
 Technologie-Peripheriegeräte
KI
Ein einschichtiges neuronales Netzwerk kann die Grundursache des XOR-Problems nicht lösen
Technologie-Peripheriegeräte
KI
Ein einschichtiges neuronales Netzwerk kann die Grundursache des XOR-Problems nicht lösen
Ein einschichtiges neuronales Netzwerk kann die Grundursache des XOR-Problems nicht lösen


Im Bereich des maschinellen Lernens ist das neuronale Netzwerk ein wichtiges Modell, das bei vielen Aufgaben gute Leistungen erbringt. Einige Aufgaben sind jedoch für einschichtige neuronale Netze schwer zu lösen. Ein typisches Beispiel ist das XOR-Problem. Das XOR-Problem bedeutet, dass bei der Eingabe zweier Binärzahlen das Ausgabeergebnis genau dann 1 ist, wenn die beiden Eingaben nicht gleich sind. In diesem Artikel werden die Gründe, warum ein einschichtiges neuronales Netzwerk das XOR-Problem nicht lösen kann, unter drei Gesichtspunkten erläutert: den strukturellen Merkmalen des einschichtigen neuronalen Netzwerks, den wesentlichen Merkmalen des XOR-Problems und dem Trainingsprozess des neuronalen Netzwerks.
Zuallererst bestimmen die strukturellen Eigenschaften eines einschichtigen neuronalen Netzwerks, dass es das XOR-Problem nicht lösen kann. Ein einschichtiges neuronales Netzwerk besteht aus einer Eingabeschicht, einer Ausgabeschicht und einer Aktivierungsfunktion. Zwischen der Eingabeschicht und der Ausgabeschicht gibt es keine weiteren Schichten, was bedeutet, dass ein einschichtiges neuronales Netzwerk nur eine lineare Klassifizierung erreichen kann. Unter linearer Klassifizierung versteht man eine Klassifizierungsmethode, bei der Datenpunkte mithilfe einer geraden Linie in zwei Kategorien unterteilt werden können. Das XOR-Problem ist jedoch ein nichtlineares Klassifizierungsproblem und kann daher nicht durch ein einschichtiges neuronales Netzwerk gelöst werden. Dies liegt daran, dass die Datenpunkte des XOR-Problems nicht perfekt durch eine gerade Linie geteilt werden können. Für das XOR-Problem müssen wir mehrschichtige neuronale Netze, auch tiefe neuronale Netze genannt, einführen, um nichtlineare Klassifizierungsprobleme zu lösen. Mehrschichtige neuronale Netze verfügen über mehrere verborgene Schichten, und jede verborgene Schicht kann verschiedene Merkmale lernen und extrahieren, um komplexe Klassifizierungsprobleme besser zu lösen. Durch die Einführung verborgener Schichten können neuronale Netze komplexere Merkmalskombinationen lernen und sich durch mehrere nichtlineare Transformationen der Entscheidungsgrenze des XOR-Problems nähern. Auf diese Weise können mehrschichtige neuronale Netze nichtlineare Klassifizierungsprobleme, einschließlich XOR-Probleme, besser lösen. Alles in allem besteht das wesentliche Merkmal des linearen
XOR-Problems eines einschichtigen neuronalen Netzwerks darin, dass Datenpunkte nicht perfekt durch eine gerade Linie in zwei Kategorien unterteilt werden können. Dies ist ein wichtiger Grund, warum ein einschichtiges neuronales Netzwerk dies nicht kann Löse dieses Problem. Am Beispiel der Darstellung von Datenpunkten auf einer Ebene stellen blaue Punkte Datenpunkte mit einem Ausgabeergebnis von 0 und rote Punkte Datenpunkte mit einem Ausgabeergebnis von 1 dar. Es ist zu beobachten, dass diese Datenpunkte nicht perfekt durch eine gerade Linie in zwei Kategorien unterteilt werden können und daher nicht mit einem einschichtigen neuronalen Netzwerk klassifiziert werden können. Der
-Prozess ist der Schlüsselfaktor, der das einschichtige neuronale Netzwerk zur Lösung des XOR-Problems beeinflusst. Das Training neuronaler Netze verwendet normalerweise den Backpropagation-Algorithmus, der auf der Methode der Gradientenabstiegsoptimierung basiert. In einem einschichtigen neuronalen Netzwerk kann der Gradientenabstiegsalgorithmus jedoch nur die lokale optimale Lösung und nicht die globale optimale Lösung finden. Dies liegt daran, dass die Eigenschaften des XOR-Problems dazu führen, dass seine Verlustfunktion nicht konvex ist. Im Optimierungsprozess nichtkonvexer Funktionen gibt es mehrere lokal optimale Lösungen, was dazu führt, dass das einschichtige neuronale Netzwerk nicht in der Lage ist, die globale optimale Lösung zu finden.
