
 Technologie-Peripheriegeräte
KI
LeCuns Bewertung: Meta-Bewertung von ConvNet und Transformer, welches ist stärker?
Technologie-Peripheriegeräte
KI
LeCuns Bewertung: Meta-Bewertung von ConvNet und Transformer, welches ist stärker?
LeCuns Bewertung: Meta-Bewertung von ConvNet und Transformer, welches ist stärker?

Wie wählt man ein visuelles Modell basierend auf spezifischen Anforderungen aus?
Wie vergleichen sich ConvNet/ViT- und überwachte/CLIP-Modelle bei anderen Indikatoren als ImageNet?
Die neueste von Forschern von MABZUAI und Meta veröffentlichte Studie vergleicht umfassend gängige visuelle Modelle für „nicht standardmäßige“ Indikatoren.

Papieradresse: https://arxiv.org/pdf/2311.09215.pdf
LeCun lobte diese Forschung sehr und nannte sie eine ausgezeichnete Forschung. Die Studie vergleicht ConvNext- und VIT-Architekturen ähnlicher Größe und bietet einen umfassenden Vergleich verschiedener Eigenschaften beim Training im überwachten Modus und unter Verwendung von CLIP-Methoden.

Über die ImageNet-Genauigkeit hinaus
Die Computer-Vision-Modelllandschaft wird immer vielfältiger und komplexer.
Von frühen ConvNets bis zur Entwicklung von Vision Transformers werden die Arten der verfügbaren Modelle ständig erweitert.
In ähnlicher Weise haben sich Trainingsparadigmen von überwachtem Training auf ImageNet zu selbstüberwachtem Lernen und Bild-Text-Paar-Training wie CLIP entwickelt.

Beim Markieren von Fortschritten stellt diese Explosion an Optionen eine große Herausforderung für Praktiker dar: Wie wählen Sie das richtige Zielmodell für Sie aus?
Die ImageNet-Genauigkeit war schon immer der Hauptindikator für die Bewertung der Modellleistung. Seitdem es die Deep-Learning-Revolution ausgelöst hat, hat es bedeutende Fortschritte auf dem Gebiet der künstlichen Intelligenz vorangetrieben.
Es kann jedoch nicht die Nuancen von Modellen messen, die sich aus unterschiedlichen Architekturen, Trainingsparadigmen und Daten ergeben.
Wenn man ausschließlich die ImageNet-Genauigkeit beurteilt, sehen Modelle mit unterschiedlichen Eigenschaften möglicherweise ähnlich aus (Abbildung 1). Diese Einschränkung wird deutlicher, wenn das Modell beginnt, die Funktionen von ImageNet zu übertreffen und die Sättigung der Genauigkeit erreicht.
Um diese Lücke zu schließen, führten Forscher eine eingehende Untersuchung des Modellverhaltens durch, das über die ImageNet-Genauigkeit hinausgeht.
Um den Einfluss von Architektur und Trainingszielen auf die Modellleistung zu untersuchen, wurden Vision Transformer (ViT) und ConvNeXt gezielt verglichen. Die ImageNet-1K-Validierungsgenauigkeit und die Rechenanforderungen dieser beiden modernen Architekturen sind vergleichbar.
Darüber hinaus verglich die Studie überwachte Modelle, die durch DeiT3-Base/16 und ConvNeXt-Base repräsentiert werden, sowie den visuellen Encoder von OpenCLIP, der auf dem CLIP-Modell basiert.

Ergebnisanalyse
Die Analyse der Forscher wurde entwickelt, um Modellverhalten zu untersuchen, das ohne weiteres Training oder Feinabstimmung bewertet werden kann.
Dieser Ansatz ist besonders wichtig für Praktiker mit begrenzten Rechenressourcen, da sie häufig auf vorab trainierte Modelle angewiesen sind.
