
 Technologie-Peripheriegeräte
KI
Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Technologie-Peripheriegeräte
KI
Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung

0. Geschrieben im Vordergrund und persönlichem Verständnis
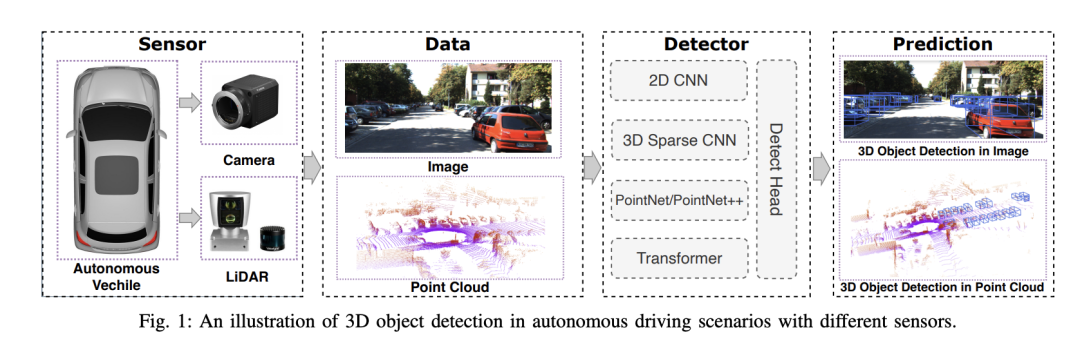
Autonomes Fahrsystem basiert auf fortschrittlicher Wahrnehmungs-, Entscheidungs- und Steuerungstechnologie, um die Umgebung durch den Einsatz verschiedener Sensoren (wie Kameras, Lidar, Radar usw.) wahrzunehmen .) und nutzen Algorithmen und Modelle für Echtzeitanalysen und Entscheidungsfindung. Dies ermöglicht es Fahrzeugen, Verkehrszeichen zu erkennen, andere Fahrzeuge zu erkennen und zu verfolgen, das Verhalten von Fußgängern vorherzusagen usw. und sich so sicher an komplexe Verkehrsumgebungen anzupassen. Diese Technologie erregt derzeit große Aufmerksamkeit und gilt als wichtiger Entwicklungsbereich für die Zukunft des Transportwesens . eins. Aber was autonomes Fahren schwierig macht, ist herauszufinden, wie man dem Auto klarmachen kann, was um es herum passiert. Dies erfordert 3D-Objekterkennungsalgorithmen in autonomen Fahrsystemen, die Objekte in der Umgebung genau wahrnehmen und beschreiben können, einschließlich ihrer Position, Form, Größe und Kategorie. Dieses umfassende Umweltbewusstsein hilft autonomen Fahrsystemen, die Fahrumgebung besser zu verstehen und präzisere Entscheidungen zu treffen.
Wir haben eine umfassende Bewertung von 3D-Objekterkennungsalgorithmen beim autonomen Fahren durchgeführt, wobei wir vor allem die Robustheit berücksichtigten. Bei der Bewertung wurden drei Schlüsselfaktoren identifiziert: Umgebungsvariabilität, Sensorrauschen und Fehlausrichtung. Diese Faktoren sind wichtig für die Leistung von Erkennungsalgorithmen unter realen, variablen Bedingungen.
- Umgebungsvariabilität: Der Artikel betont, dass sich der Erkennungsalgorithmus an unterschiedliche Umgebungsbedingungen anpassen muss, wie z. B. Änderungen der Beleuchtung, des Wetters und der Jahreszeiten.
- Sensorrauschen: Der Algorithmus muss effektiv mit Sensorrauschen umgehen, zu dem auch Probleme wie Bewegungsunschärfe der Kamera gehören können.
- Fehlausrichtung: Bei Fehlausrichtungen, die durch Kalibrierungsfehler oder andere Faktoren verursacht werden, muss der Algorithmus diese Faktoren berücksichtigen, unabhängig davon, ob sie extern (z. B. unebene Straßenoberflächen) oder intern (z. B. eine Fehlausrichtung der Systemuhr) sind.
Befasst sich außerdem mit drei Schlüsselbereichen der Leistungsbewertung: Genauigkeit, Latenz und Robustheit.
- Genauigkeit: Während sich Studien häufig auf die Genauigkeit als wichtige Leistungsmetrik konzentrieren, erfordert die Leistung unter komplexen und extremen Bedingungen ein tieferes Verständnis, um die Zuverlässigkeit in der Praxis sicherzustellen.
- Latenz: Echtzeitfähigkeiten beim autonomen Fahren sind entscheidend. Verzögerungen bei den Erkennungsmethoden beeinträchtigen die Fähigkeit des Systems, rechtzeitig Entscheidungen zu treffen, insbesondere in Notfallsituationen.
- Robustheit: Erfordert eine umfassendere Bewertung der Stabilität von Systemen unter verschiedenen Bedingungen, da viele aktuelle Bewertungen die Vielfalt realer Szenarien möglicherweise nicht vollständig berücksichtigen.
Das Papier weist auf die erheblichen Vorteile multimodaler 3D-Erkennungsmethoden bei der Sicherheitswahrnehmung hin. Durch die Zusammenführung von Daten verschiedener Sensoren werden umfassendere und vielfältigere Wahrnehmungsfähigkeiten bereitgestellt, wodurch die Sicherheit autonomer Fahrsysteme verbessert wird.
1. Datensatz
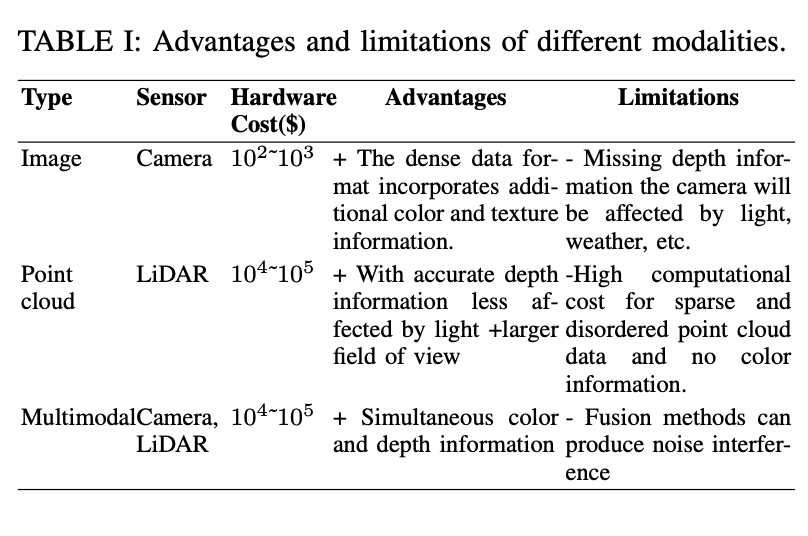
Oben wird der in autonomen Fahrsystemen verwendete 3D-Objekterkennungsdatensatz kurz vorgestellt, wobei der Schwerpunkt hauptsächlich auf der Bewertung der Vorteile und Einschränkungen verschiedener Sensormodi sowie der Eigenschaften öffentlicher Datensätze liegt .
Zunächst werden in der Tabelle drei Arten von Sensoren angezeigt: Kamera, Punktwolke und multimodal (Kamera und Lidar). Für jeden Typ werden die Hardwarekosten, Vorteile und Einschränkungen aufgeführt. Der Vorteil von Kameradaten besteht darin, dass sie reichhaltige Farb- und Texturinformationen liefern. Ihre Einschränkungen liegen jedoch im Mangel an Tiefeninformationen und in ihrer Anfälligkeit gegenüber Licht- und Wettereffekten. LiDAR kann genaue Tiefeninformationen liefern, ist jedoch teuer und verfügt über keine Farbinformationen.
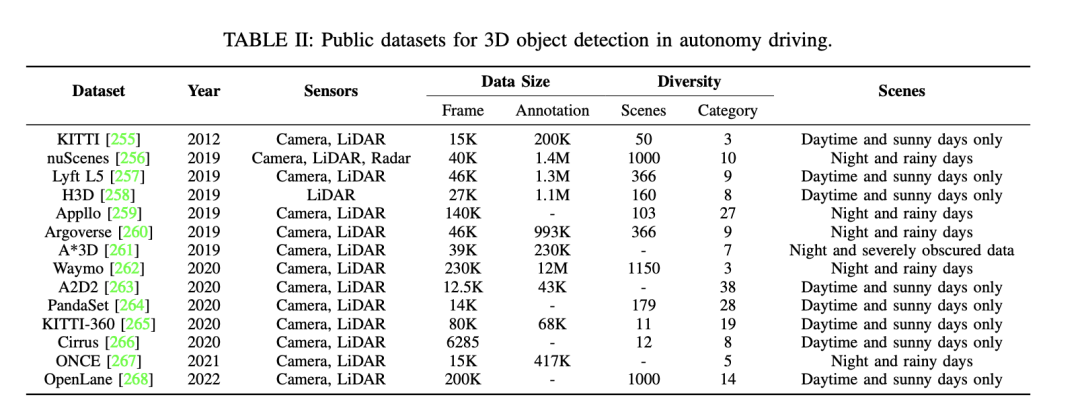
Als nächstes stehen einige weitere öffentliche Datensätze für die 3D-Objekterkennung beim autonomen Fahren zur Verfügung. Zu diesen Datensätzen gehören KITTI, nuScenes, Waymo usw. Einzelheiten zu diesen Datensätzen sind wie folgt: – Der KITTI-Datensatz enthält Daten, die über mehrere Jahre hinweg unter Verwendung verschiedener Sensortypen veröffentlicht wurden. Es bietet eine große Anzahl von Bildern und Anmerkungen sowie eine Vielzahl von Szenen, einschließlich Szenennummern und -kategorien sowie verschiedener Szenentypen wie Tag, sonnig, Nacht, regnerisch usw. – Der nuScenes-Datensatz ist ebenfalls ein wichtiger Datensatz, der auch Daten enthält, die über mehrere Jahre hinweg veröffentlicht wurden. Dieser Datensatz nutzt eine Vielzahl von Sensoren und bietet eine große Anzahl an Frames und Anmerkungen. Es deckt eine Vielzahl von Szenarien ab, darunter unterschiedliche Szenennummern und -kategorien sowie verschiedene Szenentypen. – Der Waymo-Datensatz ist ein weiterer Datensatz für autonomes Fahren, der ebenfalls Daten aus mehreren Jahren enthält. Dieser Datensatz nutzt verschiedene Arten von Sensoren und bietet eine große Anzahl an Frames und Anmerkungen. Es deckt verschiedene Bereiche ab
Darüber hinaus wird die Forschung zu „sauberen“ Datensätzen zum autonomen Fahren erwähnt und die Bedeutung der Bewertung der Modellrobustheit unter lauten Szenarien hervorgehoben. Einige Studien konzentrieren sich auf Kamera-Single-Modality-Methoden unter rauen Bedingungen, während andere multimodale Datensätze sich auf Lärmprobleme konzentrieren. Der GROUNDED-Datensatz konzentriert sich beispielsweise auf die Positionierung von Bodenradaren unter verschiedenen Wetterbedingungen, während der offene ApolloScape-Datensatz Lidar-, Kamera- und GPS-Daten umfasst, die eine Vielzahl von Wetter- und Lichtbedingungen abdecken.
