
 Technologie-Peripheriegeräte
KI
UniVision stellt eine neue Generation eines einheitlichen Frameworks vor: Die Doppelaufgaben BEV-Erkennung und Belegung erreichen das fortschrittlichste Niveau!
Technologie-Peripheriegeräte
KI
UniVision stellt eine neue Generation eines einheitlichen Frameworks vor: Die Doppelaufgaben BEV-Erkennung und Belegung erreichen das fortschrittlichste Niveau!
UniVision stellt eine neue Generation eines einheitlichen Frameworks vor: Die Doppelaufgaben BEV-Erkennung und Belegung erreichen das fortschrittlichste Niveau!

Vorab geschrieben & persönliches Verständnis
In den letzten Jahren hat sich die visionszentrierte 3D-Wahrnehmung in der autonomen Fahrtechnologie rasant weiterentwickelt. Obwohl 3D-Wahrnehmungsmodelle strukturell und konzeptionell ähnlich sind, gibt es immer noch Lücken in der Merkmalsdarstellung, den Datenformaten und Zielen, was eine Herausforderung beim Entwurf eines einheitlichen und effizienten 3D-Wahrnehmungsrahmens darstellt. Daher müssen Forscher hart daran arbeiten, diese Lücken zu schließen, um genauere und zuverlässigere autonome Fahrsysteme zu entwickeln. Durch Zusammenarbeit und Innovation hoffen wir, die Sicherheit und Leistung des autonomen Fahrens weiter zu verbessern.
Besonders bei Erkennungsaufgaben und Belegungsaufgaben im Rahmen von BEV ist es sehr schwierig, ein gemeinsames Training zu erreichen und gute Ergebnisse zu erzielen. Dies führt bei vielen Anwendungen zu großen Problemen aufgrund von Instabilität und schwer kontrollierbaren Effekten. UniVision ist jedoch ein einfaches und effizientes Framework, das die beiden Hauptaufgaben der visionszentrierten 3D-Wahrnehmung vereint, nämlich Belegungsvorhersage und Objekterkennung. Der Kern des Frameworks ist ein explizit-implizites Ansichtstransformationsmodul für die komplementäre 2D-3D-Feature-Transformation. Darüber hinaus schlägt UniVision auch ein lokales globales Merkmalsextraktions- und Fusionsmodul für eine effiziente und adaptive Voxel- und BEV-Merkmalsextraktion, -verbesserung und -interaktion vor. Durch die Übernahme dieser Methoden ist UniVision in der Lage, zufriedenstellende Ergebnisse bei Erkennungs- und Belegungsaufgaben unter BEV zu erzielen.
UniVision schlägt eine gemeinsame Strategie zur Verbesserung der Belegungserkennungsdaten und eine progressive Gewichtsanpassungsstrategie vor, um die Effizienz und Stabilität des Multitasking-Framework-Trainings zu verbessern. Umfangreiche Experimente werden an vier öffentlichen Benchmarks durchgeführt, darunter szenenfreie Lidar-Segmentierung, szenenfreie Erkennung, OpenOccupancy und Occ3D. Experimentelle Ergebnisse zeigen, dass UniVision bei jedem Benchmark Zuwächse von +1,5 mIoU, +1,8 NDS, +1,5 mIoU bzw. +1,8 mIoU erzielte und damit das SOTA-Niveau erreichte. Daher kann das UniVision-Framework als leistungsstarke Basis für einheitliche visionszentrierte 3D-Wahrnehmungsaufgaben dienen.
Der aktuelle Stand auf dem Gebiet der 3D-Wahrnehmung
3D-Wahrnehmung ist die Hauptaufgabe autonomer Fahrsysteme. Ihr Zweck besteht darin, Daten aus einer Reihe von Sensoren (wie Lidar, Radar und Kameras) zu nutzen, um sie umfassend zu verstehen der Fahrszene für die spätere Nutzungsplanung und Entscheidungsfindung. In der Vergangenheit wurde der Bereich der 3D-Wahrnehmung aufgrund der präzisen 3D-Informationen, die aus Punktwolkendaten abgeleitet wurden, von Lidar-basierten Modellen dominiert. Allerdings sind Lidar-basierte Systeme kostspielig, anfällig für Unwetter und unpraktisch in der Bereitstellung. Im Gegensatz dazu bieten visionsbasierte Systeme viele Vorteile, wie etwa niedrige Kosten, einfache Bereitstellung und gute Skalierbarkeit. Daher hat die visionszentrierte dreidimensionale Wahrnehmung bei Forschern große Aufmerksamkeit erregt.
