

Grundprinzipien der intelligenten Sprachsynthese

Statistische parametrische Sprachsynthesemethoden haben aufgrund ihrer Flexibilität im Bereich der Sprachsynthese große Aufmerksamkeit erregt. In den letzten Jahren hat die Anwendung tiefer neuronaler Netzwerkmodelle im Bereich der maschinellen Lernforschung erhebliche Vorteile gegenüber herkömmlichen Methoden erzielt. Die Anwendung neuronaler netzwerkbasierter Modellierungsmethoden in der statistischen parametrischen Sprachsynthese hat sich allmählich vertieft und ist zu einer der gängigen Methoden der Sprachsynthese geworden.
Backend-Akustikmodellierung für die statistische parametrische Sprachsynthese ist das Thema dieses Artikels.
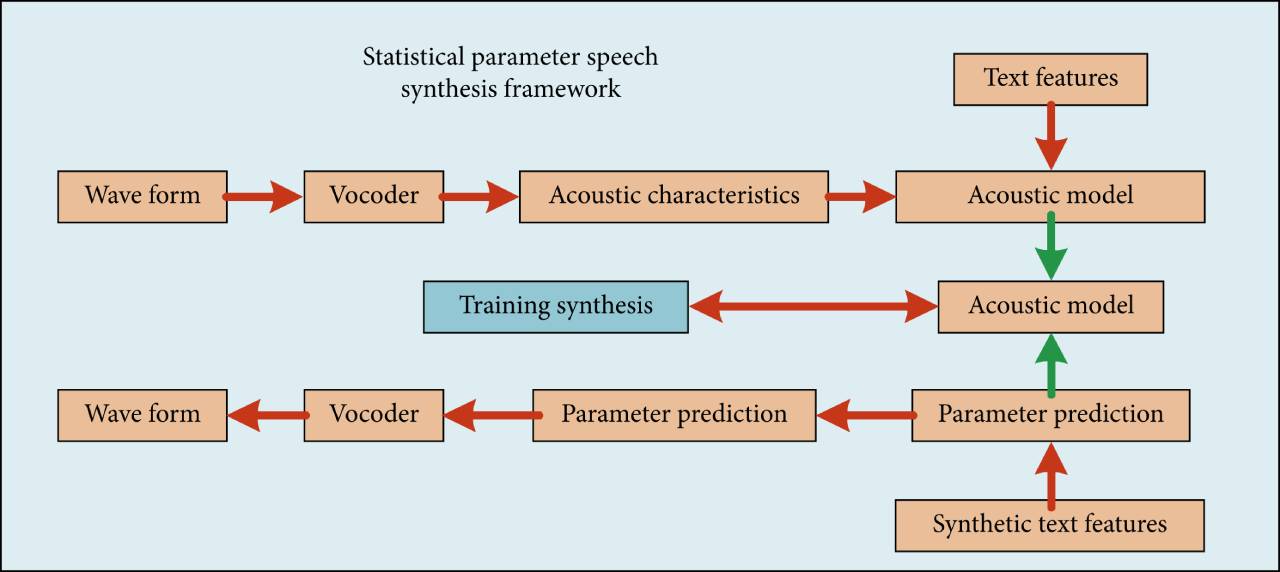
Das Backend-Framework der parametrischen Sprachsynthese
Wie in der Abbildung gezeigt, wird das Backend-Framework der statistischen parametrischen Sprachsynthese beschrieben, das hauptsächlich zwei Phasen umfasst: Training und Synthese.
In der Trainingsphase werden die Sprachwellenformen und entsprechenden Textmerkmale in der Soundbibliothek als Eingabe verwendet. Sprachwellenformen werden durch einen Vocoder extrahiert und mit Textmerkmalen zur akustischen Modellierung kombiniert.
In der Synthesephase werden gemäß dem trainierten akustischen Modell die zu synthetisierenden Textmerkmale eingegeben und die entsprechenden akustischen Merkmale vorhergesagt. Die vorhergesagten akustischen Merkmale werden dann mithilfe eines Vocoders in Sprachwellenformen umgewandelt. Vocoder- und Akustikmodelle sind Schlüsselkomponenten in statistischen parametrischen Sprachsynthesesystemen.