In der spezifischen Analyse erkennen die Autoren zwar den Wert nachgelagerter Aufgaben wie der Objekterkennung an, der Schwerpunkt liegt jedoch auf jenen Funktionen, die Erkenntnisse mit minimalem Rechenaufwand liefern und Verhaltensweisen widerspiegeln, die für reale Anwendungen wichtig sind.
Modellfehler
ImageNet-X ist ein Datensatz, der ImageNet-1K um detaillierte manuelle Anmerkungen zu 16 sich ändernden Faktoren erweitert und so eine eingehende Analyse von Modellfehlern bei der Bildklassifizierung ermöglicht.
Es nutzt die Fehlerrate (je niedriger, desto besser), um die Leistung des Modells in Bezug auf bestimmte Faktoren im Verhältnis zur Gesamtgenauigkeit zu quantifizieren, was eine differenzierte Analyse von Modellfehlern ermöglicht. Ergebnisse auf ImageNet-X zeigen:
1. Im Verhältnis zur ImageNet-Genauigkeit macht das CLIP-Modell weniger Fehler als das überwachte Modell.
2. Alle Modelle werden hauptsächlich von komplexen Faktoren wie Okklusion beeinflusst.
3. Die Textur ist der anspruchsvollste Faktor aller Modelle.
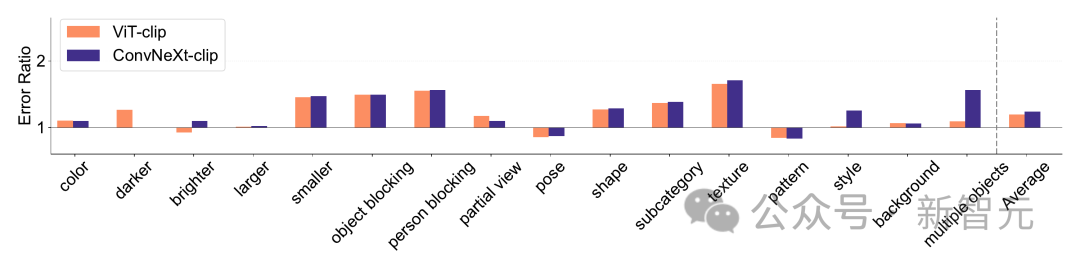
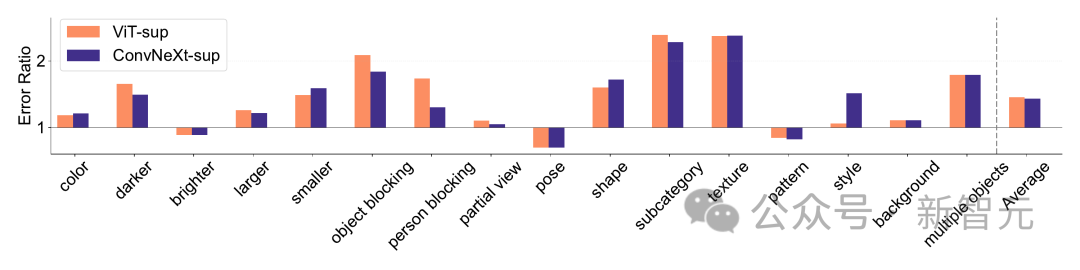
Shape/Texture Bias
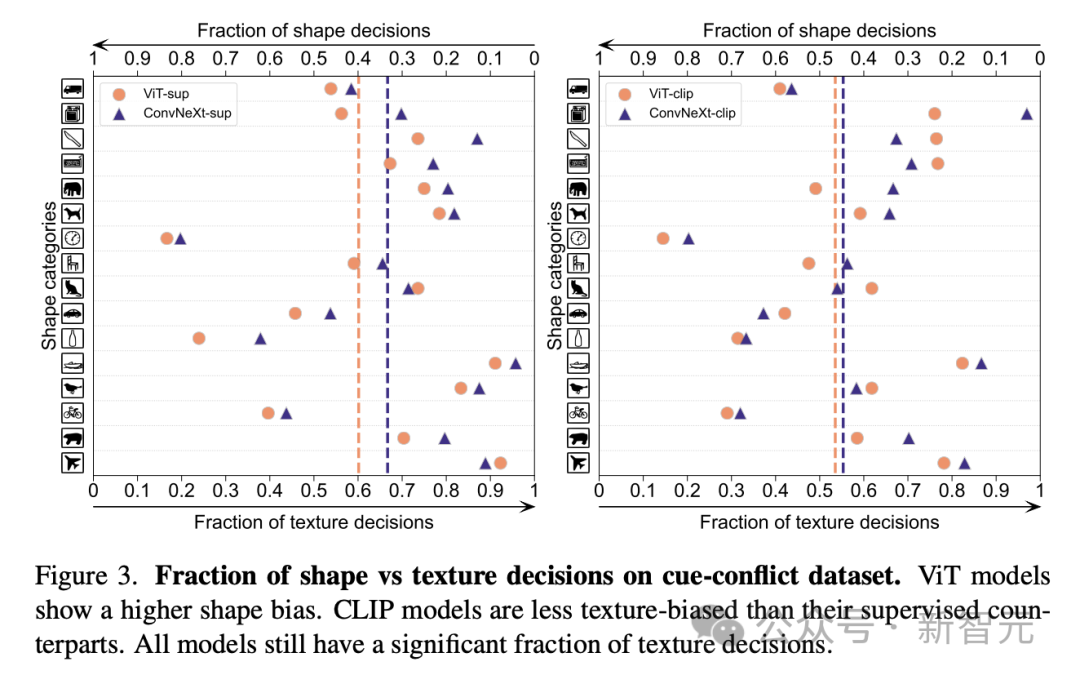
Shape/Texture Bias prüft, ob das Modell auf Texturverknüpfungen und nicht auf erweiterten Formhinweisen basiert.
Diese Tendenz lässt sich untersuchen, indem man Bilder unterschiedlicher Kategorien von Formen und Texturen kombiniert, die mit Hinweisen in Konflikt stehen.
Dieser Ansatz hilft zu verstehen, inwieweit die Entscheidungen des Modells auf der Form im Vergleich zur Textur basieren.
Die Forscher bewerteten die Form-Textur-Verzerrung im Cue-Konflikt-Datensatz und stellten fest, dass die Textur-Verzerrung des CLIP-Modells kleiner war als die des überwachten Modells, während die Form-Verzerrung des ViT-Modells höher war als die von ConvNets .
