vier verschiedene Richtlinienköpfe: MLP ohne Hist, MLP mit Hist, GPT und LSTM. Unter diesen prognostiziert MLP ohne Hist den Verlauf direkt auf der Grundlage aktueller Beobachtungen, und seine Leistung ist am schlechtesten. MLP mit Hist führt historische Beobachtungen am Ende des Vision-Encoders zusammen und sagt Aktionen voraus, und die Leistung wird explizit angegeben An der Spitze der Richtlinie werden implizit historische Informationen verwaltet, und ihre Leistung ist die beste, was die Wirksamkeit der Zusammenführung historischer Informationen durch die Leitung der Richtlinie veranschaulicht.
Die Wirkung des visuellen Sprachvortrainings:
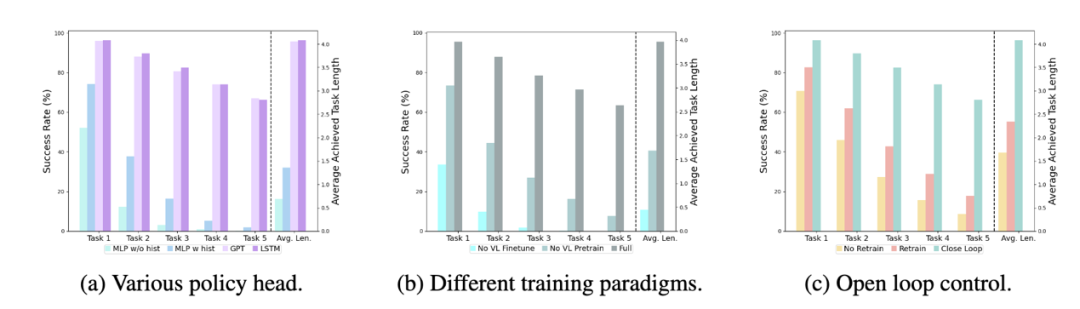 Vortraining spielt eine Schlüsselrolle bei der Verbesserung der Leistung von RoboFlamingo. Experimente zeigen, dass RoboFlamingo bei Roboteraufgaben eine bessere Leistung erbringt, indem es vorab anhand eines großen visuell-linguistischen Datensatzes trainiert.
Vortraining spielt eine Schlüsselrolle bei der Verbesserung der Leistung von RoboFlamingo. Experimente zeigen, dass RoboFlamingo bei Roboteraufgaben eine bessere Leistung erbringt, indem es vorab anhand eines großen visuell-linguistischen Datensatzes trainiert.
Modellgröße und Leistung:
Während im Allgemeinen größere Modelle zu einer besseren Leistung führen, zeigen experimentelle Ergebnisse, dass sogar kleinere Modelle bei einigen Aufgaben mit großen Modellen konkurrieren können.
Auswirkungen der Feinabstimmung von Anweisungen:
Die Feinabstimmung von Anweisungen ist eine leistungsstarke Technik, und experimentelle Ergebnisse zeigen, dass sie die Leistung des Modells weiter verbessern kann.
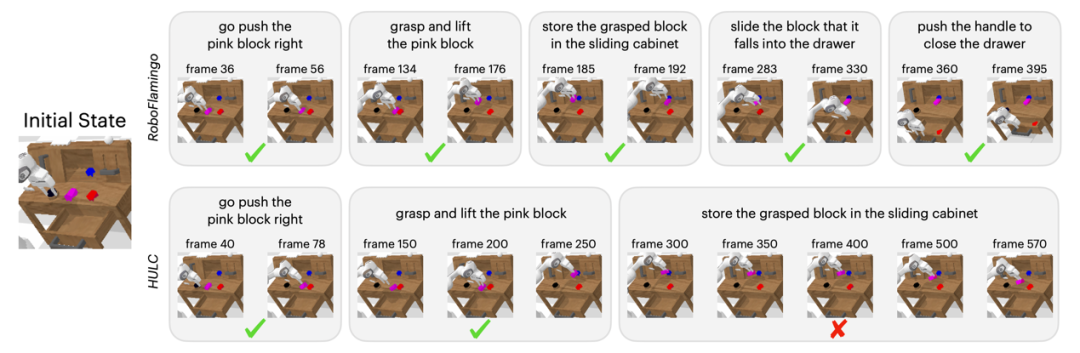
Qualitative Ergebnisse
Im Vergleich zur Baseline-Methode führte RoboFlamingo nicht nur 5 aufeinanderfolgende Teilaufgaben vollständig aus, sondern benötigte auch deutlich weniger Schritte für die ersten beiden Teilaufgaben, die die Baseline-Seite erfolgreich ausführten.