Das Quellfiltermodell der Spracherzeugung wird verwendet, um das Kurzzeitspektrum der Sprache während des Parametrisierungsprozesses der Sprachwellenform in Grundfrequenz und Spektralhüllkurve zu unterteilen. Normalerweise erhalten wir die Anregungseigenschaften von Sprache durch Analyse von Zeitbereichswellenformen oder Frequenzbereichsharmonischen und entfernen dann die Periodizität von Zeit und Frequenz aus dem Amplitudenspektrum, das durch die Kurzzeit-Fourier-Transformation der Sprachwellenform erhalten wird, um das Spektrumpaket von zu erhalten Rede. Netzwerk. Diese Methode kann uns helfen, Sprachsignale besser zu verstehen und zu verarbeiten.
Aufgrund der höheren Dimensionalität der Spektralhülle wird die Modellierung schwieriger, sodass es oft notwendig ist, die Dimensionalität der Spektralhülle zu reduzieren. Die Rekonstruktion der Sprachwellenform ist der umgekehrte Prozess zur Wiederherstellung der ursprünglichen Sprache aus den akustischen Parametern der Sprache. Durch die Angabe der Grundfrequenz, der spektralen Hüllkurve und der Anregungseigenschaften der Sprache in Kombination mit geeigneten Phasenbeschränkungen kann das STFT-Amplitudenspektrum rekonstruiert werden.
Die Dauermodellierung ist ein weiteres Modul der statistischen parametrischen Sprachsynthese. Für die Dauermodellierung ist kein Vocoder erforderlich. Das Grundgerüst ähnelt der akustischen Modellierung. Statistische Modelle werden verwendet, um die Wahrscheinlichkeitsverteilung entsprechender Zeitlängen gegebener Textmerkmale zu modellieren.
Nach mehr als 20 Jahren Entwicklungszeit hat sich die HMM-basierte statistische Parameter-Sprachsynthesemethode zu einer ausgereiften Sprachsynthesemethode entwickelt.
In diesem Abschnitt werden das Hidden-Markov-Modell und seine theoretischen Grundlagen vorgestellt. In Kombination mit bestimmten Phasenbeschränkungen wird das STFT-Amplitudenspektrum rekonstruiert. Die Dauermodellierung ist ein weiteres Modul der statistischen parametrischen Sprachsynthese. Für die Dauermodellierung ist kein Vocoder erforderlich. Das Grundgerüst ähnelt der akustischen Modellierung. Statistische Modelle werden verwendet, um die Wahrscheinlichkeitsverteilung entsprechender Zeitlängen gegebener Textmerkmale zu modellieren. Nach mehr als 20 Jahren Entwicklungszeit hat sich die auf HMM basierende Sprachsynthesemethode mit statistischen Parametern zu einer ausgereiften Sprachsynthesemethode entwickelt.
Das Hidden-Markov-Modell ist ein probabilistisches Modell zur Modellierung von Sequenzen, das aus einer Reihe versteckter Zustandsvariablen und einer Reihe von Beobachtungsvariablen besteht. Das HMM-Modell basiert auf zwei Annahmen.
Die Zustandsvariable gehorcht der Markov-Kette erster Ordnung, das heißt, der aktuelle Zustand hängt nur mit dem vorherigen Zustand zusammen, wie in Formel (1) gezeigt.
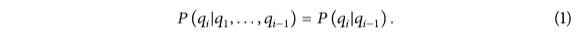
Die Wahrscheinlichkeitsverteilung der beobachteten Variablen zu einem bestimmten Zeitpunkt bezieht sich nur auf den Zustand zum aktuellen Zeitpunkt und hat nichts mit dem Zustand oder den beobachteten Variablen zu anderen Zeitpunkten zu tun, wie in Gleichung (2) dargestellt. .
