
 Technologie-Peripheriegeräte
KI
Warum hat das ICLR Mambas Papier nicht akzeptiert? Die KI-Community hat eine große Diskussion entfacht
Technologie-Peripheriegeräte
KI
Warum hat das ICLR Mambas Papier nicht akzeptiert? Die KI-Community hat eine große Diskussion entfacht
Warum hat das ICLR Mambas Papier nicht akzeptiert? Die KI-Community hat eine große Diskussion entfacht

Im Jahr 2023 wird der Status von Transformer, dem dominierenden Akteur im Bereich der großen KI-Modelle, in Frage gestellt. Es ist eine neue Architektur namens „Mamba“ entstanden. Dabei handelt es sich um ein selektives Zustandsraummodell, das in der Sprachmodellierung mit Transformer vergleichbar ist und dieses möglicherweise sogar übertrifft. Gleichzeitig kann Mamba mit zunehmender Kontextlänge eine lineare Skalierung erreichen, was es ihm ermöglicht, Sequenzen mit einer Länge von einer Million Wörtern zu verarbeiten und den Inferenzdurchsatz bei der Verarbeitung realer Daten um das Fünffache zu verbessern. Diese bahnbrechende Leistungsverbesserung ist auffällig und eröffnet neue Möglichkeiten für die Entwicklung des KI-Bereichs.
Mehr als einen Monat nach seiner Veröffentlichung begann Mamba allmählich seinen Einfluss zu zeigen und brachte viele Projekte wie MoE-Mamba, Vision Mamba, VMamba, U-Mamba, MambaByte usw. hervor. Mamba hat großes Potenzial gezeigt, die Mängel von Transformer kontinuierlich zu überwinden. Diese Entwicklungen zeigen die kontinuierliche Entwicklung und Weiterentwicklung von Mamba und eröffnen neue Möglichkeiten im Bereich der künstlichen Intelligenz.
Allerdings erlebte dieser aufstrebende „Stern“ beim ICLR-Treffen 2024 einen Rückschlag. Die neuesten öffentlichen Ergebnisse zeigen, dass sich Mambas Papier immer noch im Status „Ausstehend“ befindet. Wir können seinen Namen nur in der Spalte „Ausstehende Entscheidung“ sehen und wir können nicht feststellen, ob es verzögert oder abgelehnt wurde.

Insgesamt erhielt Mamba Bewertungen von vier Rezensenten, die jeweils 8/8/6/3 waren. Einige Leute sagten, es sei wirklich rätselhaft, nach einer solchen Bewertung immer noch abgelehnt zu werden.

Um zu verstehen, warum, müssen wir uns ansehen, was die Rezensenten gesagt haben, die niedrige Bewertungen abgegeben haben.
Papierrezensionsseite: https://openreview.net/forum?id=AL1fq05o7H
Warum „nicht gut genug“?
In der Bewertungsrückmeldung erläuterte der Rezensent, der eine Bewertung von „3: ablehnen, nicht gut genug“ gab, mehrere Meinungen zu Mamba:
Gedanken zum Modelldesign:
- Mambas Motivation besteht darin, sich mit anderen auseinanderzusetzen die Mängel rekursiver Modelle beseitigen und gleichzeitig die Effizienz aufmerksamkeitsbasierter Modelle verbessern. Es gibt viele Studien in diese Richtung: S4-diagonal [1], SGConv [2], MEGA [3], SPADE [4] und viele effiziente Transformer-Modelle (z. B. [5]). Alle diese Modelle erreichen eine nahezu lineare Komplexität und die Autoren müssen Mamba hinsichtlich der Modellleistung und -effizienz mit diesen Werken vergleichen. Bezüglich der Modellleistung reichen einige einfache Experimente (wie die Sprachmodellierung von Wikitext-103) aus.
