
 Technologie-Peripheriegeräte
KI
ICLR'24 neue Ideen ohne Bilder! LaneSegNet: Kartenlernen basierend auf dem Bewusstsein für die Spursegmentierung
Technologie-Peripheriegeräte
KI
ICLR'24 neue Ideen ohne Bilder! LaneSegNet: Kartenlernen basierend auf dem Bewusstsein für die Spursegmentierung
ICLR'24 neue Ideen ohne Bilder! LaneSegNet: Kartenlernen basierend auf dem Bewusstsein für die Spursegmentierung

Vorab geschrieben und nach persönlichem Verständnis des Autors
Als Schlüsselinformation für nachgelagerte Anwendungen autonomer Fahrsysteme werden Karten normalerweise durch Fahrspuren oder Mittellinien dargestellt. Die vorhandene Literatur zum Kartenlernen konzentriert sich jedoch hauptsächlich auf die Erkennung geometriebasierter topologischer Beziehungen von Fahrspuren oder die Erfassung von Mittellinien. Beide Methoden ignorieren die inhärente Beziehung zwischen Fahrspurlinien und Mittellinien, das heißt, Fahrspurlinien binden Mittellinien. Obwohl die einfache Vorhersage zweier Fahrspurtypen in einem Modell sich im Lernziel gegenseitig ausschließt, schlägt dieser Artikel die Fahrspursegmentierung als neue Darstellung vor, die geometrische und topologische Informationen nahtlos kombiniert, und schlägt somit LaneSegNet vor. Dies ist das erste End-to-End-Kartierungsnetzwerk, das Fahrspursegmente generiert, um eine vollständige Darstellung der Straßenstruktur zu erhalten. LaneSegNet weist zwei wichtige Modifikationen auf: Eine davon ist das Spuraufmerksamkeitsmodul, das zur Erfassung wichtiger Bereichsdetails im Fernmerkmalsraum verwendet wird. Das andere ist die gleiche Initialisierungsstrategie des Referenzpunkts, die das Lernen von Positionspriors für die Fahrspuraufmerksamkeit verbessert. Im OpenLane-V2-Datensatz bietet LaneSegNet in drei Aufgaben erhebliche Vorteile gegenüber früheren ähnlichen Produkten: Erkennung von Kartenelementen (+4,8 mAP), Wahrnehmung der Fahrspurmittellinie (+6,9 DETl) und neu definierte Spursegmenterkennung (+5,6 mAP). Darüber hinaus wurde eine Echtzeit-Inferenzgeschwindigkeit von 14,7 FPS erreicht.
Open-Source-Link: https://github.com/OpenDriveLab/LaneSegNet
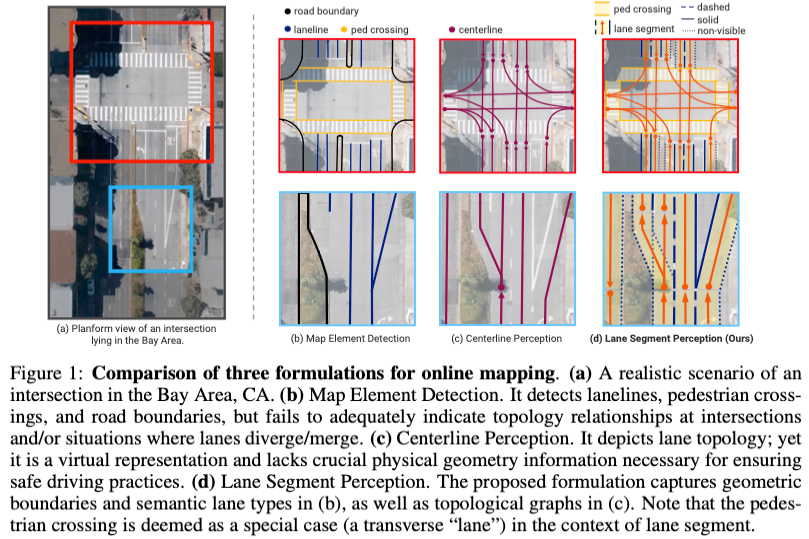
Zusammenfassend sind die Hauptbeiträge dieses Artikels wie folgt:
- Dieser Artikel stellt eine neue Spursegmentwahrnehmung als neue Karte vor Lernformel. Es enthält geometrische und topologische Elemente. Wir hoffen, dass es neue Erkenntnisse auf diesem Gebiet bringen wird.
