
 Backend-Entwicklung
Python-Tutorial
Verwendung von Python zur Implementierung des Baumdurchquerungsalgorithmus und der Art der Baumdurchquerung
Backend-Entwicklung
Python-Tutorial
Verwendung von Python zur Implementierung des Baumdurchquerungsalgorithmus und der Art der Baumdurchquerung
Verwendung von Python zur Implementierung des Baumdurchquerungsalgorithmus und der Art der Baumdurchquerung

树遍历意味着访问树中的每个节点。和线性数据结构单一的遍历方式不同,二叉树是分层式数据结构可以以不同的方式遍历。
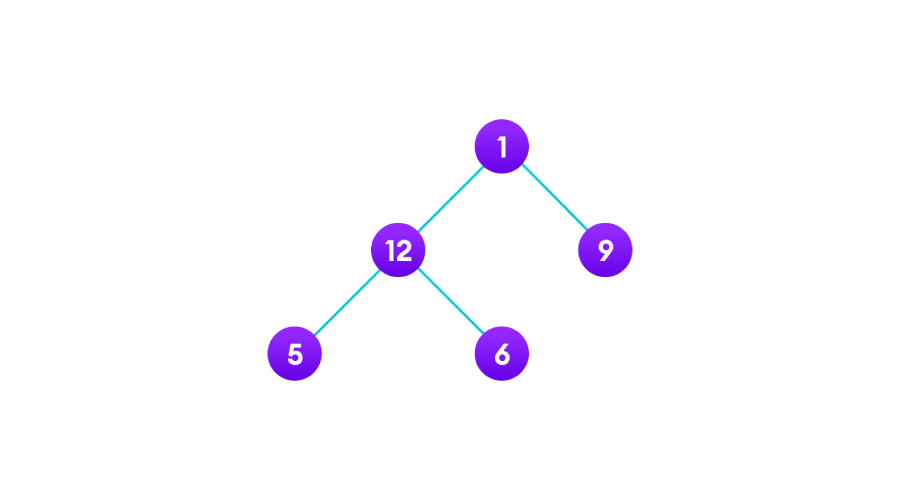
树遍历结构特点
1、每个树的节点都承载一个数据
2、每个树下都有2个子树
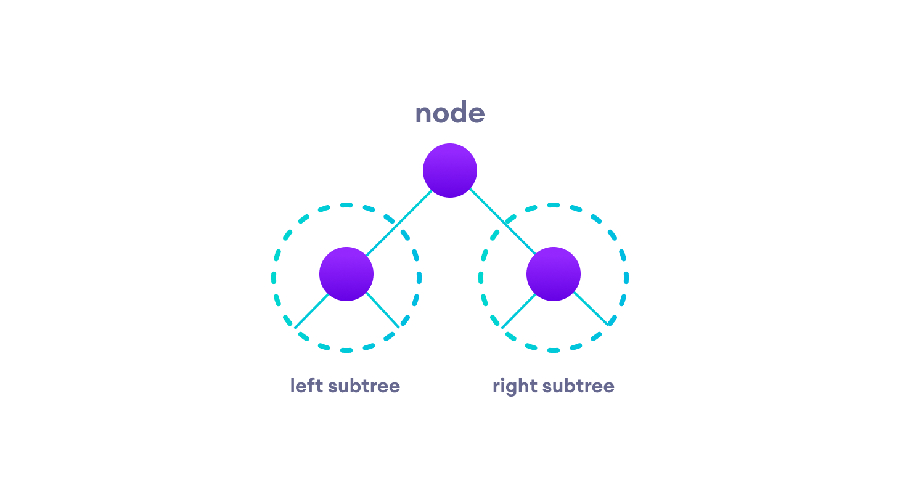
树遍历有三种类型
1、中序遍历
先遍历左子树所有节点,在是根节点,最后访问右子树所有节点。
2、前序遍历
先遍历根节点,再访问左子树中的所有节点,最后访问右子树中的所有节点。
3、后序遍历
先访问左子树中的所有节点,再访问右子树中的所有节点,最后访问根节点。
Python实现树遍历
class Node:
def __init__(self,item):
self.left=None
self.right=None
self.val=item
#中序遍历
def inorder(root):
if root:
inorder(root.left)
print(str(root.val)+"->",end='')
inorder(root.right)
#前序遍历
def postorder(root):
if root:
postorder(root.left)
postorder(root.right)
print(str(root.val)+"->",end='')
#后序遍历
def preorder(root):
if root:
print(str(root.val)+"->",end='')
preorder(root.left)
preorder(root.right)
root=Node(1)
root.left=Node(2)
root.right=Node(3)
root.left.left=Node(4)
root.left.right=Node(5)
print("中序遍历")
inorder(root)
print("前序遍历")
preorder(root)
print("后序遍历")
postorder(root)Das obige ist der detaillierte Inhalt vonVerwendung von Python zur Implementierung des Baumdurchquerungsalgorithmus und der Art der Baumdurchquerung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Wie löste ich das Problem der Berechtigungen beim Betrachten der Python -Version in Linux Terminal?