In letzter Zeit hat die visionsbasierte 3D-Erkennung durch verbesserte Transformation der Merkmalsdarstellung, zeitliche Fusion und Überwachungssignaldesign erhebliche Fortschritte gemacht, und die Lücke zu LiDAR-basierten Modellen wird immer kleiner. Darüber hinaus haben sich in den letzten Jahren auch visionsbasierte Belegungsaufgaben rasant weiterentwickelt. Im Gegensatz zur Verwendung von 3D-Boxen zur Darstellung von Objekten kann die Belegung die geometrischen und semantischen Eigenschaften der Fahrszene umfassender beschreiben und ist nicht durch die Form und Kategorie des Objekts eingeschränkt.
Obwohl Erkennungsmethoden und Belegungsmethoden strukturelle und konzeptionelle Ähnlichkeiten aufweisen, gibt es nicht genügend Forschung zur gleichzeitigen Bewältigung dieser beiden Aufgaben und zur Erforschung ihrer Wechselbeziehungen. Belegungsmodelle und Erkennungsmodelle extrahieren häufig unterschiedliche Merkmalsdarstellungen. Die Aufgabe der Belegungsvorhersage erfordert umfassende semantische und geometrische Beurteilungen, daher wird die Voxeldarstellung häufig verwendet, um feinkörnige 3D-Informationen zu bewahren. Bei Erkennungsaufgaben ist jedoch die BEV-Darstellung vorzuziehen, da die meisten Objekte mit geringerer Überlappung auf derselben horizontalen Ebene liegen.
Im Vergleich zur BEV-Darstellung ist die Voxel-Darstellung feiner, aber weniger effizient. Darüber hinaus sind viele fortgeschrittene Operatoren hauptsächlich für 2D-Funktionen konzipiert und optimiert, was ihre Integration in die 3D-Voxeldarstellung nicht so einfach macht. Die BEV-Darstellung ist im Hinblick auf Zeiteffizienz und Speichereffizienz vorteilhafter, für eine dichte räumliche Vorhersage jedoch nicht optimal, da Strukturinformationen in der Höhendimension verloren gehen. Neben der Merkmalsdarstellung unterscheiden sich verschiedene Wahrnehmungsaufgaben auch in Datenformaten und Zielen. Daher ist es eine große Herausforderung, die Einheitlichkeit und Effizienz des Trainings von Multitasking-3D-Wahrnehmungsframeworks sicherzustellen.
UniVision-Netzwerkstruktur
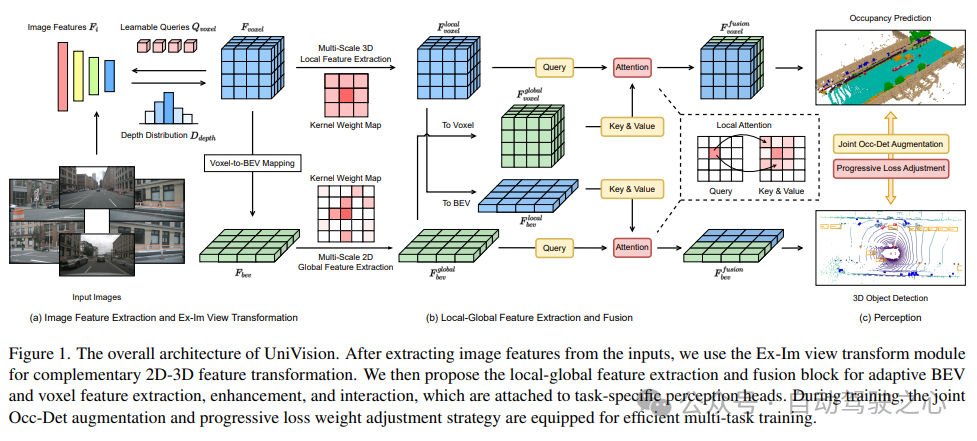
Die Gesamtarchitektur des UniVision-Frameworks ist in Abbildung 1 dargestellt. Das Framework empfängt Multi-View-Bilder von umliegenden N Kameras als Eingabe und extrahiert Bildmerkmale über ein Netzwerk zur Bildmerkmalsextraktion. Als nächstes wird das Ex-Im-Ansichtstransformationsmodul verwendet, um 2D-Bildmerkmale in 3D-Voxelmerkmale umzuwandeln. Dieses Modul kombiniert tiefengesteuertes explizites Feature-Boosting und abfragegesteuertes implizites Feature-Sampling. Nach der Ansichtstransformation werden die Voxel-Features in den lokalen globalen Feature-Extraktions- und Fusionsblock eingespeist, um lokale kontextsensitive Voxel-Features bzw. globale kontextsensitive BEV-Features zu extrahieren. Als nächstes werden Informationen über Voxel-Merkmale und BEV-Merkmale für verschiedene nachgelagerte Wahrnehmungsaufgaben über das Cross-Representation-Feature-Interaktionsmodul ausgetauscht. Während des Trainingsprozesses verwendet das UniVision-Framework kombinierte Occ-Det-Datenverbesserungs- und progressive Gewichtsanpassungsstrategien für ein effektives Training. Diese Strategien können den Trainingseffekt und die Generalisierungsfähigkeit des Frameworks verbessern. Kurz gesagt, das UniVision-Framework realisiert die Aufgabe der Erfassung der Umgebung durch die Verarbeitung von Multi-View-Bildern und 3D-Voxel-Features sowie die Anwendung von Feature-Interaktionsmodulen. Gleichzeitig wird durch die Anwendung von Datenverbesserungs- und Gewichtsverlustanpassungsstrategien der Trainingseffekt des Frameworks effektiv verbessert.
