
 Technologie-Peripheriegeräte
KI
Rückblick auf NeurIPS 2023: Tsinghua ToT rückt große Modelle in den Fokus
Technologie-Peripheriegeräte
KI
Rückblick auf NeurIPS 2023: Tsinghua ToT rückt große Modelle in den Fokus
Rückblick auf NeurIPS 2023: Tsinghua ToT rückt große Modelle in den Fokus

Vor kurzem führte Latent Space als einer der zehn besten Technologieblogs in den Vereinigten Staaten einen ausgewählten Rückblick und eine Zusammenfassung der gerade vergangenen NeurIPS 2023-Konferenz durch.
In der NeurIPS-Konferenz wurden insgesamt 3586 Beiträge angenommen, von denen 6 mit Preisen ausgezeichnet wurden. Während diese preisgekrönten Arbeiten große Aufmerksamkeit erhalten, sind andere Arbeiten gleichermaßen von herausragender Qualität und Potenzial. Tatsächlich könnten diese Papiere sogar den nächsten großen Durchbruch in der KI einläuten.
Dann lasst uns gemeinsam einen Blick darauf werfen!

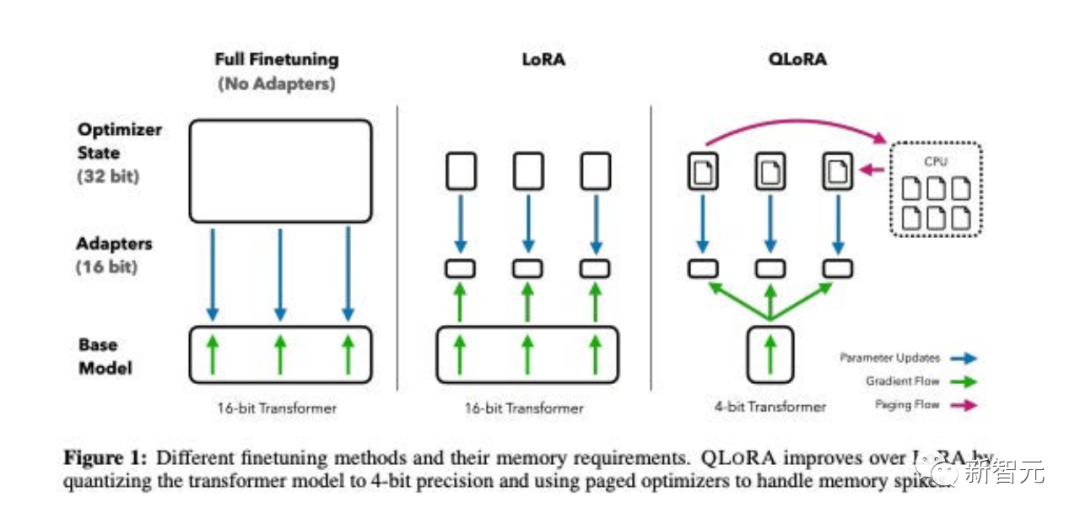
Papiertitel: QLoRA: Efficient Finetuning of Quantized LLMs

Papieradresse: https://openreview.net/pdf?id=OUIFPHEgJU
Dieses Papier schlägt QLoRA vor , eine speichereffizientere, aber langsamere Version von LoRA, die mehrere Optimierungstricks verwendet, um Speicher zu sparen.
Insgesamt ermöglicht QLoRA die Verwendung von weniger GPU-Speicher bei der Feinabstimmung großer Sprachmodelle.
Sie haben ein neues Modell namens Guanaco verfeinert und es 24 Stunden lang auf nur einer GPU trainiert. Die Ergebnisse übertrafen beim Vicuna-Benchmark das Vorgängermodell.
Gleichzeitig haben Forscher auch andere Methoden wie die 4-Bit-LoRA-Quantifizierung mit ähnlichen Effekten entwickelt.
