

LLM-Großsprachenmodell und Generierung von Abrufverbesserungen


LLM-Modelle großer Sprachen werden normalerweise mithilfe der Transformer-Architektur trainiert, um die Fähigkeit zu verbessern, natürliche Sprache anhand großer Textdatenmengen zu verstehen und zu generieren. Diese Modelle werden häufig in Chatbots, Textzusammenfassungen, maschineller Übersetzung und anderen Bereichen verwendet. Zu den bekannten LLM-Modellen für große Sprachen gehören die GPT-Serie von OpenAI und BERT von Google.
Im Bereich der Verarbeitung natürlicher Sprache ist die abrufgestützte Generierung eine Technologie, die Abruf und Generierung kombiniert. Es generiert anforderungsgerechten Text, indem es relevante Informationen aus großen Textkorpora abruft und generative Modelle verwendet, um diese Informationen neu zu kombinieren und anzuordnen. Diese Technik hat ein breites Anwendungsspektrum, darunter Textzusammenfassung, maschinelle Übersetzung, Dialoggenerierung und andere Aufgaben. Durch die Nutzung der Vorteile von Retrieval und Generierung kann die durch Retrieval verbesserte Generierung die Qualität und Genauigkeit der Textgenerierung verbessern und spielt somit eine wichtige Rolle im Bereich der Verarbeitung natürlicher Sprache.
Im großen LLM-Sprachmodell wird die Generierung der Abrufverbesserung als wichtiges technisches Mittel zur Verbesserung der Modellleistung angesehen. Durch die Integration von Abruf und Generierung kann LLM relevante Informationen effektiver aus umfangreichen Texten gewinnen und qualitativ hochwertige Texte in natürlicher Sprache generieren. Diese technischen Mittel können den Generierungseffekt und die Genauigkeit des Modells erheblich verbessern und die Anforderungen verschiedener Anwendungen zur Verarbeitung natürlicher Sprache besser erfüllen. Durch die Kombination von Abruf und Generierung sind LLM-Modelle für große Sprachen in der Lage, einige Einschränkungen traditioneller generativer Modelle zu überwinden, wie z. B. die Konsistenz und Relevanz generierter Inhalte. Daher hat die durch Retrieval erweiterte Generierung ein großes Potenzial zur Verbesserung der Modellleistung und wird voraussichtlich eine wichtige Rolle in der zukünftigen Forschung zur Verarbeitung natürlicher Sprache spielen.
Schritte zur Verwendung der Retrieval-Enhancement-Generierungstechnologie zum Anpassen eines großen LLM-Sprachmodells für einen bestimmten Anwendungsfall
Um mithilfe der Retrieval-Enhancement-Generierung ein großes LLM-Sprachmodell für einen bestimmten Anwendungsfall anzupassen, können Sie die folgenden Schritte ausführen:
1. Daten vorbereiten
Zunächst einmal ist die Vorbereitung einer großen Menge an Textdaten ein wichtiger Schritt beim Aufbau eines LLM-Modells für große Sprachen. Zu diesen Daten gehören Trainingsdaten und Abrufdaten. Trainingsdaten werden verwendet, um das Modell zu trainieren, während Abrufdaten verwendet werden, um relevante Informationen daraus abzurufen. Um den Anforderungen eines bestimmten Anwendungsfalls gerecht zu werden, können bei Bedarf relevante Textdaten ausgewählt werden. Diese Daten können aus dem Internet abgerufen werden, beispielsweise relevante Artikel, Nachrichten, Forenbeiträge usw. Die Wahl der richtigen Datenquelle ist entscheidend für das Training eines qualitativ hochwertigen Modells. Um die Qualität der Trainingsdaten sicherzustellen, müssen die Daten vorverarbeitet und bereinigt werden. Dazu gehören das Entfernen von Rauschen, das Normalisieren von Textformaten, der Umgang mit fehlenden Werten usw. Die bereinigten Daten können besser zum Trainieren des Modells und zur Verbesserung der Genauigkeit und Leistung des Modells verwendet werden. Darüber hinaus
