

Der Aufbau eines Weltmodells, das Videos erstellen kann, kann auch mit Transformer erreicht werden!
Forscher der Tsinghua-Universität und Jiji Technology haben sich zusammengetan, um ein neues universelles Weltmodell für die Videogenerierung auf den Markt zu bringen – WorldDreamer.
Es kann eine Vielzahl von Aufgaben zur Videogenerierung ausführen, darunter natürliche Szenen und autonome Fahrszenen, wie Vincent-Videos, Tu-Videos, Videobearbeitung, Action-Sequenz-Videos usw.

Nach Angaben des Teams ist WorldDreamer der erste in der Branche, der ein universelles Szenario-Weltmodell durch Vorhersage von Token erstellt.
Es wandelt die Videogenerierung in eine Sequenzvorhersageaufgabe um, die die Veränderungen und Bewegungsmuster der physischen Welt vollständig lernen kann.
Visuelle Experimente haben bewiesen, dass WorldDreamer ein tiefes Verständnis für die dynamischen Veränderungen der allgemeinen Welt hat.
Welche Videoaufgaben können damit erledigt werden und wie effektiv ist es?
WorldDreamer kann zukünftige Frames basierend auf einem einzelnen Bild vorhersagen.
Nur das erste Bild wird eingegeben. WorldDreamer behandelt die verbleibenden Videobilder als maskierte visuelle Token und sagt diese Token voraus.
Wie im Bild unten gezeigt, kann WorldDreamer hochwertige Videos auf Filmniveau erstellen.
Die resultierenden Videos zeigen eine nahtlose Bild-für-Bild-Bewegung, ähnlich den sanften Kamerabewegungen in echten Filmen.
Darüber hinaus halten sich diese Videos strikt an die Einschränkungen des Originalbilds und gewährleisten so eine bemerkenswerte Konsistenz bei der Bildkomposition.

WorldDreamer kann auch Videos basierend auf Text generieren.
Nur bei der Eingabe von Sprachtext betrachtet WorldDreamer alle Videobilder als maskierte visuelle Token und sagt diese Token voraus.
Das Bild unten zeigt die Fähigkeit von WorldDreamer, Videos aus Text unter verschiedenen Stilparadigmen zu generieren.
Das generierte Video passt nahtlos zur Eingabesprache, wobei die vom Benutzer eingegebene Sprache den Videoinhalt, den Stil und die Kamerabewegung beeinflussen kann.

WorldDreamer kann weitere Video-Inpainting-Aufgaben umsetzen.
Konkret kann der Benutzer bei einem gegebenen Video den Maskenbereich festlegen und dann den Videoinhalt des maskierten Bereichs entsprechend der Spracheingabe ändern.
Wie im Bild unten gezeigt, kann WorldDreamer die Qualle durch einen Bären oder die Eidechse durch einen Affen ersetzen, und das ersetzte Video stimmt in hohem Maße mit der Sprachbeschreibung des Benutzers überein.

Darüber hinaus kann WorldDreamer Videos stilisieren.
Geben Sie, wie im Bild unten gezeigt, ein Videosegment ein, in dem bestimmte Pixel zufällig maskiert werden, und WorldDreamer kann den Stil des Videos ändern, z. B. einen Herbstthema-Effekt basierend auf der Eingabesprache erstellen.

WorldDreamer kann auch Fahr-Action-to-Video in autonomen Fahrszenarien generieren.
Wie in der Abbildung unten gezeigt, kann WorldDreamer bei gleichem Anfangsbild und unterschiedlichen Fahrstrategien (z. B. Linkskurve, Rechtskurve) Videos generieren, die den Einschränkungen und Fahrstrategien des ersten Bildes in hohem Maße entsprechen.