- Viele aufmerksamkeitsbasierte Transformer-Modelle zeigen die Fähigkeit zur Längenverallgemeinerung, das heißt, das Modell kann auf kürzere Sequenzlängen trainiert und auf längere Sequenzlängen getestet werden. Beispiele hierfür sind relative Positionskodierung (T5) und Alibi [6]. Verfügt Mamba über diese Fähigkeit zur Längenverallgemeinerung, da SSM im Allgemeinen kontinuierlich ist?
Gedanken zum Experiment:
- Die Autoren müssen mit einer stärkeren Basislinie vergleichen. Die Autoren gaben an, dass H3 als Motivation für die Modellarchitektur verwendet wurde, verglichen sie jedoch in Experimenten nicht mit H3. Gemäß Tabelle 4 in [7] beträgt der ppl von H3 im Pile-Datensatz 8,8 (1,25 M), 7,1 (3,55 M) bzw. 6,0 (1,3 B), was deutlich besser ist als bei Mamba. Die Autoren müssen einen Vergleich mit H3 zeigen.
- Für das vorab trainierte Modell zeigt der Autor nur die Ergebnisse der Null-Stichproben-Inferenz. Dieses Setup ist eher begrenzt und die Ergebnisse stützen die Wirksamkeit von Mamba nicht gut. Ich empfehle den Autoren, weitere Experimente mit langen Sequenzen durchzuführen, wie z. B. Dokumentzusammenfassungen, bei denen die Eingabesequenzen natürlich sehr lang sind (z. B. beträgt die durchschnittliche Sequenzlänge des arXiv-Datensatzes >8k).
- Der Autor behauptet, dass einer seiner Hauptbeiträge die Modellierung langer Sequenzen ist. Die Autoren sollten mit mehr Basislinien auf LRA (Long Range Arena) vergleichen, was im Grunde der Standardmaßstab für das Verständnis langer Sequenzen ist.
- Fehlender Speicher-Benchmark. Obwohl Abschnitt 4.5 den Titel „Geschwindigkeits- und Speicher-Benchmarks“ trägt, werden nur Geschwindigkeitsvergleiche vorgestellt. Darüber hinaus sollten die Autoren auf der linken Seite von Abbildung 8 detailliertere Einstellungen bereitstellen, z. B. Modellebenen, Modellgröße, Faltungsdetails usw. Können die Autoren eine Vorstellung davon geben, warum FlashAttention am langsamsten ist, wenn die Sequenzlänge sehr groß ist (Abbildung 8 links)?