Zusammenfassung
Diese Arbeit stellt ein neuartiges Framework bereit, das auf vorhandenen Open-Source-VLMs für sprachinteraktive Roboterbetriebsstrategien basiert und mit einfacher Feinabstimmung hervorragende Ergebnisse erzielen kann. RoboFlamingo stellt Robotikforschern ein leistungsstarkes Open-Source-Framework zur Verfügung, mit dem sie das Potenzial von Open-Source-VLMs einfacher ausschöpfen können. Die reichhaltigen experimentellen Ergebnisse der Arbeit können wertvolle Erfahrungen und Daten für die praktische Anwendung der Robotik liefern und zur zukünftigen Forschung und Technologieentwicklung beitragen.
Das obige ist der detaillierte Inhalt vonDas Potenzial von Open-Source-VLMs wird durch das RoboFlamingo-Framework freigesetzt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Standort: Remote-Büro-Jobtyp: Vollzeitgehalt: 130.000 bis 140.000 US-Dollar Stellenbeschreibung Nehmen Sie an der Forschung und Entwicklung von Mobilfunkanwendungen und öffentlichen API-bezogenen Funktionen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken. Die Hauptaufgaben erledigen die Entwicklungsarbeit unabhängig von RubyonRails und arbeiten mit dem Front-End-Team von React/Redux/Relay zusammen. Erstellen Sie die Kernfunktionalität und -verbesserungen für Webanwendungen und arbeiten Sie eng mit Designer und Führung während des gesamten funktionalen Designprozesses zusammen. Fördern Sie positive Entwicklungsprozesse und priorisieren Sie die Iterationsgeschwindigkeit. Erfordert mehr als 6 Jahre komplexes Backend für Webanwendungen
 Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
MySQL kann JSON -Daten zurückgeben. Die JSON_EXTRACT -Funktion extrahiert Feldwerte. Über komplexe Abfragen sollten Sie die Where -Klausel verwenden, um JSON -Daten zu filtern, aber auf die Leistungsauswirkungen achten. Die Unterstützung von MySQL für JSON nimmt ständig zu, und es wird empfohlen, auf die neuesten Versionen und Funktionen zu achten.
 Der Hauptschlüssel von MySQL kann null sein
Apr 08, 2025 pm 03:03 PM
Der Hauptschlüssel von MySQL kann null sein
Apr 08, 2025 pm 03:03 PM
Der MySQL -Primärschlüssel kann nicht leer sein, da der Primärschlüssel ein Schlüsselattribut ist, das jede Zeile in der Datenbank eindeutig identifiziert. Wenn der Primärschlüssel leer sein kann, kann der Datensatz nicht eindeutig identifiziert werden, was zu Datenverwirrung führt. Wenn Sie selbstsinkrementelle Ganzzahlsspalten oder UUIDs als Primärschlüssel verwenden, sollten Sie Faktoren wie Effizienz und Raumbelegung berücksichtigen und eine geeignete Lösung auswählen.
 Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Detaillierte Erläuterung von Datenbanksäureattributen Säureattribute sind eine Reihe von Regeln, um die Zuverlässigkeit und Konsistenz von Datenbanktransaktionen sicherzustellen. Sie definieren, wie Datenbanksysteme Transaktionen umgehen, und sorgen dafür, dass die Datenintegrität und -genauigkeit auch im Falle von Systemabstürzen, Leistungsunterbrechungen oder mehreren Benutzern gleichzeitiger Zugriff. Säureattributübersicht Atomizität: Eine Transaktion wird als unteilbare Einheit angesehen. Jeder Teil schlägt fehl, die gesamte Transaktion wird zurückgerollt und die Datenbank behält keine Änderungen bei. Wenn beispielsweise eine Banküberweisung von einem Konto abgezogen wird, jedoch nicht auf ein anderes erhöht wird, wird der gesamte Betrieb widerrufen. begintransaktion; updateAccountsSetBalance = Balance-100WH
 Master SQL Limit -Klausel: Steuern Sie die Anzahl der Zeilen in einer Abfrage
Apr 08, 2025 pm 07:00 PM
Master SQL Limit -Klausel: Steuern Sie die Anzahl der Zeilen in einer Abfrage
Apr 08, 2025 pm 07:00 PM
SQllimit -Klausel: Steuern Sie die Anzahl der Zeilen in Abfrageergebnissen. Die Grenzklausel in SQL wird verwendet, um die Anzahl der von der Abfrage zurückgegebenen Zeilen zu begrenzen. Dies ist sehr nützlich, wenn große Datensätze, paginierte Anzeigen und Testdaten verarbeitet werden und die Abfrageeffizienz effektiv verbessern können. Grundlegende Syntax der Syntax: SelectColumn1, Spalte2, ... Fromtable_Namelimitnumber_of_rows; number_of_rows: Geben Sie die Anzahl der zurückgegebenen Zeilen an. Syntax mit Offset: SelectColumn1, Spalte2, ... Fromtable_NamelimitOffset, Number_of_rows; Offset: Skip überspringen