- In diesem Artikel wird LaneSegNet vorgeschlagen, ein End-to-End-Netzwerk zur Erkennung von Spursegmenten. Es wurden zwei neue Modifikationen vorgeschlagen, darunter ein Spuraufmerksamkeitsmodul mit Heads-to-Regions-Mechanismus zur Erfassung der Fernaufmerksamkeit und die gleiche Initialisierungsstrategie für Referenzpunkte zur Verbesserung der Position vor der Spuraufmerksamkeit.
Überprüfung verwandter Arbeiten
Mittellinienbewusstsein: Das Mittellinienbewusstsein aus fahrzeugmontierten Sensordaten (dasselbe wie das Spurkartenlernen in diesem Artikel) hat in letzter Zeit große Aufmerksamkeit erregt. STSU schlug ein DETR-ähnliches Netzwerk zur Erkennung von Mittellinien vor, gefolgt von einem Multilayer-Perceptron-Modul (MLP) zur Bestimmung ihrer Konnektivität. Basierend auf STSU führten Can et al. eine zusätzliche Mindestschleifenabfrage ein, um die korrekte Reihenfolge überlappender Zeilen sicherzustellen. CenterLineDet behandelt Mittellinien als Scheitelpunkte und entwirft ein Diagrammaktualisierungsmodell, das durch Nachahmungslernen trainiert wird. Es ist erwähnenswert, dass Tesla das Konzept der „Spursprache“ vorgeschlagen hat, um die Spurkarte als Satz auszudrücken. Ihr aufmerksamkeitsbasiertes Modell sagt rekursiv Fahrbahnmarkierungen und deren Konnektivität voraus. Zusätzlich zu diesen Segmentierungsmethoden führt LaneGAP auch eine Pfadmethode ein, die einen zusätzlichen Transformationsalgorithmus verwendet, um die Fahrspurkarte wiederherzustellen. TopoNet zielt auf vollständige und vielfältige Fahrszenendiagramme ab, modelliert explizit die Konnektivität von Mittellinien innerhalb des Netzwerks und bezieht Verkehrselemente in die Aufgabe ein. In dieser Arbeit verwenden wir die Segmentmethode, um Spurdiagramme zu erstellen. Wir unterscheiden uns jedoch von früheren Methoden bei der Modellierung von Fahrspursegmenten, anstatt die Mittellinie als Scheitelpunkt des Fahrspurdiagramms zu verwenden, was eine bequeme Integration geometrischer und semantischer Informationen auf Segmentebene ermöglicht.
Erkennung von Kartenelementen: In früheren Arbeiten wurde darauf geachtet, die Erkennung von Kartenelementen von der Kameraebene auf den 3D-Raum zu verlagern, um Projektionsfehler zu überwinden. Angesichts des beliebten Trends der BEV-Erkennung konzentrieren sich aktuelle Arbeiten auf das Erlernen von HD-Karten mithilfe von Segmentierungs- und Vektorisierungsmethoden. Durch die Kartensegmentierung wird die Semantik jedes reinen BEV-Rasters vorhergesagt, z. B. Fahrspuren, Fußgängerüberwege und befahrbare Bereiche. Diese Arbeiten unterscheiden sich hauptsächlich in der perspektivischen Ansicht (PV) zu BEV-Konvertierungsmodulen. Segmentierte Karten liefern jedoch keine direkten Informationen, die von nachgeschalteten Modulen verwendet werden. HDMapNet löst dieses Problem, indem es Segmentierungskarten mit komplexer Nachbearbeitung gruppiert und vektorisiert.
Obwohl die dichte Segmentierung Informationen auf Pixelebene liefert, kann sie dennoch nicht die komplexen Beziehungen überlappender Elemente berühren. VectorMapNet schlägt vor, jedes Kartenelement direkt als Folge von Punkten darzustellen und dabei grobe Schlüsselpunkte zu verwenden, um die Spurpositionen sequentiell zu dekodieren. MapTR erforscht einen einheitlichen permutationsbasierten Punktsequenzmodellierungsansatz, um Modellierungsmehrdeutigkeiten zu beseitigen und Leistung und Effizienz zu verbessern. PivotNet modelliert Kartenelemente außerdem mithilfe einer Pivot-basierten Darstellung in einem Ensemble-Vorhersage-Framework, um Redundanz zu reduzieren und die Genauigkeit zu verbessern. StreamMapNet nutzt Mehrpunktaufmerksamkeit und zeitliche Informationen, um die Stabilität der Remote-Erkennung von Kartenelementen zu verbessern. Da die Vektorisierung tatsächlich auch die Richtungsinformationen von Fahrspuren bereichert, können vektorisierungsbasierte Methoden durch abwechselnde Überwachung leicht an die Mittellinienerkennung angepasst werden. In dieser Arbeit schlagen wir eine einheitliche, leicht zu erlernende Darstellung – Fahrspursegmentierung – für alle HD-Kartenelemente auf einer Straße vor.
