
 Technologie-Peripheriegeräte
KI
Die Zhejiang-Universität schlägt die neue SOTA-Technologie SIFU vor: Nur ein Bild kann ein hochwertiges 3D-Modell des menschlichen Körpers rekonstruieren
Technologie-Peripheriegeräte
KI
Die Zhejiang-Universität schlägt die neue SOTA-Technologie SIFU vor: Nur ein Bild kann ein hochwertiges 3D-Modell des menschlichen Körpers rekonstruieren
Die Zhejiang-Universität schlägt die neue SOTA-Technologie SIFU vor: Nur ein Bild kann ein hochwertiges 3D-Modell des menschlichen Körpers rekonstruieren

In vielen Bereichen wie AR, VR, 3D-Druck, Szenenaufbau und Filmproduktion sind hochwertige 3D-Modelle des bekleideten menschlichen Körpers sehr wichtig.
Die Erstellung von Modellen mit herkömmlichen Methoden erfordert viel Zeit und kann nur von professioneller Ausrüstung und Technikern durchgeführt werden.

Im Alltag nutzen wir dagegen meist Handykameras oder Porträtfotos von Webseiten.
Daher kann eine Methode, die ein dreidimensionales menschliches Modell aus einem einzigen Bild genau rekonstruieren kann, die Kosten erheblich senken und den unabhängigen Erstellungsprozess vereinfachen.
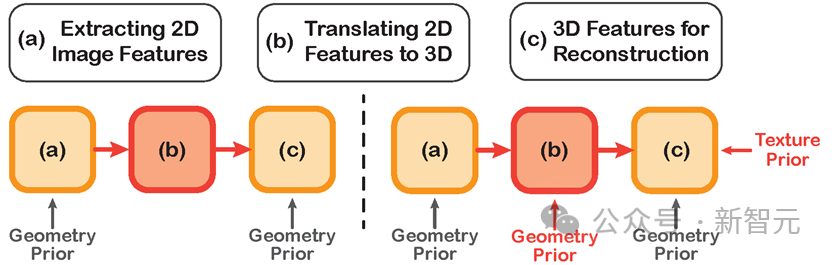 Vergleich der technischen Route früherer Methoden (links) und dieser Methode (rechts)
Vergleich der technischen Route früherer Methoden (links) und dieser Methode (rechts)
Frühere Deep-Learning-Modelle, die für die 3D-Rekonstruktion des menschlichen Körpers verwendet wurden, erfordern häufig drei Schritte: Extrahieren von 2D-Merkmalen aus dem Bild, Die 2D-Merkmale werden in den 3D-Raum übertragen und die 3D-Merkmale werden für die Rekonstruktion des menschlichen Körpers verwendet.
Allerdings ignorieren diese Methoden häufig die Einführung von Prioritäten für den menschlichen Körper in der Phase der Konvertierung von 2D-Merkmalen in den 3D-Raum, was zu einer unzureichenden Merkmalsextraktion und verschiedenen Fehlern in den endgültigen Rekonstruktionsergebnissen führt.
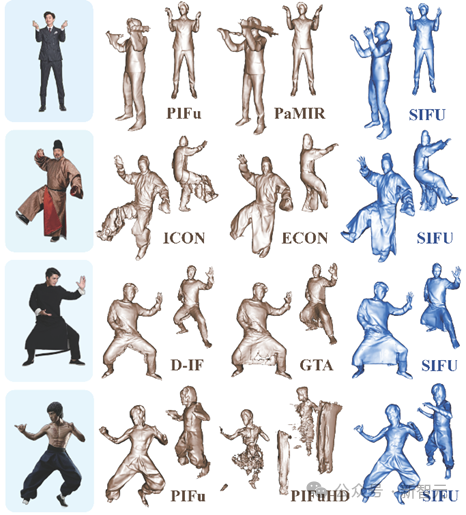 Vergleich des Rekonstruktionseffekts von SIFU und anderen SOTA-Modellen
Vergleich des Rekonstruktionseffekts von SIFU und anderen SOTA-Modellen
Darüber hinaus stützten sich frühere Modelle in der Phase der Texturvorhersage nur auf das im Trainingssatz erlernte Wissen und hatten keine Vorkenntnisse darüber reale Welt, was oft dazu führte, dass die Texturvorhersage in unsichtbaren Bereichen schlecht ist.