Aufgrund der unerschwinglichen Kosten für die Erfassung umfangreicher verrauschter Daten in der realen Welt greifen viele Studien auf die Verwendung synthetischer Datensätze zurück. ImageNet-C ist beispielsweise eine Benchmark-Studie gegen häufige Störungen in Bildklassifizierungsmodellen. Diese Forschungsrichtung wurde anschließend auf robuste Datensätze ausgeweitet, die auf die 3D-Objekterkennung beim autonomen Fahren zugeschnitten sind. 2. Visionbasierte 3D-Objekterkennung 3D-Objekterkennung, monokulare 3D-Objekterkennung nur mit Kamera und tiefenunterstützte monokulare 3D-Objekterkennung.
Vorab gesteuerte monokulare 3D-Objekterkennung
Diese Methode nutzt Vorkenntnisse über in Bildern verborgene Objektformen und Szenengeometrie, um die Herausforderung der monokularen 3D-Objekterkennung zu lösen. Durch die Einführung vorab trainierter Teilnetze oder Hilfsaufgaben können Vorkenntnisse zusätzliche Informationen oder Einschränkungen liefern, um die genaue Lokalisierung von 3D-Objekten zu unterstützen und die Genauigkeit und Robustheit der Erkennung zu verbessern. Zu den allgemeinen Vorkenntnissen gehören Objektform, geometrische Konsistenz, zeitliche Einschränkungen und Segmentierungsinformationen. Beispielsweise geht der Mono3D-Algorithmus zunächst davon aus, dass das 3D-Objekt auf einer festen Grundebene liegt, und verwendet dann die vorherige 3D-Form des Objekts, um den Begrenzungsrahmen im 3D-Raum zu rekonstruieren. 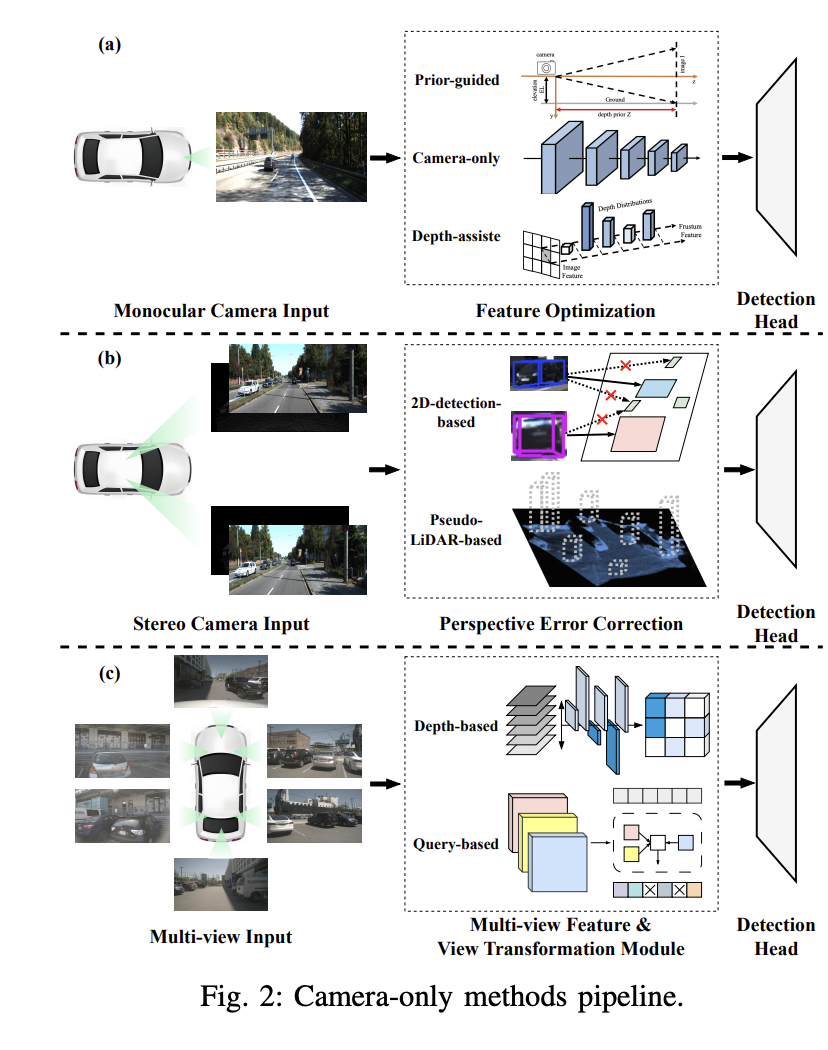
Monokulare 3D-Objekterkennung nur mit Kamera
Diese Methode verwendet nur Bilder, die von einer einzelnen Kamera aufgenommen wurden, um 3D-Objekte zu erkennen und zu lokalisieren. Es nutzt ein Faltungs-Neuronales Netzwerk (CNN), um 3D-Bounding-Box-Parameter direkt aus Bildern zu regressieren und so die Größe und Lage von Objekten im dreidimensionalen Raum abzuschätzen. Diese direkte Regressionsmethode kann durchgängig trainiert werden und fördert so das allgemeine Lernen und die Schlussfolgerung von 3D-Objekten. Beispielsweise verzichtet der Smoke-Algorithmus auf die Regression von 2D-Begrenzungsrahmen und sagt den 3D-Rahmen jedes erkannten Objekts voraus, indem er die Schätzung einzelner Schlüsselpunkte und die Regression von 3D-Variablen kombiniert.
Tiefenunterstützte monokulare 3D-ObjekterkennungDie Tiefenschätzung spielt eine Schlüsselrolle bei der tiefenunterstützten monokularen 3D-Objekterkennung. Um genauere monokulare Erkennungsergebnisse zu erzielen, nutzen viele Studien vorab trainierte zusätzliche Netzwerke zur Tiefenschätzung. Dieser Prozess beginnt mit der Umwandlung des monokularen Bildes in ein Tiefenbild mithilfe eines vorab trainierten Tiefenschätzers wie MonoDepth. Anschließend werden zwei Hauptmethoden zur Verarbeitung von Tiefenbildern und monokularen Bildern angewendet. Beispielsweise verwendet der Pseudo-LiDAR-Detektor ein vorab trainiertes Tiefenschätzungsnetzwerk, um Pseudo-LiDAR-Darstellungen zu generieren. Aufgrund von Fehlern bei der Bild-zu-LiDAR-Erzeugung besteht jedoch eine große Leistungslücke zwischen Pseudo-LiDAR und LiDAR-basierten Detektoren. 
Durch die Erforschung und Anwendung dieser Methoden hat die monokulare 3D-Objekterkennung in den Bereichen Computer Vision und intelligente Systeme erhebliche Fortschritte gemacht und Durchbrüche und Chancen in diese Bereiche gebracht.
2.2 Stereobasierte 3D-ObjekterkennungIn diesem Teil wird die 3D-Objekterkennungstechnologie auf Basis von Stereovision besprochen. Die stereoskopische 3D-Objekterkennung nutzt ein Paar stereoskopischer Bilder, um 3D-Objekte zu identifizieren und zu lokalisieren. Durch die Nutzung von Doppelansichten, die von Stereokameras erfasst werden, zeichnen sich diese Methoden dadurch aus, dass sie durch Stereoabgleich und Kalibrierung hochpräzise Tiefeninformationen erhalten, was sie von monokularen Kameraaufbauten unterscheidet. Trotz dieser Vorteile weisen Stereo-Vision-Methoden im Vergleich zu Lidar-basierten Methoden immer noch einen erheblichen Leistungsunterschied auf. Darüber hinaus ist der Bereich der 3D-Objekterkennung anhand von Stereobildern relativ wenig erforscht und es gibt nur begrenzte Forschungsanstrengungen in diesem Bereich.
- Auf 2D-Erkennung basierende Methoden: Das herkömmliche 2D-Objekterkennungs-Framework kann geändert werden, um das Stereoerkennungsproblem zu lösen. Stereo R-CNN verwendet beispielsweise einen bildbasierten 2D-Detektor, um 2D-Vorschläge vorherzusagen und linke und rechte Regions of Interest (RoIs) für die entsprechenden linken und rechten Bilder zu generieren. Anschließend schätzt es im zweiten Schritt direkt die 3D-Objektparameter auf Basis der zuvor generierten RoIs. Dieses Paradigma wurde in späteren Arbeiten weitgehend übernommen.
- Pseudo-LiDAR-basierte Methoden: Die aus dem Stereobild vorhergesagte Disparitätskarte kann in eine Tiefenkarte umgewandelt und weiter in Pseudo-LiDAR-Punkte umgewandelt werden. Daher kann die Pseudo-Lidar-Darstellung, ähnlich wie bei monokularen Erkennungsverfahren, auch in auf Stereovision basierenden 3D-Objekterkennungsverfahren verwendet werden. Diese Methoden zielen darauf ab, die Disparitätsschätzung beim Stereo-Matching zu verbessern, um eine genauere Tiefenvorhersage zu erreichen. Beispielsweise waren Wang et al. Pioniere bei der Einführung der Pseudo-Lidar-Darstellung. Diese Darstellung wird aus einem Bild mit einer Tiefenkarte generiert, sodass das Modell Tiefenschätzungsaufgaben ausführen muss, um die Erkennung zu unterstützen. Nachfolgende Arbeiten folgten diesem Paradigma und verfeinerten es durch die Einführung zusätzlicher Farbinformationen zur Verbesserung von Pseudopunktwolken, Hilfsaufgaben (wie Instanzsegmentierung, Vordergrund- und Hintergrundsegmentierung, Domänenanpassung) und Koordinatentransformationsschemata. Es ist erwähnenswert, dass das von Ma et al. vorgeschlagene PatchNet das traditionelle Konzept der Verwendung einer Pseudo-Lidar-Darstellung zur monokularen 3D-Objekterkennung in Frage stellt. Durch die Kodierung der 3D-Koordinaten für jedes Pixel kann PatchNet vergleichbare monokulare Erkennungsergebnisse ohne Pseudo-Lidar-Darstellung erzielen. Diese Beobachtung legt nahe, dass die Leistungsfähigkeit der Pseudo-Lidar-Darstellung eher auf der Koordinatentransformation als auf der Punktwolkendarstellung selbst beruht. 2.3 Multi-View-3D-Objekterkennung Im Gegensatz zur LiDAR-basierten 3D-Objekterkennung macht die neueste Panorama-Bird's-Eye-View-Methode (BEV) hochpräzise Karten überflüssig und verbessert die Erkennung von 2D auf 3D. Dieser Fortschritt hat zu bedeutenden Entwicklungen bei der 3D-Objekterkennung mit mehreren Ansichten geführt. Bei der 3D-Objekterkennung mit mehreren Kameras besteht die größte Herausforderung darin, dasselbe Objekt in verschiedenen Bildern zu identifizieren und Körpermerkmale aus mehreren Blickwinkeleingaben zu aggregieren. Aktuelle Methoden beinhalten die einheitliche Abbildung mehrerer Ansichten im BEV-Raum (Bird's Eye View), was eine gängige Praxis ist.
