

Wenn Sie Pandas jemals mit tabellarischen Daten verwendet haben, sind Sie möglicherweise mit dem Prozess des Importierens, Bereinigens und Transformierens der Daten und der anschließenden Verwendung als Eingabe für das Modell vertraut. Wenn Sie Ihren Code jedoch skalieren und in die Produktion überführen müssen, wird Ihre Pandas-Pipeline höchstwahrscheinlich abstürzen und langsam laufen. In diesem Artikel werde ich zwei Tipps geben, die Ihnen helfen, die Ausführung von Pandas-Code zu beschleunigen, die Effizienz der Datenverarbeitung zu verbessern und häufige Fallstricke zu vermeiden.

In Pandas sind Vektorisierungsoperationen ein effizientes Werkzeug, das die Spalten des gesamten Datenrahmens prägnanter verarbeiten kann, ohne Zeile für Zeile zu schleifen.
Broadcasting ist ein Schlüsselelement der vektorisierten Manipulation und ermöglicht Ihnen die intuitive Manipulation von Objekten mit unterschiedlichen Formen.
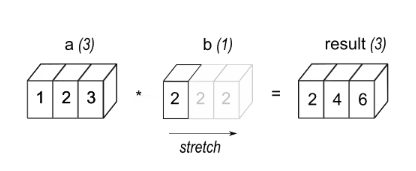
eg1: Ein Array a mit 3 Elementen wird mit einem Skalar b multipliziert, was zu einem Array mit derselben Form wie Quelle führt.
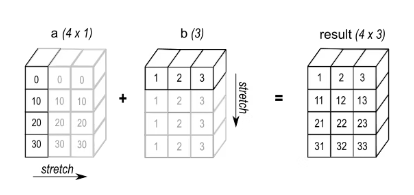
eg2: Wenn Sie eine Additionsoperation durchführen, fügen Sie Array a mit Form (4,1) und Array b mit Form (3,) hinzu.
Es gab viele Artikel, in denen dies diskutiert wurde, insbesondere im Deep Learning, wo groß angelegte Matrixmultiplikationen üblich sind. In diesem Artikel werden zwei kurze Beispiele erläutert.
Angenommen, Sie möchten zunächst zählen, wie oft eine bestimmte Ganzzahl in einer Spalte vorkommt. Hier sind 2 mögliche Methoden.
"""计算DataFrame X 中 "column_1" 列中等于目标值 target 的元素个数。参数:X: DataFrame,包含要计算的列 "column_1"。target: int,目标值。返回值:int,等于目标值 target 的元素个数。"""# 使用循环计数def count_loop(X, target: int) -> int:return sum(x == target for x in X["column_1"])# 使用矢量化操作计数def count_vectorized(X, target: int) -> int:return (X["column_1"] == target).sum()
Angenommen, Sie haben einen DataFrame mit einer Datumsspalte und möchten diesen um eine bestimmte Anzahl von Tagen verschieben. Die Berechnung mithilfe vektorisierter Operationen ist wie folgt:
def offset_loop(X, days: int) -> pd.DataFrame:d = pd.Timedelta(days=days)X["column_const"] = [x + d for x in X["column_10"]]return Xdef offset_vectorized(X, days: int) -> pd.DataFrame:X["column_const"] = X["column_10"] + pd.Timedelta(days=days)return X
Der erste und intuitivste Weg zum Iterieren ist die Verwendung einer Python-for-Schleife.
def loop(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:res = []i_remove_col = df.columns.get_loc(remove_col)i_words_to_remove_col = df.columns.get_loc(words_to_remove_col)for i_row in range(df.shape[0]):res.append(remove_words(df.iat[i_row, i_remove_col], df.iat[i_row, i_words_to_remove_col]))return result
def apply(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:return df.apply(func=lambda x: remove_words(x[remove_col], x[words_to_remove_col]), axis=1).tolist()
Bei jeder Iteration von df.apply erhält das bereitgestellte Callable eine Serie, deren Index df.columns ist und deren Werte Zeilen sind. Das bedeutet, dass Pandas die Sequenz in jeder Schleife generieren muss, was teuer ist. Um die Kosten zu senken, ist es besser, apply für die Teilmenge von df aufzurufen, von der Sie wissen, dass Sie sie verwenden werden, etwa so:
def apply_only_used_cols(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:return df[[remove_col, words_to_remove_col]].apply(func=lambda x: remove_words(x[remove_col], x[words_to_remove_col]), axis=1)
Es ist auf jeden Fall besser, die Iteration mit Itertuples in Kombination mit Listen durchzuführen. itertuples generiert (benannte) Tupel mit Zeilendaten.