1) Ex-Im View Transform
Tiefengesteuerte explizite Funktionserweiterung. Hier wird der LSS-Ansatz verfolgt:
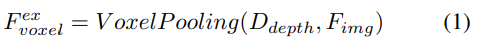
2) Abfragegesteuertes implizites Feature-Sampling. Die Darstellung von 3D-Informationen weist jedoch einige Nachteile auf. Die Genauigkeit von korreliert stark mit der Genauigkeit der geschätzten Tiefenverteilung. Darüber hinaus sind die von LSS generierten Punkte nicht gleichmäßig verteilt. In der Nähe der Kamera sind die Punkte dicht gepackt und in der Ferne spärlich verteilt. Daher verwenden wir weiterhin abfragegesteuertes Feature-Sampling, um die oben genannten Mängel zu kompensieren.
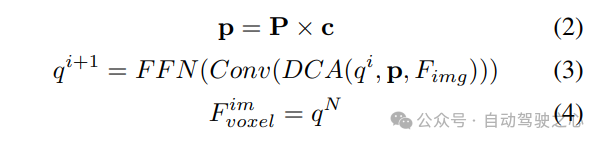
Im Vergleich zu aus LSS generierten Punkten sind Voxelabfragen gleichmäßig im 3D-Raum verteilt und werden aus den statistischen Eigenschaften aller Trainingsmuster gelernt, was unabhängig von den in LSS verwendeten Tiefenvorabinformationen ist. Verbinden Sie sie daher und ergänzen Sie sie als Ausgabefunktionen des Ansichtstransformationsmoduls: axis und verwenden Sie Faltungsschichten, um Kanäle zu reduzieren und BEV-Merkmale zu erhalten:
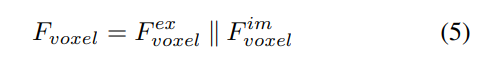
Anschließend wird das Modell zur Merkmalsextraktion und -verbesserung in zwei parallele Zweige unterteilt. Lokale Merkmalsextraktion + globale Merkmalsextraktion und die endgültige darstellungsübergreifende Merkmalsinteraktion! Wie in Abbildung 1(b) dargestellt.
3) Verlustfunktion und Erkennungskopf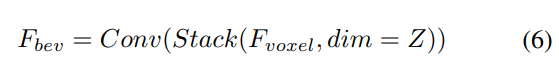
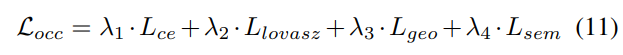
Strategie zur progressiven Gewichtsanpassung. In der Praxis zeigt sich, dass die direkte Einbeziehung der oben genannten Verluste häufig dazu führt, dass der Trainingsprozess fehlschlägt und das Netzwerk nicht konvergiert. In den frühen Phasen des Trainings sind die Voxelmerkmale Fvoxel zufällig verteilt, und die Überwachung im Belegungskopf und Erkennungskopf trägt weniger zu Konvergenzverlusten bei als andere. Gleichzeitig sind Verlustelemente wie der Klassifizierungsverlust Lcls in der Erkennungsaufgabe sehr groß und dominieren den Trainingsprozess, was die Optimierung des Modells erschwert. Um dieses Problem zu lösen, wird eine progressive Strategie zur Anpassung des Verlustgewichts vorgeschlagen, um das Verlustgewicht dynamisch anzupassen. Insbesondere wird ein Steuerparameter δ zu den Verlusten außerhalb der Bildebene (d. h. Belegungsverlust und Erkennungsverlust) hinzugefügt, um das Verlustgewicht in verschiedenen Trainingsepochen anzupassen. Das Kontrollgewicht δ wird zu Beginn auf einen kleinen Wert Vmin eingestellt und steigt über N Trainingsepochen schrittweise auf Vmax an: 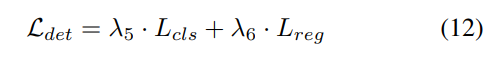
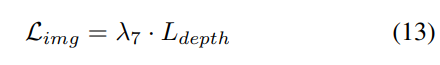
4) Kombinierte Occ-Det-Geodatenverbesserung
Bei 3D-Erkennungsaufgaben ist neben der üblichen Datenverbesserung auf Bildebene auch die Datenverbesserung auf räumlicher Ebene wirksam bei der Verbesserung der Modellleistung. Allerdings ist die Anwendung der Verbesserung der räumlichen Ebene bei Belegungsaufgaben nicht einfach. Wenn wir Datenerweiterungen (z. B. zufällige Skalierung und Rotation) auf diskrete Belegungsbezeichnungen anwenden, ist es schwierig, die resultierende Voxelsemantik zu bestimmen. Daher wenden bestehende Methoden nur einfache räumliche Erweiterungen an, wie z. B. zufälliges Umdrehen bei Belegungsaufgaben.
