
 Technologie-Peripheriegeräte
KI
Googles neue Methode ASPIRE: Bietet LLM-Selbstbewertungsfunktionen, löst effektiv das „Illusions'-Problem und übertrifft das Volumenmodell um das Zehnfache
Technologie-Peripheriegeräte
KI
Googles neue Methode ASPIRE: Bietet LLM-Selbstbewertungsfunktionen, löst effektiv das „Illusions'-Problem und übertrifft das Volumenmodell um das Zehnfache
Googles neue Methode ASPIRE: Bietet LLM-Selbstbewertungsfunktionen, löst effektiv das „Illusions'-Problem und übertrifft das Volumenmodell um das Zehnfache

Das „Illusions“-Problem großer Modelle ist bald gelöst?
Forscher der University of Wisconsin-Madison und Google haben kürzlich das ASPIRE-System eingeführt, das es großen Modellen ermöglicht, ihre Ergebnisse selbst zu bewerten.
Wenn der Benutzer sieht, dass das vom Modell generierte Ergebnis eine niedrige Punktzahl aufweist, wird ihm klar, dass die Antwort möglicherweise eine Illusion ist.
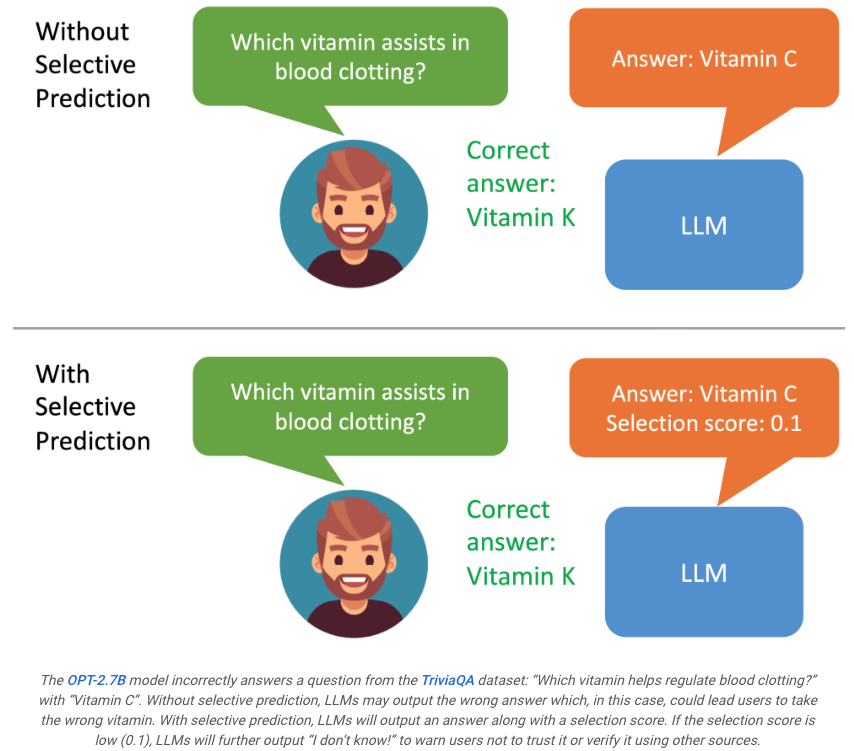
Wenn das System den Ausgabeinhalt basierend auf den Bewertungsergebnissen weiter filtern kann, beispielsweise wenn die Bewertung niedrig ist, kann ein großes Modell Aussagen wie „Ich kann diese Frage nicht beantworten“ generieren, was möglicherweise der Fall ist Maximieren Sie die Verbesserung des Halluzinationsproblems.

Papieradresse: https://aclanthology.org/2023.findings-emnlp.345.pdf
ASPIRE ermöglicht LLM, die Antwort und den Konfidenzwert der Antwort auszugeben.