2. Trainieren Sie das LLM-Großsprachenmodell.
Verwenden Sie das vorhandene LLM-Großsprachenmodell-Framework, wie z. B. die GPT-Reihe von OpenAI oder Googles BERT, um anhand der vorbereiteten Trainingsdaten zu trainieren. Während des Trainingsprozesses kann eine Feinabstimmung vorgenommen werden, um die Leistung des Modells für bestimmte Anwendungsfälle zu verbessern.
3. Erstellen Sie ein Retrieval-System
Um eine Retrieval-Verbesserung zu erreichen, ist es notwendig, ein Retrieval-System zum Abrufen relevanter Informationen aus umfangreichen Textkorpora aufzubauen. Es können bestehende Suchmaschinentechnologien genutzt werden, etwa die schlüsselwortbasierte oder inhaltsbasierte Suche. Darüber hinaus können auch fortschrittlichere Deep-Learning-Technologien wie Transformer-basierte Retrieval-Modelle zur Verbesserung der Retrieval-Ergebnisse eingesetzt werden. Diese Technologien können die Abfrageabsicht des Benutzers besser verstehen, indem sie semantische und kontextbezogene Informationen analysieren und relevante Ergebnisse genau zurückgeben. Durch kontinuierliche Optimierung und Iteration kann das Abrufsystem Informationen zu Benutzeranforderungen in großen Textkorpora effizient abrufen.
4. Kombinieren Sie das Retrieval-System und das große LLM-Sprachmodell.
Kombinieren Sie das Retrieval-System und das große LLM-Sprachmodell, um eine verbesserte Retrieval-Generierung zu erreichen. Zunächst wird ein Retrieval-System verwendet, um relevante Informationen aus einem umfangreichen Textkorpus abzurufen. Anschließend wird das LLM-Großsprachenmodell verwendet, um diese Informationen neu anzuordnen und zu kombinieren, um Text zu generieren, der den Anforderungen entspricht. Auf diese Weise können die Genauigkeit und Vielfalt des generierten Textes verbessert werden, um den Bedürfnissen der Benutzer besser gerecht zu werden.
5. Optimierung und Bewertung
Um den Anforderungen spezifischer Anwendungsfälle gerecht zu werden, können wir maßgeschneiderte große LLM-Sprachmodelle optimieren und bewerten. Um die Leistung des Modells zu bewerten, können Sie Bewertungsindikatoren wie Genauigkeit, Rückruf und F1-Score verwenden. Darüber hinaus können wir auch Daten aus realen Anwendungsszenarien nutzen, um die Praxistauglichkeit des Modells zu testen.
Beispiel 1: Großes LLM-Sprachmodell für Filmrezensionen
Angenommen, wir möchten ein großes LLM-Sprachmodell für Filmrezensionen anpassen, den Benutzer einen Filmnamen eingeben lassen und dann kann das Modell Kommentare zum Film generieren.
Zuerst müssen wir Trainingsdaten vorbereiten und Daten abrufen. Relevante Filmkritikartikel, Nachrichten, Forumbeiträge usw. können als Trainingsdaten und Abrufdaten aus dem Internet abgerufen werden.
Dann können wir das GPT-Serien-Framework von OpenAI verwenden, um das große LLM-Sprachmodell zu trainieren. Während des Trainingsprozesses kann das Modell für die Aufgabe der Filmrezension feinabgestimmt werden, z. B. durch Anpassung des Vokabulars, des Korpus usw.
Als nächstes können wir ein schlüsselwortbasiertes Retrievalsystem zum Abrufen relevanter Informationen aus umfangreichen Textkorpora erstellen. In diesem Beispiel können wir den Filmtitel als Schlüsselwort verwenden, um relevante Rezensionen aus den Trainingsdaten und Abrufdaten abzurufen.