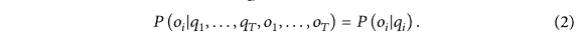
Normalerweise bildet
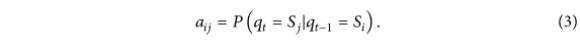
im HMM-Modell geschickt die Zustandsübergangsmatrix A des HMM, und die Wahrscheinlichkeitsdichte der beobachteten Variablen beträgt:
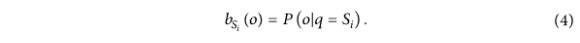
Das ist es Es ist erwähnenswert, dass die HMM-Ausgabewahrscheinlichkeit:
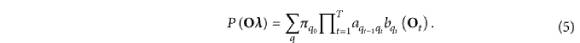
Das Kernprinzip der akustischen Modellierung in der HMM-basierten statistischen parametrischen Sprachsynthesemethode besteht darin, das HMM-Modell zu verwenden, um die akustische Merkmalssequenz von Sprache in einer bestimmten Situation probabilistisch zu modellieren .
Die Konfiguration des gesamten Systems umfasst die Auswahl sprachakustischer Funktionen, die Auswahl von Modellierungseinheiten und die Konfiguration von HMM-Modellen. Zu den akustischen Merkmalen in Sprachsynthesesystemen gehören Anregungsmerkmale und spektrale Merkmale.
Um die Schwierigkeit der HMM-Modellierung bei der Auswahl von Spektralmerkmalen zu verringern, werden im Allgemeinen niedrigdimensionale Spektraldarstellungen verwendet, die die Korrelation zwischen Dimensionen beseitigen, wie z. B. Mel-Cepstrum- und Linienspektrumpaarmerkmale. In Anbetracht der kurzfristigen stationären Eigenschaften von Sprachsignalen und der Modellierungsfähigkeit von HM modellieren HMMs in Sprachsynthesesystemen normalerweise Einheiten auf Phonemebene, wie beispielsweise Vokaleinheiten im Chinesischen. Aufgrund der zeitlichen Eigenschaften von Sprache ist die Topologie von HMM bei der Audiomodellierung häufig ein einseitiger Durchlaufzustand von links nach rechts.
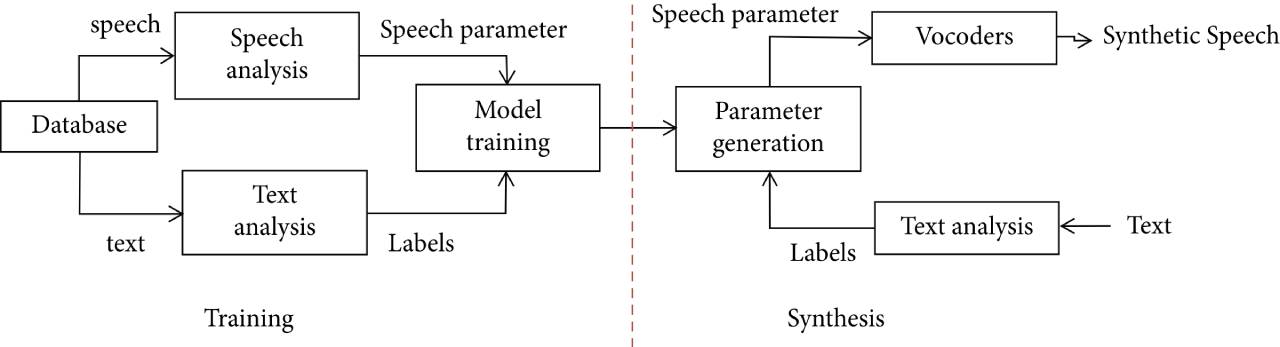
HMM-basiertes Sprachsynthesesystem mit statistischen Parametern
Die Abbildung zeigt das Framework des HMM-basierten Sprachsynthesesystems mit statistischen Parametern. Es ist in die Ausbildungsphase und die umfassende Phase unterteilt. Die Trainingsphase umfasst die Extraktion sprachakustischer Merkmale und das HMM-Modelltraining. Da das HMM-Modell Phoneme als Modellierungseinheiten verwendet, werden normalerweise drei kontextbezogene Phoneme modelliert, um die Modellierungsgenauigkeit zu verbessern.
Im ersten Systemtrainingsprozess wird die Untergrenze der Varianz des HMM-Modells geschätzt, dann wird das Einton-HMM-Modell als Modellinitialisierungsparameter trainiert, dann wird das kontextbezogene Drei-Phonem-HMM-Modell trainiert, und schließlich wird eine Mn-Druckclusterung basierend auf dem Entscheidungsbaum durchgeführt.
