
 Technologie-Peripheriegeräte
KI
Google veröffentlicht ASPIRE, ein Modelltrainings-Framework, das es der KI ermöglicht, die Ausgabegenauigkeit unabhängig zu beurteilen
Technologie-Peripheriegeräte
KI
Google veröffentlicht ASPIRE, ein Modelltrainings-Framework, das es der KI ermöglicht, die Ausgabegenauigkeit unabhängig zu beurteilen
Google veröffentlicht ASPIRE, ein Modelltrainings-Framework, das es der KI ermöglicht, die Ausgabegenauigkeit unabhängig zu beurteilen


Google hat kürzlich eine Pressemitteilung veröffentlicht, in der die Einführung des ASPIRE-Trainingsframeworks angekündigt wird, das speziell für große Sprachmodelle entwickelt wurde. Dieses Framework zielt darauf ab, die selektiven Vorhersagefähigkeiten von KI-Modellen zu verbessern.
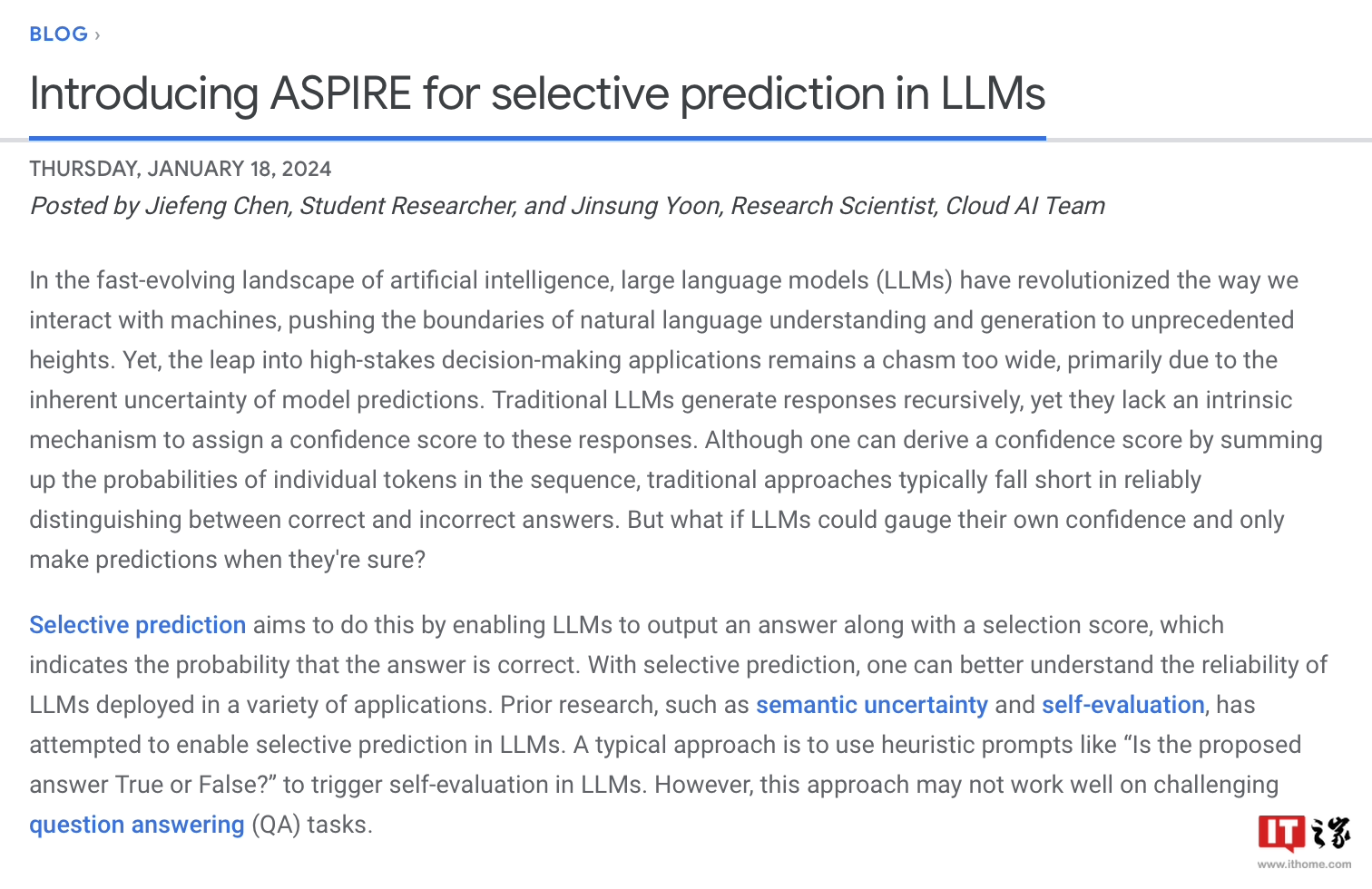