Es gibt drei Hauptgründe, warum ein einschichtiges neuronales Netzwerk das XOR-Problem nicht lösen kann. Erstens bestimmen die strukturellen Eigenschaften eines einschichtigen neuronalen Netzwerks, dass es nur eine lineare Klassifizierung erreichen kann. Da das wesentliche Merkmal des XOR-Problems ein nichtlineares Klassifizierungsproblem ist, kann ein einschichtiges neuronales Netzwerk es nicht genau klassifizieren. Zweitens ist die Datenverteilung des XOR-Problems nicht linear trennbar, was bedeutet, dass die beiden Datentypen nicht vollständig durch eine gerade Linie getrennt werden können. Daher kann ein einschichtiges neuronales Netzwerk die Klassifizierung von XOR-Problemen nicht durch einfache lineare Transformation erreichen. Schließlich kann es während des Trainingsprozesses des neuronalen Netzwerks mehrere lokale optimale Lösungen geben, und die globale optimale Lösung kann nicht gefunden werden. Dies liegt daran, dass der Parameterraum eines einschichtigen neuronalen Netzwerks nicht konvex ist und es mehrere lokale optimale Lösungen gibt, sodass es schwierig ist, die globale optimale Lösung durch einen einfachen Gradientenabstiegsalgorithmus zu finden. Daher kann ein einschichtiges neuronales Netzwerk das XOR-Problem nicht lösen.
Um das XOR-Problem zu lösen, müssen daher mehrschichtige neuronale Netze oder andere komplexere Modelle verwendet werden. Mehrschichtige neuronale Netze können durch die Einführung verborgener Schichten eine nichtlineare Klassifizierung erreichen und auch komplexere Optimierungsalgorithmen verwenden, um die global optimale Lösung zu finden.
Das obige ist der detaillierte Inhalt vonEin einschichtiges neuronales Netzwerk kann die Grundursache des XOR-Problems nicht lösen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1389
1389
 52
52

 Entdecken Sie die Konzepte, Unterschiede, Vor- und Nachteile von RNN, LSTM und GRU
Jan 22, 2024 pm 07:51 PM
Entdecken Sie die Konzepte, Unterschiede, Vor- und Nachteile von RNN, LSTM und GRU
Jan 22, 2024 pm 07:51 PM
In Zeitreihendaten gibt es Abhängigkeiten zwischen Beobachtungen, sie sind also nicht unabhängig voneinander. Herkömmliche neuronale Netze behandeln jedoch jede Beobachtung als unabhängig, was die Fähigkeit des Modells zur Modellierung von Zeitreihendaten einschränkt. Um dieses Problem zu lösen, wurde das Recurrent Neural Network (RNN) eingeführt, das das Konzept des Speichers einführte, um die dynamischen Eigenschaften von Zeitreihendaten zu erfassen, indem Abhängigkeiten zwischen Datenpunkten im Netzwerk hergestellt werden. Durch wiederkehrende Verbindungen kann RNN frühere Informationen an die aktuelle Beobachtung weitergeben, um zukünftige Werte besser vorherzusagen. Dies macht RNN zu einem leistungsstarken Werkzeug für Aufgaben mit Zeitreihendaten. Aber wie erreicht RNN diese Art von Gedächtnis? RNN realisiert das Gedächtnis durch die Rückkopplungsschleife im neuronalen Netzwerk. Dies ist der Unterschied zwischen RNN und herkömmlichen neuronalen Netzwerken.