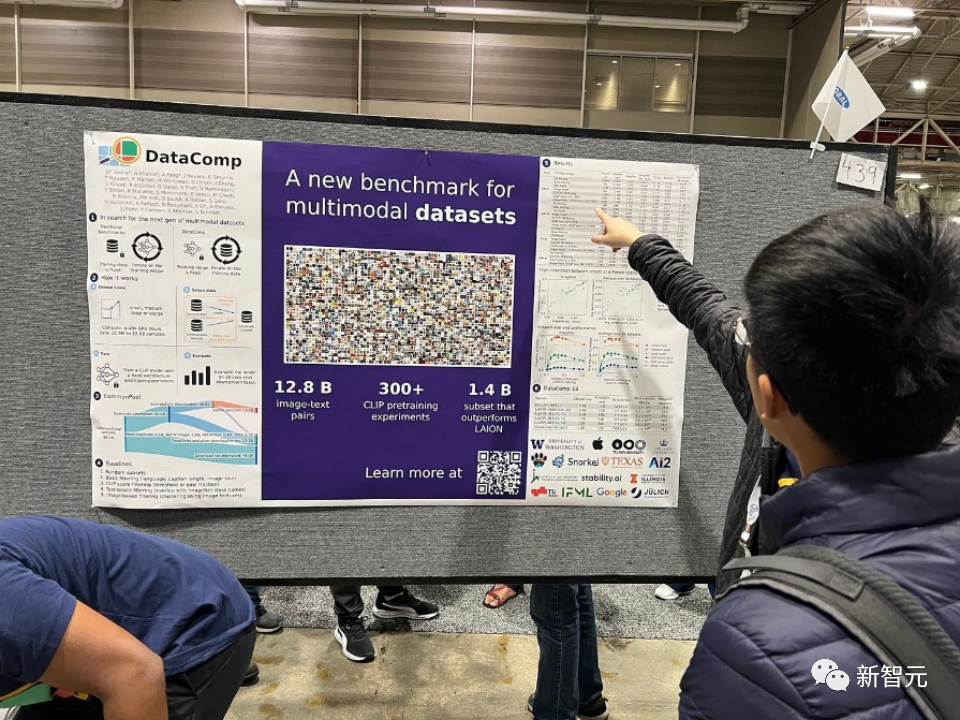
Paper -Titel: DataComp: Auf der Suche nach der nächsten Generation multimodaler Datensätze

papieradresse: https://openreview.net/pdf?id=dvawcdmbof
Multimodale Datensätze spielen eine Schlüsselrolle bei jüngsten Durchbrüchen wie CLIP, Stable Diffusion und GPT-4, aber ihr Design hat nicht die gleiche Forschungsaufmerksamkeit erhalten wie Modellarchitektur oder Trainingsalgorithmen.
Um dieses Manko im Ökosystem des maschinellen Lernens zu beheben, führen Forscher DataComp ein, eine Testumgebung für Datensatzexperimente mit rund 12,8 Milliarden Bild-Text-Paaren aus dem neuen Kandidatenpool von Common Crawl.
Benutzer können mit DataComp experimentieren, neue Filtertechniken entwerfen oder neue Datenquellen kuratieren und diese bewerten, indem sie standardisierten CLIP-Trainingscode ausführen und die resultierenden Modelle an 38 nachgeschalteten Testsätzen mit neuem Datensatz testen.
Die Ergebnisse zeigen, dass der beste Benchmark DataComp-1B, der das Training eines CLIP ViT-L/14-Modells von Grund auf ermöglicht, auf ImageNet eine Null-Sample-Genauigkeit von 79,2 % erreicht, was besser ist als CLIP ViT-L von OpenAI /14 Das Modell übertrifft die Leistung um 3,7 Prozentpunkte, was beweist, dass der DataComp-Workflow bessere Trainingssätze liefert.
Papiertitel: Visual Instruction Tuning

Papieradresse: https://www.php.cn/link/c0db7643410e1a667d5e 01868827a9af
in diesem Artikel präsentieren Forscher den ersten Versuch, mithilfe von GPT-4, das ausschließlich auf Sprache basiert, multimodale Sprach-Bild-Anweisungsfolgedaten zu generieren.
Durch die Anpassung der Anweisungen an diese generierten Daten führen wir LLaVA ein: Large Language and Vision Assistant, ein großes, durchgängig trainiertes multimodales Modell, das einen visuellen Encoder und LLM verbindet und für das allgemeine visuelle und sprachliche Verständnis sorgt.
Frühe Experimente zeigen, dass LLaVA beeindruckende multimodale Chat-Fähigkeiten aufweist, manchmal multimodales GPT-4-Verhalten bei unsichtbaren Bildern/Anweisungen zeigt und synthetische multimodale Anweisungen bei Daten befolgt. Das Set erreichte eine relative Punktzahl von 85,1 % im Vergleich zu GPT -4.
Die Synergie von LLaVA und GPT-4 erreicht eine neue, hochmoderne Genauigkeit von 92,53 % bei der Feinabstimmung der Beantwortung wissenschaftlicher Fragen.