Tiefenbasierte Multi-View-Methoden: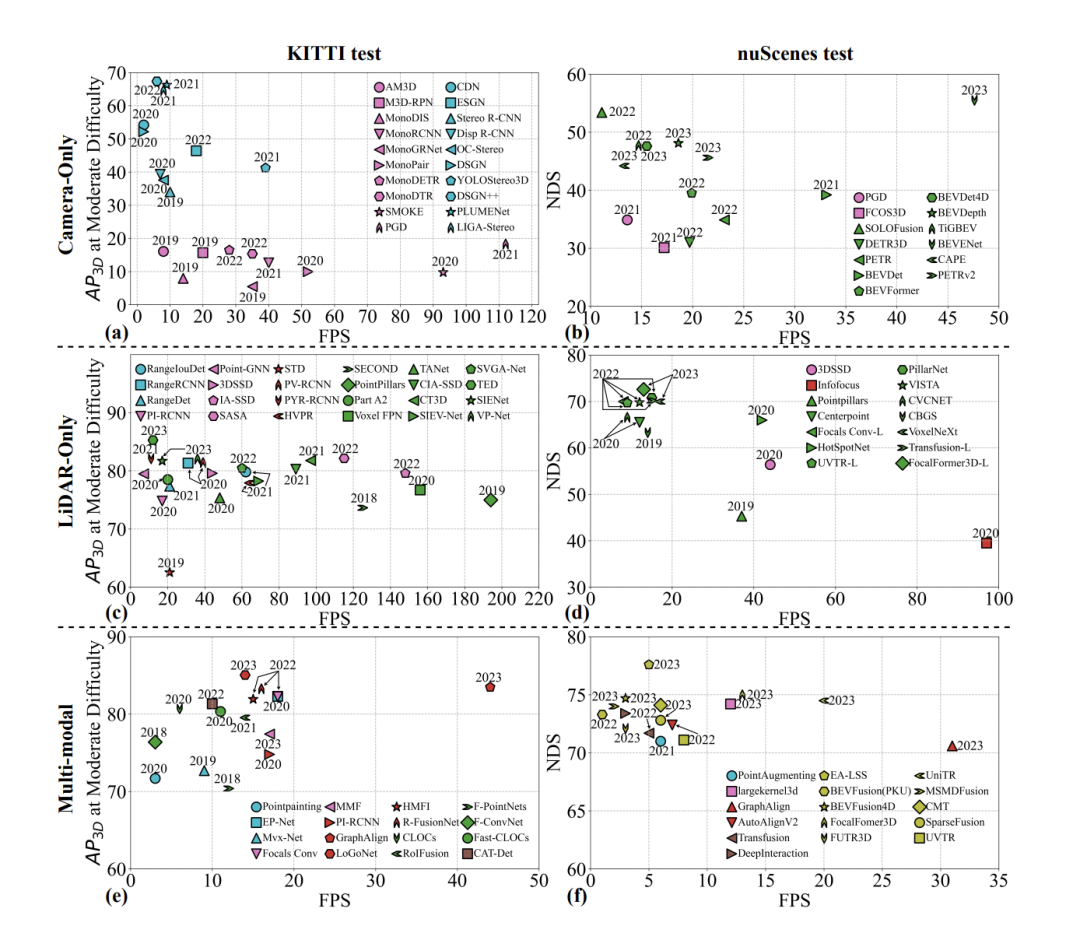
Die direkte Konvertierung vom 2D- in den BEV-Raum stellt eine erhebliche Herausforderung dar. LSS ist der erste, der eine tiefenbasierte Methode vorschlägt, die den 3D-Raum als Vermittler nutzt. Diese Methode sagt zunächst die Gittertiefenverteilung von 2D-Features voraus und hebt diese Features dann in den Voxelraum. Dieser Ansatz bietet Hoffnung auf eine effizientere Transformation vom 2D- zum BEV-Raum. Nach LSS verwendet CaDDN eine ähnliche Tiefendarstellungsmethode. Durch die Komprimierung von Voxelraummerkmalen in den BEV-Raum wird die endgültige 3D-Erkennung durchgeführt. Es ist erwähnenswert, dass CaDDN nicht Teil der 3D-Objekterkennung mit mehreren Ansichten ist, sondern der 3D-Objekterkennung mit einer einzigen Ansicht, was sich auf die spätere eingehende Forschung ausgewirkt hat. Der Hauptunterschied zwischen LSS und CaDDN besteht darin, dass CaDDN tatsächliche Ground-Truth-Tiefenwerte verwendet, um die Vorhersage seiner Klassifizierungstiefenverteilung zu überwachen und so ein überlegenes tiefes Netzwerk zu schaffen, das 3D-Informationen genauer aus dem 2D-Raum extrahieren kann.
Abfragebasierte Multi-View-MethodenUnter dem Einfluss der Transformer-Technologie rufen abfragebasierte Multi-View-Methoden 2D-Raummerkmale aus dem 3D-Raum ab. DETR3D führt eine 3D-Objektabfrage ein, um das Aggregationsproblem von Multi-View-Features zu lösen. Es erhält Bildmerkmale im BEV-Raum (Bird's Eye View), indem Bildmerkmale aus verschiedenen Blickwinkeln ausgeschnitten und mithilfe erlernter 3D-Referenzpunkte in den 2D-Raum projiziert werden. Im Gegensatz zur tiefenbasierten Multi-View-Methode werden bei der abfragebasierten Multi-View-Methode spärliche BEV-Funktionen mithilfe der Reverse-Query-Technologie erzielt, was sich grundlegend auf die nachfolgende abfragebasierte Entwicklung auswirkt. Aufgrund möglicher Ungenauigkeiten im Zusammenhang mit expliziten 3D-Referenzpunkten übernahm PETR jedoch eine implizite Positionskodierungsmethode zur Konstruktion des BEV-Raums, was sich auf die nachfolgende Arbeit auswirkte.
2.4 Analyse: Genauigkeit, Latenz, RobustheitDerzeit entwickeln sich 3D-Objekterkennungslösungen basierend auf der Wahrnehmung aus der Vogelperspektive (BEV) rasant. Trotz der Existenz zahlreicher Übersichtsartikel ist eine umfassende Übersicht über dieses Gebiet immer noch unzureichend. Das Shanghai AI Lab und das SenseTime Research Institute bieten einen detaillierten Überblick über die Technologie-Roadmap für BEV-Lösungen. Im Gegensatz zu bestehenden Bewertungen berücksichtigen wir jedoch wichtige Aspekte wie die Sicherheitswahrnehmung beim autonomen Fahren. Nach der Analyse der Technologie-Roadmap und des aktuellen Entwicklungsstands kamerabasierter Lösungen wollen wir auf Basis der Grundprinzipien „Genauigkeit, Latenz, Robustheit“ diskutieren. Wir werden die Perspektive des Sicherheitsbewusstseins integrieren, um die praktische Umsetzung des Sicherheitsbewusstseins beim autonomen Fahren zu steuern.
- Genauigkeit: In den meisten Forschungsartikeln und Rezensionen wird großer Wert auf Genauigkeit gelegt, und das ist wirklich wichtig. Obwohl die Genauigkeit durch AP (durchschnittliche Präzision) widergespiegelt werden kann, bietet die Betrachtung von AP allein möglicherweise keine umfassende Perspektive, da verschiedene Methoden aufgrund unterschiedlicher Paradigmen erhebliche Unterschiede aufweisen können. Wie in der Abbildung gezeigt, haben wir 10 repräsentative Methoden zum Vergleich ausgewählt. Die Ergebnisse zeigen, dass es erhebliche metrische Unterschiede zwischen der monokularen 3D-Objekterkennung und der stereoskopischen 3D-Objekterkennung gibt. Die aktuelle Situation zeigt, dass die Genauigkeit der monokularen 3D-Objekterkennung deutlich geringer ist als die der stereoskopischen 3D-Objekterkennung. Die Stereovision-3D-Objekterkennung nutzt Bilder, die aus zwei verschiedenen Perspektiven derselben Szene aufgenommen wurden, um Tiefeninformationen zu erhalten. Je größer die Basislinie zwischen den Kameras ist, desto größer ist der Bereich der erfassten Tiefeninformationen. Im Laufe der Zeit ersetzte die Multi-View-3D-Objekterkennung (Wahrnehmung aus der Vogelperspektive) nach und nach monokulare Methoden und verbesserte mAP erheblich. Die Erhöhung der Anzahl der Sensoren hat erhebliche Auswirkungen auf mAP.
- Latenz: Im Bereich des autonomen Fahrens ist die Latenz entscheidend. Es bezieht sich auf die Zeit, die ein System benötigt, um auf ein Eingangssignal zu reagieren, einschließlich des gesamten Prozesses von der Sensordatenerfassung bis zur Systementscheidung und der Ausführung von Aktionen. Beim autonomen Fahren sind die Latenzanforderungen sehr streng, da jede Form der Verzögerung schwerwiegende Folgen haben kann. Die Bedeutung der Latenz beim autonomen Fahren spiegelt sich in folgenden Aspekten wider: Echtzeit-Reaktionsfähigkeit, Sicherheit, Benutzererfahrung, Interaktivität und Notfallreaktion. Im Bereich der 3D-Objekterkennung sind Latenz (Bilder pro Sekunde, FPS) und Genauigkeit wichtige Indikatoren zur Bewertung der Algorithmusleistung. Wie in der Abbildung dargestellt, zeigt das Diagramm der monokularen und stereoskopischen 3D-Objekterkennung die durchschnittliche Genauigkeit (AP) im Vergleich zu FPS für gleiche Schwierigkeitsgrade im KITTI-Datensatz. Für die Umsetzung des autonomen Fahrens müssen 3D-Objekterkennungsalgorithmen ein Gleichgewicht zwischen Latenz und Genauigkeit finden. Während die monokulare Erkennung zwar schnell ist, mangelt es ihr an Genauigkeit; umgekehrt sind Stereo- und Multiview-Methoden zwar genau, aber langsamer. Zukünftige Forschungen sollten nicht nur eine hohe Genauigkeit aufrechterhalten, sondern auch mehr Aufmerksamkeit auf die Verbesserung der FPS und die Reduzierung der Latenz richten, um den doppelten Anforderungen von Echtzeit-Reaktionsfähigkeit und Sicherheit beim autonomen Fahren gerecht zu werden.