Um dieses Problem zu lösen, schlägt UniVision eine gemeinsame räumliche Datenerweiterung von Occ-Det vor, um eine gleichzeitige Verbesserung von 3D-Erkennungsaufgaben und Belegungsaufgaben im Framework zu ermöglichen. Da es sich bei den Beschriftungen der 3D-Box um kontinuierliche Werte handelt und die erweiterte 3D-Box für das Training direkt berechnet werden kann, wird zur Erkennung die Erweiterungsmethode in BEVDet befolgt. Obwohl Belegungsbezeichnungen diskret und schwer zu manipulieren sind, können Voxelmerkmale als kontinuierlich behandelt und durch Operationen wie Abtastung und Interpolation verarbeitet werden. Es wird daher empfohlen, Voxelmerkmale zu transformieren, anstatt zur Datenerweiterung direkt auf Belegungsbezeichnungen zu arbeiten.
Konkret wird zunächst die räumliche Datenerweiterung abgetastet und die entsprechende 3D-Transformationsmatrix berechnet. Für die Belegungsbezeichnungen und deren Voxel-Indizes berechnen wir deren dreidimensionale Koordinaten. Anschließend wird es auf die Voxel-Indizes in den erweiterten Voxel-Funktionen angewendet und normalisiert. : OpenOccupancy und Occ3D.
NuScenes LiDAR-Segmentierung: Gemäß dem aktuellen OccFormer und TPVFormer werden Kamerabilder als Eingabe für die LIDAR-Segmentierungsaufgabe verwendet und die LIDAR-Daten werden nur verwendet, um 3D-Standorte für die Abfrage der Ausgabemerkmale bereitzustellen. Verwenden Sie mIoU als Bewertungsmetrik. 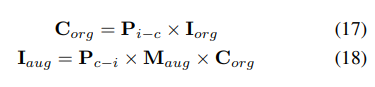
OpenOccupancy: Der OpenOccupancy-Benchmark basiert auf dem nuScenes-Datensatz und bietet semantische Belegungsbezeichnungen mit einer Auflösung von 512×512×40. Die beschrifteten Klassen sind die gleichen wie in der LIDAR-Segmentierungsaufgabe, wobei mIoU als Bewertungsmetrik verwendet wird!