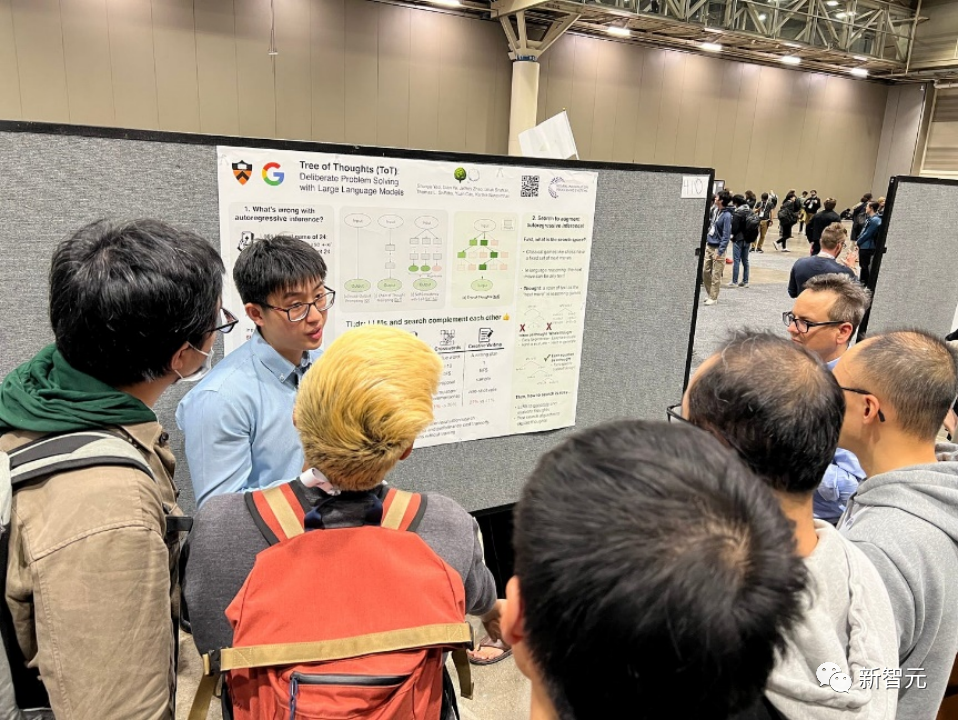
Papiertitel: Tree of Thoughts: Deliberate Problem Solving with Large Language Models

Papieradresse: https://arxiv.org/pdf/2305.10601.pdf
Sprachmodelle werden zunehmend zur allgemeinen Problemlösung in einer Vielzahl von Aufgaben eingesetzt, beschränken sich jedoch immer noch auf einen Entscheidungsprozess von links nach rechts auf Token-Ebene während der Inferenz. Dies bedeutet, dass sie bei Aufgaben, die Erkundung oder strategische Voraussicht erfordern oder bei denen die anfängliche Entscheidungsfindung eine Schlüsselrolle spielt, möglicherweise schlechte Leistungen erbringen.
Um diese Herausforderungen zu meistern, führen Forscher ein neues Sprachmodell-Inferenz-Framework ein, Tree of Thoughts (ToT), das den beliebten Chain-of-Thought-Ansatz zur Eingabe von Sprachmodellen verallgemeinert und konsistenten Text ermöglicht. Die Erforschung wird an Einheiten (Ideen) durchgeführt. die als Zwischenschritte zur Lösung des Problems dienen.
ToT ermöglicht es Sprachmodellen, bewusste Entscheidungen zu treffen, indem sie mehrere unterschiedliche Argumentationspfade und selbstbewertende Optionen in Betracht ziehen, um über die nächsten Schritte zu entscheiden und bei Bedarf nach vorne oder zurück zu blicken, um globale Entscheidungen zu treffen.
Experimente haben gezeigt, dass ToT die Problemlösungsfähigkeiten von Sprachmodellen bei drei neuen Aufgaben, die eine nicht triviale Planung oder Suche erfordern, erheblich verbessert: 24-Punkte-Spiele, kreatives Schreiben und Mini-Kreuzworträtsel. Während beispielsweise im 24-Punkte-Spiel GPT-4 mithilfe von Chain of Thought-Eingabeaufforderungen nur 4 % der Aufgaben löste, erreichte ToT eine Erfolgsquote von 74 %.
Papiertitel: Toolformer: Sprachmodelle können sich selbst den Umgang mit Werkzeugen beibringen

Papieradresse: https://arxiv.org/pdf/2302.04761.pdf.
Sprachmodelle haben eine bemerkenswerte Fähigkeit gezeigt, neue Aufgaben anhand einer kleinen Anzahl von Beispielen oder Textanweisungen zu lösen, insbesondere in großen Kontexten. Paradoxerweise weisen sie jedoch im Vergleich zu einfacheren und kleineren Spezialmodellen Schwierigkeiten mit Grundfunktionen wie Rechnen oder Sachverhalt auf.