Detaillierte Erläuterung von LaneSegNet
Beschreibung der Aufgabe zur Sensibilisierung für die Spursegmentierung
Instanzen von Lane Segment enthalten die geometrischen und semantischen Aspekte der Straße. Die Geometrie kann als Liniensegment dargestellt werden, das aus einer vektorisierten Mittellinie und der entsprechenden Fahrspurbegrenzung besteht: . Jede Linie ist als geordnete Ansammlung von Punkten im 3D-Raum definiert. Alternativ kann die Geometrie als geschlossenes Polygon beschrieben werden, das den befahrbaren Bereich innerhalb dieser Fahrspur definiert.
In Bezug auf die Semantik umfasst es die Fahrspursegmentkategorie C (z. B. Fahrspursegment, Fußgängerüberweg) und den Linienstil der linken/rechten Fahrspurbegrenzung (z. B. unsichtbare, durchgezogene, gestrichelte Linie): {}. Diese Details liefern autonomen Fahrzeugen wichtige Erkenntnisse über Verzögerungsanforderungen und die Durchführbarkeit von Spurwechseln.
Darüber hinaus spielen topologische Informationen eine entscheidende Rolle bei der Pfadplanung. Um diese Informationen darzustellen, wird ein Fahrspurdiagramm für das Fahrspursegment erstellt, dargestellt als G = (V, E). Jedes Spursegment ist ein Knoten im Diagramm, dargestellt durch die Menge V, und die Kanten in der Menge E beschreiben die Konnektivität zwischen Spursegmenten. Wir verwenden eine Adjazenzmatrix, um dieses Spurdiagramm zu speichern, wobei das Matrixelement (i, j) nur dann auf 1 gesetzt wird, wenn das j-te Spursegment auf das i-te Spursegment folgt, andernfalls bleibt es 0.
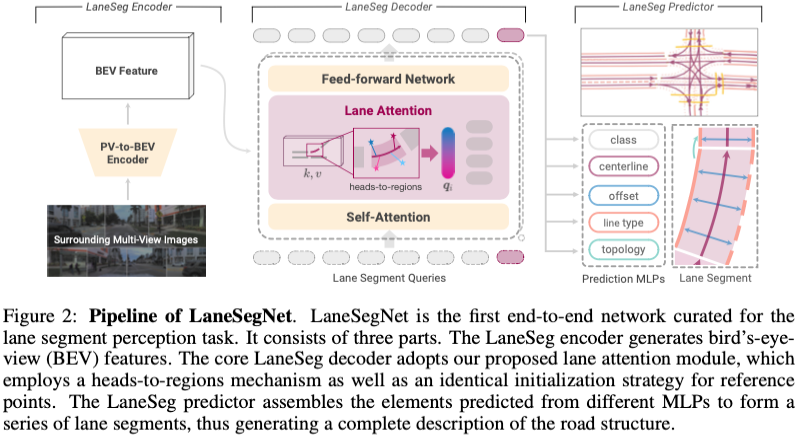
LaneSegNet-Framework
Das Gesamtframework von LaneSegNet ist in Abbildung 2 dargestellt. LaneSegNet verwendet Surround-Bilder als Eingabe, um Spursegmente innerhalb eines bestimmten BEV-Bereichs wahrzunehmen. In diesem Abschnitt stellen wir zunächst kurz den LaneSeg-Encoder vor, der zum Generieren von BEV-Funktionen verwendet wird. Anschließend führen wir den Spursegmentierungsdecoder und die Spuraufmerksamkeit ein. Schließlich schlagen wir Prädiktoren für die Spursegmentierung sowie Trainingsverluste vor.
LaneSeg-Encoder
Der Encoder wandelt das Surround-Bild in BEV-Funktionen für die Spursegmentextraktion um. Wir nutzen das Standard-ResNet-50-Backbone, um Feature-Maps aus Rohbildern abzuleiten. Das PV-zu-BEV-Encodermodul mit BEVFormer wird dann für die Ansichtskonvertierung verwendet.