Darüber hinaus wies ein anderer Rezensent auch auf die Mängel von Mamba hin: Das Modell hat während des Trainings immer noch sekundären Speicherbedarf wie Transformers.
Autor: Überarbeitet, bitte überprüfen
Nachdem das Autorenteam die Meinungen aller Rezensenten zusammengefasst hatte, überarbeitete und verbesserte das Autorenteam auch den Inhalt des Papiers und fügte neue experimentelle Ergebnisse und Analysen hinzu:
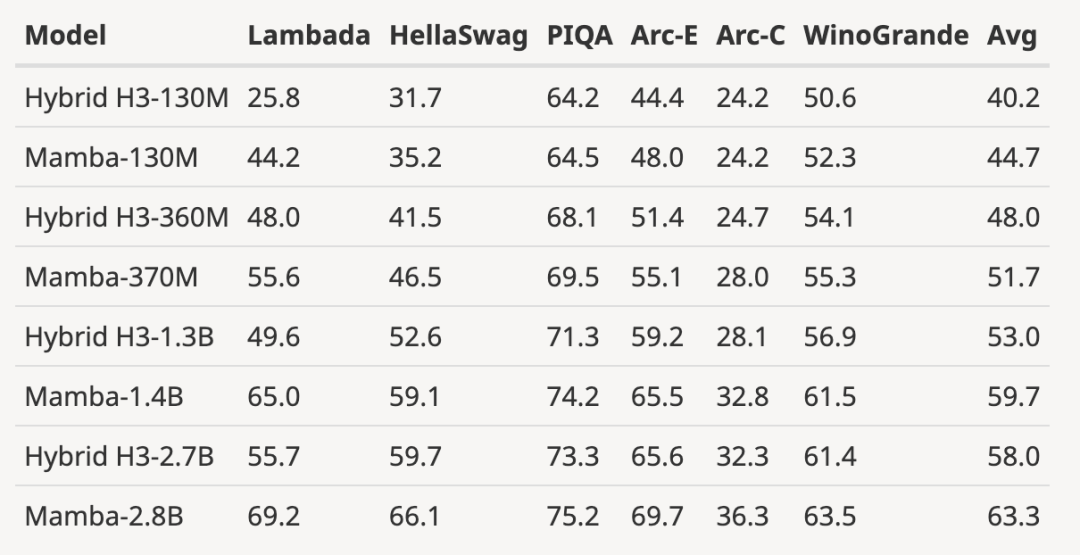
- Bewertungsergebnisse hinzugefügt von H3-Modell
Der Autor hat das vorab trainierte H3-Modell mit einer Größe von 125M-2,7B-Parametern heruntergeladen und eine Reihe von Bewertungen durchgeführt. Mamba schneidet bei allen Sprachbewertungen deutlich besser ab. Es ist erwähnenswert, dass es sich bei diesen H3-Modellen um Hybridmodelle mit quadratischer Aufmerksamkeit handelt, während das reine Modell des Autors, das nur die lineare Mamba-Schicht verwendet, bei allen Indikatoren deutlich besser ist.
Der Bewertungsvergleich mit dem vorab trainierten H3-Modell sieht wie folgt aus:
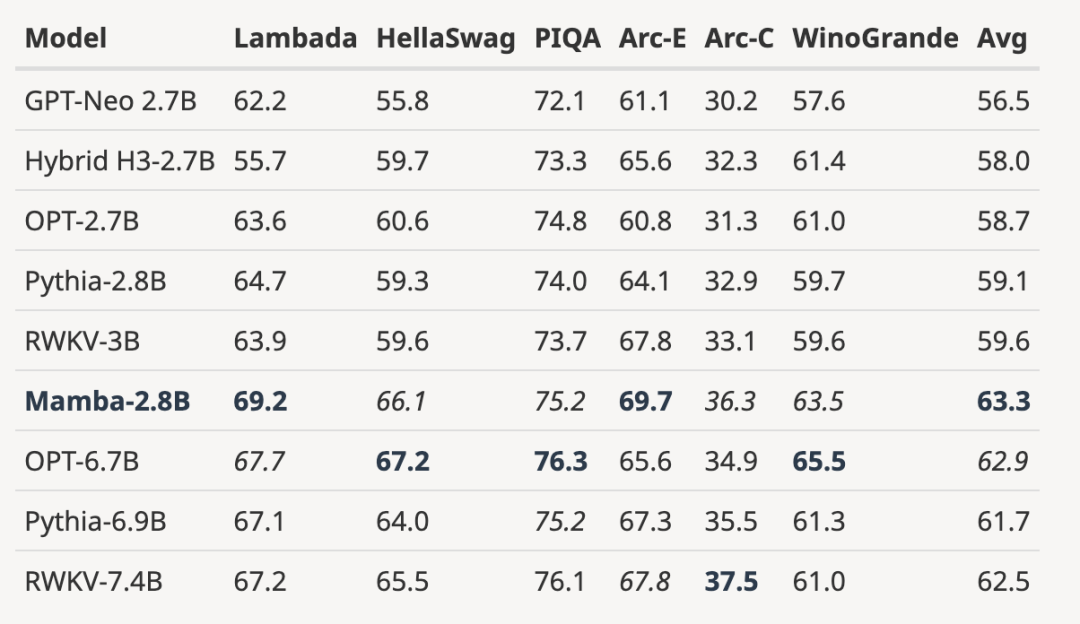
- Skalieren des vollständig trainierten Modells auf eine größere Modellgröße
wie in der Abbildung unten gezeigt Im Vergleich zum 3B-Open-Source-Modell, das mit der gleichen Anzahl von Token (300B) trainiert wurde, ist Mamba in jedem Bewertungsergebnis überlegen. Es ist sogar mit Modellen im Maßstab 7B vergleichbar: Beim Vergleich von Mamba (2,8B) mit OPT, Pythia und RWKV (7B) erreicht Mamba bei jedem Benchmark die beste Durchschnittspunktzahl und die beste/zweitbeste Punktzahl.