Schließlich kombinieren wir das Retrieval-System mit dem LLM-Großsprachenmodell, um eine verbesserte Retrieval-Generierung zu erreichen. Konkret können Sie zunächst ein Abrufsystem verwenden, um Kommentare zu Filmtiteln aus einem umfangreichen Textkorpus abzurufen, und dann das LLM-Großsprachenmodell verwenden, um diese Kommentare neu anzuordnen und zu kombinieren, um Text zu generieren, der den Anforderungen entspricht.
Das Folgende ist ein Beispielcode zum Implementieren des oben genannten Prozesses mit Python und der GPT-Bibliothek:
<code>import torch from transformers import GPT2Tokenizer, GPT2LMHeadModel # 准备训练数据和检索数据 train_data = [... # 训练数据] retrieval_data = [... # 检索数据] # 训练LLM大语言模型 tokenizer = GPT2Tokenizer.from_pretrained('gpt2-large') model = GPT2LMHeadModel.from_pretrained('gpt2-large') model.train() input_ids = tokenizer.encode("电影名称", return_tensors='pt') output = model(input_ids) output_ids = torch.argmax(output.logits, dim=-1) generated_text = tokenizer.decode(output_ids, skip_special_tokens=True) # 使用检索系统获取相关评论 retrieved_comments = [... # 从大规模文本语料库中检索与电影名称相关的评论] # 结合检索系统和LLM大语言模型生成评论 generated_comment = "".join(retrieved_comments) + " " + generated_text</code>Beispiel 2: Helfen Sie Benutzern, Fragen zur Programmierung zu beantworten
Zunächst benötigen wir ein einfaches Abrufsystem, beispielsweise die Verwendung von Elasticsearch. Anschließend können wir mit Python Code schreiben, um das LLM-Modell mit Elasticsearch zu verbinden und es zu optimieren. Hier ist ein einfacher Beispielcode:
<code># 导入所需的库import torchfrom transformers import GPT2LMHeadModel, GPT2Tokenizerfrom elasticsearch import Elasticsearch# 初始化Elasticsearch客户端es = Elasticsearch()# 加载GPT-2模型和tokenizertokenizer = GPT2Tokenizer.from_pretrained("gpt2")model = GPT2LMHeadModel.from_pretrained("gpt2")# 定义一个函数,用于通过Elasticsearch检索相关信息def retrieve_information(query): # 在Elasticsearch上执行查询 # 这里假设我们有一个名为"knowledge_base"的索引 res = es.search(index="knowledge_base", body={"query": {"match": {"text": query}}}) # 返回查询结果 return [hit['_source']['text'] for hit in res['hits']['hits']]# 定义一个函数,用于生成文本,并利用检索到的信息def generate_text_with_retrieval(prompt): # 从Elasticsearch检索相关信息 retrieved_info = retrieve_information(prompt) # 将检索到的信息整合到输入中 prompt += " ".join(retrieved_info) # 将输入编码成tokens input_ids = tokenizer.encode(prompt, return_tensors="pt") # 生成文本 output = model.generate(input_ids, max_length=100, num_return_sequences=1, no_repeat_ngram_size=2) # 解码生成的文本 generated_text = tokenizer.decode(output[0], skip_special_tokens=True) return generated_text# 用例:生成回答编程问题的文本user_query = "What is a function in Python?"generated_response = generate_text_with_retrietrieved_response = generate_text_with_retrieval(user_query)# 打印生成的回答print(generated_response)</code>Dieses Python-Codebeispiel zeigt, wie man ein GPT-2-Modell in Verbindung mit Elasticsearch verwendet, um eine abrufverbesserte Generierung zu erreichen. In diesem Beispiel gehen wir davon aus, dass es einen Index namens „knowledge_base“ gibt, der programmbezogene Informationen speichert. In der Funktion „retrie_information“ führen wir eine einfache Elasticsearch-Abfrage aus und integrieren dann in der Funktion „generate_text_with_retrieval“ die abgerufenen Informationen und generieren die Antwort mithilfe des GPT-2-Modells.