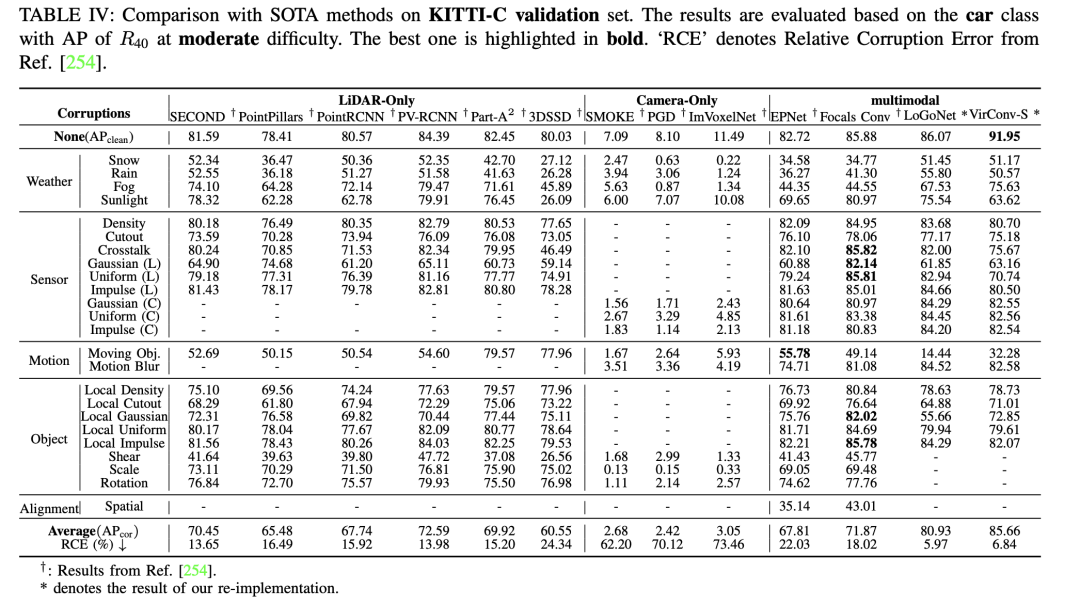
- Robustheit: Robustheit ist ein Schlüsselfaktor für die Wahrnehmung der Sicherheit beim autonomen Fahren und stellt ein wichtiges Thema dar, das in umfassenden Rezensionen bisher übersehen wurde. Dieser Aspekt wird in aktuellen, gut gestalteten sauberen Datensätzen und Benchmarks wie KITTI, nuScenes und Waymo oft nicht berücksichtigt. Derzeit beziehen Forschungsarbeiten wie RoboBEV und Robo3D Robustheitsüberlegungen in die 3D-Objekterkennung ein, wie z. B. Sensorverlust und andere Faktoren. Sie verwenden eine Methodik, bei der Störungen in Datensätze im Zusammenhang mit der 3D-Objekterkennung eingeführt werden, um die Robustheit zu bewerten. Dazu gehört die Einbringung verschiedener Arten von Geräuschen, wie z. B. Änderungen der Wetterbedingungen, Sensorausfälle, Bewegungsstörungen und objektbedingte Störungen, mit dem Ziel, die unterschiedlichen Auswirkungen verschiedener Geräuschquellen auf das Modell aufzuzeigen. Typischerweise werden die meisten Arbeiten zur Robustheit bewertet, indem Rauschen in den Validierungssatz sauberer Datensätze (wie KITTI, nuScenes und Waymo) eingeführt wird. Darüber hinaus heben wir die Ergebnisse in Ref. hervor, die KITTI-C und nuScenes-C als Beispiele für reine Kamera-3D-Objekterkennungsmethoden hervorheben. Die Tabelle bietet einen Gesamtvergleich, aus dem hervorgeht, dass der Nur-Kamera-Ansatz insgesamt weniger robust ist als der Nur-Lidar-Ansatz und der Multimodell-Fusion-Ansatz. Sie sind sehr anfällig für verschiedene Arten von Lärm. In KITTI-C zeigen drei repräsentative Werke – SMOKE, PGD und ImVoxelNet – eine durchweg geringere Gesamtleistung und eine verringerte Robustheit gegenüber Rauschen. In nuScenes-C zeigen bemerkenswerte Methoden wie DETR3D und BEVFormer eine größere Robustheit im Vergleich zu FCOS3D und PGD, was darauf hindeutet, dass die Gesamtrobustheit mit zunehmender Anzahl der Sensoren zunimmt. Zusammenfassend lässt sich sagen, dass zukünftige reine Kameraansätze nicht nur Kostenfaktoren und Genauigkeitsmetriken (mAP, NDS usw.) berücksichtigen müssen, sondern auch Faktoren im Zusammenhang mit der Sicherheitswahrnehmung und Robustheit. Ziel unserer Analyse ist es, wertvolle Erkenntnisse zur Sicherheit zukünftiger autonomer Fahrsysteme zu liefern.
3. Lidar-basierte 3D-Objekterkennung

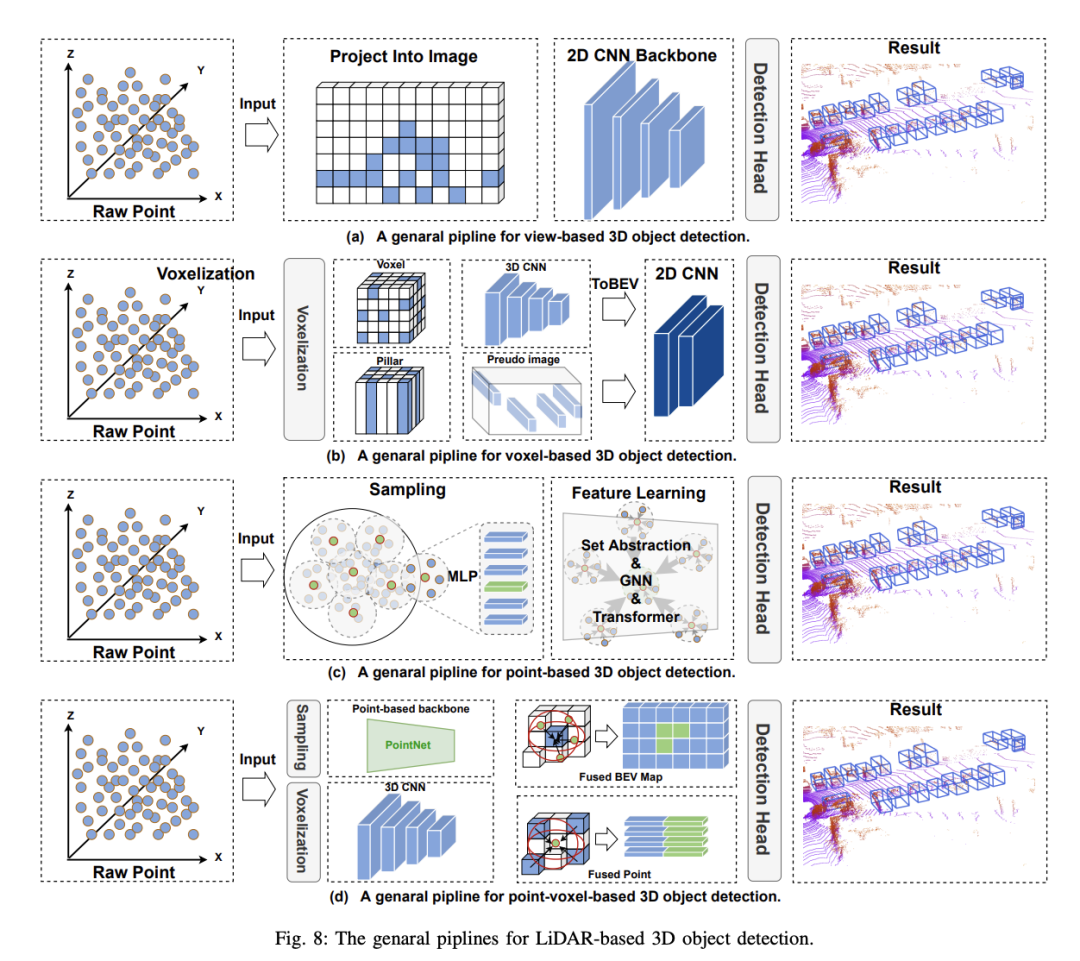
Die voxelbasierte 3D-Objekterkennungsmethode schlägt vor, spärliche Punktwolken zu segmentieren und in regelmäßige Voxel zu verteilen, um eine dichte Datendarstellung zu bilden. Im Vergleich zu ansichtsbasierten Methoden nutzen voxelbasierte Methoden räumliche Faltung, um 3D-Rauminformationen effektiv wahrzunehmen und eine höhere Erkennungsgenauigkeit zu erreichen, was für die Sicherheitswahrnehmung beim autonomen Fahren von entscheidender Bedeutung ist. Allerdings stehen diese Methoden noch vor folgenden Herausforderungen:
-
Hohe Rechenkomplexität: Im Vergleich zu kamerabasierten Methoden erfordern voxelbasierte Methoden aufgrund der großen Anzahl von Voxeln, die zur Darstellung des 3D-Raums verwendet werden, erhebliche Speicher- und Rechenressourcen.
-
Räumlicher Informationsverlust: Aufgrund der Diskretisierungseigenschaften von Voxeln können Details und Forminformationen während des Voxelisierungsprozesses verloren gehen oder verschwimmen, während die begrenzte Auflösung von Voxeln die genaue Erkennung kleiner Objekte erschwert.
-
Skalen- und Dichteinkonsistenz: Voxelbasierte Methoden erfordern normalerweise eine Erkennung auf Voxelgittern mit unterschiedlichen Maßstäben und Dichten. Da jedoch Maßstab und Dichte von Zielen in verschiedenen Szenen stark variieren, ist es wichtig, den geeigneten Maßstab und die entsprechende Dichte auszuwählen Unterschiedliche Ziele unter einen Hut zu bringen, wird zur Herausforderung.
Um diese Herausforderungen zu meistern, ist es notwendig, die Einschränkungen der Datendarstellung zu überwinden, die Netzwerkfunktionsfähigkeiten und die Zielpositionierungsgenauigkeit zu verbessern und das Verständnis des Algorithmus für komplexe Szenen zu stärken. Obwohl Optimierungsstrategien unterschiedlich sind, zielen sie im Allgemeinen darauf ab, sowohl die Datendarstellung als auch die Modellstruktur zu optimieren.