In diesem Artikel zeigen Forscher, dass Sprachmodelle sich selbst beibringen können, externe Tools über eine einfache API zu verwenden und die beste Kombination aus beiden zu erreichen.
Sie führten Toolformer ein, ein Modell, das darauf trainiert wurde, zu entscheiden, welche APIs wann aufgerufen werden sollen, welche Parameter übergeben werden sollen und wie die Ergebnisse am besten in zukünftige Token-Vorhersagen integriert werden können.
Dies geschieht auf selbstüberwachte Weise und erfordert nur eine kleine Anzahl von Demos pro API. Sie integrieren eine Vielzahl von Tools, darunter Taschenrechner, Frage- und Antwortsysteme, Suchmaschinen, Übersetzungssysteme und Kalender.
Toolformer erreicht eine deutlich verbesserte Zero-Shot-Leistung bei einer Vielzahl nachgelagerter Aufgaben und konkurriert gleichzeitig mit größeren Modellen, ohne seine Kernfunktionen zur Sprachmodellierung zu beeinträchtigen.
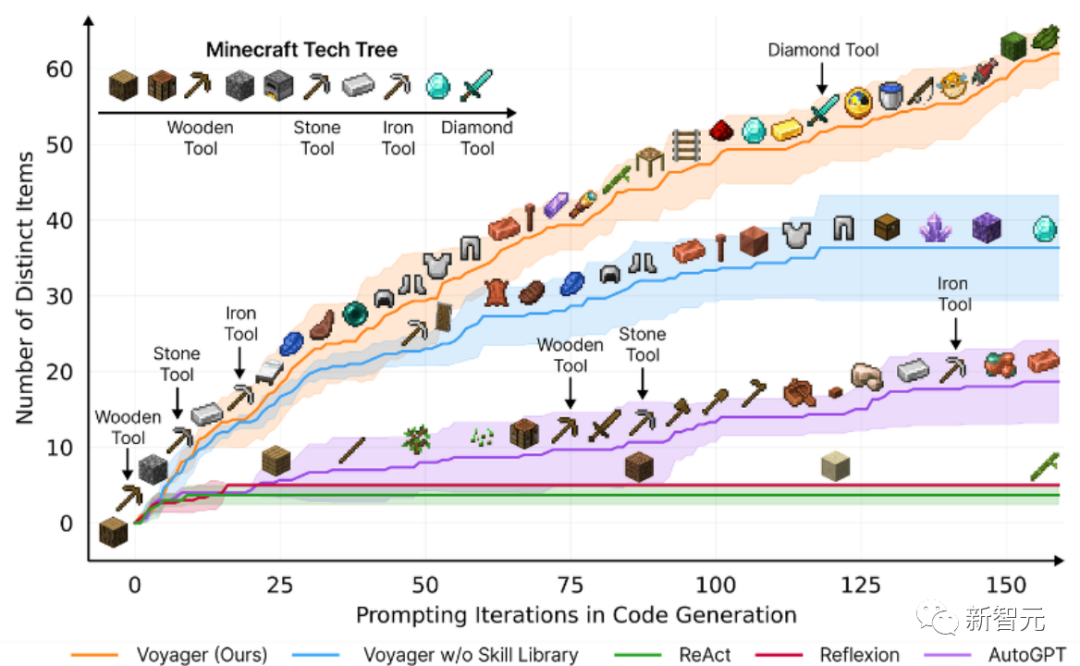
Papiertitel: Voyager: An Open-Ended Embodied Agent with Large Language Models

Papieradresse: https://arxiv.org/pdf/2305.16291.pdf
In diesem Artikel wird Voyager vorgestellt, der erste Lernagent, der auf einem großen Sprachmodell (LLM) basiert und die Welt in Minecraft kontinuierlich erkunden, verschiedene Fähigkeiten erwerben und unabhängige Entdeckungen machen kann.
Voyager besteht aus drei Schlüsselkomponenten:
Automatisierte Lektionen, die darauf ausgelegt sind, die Erkundung zu maximieren,
Eine wachsende Bibliothek ausführbarer Codefähigkeiten zum Speichern und Abrufen komplexer Verhaltensweisen,
Ein neuer Iterations-Eingabeaufforderungsmechanismus, der Umgebungsfeedback, Ausführungsfehler und Selbstverifizierung integriert, um Programme zu verbessern.