SIFU führt Vorkenntnisse in die Texturvorhersagephase ein, um den Textureffekt unsichtbarer Bereiche (Rückseite usw.) zu verbessern.
In diesem Zusammenhang schlugen Forscher des ReLER-Labors der Universität Zhejiang das SIFU-Modell vor, das auf der bedingten impliziten Funktion der Seitenansicht beruht, um ein 3D-Modell des menschlichen Körpers aus einem einzelnen Bild zu rekonstruieren.
 Bilder
Bilder
Papieradresse: https://arxiv.org/abs/2312.06704
Projektadresse: https://github.com/River-Zhang/SIFU
Dieses Modell wurde bestanden Die 2D-Merkmale werden in den 3D-Raum konvertiert und die Seitenansicht des menschlichen Körpers wird als a priori-Bedingung eingeführt, um den geometrischen Rekonstruktionseffekt zu verbessern. Und in der Texturoptimierungsphase wird ein vorab trainiertes Diffusionsmodell eingeführt, um das Problem schlechter Textur in unsichtbaren Bereichen zu lösen.
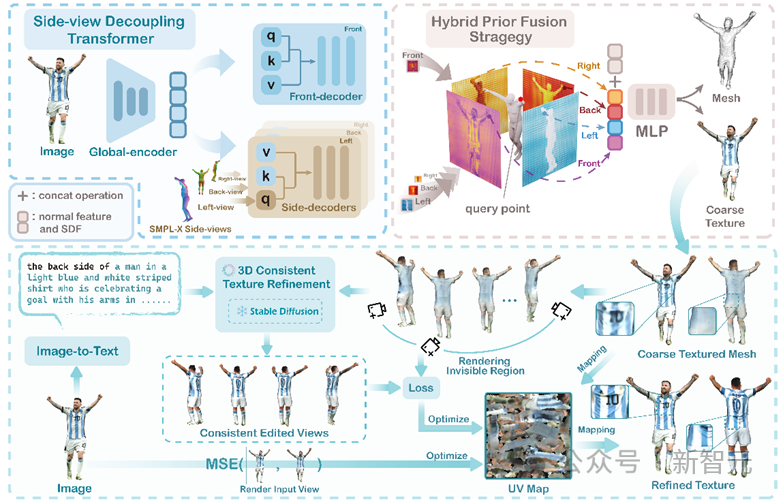
Modellstruktur
Die Modellpipeline ist wie folgt:
 Bilder
Bilder
Die erste Stufe verwendet die seitliche implizite Funktion, um die Geometrie zu rekonstruieren ( Mesh) des menschlichen Körpers und grobe Textur, die zweite Stufe verwendet das vorab trainierte Diffusionsmodell, um die Textur zu verfeinern.
In der ersten Phase entwarf der Autor einen einzigartigen Seitenansichts-Entkopplungstransformator. Nach dem Extrahieren von 2D-Merkmalen durch den globalen Encoder wurde die Seitenansicht des menschlichen Körpers des Vorgängermodells SMPL-X als Abfrage in den Decoder eingeführt Die 3D-Merkmale des menschlichen Körpers in verschiedenen Richtungen (vorne, hinten, links und rechts) werden von den 2D-Merkmalen des Bildes entkoppelt und schließlich zur Rekonstruktion verwendet.
Diese Methode kombiniert erfolgreich Vorkenntnisse über den menschlichen Körper bei der Umwandlung von 2D-Merkmalen in den 3D-Raum, was zu einem besseren Rekonstruktionseffekt des Modells führt.
