

Der Random Forest-Algorithmus ist eine Ensemble-Technik, die Regressions- und Klassifizierungsaufgaben mithilfe mehrerer Entscheidungsbäume und einer Technik namens Bootstrap und Aggregation durchführen kann. Die Grundidee dahinter besteht darin, mehrere Entscheidungsbäume zu kombinieren, um die endgültige Ausgabe zu bestimmen, anstatt sich auf einen einzigen Entscheidungsbaum zu verlassen.
Random Forest produziert eine große Anzahl von Klassifizierungsbäumen. Platzieren Sie den Eingabevektor unter jedem Baum in der Gesamtstruktur, um neue Objekte basierend auf dem Eingabevektor zu klassifizieren. Jedem Baum wird eine Klasse zugewiesen, die wir „Abstimmung“ nennen können, und letztendlich wird die Klasse mit der höchsten Anzahl an Stimmen ausgewählt.
Die folgenden Schritte helfen uns zu verstehen, wie der Random-Forest-Algorithmus funktioniert.
Schritt 1: Wählen Sie zunächst eine Zufallsstichprobe aus dem Datensatz aus.
Schritt 2: Für jede Stichprobe erstellt der Algorithmus einen Entscheidungsbaum. Anschließend werden die Vorhersageergebnisse für jeden Entscheidungsbaum erhalten.
Schritt 3: Über jedes erwartete Ergebnis in diesem Schritt wird abgestimmt.
Schritt 4: Wählen Sie abschließend das Vorhersageergebnis mit den meisten Stimmen als endgültiges Vorhersageergebnis aus.
Das Folgende sind die Hauptmerkmale des Random Forest-Algorithmus:
Random Forest verfügt über mehrere Entscheidungsbäume als grundlegendes Lernmodell. Wir führen zufällige Zeilenstichproben und Merkmalsstichproben aus dem Datensatz durch, um für jedes Modell einen Stichprobendatensatz zu erstellen. Dieser Teil wird Bootstrap genannt.
Schritt 1: Importieren Sie die erforderlichen Bibliotheken.
import numpy as np import matplotlib.pyplot as plt import pandas as pd
Schritt 2: Importieren und drucken Sie den Datensatz
ata=pd.read_csv('Salaries.csv') print(data)
Schritt 3: Wählen Sie alle Zeilen und Spalte 1 aus dem Datensatz bis x aus, wählen Sie alle Zeilen und Spalte 2 als y aus
x=df.iloc[: ,:-1] #:: bedeutet, dass alle Zeilen ausgewählt werden. „:-1“ bedeutet, dass die letzte Spalte ignoriert wird.
y=df.iloc[:,-1:]#:: bedeutet, dass alle Zeilen ausgewählt werden. „- 1:“ bedeutet, dass alle Spalten außer der letzten Spalte ignoriert werden
#Die Funktion „iloc()“ ermöglicht es uns, bestimmte Zellen des Datensatzes auszuwählen, das heißt, sie hilft uns, die spezifischen Zellen des Datensatzes aus dem Datenrahmen auszuwählen oder Datensatz Wählt aus einer Menge von Werten den Wert aus, der zu einer bestimmten Zeile oder Spalte gehört.
Schritt 4: Passen Sie einen zufälligen Waldregressor an den Datensatz an
from sklearn.ensemble import RandomForestRegressor regressor=RandomForestRegressor(n_estimators=100,random_state=0) regressor.fit(x,y)
Schritt 5: Neue Ergebnisse vorhersagen
Y_pred=regressor.predict(np.array([6.5]).reshape(1,1))
Schritt 6: Visualisieren Sie die Ergebnisse
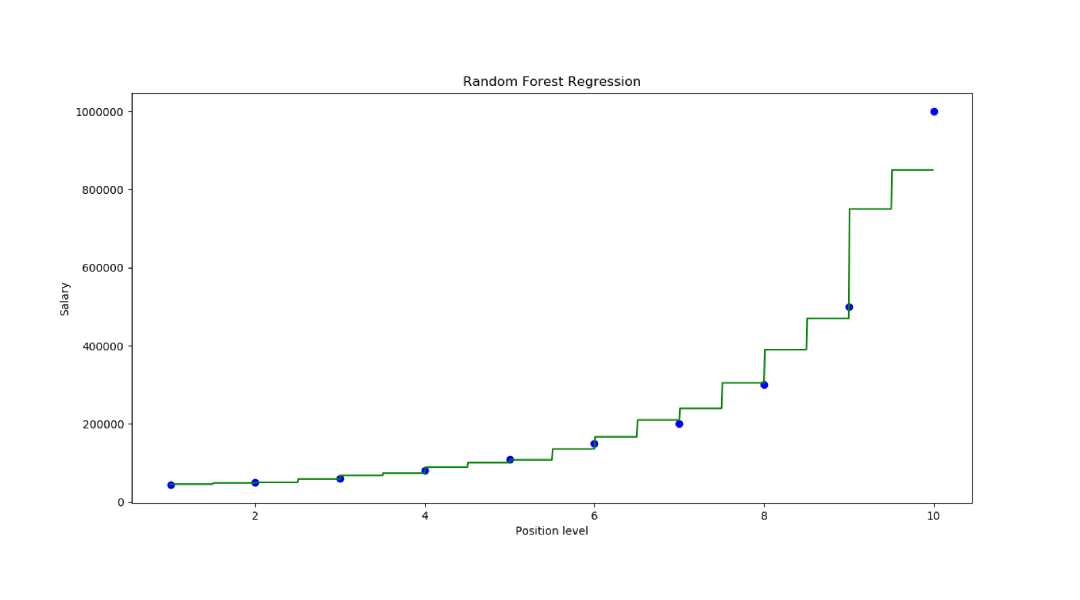
X_grid=np.arrange(min(x),max(x),0.01) X_grid=X_grid.reshape((len(X_grid),1)) plt.scatter(x,y,color='blue') plt.plot(X_grid,regressor.predict(X_grid), color='green') plt.title('Random Forest Regression') plt.xlabel('Position level') plt.ylabel('Salary') plt.show()
Das obige ist der detaillierte Inhalt vonPython-Beispiele für Prinzipien und praktische Anwendungen von Random-Forest-Algorithmen (mit vollständigem Code). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