Wenn ein Benutzer eine Frage zu einer Python-Funktion stellt, ruft der Code relevante Informationen von Elasticsearch ab, integriert sie in die Benutzerabfrage und verwendet dann das GPT-2-Modell, um eine Antwort zu generieren.
Das obige ist der detaillierte Inhalt vonLLM-Großsprachenmodell und Generierung von Abrufverbesserungen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Entdecken Sie die Konzepte, Unterschiede, Vor- und Nachteile von RNN, LSTM und GRU
Jan 22, 2024 pm 07:51 PM
Entdecken Sie die Konzepte, Unterschiede, Vor- und Nachteile von RNN, LSTM und GRU
Jan 22, 2024 pm 07:51 PM
In Zeitreihendaten gibt es Abhängigkeiten zwischen Beobachtungen, sie sind also nicht unabhängig voneinander. Herkömmliche neuronale Netze behandeln jedoch jede Beobachtung als unabhängig, was die Fähigkeit des Modells zur Modellierung von Zeitreihendaten einschränkt. Um dieses Problem zu lösen, wurde das Recurrent Neural Network (RNN) eingeführt, das das Konzept des Speichers einführte, um die dynamischen Eigenschaften von Zeitreihendaten zu erfassen, indem Abhängigkeiten zwischen Datenpunkten im Netzwerk hergestellt werden. Durch wiederkehrende Verbindungen kann RNN frühere Informationen an die aktuelle Beobachtung weitergeben, um zukünftige Werte besser vorherzusagen. Dies macht RNN zu einem leistungsstarken Werkzeug für Aufgaben mit Zeitreihendaten. Aber wie erreicht RNN diese Art von Gedächtnis? RNN realisiert das Gedächtnis durch die Rückkopplungsschleife im neuronalen Netzwerk. Dies ist der Unterschied zwischen RNN und herkömmlichen neuronalen Netzwerken.
 Berechnung von Gleitkommaoperanden (FLOPS) für neuronale Netze
Jan 22, 2024 pm 07:21 PM
Berechnung von Gleitkommaoperanden (FLOPS) für neuronale Netze
Jan 22, 2024 pm 07:21 PM
FLOPS ist einer der Standards zur Bewertung der Computerleistung und dient zur Messung der Anzahl der Gleitkommaoperationen pro Sekunde. In neuronalen Netzen wird FLOPS häufig verwendet, um die Rechenkomplexität des Modells und die Nutzung von Rechenressourcen zu bewerten. Es ist ein wichtiger Indikator zur Messung der Rechenleistung und Effizienz eines Computers. Ein neuronales Netzwerk ist ein komplexes Modell, das aus mehreren Neuronenschichten besteht und für Aufgaben wie Datenklassifizierung, Regression und Clustering verwendet wird. Das Training und die Inferenz neuronaler Netze erfordert eine große Anzahl von Matrixmultiplikationen, Faltungen und anderen Rechenoperationen, sodass die Rechenkomplexität sehr hoch ist. Mit FLOPS (FloatingPointOperationsperSecond) kann die Rechenkomplexität neuronaler Netze gemessen werden, um die Effizienz der Rechenressourcennutzung des Modells zu bewerten. FLOP
 Definition und Strukturanalyse eines Fuzzy-Neuronalen Netzwerks
Jan 22, 2024 pm 09:09 PM
Definition und Strukturanalyse eines Fuzzy-Neuronalen Netzwerks
Jan 22, 2024 pm 09:09 PM