In der zweiten Stufe schlägt der Autor einen 3D-konsistenten Texturverfeinerungsprozess vor. Zuerst können die unsichtbaren Bereiche des menschlichen Körpers (Seiten, Rücken) in eine Reihe von Bildern mit kontinuierlichen Betrachtungswinkeln differenziert werden, und dann mit dem Mithilfe eines Diffusionsmodells, das Vorwissen aus umfangreichen Daten erlernt, können grobe Texturbilder konsistent bearbeitet werden, um verfeinerte Ergebnisse zu erzielen. Abschließend wird die Texturkarte des 3D-Modells optimiert, indem der Verlust aus den Bildern vor und nach der Verfeinerung berechnet wird.
Experimenteller Teil
Höhere Rekonstruktionsgenauigkeit
Im experimentellen Teil testen die Autoren ihr Modell anhand eines umfassend vielfältigen Testsatzes, darunter CAPE-NFP, CAPE-FP und THuman2.0, und vergleichen es mit Frühere SOTA-Modelle zur Einzelbildrekonstruktion des menschlichen Körpers wurden auf großen Konferenzen veröffentlicht. Nach quantitativen Tests zeigte das SIFU-Modell die besten Ergebnisse sowohl bei der geometrischen Rekonstruktion als auch bei der Texturrekonstruktion.
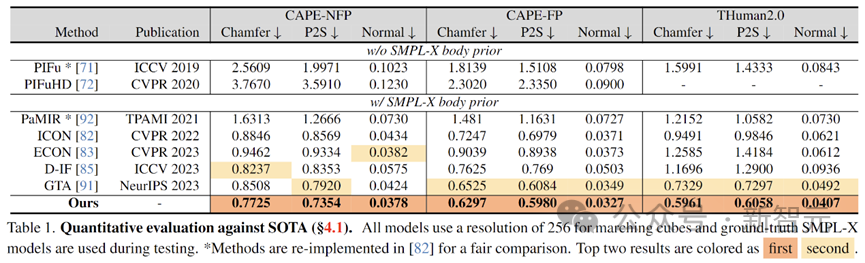 Bewerten Sie die geometrische Rekonstruktionsgenauigkeit quantitativ.
Bewerten Sie die geometrische Rekonstruktionsgenauigkeit quantitativ.
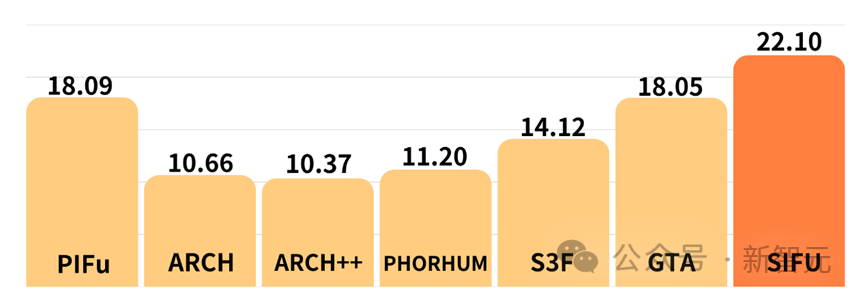 Bewerten Sie den Texturrekonstruktionseffekt quantitativ.
Bewerten Sie den Texturrekonstruktionseffekt quantitativ.
 Verwenden Sie öffentliche Bilder im Internet als Eingabe für die qualitative Effektdemonstration.
Verwenden Sie öffentliche Bilder im Internet als Eingabe für die qualitative Effektdemonstration.
Stärkere Robustheit
Wenn frühere Modelle andere Daten als den Trainingssatz anwenden, weichen die Rekonstruktionsergebnisse oft stark von den Eingabebildern ab, da das geschätzte menschliche Körpermodell SMPL/SMPL-X nicht genau genug ist, was es schwierig macht, sie in praktische Anwendungen umzusetzen.