In der Synthesephase wird zunächst der Text analysiert, mit der vorhergesagten Zeitlänge kombiniert, die kontextbezogene HMM-Modellsequenz basierend auf dem Entscheidungsbaum bestimmt und anschließend die kontinuierliche akustische Merkmalssequenz durch die Maximum-Likelihood-Parametergenerierung erhalten Algorithmus, und die Sprachwellenform wird vom Synthesizer synthetisiert. Auf HMM basierende statistische parametrische Sprachsynthesesysteme sind zu glatt; ein Grund dafür ist die begrenzte Modellierungsfähigkeit von HMM.
In den letzten Jahren hat sich Deep Learning als Zweig des maschinellen Lernens rasant weiterentwickelt. Unter Deep Learning versteht man die Verwendung von Netzwerkmodellen, die aus mehreren nichtlinearen Transformationen und mehreren Verarbeitungsschichten bestehen, nämlich neuronalen Netzen. Aufgrund der hervorragenden Modellierungsfähigkeiten von DNN und Zoll wird die auf DNN und RNN basierende akustische Modellierungsmethode auf die statistische parametrische Sprachsynthese angewendet, und ihre Wirkung ist besser als die auf HMM basierende akustische Modellierungsmethode.
Es ist mittlerweile die gängige Methode der statistischen parametrischen Sprachsynthese-Akustikmodellierung. Auf DNN und RNN basierende Sprachsynthesesysteme sind im Systemrahmen ähnlich.
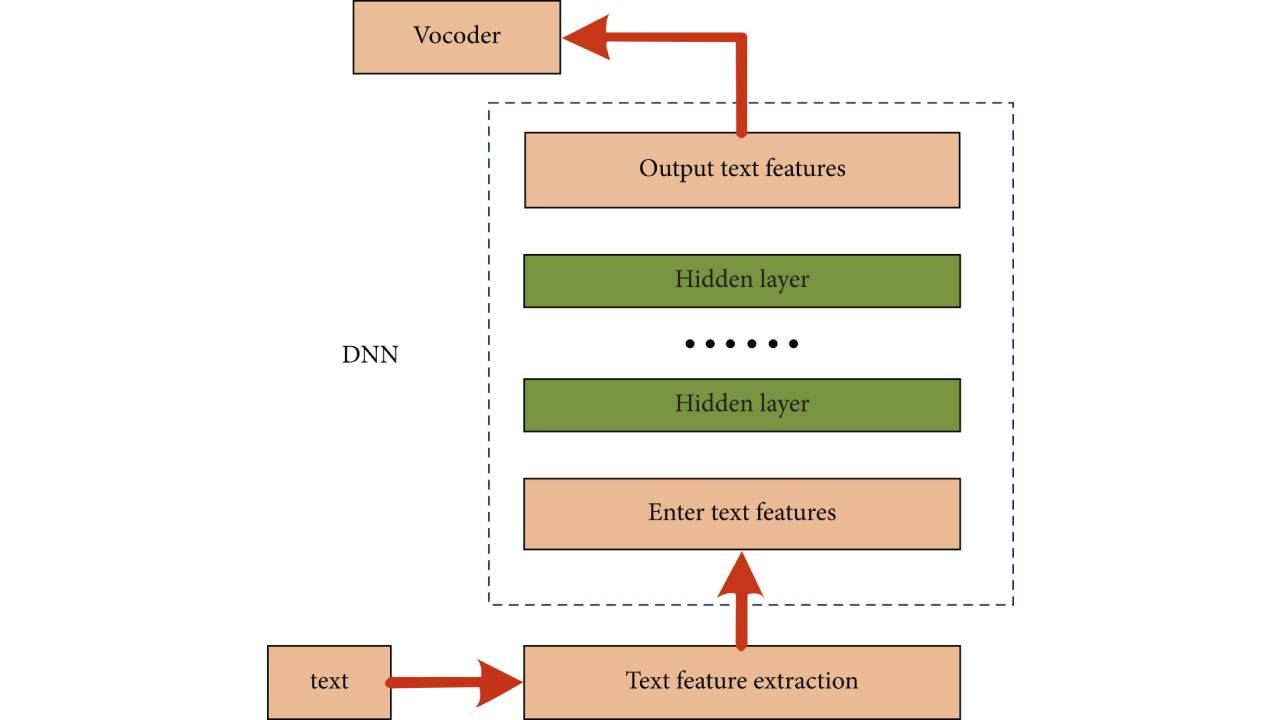
Rahmendiagramm der auf einem neuronalen Netzwerk basierenden Sprachsynthesemethode
Wie in der Abbildung gezeigt, handelt es sich bei den Eingabemerkmalen in der Abbildung um aus dem Text extrahierte Merkmale, d. h. zur Beschreibung werden diskrete oder kontinuierliche numerische Merkmale verwendet Text.