LaneSeg Decoder
Die transformatorbasierte Erkennungsmethode nutzt den Decoder, um Features von BEV-Features zu sammeln und aktualisiert die Decoderabfrage über mehrere Ebenen. Jede Decoderschicht nutzt Selbstaufmerksamkeits-, Kreuzaufmerksamkeitsmechanismen und Feed-Forward-Netzwerke, um die Abfrage zu aktualisieren. Zusätzlich werden lernbare Standortabfragen eingesetzt. Die aktualisierte Abfrage wird dann ausgegeben und der nächsten Stufe zugeführt.
Aufgrund komplexer und langgestreckter Kartengeometrien ist die Erfassung von BEV-Merkmalen mit großer Reichweite für Online-Kartierungsaufgaben von entscheidender Bedeutung. Frühere Arbeiten nutzen hierarchische (Instanzpunkt-)Decoder-Abfragen und verformbare Aufmerksamkeit, um lokale Merkmale für jede Punktabfrage zu extrahieren. Obwohl dieser Ansatz die Erfassung von Informationen über große Entfernungen vermeidet, ist er aufgrund der erhöhten Anzahl von Abfragen mit einem hohen Rechenaufwand verbunden.
Lane Segment weist als Lane-Instanzdarstellung zum Erstellen von Szenendiagrammen überlegene Eigenschaften auf Instanzebene auf. Unser Ziel besteht nicht darin, Mehrpunktabfragen zu verwenden, sondern Einzelinstanzabfragen zur Darstellung von Spursegmenten zu verwenden. Die zentrale Herausforderung besteht daher darin, Einzelinstanzabfragen zu verwenden, um den Fokus auf globale BEV-Funktionen zu richten.
Lane Attention: Bei der Zielerkennung nutzt die verformbare Aufmerksamkeit die Position vor dem Ziel und konzentriert sich nur auf einen kleinen Teil der Aufmerksamkeitswerte in der Nähe des Zielreferenzpunkts als Vorfilter, was die Konvergenz erheblich beschleunigt. Während der Schichtiterationen wird ein Referenzpunkt in der Mitte des Vorhersageziels platziert, um die Abtastorte der Aufmerksamkeitswerte zu verfeinern, die über lernbare Abtastversätze um den Referenzpunkt verteilt werden. Die absichtliche Initialisierung des Sampling-Offsets berücksichtigt die Geometrie vor dem 2D-Ziel. Auf diese Weise kann der Mehrzweigmechanismus die Eigenschaften jeder Richtung gut erfassen, wie in Abbildung 3a dargestellt.
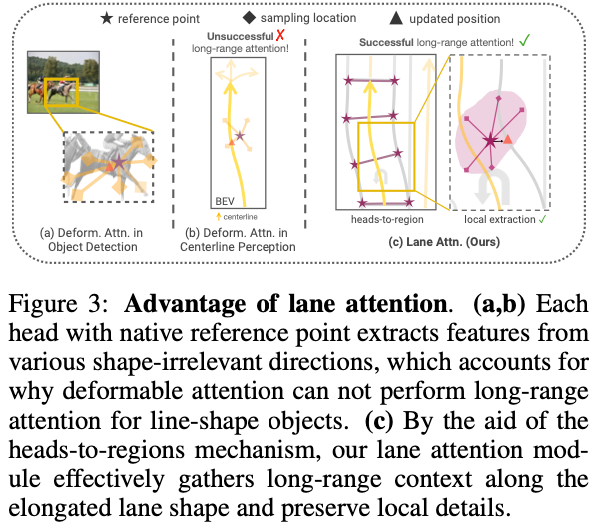
Im Zusammenhang mit dem Kartenlernen verwendeten Li et al. naive deformierbare Aufmerksamkeit, um Mittellinien vorherzusagen. Wie in Abbildung 3b dargestellt, ist es jedoch aufgrund der naiven Platzierung der Referenzpunkte möglicherweise nicht möglich, die Aufmerksamkeit eines einzelnen Bereichs zu erhalten. Darüber hinaus erfordert dieser Prozess aufgrund der länglichen Form des Ziels und komplexer visueller Hinweise (z. B. die genaue Vorhersage von Haltepunkten zwischen durchgezogenen und gestrichelten Linien) ein zusätzliches adaptives Design für unsere Aufgabe. Unter Berücksichtigung all dieser Merkmale muss das Netzwerk nicht nur in der Lage sein, sich auf weitreichende Kontextinformationen zu konzentrieren, sondern auch lokale Details präzise zu extrahieren. Daher wird empfohlen, die Probenahmeorte über einen großen Bereich zu verteilen, um Informationen über große Entfernungen effektiv wahrnehmen zu können. Andererseits sollten lokale Details leicht erkennbar sein, um wichtige Punkte zu identifizieren. Es ist erwähnenswert, dass, obwohl eine Konkurrenzbeziehung zwischen Wertmerkmalen innerhalb eines einzelnen Aufmerksamkeitskopfes besteht, Wertmerkmale zwischen verschiedenen Köpfen während des Aufmerksamkeitsprozesses beibehalten werden können. Daher ist es vielversprechend, diese Eigenschaft gezielt zu nutzen, um die Aufmerksamkeit auf lokale Besonderheiten einer bestimmten Region zu lenken.