3.1 Voxelbasierte 3D-Objekterkennung
Dank des Erfolgs von PC im Bereich Deep Learning übernimmt die punktbasierte 3D-Objekterkennung viele ihrer Frameworks und schlägt vor, 3D-Objekte ohne Vorverarbeitung direkt von Originalpunkten aus zu erkennen. Im Vergleich zu voxelbasierten Methoden behält die ursprüngliche Punktwolke die maximale Menge an Originalinformationen bei, was sich positiv auf die feinkörnige Merkmalserfassung auswirkt und zu einer hohen Genauigkeit führt. Gleichzeitig bietet eine Reihe von Arbeiten zu PointNet natürlich eine solide Grundlage für punktbasierte Methoden. Punktbasierte 3D-Objektdetektoren bestehen aus zwei Grundkomponenten: Punktwolken-Sampling und Feature-Learning. Derzeit wird die Leistung punktbasierter Methoden noch von zwei Faktoren beeinflusst: der Anzahl der Kontextpunkte und dem beim Feature-Lernen verwendeten Kontextradius. . Beispielsweise können durch Erhöhen der Anzahl der Kontextpunkte detailliertere 3D-Informationen erhalten werden, die Inferenzzeit des Modells wird jedoch erheblich verlängert. Ebenso kann die Reduzierung des Kontextradius den gleichen Effekt haben. Daher kann die Auswahl geeigneter Werte für diese beiden Faktoren es dem Modell ermöglichen, ein Gleichgewicht zwischen Genauigkeit und Geschwindigkeit zu erreichen. Da außerdem jeder Punkt in der Punktwolke berechnet werden muss, ist der Punktwolken-Sampling-Prozess der Hauptfaktor, der den Echtzeitbetrieb punktbasierter Methoden einschränkt. Um die oben genannten Probleme zu lösen, sind die meisten vorhandenen Methoden insbesondere auf die beiden Grundkomponenten punktbasierter 3D-Objektdetektoren optimiert: 1) Punktabtastung 2) Merkmalslernen
3.2 Punktbasierte 3D-Objekterkennung
Punktbasierte 3D-Objekterkennungsmethoden erben viele Deep-Learning-Frameworks und schlagen vor, 3D-Objekte ohne Vorverarbeitung direkt aus Rohpunktwolken zu erkennen. Im Vergleich zu voxelbasierten Methoden behält die ursprüngliche Punktwolke die ursprünglichen Informationen maximal bei, was der Erfassung feinkörniger Merkmale förderlich ist und dadurch eine hohe Genauigkeit erreicht. Gleichzeitig bietet die PointNet-Arbeitsreihe eine solide Grundlage für punktbasierte Methoden. Bisher wird die Leistung punktbasierter Methoden jedoch noch von zwei Faktoren beeinflusst: der Anzahl der Kontextpunkte und dem Kontextradius, der beim Feature-Learning verwendet wird. Wenn Sie beispielsweise die Anzahl der Kontextpunkte erhöhen, können detailliertere 3D-Informationen erhalten werden, die Inferenzzeit des Modells wird jedoch erheblich verlängert. Ebenso wird durch die Reduzierung des Kontextradius derselbe Effekt erzielt. Durch die Auswahl geeigneter Werte für diese beiden Faktoren kann das Modell daher ein Gleichgewicht zwischen Genauigkeit und Geschwindigkeit erreichen. Darüber hinaus ist der Punktwolken-Sampling-Prozess der Hauptfaktor, der den Echtzeitbetrieb punktbasierter Methoden einschränkt, da Berechnungen für jeden Punkt in der Punktwolke durchgeführt werden müssen. Um diese Probleme zu lösen, optimieren bestehende Methoden hauptsächlich um zwei grundlegende Komponenten punktbasierter 3D-Objektdetektoren: 1) Punktwolkenabtastung; 2) Merkmalslernen.
Farth Point Sampling (FPS) ist von PointNet++ abgeleitet und eine Punktwolken-Sampling-Methode, die häufig in punktbasierten Methoden verwendet wird. Sein Ziel besteht darin, einen repräsentativen Satz von Punkten aus der ursprünglichen Punktwolke auszuwählen, um den Abstand zwischen ihnen zu maximieren und so die räumliche Verteilung der gesamten Punktwolke bestmöglich abzudecken. PointRCNN ist ein bahnbrechender zweistufiger Detektor für punktbasierte Methoden, der PointNet++ als Backbone-Netzwerk verwendet. Im ersten Schritt werden 3D-Vorschläge aus Punktwolken von unten nach oben generiert. In der zweiten Stufe werden die Vorschläge durch die Kombination semantischer Merkmale und lokaler räumlicher Merkmale verfeinert. Bestehende FPS-basierte Methoden sind jedoch immer noch mit einigen Problemen konfrontiert: 1) Punkte, die nichts mit der Erkennung zu tun haben, sind ebenfalls am Abtastprozess beteiligt, was einen zusätzlichen Rechenaufwand mit sich bringt. 2) Punkte sind in verschiedenen Teilen des Objekts ungleichmäßig verteilt, was zu suboptimalen Abtaststrategien führt. Um diese Probleme anzugehen, übernahmen nachfolgende Arbeiten ein FPS-ähnliches Designparadigma und führten Verbesserungen durch, wie z. B. durch Segmentierung gesteuerte Hintergrundpunktfilterung, Zufallsstichprobe, Merkmalsraumstichprobe, Voxel-basierte Stichprobe und Strahlengruppierungs-basierte Stichprobe.
Die Feature-Lernphase punktbasierter 3D-Objekterkennungsmethoden zielt darauf ab, diskriminierende Feature-Darstellungen aus spärlichen Punktwolkendaten zu extrahieren. Das in der Feature-Lernphase verwendete neuronale Netzwerk sollte die folgenden Eigenschaften aufweisen: 1) Invarianz, das Punktwolken-Backbone-Netzwerk sollte unempfindlich gegenüber der Reihenfolge der Eingabepunktwolke sein. 2) Es verfügt über lokale Wahrnehmungsfähigkeiten und kann lokale Bereiche erfassen und modellieren und lokale Merkmale extrahieren; 3) Die Fähigkeit, Kontextinformationen zu integrieren und Merkmale aus globalen und lokalen Kontextinformationen zu extrahieren. Basierend auf den oben genannten Eigenschaften ist eine große Anzahl von Detektoren für die Verarbeitung roher Punktwolken ausgelegt. Die meisten Methoden können nach den verwendeten Kernoperatoren unterteilt werden: 1) PointNet-basierte Methoden; 2) Graph-Neuronale Netzwerk-basierte Methoden;
PointNet-basierte Methoden
PointNet-basierte Methoden basieren hauptsächlich auf der Mengenabstraktion, um die Originalpunkte herunterzurechnen, lokale Informationen zu aggregieren und Kontextinformationen zu integrieren und gleichzeitig die Symmetrieinvarianz der Originalpunkte beizubehalten. Point-RCNN ist die erste zweistufige Arbeit unter den punktbasierten Methoden und erzielt eine hervorragende Leistung, steht jedoch immer noch vor dem Problem hoher Rechenkosten. Nachfolgende Arbeiten lösten dieses Problem, indem sie eine zusätzliche semantische Segmentierungsaufgabe in den Erkennungsprozess einführten, um Hintergrundpunkte herauszufiltern, die nur minimal zur Erkennung beitragen.
Methoden, die auf graphischen neuronalen Netzen basieren
Graphische neuronale Netze (GNN) verfügen über adaptive Strukturen, dynamische Nachbarschaften, die Fähigkeit, lokale und globale Kontextbeziehungen aufzubauen, und sind robust gegenüber unregelmäßigen Stichproben. Point-GNN ist eine bahnbrechende Arbeit, die ein einstufiges graphisches neuronales Netzwerk entwirft, um die Kategorie und Form von Objekten durch automatische Registrierungsmechanismen, Zusammenführungs- und Bewertungsvorgänge vorherzusagen und die Verwendung graphischer neuronaler Netzwerke als neue Methode zur 3D-Objekterkennung demonstriert. Potenzial.
Transformer-basierte Methoden
In den letzten Jahren wurden Transformer (Transformer) in der Punktwolkenanalyse untersucht und haben bei vielen Aufgaben gute Leistungen erbracht. Pointformer führt beispielsweise lokale und globale Aufmerksamkeitsmodule ein, um 3D-Punktwolken zu verarbeiten, das lokale Transformer-Modul dient zur Modellierung von Interaktionen zwischen Punkten in lokalen Regionen und der globale Transformer zielt darauf ab, kontextsensitive Darstellungen auf Szenenebene zu erlernen. Group-free nutzt direkt alle Punkte in der Punktwolke, um die Merkmale jedes Objektkandidaten zu berechnen, wobei der Beitrag jedes Punkts durch ein automatisch erlerntes Aufmerksamkeitsmodul bestimmt wird. Diese Methoden demonstrieren das Potenzial transformatorbasierter Methoden bei der Verarbeitung unstrukturierter und ungeordneter Rohpunktwolken.
3.3 Punkt-Voxel-basierte 3D-Objekterkennung
Punktwolkenbasierte 3D-Objekterkennungsmethoden bieten eine hohe Auflösung und bewahren die räumliche Struktur der Originaldaten, sind jedoch bei der Verarbeitung spärlicher Daten mit hoher Rechenkomplexität und geringer Effizienz konfrontiert. Im Gegensatz dazu bieten voxelbasierte Methoden eine strukturierte Datendarstellung, verbessern die Recheneffizienz und erleichtern die Anwendung der traditionellen Faltungs-Neuronalen-Netzwerk-Technologie. Durch den Diskretisierungsprozess gehen jedoch häufig feine räumliche Details verloren. Um diese Probleme zu lösen, wurden Punkt-Voxel (PV)-basierte Methoden entwickelt. Punkt-Voxel-Methoden zielen darauf ab, die feinkörnigen Informationserfassungsfähigkeiten punktbasierter Methoden und die Recheneffizienz voxelbasierter Methoden zu nutzen. Durch die Integration dieser Methoden können Punkt-Voxel-basierte Methoden Punktwolkendaten detaillierter verarbeiten und globale Strukturen und mikrogeometrische Details erfassen. Dies ist für die Sicherheitswahrnehmung beim autonomen Fahren von entscheidender Bedeutung, da die Entscheidungsgenauigkeit des autonomen Fahrsystems von hochpräzisen Erkennungsergebnissen abhängt.