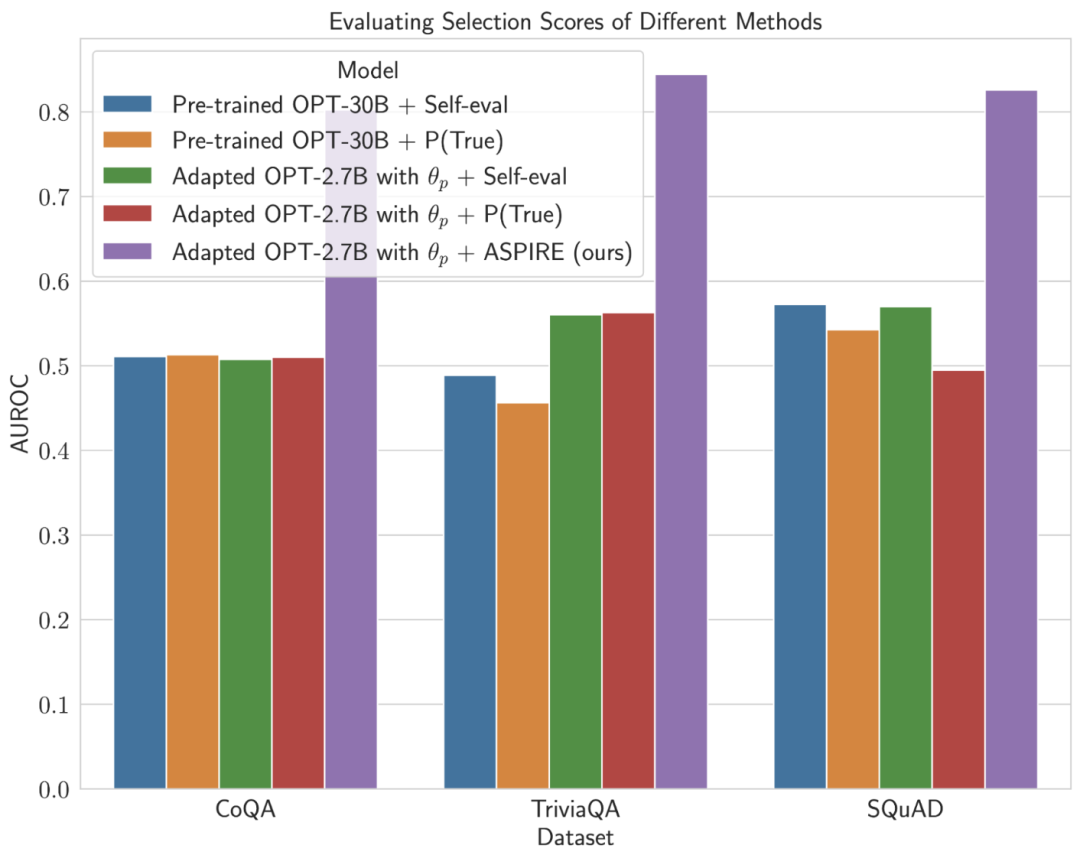
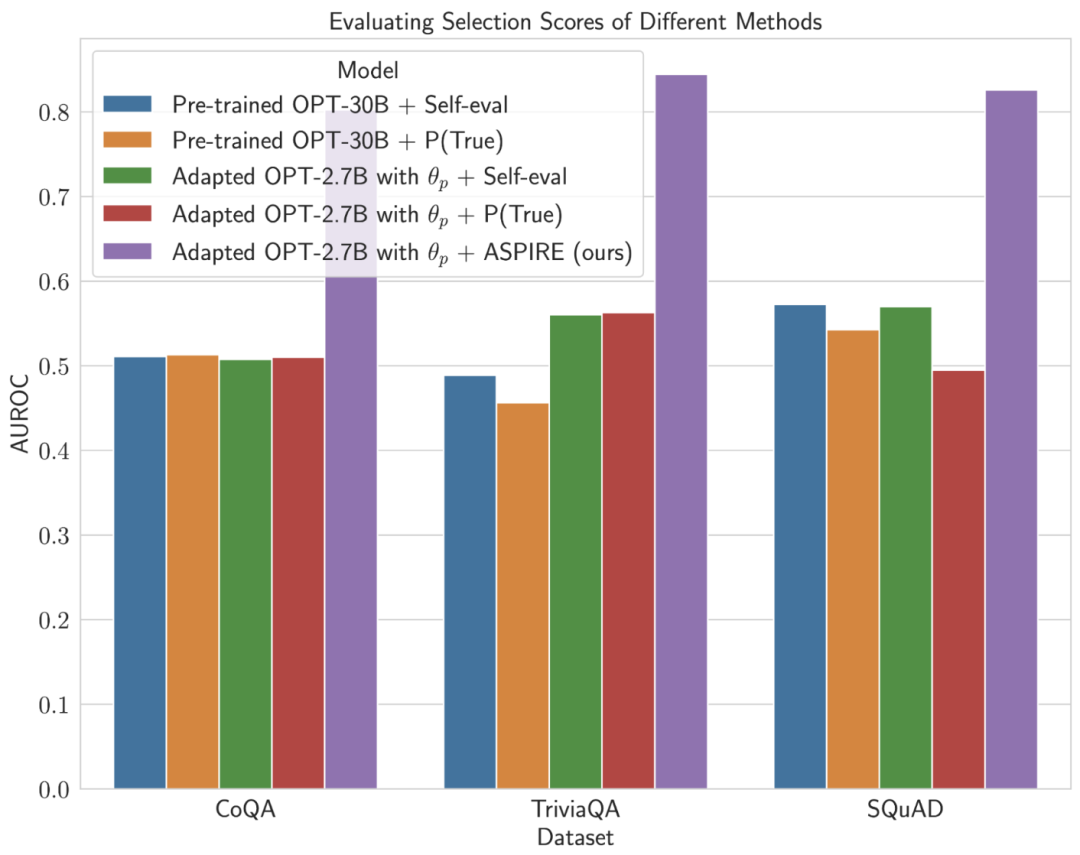
Die experimentellen Ergebnisse der Forscher zeigen, dass ASPIRE herkömmliche selektive Vorhersagemethoden für verschiedene QA-Datensätze (wie den CoQA-Benchmark) deutlich übertrifft.
Lassen Sie LLM nicht nur Fragen beantworten, sondern diese Antworten auch auswerten.
Im Benchmark-Test der selektiven Vorhersage erzielten Forscher mit dem ASPIRE-System Ergebnisse von mehr als dem Zehnfachen des Maßstabs des Modells.
Es ist, als würde man die Schüler bitten, ihre eigenen Antworten am Ende des Lehrbuchs zu überprüfen. Auch wenn es etwas unzuverlässig klingt, wird man bei sorgfältiger Überlegung nach der Beantwortung einer Frage tatsächlich mit der Antwort zufrieden sein. Es wird eine Wertung geben.
Das ist die Essenz von ASPIRE, die drei Phasen umfasst:
(1) Abstimmung auf eine bestimmte Aufgabe,
(2) Antwortproben,
( 3 ) Selbsteinschätzung des Lernens.
In den Augen der Forscher ist ASPIRE nicht nur ein weiteres Framework, es stellt eine vielversprechende Zukunft dar, die die LLM-Zuverlässigkeit umfassend verbessert und Halluzinationen reduziert.
Wenn LLM ein vertrauenswürdiger Partner im Entscheidungsprozess sein kann.