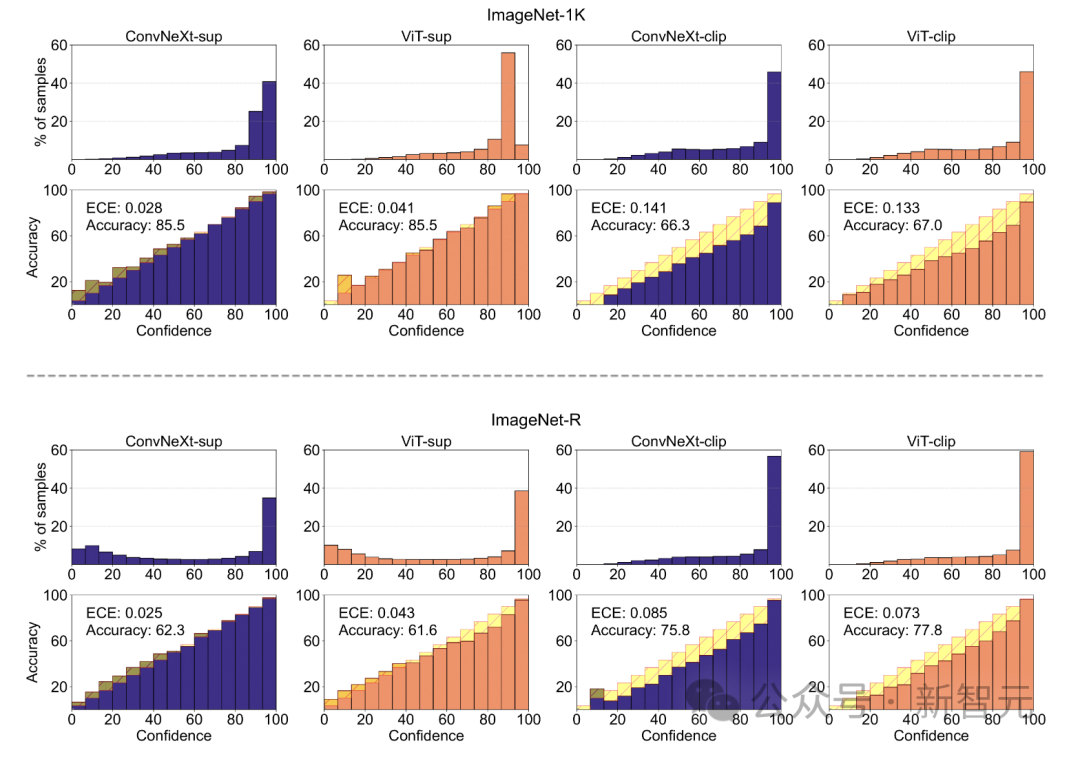
Modellkalibrierung
Die Kalibrierung quantifiziert, ob die Vorhersagesicherheit eines Modells mit seiner tatsächlichen Genauigkeit übereinstimmt.
Dies kann anhand von Metriken wie dem erwarteten Kalibrierungsfehler (ECE) sowie Visualisierungstools wie Zuverlässigkeitsdiagrammen und Konfidenzhistogrammen beurteilt werden.
Die Forscher bewerteten die Kalibrierung auf ImageNet-1K und ImageNet-R und klassifizierten Vorhersagen in 15 Stufen. Im Experiment wurden folgende Punkte beobachtet:
- Das CLIP-Modell weist ein hohes Vertrauen auf, während das überwachte Modell etwas unzureichend ist.
– Überwachtes ConvNeXt ist besser kalibriert als überwachtes ViT.
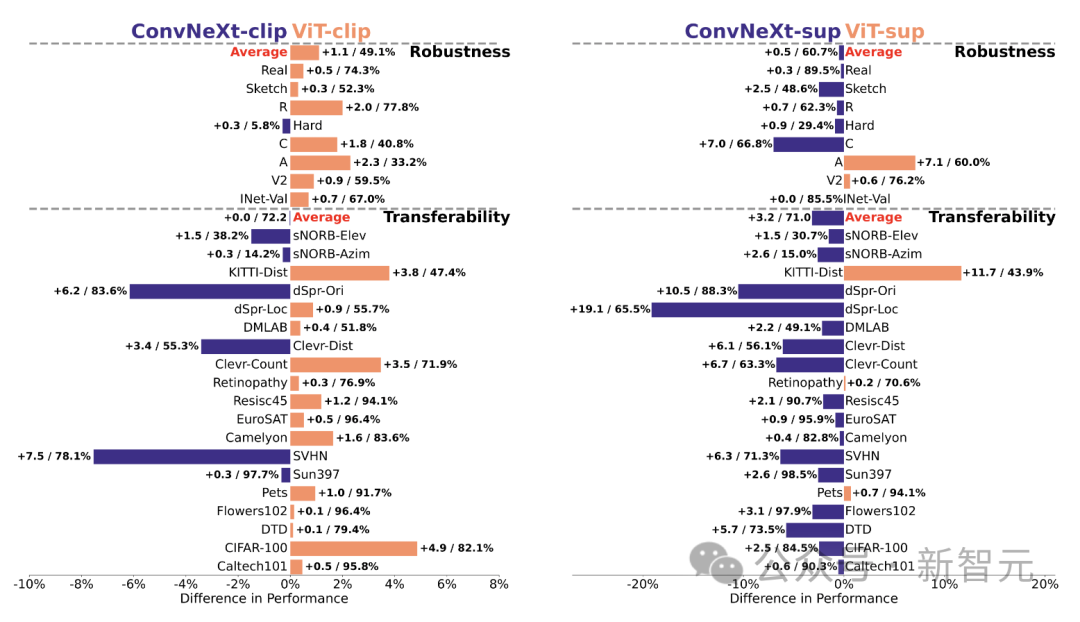
Robustheit und Portabilität
Die Robustheit und Portabilität des Modells sind der Schlüssel zur Anpassung an Änderungen in der Datenverteilung und neue Aufgaben.