Das Hauptziel der Punkt-Voxel-Methode besteht darin, durch Punkt-zu-Voxel- oder Voxel-zu-Punkt-Konvertierung eine Merkmalsinteraktion zwischen Voxeln und Punkten zu erreichen. In vielen Arbeiten wurde die Idee untersucht, die Punkt-Voxel-Merkmalsfusion in Backbone-Netzwerken zu nutzen. Diese Methoden können in zwei Kategorien unterteilt werden: 1) frühe Fusion; 2) späte Fusion.
a) Frühe Fusion: Einige Methoden haben die Verwendung neuer Faltungsoperatoren zur Fusion von Voxel- und Punktmerkmalen untersucht, und PVCNN ist möglicherweise die erste Arbeit in dieser Richtung. Bei diesem Ansatz wandelt der voxelbasierte Zweig zunächst Punkte in ein Voxelgitter mit niedriger Auflösung um und aggregiert benachbarte Voxelmerkmale durch Faltung. Anschließend werden die Merkmale auf Voxelebene durch einen als Devoxelisierung bezeichneten Prozess wieder in Merkmale auf Punktebene umgewandelt und mit Merkmalen verschmolzen, die durch den punktbasierten Zweig erhalten wurden. Der punktbasierte Zweig extrahiert Features für jeden einzelnen Punkt. Da keine Nachbarinformationen aggregiert werden, kann diese Methode mit höheren Geschwindigkeiten ausgeführt werden. Anschließend wurde SPVCNN auf den Bereich der Objekterkennung basierend auf PVCNN ausgeweitet. Andere Methoden versuchen aus unterschiedlichen Perspektiven zu verbessern, etwa durch Hilfsaufgaben oder Multiskalen-Feature-Fusion.
b) Post-Fusion: Diese Methodenreihe verwendet hauptsächlich ein zweistufiges Erkennungsframework. Zunächst werden vorläufige Objektvorschläge mithilfe eines voxelbasierten Ansatzes generiert. Anschließend werden Merkmale auf Punktebene verwendet, um den Erkennungsrahmen genau zu unterteilen. Das von Shi et al. vorgeschlagene PV-RCNN ist ein Meilenstein in der Punkt-Voxel-basierten Methode. Es verwendet SECOND als Detektor der ersten Stufe und schlägt eine Verfeinerungsstufe der zweiten Stufe mit RoI-Grid-Pooling für die Fusion von Schlüsselpunktmerkmalen vor. Nachfolgende Arbeiten folgen hauptsächlich dem oben genannten Paradigma und konzentrieren sich auf den Fortschritt der Erkennung in der zweiten Stufe. Zu den bemerkenswerten Entwicklungen gehören Aufmerksamkeitsmechanismen, skalenbewusstes Pooling und punktdichtebewusste Verfeinerungsmodule.
Punktvoxelbasierte Methoden verfügen sowohl über die Recheneffizienz voxelbasierter Methoden als auch über die Fähigkeit punktbasierter Methoden, feinkörnige Informationen zu erfassen. Der Aufbau von Punkt-zu-Voxel- oder Voxel-zu-Punkt-Beziehungen sowie die Merkmalsfusion von Voxeln und Punkten bringen jedoch zusätzlichen Rechenaufwand mit sich. Daher können Punkt-Voxel-basierte Methoden im Vergleich zu Voxel-basierten Methoden eine bessere Erkennungsgenauigkeit erreichen, allerdings auf Kosten einer längeren Inferenzzeit. 4. Multimodale 3D-Objekterkennung und Bildfunktionen integrieren. Der Schlüssel liegt hier darin, sich auf die Projektion während der Feature-Fusion zu konzentrieren und nicht auf andere Projektionsprozesse in der Fusionsphase, wie z. B. Datenerweiterung usw. Abhängig von den verschiedenen Arten von Projektionen, die in der Fusionsphase verwendet werden, können projektionsbasierte 3D-Objekterkennungsmethoden weiter in die folgenden Kategorien unterteilt werden:
3D-Objekterkennung basierend auf Punktprojektion: Diese Art von Methode funktioniert durch die Projektion von Bildern Features auf die ursprüngliche Punktwolke werden verwendet, um die Darstellungsfähigkeit der ursprünglichen Punktwolkendaten zu verbessern. Der erste Schritt bei diesen Methoden besteht darin, mithilfe einer Kalibrierungsmatrix starke Korrelationen zwischen LIDAR-Punkten und Bildpixeln herzustellen. Anschließend werden die Punktwolkenfunktionen durch das Hinzufügen zusätzlicher Daten erweitert. Diese Verbesserung gibt es in zwei Formen: zum einen durch Zusammenführen von Segmentierungswerten (wie PointPainting) und zum anderen durch die Verwendung von CNN-Funktionen relevanter Pixel (wie MVP). PointPainting verbessert LIDAR-Punkte durch Anhängen von Segmentierungswerten, weist jedoch Einschränkungen bei der effektiven Erfassung von Farb- und Texturdetails in Bildern auf. Um diese Probleme zu lösen, wurden ausgefeiltere Methoden wie FusionPainting entwickelt.
3D-Objekterkennung basierend auf Merkmalsprojektion: Im Gegensatz zu Methoden, die auf Punktprojektion basieren, konzentriert sich diese Art von Methode hauptsächlich auf die Fusion von Punktwolkenmerkmalen mit Bildmerkmalen in der Phase der Punktwolkenmerkmalsextraktion. In diesem Prozess werden Punktwolke und Bildmodalitäten effektiv verschmolzen, indem eine Kalibrierungsmatrix angewendet wird, um das 3D-Koordinatensystem von Voxeln in das Pixelkoordinatensystem des Bildes umzuwandeln. Beispielsweise führt ContFuse Faltungs-Feature-Maps mit mehreren Maßstäben durch kontinuierliche Faltung zusammen.
Automatische projektionsbasierte 3D-Objekterkennung: Viele Studien führen die Fusion durch direkte Projektion durch, lösen jedoch nicht das Problem des Projektionsfehlers. Einige Werke (z. B. AutoAlignV2) mildern diese Fehler, indem sie Offsets und Nachbarschaftsprojektionen usw. lernen. Beispielsweise nutzen HMFI, GraphAlign und GraphAlign++ Vorkenntnisse der Projektionskalibrierungsmatrix für die Bildprojektion und die lokale Graphenmodellierung.
Entscheidungsprojektionsbasierte 3D-Objekterkennung: Diese Art von Methode verwendet eine Projektionsmatrix, um Merkmale in einer Region of Interest (RoI) oder einem bestimmten Ergebnis auszurichten. Graph-RCNN projiziert beispielsweise Diagrammknoten auf Positionen in einem Kamerabild und sammelt Merkmalsvektoren für dieses Pixel im Kamerabild durch bilineare Interpolation. F-PointNet bestimmt die Kategorie und Positionierung von Objekten durch 2D-Bilderkennung und erhält Punktwolken im entsprechenden 3D-Raum durch kalibrierte Sensorparameter und Transformationsmatrizen im 3D-Raum. -
Diese Methoden zeigen, wie mithilfe der Projektionstechnologie eine Merkmalsfusion bei der multimodalen 3D-Objekterkennung erreicht werden kann. Sie weisen jedoch immer noch gewisse Einschränkungen bei der Handhabung der Interaktion zwischen verschiedenen Modalitäten und der Genauigkeit auf.
- 4.2 Nicht projektionsbasierte 3D-Objekterkennung
-
Die nicht projektionsbasierte 3D-Objekterkennungsmethode erreicht eine Fusion, indem sie nicht auf Feature-Ausrichtung angewiesen ist, was zu einer robusten Feature-Darstellung führt. Sie umgehen die Einschränkungen der Kamera-zu-Lidar-Projektion, die häufig die semantische Dichte von Kamerafunktionen verringert und die Wirksamkeit von Techniken wie Focals Conv und PointPainting beeinträchtigt. Nicht-projektive Methoden verwenden normalerweise einen Kreuzaufmerksamkeitsmechanismus oder konstruieren einen einheitlichen Raum, um das inhärente Fehlausrichtungsproblem bei der direkten Merkmalsprojektion zu lösen. Diese Methoden sind hauptsächlich in zwei Kategorien unterteilt: (1) auf Abfragelernen basierende Methoden und (2) einheitliche merkmalsbasierte Methoden. Auf Abfragelernen basierende Methoden machen eine Ausrichtung während des Fusionsprozesses vollständig überflüssig. Im Gegensatz dazu vermeiden vereinheitlichte merkmalsbasierte Methoden die Projektion, obwohl sie einen einheitlichen Merkmalsraum konstruieren, normalerweise in einem einzigen Modalitätskontext. BEVFusion nutzt beispielsweise LSS für die Kamera-zu-BEV-Projektion. Dieser Prozess findet vor der Fusion statt und zeigt eine beträchtliche Robustheit in Szenarien, in denen Features falsch ausgerichtet sind.
-
Dreidimensionale Objekterkennung basierend auf Abfragelernen: Dreidimensionale Objekterkennungsmethoden basierend auf Abfragelernen, wie Transfusion, DeepFusion, DeepInteraction, Autoalign, CAT-Det, MixedFusion usw., machen eine Projektion überflüssig der Feature-Fusion-Prozess. Stattdessen erreichen sie eine Merkmalsausrichtung, bevor sie eine Merkmalsfusion durch einen Kreuzaufmerksamkeitsmechanismus durchführen. Punktwolken-Features werden normalerweise als Abfragen verwendet, und Bild-Features werden als Schlüssel und Werte verwendet, die durch globale Feature-Abfragen erhalten werden. Darüber hinaus führt DeepInteraction eine multimodale Interaktion ein, bei der Punktwolken- und Bildmerkmale als unterschiedliche Abfragen verwendet werden, um eine weitere Merkmalsinteraktion zu erreichen. Die umfassende Integration von Bildmerkmalen führt zur Erfassung robusterer multimodaler Merkmale im Vergleich zur ausschließlichen Verwendung von Punktwolkenmerkmalen als Abfragen. Im Allgemeinen verwendet die auf Abfragelernen basierende dreidimensionale Objekterkennungsmethode eine transformatorbasierte Struktur, um Merkmalsabfragen durchzuführen und eine Merkmalsausrichtung zu erreichen. Schließlich wurden multimodale Funktionen in Lidar-basierte Prozesse wie CenterPoint integriert.