Zu diesem Zweck wird in diesem Artikel die Einrichtung eines Heads-to-Regions-Mechanismus vorgeschlagen. Wir verteilen zunächst mehrere Referenzpunkte gleichmäßig innerhalb des Fahrspursegmentbereichs. Die Probenahmeorte werden dann um jeden Referenzpunkt im lokalen Bereich herum initialisiert. Um komplexe lokale Details zu bewahren, verwenden wir einen mehrzweigigen Mechanismus, bei dem sich jeder Kopf auf einen bestimmten Satz von Probenahmeorten innerhalb eines lokalen Bereichs konzentriert, wie in Abbildung 3c dargestellt.
Eine mathematische Beschreibung des Fahrspuraufmerksamkeitsmoduls wird jetzt bereitgestellt. Unter Berücksichtigung der BEV-Merkmale, des i-ten Spursegment-Abfragemerkmals qi und einer Reihe von Referenzpunkten pi als Eingabe wird die Spuraufmerksamkeit wie folgt berechnet:
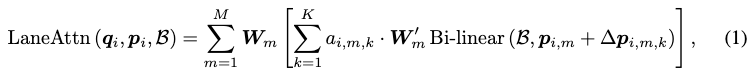
Gleiche Initialisierung der Referenzpunkte: Die Position des Referenzpunkts ist die Spuraufmerksamkeit Modulfunktion bestimmende Faktoren. Um den Interessenbereich jeder Instanzabfrage mit ihrer tatsächlichen Geometrie und Position in Einklang zu bringen, wird der Referenzpunkt p in jeder Instanzabfrage basierend auf der Spursegmentvorhersage der vorherigen Ebene verteilt, wie in Abbildung 3c dargestellt. und die Vorhersagen iterativ verfeinern.
Frühere Arbeiten argumentierten, dass die der ersten Schicht bereitgestellten Referenzpunkte individuell mit lernbaren Prioritäten initialisiert werden sollten, die aus Einbettungen von Positionsabfragen abgeleitet werden. Da die Standortabfrage jedoch unabhängig vom Eingabebild ist, kann diese Initialisierungsmethode wiederum die Fähigkeit des Modells einschränken, sich geometrische und ortsbezogene Prioritäten zu merken, und falsch generierte Initialisierungsstandorte können ebenfalls ein Hindernis für das Training darstellen.
Daher schlagen wir für die erste Schicht des Spursegmentdecoders dieselbe Initialisierungsstrategie vor. In der ersten Ebene nimmt jeder Kopf denselben Referenzpunkt an, der durch die Positionsabfrage generiert wurde. Verglichen mit der verteilten Initialisierung von Referenzpunkten in herkömmlichen Methoden (d. h. der Initialisierung mehrerer Referenzpunkte für jede Abfrage) wird dieselbe Initialisierung das Lernen von Positionspriors stabiler machen, indem die Interferenz komplexer Geometrien herausgefiltert wird. Beachten Sie, dass dieselbe Initialisierung möglicherweise kontraintuitiv erscheint, aber beobachtet wurde, dass sie funktioniert.
LaneSeg Predictor
Wir verwenden MLP in mehreren Vorhersagezweigen, um das endgültige vorhergesagte Spursegment aus der Spursegmentabfrage zu generieren, wobei geometrische, semantische und topologische Aspekte berücksichtigt werden.