- zeigt die Ergebnisse der Längenextrapolation über die Trainingslänge hinaus
Der Autor hat eine Abbildung beigefügt, die die Längenextrapolation des vorab trainierten parametrischen 3B-Sprachmodells bewertet:
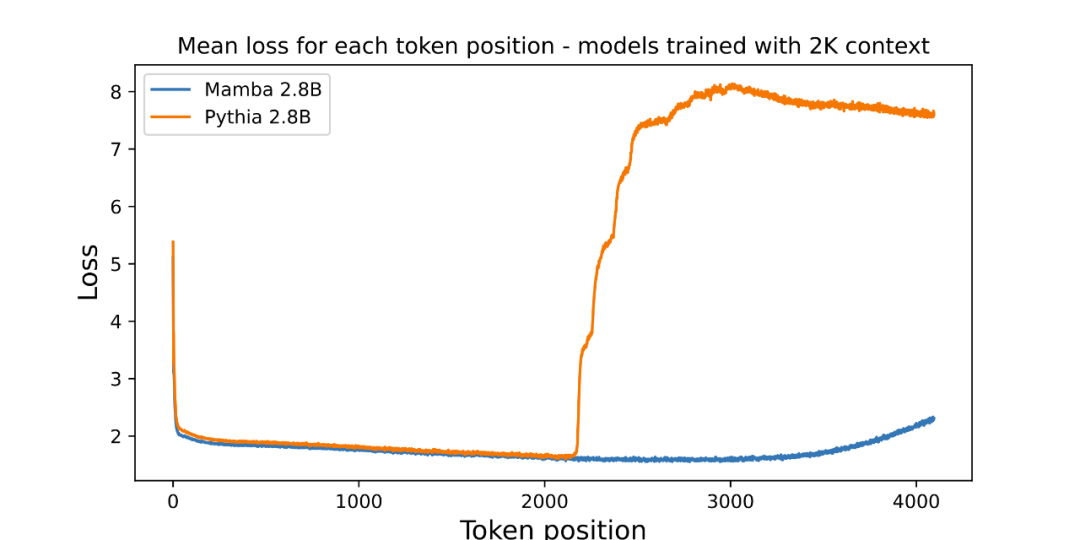
Die Grafik zeigt den durchschnittlichen Verlust pro Position (Protokolllesbarkeit). Die Verwirrung des ersten Tokens ist hoch, da es keinen Kontext hat, während die Verwirrung sowohl von Mamba als auch vom Basistransformer (Pythia) vor der Trainingskontextlänge (2048) zunimmt. Interessanterweise verbessert sich die Lösbarkeit von Mamba über den Trainingskontext hinaus bis zu einer Länge von etwa 3000 deutlich.
Der Autor betont, dass die Längenextrapolation nicht die direkte Motivation des Modells in diesem Artikel ist, sondern behandelt sie als zusätzliche Funktion:
- Das Basismodell (Pythia) berücksichtigt hier die Längenextrapolation beim Training nicht. Möglicherweise gibt es andere Transformer-Varianten, die vielseitiger sind (z. B. relative Positionskodierung T5 oder Alibi).
- Es wurden keine auf Pile trainierten Open-Source-3B-Modelle mit relativer Positionskodierung gefunden, daher kann dieser Vergleich nicht durchgeführt werden.
- Mamba berücksichtigt wie Pythia beim Training keine Längenextrapolation, daher ist es nicht vergleichbar. So wie Transformers über viele Techniken verfügen (z. B. unterschiedliche Positionseinbettungen), um ihre Fähigkeit zur isometrischen Längenverallgemeinerung zu verbessern, könnte es in zukünftigen Arbeiten interessant sein, SSM-spezifische Techniken für ähnliche Fähigkeiten abzuleiten.