-
Dreidimensionale Objekterkennung basierend auf einheitlichen Merkmalen: Dreidimensionale Objekterkennungsmethoden basierend auf einheitlichen Merkmalen, wie EA-BEV, BEVFusion, cai2023bevfusion4d, FocalFormer3D, FUTR3D, UniTR, Uni3D, virconv, MSMDFusion, sfd, cmt , UVTR, Sparsefusion usw. , normalerweise wird die Vereinheitlichung heterogener Modalitäten vor der Fusion durch Projektion vor der Merkmalsfusion erreicht. In der BEV-Fusionsserie wird LSS zur Tiefenschätzung verwendet, die Vorderansichtsmerkmale werden in BEV-Merkmale umgewandelt und anschließend werden das BEV-Bild und die BEV-Punktwolkenmerkmale fusioniert. Andererseits verwenden CMT und UniTR Transformer zur Tokenisierung von Punktwolken und Bildern und erstellen durch Transformer-Codierung einen impliziten einheitlichen Raum. CMT verwendet Projektion im Positionskodierungsprozess, vermeidet jedoch vollständig die Abhängigkeit von Projektionsbeziehungen auf der Feature-Lernebene. FocalFormer3D, FUTR3D und UVTR verwenden die Abfrage von Transformer, um eine DETR3D-ähnliche Lösung zu implementieren und durch Abfrage einen einheitlichen spärlichen BEV-Feature-Raum zu erstellen, wodurch die durch die direkte Projektion verursachte Instabilität verringert wird.
VirConv, MSMDFusion und SFD bilden durch Pseudopunktwolken einen einheitlichen Raum, und die Projektion erfolgt vor dem Feature-Lernen. Die durch die direkte Projektion verursachten Probleme werden durch anschließendes Feature-Lernen gelöst. Zusammenfassend stellen einheitliche, merkmalsbasierte 3D-Objekterkennungsmethoden derzeit äußerst genaue und robuste Lösungen dar. Obwohl sie eine Projektionsmatrix enthalten, findet diese Projektion nicht zwischen multimodalen Fusionen statt und wird daher als nicht-projektive 3D-Objekterkennungsmethode betrachtet. Im Gegensatz zu automatischen Projektionsmethoden zur Erkennung von 3D-Objekten lösen sie das Problem des Projektionsfehlers nicht direkt, sondern erstellen einen einheitlichen Raum und berücksichtigen mehrere Dimensionen der multimodalen 3D-Objekterkennung, um äußerst robuste multimodale Merkmale zu erhalten.
5. Fazit
Die 3D-Objekterkennung spielt eine entscheidende Rolle bei der Wahrnehmung des autonomen Fahrens. In den letzten Jahren hat sich dieses Gebiet rasant entwickelt und eine große Anzahl von Forschungsarbeiten hervorgebracht. Basierend auf den vielfältigen Datenformen, die von Sensoren generiert werden, werden diese Methoden hauptsächlich in drei Typen unterteilt: bildbasiert, punktwolkenbasiert und multimodal. Die wichtigsten Bewertungsmaßstäbe dieser Methoden sind hohe Genauigkeit und geringe Latenz. Viele Rezensionen fassen diese Ansätze zusammen und konzentrieren sich dabei hauptsächlich auf die Kernprinzipien „hohe Genauigkeit und geringe Latenz“ und beschreiben ihre technische Entwicklung.
Im Zuge des Übergangs der autonomen Fahrtechnologie von Durchbrüchen zu praktischen Anwendungen legen die bestehenden Überprüfungen jedoch nicht den Schwerpunkt auf die Sicherheitswahrnehmung und decken nicht die aktuellen technischen Wege im Zusammenhang mit der Sicherheitswahrnehmung ab. Beispielsweise werden neuere multimodale Fusionsmethoden häufig während der experimentellen Phase auf ihre Robustheit getestet, ein Aspekt, der in der aktuellen Übersicht nicht vollständig berücksichtigt wurde.
Untersuchen Sie daher den 3D-Objekterkennungsalgorithmus erneut und konzentrieren Sie sich dabei auf „Genauigkeit, Latenz und Robustheit“ als Schlüsselaspekte. Wir klassifizieren frühere Bewertungen neu und legen dabei besonderen Wert auf die Neuklassifizierung aus Sicht der Sicherheitswahrnehmung. Es besteht die Hoffnung, dass diese Arbeit neue Einblicke in die zukünftige Forschung zur 3D-Objekterkennung liefern wird, die über die bloße Erforschung der Grenzen hoher Genauigkeit hinausgehen.
 : Im Gegensatz zu Methoden, die auf Punktprojektion basieren, konzentriert sich diese Art von Methode hauptsächlich auf die Fusion von Punktwolkenmerkmalen mit Bildmerkmalen in der Phase der Punktwolkenmerkmalsextraktion. In diesem Prozess werden Punktwolke und Bildmodalitäten effektiv verschmolzen, indem eine Kalibrierungsmatrix angewendet wird, um das 3D-Koordinatensystem von Voxeln in das Pixelkoordinatensystem des Bildes umzuwandeln. Beispielsweise führt ContFuse Faltungs-Feature-Maps mit mehreren Maßstäben durch kontinuierliche Faltung zusammen.
: Im Gegensatz zu Methoden, die auf Punktprojektion basieren, konzentriert sich diese Art von Methode hauptsächlich auf die Fusion von Punktwolkenmerkmalen mit Bildmerkmalen in der Phase der Punktwolkenmerkmalsextraktion. In diesem Prozess werden Punktwolke und Bildmodalitäten effektiv verschmolzen, indem eine Kalibrierungsmatrix angewendet wird, um das 3D-Koordinatensystem von Voxeln in das Pixelkoordinatensystem des Bildes umzuwandeln. Beispielsweise führt ContFuse Faltungs-Feature-Maps mit mehreren Maßstäben durch kontinuierliche Faltung zusammen. - Dreidimensionale Objekterkennung basierend auf Abfragelernen: Dreidimensionale Objekterkennungsmethoden basierend auf Abfragelernen, wie Transfusion, DeepFusion, DeepInteraction, Autoalign, CAT-Det, MixedFusion usw., machen eine Projektion überflüssig der Feature-Fusion-Prozess. Stattdessen erreichen sie eine Merkmalsausrichtung, bevor sie eine Merkmalsfusion durch einen Kreuzaufmerksamkeitsmechanismus durchführen. Punktwolken-Features werden normalerweise als Abfragen verwendet, und Bild-Features werden als Schlüssel und Werte verwendet, die durch globale Feature-Abfragen erhalten werden. Darüber hinaus führt DeepInteraction eine multimodale Interaktion ein, bei der Punktwolken- und Bildmerkmale als unterschiedliche Abfragen verwendet werden, um eine weitere Merkmalsinteraktion zu erreichen. Die umfassende Integration von Bildmerkmalen führt zur Erfassung robusterer multimodaler Merkmale im Vergleich zur ausschließlichen Verwendung von Punktwolkenmerkmalen als Abfragen. Im Allgemeinen verwendet die auf Abfragelernen basierende dreidimensionale Objekterkennungsmethode eine transformatorbasierte Struktur, um Merkmalsabfragen durchzuführen und eine Merkmalsausrichtung zu erreichen. Schließlich wurden multimodale Funktionen in Lidar-basierte Prozesse wie CenterPoint integriert.
- Dreidimensionale Objekterkennung basierend auf einheitlichen Merkmalen: Dreidimensionale Objekterkennungsmethoden basierend auf einheitlichen Merkmalen, wie EA-BEV, BEVFusion, cai2023bevfusion4d, FocalFormer3D, FUTR3D, UniTR, Uni3D, virconv, MSMDFusion, sfd, cmt , UVTR, Sparsefusion usw. , normalerweise wird die Vereinheitlichung heterogener Modalitäten vor der Fusion durch Projektion vor der Merkmalsfusion erreicht. In der BEV-Fusionsserie wird LSS zur Tiefenschätzung verwendet, die Vorderansichtsmerkmale werden in BEV-Merkmale umgewandelt und anschließend werden das BEV-Bild und die BEV-Punktwolkenmerkmale fusioniert. Andererseits verwenden CMT und UniTR Transformer zur Tokenisierung von Punktwolken und Bildern und erstellen durch Transformer-Codierung einen impliziten einheitlichen Raum. CMT verwendet Projektion im Positionskodierungsprozess, vermeidet jedoch vollständig die Abhängigkeit von Projektionsbeziehungen auf der Feature-Lernebene. FocalFormer3D, FUTR3D und UVTR verwenden die Abfrage von Transformer, um eine DETR3D-ähnliche Lösung zu implementieren und durch Abfrage einen einheitlichen spärlichen BEV-Feature-Raum zu erstellen, wodurch die durch die direkte Projektion verursachte Instabilität verringert wird.
VirConv, MSMDFusion und SFD bilden durch Pseudopunktwolken einen einheitlichen Raum, und die Projektion erfolgt vor dem Feature-Lernen. Die durch die direkte Projektion verursachten Probleme werden durch anschließendes Feature-Lernen gelöst. Zusammenfassend stellen einheitliche, merkmalsbasierte 3D-Objekterkennungsmethoden derzeit äußerst genaue und robuste Lösungen dar. Obwohl sie eine Projektionsmatrix enthalten, findet diese Projektion nicht zwischen multimodalen Fusionen statt und wird daher als nicht-projektive 3D-Objekterkennungsmethode betrachtet. Im Gegensatz zu automatischen Projektionsmethoden zur Erkennung von 3D-Objekten lösen sie das Problem des Projektionsfehlers nicht direkt, sondern erstellen einen einheitlichen Raum und berücksichtigen mehrere Dimensionen der multimodalen 3D-Objekterkennung, um äußerst robuste multimodale Merkmale zu erhalten.
5. Fazit
Die 3D-Objekterkennung spielt eine entscheidende Rolle bei der Wahrnehmung des autonomen Fahrens. In den letzten Jahren hat sich dieses Gebiet rasant entwickelt und eine große Anzahl von Forschungsarbeiten hervorgebracht. Basierend auf den vielfältigen Datenformen, die von Sensoren generiert werden, werden diese Methoden hauptsächlich in drei Typen unterteilt: bildbasiert, punktwolkenbasiert und multimodal. Die wichtigsten Bewertungsmaßstäbe dieser Methoden sind hohe Genauigkeit und geringe Latenz. Viele Rezensionen fassen diese Ansätze zusammen und konzentrieren sich dabei hauptsächlich auf die Kernprinzipien „hohe Genauigkeit und geringe Latenz“ und beschreiben ihre technische Entwicklung.
Im Zuge des Übergangs der autonomen Fahrtechnologie von Durchbrüchen zu praktischen Anwendungen legen die bestehenden Überprüfungen jedoch nicht den Schwerpunkt auf die Sicherheitswahrnehmung und decken nicht die aktuellen technischen Wege im Zusammenhang mit der Sicherheitswahrnehmung ab. Beispielsweise werden neuere multimodale Fusionsmethoden häufig während der experimentellen Phase auf ihre Robustheit getestet, ein Aspekt, der in der aktuellen Übersicht nicht vollständig berücksichtigt wurde.