Google erwähnte, dass sich große Sprachmodelle beim Verstehen natürlicher Sprache und bei der Generierung von Inhalten schnell entwickeln und zur Entwicklung verschiedener innovativer Anwendungen verwendet wurden, es jedoch immer noch unangemessen ist, sie auf Situationen mit hoher Entscheidungsfindung anzuwenden. Dies liegt an der Unsicherheit und der Möglichkeit einer „Halluzination“ bei Modellvorhersagen. Daher hat Google ein ASPIRE-Trainingsframework entwickelt, das einen „Glaubwürdigkeits“-Mechanismus für eine Reihe von Modellen einführt , jede Die Antworten haben alle einen Wahrscheinlichkeitswert für die Richtigkeit .
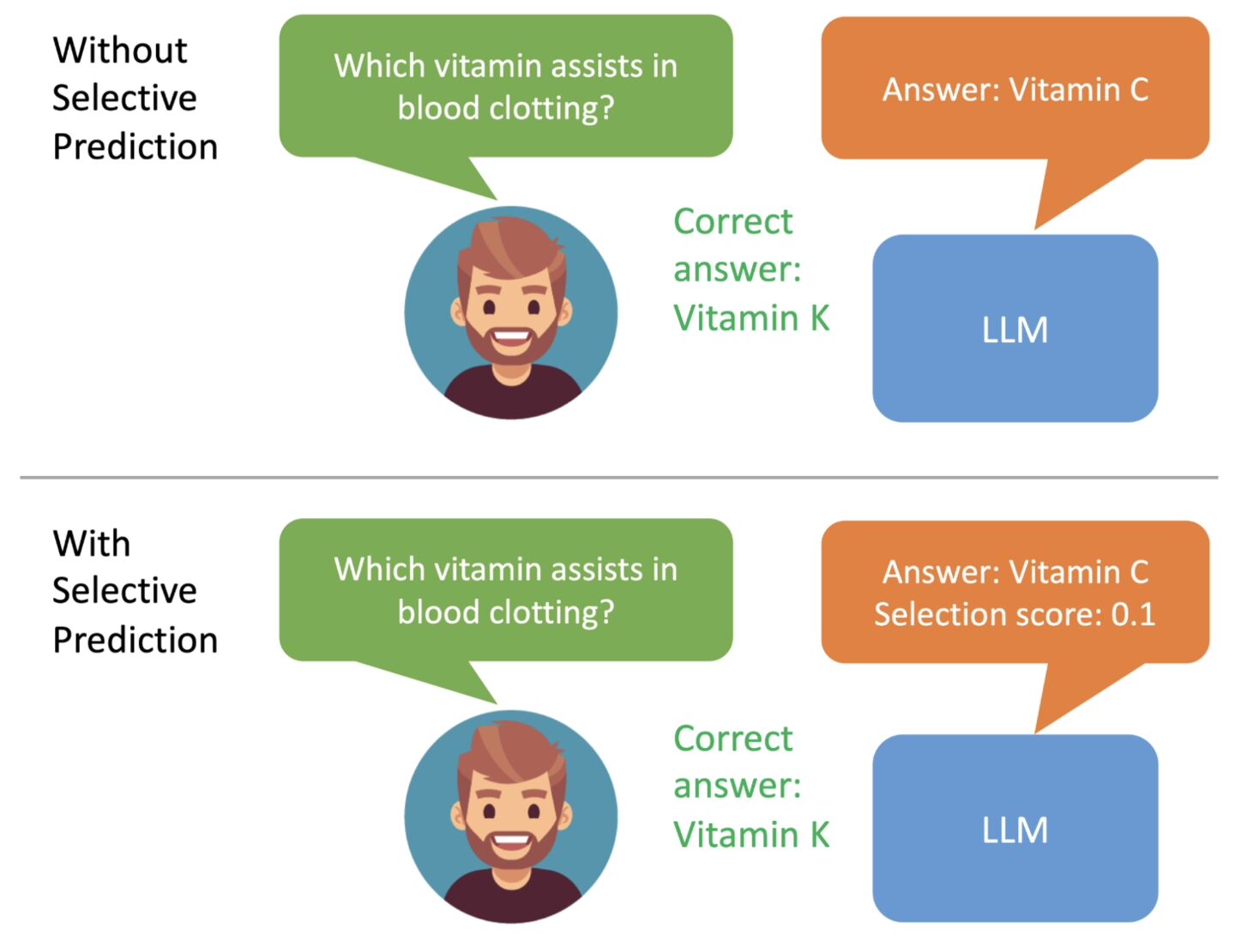
Die zweite Stufe ist das „Antwort-Sampling“. Nach einer spezifischen Feinabstimmung kann das Modell die zuvor erlernten einstellbaren Parameter