Solange wir die Fähigkeit zur selektiven Vorhersage weiter optimieren, ist der Mensch der vollständigen Ausschöpfung des Potenzials großer Modelle einen Schritt näher gekommen.
Forscher hoffen, mit ASPIRE die Entwicklung der nächsten Generation von LLM voranzutreiben und so eine zuverlässigere und selbstbewusstere künstliche Intelligenz zu schaffen. Der Mechanismus von ASPIRE: Aufgabenspezifische Feinabstimmung
Anhand eines Trainingsdatensatzes für die Generierungsaufgabe wird das vorab trainierte LLM optimiert, um seine Vorhersageleistung zu verbessern.
Zu diesem Zweck können Parameter-effiziente Feinabstimmungstechniken (z. B. Soft-Cue-Word-Feinabstimmung und LoRA) eingesetzt werden, um vorab trainierte LLMs auf die Aufgabe abzustimmen, da sie damit effektiv eine starke Generalisierung erreichen können eine kleine Anzahl von Zieldaten.
Konkret werden die LLM-Parameter (θ) eingefroren und adaptive Parameter zur Feinabstimmung hinzugefügt. 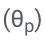
Diese Feinabstimmung kann die Leistung der selektiven Vorhersage verbessern, da sie nicht nur die Vorhersagegenauigkeit verbessert, sondern auch die Wahrscheinlichkeit einer korrekten Ausgabe der Sequenz erhöht.