In diesem Zusammenhang testete der Autor speziell die Robustheit des Modells, indem er Störungen zu den Parametern des vorherigen Modells hinzufügte, um die Pose auszugleichen, und simulierte so die ungenaue SMPL-X-Schätzung in realen Szenen Genauigkeit der Modellrekonstruktion. Die Ergebnisse zeigen, dass das SIFU-Modell in diesem Fall immer noch die beste Rekonstruktionsgenauigkeit aufweist.
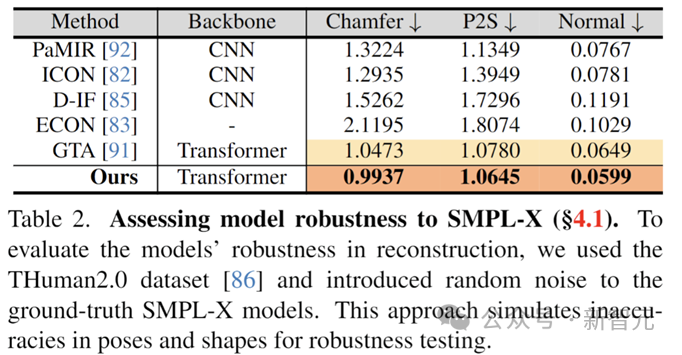 Bewerten Sie die Robustheit des Modells, wenn Sie mit einem fehlerhaften menschlichen Körpermodell konfrontiert werden.
Bewerten Sie die Robustheit des Modells, wenn Sie mit einem fehlerhaften menschlichen Körpermodell konfrontiert werden.
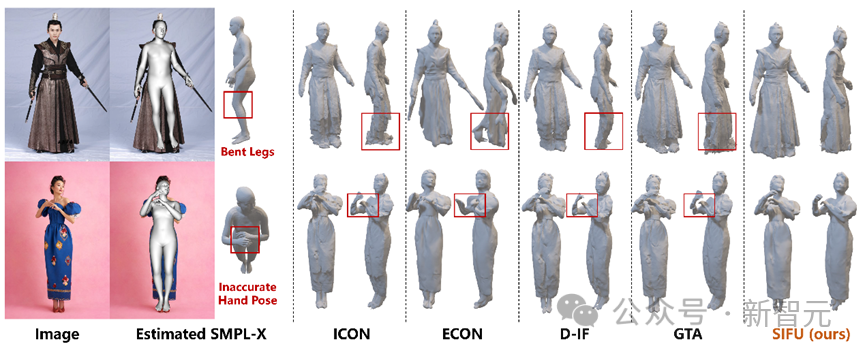 Mit realen Bildern funktioniert SIFU immer noch, wenn die vorherige Schätzung des menschlichen Körpermodells ungenau ist. Besserer Rekonstruktionseffekt
Mit realen Bildern funktioniert SIFU immer noch, wenn die vorherige Schätzung des menschlichen Körpermodells ungenau ist. Besserer Rekonstruktionseffekt
Umfassendere Anwendungsszenarien
Der hochpräzise und hochwertige Rekonstruktionseffekt des SIFU-Modells macht es für eine Vielzahl von Anwendungsszenarien geeignet, einschließlich 3D-Druck, Szenenaufbau, Texturbearbeitung usw. 3D-gedrucktes SIFU-rekonstruiertes menschliches Körpermodell
 Mit Hilfe öffentlicher Aktionssequenzdaten , können Sie das rekonstruierte SIFU-Modell steuern Die Texturvorhersage verbessert die Genauigkeit und Wirkung der Rekonstruktion des menschlichen Körpers in einem einzigen Bild erheblich, was dem Modell erhebliche Vorteile in realen Anwendungen verschafft und auch neue Ideen für zukünftige Forschungen auf diesem Gebiet liefert.
Mit Hilfe öffentlicher Aktionssequenzdaten , können Sie das rekonstruierte SIFU-Modell steuern Die Texturvorhersage verbessert die Genauigkeit und Wirkung der Rekonstruktion des menschlichen Körpers in einem einzigen Bild erheblich, was dem Modell erhebliche Vorteile in realen Anwendungen verschafft und auch neue Ideen für zukünftige Forschungen auf diesem Gebiet liefert.