def itertuples_only_used_cols(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:return [remove_words(x[0], x[1])for x in df[[remove_col, words_to_remove_col]].itertuples(index=False, name=None)]
zip akzeptiert ein iterierbares Objekt und generiert ein Tupel, wobei das i-te Tupel alle i-ten Elemente des gegebenen iterierbaren Objekts der Reihe nach enthält.
def zip_only_used_cols(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:return [remove_words(x, y) for x, y in zip(df[remove_col], df[words_to_remove_col])]
def to_dict_only_used_columns(df: pd.DataFrame) -> list[str]:return [remove_words(row[remove_col], row[words_to_remove_col])for row in df[[remove_col, words_to_remove_col]].to_dict(orient="records")]
Zusätzlich zu den besprochenen iterativen Techniken können zwei weitere Methoden dazu beitragen, die Leistung des Codes zu verbessern: Caching und Parallelisierung. Caching ist besonders nützlich, wenn Sie eine Pandas-Funktion mehrmals mit denselben Argumenten aufrufen. Wenn beispielsweise „remove_words“ auf einen Datensatz mit vielen doppelten Werten angewendet wird, können Sie functools.lru_cache verwenden, um die Ergebnisse der Funktion zu speichern und zu vermeiden, dass sie jedes Mal neu berechnet werden. Um lru_cache zu verwenden, fügen Sie einfach den @lru_cache-Dekorator zur Deklaration von „remove_words“ hinzu und wenden Sie die Funktion dann mit Ihrer bevorzugten Iterationsmethode auf Ihren Datensatz an. Dies kann die Geschwindigkeit und Effizienz Ihres Codes erheblich verbessern. Nehmen Sie den folgenden Code als Beispiel:
@lru_cachedef remove_words(...):... # Same implementation as beforedef zip_only_used_cols_cached(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:return [remove_words(x, y) for x, y in zip(df[remove_col], df[words_to_remove_col])]
Das Hinzufügen dieses Dekorators generiert eine Funktion, die sich die Ausgabe zuvor gefundener Eingaben „merkt“, sodass der gesamte Code nicht erneut ausgeführt werden muss.
Der letzte Trumpf besteht darin, Pandarallel zu verwenden, um unsere Funktionsaufrufe über mehrere unabhängige DF-Blöcke hinweg zu parallelisieren. Das Tool ist einfach zu verwenden: Sie importieren und initialisieren es einfach und ändern dann alle .applys in .parallel_applys.
from pandarallel import pandarallelpandarallel.initialize(nb_workers=min(os.cpu_count(), 12))def parapply_only_used_cols(df: pd.DataFrame, remove_col: str, words_to_remove_col: str) -> list[str]:return df[[remove_col, words_to_remove_col]].parallel_apply(lambda x: remove_words(x[remove_col], x[words_to_remove_col]), axis=1)
Das obige ist der detaillierte Inhalt vonZwei tolle Tipps zur Verbesserung der Effizienz Ihres Pandas-Codes. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Einführung in die Verwendung des gesamten VBS-Codes
Einführung in die Verwendung des gesamten VBS-Codes
 So ändern Sie den Dateityp in Win7
So ändern Sie den Dateityp in Win7
 So erstatten Sie den von Douyin aufgeladenen Doucoin zurück
So erstatten Sie den von Douyin aufgeladenen Doucoin zurück
 Was sind die Oracle-Indextypen?
Was sind die Oracle-Indextypen?
 Welche Möglichkeiten gibt es, Iframe zu schreiben?
Welche Möglichkeiten gibt es, Iframe zu schreiben?
 Was ist der cmd-Befehl zum Bereinigen von Datenmüll auf Laufwerk C?
Was ist der cmd-Befehl zum Bereinigen von Datenmüll auf Laufwerk C?
 Wie ist die Leistung von thinkphp?
Wie ist die Leistung von thinkphp?
 Kernelpanic-Lösung
Kernelpanic-Lösung
 mysqlPasswort vergessen
mysqlPasswort vergessen








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