Nachdem ASPIRE auf eine bestimmte Aufgabe abgestimmt wurde, verwendet ASPIRE LLM und hat gelernt Das Ziel des Forschers besteht darin, Ausgabesequenzen mit hoher Wahrscheinlichkeit zu generieren. Sie verwendeten Beam Search als Dekodierungsalgorithmus, um Ausgabesequenzen mit hoher Wahrscheinlichkeit zu generieren, und verwendeten die Rouge-L-Metrik, um zu bestimmen, ob die generierten Ausgabesequenzen korrekt waren. Nachdem ASPIRE die High-Likelihood-Ausgabe jeder Abfrage abgetastet hat, fügt ASPIRE adaptive Parameter Da die Generierung der Ausgabesequenz nur von θ und Die Forscher haben In diesem Rahmen kann jede Parameter-effiziente Feinabstimmungsmethode zum Trainieren von In dieser Arbeit verwenden die Forscher die Feinabstimmung von Soft-Cues, einen einfachen, aber effektiven Mechanismus zum Erlernen von „Soft-Cues“, um eingefrorene Sprachmodelle so abzustimmen, dass sie effektiver als herkömmliche diskrete Text-Cues sind, um bestimmte nachgelagerte Aufgaben auszuführen. Der Kern dieses Ansatzes ist die Erkenntnis, dass, wenn Hinweise entwickelt werden können, die die Selbsteinschätzung effektiv anregen, diese Hinweise durch die Feinabstimmung weicher Hinweise in Kombination mit gezielten Trainingszielen erkennbar sein sollten. Nach dem Training Die Forscher definieren dann einen Auswahlwert, der die Wahrscheinlichkeit, eine Antwort zu generieren, mit dem erlernten Selbstbewertungswert (d. h. der Wahrscheinlichkeit, dass die Vorhersage für die Abfrage richtig ist) kombiniert, um selektive Vorhersagen zu treffen. Ergebnisse Um die Wirksamkeit von ASPIRE zu demonstrieren, verwendeten die Forscher verschiedene offene, vorab trainierte Transformer (OPT)-Modelle, um sie anhand von drei Frage-Antwort-Datensätzen (CoQA, TriviaQA und SQuAD) auszuwerten. Durch die Anpassung des Trainings mithilfe von Soft Cues Zum Beispiel zeigte das OPT-2.7B-Modell mit ASPIRE eine bessere Leistung im Vergleich zum größeren vorab trainierten OPT-30B-Modell mit CoQA- und SQuAD-Datensätzen. Diese Ergebnisse deuten darauf hin, dass kleinere LLMs bei entsprechender Abstimmung in einigen Fällen die Genauigkeit größerer Modelle erreichen oder möglicherweise sogar übertreffen können. Bei der näheren Betrachtung der Berechnung von Auswahlwerten für feste Modellvorhersagen erzielte ASPIRE für alle Datensätze höhere AUROC-Werte als die Basismethoden (zufällig ausgewählte korrekte Ausgabesequenzen haben höhere Werte als zufällig ausgewählte falsche Ausgabesequenzen). Wahrscheinlichkeit einer höheren Auswahlpunktzahl). Zum Beispiel verbessert ASPIRE beim CoQA-Benchmark den AUROC von 51,3 % auf 80,3 % im Vergleich zum Ausgangswert. Bei der Auswertung des TriviaQA-Datensatzes ergab sich ein interessantes Muster. Während das vorab trainierte OPT-30B-Modell eine höhere Grundgenauigkeit aufweist, verbessert sich seine selektive Vorhersageleistung nicht wesentlich, wenn herkömmliche Selbstbewertungsmethoden (Selbstbewertung und P(True)) angewendet werden. Im Gegensatz dazu übertrifft das viel kleinere OPT-2.7B-Modell in dieser Hinsicht andere Modelle, nachdem es mit ASPIRE erweitert wurde. Dieser Unterschied verkörpert ein wichtiges Problem: Größere LLMs, die herkömmliche Selbstbewertungstechniken verwenden, sind bei der selektiven Vorhersage möglicherweise nicht so effektiv wie kleinere, durch ASPIRE erweiterte Modelle. Die experimentelle Reise der Forscher mit ASPIRE verdeutlicht einen wichtigen Wandel in der LLM-Landschaft: Die Kapazität eines Sprachmodells ist nicht das A und O seiner Leistung. Im Gegensatz dazu kann die Modelleffektivität durch Richtlinienanpassungen erheblich verbessert werden, was selbst in kleineren Modellen genauere und zuverlässigere Vorhersagen ermöglicht. Damit demonstriert ASPIRE das Potenzial von LLM, die Sicherheit seiner eigenen Antworten sinnvoll zu bestimmen und andere 10x größere Modelle bei selektiven Vorhersageaufgaben deutlich zu übertreffen. Antwortstichprobe
 , unterschiedliche Antworten für jede Trainingsfrage zu generieren und einen Datensatz für das Selbstbewertungslernen zu erstellen.