verwenden, um für jede Trainingsfrage unterschiedliche Antworten zu generieren und einen Datensatz für das Selbstbewertungslernen zu generieren eine Reihe von Antworten mit hoher Glaubwürdigkeit. 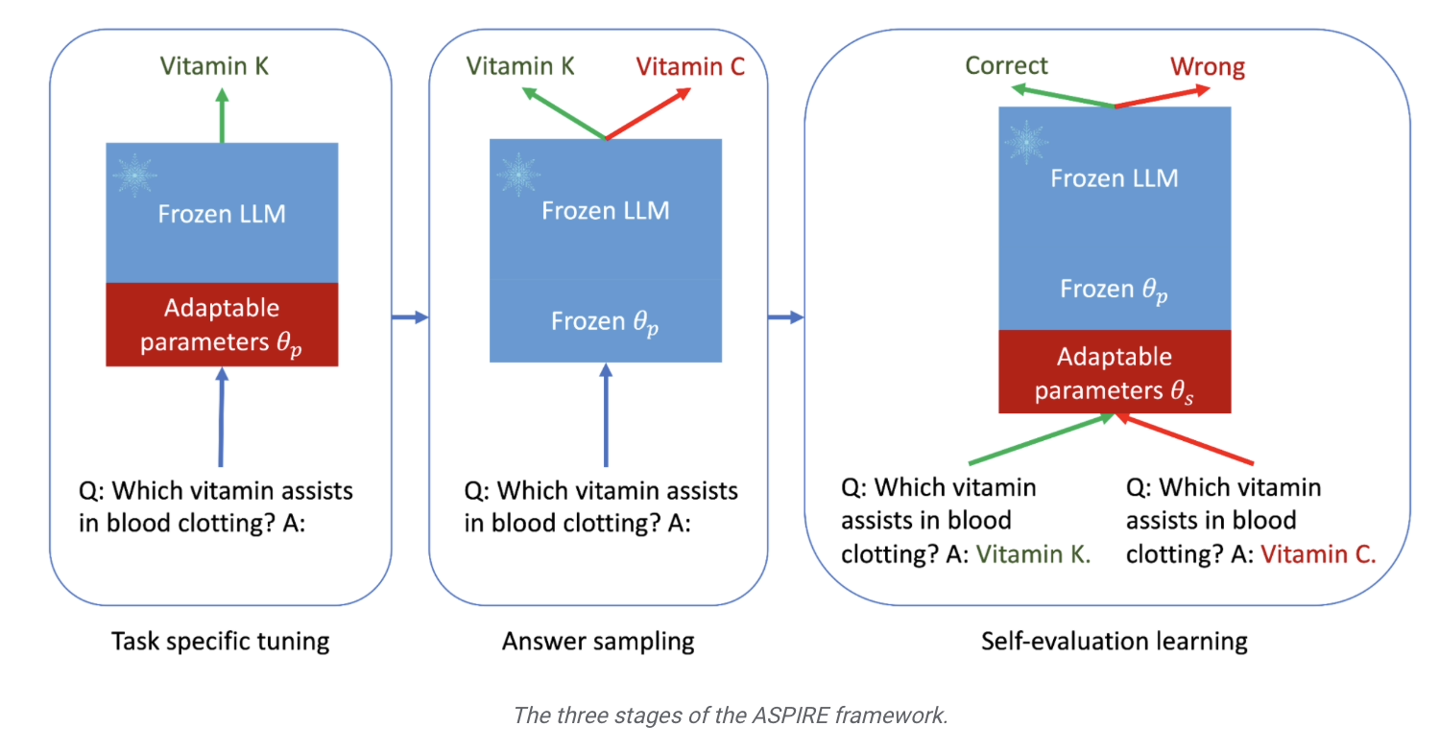 Die Forscher verwendeten außerdem die „Beam Search“-Methode und den Rouge-L-Algorithmus, um die Qualität der Antworten zu bewerten, und gaben die generierten Antworten und Bewertungen erneut in das Modell ein, um die dritte Stufe zu starten
Die Forscher verwendeten außerdem die „Beam Search“-Methode und den Rouge-L-Algorithmus, um die Qualität der Antworten zu bewerten, und gaben die generierten Antworten und Bewertungen erneut in das Modell ein, um die dritte Stufe zu starten
In der dritten Stufe des „Selbstbewertungslernens“ fügten die Forscher dem Modell eine Reihe anpassbarer Parameter hinzu, um insbesondere die Selbstbewertungsfähigkeiten des Modells zu verbessern.  Das Ziel dieser Phase besteht darin, das Modell lernen zu lassen, „die Genauigkeit der Ausgabeantwort selbst zu beurteilen“
Das Ziel dieser Phase besteht darin, das Modell lernen zu lassen, „die Genauigkeit der Ausgabeantwort selbst zu beurteilen“
Google-Forscher verwendeten drei Frage- und Antwortdatensätze, CoQA, TriviaQA und SQuAD, um die Ergebnisse des ASPIRE-Trainingsrahmens zu überprüfen. Es heißt, dass „das von ASPIRE angepasste kleine Modell OPT-2.7B das größere OPT-2.7B bei weitem übertrifft.“ 30B-Modell.“ Die experimentellen Ergebnisse zeigen auch, dass bei entsprechenden Anpassungen in einigen Szenarien sogar ein kleines Sprachmodell ein großes Sprachmodell übertreffen kann.