Für die Geometrie haben wir zunächst einen Mittellinien-Regressionszweig entworfen, um die vektorisierte Punktposition der Mittellinie in dreidimensionalen Koordinaten zu regressieren. Das Ausgabeformat ist. Aufgrund der Symmetrie der linken und rechten Spurgrenzen führen wir einen Offset-Zweig ein, um den Offset vorherzusagen, dessen Format ist. Daher können die Koordinaten der linken und rechten Spurbegrenzung mithilfe berechnet werden
Unter der Annahme, dass Fahrspursegmente als befahrbare Bereiche konzipiert werden können, integrieren wir den Instanzsegmentierungszweig in den Prädiktor. In Bezug auf die Semantik sagen drei Klassifizierungszweige die Klassifizierungsbewertung von C und die Bewertung von C parallel voraus. Der topologische Zweig verwendet die aktualisierten Abfragemerkmale als Eingabe und gibt mithilfe von MLP eine gewichtete Adjazenzmatrix des Spurgraphen G aus.
Training Loss
LaneSegNet übernimmt ein DETR-ähnliches Paradigma und verwendet den ungarischen Algorithmus, um effizient eine eins-zu-eins optimale Zuordnung zwischen Vorhersagen und Grundwahrheit zu berechnen. Der Trainingsverlust wird dann basierend auf den Verteilungsergebnissen berechnet. Die Verlustfunktion besteht aus vier Teilen: geometrischer Verlust, Klassifizierungsverlust, Spurlinienklassifizierungsverlust und topologischer Verlust.
Geometrischer Verlust überwacht die Geometrie jedes vorhergesagten Fahrspursegments. Gemäß dem Ergebnis des binären Abgleichs wird jedem vorhergesagten vektorisierten Spursegment ein GT-Spursegment zugewiesen. Der vektorisierte geometrische Verlust ist definiert als der Manhattan-Abstand, der zwischen zugewiesenen Spursegmentpaaren berechnet wird.
Experimentelle Ergebnisse
Hauptexperimentelle Struktur
Spursegmentwahrnehmung: In Tabelle 1 vergleichen wir LaneSegNet mit mehreren hochmodernen Methoden, MapTR, MapTRv2 und TopoNet. Trainieren Sie ihr Modell mit unseren Lane-Segment-Labels. LaneSegNet übertrifft andere Methoden in mAP um bis zu 9,6 %, und der durchschnittliche Entfernungsfehler wird relativ um 12,5 % reduziert. LaneSegNet-mini übertrifft auch frühere Methoden mit einer höheren FPS von 16,2.

Qualitative Ergebnisse sind in Abbildung 4 dargestellt:

Erkennung von Kartenelementen: Für einen faireren Vergleich mit Methoden zur Erkennung von Kartenelementen zerlegen wir das vorhergesagte Fahrspursegment von LaneSegNet in Fahrspurpaare verglichen mit modernsten Methoden, die Metriken zur Erkennung von Kartenelementen verwenden. Wir führen die demontierten Fahrspurmarkierungen und Zebrastreifenmarkierungen mehreren hochmodernen Methoden zur Umschulung zu. Die experimentellen Ergebnisse sind in Tabelle 2 aufgeführt und zeigen, dass LaneSegNet andere Methoden bei Aufgaben zur Erkennung von Kartenelementen immer übertrifft. Im fairen Vergleich stellt LaneSegNet die Straßengeometrie mit zusätzlicher Überwachung besser wieder her. Dies zeigt, dass die Lerndarstellung des Fahrspursegments gut zur Erfassung geometrischer Straßeninformationen geeignet ist.
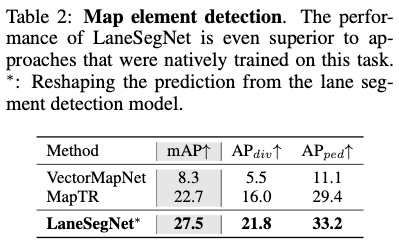
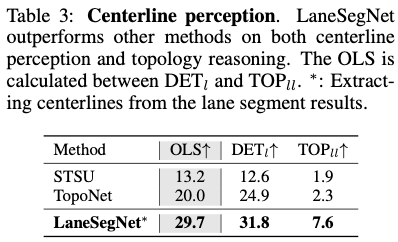
Mittellinienbewusstsein: In Tabelle 3 vergleichen wir LaneSegNet auch mit modernsten Mittellinienbewusstseinsmethoden. Aus Gründen der Konsistenz werden zur Neuschulung auch Mittellinien aus dem Fahrspursegment extrahiert. Daraus lässt sich schließen, dass die Leistung von LaneSegNet bei der Aufgabe der Fahrspurkartenwahrnehmung deutlich höher ist als bei anderen Methoden. Mit zusätzlicher geografischer Überwachung demonstriert LaneSegNet auch überlegene topologische Argumentationsfähigkeiten. Es ist erwiesen, dass die Denkfähigkeit eng mit starken Positionierungs- und Erkennungsfähigkeiten zusammenhängt.