Occ3D: Der Occ3D-Benchmark basiert auf dem nuScenes-Datensatz und bietet semantische Belegungsbezeichnungen mit einer Auflösung von 200×200×16. Occ3D bietet außerdem sichtbare Masken für Training und Auswertung. Die beschrifteten Klassen sind die gleichen wie in der LIDAR-Segmentierungsaufgabe, wobei mIoU als Bewertungsmetrik verwendet wird!1) Nuscenes LiDAR-Segmentierung
Tabelle 1 zeigt die Ergebnisse des nuScenes LiDAR-Segmentierungs-Benchmarks. UniVision übertrifft die hochmoderne visionsbasierte Methode OccFormer deutlich um 1,5 % mIoU und stellt einen neuen Rekord für visionsbasierte Modelle auf der Bestenliste auf. Bemerkenswert ist, dass UniVision auch einige Lidar-basierte Modelle wie PolarNe und DB-UNet übertrifft.2) NuScenes 3D-Objekterkennungsaufgabe
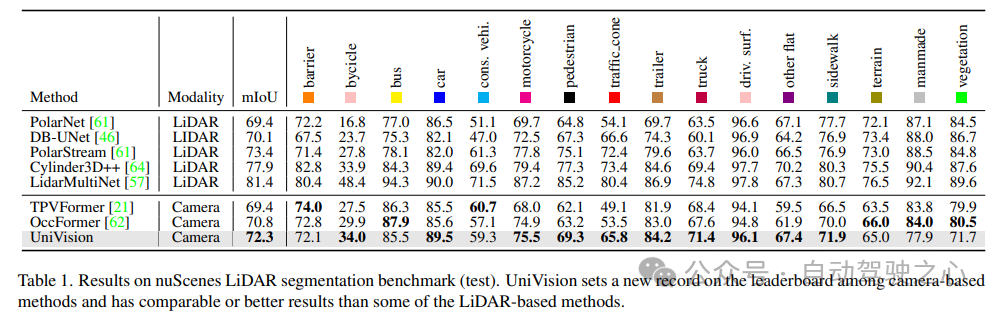
Wie in Tabelle 2 gezeigt, übertrifft UniVision andere Methoden, wenn dieselben Trainingseinstellungen für einen fairen Vergleich verwendet werden. Im Vergleich zu BEVDepth bei einer Bildauflösung von 512×1408 erzielt UniVision Zuwächse von 2,4 % bzw. 1,1 % bei mAP und NDS. Wenn das Modell vergrößert wird und UniVision mit zeitlichen Eingaben kombiniert wird, übertrifft es SOTA-basierte zeitliche Detektoren um ein Vielfaches. UniVision erreicht dies mit einer kleineren Eingabeauflösung und verwendet kein CBGS.
3) OpenOccupancy-Ergebnisvergleich
Die Ergebnisse des OpenOccupancy-Benchmarktests sind in Tabelle 3 dargestellt. UniVision übertrifft aktuelle visionsbasierte Belegungsmethoden, einschließlich MonoScene, TPVFormer und C-CONet, in Bezug auf mIoU deutlich um 7,3 %, 6,5 % bzw. 1,5 %. Darüber hinaus übertrifft UniVision einige Lidar-basierte Methoden wie LMSCNet und JS3C-Net.
4) Occ3D-Experimentalergebnisse
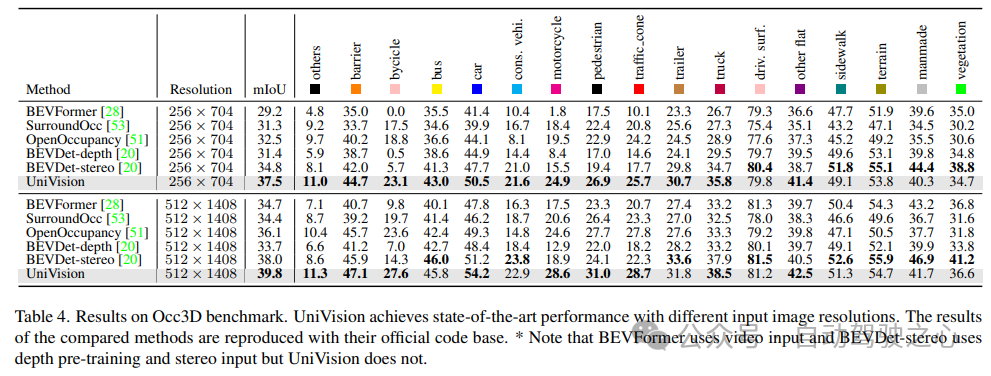
Tabelle 4 listet die Ergebnisse des Occ3D-Benchmarks auf. UniVision übertrifft aktuelle visionsbasierte Methoden in Bezug auf mIoU bei unterschiedlichen Eingabebildauflösungen deutlich um mehr als 2,7 % bzw. 1,8 %. Es ist erwähnenswert, dass BEVFormer und BEVDet-stereo vorab trainierte Gewichte laden und zeitliche Eingaben in der Inferenz verwenden, während UniVision diese nicht verwendet, aber dennoch eine bessere Leistung erzielt.