Das Training statistischer parametrischer Sprachsynthesesysteme basierend auf DNN und RNN übernimmt normalerweise Trainingskriterien und verwendet den BP-Algorithmus und den SGD-Algorithmus, um Modellparameter so zu aktualisieren, dass die vorhergesagten akustischen Parameter den natürlichen akustischen Parametern so nahe wie möglich kommen. In der Synthesephase werden Textmerkmale aus dem synthetisierten Text extrahiert, dann werden die entsprechenden akustischen Parameter über DNN oder RNN vorhergesagt und schließlich wird die Sprachwellenform über den Vocoder synthetisiert.
Derzeit werden auf DNN und RNN basierende Modellierungsmethoden hauptsächlich auf sprachakustische Parameter angewendet, einschließlich Grundfrequenz- und Spektralparameter. Informationen zur Dauer müssen noch über andere Systeme abgerufen werden. Darüber hinaus müssen die Eingabe- und Ausgabefunktionen von DNN- und RNN-Modellen zeitlich angepasst werden.
Das obige ist der detaillierte Inhalt vonGrundprinzipien der intelligenten Sprachsynthese. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 15 empfohlene kostenlose Open-Source-Bildanmerkungstools
Mar 28, 2024 pm 01:21 PM
15 empfohlene kostenlose Open-Source-Bildanmerkungstools
Mar 28, 2024 pm 01:21 PM
Bei der Bildanmerkung handelt es sich um das Verknüpfen von Beschriftungen oder beschreibenden Informationen mit Bildern, um dem Bildinhalt eine tiefere Bedeutung und Erklärung zu verleihen. Dieser Prozess ist entscheidend für maschinelles Lernen, das dabei hilft, Sehmodelle zu trainieren, um einzelne Elemente in Bildern genauer zu identifizieren. Durch das Hinzufügen von Anmerkungen zu Bildern kann der Computer die Semantik und den Kontext hinter den Bildern verstehen und so den Bildinhalt besser verstehen und analysieren. Die Bildanmerkung hat ein breites Anwendungsspektrum und deckt viele Bereiche ab, z. B. Computer Vision, Verarbeitung natürlicher Sprache und Diagramm-Vision-Modelle. Sie verfügt über ein breites Anwendungsspektrum, z. B. zur Unterstützung von Fahrzeugen bei der Identifizierung von Hindernissen auf der Straße und bei der Erkennung und Diagnose von Krankheiten durch medizinische Bilderkennung. In diesem Artikel werden hauptsächlich einige bessere Open-Source- und kostenlose Bildanmerkungstools empfohlen. 1.Makesens
 In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In diesem Artikel erfahren Sie mehr über SHAP: Modellerklärung für maschinelles Lernen
Jun 01, 2024 am 10:58 AM
In den Bereichen maschinelles Lernen und Datenwissenschaft stand die Interpretierbarkeit von Modellen schon immer im Fokus von Forschern und Praktikern. Mit der weit verbreiteten Anwendung komplexer Modelle wie Deep Learning und Ensemble-Methoden ist das Verständnis des Entscheidungsprozesses des Modells besonders wichtig geworden. Explainable AI|XAI trägt dazu bei, Vertrauen in maschinelle Lernmodelle aufzubauen, indem es die Transparenz des Modells erhöht. Eine Verbesserung der Modelltransparenz kann durch Methoden wie den weit verbreiteten Einsatz mehrerer komplexer Modelle sowie der Entscheidungsprozesse zur Erläuterung der Modelle erreicht werden. Zu diesen Methoden gehören die Analyse der Merkmalsbedeutung, die Schätzung des Modellvorhersageintervalls, lokale Interpretierbarkeitsalgorithmen usw. Die Merkmalswichtigkeitsanalyse kann den Entscheidungsprozess des Modells erklären, indem sie den Grad des Einflusses des Modells auf die Eingabemerkmale bewertet. Schätzung des Modellvorhersageintervalls