Die Forscher bewerteten die Robustheit anhand verschiedener ImageNet-Varianten und stellten fest, dass die Modelle ViT und ConvNeXt mit Ausnahme von ImageNet-R und ImageNet-Sketch zwar eine ähnliche durchschnittliche Leistung aufwiesen, die überwachten Modelle jedoch im Allgemeinen hinsichtlich der Robustheit CLIP übertrafen.
In Bezug auf die Portabilität, bewertet anhand von 19 Datensätzen mithilfe des VTAB-Benchmarks, übertrifft das überwachte ConvNeXt ViT und liegt fast auf Augenhöhe mit der Leistung des CLIP-Modells.
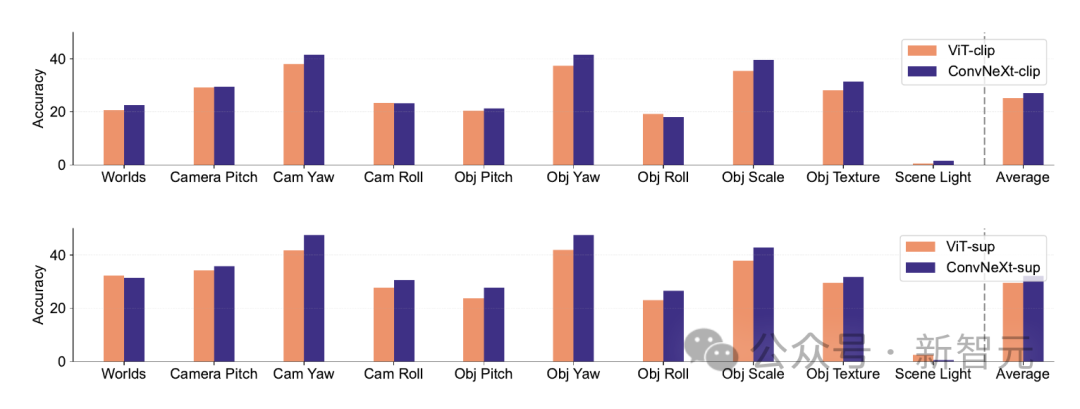
Synthetische Daten
Synthetische Datensätze wie PUG-ImageNet, die Faktoren wie Kamerawinkel und Textur präzise steuern können, sind zu einem vielversprechenden Forschungsweg geworden, sodass Forscher auf synthetischer Datenanalyse basieren Modelle.
PUG-ImageNet enthält fotorealistische ImageNet-Bilder mit systematischen Variationen in der Beleuchtung und anderen Faktoren, wobei die Leistung als absolut höchste Genauigkeit gemessen wird.
Die Forscher liefern Ergebnisse für verschiedene Faktoren in PUG-ImageNet und stellen fest, dass ConvNeXt ViT in fast allen Faktoren übertrifft.
Dies zeigt, dass ConvNeXt ViT bei synthetischen Daten übertrifft, während die Lücke des CLIP-Modells kleiner ist, da die Genauigkeit des CLIP-Modells geringer ist als die des überwachten Modells, was möglicherweise mit der geringeren Genauigkeit des ursprünglichen ImageNet zusammenhängt .