Die Forscher kamen zu dem Schluss, dass das 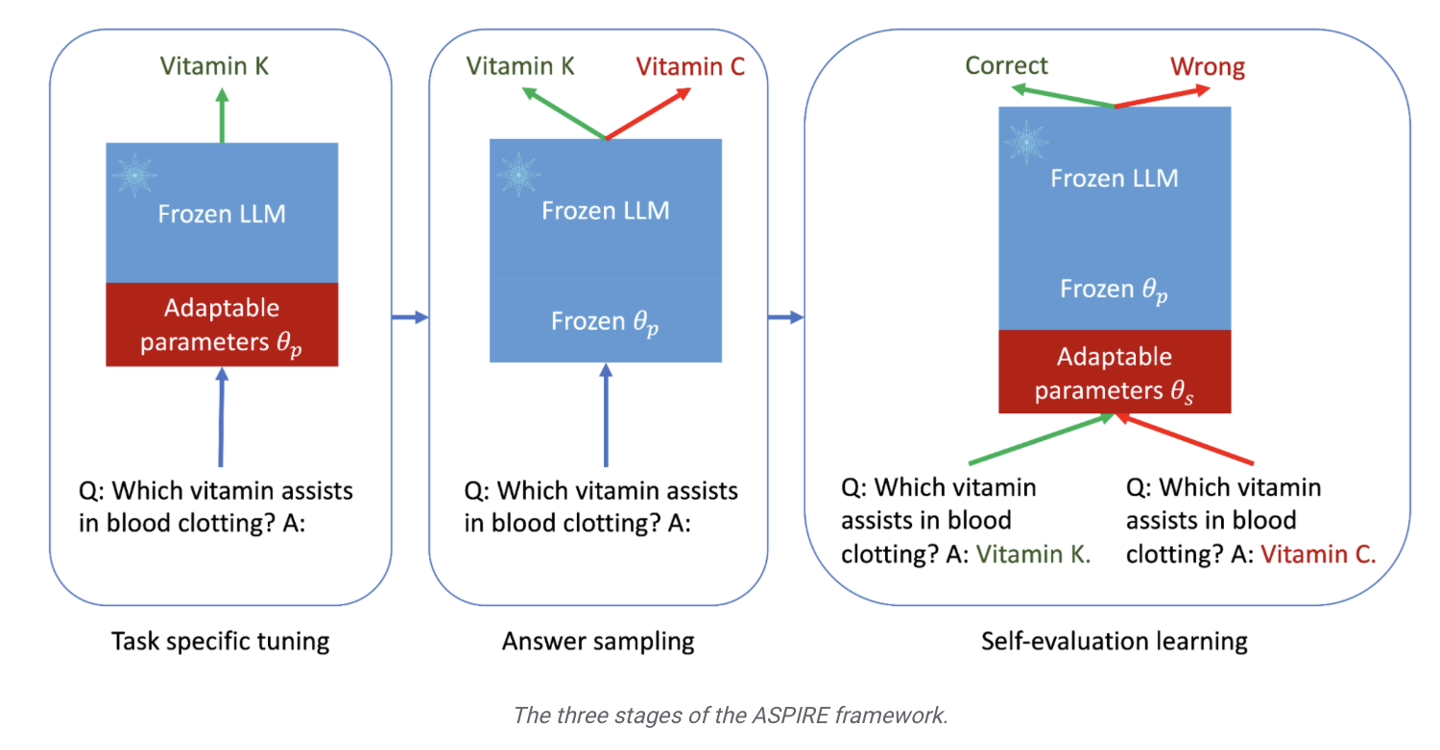 ASPIRE-Framework-Training die Ausgabegenauigkeit großer Sprachmodelle deutlich verbessern kann und selbst kleinere Modelle nach der Feinabstimmung „genaue und sichere“ Vorhersagen machen können
ASPIRE-Framework-Training die Ausgabegenauigkeit großer Sprachmodelle deutlich verbessern kann und selbst kleinere Modelle nach der Feinabstimmung „genaue und sichere“ Vorhersagen machen können
Das obige ist der detaillierte Inhalt vonGoogle veröffentlicht ASPIRE, ein Modelltrainings-Framework, das es der KI ermöglicht, die Ausgabegenauigkeit unabhängig zu beurteilen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 So erstellen Sie die Oracle -Datenbank So erstellen Sie die Oracle -Datenbank
Apr 11, 2025 pm 02:36 PM
So erstellen Sie die Oracle -Datenbank So erstellen Sie die Oracle -Datenbank
Apr 11, 2025 pm 02:36 PM
Um eine Oracle -Datenbank zu erstellen, besteht die gemeinsame Methode darin, das dbca -grafische Tool zu verwenden. Die Schritte sind wie folgt: 1. Verwenden Sie das DBCA -Tool, um den DBNAME festzulegen, um den Datenbanknamen anzugeben. 2. Setzen Sie Syspassword und SystemPassword auf starke Passwörter. 3.. Setzen Sie Charaktere und NationalCharacterset auf AL32UTF8; 4. Setzen Sie MemorySize und tablespacesize, um sie entsprechend den tatsächlichen Bedürfnissen anzupassen. 5. Geben Sie den Logfile -Pfad an. Erweiterte Methoden werden manuell mit SQL -Befehlen erstellt, sind jedoch komplexer und anfällig für Fehler. Achten Sie auf die Kennwortstärke, die Auswahl der Zeichensatz, die Größe und den Speicher von Tabellenräumen
 Erstellen einer Oracle -Datenbank So erstellen Sie eine Oracle -Datenbank
Apr 11, 2025 pm 02:33 PM
Erstellen einer Oracle -Datenbank So erstellen Sie eine Oracle -Datenbank
Apr 11, 2025 pm 02:33 PM