5) Wirksamkeit von Komponenten bei Erkennungsaufgaben
Die Ablationsstudie von Erkennungsaufgaben ist in Tabelle 5 dargestellt. Wenn der BEV-basierte globale Merkmalsextraktionszweig in das Basismodell eingefügt wird, verbessert sich die Leistung um 1,7 % mAP und 3,0 % NDS. Wenn die voxelbasierte Belegungsaufgabe als Hilfsaufgabe zum Detektor hinzugefügt wird, erhöht sich der mAP-Gewinn des Modells um 1,6 %. Wenn Kreuzdarstellungsinteraktionen explizit aus Voxelmerkmalen eingeführt werden, erzielt das Modell die beste Leistung und verbessert mAP und NDS um 3,5 % bzw. 4,2 % im Vergleich zur Basislinie; 6) Belegung aufgabeninterner Komponenten Die Wirksamkeit von
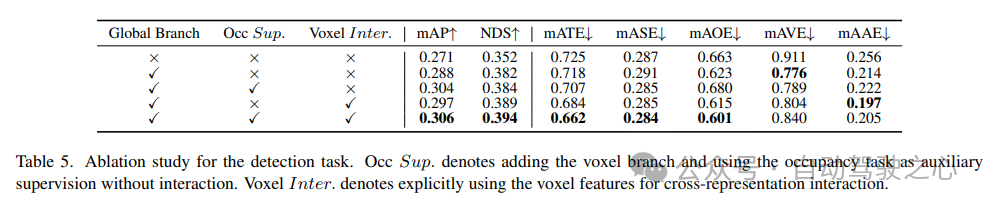 ist in Tabelle 6 für die Ablationsstudie zur Belegungsaufgabe dargestellt. Das voxelbasierte lokale Merkmalsextraktionsnetzwerk bringt eine Verbesserung von 1,96 % mIoU-Gewinn gegenüber dem Basismodell. Wenn die Erkennungsaufgabe als zusätzliches Überwachungssignal eingeführt wird, verbessert sich die Modellleistung um 0,4 % mIoU.
ist in Tabelle 6 für die Ablationsstudie zur Belegungsaufgabe dargestellt. Das voxelbasierte lokale Merkmalsextraktionsnetzwerk bringt eine Verbesserung von 1,96 % mIoU-Gewinn gegenüber dem Basismodell. Wenn die Erkennungsaufgabe als zusätzliches Überwachungssignal eingeführt wird, verbessert sich die Modellleistung um 0,4 % mIoU.
7) Sonstiges
 Tabelle 5 und Tabelle 6 zeigen, dass im UniVision-Framework Erkennungsaufgaben und Belegungsaufgaben einander ergänzen. Bei Erkennungsaufgaben kann die Belegungsüberwachung die mAP- und mATE-Metriken verbessern, was darauf hindeutet, dass Voxel-semantisches Lernen die Wahrnehmung der Objektgeometrie, d. h. Zentralität und Skalierung, durch den Detektor effektiv verbessert. Für die Belegungsaufgabe verbessert die Erkennungsüberwachung die Leistung der Vordergrundkategorie (d. h. der Erkennungskategorie) erheblich, was zu einer Gesamtverbesserung führt.
Tabelle 5 und Tabelle 6 zeigen, dass im UniVision-Framework Erkennungsaufgaben und Belegungsaufgaben einander ergänzen. Bei Erkennungsaufgaben kann die Belegungsüberwachung die mAP- und mATE-Metriken verbessern, was darauf hindeutet, dass Voxel-semantisches Lernen die Wahrnehmung der Objektgeometrie, d. h. Zentralität und Skalierung, durch den Detektor effektiv verbessert. Für die Belegungsaufgabe verbessert die Erkennungsüberwachung die Leistung der Vordergrundkategorie (d. h. der Erkennungskategorie) erheblich, was zu einer Gesamtverbesserung führt.
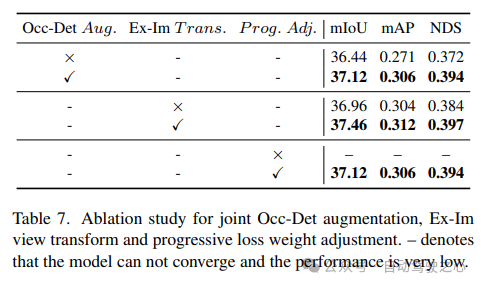
Die Wirksamkeit der kombinierten Occ-Det-Raumverbesserung, des Ex-Im-Ansichtskonvertierungsmoduls und der progressiven Gewichtsanpassungsstrategie wird in Tabelle 7 gezeigt. Mit der vorgeschlagenen räumlichen Erweiterung und dem vorgeschlagenen Ansichtstransformationsmodul zeigt es erhebliche Verbesserungen bei Erkennungsaufgaben und Belegungsaufgaben für mIoU-, mAP- und NDS-Metriken. Mit der Strategie zur Gewichtsanpassung kann das Multitasking-Framework effektiv trainiert werden. Ohne dies kann das Training des einheitlichen Frameworks nicht konvergieren und die Leistung ist sehr gering.