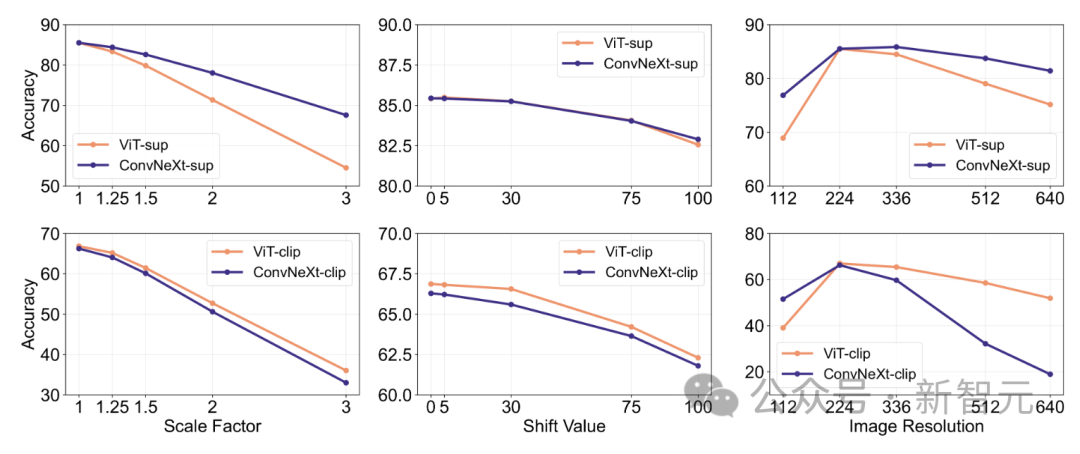
Feature-Invarianz
Feature-Invarianz bezieht sich auf die Fähigkeit des Modells, konsistente Darstellungen zu erzeugen, die nicht von Eingabetransformationen beeinflusst werden, wodurch die Semantik wie Skalierung oder Bewegung erhalten bleibt.
Diese Funktion ermöglicht dem Modell eine gute Verallgemeinerung über verschiedene, aber semantisch ähnliche Eingaben hinweg.
Der Ansatz der Forscher umfasst die Größenänderung von Bildern für Skaleninvarianz, das Verschieben von Ausschnitten für Positionsinvarianz und die Anpassung der Auflösung des ViT-Modells mithilfe interpolierter Positionseinbettungen.
ConvNeXt übertrifft ViT im betreuten Training.
Insgesamt ist das Modell robuster gegenüber Skalierungs-/Auflösungstransformationen als gegenüber Bewegungen. Für Anwendungen, die eine hohe Robustheit gegenüber Skalierung, Verschiebung und Auflösung erfordern, deuten die Ergebnisse darauf hin, dass überwachtes ConvNeXt möglicherweise die beste Wahl ist.
Forscher fanden heraus, dass jedes Modell seine eigenen einzigartigen Vorteile hat.
Dies legt nahe, dass die Modellauswahl vom Zielanwendungsfall abhängen sollte, da Standardleistungsmetriken möglicherweise geschäftskritische Nuancen übersehen.
Darüber hinaus sind viele bestehende Benchmarks von ImageNet abgeleitet, was die Bewertung verzerrt. Die Entwicklung neuer Benchmarks mit unterschiedlichen Datenverteilungen ist entscheidend, um Modelle in einem realistischeren repräsentativen Kontext zu bewerten.
ConvNet vs. Transformer
– In vielen Benchmarks hat überwachtes ConvNeXt eine bessere Leistung als überwachtes VIT: Es ist besser kalibriert, invariant gegenüber Datentransformationen, zeigt eine bessere Leistung, gute Übertragbarkeit und Robustheit.
- ConvNeXt übertrifft ViT bei synthetischen Daten.
- ViT hat eine höhere Formvoreingenommenheit.
Supervised vs. CLIP
– Obwohl das CLIP-Modell hinsichtlich der Übertragbarkeit besser ist, zeigte das überwachte ConvNeXt bei dieser Aufgabe eine wettbewerbsfähige Leistung. Dies zeigt das Potenzial überwachter Modelle.
– Überwachte Modelle schneiden bei Robustheitsbenchmarks besser ab, wahrscheinlich weil diese Modelle Varianten von ImageNet sind.
– Das CLIP-Modell weist im Vergleich zu seiner ImageNet-Genauigkeit eine höhere Formverzerrung und weniger Klassifizierungsfehler auf.