, unterschiedliche Antworten für jede Trainingsfrage zu generieren und einen Datensatz für das Selbstbewertungslernen zu erstellen. Selbstbewertungslernen
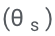 und nur Feinabstimmungen
und nur Feinabstimmungen 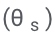 hinzu, um Selbstbewertung zu lernen.
hinzu, um Selbstbewertung zu lernen. 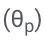 abhängt, kann durch das Einfrieren von θ und dem gelernten
abhängt, kann durch das Einfrieren von θ und dem gelernten 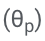 eine Änderung des Vorhersageverhaltens des LLM beim Lernen der Selbstbewertung vermieden werden.
eine Änderung des Vorhersageverhaltens des LLM beim Lernen der Selbstbewertung vermieden werden. 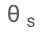 so optimiert, dass das angepasste LLM selbstständig richtige und falsche Antworten unterscheiden kann.
so optimiert, dass das angepasste LLM selbstständig richtige und falsche Antworten unterscheiden kann. 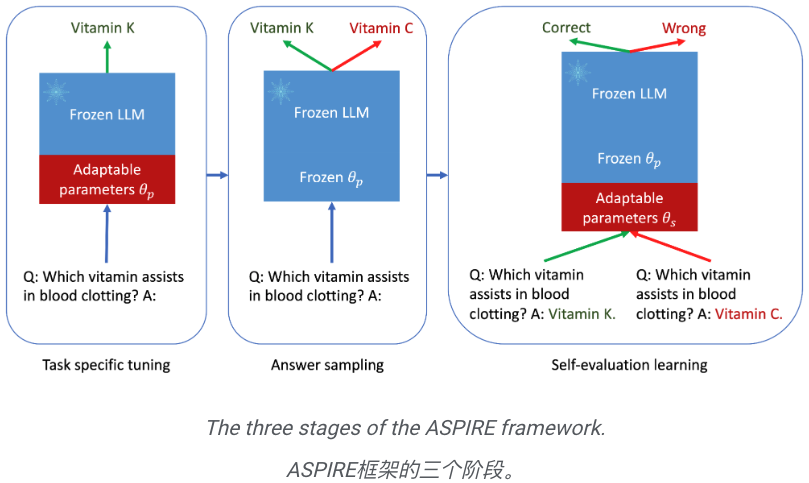
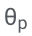 und
und 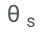 verwendet werden.
verwendet werden. 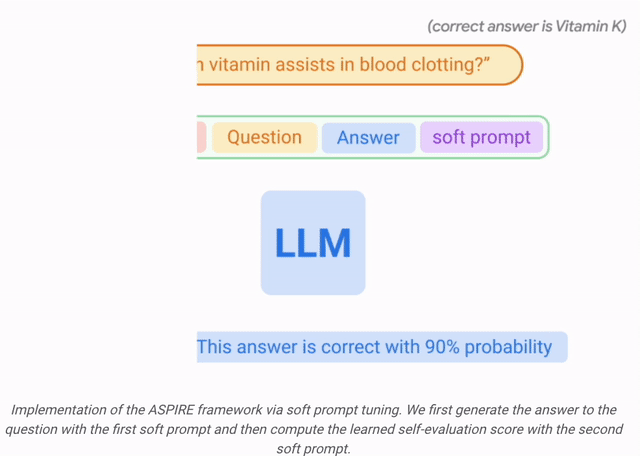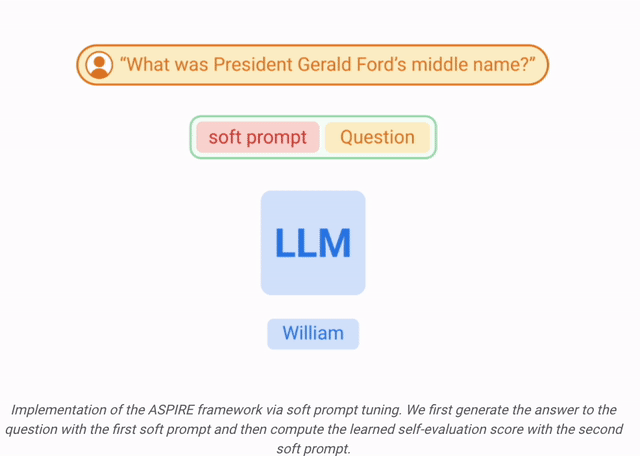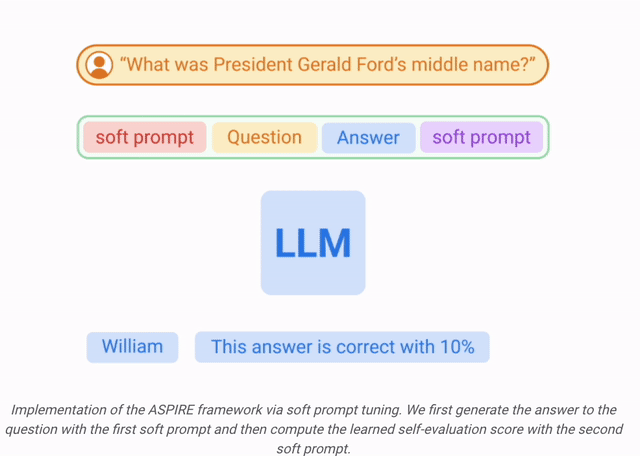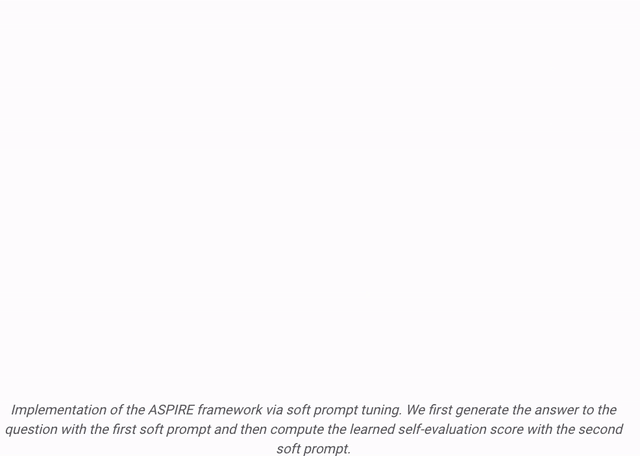
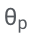 und
und 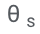 erhielten die Forscher die Vorhersage der Abfrage durch Beam-Search-Dekodierung.
erhielten die Forscher die Vorhersage der Abfrage durch Beam-Search-Dekodierung. 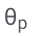 Die Forscher beobachteten eine erhebliche Verbesserung der LLM-Genauigkeit.
Die Forscher beobachteten eine erhebliche Verbesserung der LLM-Genauigkeit. 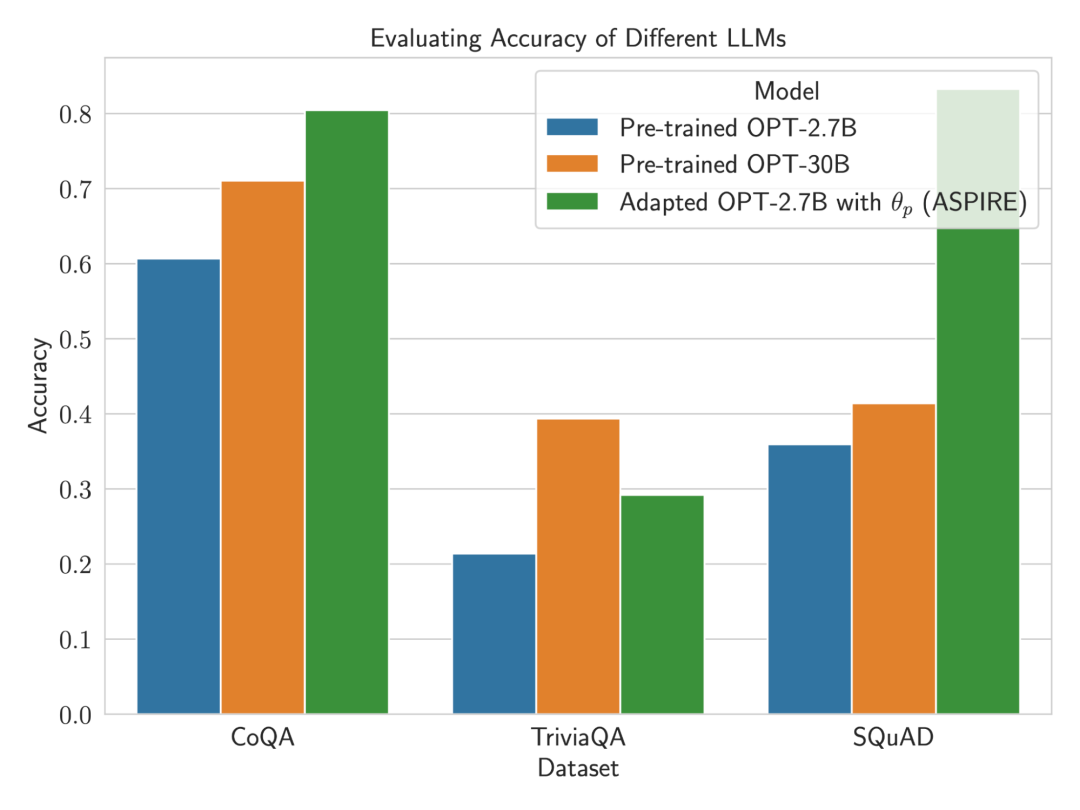
Das obige ist der detaillierte Inhalt vonGoogles neue Methode ASPIRE: Bietet LLM-Selbstbewertungsfunktionen, löst effektiv das „Illusions'-Problem und übertrifft das Volumenmodell um das Zehnfache. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Verwenden Sie ddrescue, um Daten unter Linux wiederherzustellen