- Ergänzt durch neue Ergebnisse auf WikiText-103
Der Autor analysierte die Ergebnisse mehrerer Arbeiten und zeigte, dass Mamba auf WikiText-103 deutlich besser abschneidet als andere mehr als 20 aktuelle subquadratische Sequenzen.
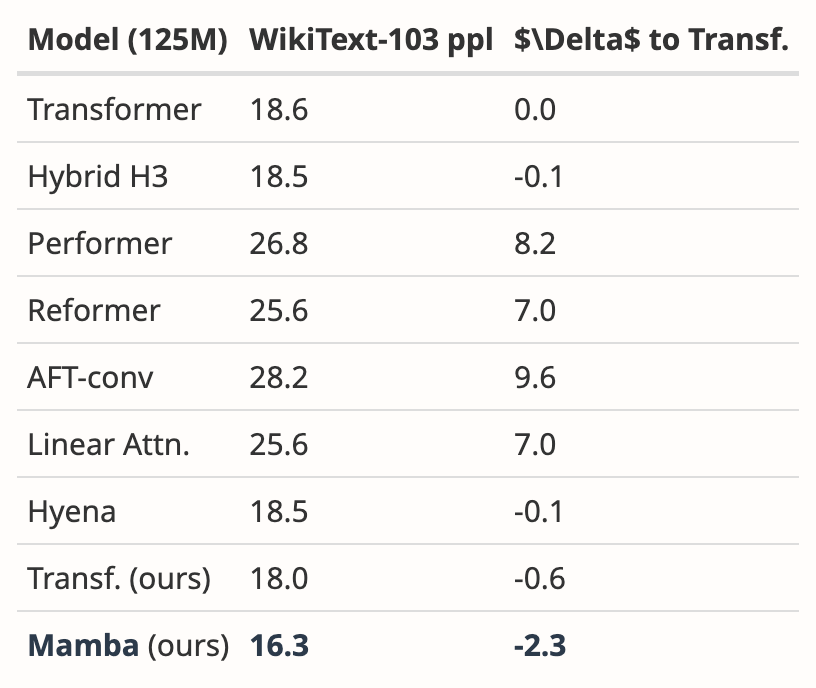
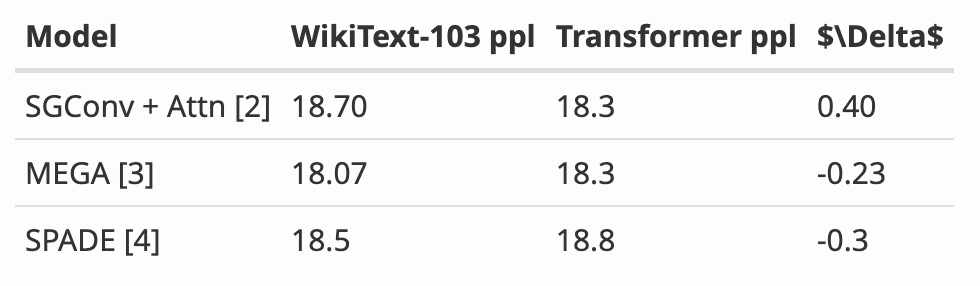
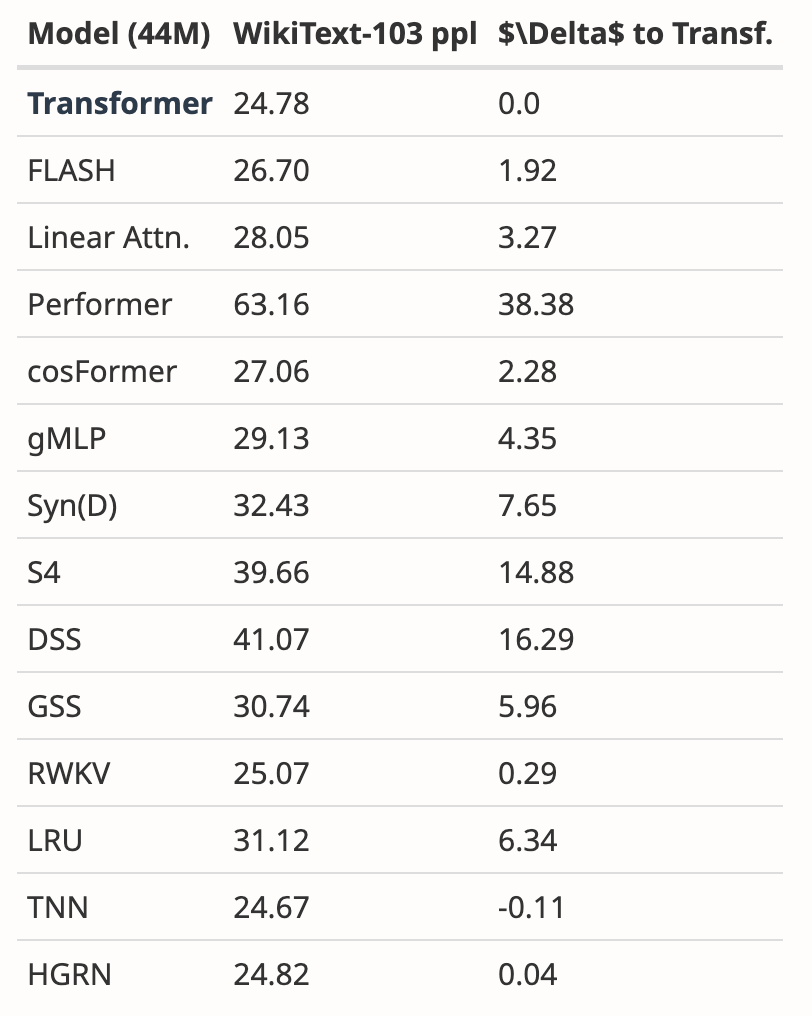
Trotzdem sind zwei Monate vergangen und dieses Papier befindet sich immer noch im Verfahren „Entscheidung ausstehend“, ohne dass es ein klares Ergebnis für „Annahme“ oder „Ablehnung“ gibt.
Die von den Top-Konferenzen abgelehnten Beiträge
Bei großen KI-Top-Konferenzen ist die „explosive Zahl der Einreichungen“ ein lästiges Problem, sodass Gutachter mit begrenzter Energie unweigerlich Fehler machen. Dies hat zur Ablehnung vieler berühmter Artikel in der Geschichte geführt, darunter YOLO, Transformer XL, Dropout, Support Vector Machine (SVM), Wissensdestillation, SIFT und der Webseiten-Ranking-Algorithmus der Google-Suchmaschine PageRank (siehe: „Das berühmte YOLO und PageRank“) „Einflussreiche Forschung wurde von der obersten CS-Konferenz abgelehnt“).
Auch Yann LeCun, einer der drei Giganten des Deep Learning, ist ein großer Papiermacher, der oft abgelehnt wird. Gerade eben twitterte er, dass sein 1887-mal zitierter Aufsatz „Deep Convolutional Networks on Graph-Structured Data“ ebenfalls von der Spitzenkonferenz abgelehnt wurde.