Referenz:
https://arxiv.org/abs/2312.06704
Das obige ist der detaillierte Inhalt vonDie Zhejiang-Universität schlägt die neue SOTA-Technologie SIFU vor: Nur ein Bild kann ein hochwertiges 3D-Modell des menschlichen Körpers rekonstruieren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 So schreiben Sie einen Roman in der Tomato Free Novel-App. Teilen Sie das Tutorial zum Schreiben eines Romans in der Tomato Novel-App
Mar 28, 2024 pm 12:50 PM
So schreiben Sie einen Roman in der Tomato Free Novel-App. Teilen Sie das Tutorial zum Schreiben eines Romans in der Tomato Novel-App
Mar 28, 2024 pm 12:50 PM
Tomato Novel ist eine sehr beliebte Roman-Lesesoftware. Jeder Roman und Comic ist sehr interessant und möchte auch Romane schreiben Also, wie schreiben wir den Roman darin? Meine Freunde wissen es nicht, also lasst uns gemeinsam auf diese Seite gehen und uns eine Einführung zum Schreiben eines Romans ansehen. Teilen Sie das Tomato-Roman-Tutorial zum Schreiben eines Romans. 1. Öffnen Sie zunächst die kostenlose Tomato-Roman-App auf Ihrem Mobiltelefon und klicken Sie auf „Personal Center – Writer Center“. 2. Gehen Sie zur Seite „Tomato Writer Assistant“ – klicken Sie auf „Neues Buch erstellen“. am Ende des Romans.
 Wie rufe ich das BIOS auf dem Colorful-Motherboard auf? Bringen Sie Ihnen zwei Methoden bei
Mar 13, 2024 pm 06:01 PM
Wie rufe ich das BIOS auf dem Colorful-Motherboard auf? Bringen Sie Ihnen zwei Methoden bei
Mar 13, 2024 pm 06:01 PM
Colorful-Motherboards erfreuen sich auf dem chinesischen Inlandsmarkt großer Beliebtheit und Marktanteil, aber einige Benutzer von Colorful-Motherboards wissen immer noch nicht, wie sie im BIOS Einstellungen vornehmen sollen? Als Reaktion auf diese Situation hat Ihnen der Herausgeber speziell zwei Methoden zum Aufrufen des farbenfrohen Motherboard-BIOS vorgestellt. Kommen Sie und probieren Sie es aus! Methode 1: Verwenden Sie die U-Disk-Start-Tastenkombination, um das U-Disk-Installationssystem direkt aufzurufen. Die Tastenkombination für das Colorful-Motherboard zum Starten der U-Disk ist zunächst ESC oder F11, um ein Black zu erstellen Wenn Sie den Startbildschirm sehen, drücken Sie kontinuierlich die ESC- oder F11-Taste auf der Tastatur, um ein Fenster zur Auswahl der Startelementsequenz aufzurufen. Bewegen Sie den Cursor an die Stelle, an der „USB“ angezeigt wird " wird angezeigt, und dann
 So stellen Sie gelöschte Kontakte auf WeChat wieder her (ein einfaches Tutorial erklärt Ihnen, wie Sie gelöschte Kontakte wiederherstellen)
May 01, 2024 pm 12:01 PM
So stellen Sie gelöschte Kontakte auf WeChat wieder her (ein einfaches Tutorial erklärt Ihnen, wie Sie gelöschte Kontakte wiederherstellen)
May 01, 2024 pm 12:01 PM
Leider löschen Menschen aus bestimmten Gründen oft versehentlich bestimmte Kontakte. WeChat ist eine weit verbreitete soziale Software. Um Benutzern bei der Lösung dieses Problems zu helfen, wird in diesem Artikel erläutert, wie gelöschte Kontakte auf einfache Weise wiederhergestellt werden können. 1. Verstehen Sie den WeChat-Kontaktlöschmechanismus. Dies bietet uns die Möglichkeit, gelöschte Kontakte wiederherzustellen. Der Kontaktlöschmechanismus in WeChat entfernt sie aus dem Adressbuch, löscht sie jedoch nicht vollständig. 2. Nutzen Sie die integrierte „Kontaktbuch-Wiederherstellung“-Funktion von WeChat, um Zeit und Energie zu sparen. Mit dieser Funktion können Benutzer schnell gelöschte Kontakte wiederherstellen. 3. Rufen Sie die WeChat-Einstellungsseite auf und klicken Sie auf die untere rechte Ecke, öffnen Sie die WeChat-Anwendung „Me“ und klicken Sie auf das Einstellungssymbol in der oberen rechten Ecke, um die Einstellungsseite aufzurufen.