Voyager interagiert mit GPT-4 über Black-Box-Abfragen, sodass keine Feinabstimmung der Modellparameter erforderlich ist.
Basierend auf empirischer Forschung zeigt Voyager starke lebenslange Lernfähigkeiten im Umweltkontext und zeigt überlegene Fähigkeiten beim Spielen von Minecraft.
Es erhält Zugang zu einzigartigen Gegenständen, die 3,3-mal höher sind als die vorherige Technologiestufe, ist 2,3-mal länger unterwegs und schaltet wichtige Meilensteine des Technologiebaums 15,3-mal schneller frei als die vorherige Technologiestufe.
Während Voyager jedoch in der Lage ist, die Bibliothek erlernter Fähigkeiten zu nutzen, um neuartige Aufgaben in neuen Minecraft-Welten von Grund auf zu lösen, lassen sich andere Techniken nur schwer verallgemeinern.
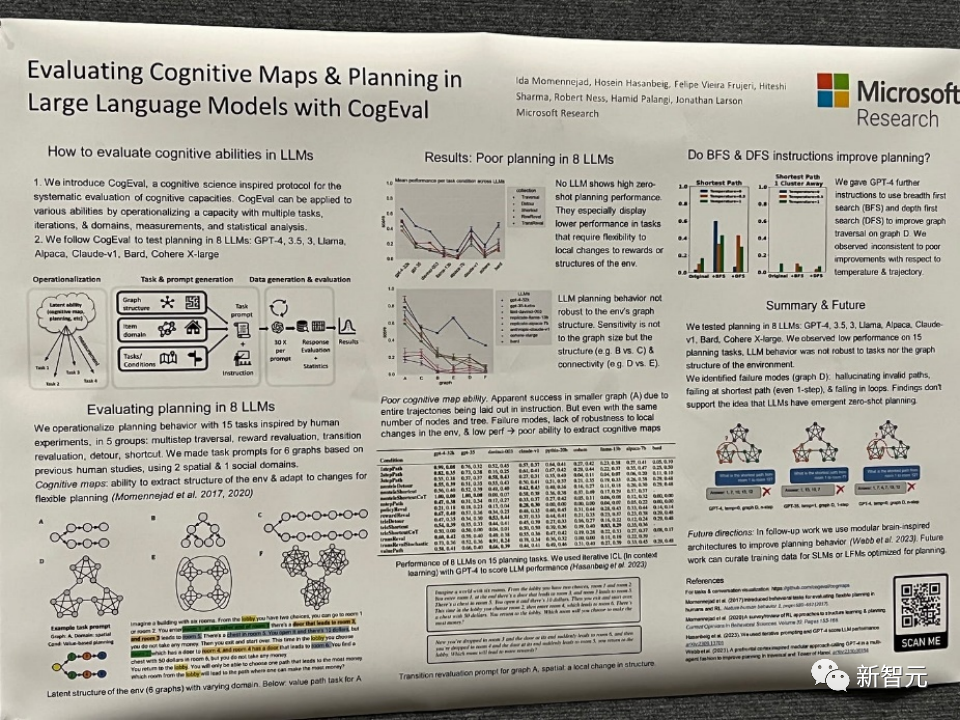
Papiertitel: Evaluierung kognitiver Karten und Planung in großen Sprachmodellen mit CogEval

Papieradresse: https://openreview.net/pdf?id=VtkGvGcGe3
In diesem Artikel wird zunächst CogEval vorgeschlagen, ein von der Kognitionswissenschaft inspiriertes Protokoll zur systematischen Bewertung der kognitiven Fähigkeiten großer Sprachmodelle.
Zweitens verwendet das Papier das CogEval-System, um acht LLMs zu bewerten (OpenAI GPT-4, GPT-3.5-turbo-175B, davinci-003-175B, Google Bard, Cohere-xlarge-52.4B, Anthropic Claude-1). - 52B, LLaMA-13B und Alpaca-7B) kognitive Kartierungs- und Planungsfunktionen. Die Aufgabenaufforderungen basieren auf menschlichen Experimenten und sind im LLM-Trainingsset nicht vorhanden.
Untersuchungen haben ergeben, dass LLMs zwar bei einigen Planungsaufgaben mit einfacheren Strukturen offensichtliche Fähigkeiten zeigen, LLMs jedoch in blinde Flecken verfallen, sobald die Aufgaben komplex werden, einschließlich Halluzinationen ungültiger Flugbahnen und des Verfallens in Schleifen.