Mar 20, 2024 pm 01:37 PM
Verwenden Sie ddrescue, um Daten unter Linux wiederherzustellen
Mar 20, 2024 pm 01:37 PM
DDREASE ist ein Tool zum Wiederherstellen von Daten von Datei- oder Blockgeräten wie Festplatten, SSDs, RAM-Disks, CDs, DVDs und USB-Speichergeräten. Es kopiert Daten von einem Blockgerät auf ein anderes, wobei beschädigte Blöcke zurückbleiben und nur gute Blöcke verschoben werden. ddreasue ist ein leistungsstarkes Wiederherstellungstool, das vollständig automatisiert ist, da es während der Wiederherstellungsvorgänge keine Unterbrechungen erfordert. Darüber hinaus kann es dank der ddasue-Map-Datei jederzeit gestoppt und fortgesetzt werden. Weitere wichtige Funktionen von DDREASE sind: Es überschreibt die wiederhergestellten Daten nicht, füllt aber die Lücken im Falle einer iterativen Wiederherstellung. Es kann jedoch gekürzt werden, wenn das Tool explizit dazu aufgefordert wird. Stellen Sie Daten aus mehreren Dateien oder Blöcken in einer einzigen wieder her
 Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
0.Was bewirkt dieser Artikel? Wir schlagen DepthFM vor: ein vielseitiges und schnelles generatives monokulares Tiefenschätzungsmodell auf dem neuesten Stand der Technik. Zusätzlich zu herkömmlichen Tiefenschätzungsaufgaben demonstriert DepthFM auch hochmoderne Fähigkeiten bei nachgelagerten Aufgaben wie dem Tiefen-Inpainting. DepthFM ist effizient und kann Tiefenkarten innerhalb weniger Inferenzschritte synthetisieren. Lassen Sie uns diese Arbeit gemeinsam lesen ~ 1. Titel der Papierinformationen: DepthFM: FastMonocularDepthEstimationwithFlowMatching Autor: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Stehen Sie vor einer Verzögerung oder einer langsamen mobilen Datenverbindung auf dem iPhone? Normalerweise hängt die Stärke des Mobilfunk-Internets auf Ihrem Telefon von mehreren Faktoren ab, wie z. B. der Region, dem Mobilfunknetztyp, dem Roaming-Typ usw. Es gibt einige Dinge, die Sie tun können, um eine schnellere