 Zusammenfassung der Methoden zum Erhalten von Administratorrechten in Win11
Mar 09, 2024 am 08:45 AM
Zusammenfassung der Methoden zum Erhalten von Administratorrechten in Win11
Mar 09, 2024 am 08:45 AM
Eine Zusammenfassung, wie Sie Win11-Administratorrechte erhalten. Im Betriebssystem Windows 11 sind Administratorrechte eine der sehr wichtigen Berechtigungen, die es Benutzern ermöglichen, verschiedene Vorgänge auf dem System auszuführen. Manchmal benötigen wir möglicherweise Administratorrechte, um einige Vorgänge abzuschließen, z. B. die Installation von Software, das Ändern von Systemeinstellungen usw. Im Folgenden werden einige Methoden zum Erhalten von Win11-Administratorrechten zusammengefasst. Ich hoffe, dass sie Ihnen helfen können. 1. Verwenden Sie Tastenkombinationen. Im Windows 11-System können Sie die Eingabeaufforderung schnell über Tastenkombinationen öffnen.
 CLIP-BEVFormer: Überwacht explizit die BEVFormer-Struktur, um die Leistung der Long-Tail-Erkennung zu verbessern
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Überwacht explizit die BEVFormer-Struktur, um die Leistung der Long-Tail-Erkennung zu verbessern
Mar 26, 2024 pm 12:41 PM
Oben geschrieben und das persönliche Verständnis des Autors: Derzeit spielt das Wahrnehmungsmodul im gesamten autonomen Fahrsystem eine entscheidende Rolle Das Steuermodul im autonomen Fahrsystem trifft zeitnahe und korrekte Urteile und Verhaltensentscheidungen. Derzeit sind Autos mit autonomen Fahrfunktionen in der Regel mit einer Vielzahl von Dateninformationssensoren ausgestattet, darunter Rundumsichtkamerasensoren, Lidar-Sensoren und Millimeterwellenradarsensoren, um Informationen in verschiedenen Modalitäten zu sammeln und so genaue Wahrnehmungsaufgaben zu erfüllen. Der auf reinem Sehen basierende BEV-Wahrnehmungsalgorithmus wird von der Industrie aufgrund seiner geringen Hardwarekosten und einfachen Bereitstellung bevorzugt, und seine Ausgabeergebnisse können problemlos auf verschiedene nachgelagerte Aufgaben angewendet werden.