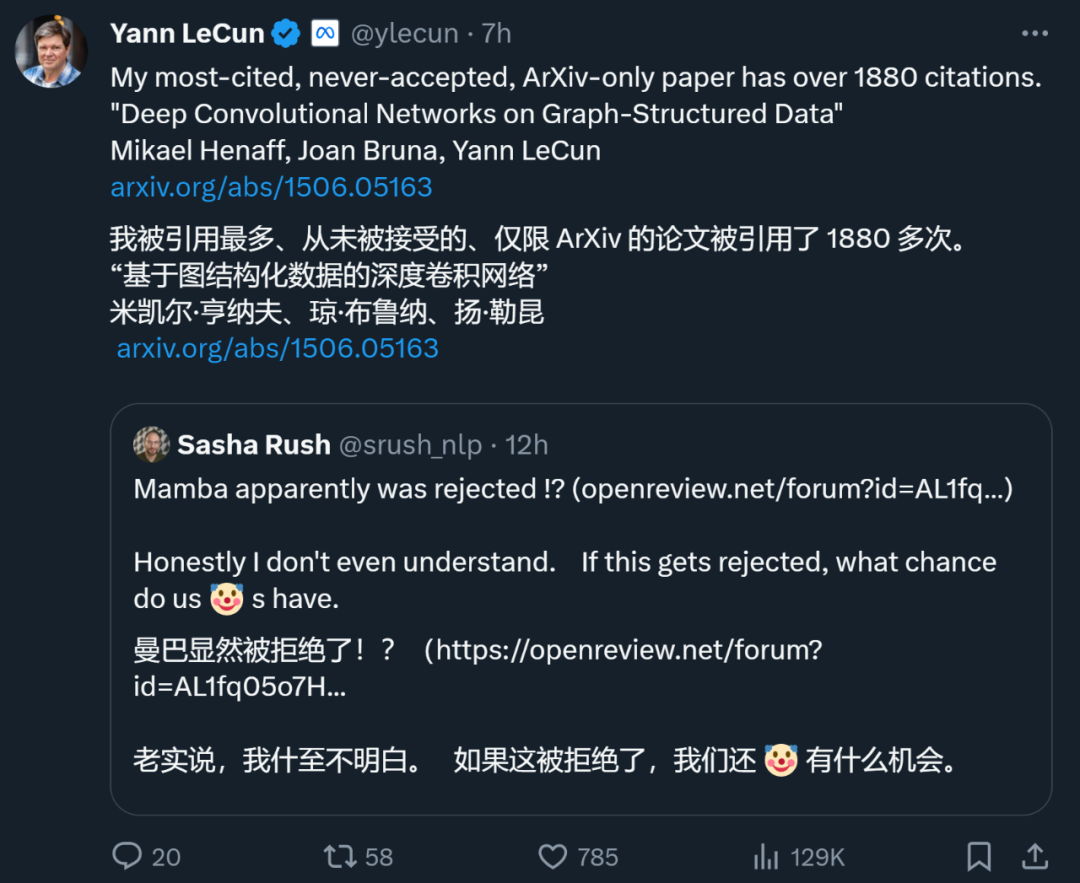
Während der ICML 2022 reichte er sogar „drei Artikel ein und drei wurden abgelehnt.“

Nur weil das Papier von einer bestimmten Spitzenkonferenz abgelehnt wird, heißt das nicht, dass es keinen Wert hat. Von den oben genannten abgelehnten Beiträgen entschieden sich viele für die Übertragung auf andere Konferenzen und wurden schließlich angenommen. Daher schlugen Internetnutzer vor, dass Mamba zu COLM wechseln sollte, das von jungen Wissenschaftlern wie Chen Danqi gegründet wurde. COLM ist ein akademischer Ort, der sich der Sprachmodellierungsforschung widmet und sich auf das Verständnis, die Verbesserung und die Kommentierung der Entwicklung der Sprachmodelltechnologie konzentriert. Er ist möglicherweise die bessere Wahl für Arbeiten wie die von Mamba.
Aber unabhängig davon, ob Mamba letztendlich vom ICLR akzeptiert wird, ist es zu einem einflussreichen Werk geworden und hat der Community auch Hoffnung gegeben, die Fesseln von Transformer zu durchbrechen und Hoffnung in die Erforschung jenseits des Traditionellen zu bringen Transformatormodell. Neue Energie.
Das obige ist der detaillierte Inhalt vonWarum hat das ICLR Mambas Papier nicht akzeptiert? Die KI-Community hat eine große Diskussion entfacht. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Welche Methode wird verwendet, um Strings in Objekte in Vue.js umzuwandeln?