 Identifizieren Sie Über- und Unteranpassung anhand von Lernkurven
Apr 29, 2024 pm 06:50 PM
Identifizieren Sie Über- und Unteranpassung anhand von Lernkurven
Apr 29, 2024 pm 06:50 PM
In diesem Artikel wird vorgestellt, wie Überanpassung und Unteranpassung in Modellen für maschinelles Lernen mithilfe von Lernkurven effektiv identifiziert werden können. Unteranpassung und Überanpassung 1. Überanpassung Wenn ein Modell mit den Daten übertrainiert ist, sodass es daraus Rauschen lernt, spricht man von einer Überanpassung des Modells. Ein überangepasstes Modell lernt jedes Beispiel so perfekt, dass es ein unsichtbares/neues Beispiel falsch klassifiziert. Für ein überangepasstes Modell erhalten wir einen perfekten/nahezu perfekten Trainingssatzwert und einen schrecklichen Validierungssatz-/Testwert. Leicht geändert: „Ursache der Überanpassung: Verwenden Sie ein komplexes Modell, um ein einfaches Problem zu lösen und Rauschen aus den Daten zu extrahieren. Weil ein kleiner Datensatz als Trainingssatz möglicherweise nicht die korrekte Darstellung aller Daten darstellt. 2. Unteranpassung Heru.“
 Transparent! Eine ausführliche Analyse der Prinzipien der wichtigsten Modelle des maschinellen Lernens!
Apr 12, 2024 pm 05:55 PM
Transparent! Eine ausführliche Analyse der Prinzipien der wichtigsten Modelle des maschinellen Lernens!
Apr 12, 2024 pm 05:55 PM
Laienhaft ausgedrückt ist ein Modell für maschinelles Lernen eine mathematische Funktion, die Eingabedaten einer vorhergesagten Ausgabe zuordnet. Genauer gesagt ist ein Modell für maschinelles Lernen eine mathematische Funktion, die Modellparameter anpasst, indem sie aus Trainingsdaten lernt, um den Fehler zwischen der vorhergesagten Ausgabe und der wahren Bezeichnung zu minimieren. Beim maschinellen Lernen gibt es viele Modelle, z. B. logistische Regressionsmodelle, Entscheidungsbaummodelle, Support-Vektor-Maschinenmodelle usw. Jedes Modell verfügt über seine anwendbaren Datentypen und Problemtypen. Gleichzeitig gibt es viele Gemeinsamkeiten zwischen verschiedenen Modellen oder es gibt einen verborgenen Weg für die Modellentwicklung. Am Beispiel des konnektionistischen Perzeptrons können wir es durch Erhöhen der Anzahl verborgener Schichten des Perzeptrons in ein tiefes neuronales Netzwerk umwandeln. Wenn dem Perzeptron eine Kernelfunktion hinzugefügt wird, kann es in eine SVM umgewandelt werden. Dieses hier
 Die Entwicklung der künstlichen Intelligenz in der Weltraumforschung und der Siedlungstechnik
Apr 29, 2024 pm 03:25 PM
Die Entwicklung der künstlichen Intelligenz in der Weltraumforschung und der Siedlungstechnik
Apr 29, 2024 pm 03:25 PM
In den 1950er Jahren wurde die künstliche Intelligenz (KI) geboren. Damals entdeckten Forscher, dass Maschinen menschenähnliche Aufgaben wie das Denken ausführen können. Später, in den 1960er Jahren, finanzierte das US-Verteidigungsministerium künstliche Intelligenz und richtete Labore für die weitere Entwicklung ein. Forscher finden Anwendungen für künstliche Intelligenz in vielen Bereichen, etwa bei der Erforschung des Weltraums und beim Überleben in extremen Umgebungen. Unter Weltraumforschung versteht man die Erforschung des Universums, das das gesamte Universum außerhalb der Erde umfasst. Der Weltraum wird als extreme Umgebung eingestuft, da sich seine Bedingungen von denen auf der Erde unterscheiden. Um im Weltraum zu überleben, müssen viele Faktoren berücksichtigt und Vorkehrungen getroffen werden. Wissenschaftler und Forscher glauben, dass die Erforschung des Weltraums und das Verständnis des aktuellen Zustands aller Dinge dazu beitragen können, die Funktionsweise des Universums zu verstehen und sich auf mögliche Umweltkrisen vorzubereiten
 Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Zu den häufigsten Herausforderungen, mit denen Algorithmen für maschinelles Lernen in C++ konfrontiert sind, gehören Speicherverwaltung, Multithreading, Leistungsoptimierung und Wartbarkeit. Zu den Lösungen gehören die Verwendung intelligenter Zeiger, moderner Threading-Bibliotheken, SIMD-Anweisungen und Bibliotheken von Drittanbietern sowie die Einhaltung von Codierungsstilrichtlinien und die Verwendung von Automatisierungstools. Praktische Fälle zeigen, wie man die Eigen-Bibliothek nutzt, um lineare Regressionsalgorithmen zu implementieren, den Speicher effektiv zu verwalten und leistungsstarke Matrixoperationen zu nutzen.
 Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Erklärbare KI: Erklären komplexer KI/ML-Modelle
Jun 03, 2024 pm 10:08 PM
Übersetzer |. Rezensiert von Li Rui |. Chonglou Modelle für künstliche Intelligenz (KI) und maschinelles Lernen (ML) werden heutzutage immer komplexer, und die von diesen Modellen erzeugten Ergebnisse sind eine Blackbox, die den Stakeholdern nicht erklärt werden kann. Explainable AI (XAI) zielt darauf ab, dieses Problem zu lösen, indem es Stakeholdern ermöglicht, die Funktionsweise dieser Modelle zu verstehen, sicherzustellen, dass sie verstehen, wie diese Modelle tatsächlich Entscheidungen treffen, und Transparenz in KI-Systemen, Vertrauen und Verantwortlichkeit zur Lösung dieses Problems gewährleistet. In diesem Artikel werden verschiedene Techniken der erklärbaren künstlichen Intelligenz (XAI) untersucht, um ihre zugrunde liegenden Prinzipien zu veranschaulichen. Mehrere Gründe, warum erklärbare KI von entscheidender Bedeutung ist. Vertrauen und Transparenz: Damit KI-Systeme allgemein akzeptiert und vertrauenswürdig sind, müssen Benutzer verstehen, wie Entscheidungen getroffen werden
 Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Fünf Schulen des maschinellen Lernens, die Sie nicht kennen
Jun 05, 2024 pm 08:51 PM
Maschinelles Lernen ist ein wichtiger Zweig der künstlichen Intelligenz, der Computern die Möglichkeit gibt, aus Daten zu lernen und ihre Fähigkeiten zu verbessern, ohne explizit programmiert zu werden. Maschinelles Lernen hat ein breites Anwendungsspektrum in verschiedenen Bereichen, von der Bilderkennung und der Verarbeitung natürlicher Sprache bis hin zu Empfehlungssystemen und Betrugserkennung, und es verändert unsere Lebensweise. Im Bereich des maschinellen Lernens gibt es viele verschiedene Methoden und Theorien, von denen die fünf einflussreichsten Methoden als „Fünf Schulen des maschinellen Lernens“ bezeichnet werden. Die fünf Hauptschulen sind die symbolische Schule, die konnektionistische Schule, die evolutionäre Schule, die Bayes'sche Schule und die Analogieschule. 1. Der Symbolismus, auch Symbolismus genannt, betont die Verwendung von Symbolen zum logischen Denken und zum Ausdruck von Wissen. Diese Denkrichtung glaubt, dass Lernen ein Prozess der umgekehrten Schlussfolgerung durch das Vorhandene ist