 Das Geheimnis des Ausbrütens mobiler Dracheneier wird gelüftet (Schritt für Schritt erfahren Sie, wie Sie mobile Dracheneier erfolgreich ausbrüten)
May 04, 2024 pm 06:01 PM
Das Geheimnis des Ausbrütens mobiler Dracheneier wird gelüftet (Schritt für Schritt erfahren Sie, wie Sie mobile Dracheneier erfolgreich ausbrüten)
May 04, 2024 pm 06:01 PM
Mobile Spiele sind mit der Entwicklung der Technologie zu einem festen Bestandteil des Lebens der Menschen geworden. Mit seinem niedlichen Drachenei-Bild und dem interessanten Schlüpfvorgang hat es die Aufmerksamkeit vieler Spieler auf sich gezogen, und eines der Spiele, das viel Aufmerksamkeit erregt hat, ist die mobile Version von Dragon Egg. Um den Spielern dabei zu helfen, ihre eigenen Drachen im Spiel besser zu kultivieren und zu züchten, erfahren Sie in diesem Artikel, wie Sie Dracheneier in der mobilen Version ausbrüten. 1. Wählen Sie den geeigneten Drachenei-Typ aus, der Ihnen gefällt und zu Ihnen passt, basierend auf den verschiedenen Arten von Drachenei-Attributen und -Fähigkeiten, die im Spiel zur Verfügung stehen. 2. Verbessern Sie die Stufe der Brutmaschine, indem Sie Aufgaben erledigen und Requisiten sammeln. Die Stufe der Brutmaschine bestimmt die Schlüpfgeschwindigkeit und die Erfolgsquote beim Schlüpfen. 3. Sammeln Sie die Ressourcen, die die Spieler zum Schlüpfen benötigen
 Schneller Meister: So eröffnen Sie zwei WeChat-Konten auf Huawei-Handys!
Mar 23, 2024 am 10:42 AM
Schneller Meister: So eröffnen Sie zwei WeChat-Konten auf Huawei-Handys!
Mar 23, 2024 am 10:42 AM
In der heutigen Gesellschaft sind Mobiltelefone zu einem unverzichtbaren Bestandteil unseres Lebens geworden. Als wichtiges Werkzeug für unsere tägliche Kommunikation, Arbeit und unser Leben wird WeChat häufig genutzt. Allerdings kann es bei der Abwicklung unterschiedlicher Transaktionen erforderlich sein, zwei WeChat-Konten zu trennen, was erfordert, dass das Mobiltelefon die gleichzeitige Anmeldung bei zwei WeChat-Konten unterstützt. Als bekannte inländische Marke werden Huawei-Mobiltelefone von vielen Menschen genutzt. Wie können also zwei WeChat-Konten auf Huawei-Mobiltelefonen eröffnet werden? Lassen Sie uns das Geheimnis dieser Methode lüften. Zunächst müssen Sie zwei WeChat-Konten gleichzeitig auf Ihrem Huawei-Mobiltelefon verwenden. Der einfachste Weg ist
 So stellen Sie die Schriftgröße auf dem Mobiltelefon ein (Schriftgröße auf dem Mobiltelefon einfach anpassen)
May 07, 2024 pm 03:34 PM
So stellen Sie die Schriftgröße auf dem Mobiltelefon ein (Schriftgröße auf dem Mobiltelefon einfach anpassen)
May 07, 2024 pm 03:34 PM
Das Festlegen der Schriftgröße ist zu einer wichtigen Personalisierungsanforderung geworden, da Mobiltelefone zu einem wichtigen Werkzeug im täglichen Leben der Menschen geworden sind. Um den Bedürfnissen verschiedener Benutzer gerecht zu werden, wird in diesem Artikel erläutert, wie Sie das Nutzungserlebnis Ihres Mobiltelefons verbessern und die Schriftgröße des Mobiltelefons durch einfache Vorgänge anpassen können. Warum müssen Sie die Schriftgröße Ihres Mobiltelefons anpassen? Durch Anpassen der Schriftgröße kann der Text klarer und leichter lesbar werden. Geeignet für die Lesebedürfnisse von Benutzern unterschiedlichen Alters. Praktisch für Benutzer mit Sehbehinderung, die Schriftgröße zu verwenden Einstellungsfunktion des Mobiltelefonsystems – So rufen Sie die Systemeinstellungsoberfläche auf – Suchen und geben Sie die Option „Anzeige“ in der Einstellungsoberfläche ein – suchen Sie die Option „Schriftgröße“ und passen Sie sie mit einem Drittanbieter an Anwendung – Laden Sie eine Anwendung herunter und installieren Sie sie, die die Anpassung der Schriftgröße unterstützt – öffnen Sie die Anwendung und rufen Sie die entsprechende Einstellungsoberfläche auf – je nach Person