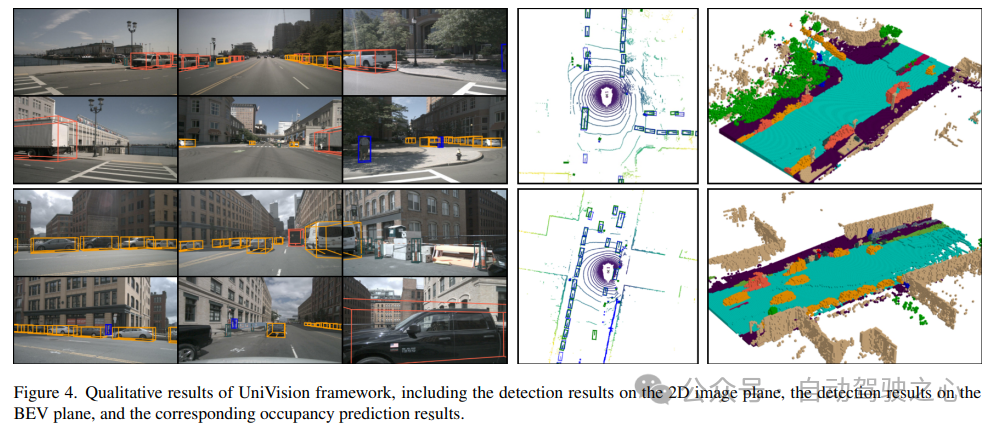
Das obige ist der detaillierte Inhalt vonUniVision stellt eine neue Generation eines einheitlichen Frameworks vor: Die Doppelaufgaben BEV-Erkennung und Belegung erreichen das fortschrittlichste Niveau!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
0.Was bewirkt dieser Artikel? Wir schlagen DepthFM vor: ein vielseitiges und schnelles generatives monokulares Tiefenschätzungsmodell auf dem neuesten Stand der Technik. Zusätzlich zu herkömmlichen Tiefenschätzungsaufgaben demonstriert DepthFM auch hochmoderne Fähigkeiten bei nachgelagerten Aufgaben wie dem Tiefen-Inpainting. DepthFM ist effizient und kann Tiefenkarten innerhalb weniger Inferenzschritte synthetisieren. Lassen Sie uns diese Arbeit gemeinsam lesen ~ 1. Titel der Papierinformationen: DepthFM: FastMonocularDepthEstimationwithFlowMatching Autor: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Das weltweit leistungsstärkste Open-Source-MoE-Modell ist da, mit chinesischen Fähigkeiten, die mit GPT-4 vergleichbar sind, und der Preis beträgt nur fast ein Prozent von GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Stellen Sie sich ein Modell der künstlichen Intelligenz vor, das nicht nur die Fähigkeit besitzt, die traditionelle Datenverarbeitung zu übertreffen, sondern auch eine effizientere Leistung zu geringeren Kosten erzielt. Dies ist keine Science-Fiction, DeepSeek-V2[1], das weltweit leistungsstärkste Open-Source-MoE-Modell, ist da. DeepSeek-V2 ist ein leistungsstarkes MoE-Sprachmodell (Mix of Experts) mit den Merkmalen eines wirtschaftlichen Trainings und einer effizienten Inferenz. Es besteht aus 236B Parametern, von denen 21B zur Aktivierung jedes Markers verwendet werden. Im Vergleich zu DeepSeek67B bietet DeepSeek-V2 eine stärkere Leistung, spart gleichzeitig 42,5 % der Trainingskosten, reduziert den KV-Cache um 93,3 % und erhöht den maximalen Generierungsdurchsatz auf das 5,76-fache. DeepSeek ist ein Unternehmen, das sich mit allgemeiner künstlicher Intelligenz beschäftigt
 KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI untergräbt die mathematische Forschung! Der Gewinner der Fields-Medaille und der chinesisch-amerikanische Mathematiker führten 11 hochrangige Arbeiten an | Gefällt mir bei Terence Tao
Apr 09, 2024 am 11:52 AM
KI verändert tatsächlich die Mathematik. Vor kurzem hat Tao Zhexuan, der diesem Thema große Aufmerksamkeit gewidmet hat, die neueste Ausgabe des „Bulletin of the American Mathematical Society“ (Bulletin der American Mathematical Society) weitergeleitet. Zum Thema „Werden Maschinen die Mathematik verändern?“ äußerten viele Mathematiker ihre Meinung. Der gesamte Prozess war voller Funken, knallhart und aufregend. Der Autor verfügt über eine starke Besetzung, darunter der Fields-Medaillengewinner Akshay Venkatesh, der chinesische Mathematiker Zheng Lejun, der NYU-Informatiker Ernest Davis und viele andere bekannte Wissenschaftler der Branche. Die Welt der KI hat sich dramatisch verändert. Viele dieser Artikel wurden vor einem Jahr eingereicht.
 KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
KAN, das MLP ersetzt, wurde durch Open-Source-Projekte auf Faltung erweitert
Jun 01, 2024 pm 10:03 PM
Anfang dieses Monats schlugen Forscher des MIT und anderer Institutionen eine vielversprechende Alternative zu MLP vor – KAN. KAN übertrifft MLP in Bezug auf Genauigkeit und Interpretierbarkeit. Und es kann MLP, das mit einer größeren Anzahl von Parametern ausgeführt wird, mit einer sehr kleinen Anzahl von Parametern übertreffen. Beispielsweise gaben die Autoren an, dass sie KAN nutzten, um die Ergebnisse von DeepMind mit einem kleineren Netzwerk und einem höheren Automatisierungsgrad zu reproduzieren. Konkret verfügt DeepMinds MLP über etwa 300.000 Parameter, während KAN nur etwa 200 Parameter hat. KAN hat eine starke mathematische Grundlage wie MLP und basiert auf dem universellen Approximationssatz, während KAN auf dem Kolmogorov-Arnold-Darstellungssatz basiert. Wie in der folgenden Abbildung gezeigt, hat KAN
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Stehen Sie vor einer Verzögerung oder einer langsamen mobilen Datenverbindung auf dem iPhone? Normalerweise hängt die Stärke des Mobilfunk-Internets auf Ihrem Telefon von mehreren Faktoren ab, wie z. B. der Region, dem Mobilfunknetztyp, dem Roaming-Typ usw. Es gibt einige Dinge, die Sie tun können, um eine schnellere und zuverlässigere Mobilfunk-Internetverbindung zu erhalten. Fix 1 – Neustart des iPhone erzwingen Manchmal werden durch einen erzwungenen Neustart Ihres Geräts viele Dinge zurückgesetzt, einschließlich der Mobilfunkverbindung. Schritt 1 – Drücken Sie einfach einmal die Lauter-Taste und lassen Sie sie los. Drücken Sie anschließend die Leiser-Taste und lassen Sie sie wieder los. Schritt 2 – Der nächste Teil des Prozesses besteht darin, die Taste auf der rechten Seite gedrückt zu halten. Lassen Sie das iPhone den Neustart abschließen. Aktivieren Sie Mobilfunkdaten und überprüfen Sie die Netzwerkgeschwindigkeit. Überprüfen Sie es erneut. Fix 2 – Datenmodus ändern 5G bietet zwar bessere Netzwerkgeschwindigkeiten, funktioniert jedoch besser, wenn das Signal schwächer ist
 Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Ich weine zu Tode. Die Daten im Internet reichen überhaupt nicht aus. Das Trainingsmodell sieht aus wie „Die Tribute von Panem“, und KI-Forscher auf der ganzen Welt machen sich Gedanken darüber, wie sie diese datenhungrigen Esser ernähren sollen. Dieses Problem tritt insbesondere bei multimodalen Aufgaben auf. Zu einer Zeit, als sie ratlos waren, nutzte ein Start-up-Team der Abteilung der Renmin-Universität von China sein eigenes neues Modell, um als erstes in China einen „modellgenerierten Datenfeed selbst“ in die Realität umzusetzen. Darüber hinaus handelt es sich um einen zweigleisigen Ansatz auf der Verständnisseite und der Generierungsseite. Beide Seiten können hochwertige, multimodale neue Daten generieren und Datenrückmeldungen an das Modell selbst liefern. Was ist ein Modell? Awaker 1.0, ein großes multimodales Modell, das gerade im Zhongguancun-Forum erschienen ist. Wer ist das Team? Sophon-Motor. Gegründet von Gao Yizhao, einem Doktoranden an der Hillhouse School of Artificial Intelligence der Renmin University.
 Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Kürzlich wurde die Militärwelt von der Nachricht überwältigt: US-Militärkampfflugzeuge können jetzt mithilfe von KI vollautomatische Luftkämpfe absolvieren. Ja, erst kürzlich wurde der KI-Kampfjet des US-Militärs zum ersten Mal der Öffentlichkeit zugänglich gemacht und sein Geheimnis gelüftet. Der vollständige Name dieses Jägers lautet „Variable Stability Simulator Test Aircraft“ (VISTA). Er wurde vom Minister der US-Luftwaffe persönlich geflogen, um einen Eins-gegen-eins-Luftkampf zu simulieren. Am 2. Mai startete US-Luftwaffenminister Frank Kendall mit einer X-62AVISTA auf der Edwards Air Force Base. Beachten Sie, dass während des einstündigen Fluges alle Flugaktionen autonom von der KI durchgeführt wurden! Kendall sagte: „In den letzten Jahrzehnten haben wir über das unbegrenzte Potenzial des autonomen Luft-Luft-Kampfes nachgedacht, aber es schien immer unerreichbar.“ Nun jedoch,