Das Erstellen einer Oracle -Datenbank ist nicht einfach, Sie müssen den zugrunde liegenden Mechanismus verstehen. 1. Sie müssen die Konzepte von Datenbank und Oracle DBMS verstehen. 2. Beherrschen Sie die Kernkonzepte wie SID, CDB (Containerdatenbank), PDB (Pluggable -Datenbank); 3.. Verwenden Sie SQL*Plus, um CDB zu erstellen und dann PDB zu erstellen. Sie müssen Parameter wie Größe, Anzahl der Datendateien und Pfade angeben. 4. Erweiterte Anwendungen müssen den Zeichensatz, den Speicher und andere Parameter anpassen und die Leistungsstimmung durchführen. 5. Achten Sie auf Speicherplatz, Berechtigungen und Parametereinstellungen und überwachen und optimieren Sie die Datenbankleistung kontinuierlich. Nur indem Sie es geschickt beherrschen, müssen Sie die Erstellung und Verwaltung von Oracle -Datenbanken wirklich verstehen.
 So schreiben Sie Oracle -Datenbankanweisungen
Apr 11, 2025 pm 02:42 PM
So schreiben Sie Oracle -Datenbankanweisungen
Apr 11, 2025 pm 02:42 PM
Der Kern von Oracle SQL -Anweisungen ist ausgewählt, einfügen, aktualisiert und löschen sowie die flexible Anwendung verschiedener Klauseln. Es ist wichtig, den Ausführungsmechanismus hinter der Aussage wie die Indexoptimierung zu verstehen. Zu den erweiterten Verwendungen gehören Unterabfragen, Verbindungsabfragen, Analysefunktionen und PL/SQL. Häufige Fehler sind Syntaxfehler, Leistungsprobleme und Datenkonsistenzprobleme. Best Practices für Leistungsoptimierung umfassen die Verwendung geeigneter Indizes, die Vermeidung von Auswahl *, optimieren Sie, wo Klauseln und gebundene Variablen verwenden. Das Beherrschen von Oracle SQL erfordert Übung, einschließlich des Schreibens von Code, Debuggen, Denken und Verständnis der zugrunde liegenden Mechanismen.
 Hinzufügen, Ändern und Löschen von MySQL Data Table Field Operation Operation Guide, addieren, ändern und löschen
Apr 11, 2025 pm 05:42 PM
Hinzufügen, Ändern und Löschen von MySQL Data Table Field Operation Operation Guide, addieren, ändern und löschen
Apr 11, 2025 pm 05:42 PM
Feldbetriebshandbuch in MySQL: Felder hinzufügen, ändern und löschen. Feld hinzufügen: Alter table table_name hinzufügen column_name data_type [nicht null] [Standard default_value] [Primärschlüssel] [auto_increment] Feld ändern: Alter table table_name Ändern Sie Column_Name Data_type [nicht null] [diffault default_value] [Primärschlüssel] [Primärschlüssel]
 Was sind die Integritätsbeschränkungen von Oracle -Datenbanktabellen?