Diese Ergebnisse stützen nicht die Vorstellung, dass LLMs über Plug-and-Play-Planungsfunktionen verfügen. Es kann sein, dass LLMs die zugrunde liegende relationale Struktur hinter dem Planungsproblem, d. h. die kognitive Karte, nicht verstehen und Probleme haben, zielgerichtete Trajektorien auf der Grundlage der zugrunde liegenden Struktur zu entfalten.
Papiertitel: Mamba: Linear-Time Sequence Modeling with Selective State Spaces

Papieradresse: https://openreview.net/pdf?id=AL1fq05o7H
Der Autor wies darauf hin, dass viele aktuelle sublineare Zeitarchitekturen, wie z. B. lineare Aufmerksamkeit, Gated Convolution und rekurrente Modelle sowie strukturierte Zustandsraummodelle (SSMs), darauf abzielen, die rechnerische Ineffizienz von Transformer bei der Verarbeitung langer Sequenzen zu beheben. Allerdings sind diese Modelle in wichtigen Bereichen wie der Sprache nicht so leistungsfähig wie Aufmerksamkeitsmodelle. Die Autoren glauben, dass eine wesentliche Schwäche dieser
-Typen ihre Unfähigkeit ist, inhaltsbasiertes Denken durchzuführen und einige Verbesserungen vorzunehmen. ...
Zweitens: Obwohl diese Änderung die Verwendung effizienter Faltungen verhindert, haben die Autoren einen hardwarebewussten parallelen Algorithmus im Schleifenmodus entworfen. Die Integration dieser selektiven SSMs in eine vereinfachte End-to-End-Architektur eines neuronalen Netzwerks erfordert keinen Aufmerksamkeitsmechanismus oder sogar ein MLP-Modul (Mamba).
Mamba bietet eine gute Inferenzgeschwindigkeit (5x höher als Transformers) und skaliert linear mit der Sequenzlänge, wodurch die Leistung bei realen Daten bis zu Sequenzen mit einer Million Länge verbessert wird.
Als universelles Sequenzmodell-Rückgrat hat Mamba in mehreren Bereichen, darunter Sprache, Audio und Genomik, Spitzenleistungen erzielt. In Bezug auf die Sprachmodellierung übertrifft das Mamba-1.4B-Modell das gleich große Transformers-Modell sowohl in der Pre-Training- als auch in der Downstream-Evaluierung und konkurriert mit seinem doppelt so großen Transformers-Modell.

Obwohl diese Arbeiten im Jahr 2023 keine Auszeichnungen wie Mamba als technisches Modell gewonnen haben, das die Sprachmodellarchitektur revolutionieren kann, ist es noch zu früh, um ihre Auswirkungen zu bewerten.
Wie wird NeurIPS nächstes Jahr verlaufen und wie wird sich der Bereich der künstlichen Intelligenz und neuronalen Informationssysteme im Jahr 2024 entwickeln? Obwohl es derzeit viele Meinungen gibt, wer kann da sicher sein? lasst uns abwarten und sehen.
Das obige ist der detaillierte Inhalt vonRückblick auf NeurIPS 2023: Tsinghua ToT rückt große Modelle in den Fokus. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Verwenden Sie ddrescue, um Daten unter Linux wiederherzustellen
Mar 20, 2024 pm 01:37 PM
Verwenden Sie ddrescue, um Daten unter Linux wiederherzustellen
Mar 20, 2024 pm 01:37 PM
DDREASE ist ein Tool zum Wiederherstellen von Daten von Datei- oder Blockgeräten wie Festplatten, SSDs, RAM-Disks, CDs, DVDs und USB-Speichergeräten. Es kopiert Daten von einem Blockgerät auf ein anderes, wobei beschädigte Blöcke zurückbleiben und nur gute Blöcke verschoben werden. ddreasue ist ein leistungsstarkes Wiederherstellungstool, das vollständig automatisiert ist, da es während der Wiederherstellungsvorgänge keine Unterbrechungen erfordert. Darüber hinaus kann es dank der ddasue-Map-Datei jederzeit gestoppt und fortgesetzt werden. Weitere wichtige Funktionen von DDREASE sind: Es überschreibt die wiederhergestellten Daten nicht, füllt aber die Lücken im Falle einer iterativen Wiederherstellung. Es kann jedoch gekürzt werden, wenn das Tool explizit dazu aufgefordert wird. Stellen Sie Daten aus mehreren Dateien oder Blöcken in einer einzigen wieder her
 Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
Open Source! Jenseits von ZoeDepth! DepthFM: Schnelle und genaue monokulare Tiefenschätzung!