 Eine Fallstudie zur Verwendung des bidirektionalen LSTM-Modells zur Textklassifizierung
Jan 24, 2024 am 10:36 AM
Eine Fallstudie zur Verwendung des bidirektionalen LSTM-Modells zur Textklassifizierung
Jan 24, 2024 am 10:36 AM
Das bidirektionale LSTM-Modell ist ein neuronales Netzwerk, das zur Textklassifizierung verwendet wird. Unten finden Sie ein einfaches Beispiel, das zeigt, wie bidirektionales LSTM für Textklassifizierungsaufgaben verwendet wird. Zuerst müssen wir die erforderlichen Bibliotheken und Module importieren: importosimportnumpyasnpfromkeras.preprocessing.textimportTokenizerfromkeras.preprocessing.sequenceimportpad_sequencesfromkeras.modelsimportSequentialfromkeras.layersimportDense,Em
 Berechnung von Gleitkommaoperanden (FLOPS) für neuronale Netze
Jan 22, 2024 pm 07:21 PM
Berechnung von Gleitkommaoperanden (FLOPS) für neuronale Netze
Jan 22, 2024 pm 07:21 PM
FLOPS ist einer der Standards zur Bewertung der Computerleistung und dient zur Messung der Anzahl der Gleitkommaoperationen pro Sekunde. In neuronalen Netzen wird FLOPS häufig verwendet, um die Rechenkomplexität des Modells und die Nutzung von Rechenressourcen zu bewerten. Es ist ein wichtiger Indikator zur Messung der Rechenleistung und Effizienz eines Computers. Ein neuronales Netzwerk ist ein komplexes Modell, das aus mehreren Neuronenschichten besteht und für Aufgaben wie Datenklassifizierung, Regression und Clustering verwendet wird. Das Training und die Inferenz neuronaler Netze erfordert eine große Anzahl von Matrixmultiplikationen, Faltungen und anderen Rechenoperationen, sodass die Rechenkomplexität sehr hoch ist. Mit FLOPS (FloatingPointOperationsperSecond) kann die Rechenkomplexität neuronaler Netze gemessen werden, um die Effizienz der Rechenressourcennutzung des Modells zu bewerten. FLOP
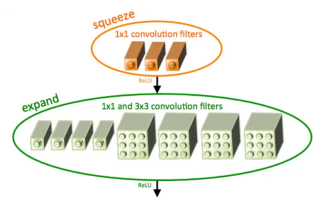 Einführung in SqueezeNet und seine Eigenschaften
Jan 22, 2024 pm 07:15 PM
Einführung in SqueezeNet und seine Eigenschaften
Jan 22, 2024 pm 07:15 PM
SqueezeNet ist ein kleiner und präziser Algorithmus, der eine gute Balance zwischen hoher Genauigkeit und geringer Komplexität schafft und sich daher ideal für mobile und eingebettete Systeme mit begrenzten Ressourcen eignet. Im Jahr 2016 schlugen Forscher von DeepScale, der University of California, Berkeley und der Stanford University SqueezeNet vor, ein kompaktes und effizientes Faltungs-Neuronales Netzwerk (CNN). In den letzten Jahren haben Forscher mehrere Verbesserungen an SqueezeNet vorgenommen, darunter SqueezeNetv1.1 und SqueezeNetv2.0. Verbesserungen in beiden Versionen erhöhen nicht nur die Genauigkeit, sondern senken auch die Rechenkosten. Genauigkeit von SqueezeNetv1.1 im ImageNet-Datensatz
 Definition und Strukturanalyse eines Fuzzy-Neuronalen Netzwerks
Jan 22, 2024 pm 09:09 PM
Definition und Strukturanalyse eines Fuzzy-Neuronalen Netzwerks
Jan 22, 2024 pm 09:09 PM
Das Fuzzy-Neuronale Netzwerk ist ein Hybridmodell, das Fuzzy-Logik und neuronale Netzwerke kombiniert, um unscharfe oder unsichere Probleme zu lösen, die mit herkömmlichen neuronalen Netzwerken nur schwer zu bewältigen sind. Sein Design ist von der Unschärfe und Unsicherheit der menschlichen Wahrnehmung inspiriert und wird daher häufig in Steuerungssystemen, Mustererkennung, Data Mining und anderen Bereichen eingesetzt. Die Grundarchitektur eines Fuzzy-Neuronalen Netzwerks besteht aus einem Fuzzy-Subsystem und einem Neuronalen Subsystem. Das Fuzzy-Subsystem verwendet Fuzzy-Logik, um Eingabedaten zu verarbeiten und in Fuzzy-Sätze umzuwandeln, um die Unschärfe und Unsicherheit der Eingabedaten auszudrücken. Das neuronale Subsystem nutzt neuronale Netze zur Verarbeitung von Fuzzy-Sets für Aufgaben wie Klassifizierung, Regression oder Clustering. Durch die Interaktion zwischen dem Fuzzy-Subsystem und dem neuronalen Subsystem verfügt das Fuzzy-Neuronale Netzwerk über leistungsfähigere Verarbeitungsfähigkeiten und kann