Wie erreicht WorldDreamer diese Funktionen?
Forscher glauben, dass die fortschrittlichsten Videogenerierungsmethoden hauptsächlich in zwei Kategorien unterteilt werden: Transformer-basierte Methoden und Diffusionsmodell-basierte Methoden.
Durch die Verwendung von Transformer zur Token-Vorhersage können die dynamischen Informationen von Videosignalen effizient erlernt und die Erfahrung der großen Sprachmodell-Community wiederverwendet werden. Daher ist die Transformer-basierte Lösung eine effektive Möglichkeit, ein allgemeines Weltmodell zu erlernen.
Methoden, die auf Diffusionsmodellen basieren, lassen sich nur schwer in ein einzelnes Modell integrieren und lassen sich nur schwer auf größere Parameter erweitern. Daher ist es schwierig, die Änderungen und Bewegungsgesetze der allgemeinen Welt zu erlernen.
Die aktuelle Weltmodellforschung konzentriert sich hauptsächlich auf die Bereiche Spiele, Roboter und autonomes Fahren und ist nicht in der Lage, allgemeine Weltveränderungen und Bewegungsmuster umfassend zu erfassen.
Daher schlug das Forschungsteam WorldDreamer vor, um das Lernen und Verstehen von Veränderungen und Bewegungsmustern in der allgemeinen Welt zu verbessern und dadurch die Fähigkeit zur Videogenerierung erheblich zu verbessern.
WorldDreamer baut auf den erfolgreichen Erfahrungen mit groß angelegten Sprachmodellen auf und übernimmt die Transformer-Architektur, um das Weltmodell-Modellierungsframework in ein unbeaufsichtigtes visuelles Token-Vorhersageproblem umzuwandeln.
Die spezifische Modellstruktur ist in der folgenden Abbildung dargestellt:
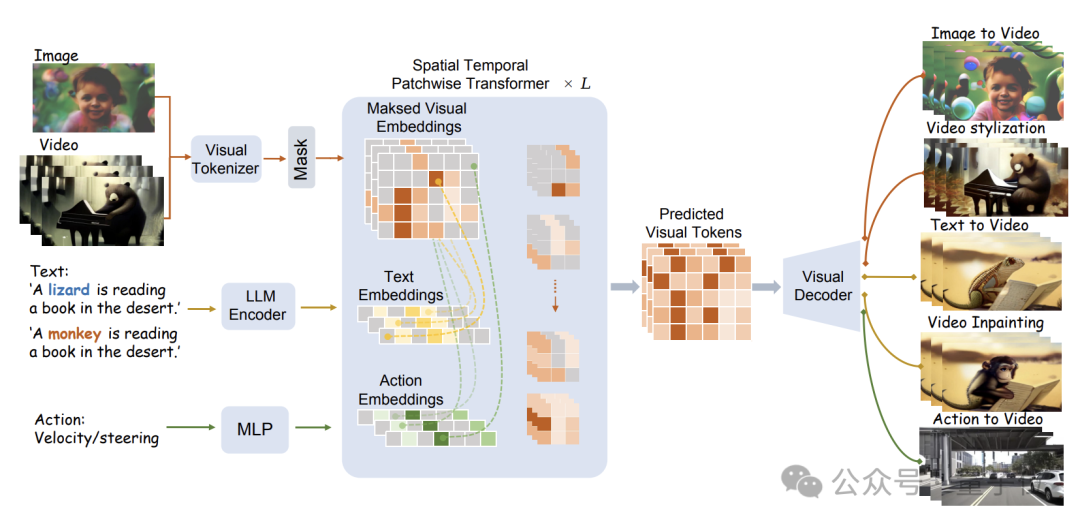
WorldDreamer verwendet zunächst einen visuellen Tokenizer, um visuelle Signale (Bilder und Videos) in diskrete Token zu kodieren.
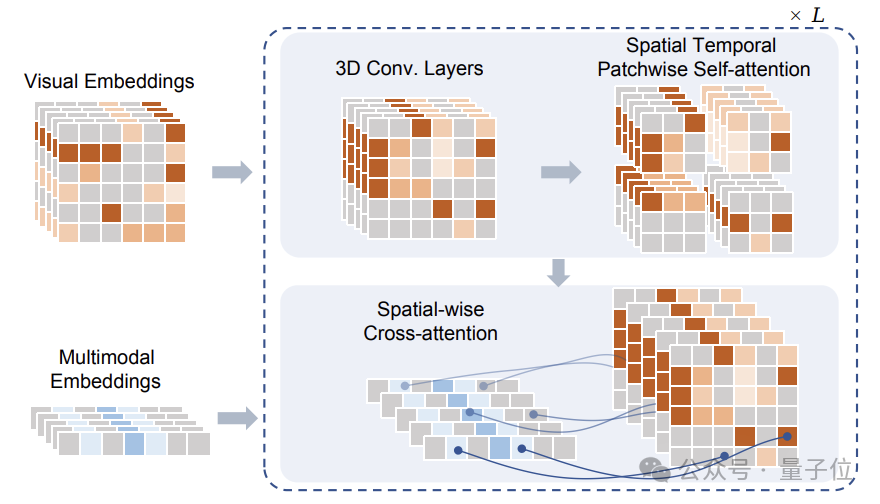
Nach der Maskierung werden diese Token in das vom Forschungsteam vorgeschlagene Sptial Temporal Patchwuse Transformer (STPT)-Modul eingegeben.
Gleichzeitig werden Text- und Aktionssignale in entsprechende Merkmalsvektoren kodiert, um als multimodale Merkmale in STPT eingegeben zu werden.
STPT lernt intern vollständig interaktiv Bild-, Sprach-, Aktions- und andere Funktionen und kann das visuelle Zeichen des maskierten Teils vorhersagen.
Letztendlich können diese vorhergesagten visuellen Token verwendet werden, um eine Vielzahl von Videogenerierungs- und Videobearbeitungsaufgaben abzuschließen.
Es ist erwähnenswert, dass das Forschungsteam beim Training von WorldDreamer auch ein Triplett von Visual-Text-Action-Daten (Visual-Text-Action) erstellt hat und die Verlustfunktion während des Trainings nur die Vorhersage des maskierten Vision-Tokens umfasst. es gibt kein zusätzliches Überwachungssignal.
In dem vom Team vorgeschlagenen Datentriplett sind nur visuelle Informationen erforderlich, sodass das WorldDreamer-Training auch ohne Text- oder Aktionsdaten durchgeführt werden kann.
Dieser Modus verringert nicht nur die Schwierigkeit der Datenerfassung, sondern ermöglicht WorldDreamer auch, die Durchführung von Videogenerierungsaufgaben ohne bekannte oder nur eine einzige Bedingung zu unterstützen.
Das Forschungsteam nutzte eine große Datenmenge, um WorldDreamer zu trainieren, darunter 2 Milliarden bereinigte Bilddaten, 10 Millionen Videos häufiger Szenen, 500.000 hochwertige sprachkommentierte Videos und fast tausend Videos autonomer Fahrszenen.
Das Team führte Millionen iterativer Schulungen auf 1 Milliarde Ebenen lernbarer Parameter durch. Nach der Konvergenz verstand WorldDreamer nach und nach die Veränderungen und Bewegungsmuster der physischen Welt und verfügt über verschiedene Videogenerierungs- und Videobearbeitungsfunktionen.
Papieradresse: https://arxiv.org/abs/2401.09985
Projekthomepage: https://world-dreamer.github.io/
Das obige ist der detaillierte Inhalt vonDas Transformer-Modell lernt erfolgreich die physische Welt mithilfe von 2 Milliarden Datenpunkten bei der Generierung von Herausforderungsvideos. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