Das Fuzzy-Neuronale Netzwerk ist ein Hybridmodell, das Fuzzy-Logik und neuronale Netzwerke kombiniert, um unscharfe oder unsichere Probleme zu lösen, die mit herkömmlichen neuronalen Netzwerken nur schwer zu bewältigen sind. Sein Design ist von der Unschärfe und Unsicherheit der menschlichen Wahrnehmung inspiriert und wird daher häufig in Steuerungssystemen, Mustererkennung, Data Mining und anderen Bereichen eingesetzt. Die Grundarchitektur eines Fuzzy-Neuronalen Netzwerks besteht aus einem Fuzzy-Subsystem und einem Neuronalen Subsystem. Das Fuzzy-Subsystem verwendet Fuzzy-Logik, um Eingabedaten zu verarbeiten und in Fuzzy-Sätze umzuwandeln, um die Unschärfe und Unsicherheit der Eingabedaten auszudrücken. Das neuronale Subsystem nutzt neuronale Netze zur Verarbeitung von Fuzzy-Sets für Aufgaben wie Klassifizierung, Regression oder Clustering. Durch die Interaktion zwischen dem Fuzzy-Subsystem und dem neuronalen Subsystem verfügt das Fuzzy-Neuronale Netzwerk über leistungsfähigere Verarbeitungsfähigkeiten und kann
 Eine Fallstudie zur Verwendung des bidirektionalen LSTM-Modells zur Textklassifizierung
Jan 24, 2024 am 10:36 AM
Eine Fallstudie zur Verwendung des bidirektionalen LSTM-Modells zur Textklassifizierung
Jan 24, 2024 am 10:36 AM
Das bidirektionale LSTM-Modell ist ein neuronales Netzwerk, das zur Textklassifizierung verwendet wird. Unten finden Sie ein einfaches Beispiel, das zeigt, wie bidirektionales LSTM für Textklassifizierungsaufgaben verwendet wird. Zuerst müssen wir die erforderlichen Bibliotheken und Module importieren: importosimportnumpyasnpfromkeras.preprocessing.textimportTokenizerfromkeras.preprocessing.sequenceimportpad_sequencesfromkeras.modelsimportSequentialfromkeras.layersimportDense,Em
 Bildrauschen mithilfe von Faltungs-Neuronalen Netzen
Jan 23, 2024 pm 11:48 PM
Bildrauschen mithilfe von Faltungs-Neuronalen Netzen
Jan 23, 2024 pm 11:48 PM
Faltungs-Neuronale Netze eignen sich gut für Aufgaben zur Bildrauschunterdrückung. Es nutzt die erlernten Filter, um das Rauschen zu filtern und so das Originalbild wiederherzustellen. In diesem Artikel wird die Methode zur Bildentrauschung basierend auf einem Faltungs-Neuronalen Netzwerk ausführlich vorgestellt. 1. Überblick über das Convolutional Neural Network Das Convolutional Neural Network ist ein Deep-Learning-Algorithmus, der eine Kombination aus mehreren Faltungsschichten, Pooling-Schichten und vollständig verbundenen Schichten verwendet, um Bildmerkmale zu lernen und zu klassifizieren. In der Faltungsschicht werden die lokalen Merkmale des Bildes durch Faltungsoperationen extrahiert und so die räumliche Korrelation im Bild erfasst. Die Pooling-Schicht reduziert den Rechenaufwand durch Reduzierung der Feature-Dimension und behält die Hauptfeatures bei. Die vollständig verbundene Schicht ist für die Zuordnung erlernter Merkmale und Beschriftungen zur Implementierung der Bildklassifizierung oder anderer Aufgaben verantwortlich. Das Design dieser Netzwerkstruktur macht das Faltungs-Neuronale Netzwerk für die Bildverarbeitung und -erkennung nützlich.