 Bildrauschen mithilfe von Faltungs-Neuronalen Netzen
Jan 23, 2024 pm 11:48 PM
Bildrauschen mithilfe von Faltungs-Neuronalen Netzen
Jan 23, 2024 pm 11:48 PM
Faltungs-Neuronale Netze eignen sich gut für Aufgaben zur Bildrauschunterdrückung. Es nutzt die erlernten Filter, um das Rauschen zu filtern und so das Originalbild wiederherzustellen. In diesem Artikel wird die Methode zur Bildentrauschung basierend auf einem Faltungs-Neuronalen Netzwerk ausführlich vorgestellt. 1. Überblick über das Convolutional Neural Network Das Convolutional Neural Network ist ein Deep-Learning-Algorithmus, der eine Kombination aus mehreren Faltungsschichten, Pooling-Schichten und vollständig verbundenen Schichten verwendet, um Bildmerkmale zu lernen und zu klassifizieren. In der Faltungsschicht werden die lokalen Merkmale des Bildes durch Faltungsoperationen extrahiert und so die räumliche Korrelation im Bild erfasst. Die Pooling-Schicht reduziert den Rechenaufwand durch Reduzierung der Feature-Dimension und behält die Hauptfeatures bei. Die vollständig verbundene Schicht ist für die Zuordnung erlernter Merkmale und Beschriftungen zur Implementierung der Bildklassifizierung oder anderer Aufgaben verantwortlich. Das Design dieser Netzwerkstruktur macht das Faltungs-Neuronale Netzwerk für die Bildverarbeitung und -erkennung nützlich.
 Vergleichen Sie die Ähnlichkeiten, Unterschiede und Beziehungen zwischen erweiterter Faltung und atröser Faltung
Jan 22, 2024 pm 10:27 PM
Vergleichen Sie die Ähnlichkeiten, Unterschiede und Beziehungen zwischen erweiterter Faltung und atröser Faltung
Jan 22, 2024 pm 10:27 PM
Dilatierte Faltung und erweiterte Faltung sind häufig verwendete Operationen in Faltungs-Neuronalen Netzen. In diesem Artikel werden ihre Unterschiede und Beziehungen im Detail vorgestellt. 1. Erweiterte Faltung Die erweiterte Faltung, auch als erweiterte Faltung oder erweiterte Faltung bekannt, ist eine Operation in einem Faltungs-Neuronalen Netzwerk. Es handelt sich um eine Erweiterung, die auf der herkömmlichen Faltungsoperation basiert und das Empfangsfeld des Faltungskerns durch Einfügen von Löchern in den Faltungskern erhöht. Auf diese Weise kann das Netzwerk ein breiteres Spektrum an Funktionen besser erfassen. Die erweiterte Faltung wird im Bereich der Bildverarbeitung häufig verwendet und kann die Leistung des Netzwerks verbessern, ohne die Anzahl der Parameter und den Rechenaufwand zu erhöhen. Durch die Erweiterung des Empfangsfelds des Faltungskerns kann die erweiterte Faltung die globalen Informationen im Bild besser verarbeiten und dadurch den Effekt der Merkmalsextraktion verbessern. Die Hauptidee der erweiterten Faltung besteht darin, einige einzuführen
 Schritte zum Schreiben eines einfachen neuronalen Netzwerks mit Rust
Jan 23, 2024 am 10:45 AM
Schritte zum Schreiben eines einfachen neuronalen Netzwerks mit Rust
Jan 23, 2024 am 10:45 AM
Rust ist eine Programmiersprache auf Systemebene, die sich auf Sicherheit, Leistung und Parallelität konzentriert. Ziel ist es, eine sichere und zuverlässige Programmiersprache bereitzustellen, die für Szenarien wie Betriebssysteme, Netzwerkanwendungen und eingebettete Systeme geeignet ist. Die Sicherheit von Rust beruht hauptsächlich auf zwei Aspekten: dem Eigentumssystem und dem Kreditprüfer. Das Besitzsystem ermöglicht es dem Compiler, den Code zur Kompilierungszeit auf Speicherfehler zu überprüfen und so häufige Speichersicherheitsprobleme zu vermeiden. Indem Rust die Überprüfung der Eigentumsübertragungen von Variablen zur Kompilierungszeit erzwingt, stellt Rust sicher, dass Speicherressourcen ordnungsgemäß verwaltet und freigegeben werden. Der Borrow-Checker analysiert den Lebenszyklus der Variablen, um sicherzustellen, dass nicht mehrere Threads gleichzeitig auf dieselbe Variable zugreifen, wodurch häufige Sicherheitsprobleme bei der Parallelität vermieden werden. Durch die Kombination dieser beiden Mechanismen ist Rust in der Lage, Folgendes bereitzustellen