Apr 11, 2025 pm 03:42 PM
Was sind die Integritätsbeschränkungen von Oracle -Datenbanktabellen?
Apr 11, 2025 pm 03:42 PM
Die Integritätsbeschränkungen von Oracle -Datenbanken können die Datengenauigkeit sicherstellen, einschließlich: nicht Null: Nullwerte sind verboten; Einzigartig: Einzigartigkeit garantieren und einen einzelnen Nullwert ermöglichen; Primärschlüssel: Primärschlüsselbeschränkung, Stärkung der einzigartigen und verboten Nullwerte; Fremdschlüssel: Verwalten Sie die Beziehungen zwischen Tabellen, Fremdschlüssel beziehen sich auf Primärtabellen -Primärschlüssel. Überprüfen Sie: Spaltenwerte nach Bedingungen begrenzen.
 Detaillierte Erläuterung verschachtelter Abfrageinstanzen in der MySQL -Datenbank
Apr 11, 2025 pm 05:48 PM
Detaillierte Erläuterung verschachtelter Abfrageinstanzen in der MySQL -Datenbank
Apr 11, 2025 pm 05:48 PM
Verschachtelte Anfragen sind eine Möglichkeit, eine andere Frage in eine Abfrage aufzunehmen. Sie werden hauptsächlich zum Abrufen von Daten verwendet, die komplexe Bedingungen erfüllen, mehrere Tabellen assoziieren und zusammenfassende Werte oder statistische Informationen berechnen. Beispiele hierfür sind zu findenen Mitarbeitern über den überdurchschnittlichen Löhnen, das Finden von Bestellungen für eine bestimmte Kategorie und die Berechnung des Gesamtbestellvolumens für jedes Produkt. Beim Schreiben verschachtelter Abfragen müssen Sie folgen: Unterabfragen schreiben, ihre Ergebnisse in äußere Abfragen schreiben (auf Alias oder als Klauseln bezogen) und optimieren Sie die Abfrageleistung (unter Verwendung von Indizes).
 Was macht Oracle?
Apr 11, 2025 pm 06:06 PM
Was macht Oracle?
Apr 11, 2025 pm 06:06 PM
Oracle ist das weltweit größte Softwareunternehmen für Datenbankverwaltungssystem (DBMS). Zu den Hauptprodukten gehören die folgenden Funktionen: Entwicklungstools für relationale Datenbankverwaltungssysteme (Oracle Database) (Oracle Apex, Oracle Visual Builder) Middleware (Oracle Weblogic Server, Oracle Soa Suite) Cloud -Dienst (Oracle Cloud Infrastructure) Analyse und Business Intelligence (Oracle Analytic
 Was sind die Systementwicklungstools für Oracle -Datenbanken?
Apr 11, 2025 pm 03:45 PM
Was sind die Systementwicklungstools für Oracle -Datenbanken?
Apr 11, 2025 pm 03:45 PM
Zu den Oracle -Datenbankentwicklungs -Tools gehören nicht nur SQL*Plus, sondern auch die folgenden Tools: PL/SQL Developer: Paid Tool, bietet Code -Bearbeitungs-, Debugging- und Datenbankverwaltungsfunktionen und unterstützt das Hervorheben und automatische Abschluss des Syntax -Codes. Toad for Oracle: Bezahltes Tool, das PL/SQL-Entwickler-ähnliche Funktionen sowie zusätzliche Funktionen zur Überwachung der Datenbankleistung und der SQL-Optimierungsfunktionen bietet. SQL Developer: Oracys offizielles kostenloses Tool, das grundlegende Funktionen für Code -Bearbeitung, Debugging und Datenbankmanagement bietet, geeignet für Entwickler mit begrenzten Budgets. DataGrip: Jetbrains