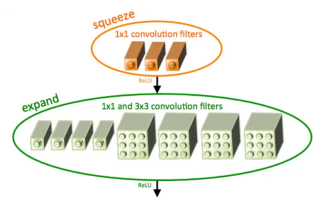 Einführung in SqueezeNet und seine Eigenschaften
Jan 22, 2024 pm 07:15 PM
Einführung in SqueezeNet und seine Eigenschaften
Jan 22, 2024 pm 07:15 PM
SqueezeNet ist ein kleiner und präziser Algorithmus, der eine gute Balance zwischen hoher Genauigkeit und geringer Komplexität schafft und sich daher ideal für mobile und eingebettete Systeme mit begrenzten Ressourcen eignet. Im Jahr 2016 schlugen Forscher von DeepScale, der University of California, Berkeley und der Stanford University SqueezeNet vor, ein kompaktes und effizientes Faltungs-Neuronales Netzwerk (CNN). In den letzten Jahren haben Forscher mehrere Verbesserungen an SqueezeNet vorgenommen, darunter SqueezeNetv1.1 und SqueezeNetv2.0. Verbesserungen in beiden Versionen erhöhen nicht nur die Genauigkeit, sondern senken auch die Rechenkosten. Genauigkeit von SqueezeNetv1.1 im ImageNet-Datensatz
 Twin Neural Network: Prinzip- und Anwendungsanalyse
Jan 24, 2024 pm 04:18 PM
Twin Neural Network: Prinzip- und Anwendungsanalyse
Jan 24, 2024 pm 04:18 PM
Das Siamese Neural Network ist eine einzigartige künstliche neuronale Netzwerkstruktur. Es besteht aus zwei identischen neuronalen Netzen mit denselben Parametern und Gewichten. Gleichzeitig teilen die beiden Netzwerke auch die gleichen Eingabedaten. Dieses Design wurde von Zwillingen inspiriert, da die beiden neuronalen Netze strukturell identisch sind. Das Prinzip des siamesischen neuronalen Netzwerks besteht darin, bestimmte Aufgaben wie Bildabgleich, Textabgleich und Gesichtserkennung durch den Vergleich der Ähnlichkeit oder des Abstands zwischen zwei Eingabedaten auszuführen. Während des Trainings versucht das Netzwerk, ähnliche Daten benachbarten Regionen und unterschiedliche Daten entfernten Regionen zuzuordnen. Auf diese Weise kann das Netzwerk lernen, verschiedene Daten zu klassifizieren oder abzugleichen, um entsprechende Ergebnisse zu erzielen
 Schritte zum Schreiben eines einfachen neuronalen Netzwerks mit Rust
Jan 23, 2024 am 10:45 AM
Schritte zum Schreiben eines einfachen neuronalen Netzwerks mit Rust
Jan 23, 2024 am 10:45 AM
Rust ist eine Programmiersprache auf Systemebene, die sich auf Sicherheit, Leistung und Parallelität konzentriert. Ziel ist es, eine sichere und zuverlässige Programmiersprache bereitzustellen, die für Szenarien wie Betriebssysteme, Netzwerkanwendungen und eingebettete Systeme geeignet ist. Die Sicherheit von Rust beruht hauptsächlich auf zwei Aspekten: dem Eigentumssystem und dem Kreditprüfer. Das Besitzsystem ermöglicht es dem Compiler, den Code zur Kompilierungszeit auf Speicherfehler zu überprüfen und so häufige Speichersicherheitsprobleme zu vermeiden. Indem Rust die Überprüfung der Eigentumsübertragungen von Variablen zur Kompilierungszeit erzwingt, stellt Rust sicher, dass Speicherressourcen ordnungsgemäß verwaltet und freigegeben werden. Der Borrow-Checker analysiert den Lebenszyklus der Variablen, um sicherzustellen, dass nicht mehrere Threads gleichzeitig auf dieselbe Variable zugreifen, wodurch häufige Sicherheitsprobleme bei der Parallelität vermieden werden. Durch die Kombination dieser beiden Mechanismen ist Rust in der Lage, Folgendes bereitzustellen