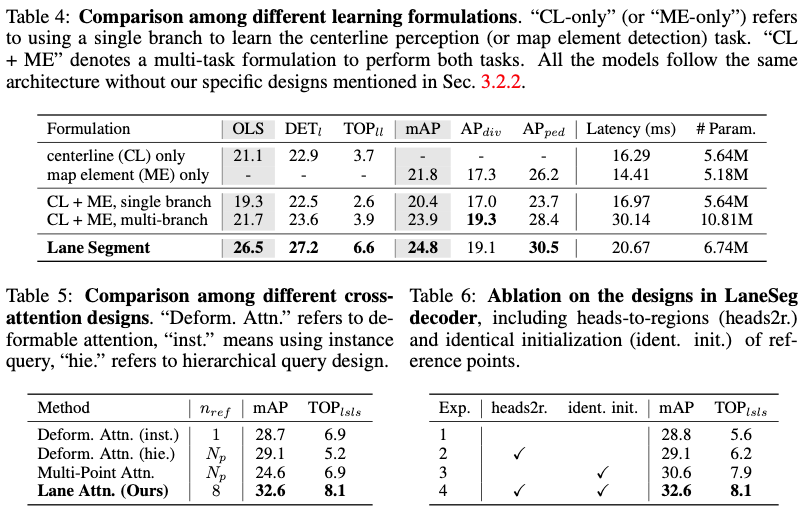
Ablationsexperiment
Lane-Segment-Formel: In Tabelle 4 stellen wir die Ablation bereit, um die Designvorteile und die Trainingseffizienz unserer vorgeschlagenen Lane-Segment-Lernformel zu überprüfen. Im Vergleich zu den separat trainierten Modellen in den ersten beiden Zeilen führt das gemeinsame Training von Mittellinien und Kartenelementen zu einer durchschnittlichen Gesamtverbesserung von 1,3 bei den beiden Hauptmetriken, wie in Zeile 4 gezeigt, was die Machbarkeit eines Multitasking-Trainings demonstriert. Der übliche Ansatz, Mittellinien und Kartenelemente in einem einzigen Zweig zu trainieren, indem zusätzliche Kategorien hinzugefügt werden, führt jedoch zu erheblichen Leistungseinbußen. Im Vergleich zur oben genannten naiven Einzelzweigmethode erzielt unser mit Spursegmentetiketten trainiertes Modell eine deutliche Leistungssteigerung (+7,2 bei OLS und +4,4 bei mAP für den Vergleich zwischen Zeilen 3 und 5). Dies bestätigt die positive Interaktion zwischen verschiedenen Straßeninformationen in Unsere Formulierung zum Kartenlernen. Unser Modell übertrifft sogar Mehrzweigmethoden, insbesondere bei der Mittellinienwahrnehmung (OLS von +4,8). Dies zeigt, dass die Geometrie das topologische Denken in unserer Kartenlernformulierung leiten kann, wobei das Mehrzweigmodell das reine CL-Modell nur geringfügig übertrifft (+0,6 OLS zwischen Zeilen 1 und 4). Der geringfügige Rückgang ist auf den Umformungsprozess unserer Vorhersageergebnisse zurückzuführen, der durch den Fehler bei der Linienklassifizierung verursacht wird. Um einen fairen Vergleich zu ermöglichen, ersetzen wir das Spuraufmerksamkeitsmodul im Framework durch ein alternatives Aufmerksamkeitsdesign. Mit unserem sorgfältigen Design übertrifft LaneSegNet mit Spuraufmerksamkeit diese Methoden deutlich und zeigt deutliche Verbesserungen (mAP verbesserte sich um 3,9 und TOPll verbesserte sich um 1,2 im Vergleich zu Zeile 1). Darüber hinaus kann die Latenz des Decoders durch die Reduzierung der Anzahl der Abfragen im Vergleich zum hierarchischen Abfragedesign weiter reduziert werden (von 23,45 ms auf 20,96 ms).