Apr 01, 2025 pm 05:09 PM
Wie löste ich das Problem der Berechtigungen beim Betrachten der Python -Version in Linux Terminal?
Apr 01, 2025 pm 05:09 PM
Lösung für Erlaubnisprobleme beim Betrachten der Python -Version in Linux Terminal Wenn Sie versuchen, die Python -Version in Linux Terminal anzuzeigen, geben Sie Python ein ...
 Wie kann ich die gesamte Spalte eines Datenrahmens effizient in einen anderen Datenrahmen mit verschiedenen Strukturen in Python kopieren?
Apr 01, 2025 pm 11:15 PM
Wie kann ich die gesamte Spalte eines Datenrahmens effizient in einen anderen Datenrahmen mit verschiedenen Strukturen in Python kopieren?
Apr 01, 2025 pm 11:15 PM
Bei der Verwendung von Pythons Pandas -Bibliothek ist das Kopieren von ganzen Spalten zwischen zwei Datenrahmen mit unterschiedlichen Strukturen ein häufiges Problem. Angenommen, wir haben zwei Daten ...
 Wie erstelle ich dynamisch ein Objekt über eine Zeichenfolge und rufe seine Methoden in Python auf?
Apr 01, 2025 pm 11:18 PM
Wie erstelle ich dynamisch ein Objekt über eine Zeichenfolge und rufe seine Methoden in Python auf?
Apr 01, 2025 pm 11:18 PM
Wie erstellt in Python ein Objekt dynamisch über eine Zeichenfolge und ruft seine Methoden auf? Dies ist eine häufige Programmieranforderung, insbesondere wenn sie konfiguriert oder ausgeführt werden muss ...
 Was sind einige beliebte Python -Bibliotheken und ihre Verwendung?
Mar 21, 2025 pm 06:46 PM
Was sind einige beliebte Python -Bibliotheken und ihre Verwendung?
Mar 21, 2025 pm 06:46 PM
In dem Artikel werden beliebte Python-Bibliotheken wie Numpy, Pandas, Matplotlib, Scikit-Learn, TensorFlow, Django, Flask und Anfragen erörtert, die ihre Verwendung in wissenschaftlichen Computing, Datenanalyse, Visualisierung, maschinellem Lernen, Webentwicklung und h beschreiben
 Wie hört Uvicorn kontinuierlich auf HTTP -Anfragen ohne Serving_forver () an?
Apr 01, 2025 pm 10:51 PM
Wie hört Uvicorn kontinuierlich auf HTTP -Anfragen ohne Serving_forver () an?
Apr 01, 2025 pm 10:51 PM
Wie hört Uvicorn kontinuierlich auf HTTP -Anfragen an? Uvicorn ist ein leichter Webserver, der auf ASGI basiert. Eine seiner Kernfunktionen ist es, auf HTTP -Anfragen zu hören und weiterzumachen ...
 Wie lehre ich innerhalb von 10 Stunden die Grundlagen für Computer-Anfänger-Programmierbasis in Projekt- und problemorientierten Methoden?
Apr 02, 2025 am 07:18 AM
Wie lehre ich innerhalb von 10 Stunden die Grundlagen für Computer-Anfänger-Programmierbasis in Projekt- und problemorientierten Methoden?
Apr 02, 2025 am 07:18 AM
Wie lehre ich innerhalb von 10 Stunden die Grundlagen für Computer -Anfänger für Programmierungen? Wenn Sie nur 10 Stunden Zeit haben, um Computer -Anfänger zu unterrichten, was Sie mit Programmierkenntnissen unterrichten möchten, was würden Sie dann beibringen ...
 Wie behandle ich die mit Kommas getrennten Listen-Abfrageparameter in Fastapi?
Apr 02, 2025 am 06:51 AM
Wie behandle ich die mit Kommas getrennten Listen-Abfrageparameter in Fastapi?
Apr 02, 2025 am 06:51 AM
Fastapi ...
 Was sind reguläre Ausdrücke?
Mar 20, 2025 pm 06:25 PM
Was sind reguläre Ausdrücke?
Mar 20, 2025 pm 06:25 PM
Regelmäßige Ausdrücke sind leistungsstarke Tools für Musteranpassung und Textmanipulation in der Programmierung, wodurch die Effizienz bei der Textverarbeitung in verschiedenen Anwendungen verbessert wird.