Das obige ist der detaillierte Inhalt vonLeCuns Bewertung: Meta-Bewertung von ConvNet und Transformer, welches ist stärker?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
Um die Zeitüberschreitung für Vue Axios festzulegen, können wir eine Axios -Instanz erstellen und die Zeitleitungsoption angeben: in globalen Einstellungen: vue.Prototyp. $ Axios = axios.create ({Timeout: 5000}); In einer einzigen Anfrage: this. $ axios.get ('/api/user', {timeout: 10000}).
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Standort: Remote-Büro-Jobtyp: Vollzeitgehalt: 130.000 bis 140.000 US-Dollar Stellenbeschreibung Nehmen Sie an der Forschung und Entwicklung von Mobilfunkanwendungen und öffentlichen API-bezogenen Funktionen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken. Die Hauptaufgaben erledigen die Entwicklungsarbeit unabhängig von RubyonRails und arbeiten mit dem Front-End-Team von React/Redux/Relay zusammen. Erstellen Sie die Kernfunktionalität und -verbesserungen für Webanwendungen und arbeiten Sie eng mit Designer und Führung während des gesamten funktionalen Designprozesses zusammen. Fördern Sie positive Entwicklungsprozesse und priorisieren Sie die Iterationsgeschwindigkeit. Erfordert mehr als 6 Jahre komplexes Backend für Webanwendungen
 Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
MySQL kann JSON -Daten zurückgeben. Die JSON_EXTRACT -Funktion extrahiert Feldwerte. Über komplexe Abfragen sollten Sie die Where -Klausel verwenden, um JSON -Daten zu filtern, aber auf die Leistungsauswirkungen achten. Die Unterstützung von MySQL für JSON nimmt ständig zu, und es wird empfohlen, auf die neuesten Versionen und Funktionen zu achten.
 So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
Die MySQL -Leistungsoptimierung muss von drei Aspekten beginnen: Installationskonfiguration, Indexierung und Abfrageoptimierung, Überwachung und Abstimmung. 1. Nach der Installation müssen Sie die my.cnf -Datei entsprechend der Serverkonfiguration anpassen, z. 2. Erstellen Sie einen geeigneten Index, um übermäßige Indizes zu vermeiden und Abfrageanweisungen zu optimieren, z. B. den Befehl Erklärung zur Analyse des Ausführungsplans; 3. Verwenden Sie das eigene Überwachungstool von MySQL (ShowProcessList, Showstatus), um die Datenbankgesundheit zu überwachen und die Datenbank regelmäßig zu sichern und zu organisieren. Nur durch kontinuierliche Optimierung dieser Schritte kann die Leistung der MySQL -Datenbank verbessert werden.
 Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Die MySQL-Datenbankleistung Optimierungshandbuch In ressourcenintensiven Anwendungen spielt die MySQL-Datenbank eine entscheidende Rolle und ist für die Verwaltung massiver Transaktionen verantwortlich. Mit der Erweiterung der Anwendung werden jedoch die Datenbankleistung Engpässe häufig zu einer Einschränkung. In diesem Artikel werden eine Reihe effektiver Strategien zur Leistungsoptimierung von MySQL -Leistung untersucht, um sicherzustellen, dass Ihre Anwendung unter hohen Lasten effizient und reaktionsschnell bleibt. Wir werden tatsächliche Fälle kombinieren, um eingehende Schlüsseltechnologien wie Indexierung, Abfrageoptimierung, Datenbankdesign und Caching zu erklären. 1. Das Design der Datenbankarchitektur und die optimierte Datenbankarchitektur sind der Eckpfeiler der MySQL -Leistungsoptimierung. Hier sind einige Kernprinzipien: Die Auswahl des richtigen Datentyps und die Auswahl des kleinsten Datentyps, der den Anforderungen entspricht, kann nicht nur Speicherplatz speichern, sondern auch die Datenverarbeitungsgeschwindigkeit verbessern.