 Fazit
Fazit
Einschränkungen und zukünftige Arbeit
. Aufgrund rechnerischer Einschränkungen erweitern wir das vorgeschlagene LaneSegNet nicht auf weitere zusätzliche Backbones. Die Formulierung von Lane Segment Awareness und LaneSegNet kann nachgelagerten Aufgaben zugute kommen und ist eine zukünftige Erkundung wert.Das obige ist der detaillierte Inhalt vonICLR'24 neue Ideen ohne Bilder! LaneSegNet: Kartenlernen basierend auf dem Bewusstsein für die Spursegmentierung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 Was passiert, wenn das Netzwerk keine Verbindung zum WLAN herstellen kann?
Apr 03, 2024 pm 12:11 PM
Was passiert, wenn das Netzwerk keine Verbindung zum WLAN herstellen kann?
Apr 03, 2024 pm 12:11 PM
1. Überprüfen Sie das WLAN-Passwort: Stellen Sie sicher, dass das von Ihnen eingegebene WLAN-Passwort korrekt ist und achten Sie auf die Groß-/Kleinschreibung. 2. Überprüfen Sie, ob das WLAN ordnungsgemäß funktioniert: Überprüfen Sie, ob der WLAN-Router normal funktioniert. Sie können andere Geräte an denselben Router anschließen, um festzustellen, ob das Problem beim Gerät liegt. 3. Starten Sie das Gerät und den Router neu: Manchmal liegt eine Fehlfunktion oder ein Netzwerkproblem mit dem Gerät oder Router vor, und ein Neustart des Geräts und des Routers kann das Problem lösen. 4. Überprüfen Sie die Geräteeinstellungen: Stellen Sie sicher, dass die WLAN-Funktion des Geräts eingeschaltet und die WLAN-Funktion nicht deaktiviert ist.
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Tesla-Roboter arbeiten in Fabriken, Musk: Der Freiheitsgrad der Hände wird dieses Jahr 22 erreichen!
May 06, 2024 pm 04:13 PM
Das neueste Video von Teslas Roboter Optimus ist veröffentlicht und er kann bereits in der Fabrik arbeiten. Bei normaler Geschwindigkeit sortiert es Batterien (Teslas 4680-Batterien) so: Der Beamte hat auch veröffentlicht, wie es bei 20-facher Geschwindigkeit aussieht – auf einer kleinen „Workstation“, pflücken und pflücken und pflücken: Dieses Mal wird es freigegeben. Eines der Highlights Der Vorteil des Videos besteht darin, dass Optimus diese Arbeit in der Fabrik völlig autonom und ohne menschliches Eingreifen während des gesamten Prozesses erledigt. Und aus Sicht von Optimus kann es auch die krumme Batterie aufnehmen und platzieren, wobei der Schwerpunkt auf der automatischen Fehlerkorrektur liegt: In Bezug auf die Hand von Optimus gab der NVIDIA-Wissenschaftler Jim Fan eine hohe Bewertung ab: Die Hand von Optimus ist der fünffingrige Roboter der Welt am geschicktesten. Seine Hände sind nicht nur taktil
 FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: der erste Zielerkennungsalgorithmus basierend auf einer Fischaugenkamera
Apr 26, 2024 am 11:37 AM
Die Zielerkennung ist ein relativ ausgereiftes Problem in autonomen Fahrsystemen, wobei die Fußgängererkennung einer der ersten Algorithmen ist, die eingesetzt werden. In den meisten Arbeiten wurde eine sehr umfassende Recherche durchgeführt. Die Entfernungswahrnehmung mithilfe von Fischaugenkameras für die Rundumsicht ist jedoch relativ wenig untersucht. Aufgrund der großen radialen Verzerrung ist es schwierig, die standardmäßige Bounding-Box-Darstellung in Fischaugenkameras zu implementieren. Um die obige Beschreibung zu vereinfachen, untersuchen wir erweiterte Begrenzungsrahmen-, Ellipsen- und allgemeine Polygondesigns in Polar-/Winkeldarstellungen und definieren eine mIOU-Metrik für die Instanzsegmentierung, um diese Darstellungen zu analysieren. Das vorgeschlagene Modell „fisheyeDetNet“ mit polygonaler Form übertrifft andere Modelle und erreicht gleichzeitig 49,5 % mAP auf dem Valeo-Fisheye-Kameradatensatz für autonomes Fahren