Apr 07, 2025 pm 09:39 PM
Welche Methode wird verwendet, um Strings in Objekte in Vue.js umzuwandeln?
Apr 07, 2025 pm 09:39 PM
Bei der Konvertierung von Zeichenfolgen in Objekte in Vue.js wird JSON.Parse () für Standard -JSON -Zeichenfolgen bevorzugt. Bei nicht standardmäßigen JSON-Zeichenfolgen kann die Zeichenfolge durch Verwendung regelmäßiger Ausdrücke verarbeitet und Methoden gemäß dem Format oder dekodierten URL-kodiert reduziert werden. Wählen Sie die entsprechende Methode gemäß dem String -Format aus und achten Sie auf Sicherheits- und Codierungsprobleme, um Fehler zu vermeiden.
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
 VUE.JS Wie kann man ein Array von String -Typ in ein Array von Objekten umwandeln?
Apr 07, 2025 pm 09:36 PM
VUE.JS Wie kann man ein Array von String -Typ in ein Array von Objekten umwandeln?
Apr 07, 2025 pm 09:36 PM
Zusammenfassung: Es gibt die folgenden Methoden zum Umwandeln von VUE.JS -String -Arrays in Objektarrays: Grundlegende Methode: Verwenden Sie die Kartenfunktion, um regelmäßige formatierte Daten zu entsprechen. Erweitertes Gameplay: Die Verwendung regulärer Ausdrücke kann komplexe Formate ausführen, müssen jedoch sorgfältig geschrieben und berücksichtigt werden. Leistungsoptimierung: In Betracht ziehen die große Datenmenge, asynchrone Operationen oder effiziente Datenverarbeitungsbibliotheken können verwendet werden. Best Practice: Clear Code -Stil, verwenden Sie sinnvolle variable Namen und Kommentare, um den Code präzise zu halten.
 So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
So stellen Sie die Zeitüberschreitung von Vue Axios fest
Apr 07, 2025 pm 10:03 PM
Um die Zeitüberschreitung für Vue Axios festzulegen, können wir eine Axios -Instanz erstellen und die Zeitleitungsoption angeben: in globalen Einstellungen: vue.Prototyp. $ Axios = axios.create ({Timeout: 5000}); In einer einzigen Anfrage: this. $ axios.get ('/api/user', {timeout: 10000}).
 So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
Die MySQL -Leistungsoptimierung muss von drei Aspekten beginnen: Installationskonfiguration, Indexierung und Abfrageoptimierung, Überwachung und Abstimmung. 1. Nach der Installation müssen Sie die my.cnf -Datei entsprechend der Serverkonfiguration anpassen, z. 2. Erstellen Sie einen geeigneten Index, um übermäßige Indizes zu vermeiden und Abfrageanweisungen zu optimieren, z. B. den Befehl Erklärung zur Analyse des Ausführungsplans; 3. Verwenden Sie das eigene Überwachungstool von MySQL (ShowProcessList, Showstatus), um die Datenbankgesundheit zu überwachen und die Datenbank regelmäßig zu sichern und zu organisieren. Nur durch kontinuierliche Optimierung dieser Schritte kann die Leistung der MySQL -Datenbank verbessert werden.
 Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Standort: Remote-Büro-Jobtyp: Vollzeitgehalt: 130.000 bis 140.000 US-Dollar Stellenbeschreibung Nehmen Sie an der Forschung und Entwicklung von Mobilfunkanwendungen und öffentlichen API-bezogenen Funktionen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken. Die Hauptaufgaben erledigen die Entwicklungsarbeit unabhängig von RubyonRails und arbeiten mit dem Front-End-Team von React/Redux/Relay zusammen. Erstellen Sie die Kernfunktionalität und -verbesserungen für Webanwendungen und arbeiten Sie eng mit Designer und Führung während des gesamten funktionalen Designprozesses zusammen. Fördern Sie positive Entwicklungsprozesse und priorisieren Sie die Iterationsgeschwindigkeit. Erfordert mehr als 6 Jahre komplexes Backend für Webanwendungen