Untersuchen Sie daher den 3D-Objekterkennungsalgorithmus erneut und konzentrieren Sie sich dabei auf „Genauigkeit, Latenz und Robustheit“ als Schlüsselaspekte. Wir klassifizieren frühere Bewertungen neu und legen dabei besonderen Wert auf die Neuklassifizierung aus Sicht der Sicherheitswahrnehmung. Es besteht die Hoffnung, dass diese Arbeit neue Einblicke in die zukünftige Forschung zur 3D-Objekterkennung liefern wird, die über die bloße Erforschung der Grenzen hoher Genauigkeit hinausgehen.

Das obige ist der detaillierte Inhalt vonKamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Warum ist Gaussian Splatting beim autonomen Fahren so beliebt, dass NeRF allmählich aufgegeben wird?
Jan 17, 2024 pm 02:57 PM
Oben geschrieben und persönliches Verständnis des Autors. Dreidimensionales Gaussplatting (3DGS) ist eine transformative Technologie, die in den letzten Jahren in den Bereichen explizite Strahlungsfelder und Computergrafik entstanden ist. Diese innovative Methode zeichnet sich durch die Verwendung von Millionen von 3D-Gaußkurven aus, was sich stark von der Neural Radiation Field (NeRF)-Methode unterscheidet, die hauptsächlich ein implizites koordinatenbasiertes Modell verwendet, um räumliche Koordinaten auf Pixelwerte abzubilden. Mit seiner expliziten Szenendarstellung und differenzierbaren Rendering-Algorithmen garantiert 3DGS nicht nur Echtzeit-Rendering-Fähigkeiten, sondern führt auch ein beispielloses Maß an Kontrolle und Szenenbearbeitung ein. Dies positioniert 3DGS als potenziellen Game-Changer für die 3D-Rekonstruktion und -Darstellung der nächsten Generation. Zu diesem Zweck geben wir erstmals einen systematischen Überblick über die neuesten Entwicklungen und Anliegen im Bereich 3DGS.
 Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Wie lässt sich das Long-Tail-Problem in autonomen Fahrszenarien lösen?
Jun 02, 2024 pm 02:44 PM
Gestern wurde ich während des Interviews gefragt, ob ich irgendwelche Long-Tail-Fragen gestellt hätte, also dachte ich, ich würde eine kurze Zusammenfassung geben. Das Long-Tail-Problem des autonomen Fahrens bezieht sich auf Randfälle bei autonomen Fahrzeugen, also mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. Das wahrgenommene Long-Tail-Problem ist einer der Hauptgründe, die derzeit den betrieblichen Designbereich intelligenter autonomer Einzelfahrzeugfahrzeuge einschränken. Die zugrunde liegende Architektur und die meisten technischen Probleme des autonomen Fahrens wurden gelöst, und die verbleibenden 5 % der Long-Tail-Probleme wurden nach und nach zum Schlüssel zur Einschränkung der Entwicklung des autonomen Fahrens. Zu diesen Problemen gehören eine Vielzahl fragmentierter Szenarien, Extremsituationen und unvorhersehbares menschliches Verhalten. Der „Long Tail“ von Randszenarien beim autonomen Fahren bezieht sich auf Randfälle in autonomen Fahrzeugen (AVs). Randfälle sind mögliche Szenarien mit geringer Eintrittswahrscheinlichkeit. diese seltenen Ereignisse
 Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
Kamera oder Lidar wählen? Eine aktuelle Übersicht über die Erzielung einer robusten 3D-Objekterkennung
Jan 26, 2024 am 11:18 AM
0. Vorab geschrieben&& Persönliches Verständnis, dass autonome Fahrsysteme auf fortschrittlichen Wahrnehmungs-, Entscheidungs- und Steuerungstechnologien beruhen, indem sie verschiedene Sensoren (wie Kameras, Lidar, Radar usw.) verwenden, um die Umgebung wahrzunehmen, und Algorithmen und Modelle verwenden für Echtzeitanalysen und Entscheidungsfindung. Dies ermöglicht es Fahrzeugen, Verkehrszeichen zu erkennen, andere Fahrzeuge zu erkennen und zu verfolgen, das Verhalten von Fußgängern vorherzusagen usw. und sich so sicher an komplexe Verkehrsumgebungen anzupassen. Diese Technologie erregt derzeit große Aufmerksamkeit und gilt als wichtiger Entwicklungsbereich für die Zukunft des Transportwesens . eins. Aber was autonomes Fahren schwierig macht, ist herauszufinden, wie man dem Auto klarmachen kann, was um es herum passiert. Dies erfordert, dass der dreidimensionale Objekterkennungsalgorithmus im autonomen Fahrsystem Objekte in der Umgebung, einschließlich ihrer Standorte, genau wahrnehmen und beschreiben kann.
 CLIP-BEVFormer: Überwacht explizit die BEVFormer-Struktur, um die Leistung der Long-Tail-Erkennung zu verbessern
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Überwacht explizit die BEVFormer-Struktur, um die Leistung der Long-Tail-Erkennung zu verbessern
Mar 26, 2024 pm 12:41 PM
Oben geschrieben und das persönliche Verständnis des Autors: Derzeit spielt das Wahrnehmungsmodul im gesamten autonomen Fahrsystem eine entscheidende Rolle Das Steuermodul im autonomen Fahrsystem trifft zeitnahe und korrekte Urteile und Verhaltensentscheidungen. Derzeit sind Autos mit autonomen Fahrfunktionen in der Regel mit einer Vielzahl von Dateninformationssensoren ausgestattet, darunter Rundumsichtkamerasensoren, Lidar-Sensoren und Millimeterwellenradarsensoren, um Informationen in verschiedenen Modalitäten zu sammeln und so genaue Wahrnehmungsaufgaben zu erfüllen. Der auf reinem Sehen basierende BEV-Wahrnehmungsalgorithmus wird von der Industrie aufgrund seiner geringen Hardwarekosten und einfachen Bereitstellung bevorzugt, und seine Ausgabeergebnisse können problemlos auf verschiedene nachgelagerte Aufgaben angewendet werden.
 Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Dieser Artikel reicht aus, um etwas über autonomes Fahren und Flugbahnvorhersage zu lesen!
Feb 28, 2024 pm 07:20 PM
Die Trajektorienvorhersage spielt eine wichtige Rolle beim autonomen Fahren. Unter autonomer Fahrtrajektorienvorhersage versteht man die Vorhersage der zukünftigen Fahrtrajektorie des Fahrzeugs durch die Analyse verschiedener Daten während des Fahrvorgangs. Als Kernmodul des autonomen Fahrens ist die Qualität der Trajektorienvorhersage von entscheidender Bedeutung für die nachgelagerte Planungssteuerung. Die Trajektorienvorhersageaufgabe verfügt über einen umfangreichen Technologie-Stack und erfordert Vertrautheit mit der dynamischen/statischen Wahrnehmung des autonomen Fahrens, hochpräzisen Karten, Fahrspurlinien, Fähigkeiten in der neuronalen Netzwerkarchitektur (CNN&GNN&Transformer) usw. Der Einstieg ist sehr schwierig! Viele Fans hoffen, so schnell wie möglich mit der Flugbahnvorhersage beginnen zu können und Fallstricke zu vermeiden. Heute werde ich eine Bestandsaufnahme einiger häufiger Probleme und einführender Lernmethoden für die Flugbahnvorhersage machen! Einführungsbezogenes Wissen 1. Sind die Vorschaupapiere in Ordnung? A: Schauen Sie sich zuerst die Umfrage an, S
 SIMPL: Ein einfacher und effizienter Multi-Agent-Benchmark zur Bewegungsvorhersage für autonomes Fahren
Feb 20, 2024 am 11:48 AM
SIMPL: Ein einfacher und effizienter Multi-Agent-Benchmark zur Bewegungsvorhersage für autonomes Fahren
Feb 20, 2024 am 11:48 AM
Originaltitel: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Paper-Link: https://arxiv.org/pdf/2402.02519.pdf Code-Link: https://github.com/HKUST-Aerial-Robotics/SIMPL Autor: Hong Kong University of Science und Technologie DJI-Papieridee: Dieses Papier schlägt eine einfache und effiziente Bewegungsvorhersagebasislinie (SIMPL) für autonome Fahrzeuge vor. Im Vergleich zum herkömmlichen Agent-Cent
 nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
nuScenes' neuestes SOTA |. SparseAD: Sparse-Abfrage hilft effizientes durchgängiges autonomes Fahren!
Apr 17, 2024 pm 06:22 PM
Vorab geschrieben und Ausgangspunkt Das End-to-End-Paradigma verwendet ein einheitliches Framework, um Multitasking in autonomen Fahrsystemen zu erreichen. Trotz der Einfachheit und Klarheit dieses Paradigmas bleibt die Leistung von End-to-End-Methoden für das autonome Fahren bei Teilaufgaben immer noch weit hinter Methoden für einzelne Aufgaben zurück. Gleichzeitig erschweren die in früheren End-to-End-Methoden weit verbreiteten Funktionen der dichten Vogelperspektive (BEV) die Skalierung auf mehr Modalitäten oder Aufgaben. Hier wird ein Sparse-Search-zentriertes End-to-End-Paradigma für autonomes Fahren (SparseAD) vorgeschlagen, bei dem die Sparse-Suche das gesamte Fahrszenario, einschließlich Raum, Zeit und Aufgaben, ohne dichte BEV-Darstellung vollständig abbildet. Insbesondere ist eine einheitliche, spärliche Architektur für die Aufgabenerkennung einschließlich Erkennung, Verfolgung und Online-Zuordnung konzipiert. Zudem schwer
 Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Sprechen wir über End-to-End- und autonome Fahrsysteme der nächsten Generation sowie über einige Missverständnisse über End-to-End-Autonomes Fahren?
Apr 15, 2024 pm 04:13 PM
Im vergangenen Monat hatte ich aus bekannten Gründen einen sehr intensiven Austausch mit verschiedenen Lehrern und Mitschülern der Branche. Ein unvermeidliches Thema im Austausch ist natürlich End-to-End und der beliebte Tesla FSDV12. Ich möchte diese Gelegenheit nutzen, einige meiner aktuellen Gedanken und Meinungen als Referenz und Diskussion darzulegen. Wie definiert man ein durchgängiges autonomes Fahrsystem und welche Probleme sollten voraussichtlich durchgängig gelöst werden? Gemäß der traditionellsten Definition bezieht sich ein End-to-End-System auf ein System, das Rohinformationen von Sensoren eingibt und für die Aufgabe relevante Variablen direkt ausgibt. Bei der Bilderkennung kann CNN beispielsweise als End-to-End bezeichnet werden, verglichen mit der herkömmlichen Methode zum Extrahieren von Merkmalen + Klassifizieren. Bei autonomen Fahraufgaben werden Eingabedaten verschiedener Sensoren (Kamera/LiDAR) benötigt