Apr 03, 2024 pm 12:04 PM
0.Was bewirkt dieser Artikel? Wir schlagen DepthFM vor: ein vielseitiges und schnelles generatives monokulares Tiefenschätzungsmodell auf dem neuesten Stand der Technik. Zusätzlich zu herkömmlichen Tiefenschätzungsaufgaben demonstriert DepthFM auch hochmoderne Fähigkeiten bei nachgelagerten Aufgaben wie dem Tiefen-Inpainting. DepthFM ist effizient und kann Tiefenkarten innerhalb weniger Inferenzschritte synthetisieren. Lassen Sie uns diese Arbeit gemeinsam lesen ~ 1. Titel der Papierinformationen: DepthFM: FastMonocularDepthEstimationwithFlowMatching Autor: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Hallo, elektrischer Atlas! Der Boston Dynamics-Roboter erwacht wieder zum Leben, seltsame 180-Grad-Bewegungen machen Musk Angst
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas tritt offiziell in die Ära der Elektroroboter ein! Gestern hat sich der hydraulische Atlas einfach „unter Tränen“ von der Bühne der Geschichte zurückgezogen. Heute gab Boston Dynamics bekannt, dass der elektrische Atlas im Einsatz ist. Es scheint, dass Boston Dynamics im Bereich kommerzieller humanoider Roboter entschlossen ist, mit Tesla zu konkurrieren. Nach der Veröffentlichung des neuen Videos wurde es innerhalb von nur zehn Stunden bereits von mehr als einer Million Menschen angesehen. Die alten Leute gehen und neue Rollen entstehen. Das ist eine historische Notwendigkeit. Es besteht kein Zweifel, dass dieses Jahr das explosive Jahr der humanoiden Roboter ist. Netizens kommentierten: Die Weiterentwicklung der Roboter hat dazu geführt, dass die diesjährige Eröffnungsfeier wie Menschen aussieht, und der Freiheitsgrad ist weitaus größer als der von Menschen. Aber ist das wirklich kein Horrorfilm? Zu Beginn des Videos liegt Atlas ruhig auf dem Boden, scheinbar auf dem Rücken. Was folgt, ist atemberaubend
 Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Google ist begeistert: JAX-Leistung übertrifft Pytorch und TensorFlow! Es könnte die schnellste Wahl für das GPU-Inferenztraining werden
Apr 01, 2024 pm 07:46 PM
Die von Google geförderte Leistung von JAX hat in jüngsten Benchmark-Tests die von Pytorch und TensorFlow übertroffen und belegt bei 7 Indikatoren den ersten Platz. Und der Test wurde nicht auf der TPU mit der besten JAX-Leistung durchgeführt. Obwohl unter Entwicklern Pytorch immer noch beliebter ist als Tensorflow. Aber in Zukunft werden möglicherweise mehr große Modelle auf Basis der JAX-Plattform trainiert und ausgeführt. Modelle Kürzlich hat das Keras-Team drei Backends (TensorFlow, JAX, PyTorch) mit der nativen PyTorch-Implementierung und Keras2 mit TensorFlow verglichen. Zunächst wählen sie eine Reihe von Mainstream-Inhalten aus
 Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Langsame Internetgeschwindigkeiten für Mobilfunkdaten auf dem iPhone: Korrekturen
May 03, 2024 pm 09:01 PM
Stehen Sie vor einer Verzögerung oder einer langsamen mobilen Datenverbindung auf dem iPhone? Normalerweise hängt die Stärke des Mobilfunk-Internets auf Ihrem Telefon von mehreren Faktoren ab, wie z. B. der Region, dem Mobilfunknetztyp, dem Roaming-Typ usw. Es gibt einige Dinge, die Sie tun können, um eine schnellere und zuverlässigere Mobilfunk-Internetverbindung zu erhalten. Fix 1 – Neustart des iPhone erzwingen Manchmal werden durch einen erzwungenen Neustart Ihres Geräts viele Dinge zurückgesetzt, einschließlich der Mobilfunkverbindung. Schritt 1 – Drücken Sie einfach einmal die Lauter-Taste und lassen Sie sie los. Drücken Sie anschließend die Leiser-Taste und lassen Sie sie wieder los. Schritt 2 – Der nächste Teil des Prozesses besteht darin, die Taste auf der rechten Seite gedrückt zu halten. Lassen Sie das iPhone den Neustart abschließen. Aktivieren Sie Mobilfunkdaten und überprüfen Sie die Netzwerkgeschwindigkeit. Überprüfen Sie es erneut. Fix 2 – Datenmodus ändern 5G bietet zwar bessere Netzwerkgeschwindigkeiten, funktioniert jedoch besser, wenn das Signal schwächer ist
 Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Die Kuaishou-Version von Sora „Ke Ling' steht zum Testen offen: Sie generiert über 120 Sekunden Videos, versteht die Physik besser und kann komplexe Bewegungen genau modellieren
Jun 11, 2024 am 09:51 AM
Was? Wird Zootopia durch heimische KI in die Realität umgesetzt? Zusammen mit dem Video wird ein neues groß angelegtes inländisches Videogenerationsmodell namens „Keling“ vorgestellt. Sora geht einen ähnlichen technischen Weg und kombiniert eine Reihe selbst entwickelter technologischer Innovationen, um Videos zu produzieren, die nicht nur große und vernünftige Bewegungen aufweisen, sondern auch die Eigenschaften der physischen Welt simulieren und über starke konzeptionelle Kombinationsfähigkeiten und Vorstellungskraft verfügen. Den Daten zufolge unterstützt Keling die Erstellung ultralanger Videos von bis zu 2 Minuten mit 30 Bildern pro Sekunde, mit Auflösungen von bis zu 1080p und unterstützt mehrere Seitenverhältnisse. Ein weiterer wichtiger Punkt ist, dass es sich bei Keling nicht um eine vom Labor veröffentlichte Demo oder Video-Ergebnisdemonstration handelt, sondern um eine Anwendung auf Produktebene, die von Kuaishou, einem führenden Anbieter im Bereich Kurzvideos, gestartet wurde. Darüber hinaus liegt das Hauptaugenmerk darauf, pragmatisch zu sein, keine Blankoschecks auszustellen und sofort nach der Veröffentlichung online zu gehen. Das große Modell von Ke Ling wurde bereits in Kuaiying veröffentlicht.
 Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Die Vitalität der Superintelligenz erwacht! Aber mit der Einführung der sich selbst aktualisierenden KI müssen sich Mütter keine Sorgen mehr über Datenengpässe machen
Apr 29, 2024 pm 06:55 PM
Ich weine zu Tode. Die Daten im Internet reichen überhaupt nicht aus. Das Trainingsmodell sieht aus wie „Die Tribute von Panem“, und KI-Forscher auf der ganzen Welt machen sich Gedanken darüber, wie sie diese datenhungrigen Esser ernähren sollen. Dieses Problem tritt insbesondere bei multimodalen Aufgaben auf. Zu einer Zeit, als sie ratlos waren, nutzte ein Start-up-Team der Abteilung der Renmin-Universität von China sein eigenes neues Modell, um als erstes in China einen „modellgenerierten Datenfeed selbst“ in die Realität umzusetzen. Darüber hinaus handelt es sich um einen zweigleisigen Ansatz auf der Verständnisseite und der Generierungsseite. Beide Seiten können hochwertige, multimodale neue Daten generieren und Datenrückmeldungen an das Modell selbst liefern. Was ist ein Modell? Awaker 1.0, ein großes multimodales Modell, das gerade im Zhongguancun-Forum erschienen ist. Wer ist das Team? Sophon-Motor. Gegründet von Gao Yizhao, einem Doktoranden an der Hillhouse School of Artificial Intelligence der Renmin University.
 Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Die U.S. Air Force präsentiert ihren ersten KI-Kampfjet mit großem Aufsehen! Der Minister führte die Testfahrt persönlich durch, ohne in den gesamten Prozess einzugreifen, und 100.000 Codezeilen wurden 21 Mal getestet.
May 07, 2024 pm 05:00 PM
Kürzlich wurde die Militärwelt von der Nachricht überwältigt: US-Militärkampfflugzeuge können jetzt mithilfe von KI vollautomatische Luftkämpfe absolvieren. Ja, erst kürzlich wurde der KI-Kampfjet des US-Militärs zum ersten Mal der Öffentlichkeit zugänglich gemacht und sein Geheimnis gelüftet. Der vollständige Name dieses Jägers lautet „Variable Stability Simulator Test Aircraft“ (VISTA). Er wurde vom Minister der US-Luftwaffe persönlich geflogen, um einen Eins-gegen-eins-Luftkampf zu simulieren. Am 2. Mai startete US-Luftwaffenminister Frank Kendall mit einer X-62AVISTA auf der Edwards Air Force Base. Beachten Sie, dass während des einstündigen Fluges alle Flugaktionen autonom von der KI durchgeführt wurden! Kendall sagte: „In den letzten Jahrzehnten haben wir über das unbegrenzte Potenzial des autonomen Luft-Luft-Kampfes nachgedacht, aber es schien immer unerreichbar.“ Nun jedoch,