und zuverlässigere Mobilfunk-Internetverbindung zu erhalten. Fix 1 – Neustart des iPhone erzwingen Manchmal werden durch einen erzwungenen Neustart Ihres Geräts viele Dinge zurückgesetzt, einschließlich der Mobilfunkverbindung. Schritt 1 – Drücken Sie einfach einmal die Lauter-Taste und lassen Sie sie los. Drücken Sie anschließend die Leiser-Taste und lassen Sie sie wieder los. Schritt 2 – Der nächste Teil des Prozesses besteht darin, die Taste auf der rechten Seite gedrückt zu halten. Lassen Sie das iPhone den Neustart abschließen. Aktivieren Sie Mobilfunkdaten und überprüfen Sie die Netzwerkgeschwindigkeit. Überprüfen Sie es erneut. Fix 2 – Datenmodus ändern 5G bietet zwar bessere Netzwerkgeschwindigkeiten, funktioniert jedoch besser, wenn das Signal schwächer ist
 Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Ich weine zu Tode. Die Daten im Internet reichen überhaupt nicht aus. Das Trainingsmodell sieht aus wie „Die Tribute von Panem“, und KI-Forscher auf der ganzen Welt machen sich Gedanken darüber, wie sie diese datenhungrigen Esser ernähren sollen. Dieses Problem tritt insbesondere bei multimodalen Aufgaben auf. Zu einer Zeit, als sie ratlos waren, nutzte ein Start-up-Team der Abteilung der Renmin-Universität von China sein eigenes neues Modell, um als erstes in China einen „modellgenerierten Datenfeed selbst“ in die Realität umzusetzen. Darüber hinaus handelt es sich um einen zweigleisigen Ansatz auf der Verständnisseite und der Generierungsseite. Beide Seiten können hochwertige, multimodale neue Daten generieren und Datenrückmeldungen an das Modell selbst liefern. Was ist ein Modell? Awaker 1.0, ein großes multimodales Modell, das gerade im Zhongguancun-Forum erschienen ist. Wer ist das Team? Sophon-Motor. Gegründet von Gao Yizhao, einem Doktoranden an der Hillhouse School of Artificial Intelligence der Renmin University.
 Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Was? Wird Zootopia durch heimische KI in die Realität umgesetzt? Zusammen mit dem Video wird ein neues groß angelegtes inländisches Videogenerationsmodell namens „Keling“ vorgestellt. Sora geht einen ähnlichen technischen Weg und kombiniert eine Reihe selbst entwickelter technologischer Innovationen, um Videos zu produzieren, die nicht nur große und vernünftige Bewegungen aufweisen, sondern auch die Eigenschaften der physischen Welt simulieren und über starke konzeptionelle Kombinationsfähigkeiten und Vorstellungskraft verfügen. Den Daten zufolge unterstützt Keling die Erstellung ultralanger Videos von bis zu 2 Minuten mit 30 Bildern pro Sekunde, mit Auflösungen von bis zu 1080p und unterstützt mehrere Seitenverhältnisse. Ein weiterer wichtiger Punkt ist, dass es sich bei Keling nicht um eine vom Labor veröffentlichte Demo oder Video-Ergebnisdemonstration handelt, sondern um eine Anwendung auf Produktebene, die von Kuaishou, einem führenden Anbieter im Bereich Kurzvideos, gestartet wurde. Darüber hinaus liegt das Hauptaugenmerk darauf, pragmatisch zu sein, keine Blankoschecks auszustellen und sofort nach der Veröffentlichung online zu gehen. Das große Modell von Ke Ling wurde bereits in Kuaiying veröffentlicht.
 Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Kürzlich wurde die Militärwelt von der Nachricht überwältigt: US-Militärkampfflugzeuge können jetzt mithilfe von KI vollautomatische Luftkämpfe absolvieren. Ja, erst kürzlich wurde der KI-Kampfjet des US-Militärs zum ersten Mal der Öffentlichkeit zugänglich gemacht und sein Geheimnis gelüftet. Der vollständige Name dieses Jägers lautet „Variable Stability Simulator Test Aircraft“ (VISTA). Er wurde vom Minister der US-Luftwaffe persönlich geflogen, um einen Eins-gegen-eins-Luftkampf zu simulieren. Am 2. Mai startete US-Luftwaffenminister Frank Kendall mit einer X-62AVISTA auf der Edwards Air Force Base. Beachten Sie, dass während des einstündigen Fluges alle Flugaktionen autonom von der KI durchgeführt wurden! Kendall sagte: „In den letzten Jahrzehnten haben wir über das unbegrenzte Potenzial des autonomen Luft-Luft-Kampfes nachgedacht, aber es schien immer unerreichbar.“ Nun jedoch,
